Geo技术助力,让风险定位更精准
1 业务背景
2 技术选型
2.1 MySQL2.2 Redis2.3 ElasticSearch3 Coding
3.1 GEOADD
3.2 GEOPOS
3.3 GEODIST
3.4 GEORADIUS
4 原理解析
4.1 存储结构
4.2 GeoHash编码
4.3 编码原理
4.4 总结
5 参考资料
1.业务背景
某天在工位上的我,正在敲着代码,听着歌,突然就被打断了:
小G:快来看看!我们的订单都被诈骗了!!!
我:What?什么情况?
小G:有些黑中介引导我们用户下单租赁,把订单机器寄到他们那里,拿到机器后再补贴给用户一笔钱,然后这批机器我们就拿不回来啦!
我:emmmm...那这些订单有没有什么特征呢?
小G:噢也有,他们的下单的地址都是黑中介那边指定的某地址,我们也是通过这部分集中下单的地址数据进行分析得知的。
我:噢那我有个想法,如果用户的下单地址与黑中介指定下单地址相同,或者在其附近,是否就可以认为这个订单有诈骗风险?
小G:可以!
于是,新的需求又开始了。
2.技术选型
要判断用户地址与中介地址是否相同,或者相近。那落到实际功能开发,其实就是计算两个地址之间的距离,由距离长短决定是否相同,或相近。
那地址之间距离计算又如何实现呢?那当然是站在巨人的肩膀上开发啦,下面就来介绍下开发中常用的GEO(Geolocation)工具,以及他们之间的区别。
2.1 MySQL
2.1.1 优兼容性:最常用的关系型数据之一。其与项目兼容度高,与其他业务数据(如用户表、订单表)天然集成,无需跨数据源查询,通用性强。持久性:数据持久化存储,适合长期保存地址数据。2.1.2 劣性能:大数据量下(如百万级以上的地址经纬度)的复杂查询(地址空间计算)性能较低。2.2 Redis
2.2.1 优性能:基于内存存储,查询/数据操作延时极低,适合实时查询/计算操作。GEO内部数据存储结构为Sorted Set,支持高效的范围查询和排序。
扩展性:支持集群模式,适合分布式场景。
2.2.2 劣存储:内存容量有限,不适合长期存储海量数据。功能:不支持高级地理计算(如面积计算、地理围栏计算)。2.3 ElasticSearch
2.3.1 优性能:分布式架构,适合海量数据和高并发场景。内部倒排索引和分片机制,优化查询性能和保证容错。内置地址空间数据类型,支持复杂地址查询(地理围栏、距离排序、多边形查询等)2.3.2 劣复杂度:需要维护ES集群,开发学习成本较高存储:内存和磁盘占用较高,不适合小规模场景3.Coding
经过上面的分析,结合需求的场景,首先保证性能,次要无须重量级的框架,开发成本低,同时还要能够满足地理计算的基本要求。于是,果断选择 Redis!
3.1 GEOADD
用于添加一个或多个地理位置信息(经纬度)
例子:添加一个key为gk,包含 天安门,故宫 的经纬度
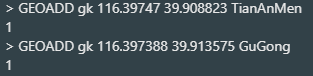 图片
图片
3.2 GEOPOS
用于查询某一个key中的指定地址经纬度
例子:查询gk中 天安门 和 故宫 的经纬度
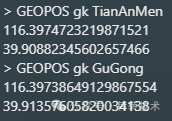 图片
图片
3.3 GEODIST
用于查询同一个key两个地址之间的距离
例子:查看gk中 天安门 和 故宫的距离(m)
 图片
图片
3.4 GEORADIUS
用于查询同一个key中指定地址范围半径内的地址
例子:查询gk中以 天安门 为中心,半径1000km的地址
 图片
图片
Java代码如下
4.原理解析
从上面的示例来看,在使用的角度来说还是简洁易懂的。所谓知其然,知其所以然,所以接下来我们再深究下,Redis的GEO是如何实现两个地址的经纬度之间的距离计算的呢?
