RisingWave x 特征工程:解锁实时特征新范式
本文将介绍 RisingWave 在实时特征工程中的应用。RisingWave 是一款开源的流式数据库,具有易用、健壮、上下游生态系统开放、性价比高等特点,支持 SQL 和 UDF 扩展,其架构包含接入层、计算层和存储引擎,支持多种数据源和下游系统,通过物化视图等实现增量实时计算。在实时特征工程中,它能够助力数据摄入、数据清洗、特征构建、样本拼接和特征查询等环节,提供高效的状态管理和 UDF 支持。此外,RisingWave 2.0 带来了如 Premium 版本、云版本增强、对流批统一的改进等新特性。通过阅读本文,读者可深入了解 RisingWave 在实时数据处理领域的优势与应用。
一、RisingWave 介绍
1. 项目背景与基本信息
RisingWave 是一款具有创新性的开源流处理系统,在实时数据处理领域展现出独特优势。其开源项目背景源于对革新流处理和数据库管理的追求,于 2021 年初创立,并在 2022 年 4 月以 Apache2.0 协议在 GitHub 开源。经过三年打磨,已在全球多领域落地应用。
RisingWave是基于Rust的自研项目,采用存算分离架构,交互接口与 PostgreSQL 协议兼容,并可通过 UDF 拓展。其包含接入层、计算层与存储层三层架构,由 meta 节点协调,计算节点执行流作业并带有多级缓存,状态持久化至基于对象存储的存储引擎。产品使命为解决易用性问题,降低实时应用开发、运维与运行成本,无论对实时计算新手还是资深从业者,都致力于提供便捷、稳定且高效的流处理方案。目前,应用领域涵盖互联网、金融、能源、供应链等多个行业,在实时监控告警、流表实时打宽、规则引擎、实时数据市场等场景均有应用。截至当前,全球日活集群已超 1700 个。
2. RisingWave 特点
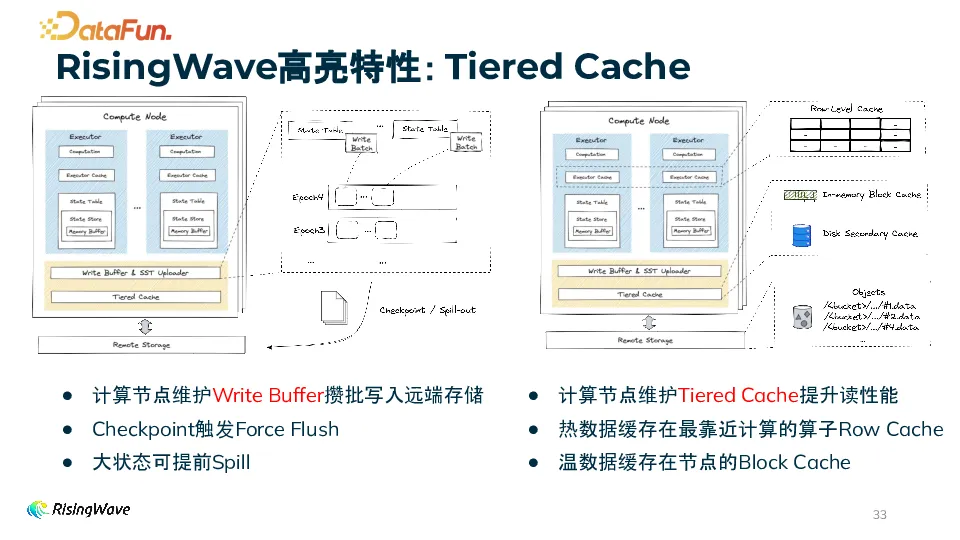
