一文聊透CAP定理
很多同学都知道,在一个分布式系统中,最多只能在一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)中三者满足其二,不能同时满足这三项。
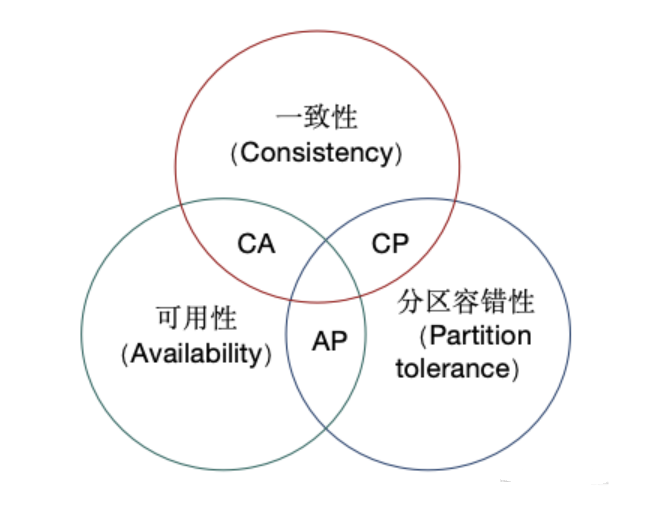
CAP定理
 图片
图片
一致性(Consistency),all nodes see the same data at the same time,按照原文翻译是:在同一时刻,分布式系统中所有节点中的数据是完全一致的。
我们也可以引申理解为“分布式系统的业务逻辑一致性”。
举个例子:用户 A 给用户 B 转账 100 元,那么在任何时刻,我们都必须能够同时看到用户 A 的账户少了 100 元,用户 B 的账户多了 100 元。
一致性分为强一致性、弱一致性和最终一致性。
强一致性,业务结果中的每个步骤,在“任何时刻”都同时生效。CAP 定理中所说的一致性就是强一致性,上述例子中所描述的也是强一致性。弱一致性,不能保证业务结果中的每个步骤,在“任何时刻”都同时生效。最终一致性,经过一段时间以后,业务结果中的每个步骤都会最终生效。可用性(Availability),reads and writes always succeed,按照原文翻译是:任何时候,分布式系统的读写操作都是成功的。
也就是说,在规定时间内,分布式系统对接收到的每个用户请求,都可以返回正常的业务结果。
分区容错性(Partition tolerance),the system continues to operate despite arbitrary message loss or failure of part of the system,这个说得比较绕一些。