4.1 存储结构
Redis的GEO底层实现采用的是Sorted Set有序集合结构,其中key存储元素信息,value存储经纬度(即权重)。而经纬度包含经度和纬度两个信息,因此需要使用GeoHash编码的方式将经纬度转化成float类型进行存储。
4.2 GeoHash编码
上面提到了GeoHash编码,其实是分别对经度和纬度进行编码,然后再组合成一个新的编码。这个方法叫:二分区间编码
4.3 编码原理
对于一个经纬度来说,经度的范围是[-180, 180],纬度的的范围是[-90, 90]。而GeoHash编码针对两个范围进行N次(N可自定义)的二分区编码,将其转化成一个N位的二进制值。
以经度为例,在进行第一次二分区时,将经度范围[-180, 180]进行二分,得到两个区间 [-180, 0) 和 [0, 180]。然后判断当前经度落在哪个区间,若落在左区间,则记录为0;若落在右区间,则记录为1。如此反复,每次都会得到一个二进制值。
例子:将经度(116.37)进行5次二分区后得到编码值:11010(如图下)
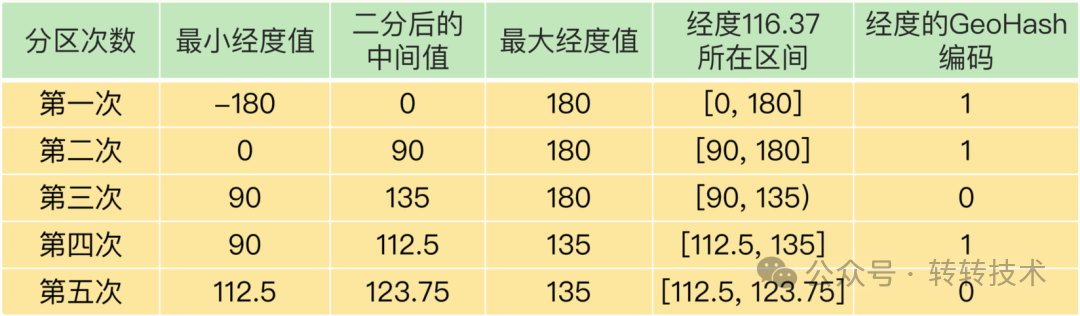 图片
图片
再将纬度(39.86)进行5次二分区后得到编码值:10111(如图下)
