在 Linux 系统的复杂生态中,内存管理堪称是维持系统高效稳定运行的核心枢纽。想象一下,Linux 系统就像是一座繁忙的超级大都市,内存则是城市里的土地资源,每一个运行的程序、进程都如同在这片土地上建造的建筑,它们都需要占用一定的内存空间来存储数据和执行指令 。如果没有一个科学合理的内存管理机制,这座 “城市” 将会陷入混乱,出现内存资源分配不均、内存泄漏等问题,进而导致程序运行缓慢、系统响应迟钝,甚至引发系统崩溃。
比如,当你在 Linux 系统上同时运行多个大型程序时,若内存管理不佳,可能会使某些程序因得不到足够的内存而无法正常运行,或者因为内存的不合理分配,导致部分内存空间被浪费,造成资源的低效利用。所以,深入了解 Linux 内存的常见分配方式,对于系统管理员、开发者以及追求系统高性能的用户来说,就如同掌握了城市规划的秘籍,能够更好地调配内存资源,让 Linux 系统这座 “城市” 有序且高效地运转,极大地激发读者探索 Linux 内存分配方式的兴趣,为后续深入讲解内容做好铺垫。
一、内存分配三剑客
在 Linux 系统中,malloc、kmalloc、vmalloc 属于不同层次的内存分配函数,它们看似相似,却各怀绝技:一个服务用户态,一个专注内核连续物理页,另一个则驾驭虚拟映射的离散空间。理解它们的差异与妙用,正是优化性能、规避陷阱的关键一步。
1.1 malloc用户空间内存分配
malloc 函数是 C 标准库中用于动态内存分配的函数,其底层由 C 库实现。C 库维护着一个缓存,当该缓存中的内存足够满足分配需求时,malloc 会直接从 C 库缓存中分配内存。而当 C 库缓存中的内存不足时,malloc 则需借助系统调用与操作系统交互来获取更多内存。
在 Linux 系统中,这主要涉及 brk 和 mmap 这两个系统调用。当申请的内存小于 128KB 时,malloc 通常会通过系统调用 brk 向内核申请内存,具体来说是从堆空间申请一个虚拟内存区域(VMA)。brk 系统调用通过移动程序数据段的结束地址(即 “堆顶” 指针)来增加堆的大小,从而分配新的内存。当申请的内存大于等于 128KB 时,malloc 一般会使用 mmap 系统调用。mmap 系统调用是在进程的虚拟地址空间中(堆和栈中间,称为文件映射区域的地方)找一块空闲的虚拟内存来满足内存分配请求。
malloc实现步骤:
请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。空闲链表搜索:接下来,malloc 会在一个空闲内存块链表中搜索一个足够大的空闲块。这个链表通常由多个空闲块组成,每个块都记录了大小和指向下一个块的指针。分裂或合并空闲块:如果找到的空闲块大小大于请求的大小,malloc 可能会将这个块分裂成两部分:一部分用于满足当前请求,另一部分保留在链表中以供未来使用。如果空闲块正好等于请求的大小,则直接使用该块。更新元数据:在使用选定的空闲块之前,malloc 需要更新其元数据(如大小和下一个块的指针),以反映内存已经被分配的事实。这可能涉及到修改当前块的大小字段或设置一个特殊的标记来表示该块已被占用。返回指针:malloc 返回指向已分配内存的指针给用户。
复制
typedef struct node {
size_t size; // 块大小
struct node* next; // 下一个节点指针
struct node* prev; // 上一个节点指针(可选)
} Node;
Node* free_list = NULL; // 空闲链表头指针
void* malloc(size_t size) {
// 步骤1: 调整大小(例如添加元数据大小)
size += sizeof(Node); // 为元数据留出空间
// 步骤2: 搜索空闲链表
Node* block = find_suitable_block(free_list, size);
if (!block) {
// 步骤3: 分裂或合并(如果需要)
// 步骤4: 更新元数据和链表结构
block = allocate_new_block(size); // 可能需要扩展堆或分裂现有块
} else {
remove_from_list(block); // 从空闲链表中移除
}
// 步骤5: 设置元数据并返回指针(跳过Node头)
block->size = size; // 设置大小
return (void*)((char*)block + sizeof(Node)); // 返回用户数据的指针部分
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.
⑴_do_sys_brk函数
经过平台相关实现,malloc最终会调用SYSCALL_DEFINE1宏,扩展为__do_sys_brk函数:
复制
SYSCALL_DEFINE1(brk, unsigned long, brk)
{
unsigned long retval;
unsigned long newbrk, oldbrk, origbrk;
struct mm_struct *mm = current->mm;
struct vm_area_struct *next;
unsigned long min_brk;
bool populate;
bool downgraded = false;
LIST_HEAD(uf);
if (down_write_killable(&mm->mmap_sem)) ///申请写类型读写信号量
return -EINTR;
origbrk = mm->brk; ///brk记录动态分配区的当前底部
#ifdef CONFIG_COMPAT_BRK
/*
* CONFIG_COMPAT_BRK can still be overridden by setting
* randomize_va_space to 2, which will still cause mm->start_brk
* to be arbitrarily shifted
*/
if (current->brk_randomized)
min_brk = mm->start_brk;
else
min_brk = mm->end_data;
#else
min_brk = mm->start_brk;
#endif
if (brk < min_brk)
goto out;
/*
* Check against rlimit here. If this check is done later after the test
* of oldbrk with newbrk then it can escape the test and let the data
* segment grow beyond its set limit the in case where the limit is
* not page aligned -Ram Gupta
*/
if (check_data_rlimit(rlimit(RLIMIT_DATA), brk, mm->start_brk,
mm->end_data, mm->start_data))
goto out;
newbrk = PAGE_ALIGN(brk);
oldbrk = PAGE_ALIGN(mm->brk);
if (oldbrk == newbrk) {
mm->brk = brk;
goto success;
}
/*
* Always allow shrinking brk.
* __do_munmap() may downgrade mmap_sem to read.
*/
if (brk <= mm->brk) { ///请求释放空间
int ret;
/*
* mm->brk must to be protected by write mmap_sem so update it
* before downgrading mmap_sem. When __do_munmap() fails,
* mm->brk will be restored from origbrk.
*/
mm->brk = brk;
ret = __do_munmap(mm, newbrk, oldbrk-newbrk, &uf, true);
if (ret < 0) {
mm->brk = origbrk;
goto out;
} else if (ret == 1) {
downgraded = true;
}
goto success;
}
/* Check against existing mmap mappings. */
next = find_vma(mm, oldbrk);
if (next && newbrk + PAGE_SIZE > vm_start_gap(next)) ///发现有重叠,不需要寻找
goto out;
/* Ok, looks good - let it rip. */
if (do_brk_flags(oldbrk, newbrk-oldbrk, 0, &uf) < 0) ///无重叠,新分配一个vma
goto out;
mm->brk = brk; ///更新brk地址
success:
populate = newbrk > oldbrk && (mm->def_flags & VM_LOCKED) != 0;
if (downgraded)
up_read(&mm->mmap_sem);
else
up_write(&mm->mmap_sem);
userfaultfd_unmap_complete(mm, &uf);
if (populate) ///调用mlockall()系统调用,mm_populate会立刻分配物理内存
mm_populate(oldbrk, newbrk - oldbrk);
return brk;
out:
retval = origbrk;
up_write(&mm->mmap_sem);
return retval;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.98.