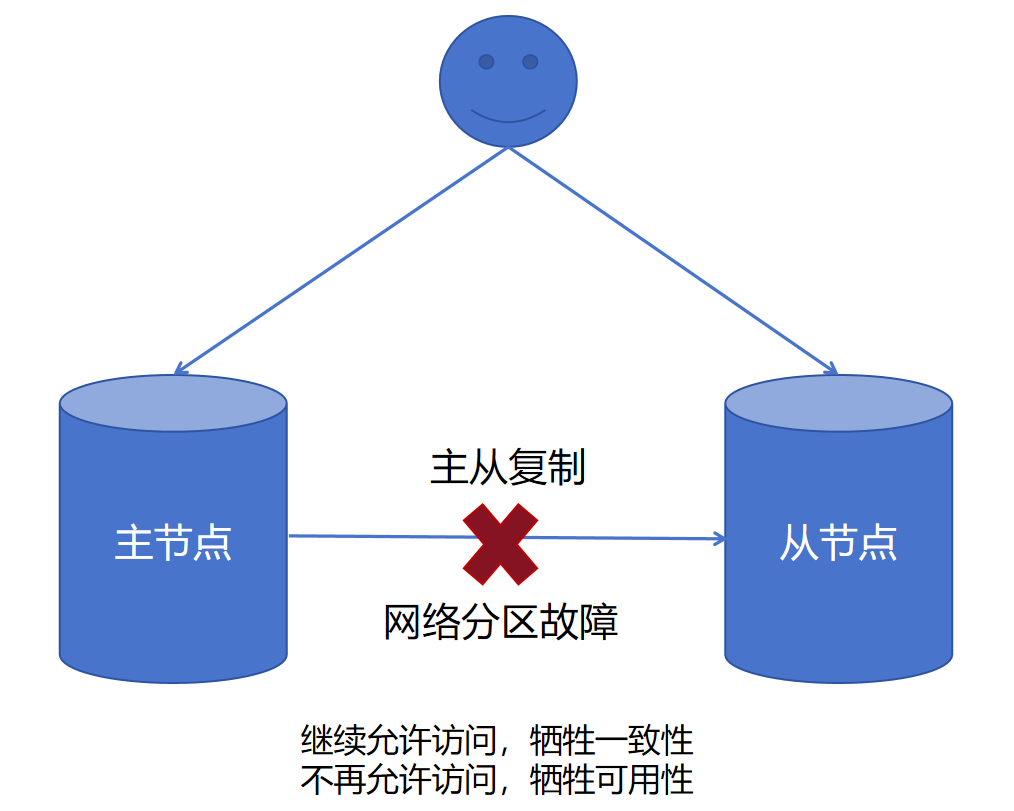
我们可以这样理解,当分布式系统遇到网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务。
这里的网络分区故障,指的是集群中各个节点的网络相互不连通,被分成了几个孤立的区域。
 图片
图片
BASE定理
BASE 定理是对 CAP 定理中 AP 方案的延伸,旨在通过最终一致性的方式来替代 CAP 定理中的强一致性。
BASE 定理 = 基本可用(Basically Available)+ Soft state(软状态)+ Eventually consistent(最终一致性)
基本可用,当分布式系统出现不可预知故障的时候,允许损失部分可用性,保证其核心功能可用。软状态,允许分布式系统中的数据存在中间状态,且该中间状态的存在不会影响系统的整体可用性。最终一致性,经过一段时间以后,分布式系统能够达到业务逻辑一致性的状态。对于分布式事务来说,可以分为刚性事务和柔性事务两种,其中刚性事务中的2PC、3PC满足于 CAP 定理中 CP 的要求。
而柔性事务中的TCC、SAGA、本地消息表、事务消息和最大努力通知,则符合于 BASE 定理。
接下来我们再着重于分析一下,我们常用的一些中间件集群,它们都符合于CAP定理中的哪两个,为我们日常工作中的技术选型提供一些参考。
MySQL主从架构
MySQL主从复制属于AP还是CP模型不能一概而论,因为其支持三种方式:异步复制(默认)、半同步复制和全同步复制。
