未来AI场景,会是向量数据库为主?还是传统数据库向量化呢?
这几年,向量数据库这个词在AI圈子里火得不行。
有人说它是AI的“记忆库”,有人说它是大模型的“外置大脑”。
那么,向量数据库到底是什么?它和传统数据库有啥区别?在AI场景中又有什么用?
今天,我们一起来研究一下。
1.什么是向量数据库?
简单来说,向量数据库是一种专门用来存储、管理和查询向量数据的数据库。
那什么是向量呢?你可以把它理解为一串数字,用来表示某个对象在多维空间中的位置。
比如,一句话、一张图片、一段音频,甚至是一个用户的行为,都可以被AI模型转换成向量。
假设你让AI看一张猫的照片。
 图片
图片
它不会记住“猫有耳朵、胡须、圆眼睛”,而是把这张图变成一串神秘数字,比如[0.3, -0.7, 1.2…]。
这串数字就是向量,相当于这张图的“数字指纹”。
这些向量不仅包含了语义信息,还能通过计算向量之间的距离来判断它们的相似性。
而向量数据库的任务,就是高效地存储这些向量,并快速找到与某个向量最相似的其他向量
2.向量数据库 vs 传统数据库
那向量数据库跟传统数据库相比,究竟有哪些区别呢?
这里让DeepSeek整理了一张表格:
特性
向量数据库
传统数据库
数据类型
主要处理高维向量数据
处理结构化数据(如文本、数字、日期等)
数据存储
存储向量嵌入(embeddings)
存储表格形式的数据
查询方式
支持相似性搜索(如最近邻搜索)
支持精确匹配和范围查询
索引结构
使用专门索引(如HNSW、Annoy)
使用B树、哈希索引等
应用场景
适用于AI、机器学习、推荐系统等
适用于事务处理、报表生成等
性能优化
针对高维数据相似性搜索优化
针对事务处理和复杂查询优化
数据规模
适合处理大规模非结构化数据
适合处理结构化数据
查询语言
可能使用自定义查询语言或API
使用SQL等标准查询语言
数据关系
通常不强调数据间的关系
强调数据间的关系(如主键、外键)
一致性
可能牺牲一致性以换取性能
通常保证强一致性
3.向量数据库在AI场景的实际应用
搜索传统搜索:输入“红色运动鞋”,返回的可能是包含“红色”和“运动鞋”两个关键词的商品,但未必符合你的预期。
向量搜索:通过理解你的搜索意图,返回风格、颜色、款式都最相似的运动鞋!
实际应用: 电商的“以图搜图”、人脸识别。
生成内容当你问大模型一个问题时,它并不是“死记硬背”地返回答案,而是从数百万个向量中找到最匹配的回答!
比如:
输入问题向量 → 找到最相似的问题 → 返回最佳答案
这样可以让 AI 更具上下文理解能力,提高问答准确性!
比如开源知识问答工具MaxKB的原理,可以看下面这张图:
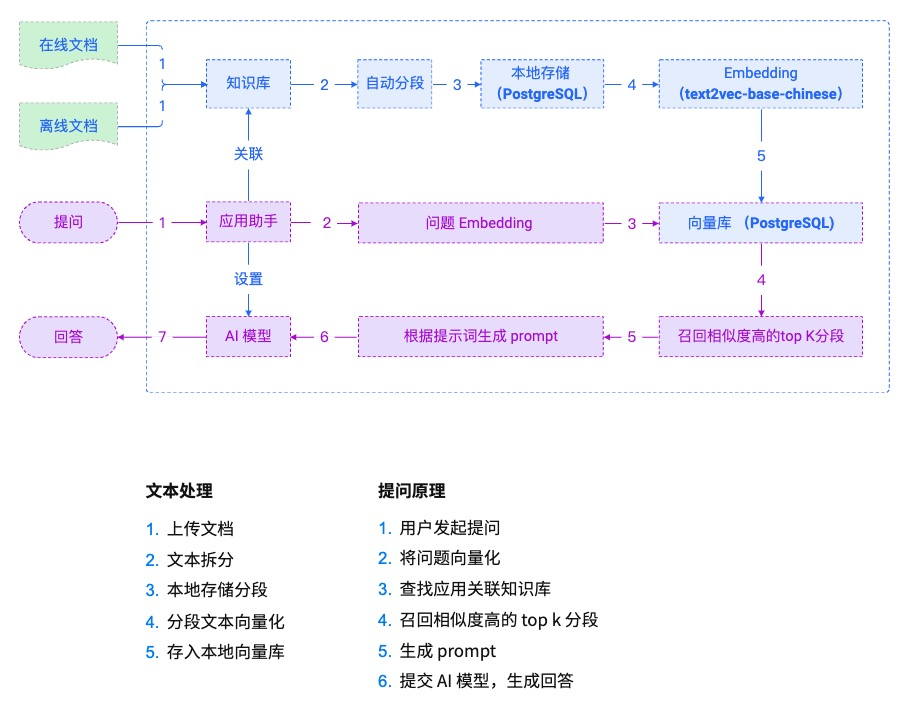 图片来源:https://maxkb.cn/docs/system_arch/
图片来源:https://maxkb.cn/docs/system_arch/
在实际工作中,可能我们想要实现一个功能全面的智能客服,需要在知识库里录入大量的知识内容。
而用户每次询问的时候,假如把所有知识都发给大模型,不单单效率很低,也会多消耗很多token。
所以就需要对知识库进行向量化。
我们在知识库导入内部文档,MaxKB会对文档进行自动分段并存储在本地。
然后经过内置的向量模型对分段的内容进行向量化处理。
最后存储到PostgreSQL数据库中。
当用户提问时,也会对问题进行向量化处理,并优先从向量库中搜索相似度比较高的分段。
再结合提示词给到大模型,最后输出问题。
实际应用: ChatGPT、DeepSeek、知识库、AI客服等。
推荐系统为什么短视频平台推荐如此精准?
背后就是你的浏览记录、观看时长、点赞行为都会被转换成向量。
向量数据库找到与你兴趣最相似的内容,让你越刷越上瘾 。
实际应用: 抖音、B站。
4.向量数据库的代表性产品
目前最流行的向量数据库包括:
Milvus(Zilliz)
FAISS(Facebook AI
Weaviate
Pinecone
等。
5.一些支持向量检索的传统数据库
PostgreSQL 上的 PGVector
Redis
ClickHouse
ES
MySQL 9.0,在Heatwave上支持了向量类型(可惜社区版暂时不能用)。
等等。