面试官:MySQL 使用 group by 语句时发现执行很慢,可能是什么原因?
大家好,我是君哥。
使用 MySQL 时,group by 是我们经常会用到的分组语句,可以帮我们做各种聚合统计工作。但有时候会发现 group by 语句执行很慢,可能是什么原因呢?今天来介绍一下。
1.简介
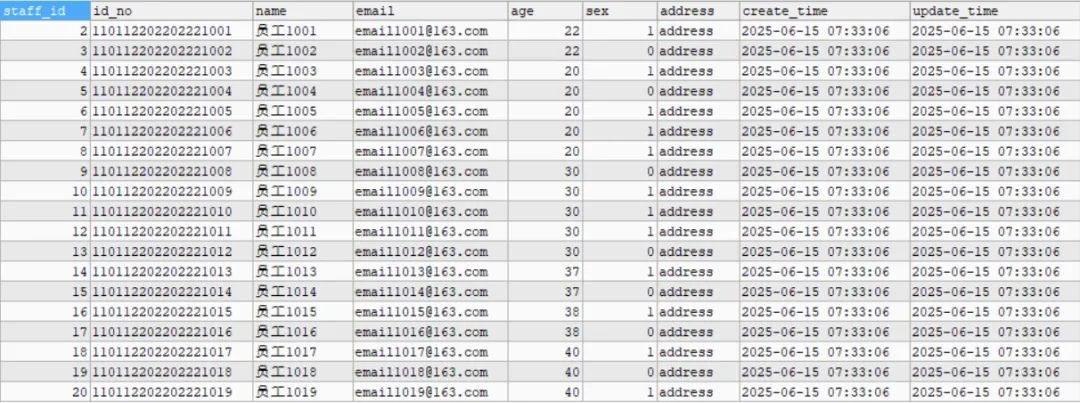
下面我们创建一张员工表:
然后往表中插入 20 条数据:
 图片
图片
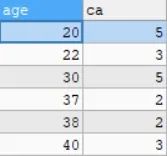
我们用一个简单的分组函数,对年龄(age)进行分组
查询结果如下图:
 图片
图片
可以看到,使用 group by 语句非常方便地对各年龄的员工数量做了统计。
2.查询分析
那使用 group by 语句时为什么会执行慢呢? 我们看一下这条 sql 的执行计划:
 图片
图片
从执行计划可以看到,这条 sql 没有走索引,并且使用到了临时表(Using temporary)和排序(Using filesort)。
注意:filesort 很容易被理解成文件排序,其实不然,MySQL 所有不走索引的排序统称为 filesort,即使数据完全在内存中排序,执行计划 Extra 也会显示 Using filesort。
下面看一下这个语句的执行流程:
创建一个内存临时表,表里有两个字段 age 和 ca,其中 age 字段是主键。扫描要查询的表中记录,取出 age 字段;如果临时表中有这条 age(比如 ag=20) 的记录,则 ca 值加 1,否则插入一条新的记录,比如(age=30,ca=1);4根据 age 做排序,将结果返回。3.如何优化
3.1 是否需要排序
在 MySQL 8.0 以前,GROUP BY 默认是会对分组字段做排序的,即使 sql 中没写 ORDER BY,也会排序。
而且,内存中排序要用到 sort_buffer,如果 sort_buffer 内存不够,就需要依靠磁盘临时表辅助排序,非常影响性能。
如果想要 sql 语句不排序,可以在 sql 尾部加 order by null,修改后的 sql 如下:
修改后再看执行计划,Extra 字段中没有了 Using filesort。
3.2 走索引
对分组字段加索引是最好的优化方法。我们对 age 字段加一个索引:
修改后我们再看一下执行计划
 图片
图片
给 age 字段加上索引后,就不走临时表和 filesort 了。
3.3 磁盘临时表
前面提到过,如果 sort_buffer 内存不够,就需要依靠磁盘临时表辅助排序。为了避免使用磁盘临时表,可以考虑减小结果集,或者临时增加 sort_buffer 大小。
对于内存临时表也一样,如果内存不够,就需要依靠磁盘临时表,可以通过修改 tmp_table_size 参数来避免使用磁盘临时表。
3.4 应用层分组
对于非常复杂的聚合,可以考虑在应用层通过代码分批处理,利用多线程并发处理能力提高效率。这样可以减小数据库压力。
3.5 物理视图
对于超大表,可以考虑增加物理视图来代替 sql 分组,或者使用大数据工具。这样可以同时减少数据库和应用服务的压力,但也带来了额外维护物理视图的工作量,结果集时效性低也不高。
4.总结
group by 语句是非常好用的分组聚合函数,但如果使用不上覆盖索引,效率可能会非常低,尤其是表中数据量比较大的情况下。可以参考本文的方法进行优化。