总结下_do_sys_brk()功能:
(1)从旧的brk边界去查询,是否有可用vma,若发现有重叠,直接使用;(2)若无发现重叠,新分配一个vma;(3)应用程序若调用mlockall(),会锁住进程所有虚拟地址空间,防止内存被交换出去,且立刻分配物理内存;否则,物理页面会等到使用时,触发缺页异常分配;⑵do_brk_flags函数(1)寻找一个可使用的线性地址;(2)查找最适合插入红黑树的节点;(3)寻到的线性地址是否可以合并现有vma,所不能,新建一个vma;(4)将新建vma插入mmap链表和红黑树中
复制
/*
* this is really a simplified "do_mmap". it only handles
* anonymous maps. eventually we may be able to do some
* brk-specific accounting here.
*/
static int do_brk_flags(unsigned long addr, unsigned long len, unsigned long flags, struct list_head *uf)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
struct rb_node **rb_link, *rb_parent;
pgoff_t pgoff = addr >> PAGE_SHIFT;
int error;
unsigned long mapped_addr;
/* Until we need other flags, refuse anything except VM_EXEC. */
if ((flags & (~VM_EXEC)) != 0)
return -EINVAL;
flags |= VM_DATA_DEFAULT_FLAGS | VM_ACCOUNT | mm->def_flags; ///默认属性,可读写
mapped_addr = get_unmapped_area(NULL, addr, len, 0, MAP_FIXED); ///返回未使用过的,未映射的线性地址区间的,起始地址
if (IS_ERR_VALUE(mapped_addr))
return mapped_addr;
error = mlock_future_check(mm, mm->def_flags, len);
if (error)
return error;
/* Clear old maps, set up prev, rb_link, rb_parent, and uf */
if (munmap_vma_range(mm, addr, len, &prev, &rb_link, &rb_parent, uf)) ///寻找适合插入的红黑树节点
return -ENOMEM;
/* Check against address space limits *after* clearing old maps... */
if (!may_expand_vm(mm, flags, len >> PAGE_SHIFT))
return -ENOMEM;
if (mm->map_count > sysctl_max_map_count)
return -ENOMEM;
if (security_vm_enough_memory_mm(mm, len >> PAGE_SHIFT))
return -ENOMEM;
/* Can we just expand an old private anonymous mapping? */ ///检查是否能合并addr到附近的vma,若不能,只能新建一个vma
vma = vma_merge(mm, prev, addr, addr + len, flags,
NULL, NULL, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
/*
* create a vma struct for an anonymous mapping
*/
vma = vm_area_alloc(mm);
if (!vma) {
vm_unacct_memory(len >> PAGE_SHIFT);
return -ENOMEM;
}
vma_set_anonymous(vma);
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_pgoff = pgoff;
vma->vm_flags = flags;
vma->vm_page_prot = vm_get_page_prot(flags);
vma_link(mm, vma, prev, rb_link, rb_parent); ///新vma添加到mmap链表和红黑树
out:
perf_event_mmap(vma);
mm->total_vm += len >> PAGE_SHIFT;
mm->data_vm += len >> PAGE_SHIFT;
if (flags & VM_LOCKED)
mm->locked_vm += (len >> PAGE_SHIFT);
vma->vm_flags |= VM_SOFTDIRTY;
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.
mm_populate()函数
依次调用:
复制
mm_populate()
->__mm_populate()
->populate_vma_page_range()
->__get_user_pages()1.2.3.4.
当设置VM_LOCKED标志时,表示要马上申请物理页面,并与vma建立映射;否则,这里不操作,直到访问该vma时,触发缺页异常,再分配物理页面,并建立映射;
⑶get_user_pages()函数
复制
static long __get_user_pages(struct mm_struct *mm,
unsigned long start, unsigned long nr_pages,
unsigned int gup_flags, struct page **pages,
struct vm_area_struct **vmas, int *locked)
{
long ret = 0, i = 0;
struct vm_area_struct *vma = NULL;
struct follow_page_context ctx = { NULL };
if (!nr_pages)
return 0;
start = untagged_addr(start);
VM_BUG_ON(!!pages != !!(gup_flags & (FOLL_GET | FOLL_PIN)));
/*
* If FOLL_FORCE is set then do not force a full fault as the hinting
* fault information is unrelated to the reference behaviour of a task
* using the address space
*/
if (!(gup_flags & FOLL_FORCE))
gup_flags |= FOLL_NUMA;
do { ///依次处理每个页面
struct page *page;
unsigned int foll_flags = gup_flags;
unsigned int page_increm;
/* first iteration or cross vma bound */
if (!vma || start >= vma->vm_end) {
vma = find_extend_vma(mm, start); ///检查是否可以扩增vma
if (!vma && in_gate_area(mm, start)) {
ret = get_gate_page(mm, start & PAGE_MASK,
gup_flags, &vma,
pages ? &pages[i] : NULL);
if (ret)
goto out;
ctx.page_mask = 0;
goto next_page;
}
if (!vma) {
ret = -EFAULT;
goto out;
}
ret = check_vma_flags(vma, gup_flags);
if (ret)
goto out;
if (is_vm_hugetlb_page(vma)) { ///支持巨页
i = follow_hugetlb_page(mm, vma, pages, vmas,
&start, &nr_pages, i,
gup_flags, locked);
if (locked && *locked == 0) {
/*
* Weve got a VM_FAULT_RETRY
* and weve lost mmap_lock.
* We must stop here.
*/
BUG_ON(gup_flags & FOLL_NOWAIT);
BUG_ON(ret != 0);
goto out;
}
continue;
}
}
retry:
/*
* If we have a pending SIGKILL, dont keep faulting pages and
* potentially allocating memory.
*/
if (fatal_signal_pending(current)) { ///如果当前进程收到SIGKILL信号,直接退出
ret = -EINTR;
goto out;
}
cond_resched(); //判断是否需要调度,内核中常用该函数,优化系统延迟
page = follow_page_mask(vma, start, foll_flags, &ctx); ///查看VMA的虚拟页面是否已经分配物理内存,返回已经映射的页面的page
if (!page) {
ret = faultin_page(vma, start, &foll_flags, locked); ///若无映射,主动触发虚拟页面到物理页面的映射
switch (ret) {
case 0:
goto retry;
case -EBUSY:
ret = 0;
fallthrough;
case -EFAULT:
case -ENOMEM:
case -EHWPOISON:
goto out;
case -ENOENT:
goto next_page;
}
BUG();
} else if (PTR_ERR(page) == -EEXIST) {
/*
* Proper page table entry exists, but no corresponding
* struct page.
