斯坦福 CS144 计算机网络播客:计算机网络底层 – 从物理层到链路层
当我们享受着丝滑的网页浏览和高清的视频通话时,我们很少会去思考,那些构成我们数字生活的 0 和 1 是如何跨越数千公里,从服务器的网卡精准地传递到我们手机的 Wi-Fi 芯片中的。这一切的魔法,都始于网络协议栈的最底层——物理层和链路层。
在著名的互联网 “沙漏” 模型中,IP 协议是连接上下层的 “细腰”。而在 IP 之下,是一个多姿多彩的世界,承载着以太网 (Ethernet)、Wi-Fi、DSL 等各种技术。本文将带你一起,从最基础的物理信号出发,逐步揭开物理层与链路层的神秘面纱。
物理层:将比特流转化为模拟信号
物理层是网络通信的基石,它的核心任务是将上层传来的数字比特流,转换为能够在线缆、光纤或空气中传播的物理信号。这个过程看似简单,却充满了精妙的设计与权衡。
弹性缓冲区:时钟不同步的优雅解法你或许会认为,网络通信中发送方和接收方的时钟应该是完全同步的。但现实是,制造出两个频率完全一致的时钟晶振几乎是不可能的。它们之间总会存在微小的差异,比如百万分之几 (parts-per-million, ppm) 的容差。
这意味着,发送方发送比特的速率和接收方接收比特的速率总会有一点点不同。如果发送方略快,接收方的缓冲区最终会 溢出 (Overflow) ;反之,如果接收方略快,缓冲区则会 欠流 (Underflow) 。
为了解决这个问题,物理层引入了 弹性缓冲区 (Elastic Buffer) 。你可以把它想象成一个先进先出的队列 (FIFO),它巧妙地调和了收发两端的速率差异。
为了确保这个缓冲区既不溢出也不欠流,网络协议设计了两个关键机制:
最大传输单元 (Maximum Transmission Unit, MTU) : 它限制了单个数据包的最大长度。这确保了即使在最坏的情况下(发送方最快、接收方最慢),一个数据包也不会把整个缓冲区撑爆。帧间间隙 (Inter-packet gap, IPG) : 发送方在发送完一个数据包后,必须强制“休息”一小段时间。这段间隙给了接收方足够的时间来清空缓冲区,使其恢复到一个安全的中间状态,为下一个数据包的到来做准备。因此,时钟的精度越高(容差越小),所需要的弹性缓冲区和帧间间隙就越小。在一个理想化的世界里,如果时钟完全同步,这两者都可以为零。
香农极限与调制:信道容量的天花板一根网线到底能跑多快?这个问题的理论上限由信息论之父克劳德·香农给出了答案。 香农容量 (Shannon Capacity) 定理告诉我们,一个信道在无差错情况下的最大数据传输速率由以下公式决定:
其中:
C 是信道容量 (Capacity),单位是比特/秒 (bps)。B 是信道的带宽 (Bandwidth),单位是赫兹 (Hz)。S/N 是信噪比 (Signal-to-Noise Ratio),即信号功率与噪声功率的比值。这个公式揭示了一个核心真理: 要想提高数据传输速率,要么增加带宽,要么提高信噪比。
那么,我们如何利用信道来传输比特呢?答案是 调制 (Modulation) 。调制是将数字比特“翻译”成模拟信号的过程。常见的调制方式有:
幅度移位键控 (Amplitude Shift Keying, ASK) :通过改变信号的幅度(振幅)来表示 0 和 1。频率移位键控 (Frequency Shift Keying, FSK) :通过改变信号的频率来表示 0 和 1。相移键控 (Phase Shift Keying, PSK) :通过改变信号的相位来表示 0 和 1。为了在每个信号单元(称为 符号 (Symbol) )中承载更多的比特,现代通信系统通常会将幅度和相位结合起来,这就是 正交幅度调制 (Quadrature Amplitude Modulation, QAM) 。
我们可以用 IQ 星座图 (IQ Constellation) 来直观地表示这些调制方式。星座图上的每一个点都代表一个独特的符号,它由特定的幅度和相位定义。一个符号可以编码多个比特。例如,QPSK (正交相移键控) 有 4 个点,每个符号可以携带 2 个比特。
