如何使用Weaviate构建语义搜索引擎

译者 | 李睿
审校 | 重楼
Weaviate是一款开源向量数据库,专为处理高维非结构化数据(文本、图像、视频)设计,通过向量嵌入实现语义搜索,替代传统关键字匹配。其核心优势包括人工智能原生架构、分布式扩展、基于图形的模型及混合搜索能力。本文将通过代码示例和实际应用,探讨Weaviate成为游戏规则改变者的原因。
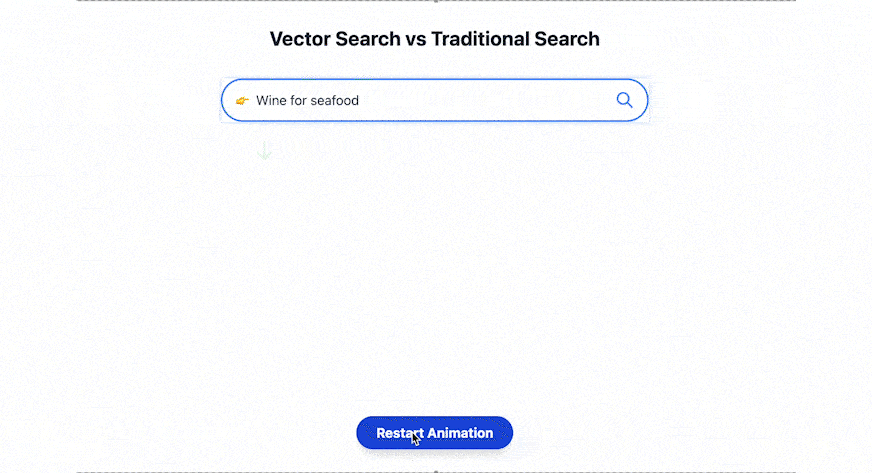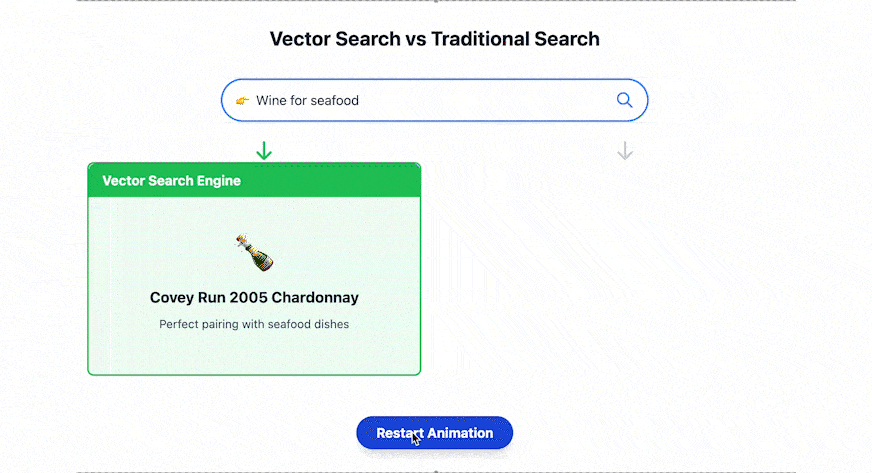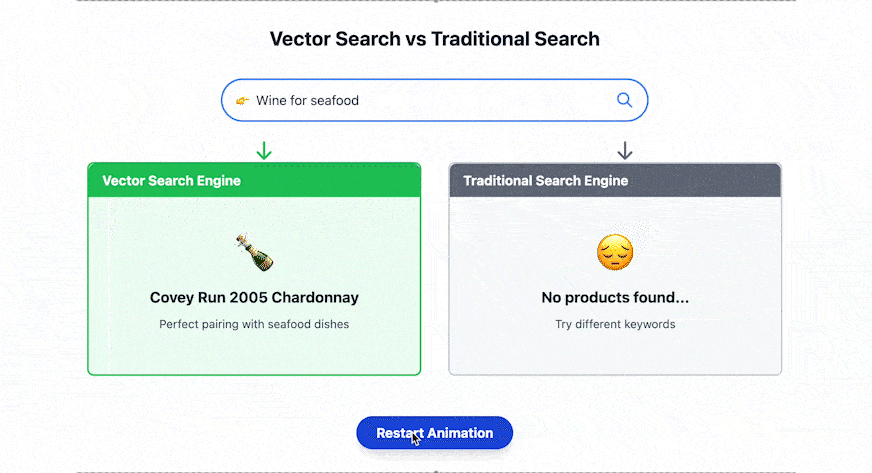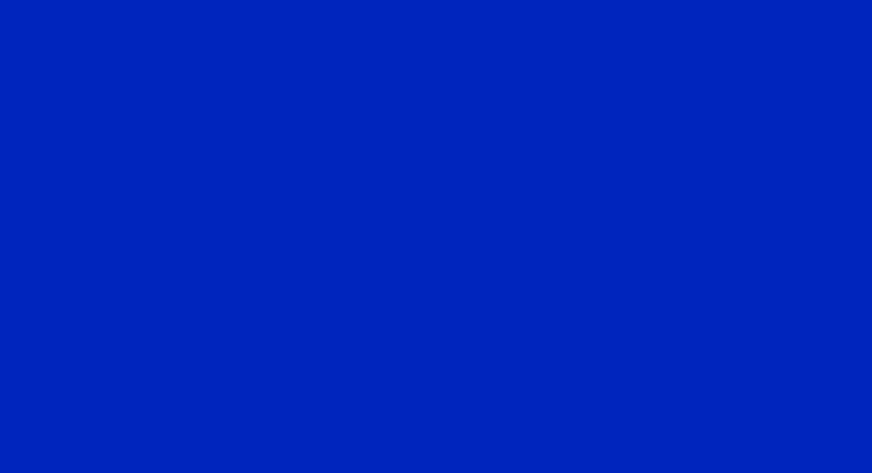
人们获取与关联信息的方式正在经历根本性的转变。在传统搜索模式中,用户需要拆分关键词进行检索,例如输入“舒适”(cozy)和“角落”(nook),而现代语义搜索技术可以直接输入“舒适的阅读角落”(cozy reading nooks)将会呈现出“壁炉旁软椅”等符合语义关联的视觉化内容。这种基于语义理解的搜索范式,标志着信息检索从机械式关键词匹配向自然语言理解的跨越。这一转变至关重要,因为在人工智能时代,图像、文本、视频等非结构化数据呈现指数级增长,传统数据库已经难以满足人工智能时代的需求。
这正是Weaviate发挥重要作用的地方,并使其成为向量数据库领域的领导者。凭借其独特的功能和性能,Weaviate正在改变企业使用基于人工智能的见解和数据的方式。本文将通过代码示例和实际应用,探讨Weaviate为何能成为游戏规则的改变者。
Weaviate是什么?
Weaviate是一款开源向量数据库,专门用于存储和处理以向量表示的高维数据,例如文本、图像或视频等。Weaviate允许企业进行语义搜索,创建推荐引擎,并轻松构建人工智能模型。
Weaviate专注于智能数据检索,而不是依赖于基于每行存储的列检索精确数据的传统数据库。它使用基于机器学习的向量嵌入来根据语义找到数据点之间的关系,而不是搜索精确的数据匹配。
Weaviate提供了一种简单的方法来构建运行人工智能模型的应用程序,这些模型需要快速有效地处理大量数据来构建模型。在Weaviate中存储和检索向量嵌入使其成为涉及非结构化数据的企业的理想选择。
Weaviate的核心原理和架构