*/
goto next_page;
} else if (IS_ERR(page)) {
ret = PTR_ERR(page);
goto out;
}
if (pages) {
pages[i] = page;
flush_anon_page(vma, page, start); ///分配完物理页面,刷新缓存
flush_dcache_page(page);
ctx.page_mask = 0;
}
next_page:
if (vmas) {
vmas[i] = vma;
ctx.page_mask = 0;
}
page_increm = 1 + (~(start >> PAGE_SHIFT) & ctx.page_mask);
if (page_increm > nr_pages)
page_increm = nr_pages;
i += page_increm;
start += page_increm * PAGE_SIZE;
nr_pages -= page_increm;
} while (nr_pages);
out:
if (ctx.pgmap)
put_dev_pagemap(ctx.pgmap);
return i ? i : ret;
}
follow_page_mask函数返回已经映射的页面的page,最终会调用follow_page_pte函数,其实现如下:1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.98.99.100.101.102.103.104.105.106.107.108.109.110.111.112.113.114.115.116.117.118.119.120.121.122.123.124.125.126.127.128.129.130.
⑷follow_page_pte函数
复制
static struct page *follow_page_pte(struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd, unsigned int flags,
struct dev_pagemap **pgmap)
{
struct mm_struct *mm = vma->vm_mm;
struct page *page;
spinlock_t *ptl;
pte_t *ptep, pte;
int ret;
/* FOLL_GET and FOLL_PIN are mutually exclusive. */
if (WARN_ON_ONCE((flags & (FOLL_PIN | FOLL_GET)) ==
(FOLL_PIN | FOLL_GET)))
return ERR_PTR(-EINVAL);
retry:
if (unlikely(pmd_bad(*pmd)))
return no_page_table(vma, flags);
ptep = pte_offset_map_lock(mm, pmd, address, &ptl); ///获得pte和一个锁
pte = *ptep;
if (!pte_present(pte)) { ///处理页面不在内存中,作以下处理
swp_entry_t entry;
/*
* KSMs break_ksm() relies upon recognizing a ksm page
* even while it is being migrated, so for that case we
* need migration_entry_wait().
*/
if (likely(!(flags & FOLL_MIGRATION)))
goto no_page;
if (pte_none(pte))
goto no_page;
entry = pte_to_swp_entry(pte);
if (!is_migration_entry(entry))
goto no_page;
pte_unmap_unlock(ptep, ptl);
migration_entry_wait(mm, pmd, address); ///等待页面合并完成再尝试
goto retry;
}
if ((flags & FOLL_NUMA) && pte_protnone(pte))
goto no_page;
if ((flags & FOLL_WRITE) && !can_follow_write_pte(pte, flags)) {
pte_unmap_unlock(ptep, ptl);
return NULL;
}
page = vm_normal_page(vma, address, pte); ///根据pte,返回物理页面page(只返回普通页面,特殊页面不参与内存管理)
if (!page && pte_devmap(pte) && (flags & (FOLL_GET | FOLL_PIN))) { ///处理设备映射文件
/*
* Only return device mapping pages in the FOLL_GET or FOLL_PIN
* case since they are only valid while holding the pgmap
* reference.
*/
*pgmap = get_dev_pagemap(pte_pfn(pte), *pgmap);
if (*pgmap)
page = pte_page(pte);
else
goto no_page;
} else if (unlikely(!page)) { ///处理vm_normal_page()没返回有效页面情况
if (flags & FOLL_DUMP) {
/* Avoid special (like zero) pages in core dumps */
page = ERR_PTR(-EFAULT);
goto out;
}
if (is_zero_pfn(pte_pfn(pte))) { ///系统零页,不会返回错误
page = pte_page(pte);
} else {
ret = follow_pfn_pte(vma, address, ptep, flags);
page = ERR_PTR(ret);
goto out;
}
}
/* try_grab_page() does nothing unless FOLL_GET or FOLL_PIN is set. */
if (unlikely(!try_grab_page(page, flags))) {
page = ERR_PTR(-ENOMEM);
goto out;
}
/*
* We need to make the page accessible if and only if we are going
* to access its content (the FOLL_PIN case). Please see
* Documentation/core-api/pin_user_pages.rst for details.
*/
if (flags & FOLL_PIN) {
ret = arch_make_page_accessible(page);
if (ret) {
unpin_user_page(page);
page = ERR_PTR(ret);
goto out;
}
}
if (flags & FOLL_TOUCH) { ///FOLL_TOUCH, 标记页面可访问
if ((flags & FOLL_WRITE) &&
!pte_dirty(pte) && !PageDirty(page))
set_page_dirty(page);
/*
* pte_mkyoung() would be more correct here, but atomic care
* is needed to avoid losing the dirty bit: it is easier to use
* mark_page_accessed().
*/
mark_page_accessed(page);
}
if ((flags & FOLL_MLOCK) && (vma->vm_flags & VM_LOCKED)) {
/* Do not mlock pte-mapped THP */
if (PageTransCompound(page))
goto out;
/*
* The preliminary mapping check is mainly to avoid the
* pointless overhead of lock_page on the ZERO_PAGE
* which might bounce very badly if there is contention.
*
* If the page is already locked, we dont need to
* handle it now - vmscan will handle it later if and
* when it attempts to reclaim the page.
*/
if (page->mapping && trylock_page(page)) {
lru_add_drain(); /* push cached pages to LRU */
/*
* Because we lock page here, and migration is
* blocked by the ptes page reference, and we
* know the page is still mapped, we dont even
* need to check for file-cache page truncation.
*/
mlock_vma_page(page);
unlock_page(page);
}
}
out:
pte_unmap_unlock(ptep, ptl);
return page;
no_page:
pte_unmap_unlock(ptep, ptl);
if (!pte_none(pte))
return NULL;
return no_page_table(vma, flags);
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.98.99.100.101.102.103.104.105.106.107.108.109.110.111.112.113.114.115.116.117.118.119.120.121.122.123.124.125.126.127.128.129.130.131.132.133.134.135.136.137.
