百万&千万级 Excel 导出场景怎样实现?怎样优化?
我见过太多网上帖子文章,上来就是各种方案,要换什么API,要加异步,要调内存等各种手段。
看到这些我都有种小时候感冒乡村医生上来就是一堆药的无奈感;至今没见过谁是从真正项目场景出发去分析因果关系。
一切手段都是为了服务场景,服务用户。
 图片
图片
这题明面上问的是 Excel 导出优化,实际上是在扒你对数据链路全流程(查询 - 处理 - 生成 - 传输)的分析感知&处理能力 —— 大部分人一上来就盯着 Excel 生成本身死磕,根本不理解对症下药以及优化过程。
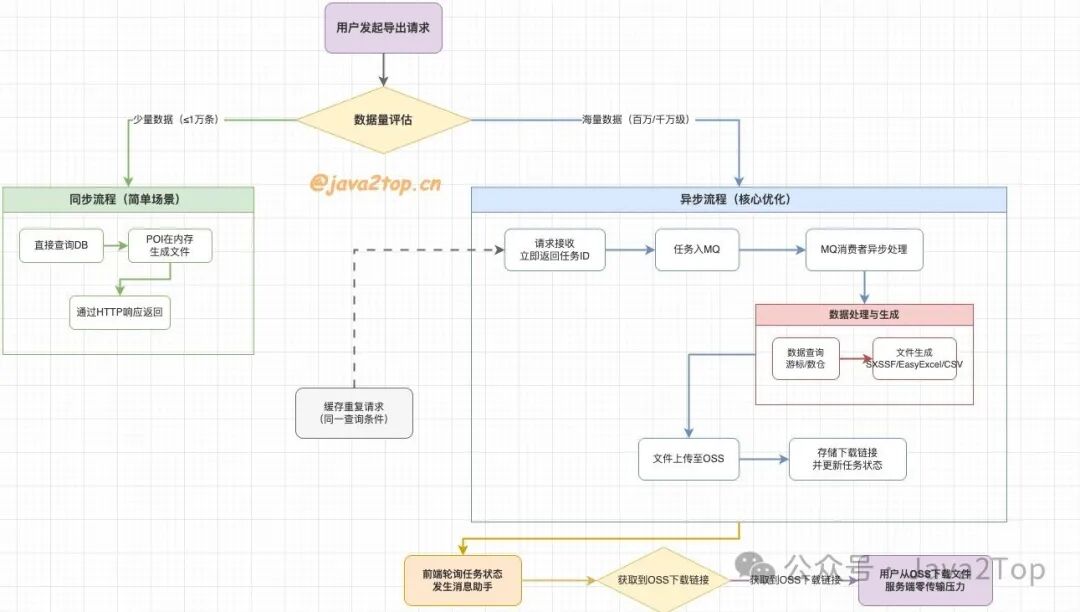
我的风格是总分,从问题场景由浅入深,先花2分钟看下决策图,再跟着我的思路来分析:
 图片
图片
这是你写的代码?
先别急着说你有什么牛逼的方案,我们先从原始问题出发,你最先接手原始的代码可能是这样:前端点导出,后端接口直接查数据库(可能还没加索引),把所有数据一次性捞到内存里,用 POI 同步生成 Excel 文件,最后通过 HTTP 响应直接返回。
你是不是觉得这流程特顺?如果是这样,那你问题大了,我们逐步道来。
先说查库,百万条订单导出挂?
如果导出的数据只有几百条,这方案凑活用。但如果业务方说 “我要导出近一年的订单,大概 100 万条,甚至更多”,你这代码会出啥问题?
首先,查库就卡壳了 ——100 万条数据一次性 select *,就算有索引,MySQL 把结果集拼装好返回给应用,这网络传输和内存占用就够你喝一壶的。
我早年做报表系统时就踩过这坑,一次导出把应用服务的 JVM 堆直接干到 GC 频繁,最后 OOM 挂了一个节点,现在想起来都脸红。
同步导出是 “连接池杀手”?
你真的以为把查库优化了(比如加索引、用 limit 分页)就没事了?好,就算你分页查库,每次查 1 万条,100 次查完。
但接下来同步生成 Excel 的过程,还是在占用着当前的 HTTP 连接 ——Tomcat 的连接池就那么大,要是同时有 10 个用户这么导出,单机容量有限,连接池直接满了,后面的正常请求全排队,这服务不就等于半瘫了?