(1)易用性RisingWave 通过 SQL 作为交互接口,兼容 PostgreSQL 协议,用户通过简单的 SQL 即可实现复杂的实时需求,同时支持通过不同语言的 UDF 进行拓展。另外,RisingWave 不仅仅是流式计算引擎,而且带有自研的存储引擎,除了支持有状态的复杂流计算外,实时分析的结果可以以物化视图的方式通过 SQL 在 RisingWave 中查询,我们称其为 Serving。同时 RisingWave 流算子的内部状态都抽象成了关系型表,也可以通过 SQL 查询,大大提升了流计算的可观测性。

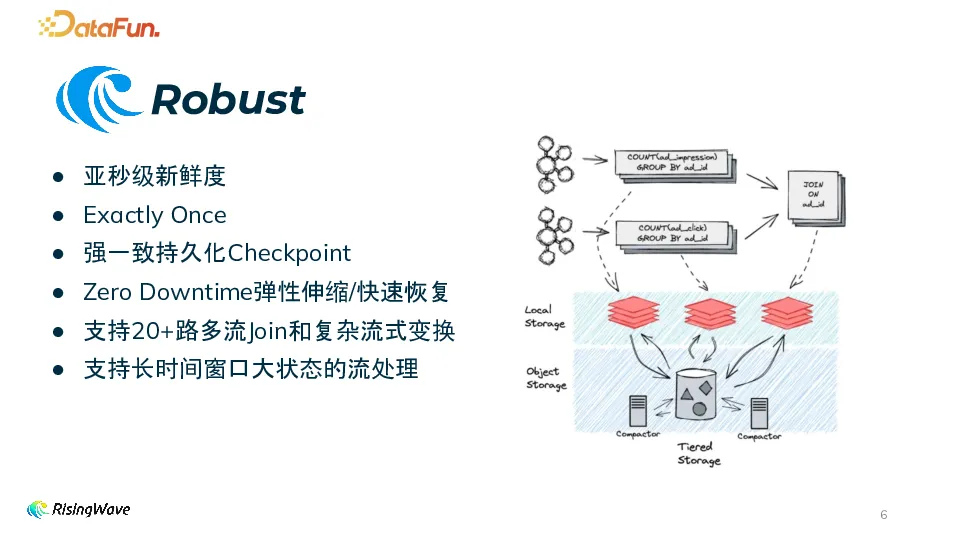
RisingWave 定位为数据库,所以健壮稳定是首要要求。实时性方面,可以达到亚秒级新鲜度,并实现了 Exactly Once。支持强一致持久化 checkpoint,当出现故障时可以立即从上一 checkpoint 恢复。基于存算分离的架构,可以实现 zero downtime 的弹性伸缩和快速恢复。同时,RisingWave 支持 20+ 路多流 join 和复杂流式变换,并且支持长时间窗口大状态的流处理。
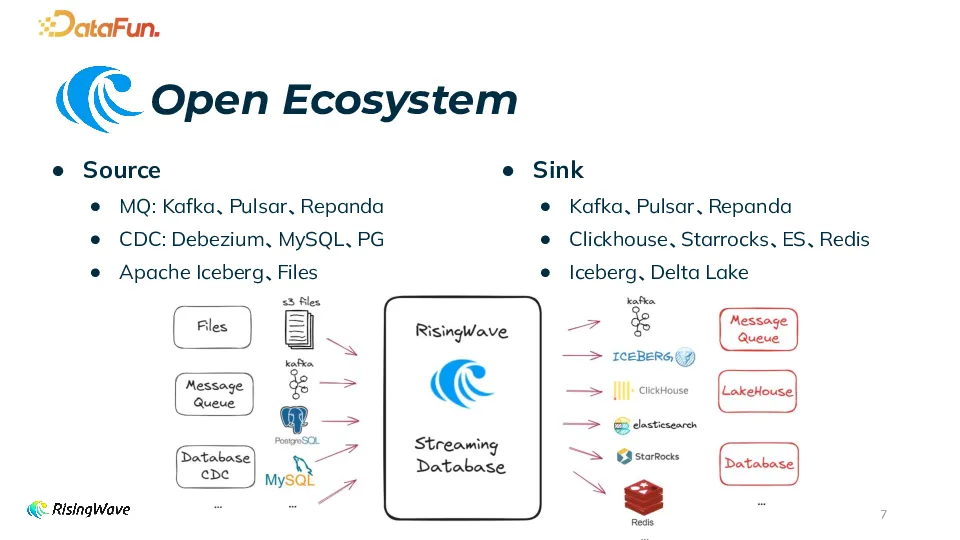
RisingWave 作为流处理系统,具备开放且多元的上下游生态系统。在上游 Source 方面,它支持多种常见的消息队列(如 Kafka 等)、各类数据库的变更数据捕获(CDC),涵盖 MySQL、PostgreSQL、Oracle 等关系型数据库以及 MongoDB 等非关系型数据库,并且支持如 Debezium 等多种 CDC 格式,同时也接纳如数据湖、文件系统内文件等批式数据源。而在下游 Sink,不仅支持消息队列,还支持 ClickHouse、StarRocks 等分析型数据库以及 Elasticsearch、Redis 等非关系型数据库,此外还实现了实时入湖功能。这种开放的生态系统,极大地拓展了 RisingWave 在不同数据场景下的应用范围,使其能更好地融入多样化的数据处理链路中。