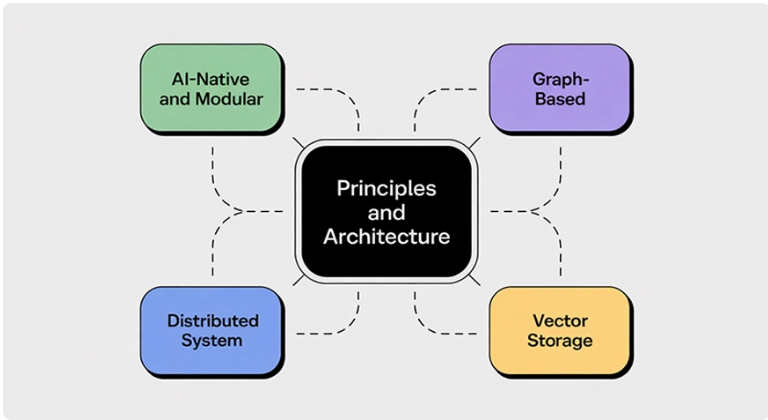
Weaviate的核心是建立在处理高维数据和利用高效和可扩展的向量搜索的原则之上。以下是其架构的设计原则与核心模块:
人工智能原生和模块化:Weaviate从设计之初就将机器学习模型集成到架构中,为其开箱即用地生成不同数据类型的嵌入(向量)提供支持。模块化设计允许用户扩展功能、集成自定义特性或调用外部系统。分布式系统:数据库被设计成能够横向扩展。Weaviate采用无领导者架构,这意味着没有单点故障。通过多节点数据复制实现高可用性,即使节点故障也能保障数据安全。最终一致性使其适用于云原生及其他环境。基于图形:Weaviate是一种基于图形的数据模型。对象(向量)通过它们的关系连接起来,使得具有复杂关系的数据易于存储和查询,这在推荐系统等应用程序中非常重要。向量存储:Weaviate旨在将数据存储为向量(对象的数值表示)。这非常适合支持人工智能的搜索、推荐引擎和所有其他人工智能/机器学习相关用例。Weaviate快速入门:实践指南
无论是在构建语义搜索引擎、聊天机器人还是推荐系统,这都无关紧要。Weaviate快速入门指南将演示如何连接到Weaviate,摄取向量化内容,并提供智能搜索功能,最终通过使用OpenAI模型的检索增强生成(RAG)生成上下文感知的答案。
前提条件确保安装了最新版本的Python。如果没有安装,可以使用如下命令安装:
创建并激活虚拟环境:
使用上述代码,shell提示符现在将显示虚拟环境名称(例如weaviate-env),表明环境已经激活。
步骤1:部署Weaviate部署Weaviate有两种方法:
选项1:使用Weaviate云服务部署Weaviate的一种方法是使用其云服务:
首先,登录https://console.weaviate.cloud/。然后,注册并通过选择OpenAI模块创建集群。还要注意WEAVIATE_URL(类似于https://xyz.weaviate.network)以及WEVIATE_API_KEY。
选项2:使用Docker Compose在本地运行创建docker- composer .yml:
配置Weaviate容器与OpenAI模块和匿名访问。
使用以下命令启动它:
这将以分离模式启动Weaviate服务器(在后台运行)。