更复杂的 16-QAM 则有 16 个点,每个符号可以携带 4 个比特,从而大大提高了数据传输速率。但是,点与点之间也变得更加密集,对噪声的抵抗能力也随之下降。
物理层的基石:编码、复用与传输延迟在理解了香农定理为我们描绘的信道容量蓝图后,让我们深入探讨物理层中一些更为具体的技术细节,它们共同构成了数据通信的坚实基础。
奈氏准则与香农定理:理想与现实香农定理描述的是一个有噪声信道的极限速率。而在一个理想的、无噪声的信道中,数据传输速率的上限由 奈奎斯特定理 (Nyquist Theorem) 给出:
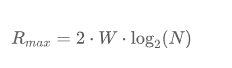
这里的关键区别在于:奈氏准则关注的是在无噪声环境下,带宽如何限制了 码元 的传输速率;而香农定理则关注在有噪声环境下,信噪比如何限制了 信息 (比特)的传输速率。奈氏准则告诉我们“最多能送多少个包裹”,香农定理则告诉我们“这些包裹里最多能装多少货”。
下面解释一下相关概念。
码元(symbol) 是物理层在每个“时间槽”里发送的最小调制单元 —— 可以看成一个“信号点”。一个码元可以表示 1 个比特,也可以表示多个比特,取决于调制方式的“点数”(星座点数)。比特(bit) 是信息单位; 码元率(symbol rate 或 Baud) 是每秒发送多少个码元; 比特率(bit rate) = 码元率 × 每个码元携带的比特数。
举例说明(一步步算)

“码元”是物理信号的一个点;码元携带多少比特取决于调制的星座大小()。奈奎斯特给出 在无噪声 情况下带宽对码元/比特率的上限;香农则在 有噪声 时压低这个上限(引入 SNR 的限制)。
所以:码元 = 信号“点”,比特 = 信息量,码元率×每码元的比特数 = 比特率。
剖析网络延迟:发送延迟与传播延迟一个数据包从源头到目的地所经历的时间,即延迟,主要由两部分构成:
发送延迟 (Transmission Delay) :将数据包的所有比特推向链路所需的时间。它等于 数据帧大小 / 数据速率。这就像是让一列火车完全驶出车站所需的时间。传播延迟 (Propagation Delay) :第一个比特从发送端到达接收端所需的时间。它等于 传输距离 / 信号传播速度。这就像是火车的车头从始发站开到终点站的时间。例如,在一个 100Mbps 的以太网链路上发送一个 1500 字节的数据包,线路长度为 100 米(信号速度按 2 \cdot 10^8 m/s 计):
发送延迟 = (1500 * 8) bits / (100 * 10^6) bps = 120 µs传播延迟 = 100 m / (2 * 10^8) m/s = 0.5 µs总延迟 ≈ 发送延迟 + 传播延迟 = 120.5 µs在这个例子中,发送延迟远大于传播延迟,这在高速局域网中非常典型。
多路复用:在一条路上跑多辆车为了提高信道利用率, 多路复用 (Multiplexing) 技术应运而生。它允许多路独立的信号共享同一条物理信道。
频分复用 (Frequency Division Multiplexing, FDM) :将信道的总带宽划分为多个不重叠的子频带,每个子频带承载一路信号。收音机电台就是最经典的例子。时分复用 (Time Division Multiplexing, TDM) :将时间划分为一个个循环的帧,每帧内再划分为多个时间片,每个时间片分配给一路信号。T1/E1 数字中继线就是 TDM 的典型应用。波分复用 (Wavelength Division Multiplexing, WDM) :在光纤通信中使用,本质上是光的频分复用。它利用不同波长(颜色)的光来承载不同的信号,极大地提升了光纤的传输容量。链路层:在共享信道上可靠传输
链路层位于物理层之上,它利用物理层提供的服务,为网络层提供在一个“单跳”链路上主机到主机的数据传输服务。
比特之战:错误与纠错码由于物理世界中噪声无处不在,接收方在解码信号时总有可能出错,导致比特错误 (Bit Errors)。信噪比越低,或者星座图越密集,比特错误率 (Bit Error Rate, BER) 就越高。