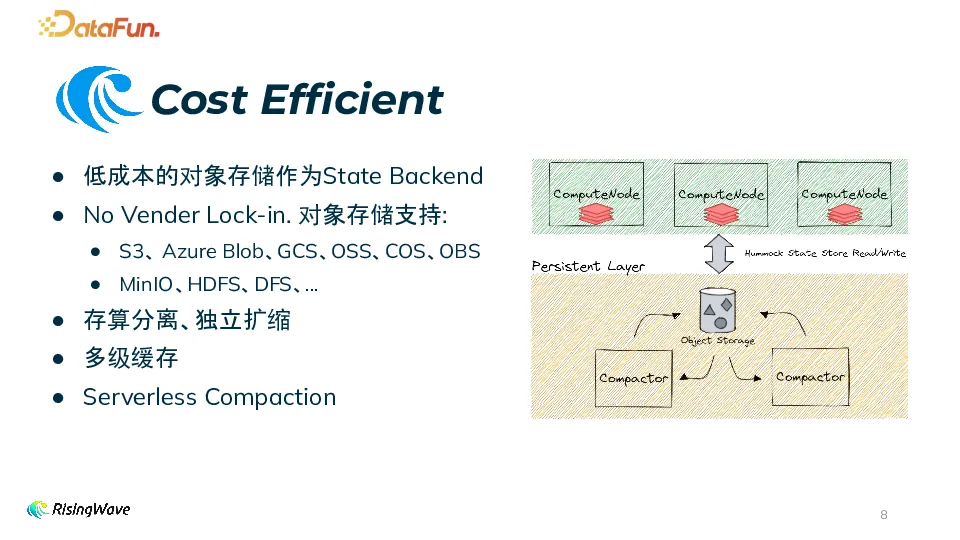
实时计算相比于离线计算通常成本更高,而 RisingWave 通过多种优化,实现了高性价比。首先,使用低成本的对象存储作为存储后端,我们自研了基于 LSM 的存储引擎降低存储成本。RisingWave 支持多种对象存储,比如 S3、Azure Blob 等,也可以自己部署 MinIO、HDFS、DFS。采用存算分离架构,计算和存储可以独立扩缩容。计算节点采用多级缓存,可以根据需求调整,并且支持 serverless compaction。
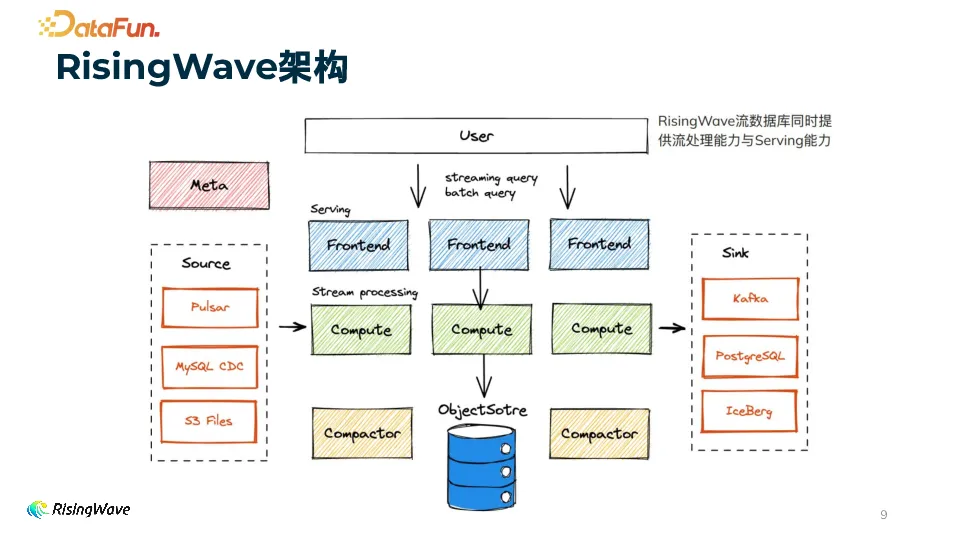
3. RisingWave 架构
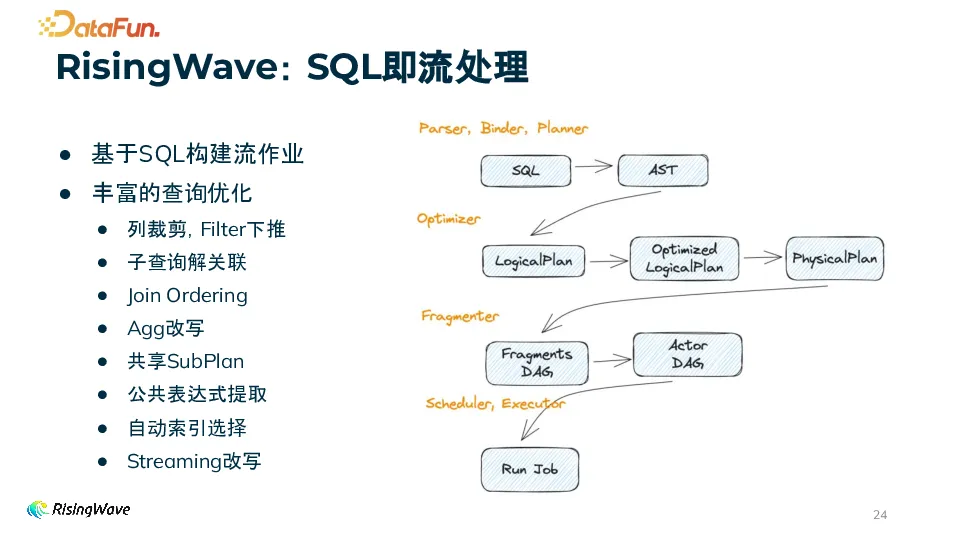
RisingWave 的架构主要分为三层。最上层是接入层(Frontend),它负责解析和优化用户请求,并生成执行计划,这些计划会被分布式调度到第二层 —— 计算层(Compute)执行。在流作业中,有状态的算子其状态会持久化到基于对象存储(ObjectStore)的存储引擎中。在这些组件之上,有一个 Meta 节点负责协调,起到控制器的作用。整体架构体现了 RisingWave 在流处理方面的高效设计,同时兼顾了存储和协调功能。
二、RisingWave 在实时特征工程中的应用
1. 特征工程步骤与链路
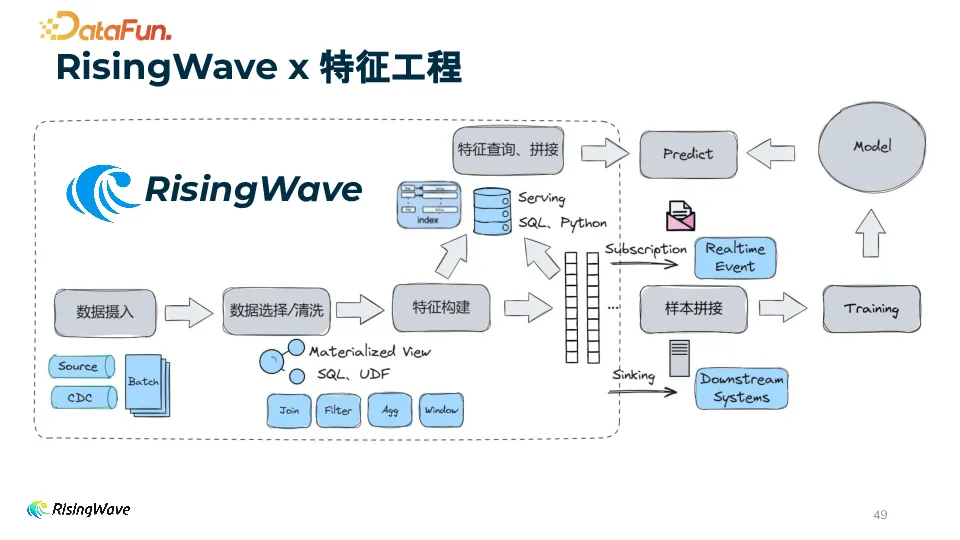
实时特征工程包含 Training 链路和 Inference 链路。Training 链路包括从上游数据源摄入数据、清洗选择、特征构建、样本拼接和实时模型训练。Inference 链路包括摄入数据构建行为特征、查询 Feature Store 特征拼接和向 Model 喂入特征完成 Inference。