(1)malloc函数,从C库缓存分配内存,其分配或释放内存,未必马上会执行;
(2)malloc实际分配内存动作,要么主动设置mlockall(),人为触发缺页异常,分配物理页面;或者在访问内存时触发缺页异常,分配物理页面;
(3)malloc分配虚拟内存,有三种情况:
malloc()分配内存后,直接读,linux内核进入缺页异常,调用do_anonymous_page函数使用零页映射,此时PTE属性只读;malloc()分配内存后,先读后写,linux内核第一次触发缺页异常,映射零页;第二次触发异常,触发写时复制;c.malloc()分配内存后, 直接写,linux内核进入匿名页面的缺页异常,调alloc_zeroed_user_highpage_movable分配一个新页面,这个PTE是可写的;
1.2 kmalloc内核空间常规内存分配
一般来说内核程序中对小于一页的小块内存的请求会通过slab分配器提供的接口kmalloc来完成(虽然它可分配32到131072字节的内存)。从内核内存分配角度讲kmalloc可被看成是get_free_page(s)的一个有效补充,内存分配粒度更灵活了。
kmalloc()函数类似与我们常见的malloc()函数,前者用于内核态的内存分配,后者用于用户态;kmalloc()函数在物理内存中分配一块连续的存储空间,且和malloc()函数一样,不会清除里面的原始数据,如果内存充足,它的分配速度很快,其原型如下:
复制
static inline void *kmalloc(size_t size, gfp_t flags); /*返回的是虚拟地址*/1.
size:待分配的内存大小。由于Linux内存管理机制的原因,内存只能按照页面大小(一般32位机为4KB,64位机为8KB)进行分配,这样就导致了当我们仅需要几个字节内存时,系统仍会返回一个页面的内存,显然这是极度浪费的。所以,不同于malloc的是,kmalloc的处理方式是:内核先为其分配一系列不同大小(32B、64B、128B、… 、128KB)的内存池,当需要分配内存时,系统会分配大于等于所需内存的最小一个内存池给它。即kmalloc分配的内存,最小为32字节,最大为128KB。如果超过128KB,需要采样其它内存分配函数,例如vmalloc()。flag:该参数用于控制函数的行为,最常用的是GFP_KERNEL,表示当当前没有足够内存分配时,进程进入睡眠,待系统将缓冲区中的内容SWAP到硬盘中后,获得足够内存后再唤醒进程,为其分配。
使用 GFP_ KERNEL 标志申请内存时,若暂时不能满足,则进程会睡眠等待页,即会引起阻塞,因此不能在中断上下文或持有自旋锁的时候使用GFP_KERNE 申请内存。所以,在中断处理函数、tasklet 和内核定时器等非进程上下文中不能阻塞,此时驱动应当使用 GFP_ATOMIC 标志来申请内存。当使用 GFP_ATOMIC 标志申请内存时,若不存在空闲页,则不等待,直接返回。
kmalloc函数
复制
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size)) {
#ifndef CONFIG_SLOB
unsigned int index;
#endif
if (size > KMALLOC_MAX_CACHE_SIZE)
return kmalloc_large(size, flags);
#ifndef CONFIG_SLOB
index = kmalloc_index(size); ///查找使用的哪个slab缓冲区
if (!index)
return ZERO_SIZE_PTR;
return kmem_cache_alloc_trace( ///从slab分配内存
kmalloc_caches[kmalloc_type(flags)][index],
flags, size);
#endif
}
return __kmalloc(size, flags);
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.
kmem_cache_alloc_trace分配函数
复制
void *
kmem_cache_alloc_trace(struct kmem_cache *cachep, gfp_t flags, size_t size)
{
void *ret;
ret = slab_alloc(cachep, flags, size, _RET_IP_); ///分配slab缓存
ret = kasan_kmalloc(cachep, ret, size, flags);
trace_kmalloc(_RET_IP_, ret,
size, cachep->size, flags);
return ret;
}1.2.3.4.5.6.7.8.9.10.11.12.
可见,kmalloc()基于slab分配器实现,因此分配的内存,物理上都是连续的。
1.3 vmalloc内核空间虚拟内存分配
vmalloc()一般用在为只存在于软件中(没有对应的硬件意义)的较大的顺序缓冲区分配内存,当内存没有足够大的连续物理空间可以分配时,可以用该函数来分配虚拟地址连续但物理地址不连续的内存。由于需要建立新的页表,所以它的开销要远远大于kmalloc及后面将要讲到的__get_free_pages()函数。且vmalloc()不能用在原子上下文中,因为它的内部实现使用了标志为 GFP_KERNEL 的kmalloc(),其函数原型如下:
复制
void *vmalloc(unsigned long size);
void vfree(const void *addr);1.2.
使用 vmalloc 函数的一个例子函数是create_module()系统调用,它利用 vmalloc()函数来获取被创建模块需要的内存空间。
内存分配是一项要求严格的任务,无论什么时候,都应该对返回值进行检测,在驱动编程中可以使用copy_from_user()对内存进行使用。下面举一个使用vmalloc函数的示例:
复制
static int xxx(...)
{
...
cpuid_entries = vmalloc(sizeof(struct kvm_cpuid_entry) * cpuid->nent);
if(!cpuid_entries)
goto out;
if(copy_from_user(cpuid_entries, entries, cpuid->nent * sizeof(struct kvm_cpuid_entry)))
goto out_free;
for(i=0; i<cpuid->nent; i++){
vcpuid->arch.cpuid_entries[i].eax = cpuid_entries[i].eax;
...
vcpuid->arch.cpuid_entries[i].index = 0;
}
...
out_free:
vfree(cpuid_entries);
out:
return r;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
核心函数__vmalloc_node_range
复制
static void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,
pgprot_t prot, unsigned int page_shift,
int node)
{
const gfp_t nested_gfp = (gfp_mask & GFP_RECLAIM_MASK) | __GFP_ZERO;
unsigned long addr = (unsigned long)area->addr;
unsigned long size = get_vm_area_size(area); ///计算vm_struct包含多少个页面
unsigned long array_size;
unsigned int nr_small_pages = size >> PAGE_SHIFT;
unsigned int page_order;
struct page **pages;
unsigned int i;
array_size = (unsigned long)nr_small_pages * sizeof(struct page *);
gfp_mask |= __GFP_NOWARN;
if (!(gfp_mask & (GFP_DMA | GFP_DMA32)))
gfp_mask |= __GFP_HIGHMEM;
/* Please note that the recursion is strictly bounded. */
if (array_size > PAGE_SIZE) {
pages = __vmalloc_node(array_size, 1, nested_gfp, node,
area->caller);
} else {
pages = kmalloc_node(array_size, nested_gfp, node);
}
if (!pages) {
free_vm_area(area);
warn_alloc(gfp_mask, NULL,
"vmalloc size %lu allocation failure: "
"page array size %lu allocation failed",
nr_small_pages * PAGE_SIZE, array_size);
return NULL;
}
area->pages = pages; ///保存已分配页面的page数据结构的指针
area->nr_pages = nr_small_pages;
set_vm_area_page_order(area, page_shift - PAGE_SHIFT);
page_order = vm_area_page_order(area);
/*
* Careful, we allocate and map page_order pages, but tracking is done
* per PAGE_SIZE page so as to keep the vm_struct APIs independent of
* the physical/mapped size.
