MySQL 在 8.0.18 中引入 hash join,这是一个为 join 查询语句设计的高效算法。今天来介绍一下 hash join。
1.简介
首先我们建立两张表,SQL 如下:
复制
CREATE TABLE t1 (c1 INT, c2 INT);
CREATE TABLE t2 (c1 INT, c2 INT);1.2.
再给出一个连接查询 SQL:
复制
SELECT * FROM t1 JOIN t2 ON t1.c1=t2.c1;1.
那 hash join 的执行过程是怎样的呢?
确定驱动表(MySQL 会选择结果集较小的表作为驱动表),将结果集加载到内存中; 以连接键为 hash key 构建 hash 表,使用链表法解决 hash 冲突。 对于非驱动表,依次扫描每一行数据,对 join 字段取 hash 值,然后在 2 构建的 hash 表中查找这个 hash 值; 如果找到,则对这个 hash 值所在的链表上每个值进行等值比较,如果比较结果一致,则结合两个表的相关字段生成结果集并输出; 如果找不到,则继续扫描下一行。 整个过程如下图:
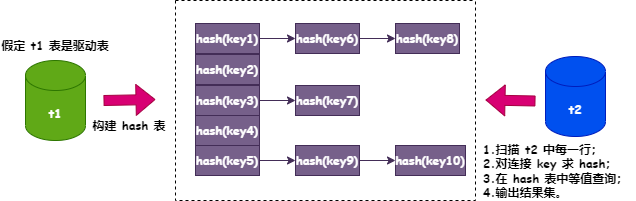 图片
图片
hash join 的时间复杂度是多少呢?假如 t1 表的记录数是 M,扫描 t1 表的时间复杂度是 o(M),t2 表的记录数是 N,扫描 t2 表的时间复杂度是 o(N),hash 表查询的复杂度是 o(1),这样使用 hash join 查找的总时间复杂度是 o(M + N)。
2.优势
在上面的例子中,t1 表和 t2 表都没有加索引,如果做 join 查询,在 MySQL 8.0 以前,会使用 BNL 算法。
 图片
图片
BNL 算法流程如下:
把 t1 表的数据读出放到 join_buffer; 扫描 t2 表中的每一行,用 c1 字段值跟 join_buffer 中 t1 表的 c1 字段值做比较; 如果 c1 值一样,则作为结果集返回,如果不一样,则继续扫描 t2 表下一行。
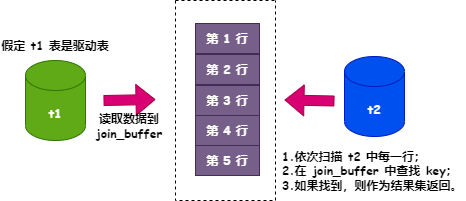 图片
图片
join_buffer 是一个无序数组,t2 表中的每一行都需要跟 t1 表的所有记录做比对。假如 t1 表的数据量是 M,t2 表的数据量是 N,则需要比对的次数是 M * N,也就是说时间复杂度是 o(M*N)。
从时间复杂度可以明显看出 hash join 的优势。
从 MySQL 8.0.20 开始,不再支持 BNL 算法,server 在原先使用 BNL 算法的地方使用 hash join。
3.hash join 优化
MySQL 8.0.18 引入 hash join,主要用于 join 语句中有等值条件并且 join 条件中不能使用索引的场景。比如前面例子中的 join 语句,t1 和 t2 的 c1 字段都没有索引:
复制
SELECT * FROM t1 JOIN t2 ON t1.c1=t2.c1;1.
3.1 配置
MySQL 8.0.18 版本中,支持设置 hash_join=on 或 hash_join=off 供优化器选择,在 MySQL 8.0.19 及更高版本中,这个设置不再生效,server 会默认使用 hash join。
3.2 连接条件优化
优化一:在 MySQL 8.0.20 以前,如果 join 条件中存在一个非等值匹配的条件,就会走 BNL 算法。MySQL 8.0.20 以后,即使有非等值条件,也会走 hash join。下面 SQL 来自官网:
复制
mysql> EXPLAIN FORMAT=TREE
-> SELECT * FROM t1
-> JOIN t2 ON (t1.c1 = t2.c1)
-> JOIN t3 ON (t2.c1 < t3.c1)\G
*************************** 1.row ***************************
EXPLAIN: -> Filter: (t1.c1 < t3.c1) (cost=1.05rows=1)
-> Innerhashjoin (no condition) (cost=1.05rows=1)
-> Tablescanon t3 (cost=0.35rows=1)
-> Hash
-> Innerhashjoin (t2.c1 = t1.c1) (cost=0.70rows=1)
-> Tablescanon t2 (cost=0.35rows=1)
-> Hash
-> Tablescanon t1 (cost=0.35rows=1)1.2.3.4.5.6.7.8.9.10.11.12.13.