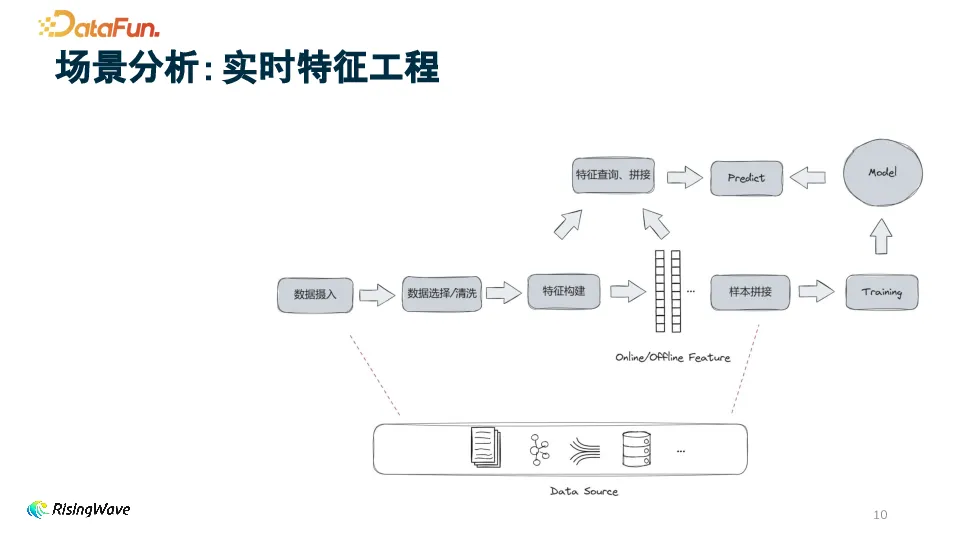
实时特征工程在架构上存在挑战。引入的组件越多,运维越困难,工程师需熟悉多个系统。同时,组件增多会使稳定性难以保障,一个组件故障就可能影响整体。此外,影响实时性的因素变多,且上线周期变长,工程师需学习不同接口与组件交互,数据分散也导致回测困难。
2. RisingWave 的助力
RisingWave 在实时特征工程方面有诸多助力。它能用 SQL + UDF 构建 Streaming Pipeline,提供统一的数据源存储,支持 Serving 查询,并具备实时流式 Sink 功能,能够有效简化和优化实时特征工程的流程,提升效率。
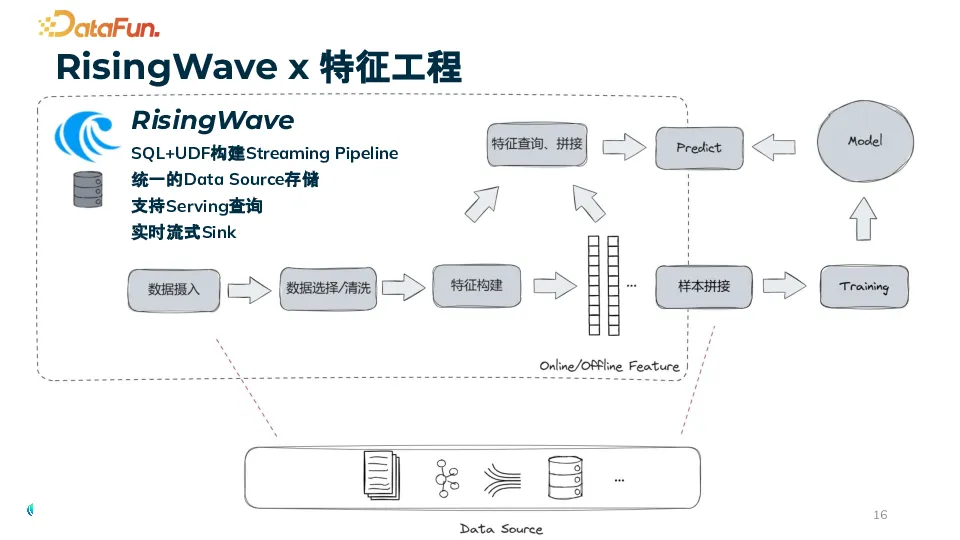
接下来具体看一下链路中的每个步骤。
(1)数据摄入在数据摄入环节,RisingWave 中可以使用 source connector 轻松接入多种数据源。
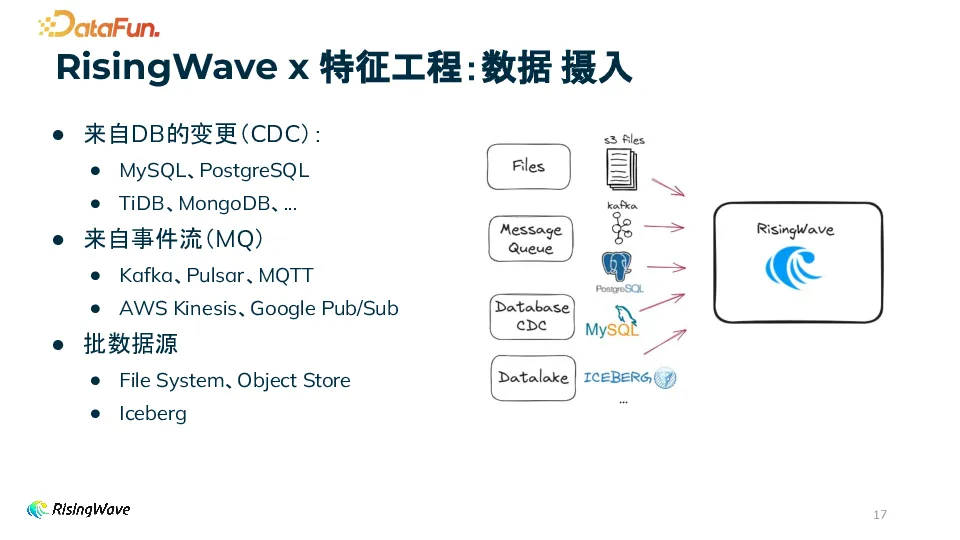


通过这些功能,RisingWave 在数据摄入环节能够灵活、高效地处理各种数据源的数据,并提供方便的数据管理和操作功能。
(2)数据选择和清洗在 RisingWave 中,丰富的 SQL 函数可以帮助用户轻松定义数据选择和清洗的逻辑,同时通过物化视图(Materialized View)构建特征工程的 Streaming Pipeline。
1)基于 SQL 进行数据选择和清洗离散化(Categorization)可以使用 SQL 语句将数据离散化到多个桶中。例如,根据一定的条件将数据划分到不同的类别。异常值处理(Filtering)通过 WHERE 条件来处理异常值。例如,筛选出符合特定范围的数据,排除异常数据。去重(Distinct On)使用 DISTINCT ON 语句可以对指定列的数据进行去重操作,只保留一条记录。缺失值处理(Coalescing)利用 SQL 函数(如 LAG)来填补缺失值,使缺失值变为上一个有效值。