*/
for (i = 0; i < area->nr_pages; i += 1U << page_order) {
struct page *page;
int p;
/* Compound pages required for remap_vmalloc_page */
page = alloc_pages_node(node, gfp_mask | __GFP_COMP, page_order); ///分配物理页面
if (unlikely(!page)) {
/* Successfully allocated i pages, free them in __vfree() */
area->nr_pages = i;
atomic_long_add(area->nr_pages, &nr_vmalloc_pages);
warn_alloc(gfp_mask, NULL,
"vmalloc size %lu allocation failure: "
"page order %u allocation failed",
area->nr_pages * PAGE_SIZE, page_order);
goto fail;
}
for (p = 0; p < (1U << page_order); p++)
area->pages[i + p] = page + p;
if (gfpflags_allow_blocking(gfp_mask))
cond_resched();
}
atomic_long_add(area->nr_pages, &nr_vmalloc_pages);
if (vmap_pages_range(addr, addr + size, prot, pages, page_shift) < 0) { ///建立物理页面到vma的映射
warn_alloc(gfp_mask, NULL,
"vmalloc size %lu allocation failure: "
"failed to map pages",
area->nr_pages * PAGE_SIZE);
goto fail;
}
return area->addr;
fail:
__vfree(area->addr);
return NULL;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.
可见,vmalloc是临时在vmalloc内存区申请vma,并且分配物理页面,建立映射;直接分配物理页面,至少一个页4K,因此vmalloc适合用于分配较大内存,并且物理内存不一定连续;
二、mmap函数详解最后
2.1mmap函数
mmap 即 memory map,也就是内存映射。mmap 是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用 read、write 等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。如下图所示:
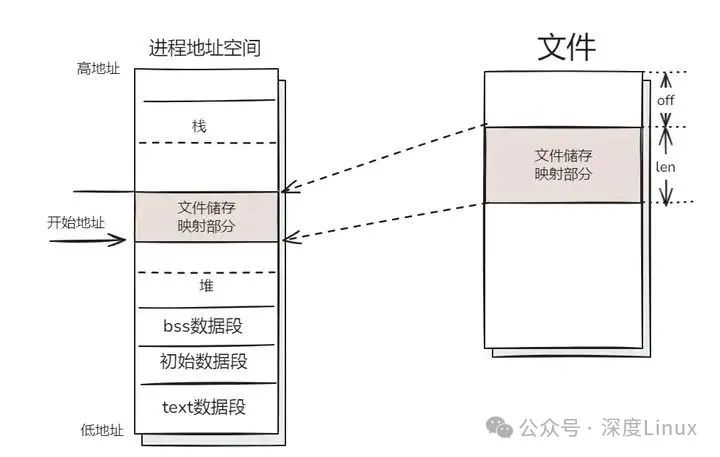 图片
图片
mmap的作用,在应用这一层,是让你把文件的某一段,当作内存一样来访问。将文件映射到物理内存,将进程虚拟空间映射到那块内存。这样,进程不仅能像访问内存一样读写文件,多个进程映射同一文件,还能保证虚拟空间映射到同一块物理内存,达到内存共享的作用。
mmap 是 Linux 中用处非常广泛的一个系统调用,它将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。mmap 必须以 PAGE_SIZE 为单位进行映射,而内存也只能以页为单位进行映射,若要映射非 PAGE_SIZE 整数倍的地址范围,要先进行内存对齐,强行以 PAGE_SIZE 的倍数大小进行映射。
其函数原型为:void *mmap (void start, size_t length, int prot, int flags, int fd, off_t offset);int munmap(void start, size_t length);。下面介绍一下内存映射的步骤:
用 open 系统调用打开文件,并返回描述符 fd。用 mmap 建立内存映射,并返回映射首地址指针 start。对映射(文件)进行各种操作,如显示(printf)、修改(sprintf)等。用 munmap (void *start, size_t length) 关闭内存映射。用 close 系统调用关闭文件 fd。
2.2mmap工作原理
mmap函数创建一个新的vm_area_struct结构,并将其与文件/设备的物理地址相连。
vm_area_struct:linux使用vm_area_struct来表示一个独立的虚拟内存区域,一个进程可以使用多个vm_area_struct来表示不用类型的虚拟内存区域(如堆,栈,代码段,MMAP区域等)。
vm_area_struct结构中包含了区域起始地址。同时也包含了一个vm_opt指针,其内部可引出所有针对这个区域可以使用的系统调用函数。从而,进程可以通过vm_area_struct获取操作这段内存区域所需的任何信息。
进程通过vma操作内存,而vma与文件/设备的物理地址相连,系统自动回写脏页面到对应的文件磁盘上(或写入到设备地址空间),实现内存映射文件。
内存映射文件的原理:
首先创建虚拟区间并完成地址映射,此时还没有将任何文件数据拷贝至主存。当进程发起读写操作时,会访问虚拟地址空间,通过查询页表,发现这段地址不在物理页上,因为只建立了地址映射,真正的数据还没有拷贝到内存,因此引发缺页异常。缺页异常经过一系列判断,确定无非法操作后,内核发起请求调页过程。
最终会调用nopage函数把所缺的页从文件在磁盘里的地址拷贝到物理内存。之后进程便可以对这片主存进行读写,如果写操作修改了内容,一定时间后系统会自动回写脏页面到对应的磁盘地址,完成了写入到文件的过程。另外,也可以调用msync()来强制同步,这样所写的内存就能立刻保存到文件中。
mmap内存映射的实现过程,总的来说可以分为三个阶段:
⑴进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域
进程在用户空间调用库函数mmap,原型:void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);在当前进程的虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址为此虚拟区分配一个vm_area_struct结构,接着对这个结构的各个域进行了初始化将新建的虚拟区结构(vm_area_struct)插入进程的虚拟地址区域链表或树中
⑵调用内核空间的系统调用函数mmap(不同于用户空间函数),实现文件物理地址和进程虚拟地址的一一映射关系