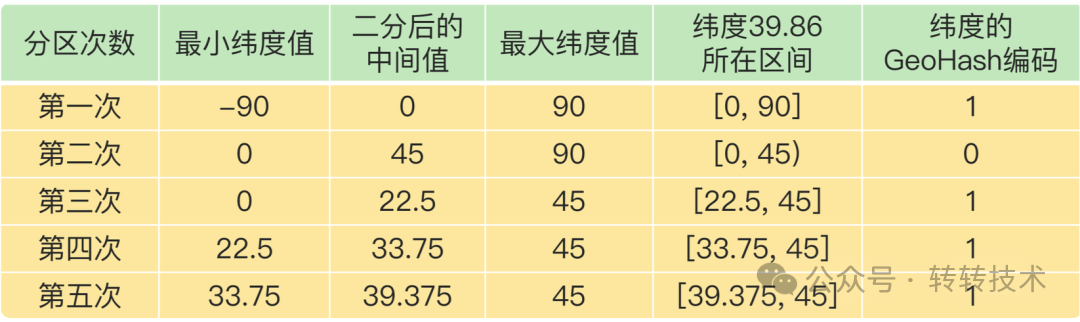 图片
图片
现在得到经纬度编码之后的值,需要再将其组合成一个编码。同时遵循组合规则(如图下)
从左到右按顺序,将经度编码值逐个放入偶数位从左到右按顺序,将纬度编码值逐个放入奇数位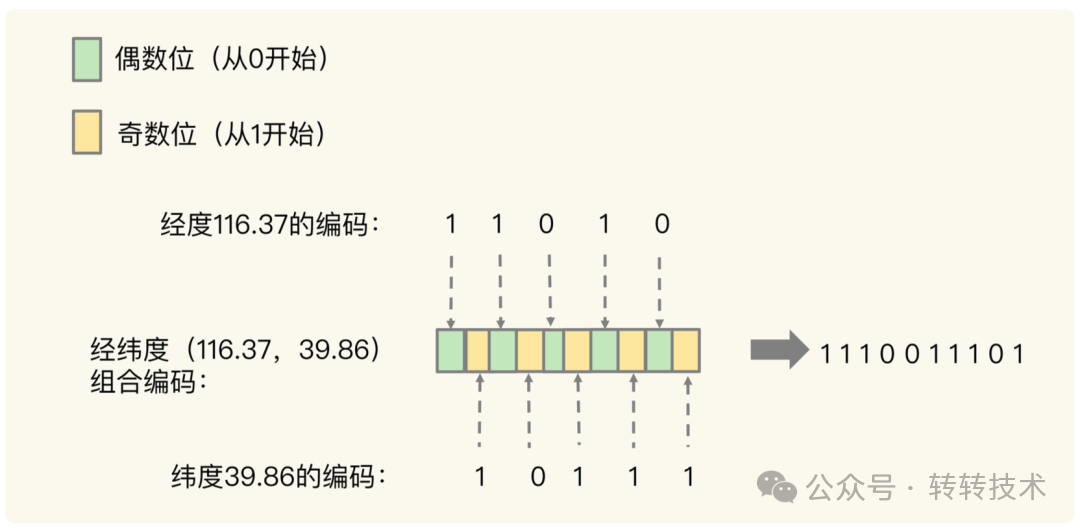 图片
图片
最终两个编码值,转化成了一个编码值(1110011101),同时保存到Sorted Set的value中。至此,编码完成。
4.4 总结
了解了GeoHash的编码原理,那这样编码有什么用呢?下面来解答这个问题。
例子:我们把 经度区间[-180, 180],纬度区间[-90, 90] 都做一次二分区编码,那么就会得到4个分区(如下图)
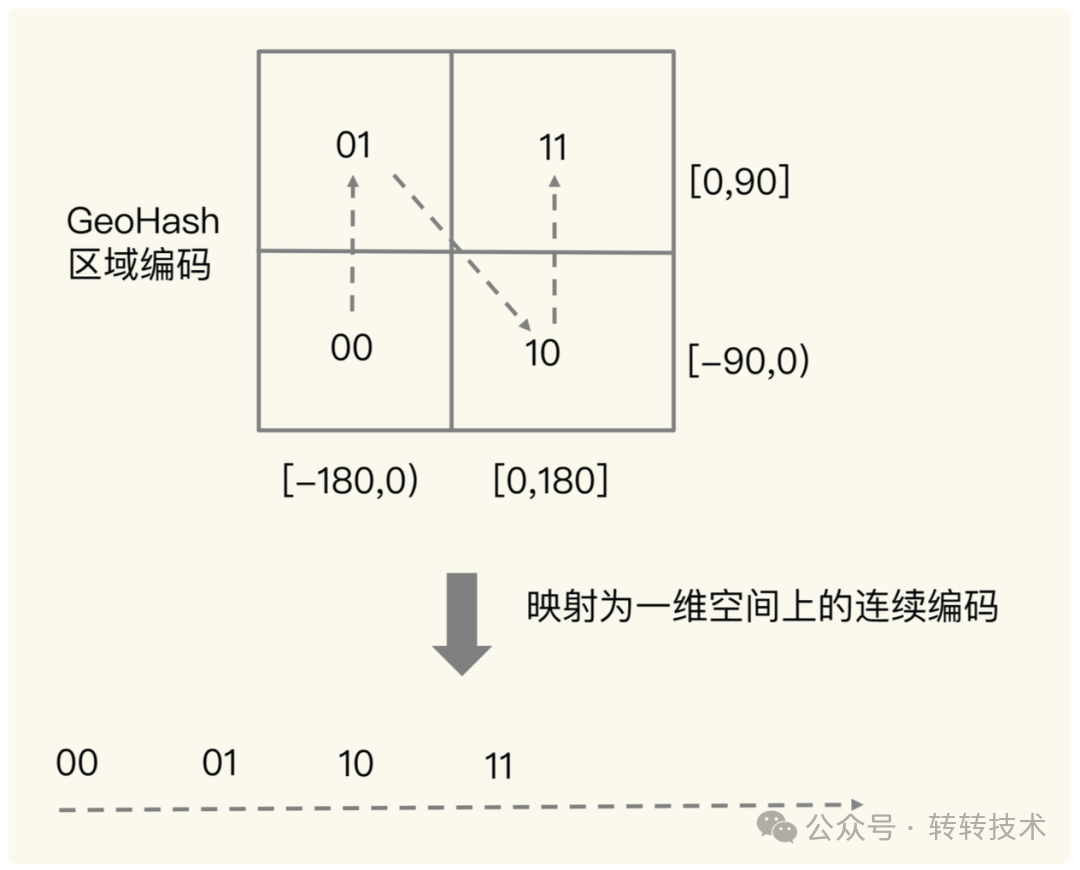
经过一次二分区编码后,本来是二维信息的经纬度,就简化成了一维信息的编码。换句话说,对于整个地理空间来说,所有的位置都能经过编码变成平面上的一个点,多个点便能组成一条线,由此计算距离便有迹可循了。
而一次二分区的结果,便是图中的4个方格,同时也对应了4个分区,每个分区都包含指定范围的经纬度。那对于N次二分区来说,N越大,分区也越多,每个分区所包含的经纬度范围就越小(所能覆盖的地理空间越小),对应映射在一维空间上的点越小,点越小则越精准。