物化视图是一个增量实时维护流处理结果的抽象。当上游数据到来时,物化视图会自动、实时、同步地增量维护流处理的结果。
支持 MV - on - MV 构建层级化的流处理管道,可以堆叠物化视图来构建多层级的流处理流程。物化视图支持丰富的 SQL 语法,包括 JOIN、窗口函数、子查询、分组等,还支持高级的流处理特性如 watermark,以及半结构化数据的处理函数。物化视图的结果是实时可查询的,用户可以通过 SQL 查询来获取物化视图的结果,方便进行数据验证和调试。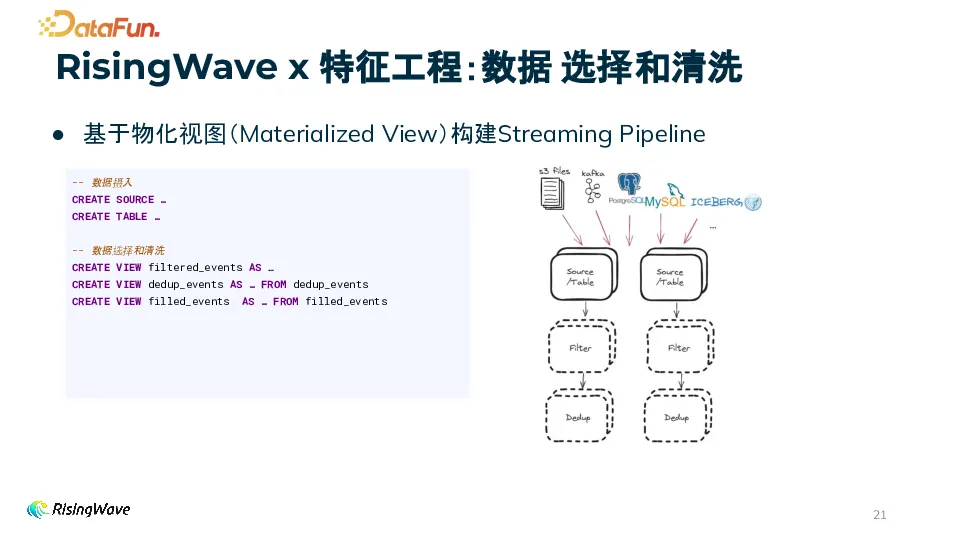

RisingWave 中的 SQL 即流处理具有诸多优势。它基于 SQL 构建流作业,具备丰富的查询优化功能,如列裁剪、Filter 下推等。还支持子查询解关联、Join 重排序等操作,能够将用户编写的 SQL 优化成高效的分布式流作业,方便用户操作。
特征构建是实时特征工程的关键环节,下面我们从一些常用特征出发,看一下如何通过 RisingWave 进行特征构建
1)聚合特征和 Over 窗口计算通过 CREATE MATERIALIZED VIEW 语句实现,例如计算用户最近 30 天行为聚合统计,从清洗后的数据表(如 cleaned_events)中筛选出特定时间范围内(NOW() - INTERVAL 30 DAYS到NOW())的数据,按用户 ID(user_id)和事件类型(event_type)进行分组,计算访问次数(COUNT())和最后访问时间(MAX(event_timestamp))。还可进一步计算如用户过去 30 天最常浏览的 Top2 商品类别,先按用户 ID 分区并按访问次数降序排序,然后选择排名前 2 的类别。