为映射分配了新的虚拟地址区域后,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,通过文件描述符,链接到内核“已打开文件集”中该文件的文件结构体(struct file),每个文件结构体维护着和这个已打开文件相关各项信息。通过该文件的文件结构体,链接到file_operations模块,调用内核函数mmap,其原型为:int mmap(struct file *filp, struct vm_area_struct *vma),不同于用户空间库函数。内核mmap函数通过虚拟文件系统inode模块定位到文件磁盘物理地址。通过remap_pfn_range函数建立页表,即实现了文件地址和虚拟地址区域的映射关系。此时,这片虚拟地址并没有任何数据关联到主存中。
⑶进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝
注:前两个阶段仅在于创建虚拟区间并完成地址映射,但是并没有将任何文件数据的拷贝至主存。真正的文件读取是当进程发起读或写操作时。
进程的读或写操作访问虚拟地址空间这一段映射地址,通过查询页表,发现这一段地址并不在物理页面上。因为目前只建立了地址映射,真正的硬盘数据还没有拷贝到内存中,因此引发缺页异常。缺页异常进行一系列判断,确定无非法操作后,内核发起请求调页过程。调页过程先在交换缓存空间(swap cache)中寻找需要访问的内存页,如果没有则调用nopage函数把所缺的页从磁盘装入到主存中。之后进程即可对这片主存进行读或者写的操作,如果写操作改变了其内容,一定时间后系统会自动回写脏页面到对应磁盘地址,也即完成了写入到文件的过程。
注:修改过的脏页面并不会立即更新回文件中,而是有一段时间的延迟,可以调用msync()来强制同步, 这样所写的内容就能立即保存到文件里了。
2.3如何使用mmap技术
(1)mmap使用细节
使用mmap需要注意的一个关键点是,mmap映射区域大小必须是物理页大小(page_size)的整倍数(32位系统中通常是4k字节)。原因是,内存的最小粒度是页,而进程虚拟地址空间和内存的映射也是以页为单位。为了匹配内存的操作,mmap从磁盘到虚拟地址空间的映射也必须是页。
内核可以跟踪被内存映射的底层对象(文件)的大小,进程可以合法的访问在当前文件大小以内又在内存映射区以内的那些字节。也就是说,如果文件的大小一直在扩张,只要在映射区域范围内的数据,进程都可以合法得到,这和映射建立时文件的大小无关。
映射建立之后,即使文件关闭,映射依然存在。因为映射的是磁盘的地址,不是文件本身,和文件句柄无关。同时可用于进程间通信的有效地址空间不完全受限于被映射文件的大小,因为是按页映射。
在上面的知识前提下,我们下面看看如果大小不是页的整倍数的具体情况:
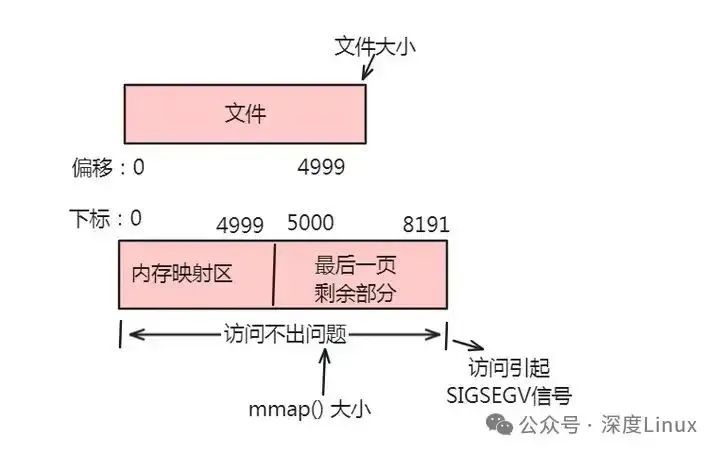
情形一:一个文件的大小是5000字节,mmap函数从一个文件的起始位置开始,映射5000字节到虚拟内存中。
分析:因为单位物理页面的大小是4096字节,虽然被映射的文件只有5000字节,但是对应到进程虚拟地址区域的大小需要满足整页大小,因此mmap函数执行后,实际映射到虚拟内存区域8192个 字节,5000~8191的字节部分用零填充。映射后的对应关系如下图所示:
 图片
图片
此时:(1)读/写前5000个字节(0~4999),会返回操作文件内容。(2)读字节50008191时,结果全为0。写50008191时,进程不会报错,但是所写的内容不会写入原文件中 。(3)读/写8192以外的磁盘部分,会返回一个SIGSECV错误。
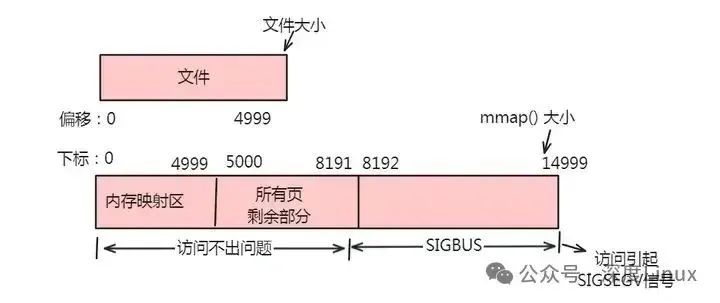
情形二:一个文件的大小是5000字节,mmap函数从一个文件的起始位置开始,映射15000字节到虚拟内存中,即映射大小超过了原始文件的大小。
分析:由于文件的大小是5000字节,和情形一一样,其对应的两个物理页。那么这两个物理页都是合法可以读写的,只是超出5000的部分不会体现在原文件中。由于程序要求映射15000字节,而文件只占两个物理页,因此8192字节~15000字节都不能读写,操作时会返回异常。如下图所示:
 图片
图片
此时:(1)进程可以正常读/写被映射的前5000字节(0~4999),写操作的改动会在一定时间后反映在原文件中。(2)对于5000~8191字节,进程可以进行读写过程,不会报错。但是内容在写入前均为0,另外,写入后不会反映在文件中。(3)对于8192~14999字节,进程不能对其进行读写,会报SIGBUS错误。(4)对于15000以外的字节,进程不能对其读写,会引发SIGSEGV错误。
情形三:一个文件初始大小为0,使用mmap操作映射了10004K的大小,即1000个物理页大约4M字节空间,mmap返回指针ptr。
分析:如果在映射建立之初,就对文件进行读写操作,由于文件大小为0,并没有合法的物理页对应,如同情形二一样,会返回SIGBUS错误。但是如果,每次操作ptr读写前,先增加文件的大小,那么ptr在文件大小内部的操作就是合法的。例如,文件扩充4096字节,ptr就能操作ptr ~ [ (char)ptr + 4095]的空间。只要文件扩充的范围在1000个物理页(映射范围)内,ptr都可以对应操作相同的大小。这样,方便随时扩充文件空间,随时写入文件,不造成空间浪费。
(2)函数定义及参数解释
在 Linux 中,mmap 函数定义如下:void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);。参数解释如下:
addr:希望映射的起始地址,通常为 NULL,表示由内核决定映射的地址。length:映射区域的大小(以字节为单位)。prot:映射区域的保护权限,决定映射的页面是否可读、可写等。常见的权限选项包括:PROT_READ(可读)、PROT_WRITE(可写)、PROT_EXEC(可执行)、PROT_NONE(无权限)。flags:映射的类型和行为控制。常见的标志包括:MAP_SHARED(共享映射,对该内存的修改会同步到文件)、MAP_PRIVATE(私有映射,对该内存的修改不会影响原文件,写时拷贝)、MAP_ANONYMOUS(匿名映射,不涉及文件,通常用于分配未初始化的内存)。fd:文件描述符,指向要映射的文件。如果使用匿名映射,应将 fd 设置为 -1,并且需要设置 MAP_ANONYMOUS 标志。offset:文件映射的偏移量,必须是页面大小的整数倍(通常为 4096 字节)。
返回值:返回映射区域的起始地址,如果映射失败,则返回 MAP_FAILED。
(3)mmap映射
在内存映射的过程中,并没有实际的数据拷贝,文件没有被载入内存,只是逻辑上被放入了内存,具体到代码,就是建立并初始化了相关的数据结构(struct address_space),这个过程有系统调用mmap()实现,所以建立内存映射的效率很高。既然建立内存映射没有进行实际的数据拷贝,那么进程又怎么能最终直接通过内存操作访问到硬盘上的文件呢?