说白了,同步模式下,导出任务就是个 “连接池杀手”,把请求线程全占着干 “慢活”。
一堆资源都在浪费没有最大化利用,线上风险极高,随时可能打爆你的服务,用户体验也极差。
大文件传输 + 重复点击何解?
就算你扛过了查库和线程占用,生成的 Excel 文件要是有几十 MB,问题又来了 ——HTTP 传输慢不说,前端等待超时怎么办?
用户点了导出,等了 5 分钟没反应,以为没成功,又点了好几次,结果后端重复生成好几个大文件,资源直接 double 浪费。
此时你开始大概意识到问题是什么了,这个场景面对的是些什么问题,把你的思考过程抬上来再谈解决方案,才是合格的RD,也是面试官喜欢的候选人。
优化1:同步改异步
那咱开始优化。首先要解决的不是 Excel,是 **“同步阻塞” 这个巨坑 **。怎么解?异步化。
把 “用户触发导出” 和 “Excel 生成” 拆成两回事 —— 用户点导出时,后端不直接处理,而是生成一个 “导出任务 ID”,扔到 MQ 里,然后立刻返回给前端 “任务已受理,请用 ID 查结果”。
前端拿着 ID 轮询(或者后端直接生成完后通过消息助手通知用户),等 MQ 消费者把 Excel 生成完,再通知用户下载。
 图片
图片
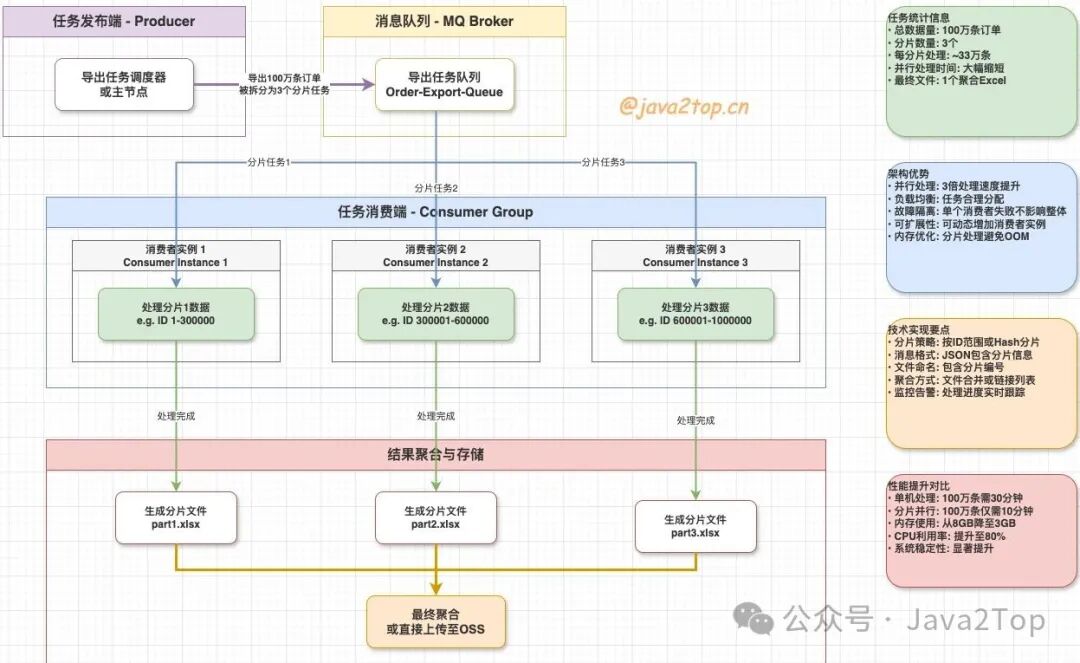
当然最好能利用mq分布式多机消费的特性,将数据量进行分批拆分,每台机器处理一批或者一段,这样就不会导致单机oom
这一步就把请求线程解放了,连接池再也不会被堵死。但这里要注意,异步不是一劳永逸的 —— 你得处理任务状态(等待中 / 生成中 / 成功 / 失败);
还得考虑失败重试(比如生成到一半 MQ 挂了怎么办?),甚至要做任务限流,不能让 1000 个用户同时扔导出任务,把 MQ 和生成服务压垮。
优化2:分页不够,游标 + 数仓来凑
解决了异步,再看数据查询。分页查库是基础,但有个坑:当偏移量很大时(比如 limit 100000, 1000),MySQL 会扫描前面 10 万条数据再跳过,这时候索引效率会骤降。
怎么办?用 “游标分页”—— 比如按订单 ID 排序,每次查的时候带上上次的最大 ID(where id > last_id limit 1000),这样索引一直有效。
另外,要是查库涉及多表关联,或者计算逻辑复杂(比如统计每个用户的订单总额);
直接查业务库会影响线上业务,如果实时性不是那么高,完全可以考虑离线数仓 —— 把导出需要的明细或汇总数据,提前用定时任务同步到 ClickHouse、Hive 这类 OLAP 数据库里,导出时查数仓,不碰业务库。
或者直接扔异步队列里面(注意,最好不要扔线程池,单机容易oom,最好分布式多机消费处理)
大厂稍微大一点的非实时场景基本都是这样干!
