从单机到分布式:拆解高并发数据库架构的六大生死决策
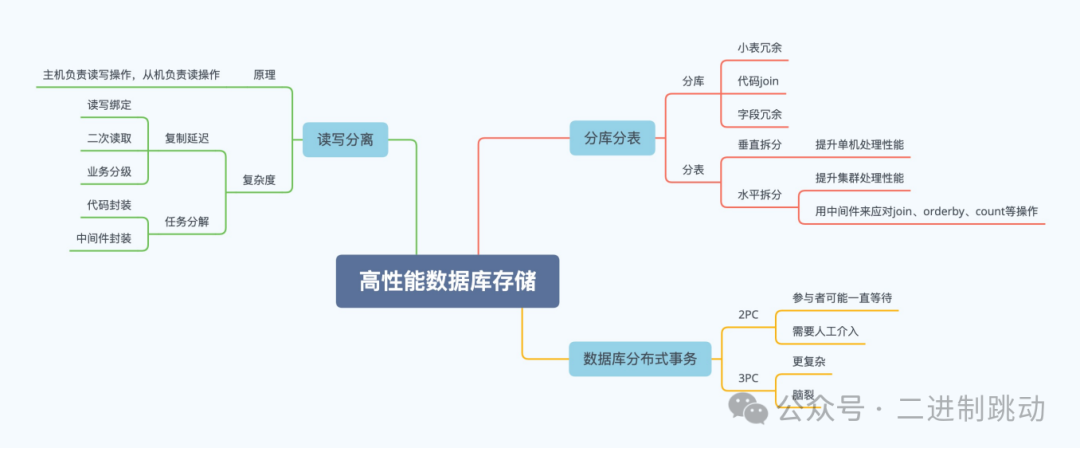
一、数据库读写分离
核心原理
主从集群搭建:一主一从/一主多从,主机负责读写,从机只读。数据同步:主机通过复制同步数据到从机,所有节点存储全量数据。流量分发:业务层将写操作指向主机,读操作分发至从机。适用场景
业务量持续增长,且已优化索引、引入缓存后仍性能不足。常见问题与解法
问题:写后读数据不一致(如刚写入主机,从机未同步)。解法:读写绑定:写后读强制走主机(侵入性强,易留坑)。二次读取:从机读失败后重试主机(增加主机压力)。业务分级:核心业务读写均走主机,非核心业务读写分离(需严格编码规范)。实现方式对比
方式
中间件代理
客户端分库
复杂度
高(需独立部署、集群管理)
低(基于JDBC封装)
维护成本
高(需高可用设计)
低(无额外部署)
语言支持
跨语言
需各语言单独实现
二、数据库分库分表拆分策略
垂直拆分:按列拆分,解决单表字段过多问题(常见于2B场景)。水平拆分:按行拆分,分散数据压力(常见于2C海量数据场景)。拆分时机
B+树层数超过3层(约2000万数据)。单表数据占满Innodb Buffer Pool(如2G数据)。数据持续增长且性能瓶颈明显。核心问题与解法
Join失效:a.冗余小表(如字典表)。
b.代码层手动Join。
c.字段冗余(如订单表直接存商品类型)。
事务一致性:引入分布式事务(如2PC、3PC)。路由与聚合:路由算法(如Hash、范围分片)。分片后Count/Order by需中间件或应用层聚合。扩展限制数据库连接数瓶颈(如MySQL默认100连接)。中间件聚合操作性能受限,需权衡分片数量。三、数据库分布式事务算法主流方案对比
算法
2PC(两阶段提交)
3PC(三阶段提交)
流程
1. 准备阶段2. 提交/回滚阶段
1. CanCommit2. PreCommit3. DoCommit
优点
强一致性,实现简单
减少阻塞,降低超时风险
缺点
协调者单点故障、同步阻塞
存在脑裂风险(部分提交、部分回滚)
XA事务实践
外部XA:跨多数据库实例,由应用代码协调(如PHP示例中的多库事务)。内部XA:单实例多存储引擎事务,由Binlog协调(如MySQL内部机制)。随堂测验**✓** 读写分离仅提升读性能,写仍由主机处理。**✓** 分库分表分散写压力,提升写性能。**✗** 中间件可能成性能瓶颈,需谨慎设计 ? 中间件性能:取决于架构设计(如集群化),不可一概而论 。**✗** 3PC存在脑裂风险,不优先于2PC ? 3PC与2PC选择:需权衡「一致性要求」与「系统可用性」,无绝对优先级。**✓** 协调者可为代码(外部XA)或独立系统(如Binlog)。思考题解析
为何传统数据库不自带分库分表?关系型数据库(如MySQL)设计侧重ACID,分片会破坏事务和Join,需业务层权衡;而Redis/MongoDB等为高扩展设计,牺牲部分特性(如强一致性)内置Sharding支持。站在巨人的肩膀上,架构之路更从容!
 图片
图片
阅读剩余
THE END