步骤2:安装Python依赖项要安装程序所需的所有依赖项,需要在操作系统的命令行中运行以下命令:
这将安装Weaviate Python客户机和OpenAI库。
步骤3:设置环境变量对于本地部署,不需要WEAVIATE_API_KEY(无需验证)。
步骤4:连接到Weaviate前面的代码使用凭据连接Weaviate云实例,并确认服务器已经启动并可访问。
对于本地实例,使用:
这将连接到本地Weaviate实例。
步骤5:使用嵌入和生成支持定义模式定义了一个名为Question的模式,其中包含属性和基于openai的向量和生成模块。
输出:
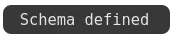
上述语句将模式上传到Weaviate并确认成功。
步骤6:批量插入样例数据创建一个小型QA数据集:
以批处理方式插入数据以提高效率:
输出:
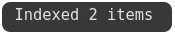
确认已经索引的项目数量。
步骤7:使用nearText进行语义搜索使用文本向量对“largest elephant”等概念进行语义搜索。仅返回确定性≥0.7且最多2个结果的结果。
输出:

显示具有确定性分数的结果。
步骤8:检索-增强生成(RAG)语义搜索,并要求Weaviate使用OpenAI(通过generate)生成响应。
输出:

根据Weaviate数据库中最接近的匹配项打印生成的答案。
Weaviate的主要特性
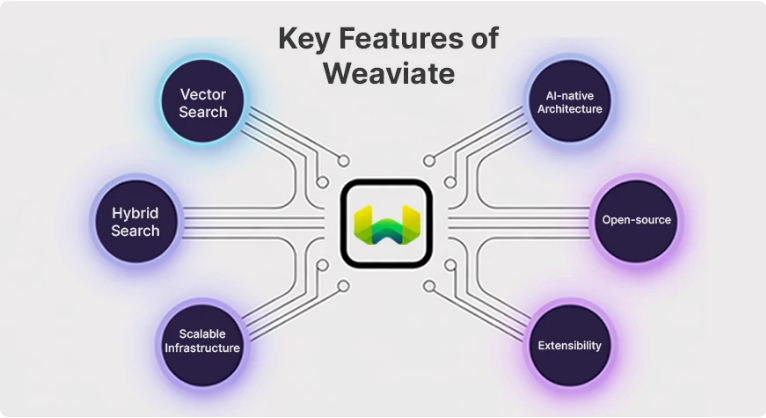
Weaviate有许多独特的功能,使它在大多数基于向量的数据管理任务中具有灵活和强大的优势。
向量搜索:Weaviate可以将数据作为向量嵌入进行存储和查询,从而进行语义搜索;它提高了准确性,因为基于意义而不是简单地匹配关键字来找到相似的数据点。混合搜索:通过将向量搜索和传统的基于关键字的搜索结合起来,Weaviate提供了更相关和上下文相关的结果,同时为各种用例提供了更大的灵活性。可扩展的基础设施:Weaviate能够使用单节点和分布式部署模型进行操作;它可以横向扩展以支持非常大的数据集,并确保性能不受影响。人工智能原生架构:Weaviate旨在与机器学习模型一起工作,支持直接生成嵌入,而无需通过额外的平台或外部工具。开源:作为开源软件,Weaviate允许一定程度的定制、集成,甚至允许用户在其持续发展中做出贡献。可扩展性:Weaviate通过模块和插件支持可扩展性,使用户能够从各种机器学习模型和外部数据源集成。Weaviate vs 竞争对手