优化二:即使 join 没有条件,也会走 hash join:
复制
mysql> EXPLAIN FORMAT=TREE
-> SELECT *
-> FROM t1
-> JOIN t2
-> WHERE t1.c2 > 50\G
*************************** 1.row ***************************
EXPLAIN: -> Innerhashjoin (cost=0.70rows=1)
-> Tablescanon t2 (cost=0.35rows=1)
-> Hash
-> Filter: (t1.c2 > 50) (cost=0.35rows=1)
-> Tablescanon t1 (cost=0.35rows=1)1.2.3.4.5.6.7.8.9.10.11.
优化三:即使 join 条件中没有等值条件,也会走 hash join。下面 5 个示例来自官网,都会走 hash join。
1.内连接无等值条件:
复制
mysql> EXPLAIN FORMAT=TREE SELECT * FROM t1 JOIN t2 ON t1.c1 < t2.c1\G
*************************** 1.row ***************************
EXPLAIN: -> Filter: (t1.c1 < t2.c1) (cost=4.70rows=12)
-> Innerhashjoin (no condition) (cost=4.70rows=12)
-> Tablescanon t2 (cost=0.08rows=6)
-> Hash
-> Tablescanon t1 (cost=0.85rows=6)1.2.3.4.5.6.7.
2.半连接:
复制
mysql> EXPLAIN FORMAT=TREE SELECT * FROM t1
-> WHERE t1.c1 IN (SELECT t2.c2 FROM t2)\G
*************************** 1.row ***************************
EXPLAIN: -> Hash semijoin (t2.c2 = t1.c1) (cost=0.70rows=1)
-> Tablescanon t1 (cost=0.35rows=1)
-> Hash
-> Tablescanon t2 (cost=0.35rows=1)1.2.3.4.5.6.7.
3.反连接:
复制
mysql> EXPLAIN FORMAT=TREE SELECT * FROM t2
-> WHERE NOT EXISTS (SELECT * FROM t1 WHERE t1.c1 = t2.c1)\G
*************************** 1.row ***************************
EXPLAIN: -> Hash antijoin (t1.c1 = t2.c1) (cost=0.70rows=1)
-> Tablescanon t2 (cost=0.35rows=1)
-> Hash
-> Tablescanon t1 (cost=0.35rows=1)
1rowinset, 1warning (0.00 sec)
mysql> SHOWWARNINGS\G
*************************** 1.row ***************************
Level: Note
Code: 1276
Message: Fieldorreferencet3.t2.c1ofSELECT#2 was resolved in SELECT #11.2.3.4.5.6.7.8.9.10.11.12.13.14.15.
4.左外连接:
复制
mysql> EXPLAIN FORMAT=TREE SELECT * FROM t1 LEFTJOIN t2 ON t1.c1 = t2.c1\G
*************************** 1.row ***************************
EXPLAIN: -> Lefthashjoin (t2.c1 = t1.c1) (cost=0.70rows=1)
-> Tablescanon t1 (cost=0.35rows=1)
-> Hash
-> Tablescanon t2 (cost=0.35rows=1)1.2.3.4.5.6.
5.右外连接:
复制
mysql> EXPLAIN FORMAT=TREE SELECT * FROM t1 RIGHTJOIN t2 ON t1.c1 = t2.c1\G
*************************** 1.row ***************************
EXPLAIN: -> Lefthashjoin (t1.c1 = t2.c1) (cost=0.70rows=1)
-> Tablescanon t2 (cost=0.35rows=1)
-> Hash
-> Tablescanon t1 (cost=0.35rows=1)1.2.3.4.5.6.
4.总结
hash join 算法的出现对 join 语句的性能大幅提升,MySQL 8.0.20 后,对 hash join 的使用又做了进一步的优化,使用更加便捷。