需要注意的是,虽然分区越多,经纬度在地理空间上代表的位置则越精准,但对于距离统计来说,并不是分区越多越好。
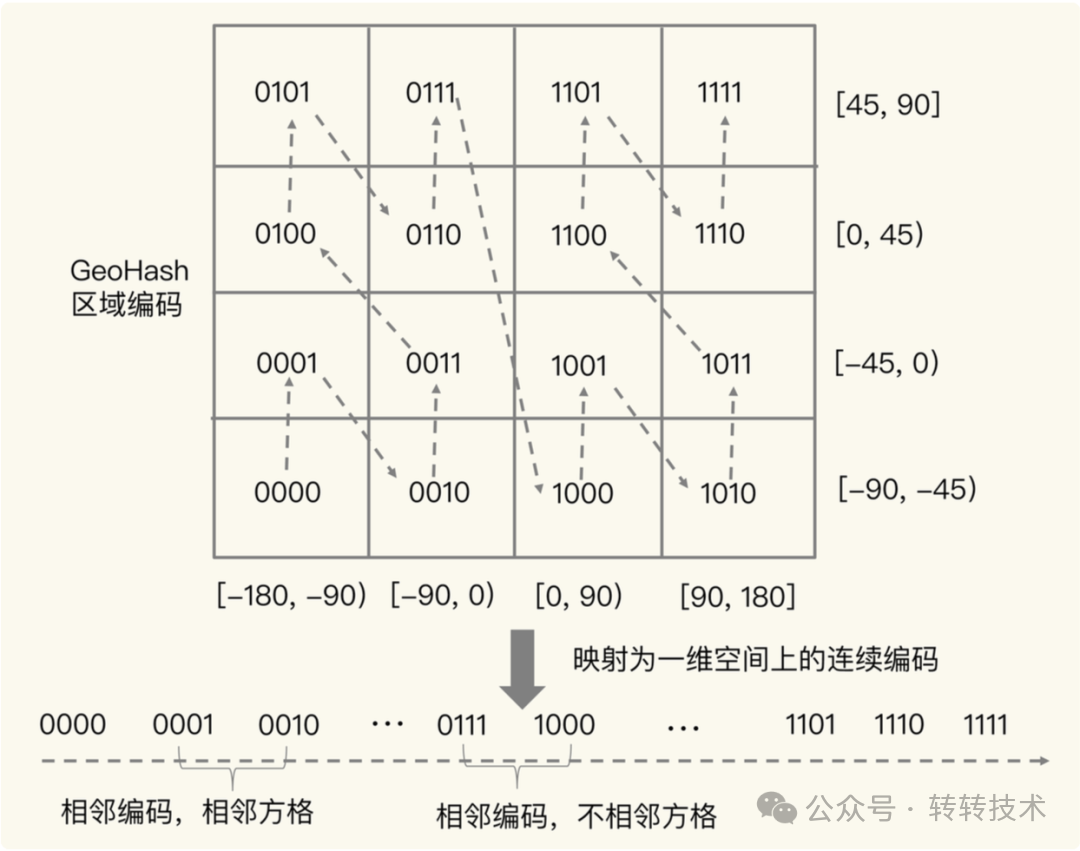
例子:还是延续上面一次二分区的例子进行举例。这次我们把N+1,做二次二分区(如下图)
 图片
图片
上图可以看到,经过二次二分区后,分区变成了16个。理论上对应地理空间上的位置更加精确了,那么将对应的编码转化为一维空间上的点后,连接成线。发现对于大部分的编码值来说,在线上相邻的编码在空间上也是相邻(如:0001,0010),但是对于某些编码来说(如:0111,1000)在线上相邻,但是在空间上却相差较远。因此,对于这两个分区来说,如果只单纯考虑计算一维空间上的距离,将会造成较大误差。
所以基于以上情况,一般不会只计算编码值的距离,还需要结合分区作为辅助计算。通常在计算过程中,会在经纬度指定的分区周围同时再查询附近的几个分区,作为距离远近的参考,提高距离计算的精度。
5.参考资料
[1] https://cloud.tencent.com/developer/article/1949540
关于作者
冯超,一名转转金融技术部后端开发程序猿