加速 MySQL 主从同步,核心架构设计思路!
MySQL主从同步为什么这么慢?
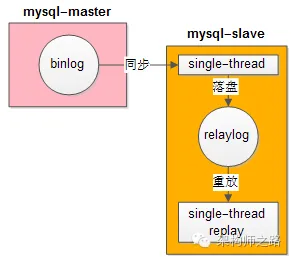
如上所示,主库binlog同步到从库,从库单线程落盘relaylog,单线程重放relaylog,在数据量大并发量大的时候,就会很慢。
如何来进行优化?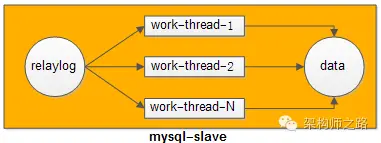
可以多线程并行重放relaylog来缩短同步时间。
多线程并行重放能否保证与主库数据的一致性?例如:三个set语句,分在三个线程重放,不能保障与主库执行序列的一致性。
复制
update X set money=100 where uid=58;
update X set money=150 where uid=58;
update X set money=200 where uid=58;1.2.3.
随机分配肯定不行,但可以按库来分配:
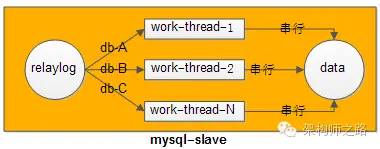
以此来够缩短同步时间。
为什么很多公司还是同步很慢呢?这个锅DBA不背。
大概是架构师在数据库架构设计时,MySQL使用了单库多表模式,升级为多库多表模式即可。
画外音:单库多表模式,还是一个线程重放。
数据库架构,多库多表模式有什么好处?主从同步快;逻辑上还能按照业务子业务进行库隔离;扩容方便,性能出现瓶颈时,加实例就能拆库扩容;架构师说拆不开怎么办?要么是架构师不懂,要么是把业务实现在SQL语句里了,导致拆不开。
如果已经是单库多表模式,库无法拆分开,还有其它方法缩短主从同步时间吗?可以进一步优化:将主库上同时并行执行的事务,分为一组,编一个号,这些事务在从库上的回放也可以并行执行。
画外音:事务在主库上的执行同时进入到prepare阶段,说明事务之间没有冲突,否则就不可能提交。
简言之:同一组提交的事务,没有锁冲突,可以并行重放。
MySQL将组提交的信息存放在GTID中,使用mysqlbinlog工具,可以看到组提交内部的内部信息:
复制
14:15 XXX GTID last_committed=0 sequence_numer=1
14:15 XXX GTID last_committed=0 sequence_numer=2
14:15 XXX GTID last_committed=0 sequence_numer=3
14:15 XXX GTID last_committed=0 sequence_numer=41.2.3.4.
如果具备相同的last_committed,说明它们在一个组内,可以并发回放执行。
总结mysql并行复制,缩短主从同步时延的核心架构思路无非两点:
单线程回放,升级为多线程并发回放;确保并发回放幂等性:“按照库幂等”,“按照组幂等”是两种不同颗粒度的实现方式;更具体的:
mysql5.5 -> 不支持并行复制,赶紧升级mysql;mysql5.6 -> 支持按照库并行复制,赶紧升级“多库”架构;mysql5.7 -> 支持按照GTID并行复制;知其然,知其所以然。
思路比结论更重要。
阅读剩余
THE END