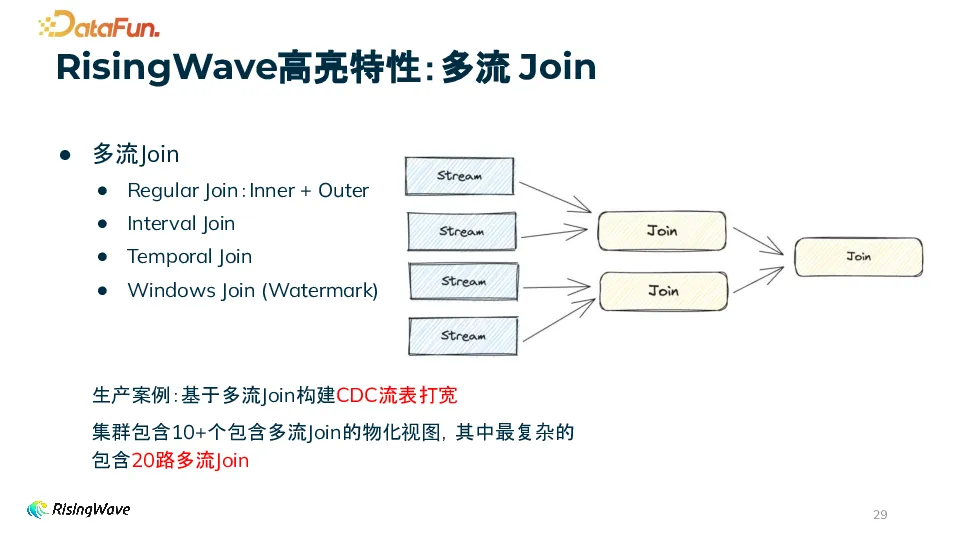
实时多流 Join 是 RisingWave 的一个高亮特性,除了上面介绍的 Regular Join 和 Interval Join,还支持 Temporal Join,以及基于 Watermark 的 Windows Join。多流 Join 是流处理中的一个难点,而 RisingWave 凭借其架构优势和丰富的优化,让用户在不感知调度和实现细节的情况下,可以轻松通过 SQL 构建包含多流 Join 的实时特征。
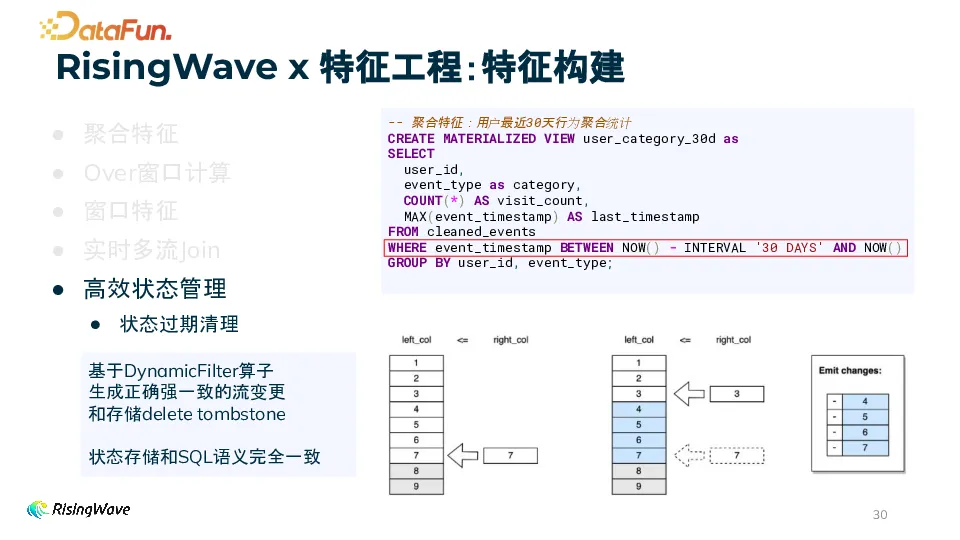

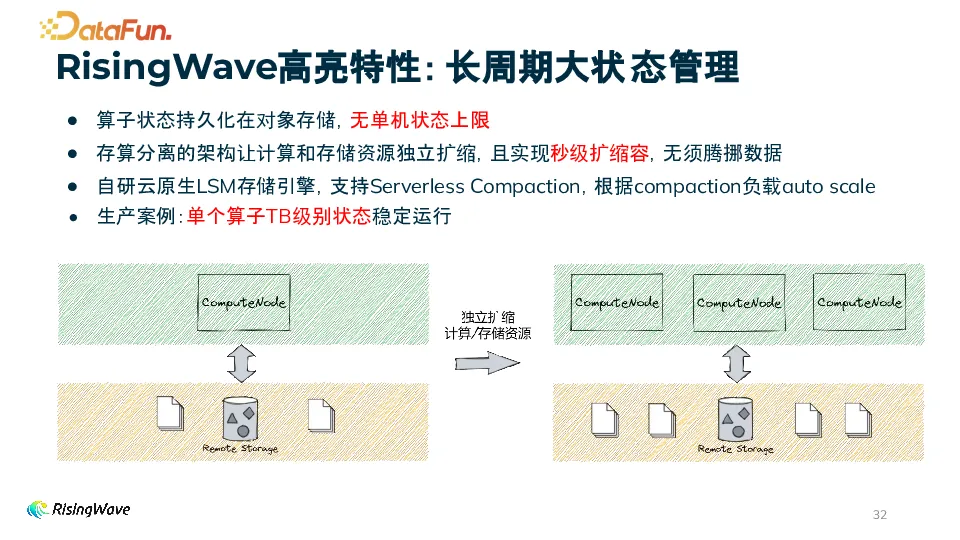
在 RisingWave 中做了大量工作去优化状态远端存储带来的延迟。通过多级缓存机制,用户可以根据实际场景在性能与成本间做出权衡。

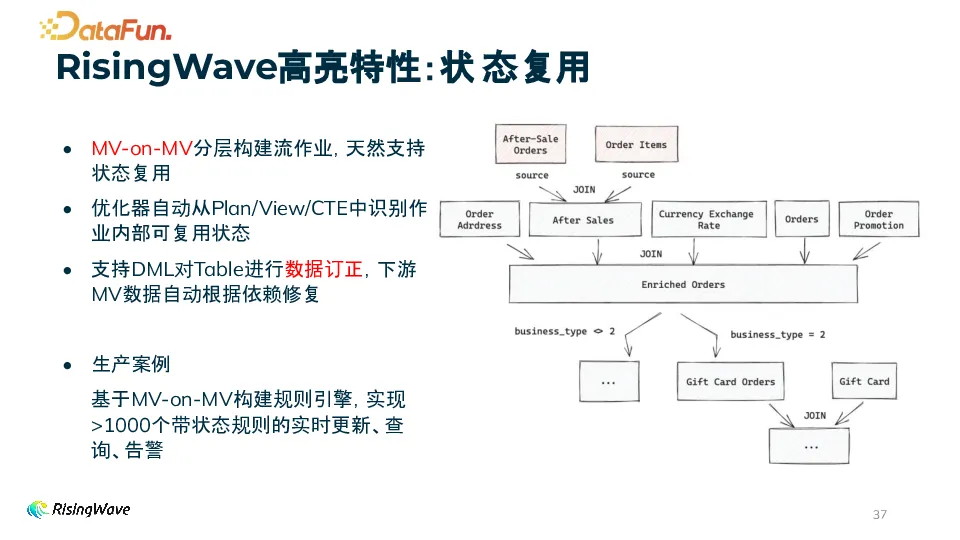
特征工程中,Source 数据清洗后的原始数据可以会物化成 MV,基于这些 MV 又可以创建不同的下游 MV,MV 之间还可以 join,这样分层构建流作业,天然支持状态复用。Source Table 支持 DML 进行数据订正,订正引起的变更会自动地同步到各个下游。
支持通过 CREATE FUNCTION 和 CREATE AGGREGATE 方式定义 UDF。


在 RisingWave中,Feature Serving 是实时特征工程的重要组成部分,提供了强大的功能用于特征查询、数据分发和服务优化。
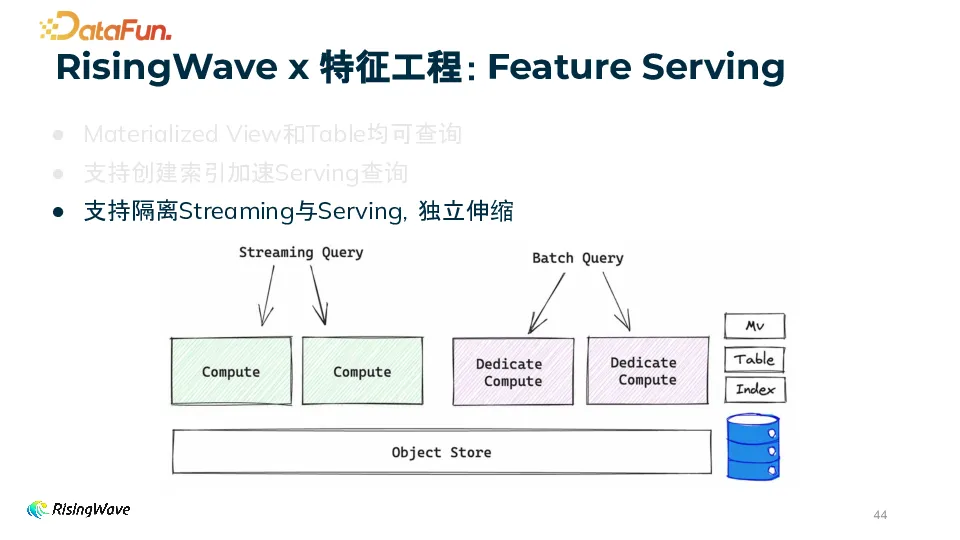