那就要看内存映射之后的几个相关的过程了。mmap()会返回一个指针ptr,它指向进程逻辑地址空间中的一个地址,这样以后,进程无需再调用read或write对文件进行读写,而只需要通过ptr就能够操作文件。但是ptr所指向的是一个逻辑地址,要操作其中的数据,必须通过MMU将逻辑地址转换成物理地址,这个过程与内存映射无关。
前面讲过,建立内存映射并没有实际拷贝数据,这时,MMU在地址映射表中是无法找到与ptr相对应的物理地址的,也就是MMU失败,将产生一个缺页中断,缺页中断的中断响应函数会在swap中寻找相对应的页面,如果找不到(也就是该文件从来没有被读入内存的情况),则会通过mmap()建立的映射关系,从硬盘上将文件读取到物理内存中,如图1中过程3所示。这个过程与内存映射无关。如果在拷贝数据时,发现物理内存不够用,则会通过虚拟内存机制(swap)将暂时不用的物理页面交换到硬盘上,这个过程也与内存映射无关。
mmap内存映射的实现过程:
进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域调用内核空间的系统调用函数mmap(不同于用户空间函数),实现文件物理地址和进程虚拟地址的一一映射关系进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝
适合的场景
您有一个很大的文件,其内容您想要随机访问一个或多个时间您有一个小文件,它的内容您想要立即读入内存并经常访问。这种技术最适合那些大小不超过几个虚拟内存页的文件。(页是地址空间的最小单位,虚拟页和物理页的大小是一样的,通常为4KB。)您需要在内存中缓存文件的特定部分。文件映射消除了缓存数据的需要,这使得系统磁盘缓存中的其他数据空间更大 当随机访问一个非常大的文件时,通常最好只映射文件的一小部分。映射大文件的问题是文件会消耗活动内存。如果文件足够大,系统可能会被迫将其他部分的内存分页以加载文件。将多个文件映射到内存中会使这个问题更加复杂。
不适合的场景
您希望从开始到结束的顺序从头到尾读取一个文件这个文件有几百兆字节或者更大。将大文件映射到内存中会快速地填充内存,并可能导致分页,这将抵消首先映射文件的好处。对于大型顺序读取操作,禁用磁盘缓存并将文件读入一个小内存缓冲区该文件大于可用的连续虚拟内存地址空间。对于64位应用程序来说,这不是什么问题,但是对于32位应用程序来说,这是一个问题该文件位于可移动驱动器上该文件位于网络驱动器上
示例代码
复制
//
// ViewController.m
// TestCode
//
// Created by zhangdasen on 2020/5/24.
// Copyright © 2020 zhangdasen. All rights reserved.
//
#import "ViewController.h"
#import <sys/mman.h>
#import <sys/stat.h>
@interface ViewController ()
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
NSString *path = [NSHomeDirectory() stringByAppendingPathComponent:@"test.data"];
NSLog(@"path: %@", path);
NSString *str = @"test str2";
[str writeToFile:path atomically:YES encoding:NSUTF8StringEncoding error:nil];
ProcessFile(path.UTF8String);
NSString *result = [NSString stringWithContentsOfFile:path encoding:NSUTF8StringEncoding error:nil];
NSLog(@"result:%@", result);
}
int MapFile(const char * inPathName, void ** outDataPtr, size_t * outDataLength, size_t appendSize)
{
int outError;
int fileDescriptor;
struct stat statInfo;
// Return safe values on error.
outError = 0;
*outDataPtr = NULL;
*outDataLength = 0;
// Open the file.
fileDescriptor = open( inPathName, O_RDWR, 0 );
if( fileDescriptor < 0 )
{
outError = errno;
}
else
{
// We now know the file exists. Retrieve the file size.
if( fstat( fileDescriptor, &statInfo ) != 0 )
{
outError = errno;
}
else
{
ftruncate(fileDescriptor, statInfo.st_size + appendSize);
fsync(fileDescriptor);
*outDataPtr = mmap(NULL,
statInfo.st_size + appendSize,
PROT_READ|PROT_WRITE,
MAP_FILE|MAP_SHARED,
fileDescriptor,
0);
if( *outDataPtr == MAP_FAILED )
{
outError = errno;
}
else
{
// On success, return the size of the mapped file.
*outDataLength = statInfo.st_size;
}
}
// Now close the file. The kernel doesn’t use our file descriptor.
close( fileDescriptor );
}
return outError;
}
void ProcessFile(const char * inPathName)
{
size_t dataLength;
void * dataPtr;
char *appendStr = " append_key2";
int appendSize = (int)strlen(appendStr);
if( MapFile(inPathName, &dataPtr, &dataLength, appendSize) == 0) {
dataPtr = dataPtr + dataLength;
memcpy(dataPtr, appendStr, appendSize);
// Unmap files
munmap(dataPtr, appendSize + dataLength);
}
}
@end1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.98.
(5)解除映射的方法
使用 mmap 后,必须调用 munmap 来解除映射,释放分配的虚拟内存。其函数定义如下:int munmap(void *addr, size_t length);。
addr:要解除映射的内存区域的起始地址。length:要解除映射的大小。
返回值:成功返回 0,失败返回 -1。
⑴利用 mmap 访问硬件,减少数据拷贝次数
mmap 可以将文件、设备等外部资源映射到内存地址空间,进程可以像访问内存一样访问文件数据或硬件资源。当使用 mmap 访问硬件时,数据可以直接从硬件设备通过 DMA 拷贝到内核缓冲区,然后进程可以直接访问这个缓冲区,减少了数据拷贝的次数。
例如,在嵌入式系统中,可以使用 mmap 将物理地址映射到用户虚拟地址空间,实现对硬件设备的直接访问。在进行数据传输时,避免了传统方式中从内核空间到用户空间的多次数据拷贝,提高了数据传输的效率。
⑵通过 mmap 实现将物理地址映射到用户虚拟地址空间:
打开 /dev/mem 文件获得文件描述符 dev_mem_fd。使用 mmap 函数进行映射,将物理地址映射到用户虚拟地址空间。例如,定义一个函数 dma_mmap 来实现这个功能,函数原型为 int dma_mmap(unsigned long addr_p, unsigned int len, unsigned char** addr_v)。在这个函数中,首先打开 /dev/mem 文件,然后使用 mmap 函数进行映射,最后返回虚拟地址。使用映射后的虚拟地址进行操作,例如读写硬件设备。在使用完后,调用 dma_munmap 函数解除映射,释放资源。函数原型为 unsigned int dma_munmap(unsigned char* addr_v, unsigned long addr_p, unsigned int len)。
⑶在嵌入式系统中,还可以通过以下方式实现物理地址到用户虚拟地址空间的映射:
在驱动程序中,实现 mmap 方法,建立虚拟地址到物理地址的页表。例如,可以使
用 remap_pfn_range 函数一次建立所有页表,或者使用 nopage VMA 方法每次建立一个页表。在用户空间程序中,使用 mmap 函数进行映射,将文件描述符、映射大小、保护权限等参数传入,获得映射后的虚拟地址。然后可以通过这个虚拟地址对硬件设备进行操作。
三、页分配函数最后
该函数定义在头文件/include/linux/gfp.h中,它既可以在内核空间分配,也可以在用户空间分配,它返回分配的第一个页的描述符而非首地址,其原型为:
复制
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
#define alloc_pages(gfp_mask, order) alloc_pages_node(numa_node_id(), gfp_mask, order)//分配连续2^order个页面
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order)
{
if(unlikely(order >= MAX_ORDER))
return NULL;
if(nid < 0)
nid = numa_node_id();
return __alloc_pages(gfp_mask, order, noed_zonelist(nid, gfp_mask));
}1.2.3.4.5.6.7.8.9.10.