如果因为一两个比特的错误就重传整个数据包,效率会非常低下。为此,工程师们发明了 前向纠错 (Forward Error Correction, FEC) 技术。其核心思想是在原始数据中主动添加一些冗余信息。这样,即使在传输过程中出现了一些错误,接收方也能利用这些冗余信息“猜”出并修正错误,从而避免了代价高昂的重传。
一种经典且强大的 FEC 算法是 里德-所罗门码 (Reed-Solomon, RS codes) 。它的原理可以通俗地理解为:
将 K 块原始数据看作一个 K-1 次多项式的系数。在这个多项式上取 N 个不同的点(N > K),并将这 N 个点的坐标值作为编码后的数据发送出去。由于 K 个点就能唯一确定一个 K-1 次多项式,接收方只要正确收到了任意 K 个点,就能反解出原始的多项式,进而恢复全部 K 块原始数据。这意味着,一个 RS(N, K) 编码可以容忍多达 N-K 个数据块的丢失(擦除错误)。这种强大的纠错能力使得 FEC 在 Wi-Fi、蜂窝网络、甚至光盘存储中都得到了广泛应用。
我们在前文提到了前向纠错码 (FEC) 的强大之处。然而,在许多场景下,我们并不需要纠错,仅仅检测出错误并请求重传(这由更高层协议如 TCP 负责)就足够了,这样可以节省大量的计算开销和冗余比特。
循环冗余校验 (CRC):高效的检错利器循环冗余校验 (Cyclic Redundancy Check, CRC) 是链路层(尤其在以太网和 Wi-Fi 中)最广泛使用的检错技术。它基于多项式除法的原理。
其工作流程如下:
发送方和接收方预先约定一个 生成多项式G(x)(例如 x^4 + x + 1 对应二进制 10011)。发送方要发送 k 位的原始数据。它首先在数据后面附加 r 个 0(r 是生成多项式最高次幂)。然后,用这个附加了 0 的长数据串,对生成多项式对应的二进制数进行“模 2 除法”(即异或运算)。得到的 r 位余数,就是 CRC 校验码。发送方将其替换掉数据末尾的 r 个 0,然后将整个数据帧(原始数据 + CRC校验码)发送出去。接收方收到数据帧后,用整个数据帧对同一个生成多项式进行模 2 除法。如果余数为零,则认为数据传输没有错误;否则,就认为数据已损坏。CRC 检错能力非常强,可以有效地检测出绝大多数的单比特、多比特及突发错误。
海明码:精巧的纠错码与只能检错的 CRC 不同, 海明码 (Hamming Code) 是一种相对简单但非常精巧的纠错码,它能够纠正单比特错误。
海明码的核心思想是在 m 位的数据中插入 k 个校验位,形成一个 m+k 位的新码字。这些校验位被放置在 2^n(1, 2, 4, 8, ...)的位置上。每一个校验位的值,都由数据中特定位置上的比特进行异或运算得到。
当接收方收到码字后,会重新计算这些校验位。如果计算结果与收到的校验位不符,这些不符的校验位的 位置之和 ,就恰好能指出发生错误的比特所在的位置!例如,如果第 1 位和第 4 位的校验出错了,那么就是第 1+4=5 位的数据发生了翻转。接收方只需将该位取反,即可完成纠错。
时钟恢复:在数据流中寻找节拍我们之前讨论了用弹性缓冲区来处理时钟的微小频率差异。但还有一个更基本的问题:接收方如何知道应该在何时对信号进行采样来读取比特呢?这就是 时钟恢复 (Clock Recovery) 要解决的问题。
在现代同步通信(如以太网)中,时钟信息被巧妙地编码在数据信号本身之中。接收端的 时钟恢复单元 (Clock Recovery Unit, CRU) 会持续观察接收到的信号,并通过信号的 **跳变 (Transition)**(例如从高电平变为低电平)来锁定发送方的时钟节拍。
为了确保信号中有足够多的跳变,链路层会采用特定的 线路编码 (Line Coding) 方案。例如:
曼彻斯特编码 (Manchester Encoding) :在早期的 10Mbps 以太网中使用。它将 1 编码为“高-低”跳变,0 编码为“低-高”跳变。这种方式保证了每个比特中间都有一次跳变,便于时钟恢复,但代价是占用的带宽翻了一倍。4B/5B 编码 :将 4 比特的数据块映射为一个 5 比特的码字。这些 5 比特的码字经过精心挑选,保证了不会出现连续过多的 0 或 1,从而确保了信号中有足够的跳变。它的效率(25% 开销)比曼彻斯特编码高得多。媒体访问控制:谁有权发言?