1)查询与结果一致性可查询性Materialized View 和 Table 均可查询,支持 Batch Query 和 Streaming Query。用户可以通过 SELECT 语句直接查询物化视图(如 user_feature)获取特征数据,例如查询特定用户 ID(user_id = 15213)的特征。这种查询方式方便快捷,能够满足不同场景下对特征数据的获取需求。结果一致性与调试回溯Streaming 和 Batch Query 结果一致,这一特性使得用户在开发和调试过程中更加便捷。用户在创建物化视图前可以先运行 Batch Query 来查看结果是否符合预期,进行数据验证和逻辑调试。如果发现问题,可以方便地回溯和排查,因为两种查询方式的结果具有一致性,保证了数据的可靠性和可追溯性。支持创建索引加速 Serving 查询
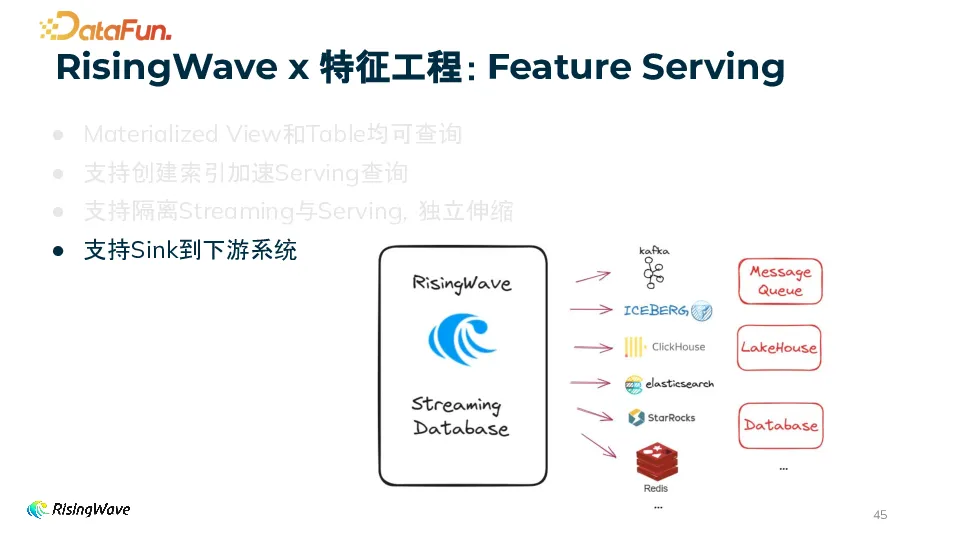
支持将数据变更 Sink 到下游系统。



让我们再来整体回顾一下 RisingWave 在特征工程各环节起到的助力作用。首先是数据摄入,利用 RisingWave 可以便捷地导入不同数据源;接下来是数据选择和清洗,基于 SQL 和 UDF,利用物化视图分层构建流处理 pipeline;特征构建完成后,可以用 SQL 或 Python 进行特征查询;最后,可以采用 push-based 也就是 sink 的方式将变更输出到下游,也可以采用 pull-based subscribe 的方式获取变更。
三、RisingWave 其他使用场景
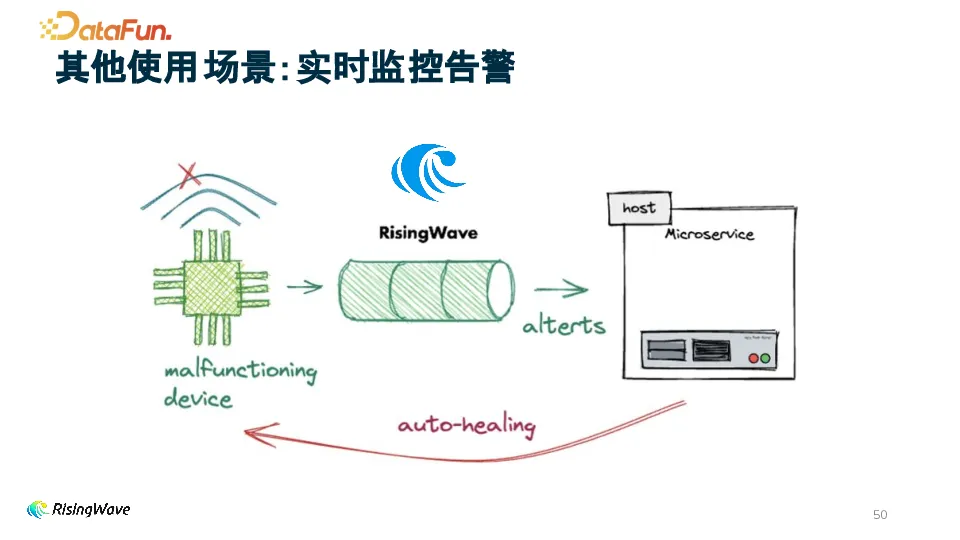
1. 实时监控告警
用户借助 RisingWave 实时处理数据,一旦监测到如设备故障等异常情况,便能迅速发出告警,实现自动修复或及时通知相关人员处理。
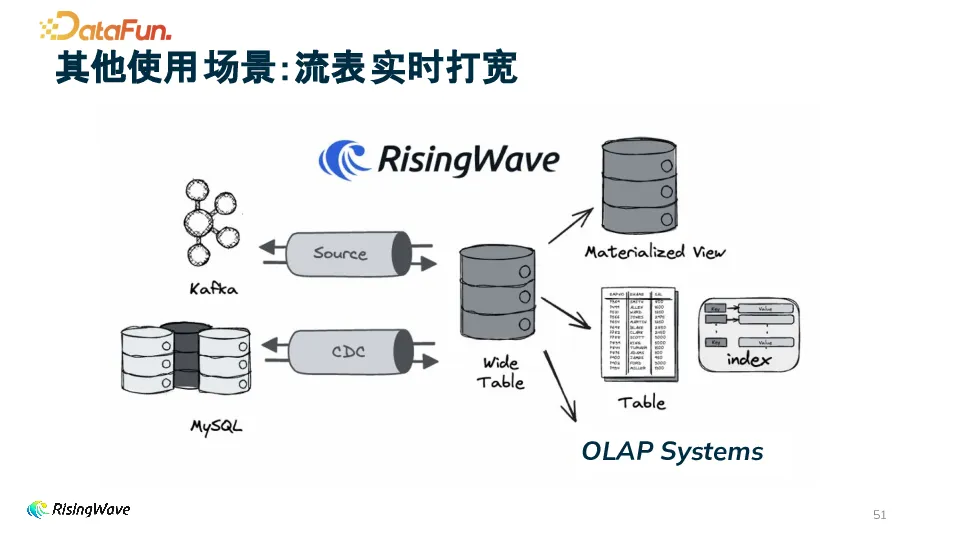
2. 流表实时打宽
当上游存在多个不同数据源的数据表时,RisingWave 可将这些表整合打宽成一张大宽表,以便在数据库中生成报表或进行深入分析,为决策提供全面的数据支持。