优化3:Excel 生成,拆服务、换格式?
接下来才到 Excel 生成本身。直接在应用服务里用 POI 生成,还是有问题 ——100 万条数据生成 Excel,就算用 SXSSF(流式生成,避免 OOM),也会占用不少 CPU 和内存。
能不能把这步也拆出去?(不到万不得已一般不拆,工作量反而增大,但是你得有这个意识)搞个专门的 “Excel 生成服务”,只负责从 MQ 接任务、从数仓查数据、生成文件。这样业务服务和生成服务解耦,各自扩容 —— 业务服务扛并发请求,生成服务扛 CPU 密集型的文件生成。
另外,生成格式也能做文章:如果业务对 Excel 格式要求不高(比如只是看数据,不用公式、图表),可以先生成 CSV 文件(生成速度比 Excel 快 10 倍不止),再转成 Excel;
或者直接让用户下载 CSV(前端也能打开);如果必须要 Excel,除了 POI,还可以试试 Alibaba 的 EasyExcel,它对内存的优化比原生 POI 更到位,还支持注解配置,少写不少破代码。
优化4:大文件传输卡?扔去 OSS
最后是大文件传输的问题。生成好的 Excel 文件,要是几十 MB 甚至上百 MB,让应用服务直接通过 HTTP 返给用户,还是会占用带宽。
这时候就得用对象存储(比如 OSS、S3)—— 刚才上面也提过,可以生成服务把 Excel 文件写完后,直接上传到 OSS,然后把 OSS 的下载链接(带签名、设过期时间,避免泄露)存到数据库里。
用户查结果时,后端直接返回这个链接,用户去 OSS 下载,应用服务彻底不用扛传输压力。也可以直接用消息助手通知用户通过链接下载,省时省力(不过小公司可能成本略高)
这里要注意签名的安全性,比如链接过期时间设 1 小时,避免用户把链接分享出去,泄露数据。
优化5:重复?加缓存呗
到这你是不是觉得差不多了?别急,还有个容易被忽略的点:缓存重复请求。
比如同一个用户,一天内重复导出 “近 7 天的订单”,数据没变化,没必要重复生成。这时候可以加个缓存,key 是 “用户 ID + 导出条件(时间范围、字段)”,value 是 OSS 链接,缓存过期时间设成数据更新的周期(比如订单数据实时更新,缓存设 1 小时)。
这样重复请求直接命中缓存,省了查库和生成的成本。但要注意缓存失效策略 —— 如果底层数据更新了(比如用户改了订单状态),得及时清掉对应的缓存,不然用户下载到的是旧数据。
总结
最后总结下,没有什么 “牛逼的方案” 能解决所有导出慢的问题,核心思路是 “拆解链路、分治优化”:把 “查数据 - 生成文件 - 传输文件” 拆成三个独立环节,每个环节用最适合的技术去扛(数仓扛查询、异步服务扛生成、对象存储扛传输)
同时用缓存减少重复劳动,通过打点监控(比如任务成功率、生成耗时)盯着链路中的坑。
任何脱离场景谈优化都是耍流氓 —— 如果业务方导出的数据永远不超过 1 万条,那搞异步和对象存储就是过度设计;
但如果是 To B 业务,用户动不动导出百万级数据,那上述的链路改造就是必须的。