在许多网络中,多个设备共享同一个通信介质(如同轴电缆、空气)。 媒体访问控制 (Medium Access Control, MAC) 协议就是为了解决“谁可以在何时发送数据”这个问题的规则集合,其目标是避免或解决数据冲突。
有线江湖的规矩:以太网与 CSMA/CD在早期的以太网中,所有计算机都连接在一根共享的总线上。为了协调通信,以太网采用了 载波侦听多路访问/冲突检测 (Carrier Sense Multiple Access with Collision Detection, CSMA/CD) 协议。
它的工作流程就像一个文明的圆桌会议:
载波侦听 (Carrier Sense) :发言前先听。设备在发送数据前,会先侦听信道是否空闲。多路访问 (Multiple Access) :如果信道空闲,就开始发送数据。冲突检测 (Collision Detection) :边说边听。设备在发送数据的同时,会持续监听信道。如果它听到的信号和自己发送的信号不一致,就意味着发生了冲突(两个设备同时“发言”)。退避与重试 (Backoff and Retry) :一旦检测到冲突,立即停止发送,并广播一个拥塞信号。然后,等待一个随机的时间(这个随机时间的上限会随着冲突次数的增加而指数级增长,即 二进制指数退避 (Binary Exponential Backoff) ),再从第一步重新开始。值得注意的是,随着技术的发展,现代以太网几乎完全由 交换机 (Switch) 构建。交换机为每个端口提供了独立的冲突域,并支持 全双工 (Full-duplex) 通信(同时发送和接收),这使得冲突不再发生,CSMA/CD 协议也因此在现代有线网络中“名存实亡”。
现代交换机如何做到全双工交换机把多个设备从一个共享总线变成了许多独立的、点对点的链路;点对点链路上可以实现同时收发(全双工),因此也就没有“两个端点同时在同一共享介质上互相干扰”的冲突问题了 —— CSMA/CD 的场景被物理结构消除了。
具体机制(几条关键点)如下。
独立的点对点链路早期总线式以太网(同轴)是“共享媒介”,所以两个主机同时发就会冲突。交换机为每个端口做转发,主机到交换机是单独的链路(一对一),交换机在两端分别维护单独的发送/接收通道,因此 A→Switch 和 B→Switch 互不干扰。物理上分离的收发路径在很多介质上,发送和接收使用不同的线对或不同的光纤:例如光纤通常一根纤维发、一根收;千兆/万兆光模块也有分别的 Tx/Rx。这样物理上就能同时发送和接收。在双绞线(例如 100BASE-TX)中,常用独立的线对完成 TX 和 RX,从而同时双向传输。在同一对线上也能全双工 —— 回声消除 + DSP像 1000BASE-T(千兆以太网)使用的是四对线,每对同时承载 Tx 和 Rx 的信号。要实现同时收发,需要把自己发出的信号从接收到的混合信号中“减去”(即 回声消除 / echo cancellation ),再做数字信号处理分离对端信号。现代 PHY 芯片用混合变压器(hybrid)+ DSP 完成这件事,使同一对线上也能无冲突地双向传输。交换机的转发与缓冲交换机在帧到达时做学习(MAC 表),并把帧转发到目标端口。它通常有高速缓存(buffer),能处理短时突发,避免丢帧。因为链路是点对点,帧不会在链路上被第三台主机“碰撞”而混乱。链路协商(autonegotiation)以太网链路双方通过自动协商确定是否使用全双工模式。如果双方都支持全双工并协商成功,就关闭 CSMA/CD 的逻辑,启用全双工通信模式。为什么 CSMA/CD 在交换网络“名存实亡”
CSMA/CD 的设计是为了 共享媒介上冲突检测 ,但在点对点全双工链路上——没有第三方会在同一物理信道上与某一端并发发送,因此不会产生可检测的冲突。既然冲突不会发生,冲突检测/退避机制没有意义,自然也就停止使用(为兼容,标准仍保留历史定义,但在全双工下不启用它)。虽然大多数现代网络是交换机 + 全双工,但以太网标准沿用了最小帧长等历史约束(主要是向后兼容老设备、规范一致)。在全双工成熟的网中,最小帧长与 CSMA/CD 的实际需求已不重要,但标准字段仍然存在。深入以太网:帧结构、最小帧长与物理规范我们已经了解了 CSMA/CD 的工作原理,现在让我们深入以太网的技术细节,看看它的数据帧是如何构成的,以及它为何对帧的长度有特殊要求。