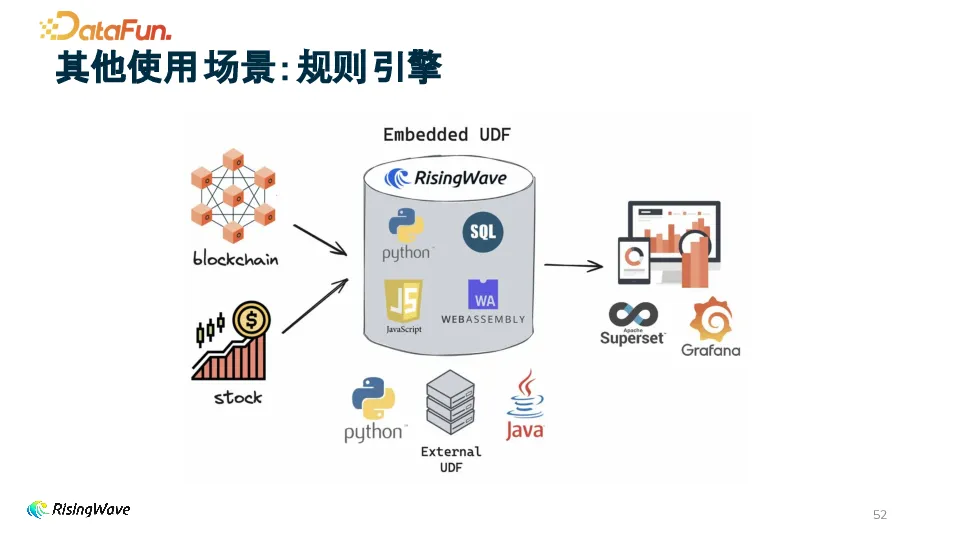
3. 规则引擎
用户通过 SQL 定义规则,利用其与 PostgreSQL 协议 的兼容性,结合如 Superset 等 BI 工具,可直观展示和分析数据,依据规则对数据进行处理和判断,如在金融交易中检测异常交易行为。
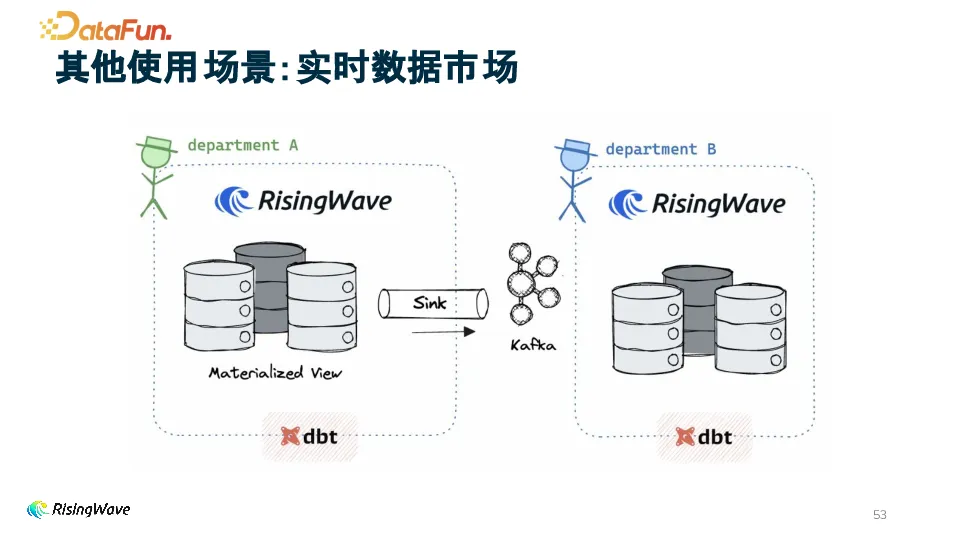
4. 实时数据市场
不同部门利用 RisingWave 构建物化视图,维护数据的可见性与权限。借助 dbt 工具,清晰管理数据血缘,保障数据质量与可追溯性,促进部门间高效的数据协作与共享。
四、RisingWave 2.0 更新内容
RisingWave 2.0 作为最新发布的版本,带来了诸多重要更新。
首先,新增 Premium 版本,专为自部署集群打造,提供企业级支持,有力保障自部署时的稳定性与性能表现。同时,RisingWave 的 Cloud 版本在应用性方面持续增强,尤其在 2.0 版本中,针对 Streaming 和 Batch 的统一支持进行了显著改进。例如,对 Batch Source、Batch Sink 以及 Batch Query 均进行了优化,提升了批量数据处理的效率与性能。
此外,该版本实现了自动的 Schema Change 和自动的 Schema Mapping 功能。这意味着当上游数据存在 Schema 时,用户导入数据无需手动编写 Schema,并且上游数据列的增减操作能够自动同步至 RisingWave 中,极大地简化了数据管理流程。同时针对创建 MV 时回填历史数据这一资源消耗大且一次性的操作提供了进一步地的优化,优化了数据处理的完整性和效率。
RisingWave 2.0 通过这些更新,致力于为用户提供更优质、高效、便捷的服务,期待用户深入了解并反馈使用体验,共同推动产品的持续优化。