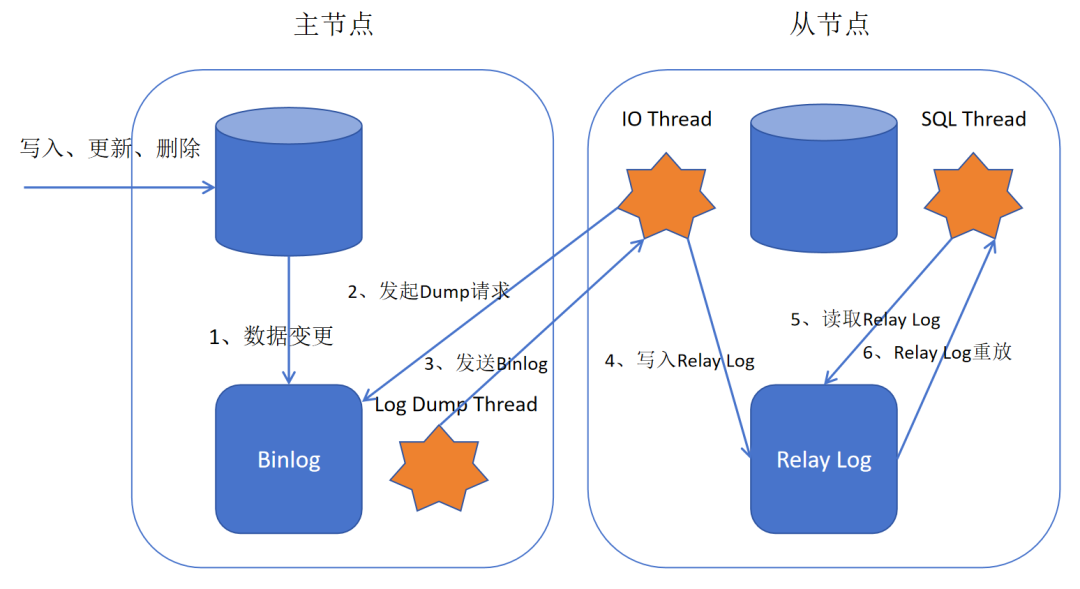
MySQL中的异步复制属于AP模型。
主库执行写操作并将该变更记录到Binlog文件中,此时就会给客户端返回结果,不需要等待从库对主库的日志事件进行确认。
 图片
图片
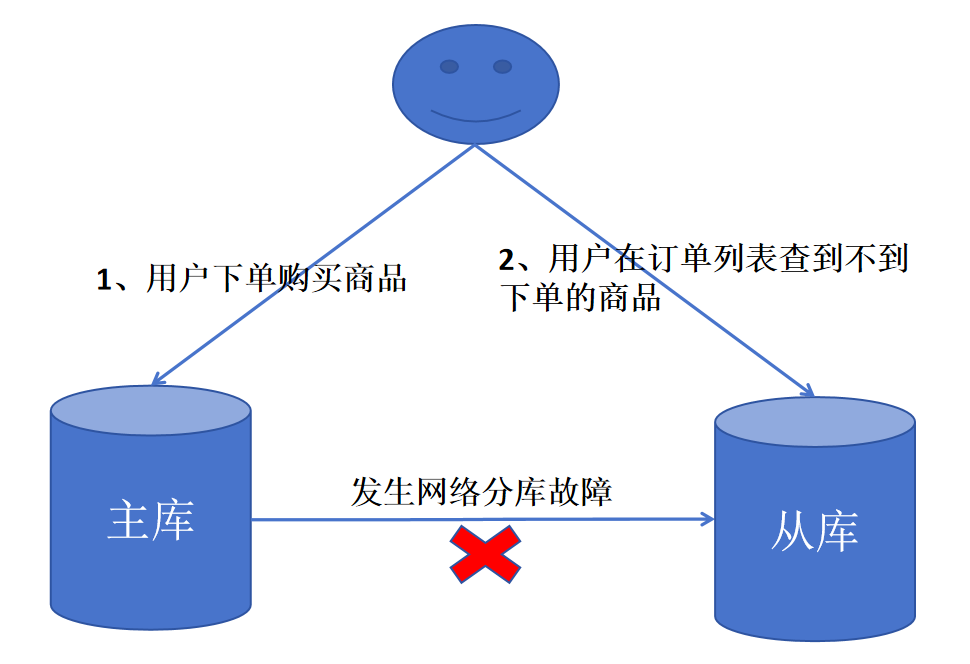
当异步复制方式出现网络分区故障时,主库无法将变更的数据同步到从库,就会产生主从库数据不一致的情况。
以经典的电商下单场景为例:
 图片
图片
MySQL中的全同步复制属于CP模型。
MySQL主库执行写操作,并将该变更记录到Binlog文件中,还需要等待所有从库对主库的日志事件进行确认后,才会给客户端返回结果。
这里需要说明的是,只有在从库的IO Thread将从主库接收的Binlog文件写入到本地的Relay Log中,才会对主库的日志事件进行确认。
当全同步复制方式出现网络分区故障时,主库为了保证与从库的数据一致性,将不再接受insert、update、delete等写操作,直到故障恢复。
MySQL中的半同步复制属于AP模型。
MySQL主库执行写操作,并将该变更记录到Binlog文件中,还需要等待至少一个从库(可配置)对主库的日志事件进行确认后,才会给客户端返回结果。
也就是说,半同步复制不需要保证全部主从数据库的数据一致性。
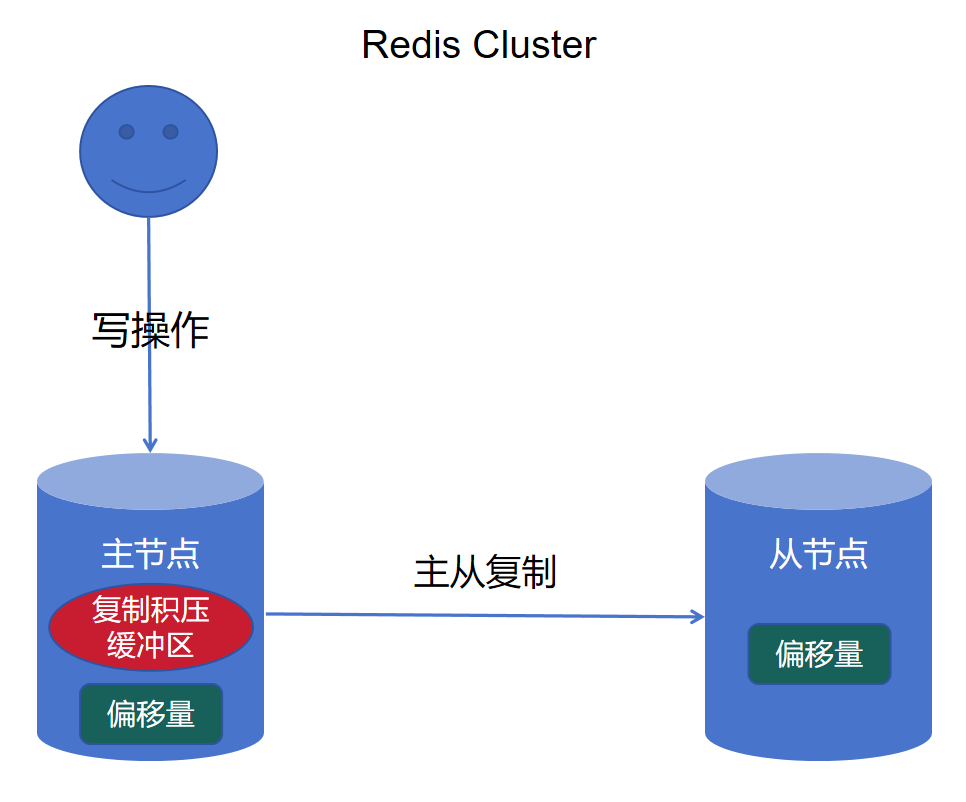
Redis Cluster
Redis Cluster的主从复制过程为:
Redis Cluster中的主节点每执行一个写操作,都会将该命令写入到复制积压缓冲区中,并更新自己的偏移量。