以太网帧结构一个标准的以太网 II 型帧(目前最常用的类型)由以下几个部分组成:
在物理层发送时,帧的前面还会加上 8 字节的 前同步码 (Preamble) 和 帧起始定界符 (Start Frame Delimiter, SFD) ,用于时钟同步和标识帧的开始。这些不计入帧长。
目的/源 MAC 地址 :全球唯一的 48 位物理地址。类型 :指明上层协议是什么,例如 0x0800 代表 IPv4。数据 :承载来自网络层的数据包。如果数据不足 46 字节,链路层会自动填充 (Padding) 到 46 字节。CRC 校验 :4 字节的循环冗余校验码,用于检测帧在传输中是否出错。最小帧长之谜为何以太网帧的数据字段最短必须是 46 字节,使得整个帧长(不含前同步码)至少为 64 字节?这与 CSMA/CD 的冲突检测机制密切相关。
在一个共享介质网络中,最坏的情况是:A 刚发完一个帧的最后一个比特,这个帧的第一个比特才刚刚到达网络最远端的 B,而 B 恰好在此时也开始发送,引发冲突。冲突信号需要再从 B 传回 A。A 必须在它发送完整个帧之前检测到这个冲突,否则它会误以为发送成功。
因此,必须满足以下不等式:
帧的发送时间信号在网络中往返一次的时间
即:
L_min 是最小帧长 (bits)。R 是数据速率 (bps)。d 是网络的最大跨度 (m)。v 是信号传播速度 (m/s)。在最初的 10Mbps 以太网标准中,规定了最大跨度为 2500 米,由此计算出最小帧长为 512 比特,即 64 字节。这个标准被后续的快速以太网和千兆以太网所继承,即使在交换式网络中 CSMA/CD 已不再必要。
以太网物理层规范的演进以太网的命名规范通常为 速率 + 信号方式 + 介质/距离。
快速以太网 (100Mbps) :最常见的 100BASE-TX 标准,使用两对 5 类非屏蔽双绞线 (UTP),传输距离 100 米。千兆以太网 (1Gbps) :1000BASE-T 标准统治了桌面市场,它巧妙地利用了全部四对 5 类 UTP,在 100 米内实现了全双工千兆传输。此外,还有用于光纤的 1000BASE-SX(多模光纤,短距离)和 1000BASE-LX(单模/多模光纤,长距离)。万兆以太网 (10Gbps) 及更高 :10GBASE-T 可以在 6A 类双绞线上实现万兆传输。而在数据中心和骨干网中,光纤是绝对的主角,如 10GBASE-SR/LR/ER 等标准,分别对应不同类型光纤和传输距离(从几百米到数十公里)。无线世界的挑战:CSMA/CA 与隐藏终端无线网络的情况要复杂得多。由于信号在空气中传播会衰减,发送方无法像在有线网络中那样,有效地“听”到接收方那里的情况。因此,冲突检测变得不可行。
Wi-Fi (IEEE 802.11) 采用了另一种策略: 载波侦听多路访问/冲突避免 (Carrier Sense Multiple Access with Collision Avoidance, CSMA/CA) 。它的核心思想是“尽量避免冲突,如果失败则确认”。
载波侦听 :发送前同样先侦听信道。冲突避免 :即使信道空闲,也要再等待一个随机的退避时间后才发送。这是因为可能还有其他设备也正准备发送。链路层确认 (Link Layer ACK) :由于无法检测冲突,发送方依赖于接收方返回的一个简短的确认帧 (ACK) 来判断数据是否成功送达。如果没在规定时间内收到 ACK,就认为数据丢失(可能因为冲突或噪声),然后进行指数退避和重传。然而,CSMA/CA 也面临着无线环境特有的难题:
隐藏终端问题 (Hidden Terminal Problem) :终端 A 和 C 都能与接入点 B 通信,但 A 和 C 之间互相听不到。如果 A 和 C 同时向 B 发送数据,就会在 B 处发生冲突,而 A 和 C 自身却毫不知情。为了缓解隐藏终端问题,Wi-Fi 引入了可选的 请求发送/清除发送 (Request-to-Send/Clear-to-Send, RTS/CTS) 机制。发送方可以先发送一个短小的 RTS 帧,接收方回复一个 CTS 帧。所有听到 CTS 帧的设备(包括隐藏终端)都会在指定时间内保持静默,从而为后续的数据传输“清场”。但这套机制本身也带来了额外的开销。