下表强调了Weaviate和在向量数据库领域的一些竞争对手之间的主要区别。
特性
Weaviate
开源
是
否
是
是
混合搜索
是(向量+关键词)
否
是(向量+关键词)
是(向量+关键词)
分布式架构
是
是
是
是
内置AI模型支持
是
否
否
否
云原生集成
是
是
是
是
数据复制
是
否
是
是
如上表所示,Weaviate是唯一提供混合搜索的向量数据库,它既可以进行向量搜索,也可以进行基于关键字的搜索。因此,有更多的搜索选项可用。Weaviate是开源的,不像Pinecone是闭源的。Weaviate的开源优势和透明库提供了有益于用户的定制选项。
特别是,Weaviate将机器学习集成到数据库中,使其解决方案与竞争对手的解决方案截然不同。
结论
Weaviate是一款处于行业前沿的基于向量的数据库,具有革命性的人工智能原生的架构,旨在处理高维数据,同时还结合了机器学习模型。Weaviate的混合数据和搜索功能及其开源特性为每个可想象的行业中的人工智能应用程序提供了强大的解决方案。Weaviate的可扩展性和高性能使其成为非结构化数据的领先解决方案。从推荐引擎和聊天机器人到语义搜索引擎,Weaviate充分发挥其先进功能的潜力,帮助开发人员增强他们的人工智能应用程序。随着人工智能解决方案需求的增长;Weaviate在向量数据库领域的重要性将变得越来越重要,并将通过其处理复杂数据集的能力从根本上影响该领域的未来。
常见问题
Q1:Weaviate是什么?答:Weaviate是一款开源向量数据库,专为高维数据(如文本、图像或视频)而设计,用于实现语义搜索和人工智能驱动的应用程序。
Q2:Weaviate与传统数据库有何不同?答:与检索精确数据的传统数据库不同,Weaviate使用基于机器学习的向量嵌入来检索结构化数据,并根据含义和关联进行检索。
Q3:Weaviate中的混合搜索是什么?答:Weaviate中的混合搜索结合了向量搜索和基于关键字的传统搜索的概念,为更多样化的用例提供相关和上下文相关的结果。
原文标题:Building a Semantic Search Engine using Weaviate,作者:Janvi Kumari