同时,主节点通过 TCP 连接将写命令发送给从节点,从节点执行命令后更新自己的偏移量,保持与主节点一致。
需要注意的是,主节点发送命令后无需等待从节点确认,而继续执行新的操作,可能会存在 “主节点宕机时,部分命令未同步到从节点” 的数据丢失风险。
 图片
图片
主节点和从节点各自维护一个偏移量,记录已处理的字节数(主节点发送的字节数、从节点接收的字节数),当两者偏移量相等时,说明数据完全同步。
复制积压缓冲区主节点内部维护一个固定大小的环形缓冲区(默认 1MB),用于缓存最近发送的写命令。
当从节点因网络波动短暂断线后重新连接时,会向主节点发送自己的偏移量,主节点只需将缓冲区中 “从节点缺失的命令”(偏移量之后的命令)发送给从节点,无需全量同步,大幅减少开销。
由此可见,Redis Cluster也属于AP模型,否则就不需要复制偏移量和复制积压缓冲区来保证最终一致性了。
ElasticSearch集群
ElasticSearch集群写操作的实现原理为,客户端请求通过协调节点路由到主分片,主分片处理完成后同步至副本分片。
而写操作一致性的设定,是通过consistency参数实现的,包括:one(仅主分片确认)、all(全部分片确认)和 quorum(大多数分片确认,默认值)。
quorum的计算公式为:int((primary_shards + number_of_replicas) / 2) + 1,如果ElasticSearch集群有三个主分片和一个副本,那至少有三个分片可用才能执行写入操作。
由此可见,ElasticSearch集群属于CP模式还是AP模式,需要看具体设定,如果consistency参数设置为all是CP模式,否则是AP模式。