跨越边界:IP 分片
不同的链路层技术可能有不同的 MTU。例如,以太网的 MTU 通常是 1500 字节。当一个大的 IP 数据报需要从一个 MTU 较大的链路(如 MTU=9000)转发到一个 MTU 较小的链路(如 MTU=1500)时,路由器就需要对这个数据报进行 分片 (Fragmentation) 。
IP 头部中有专门的字段来处理分片与重组:
Identification: 一个唯一标识,所有属于同一个原始数据报的分片都拥有相同的 Identification 值。Flags: 其中的 More Fragments (MF) 位,除了最后一个分片,其他分片的 MF 位都为 1。Fragment Offset: 指示当前分片的数据在原始数据报中的位置(以 8 字节为单位)。一个关键的设计是: 分片的重组只在最终的目的地主机进行 。中间的路由器不负责重组,它们只管转发。
然而,IP 分片是一个应该极力避免的操作。因为它非常“脆弱”——任何一个分片的丢失都会导致整个原始数据包的丢失,而上层协议(如 TCP)必须重传整个大数据包,这极大地影响了性能。
现代网络通常使用 路径 MTU 发现 (Path MTU Discovery, PMTUD) 技术来避免分片。TCP 连接在建立时,会发送一个设置了 Dont Fragment (DF) 位的探测包,通过沿途路由器返回的错误信息来发现整条路径上最小的 MTU,然后据此调整自己的数据包大小。
IP 分片实例解析为了更清晰地理解 IP 分片,我们来看一个具体的计算例子。
场景 :一台主机要发送一个总长度为 3820 字节的 IP 数据报(头部 20 字节,数据 3800 字节)。数据报需要经过一个 MTU 为 1500 字节的链路。
分片过程
确定每个分片能承载的最大数据量 :MTU 是 1500 字节,IP 头部占用 20 字节,所以每个分片最多能携带 1500 - 20 = 1480 字节的数据。为了让 Fragment Offset 的计算方便,数据长度通常会调整为 8 的倍数。1480 恰好是 8 的倍数 (1480 / 8 = 185)。分片一数据:承载原始数据的前 1480 字节。总长度:1480 (数据) + 20 (头部) = 1500 字节。MF (More Fragments) 标志:设为 1 (后面还有分片)。Fragment Offset:0 / 8 = 0 (这是第一个分片)。分片二数据 :承载原始数据的第 1481 到 2960 字节 (共 1480 字节)。总长度 :1480 (数据) + 20 (头部) = 1500 字节。MF 标志 :设为 1 (后面还有分片)。Fragment Offset :1480 / 8 = 185 (偏移量是前一个分片的数据长度除以 8)。分片三数据 :承载剩余的数据。原始数据共 3800 字节,已发送 1480 + 1480 = 2960 字节,还剩 3800 - 2960 = 840 字节。总长度 :840 (数据) + 20 (头部) = 860 字节。MF 标志 :设为 0 (这是最后一个分片)。Fragment Offset :2960 / 8 = 370。最终,这个 3820 字节的 IP 数据报被分成了三个独立的小 IP 包在网络中传输,直到最终的目的地主机才会将它们重新组装起来。
结语:坚实的基石
从处理微秒级时钟差异的弹性缓冲区,到香农定律指导下的调制编码;从避免数据冲突的 MAC 协议,到跨越不同链路的 IP 分片,物理层和链路层共同构建了网络通信的坚实基石。它们将物理世界中充满噪声和不确定性的信号,抽象成了上层协议可以信赖的、看似可靠的点对点链路。
正是这些底层的精妙设计,才支撑起了我们今天这个庞大而复杂的互联网世界。希望这篇博文能帮助你更好地理解这一切背后的智慧与魅力。