 图片
图片
根据返回页面数目分类,分为仅返回单页面的函数和返回多页面的函数。
3.1alloc_page()和alloc_pages()函数
该函数定义在头文件/include/linux/gfp.h中,它既可以在内核空间分配,也可以在用户空间分配,它返回分配的第一个页的描述符而非首地址,其原型为:
复制
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
#define alloc_pages(gfp_mask, order) alloc_pages_node(numa_node_id(), gfp_mask, order)//分配连续2^order个页面
static inline struct page *alloc_pages_node(int nid, gfp_t gfp_mask, unsigned int order)
{
if(unlikely(order >= MAX_ORDER))
return NULL;
if(nid < 0)
nid = numa_node_id();
return __alloc_pages(gfp_mask, order, noed_zonelist(nid, gfp_mask));
}1.2.3.4.5.6.7.8.9.10.
3.2_get_free_pages()系列函数
它是kmalloc函数实现的基础,返回一个或多个页面的虚拟地址。该系列函数/宏包括 get_zeroed_page()、_ _get_free_page()和_ _get_free_pages()。在使用时,其申请标志的值及含义与 kmalloc()完全一样,最常用的是 GFP_KERNEL 和 GFP_ATOMIC。
复制
/*分配多个页并返回分配内存的首地址,分配的页数为2^order,分配的页不清零。
order 允许的最大值是 10(即 1024 页)或者 11(即 2048 页),依赖于具体
的硬件平台。*/
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
page = alloc_pages(gfp_mask, order);
if(!page)
return 0;
return (unsigned long)page_address(page);
}
#define __get_free_page(gfp_mask) __get_free_pages(gfp_mask, 0)
/*该函数返回一个指向新页的指针并且将该页清零*/
unsigned long get_zeroed_page(unsigned int flags);1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.
使用_ _get_free_pages()系列函数/宏申请的内存应使用free_page(addr)或free_pages(addr, order)函数释放:
复制
#define __free_page(page) __free_pages((page), 0)
#define free_page(addr) free_pages((addr), 0)
void free_pages(unsigned long addr, unsigned int order)
{
if(addr != 0){
VM_BUG_ON(!virt_addr_valid((void*)addr));
__free_pages(virt_to_page((void *)addr), order);
}
}
void __free_pages(struct page *page, unsigned int order)
{
if(put_page_testzero(page)){
if(order == 0)
free_hot_page(page);
else
__free_pages_ok(page, order);
}
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.
free_pages()函数是调用__free_pages()函数完成内存释放的。
四、Buddy算法详解最后
4.1Buddy算法
Buddy 算法堪称 Linux 内存管理的基石,主要用于管理 DMA(直接内存存取)、常规、高端内存这 3 个区域 。它的核心理念十分巧妙,将空闲的页以 2 的 n 次方为单位进行管理,这意味着 Linux 最底层的内存申请都是以 2 的 n 次方为单位。其最大的优势在于能够有效避免内存的外部碎片。在传统的内存管理算法中,频繁的内存分配和释放容易导致内存空间被分割成许多小块,这些小块之间的空闲区域无法被有效利用,就形成了外部碎片。而 Buddy 算法通过将内存页按照 2 的幂次方大小进行组织和管理,使得系统在分配和回收内存时,能够更好地合并相邻的空闲块,从而避免了这种外部碎片的产生 。
例如,假设 ZONE_NORMAL 区域有 16 页内存(即 2 的 4 次方),当有程序申请一页内存时,Buddy 算法会把剩下的 15 页巧妙地拆分成 8 + 4 + 2 + 1,分别放到不同的链表中。此时若再有程序申请 4 页内存,系统可以直接从 4 页的链表中分配;若再申请 4 页,就从 8 页的链表中拿出 4 页进行分配,正好剩下 4 页。其精髓就在于任何正整数都可以拆分成 2 的 n 次方之和。
然而,金无足赤,人无完人,Buddy 算法也有其局限性。长期运行后,系统中大片的连续内存会逐渐减少,而 1 页、2 页、4 页这种小内存块会越来越多。当需要分配大片连续内存时,就可能会出现问题,也就是说它是以产生内部碎片为代价来避免外部碎片的产生。所谓内部碎片,就是系统已经分配给用户使用,但用户自己没有用到的那部分存储空间。我们可以通过/proc/buddyinfo文件来查看内存空闲的相关情况,以便及时了解系统内存的分配状态,为系统优化提供依据 。
4.2伙伴算法原理
Linux 便是采用这著名的伙伴系统算法来解决外部碎片的问题。把所有的空闲页框分组为 11 块链表,每一块链表分别包含大小为1,2,4,8,16,32,64,128,256,512 和 1024 个连续的页框。对1024 个页框的最大请求对应着 4MB 大小的连续RAM 块。每一块的第一个页框的物理地址是该块大小的整数倍。例如,大小为 16个页框的块,其起始地址是 16 * 2^12 (2^12 = 4096,这是一个常规页的大小)的倍数。
下面通过一个简单的例子来说明该算法的工作原理:
假设要请求一个256(129~256)个页框的块。算法先在256个页框的链表中检查是否有一个空闲块。如果没有这样的块,算法会查找下一个更大的页块,也就是,在512个页框的链表中找一个空闲块。如果存在这样的块,内核就把512的页框分成两等分,一般用作满足需求,另一半则插入到256个页框的链表中。
如果在512个页框的块链表中也没找到空闲块,就继续找更大的块——1024个页框的块。如果这样的块存在,内核就把1024个页框块的256个页框用作请求,然后剩余的768个页框中拿512个插入到512个页框的链表中,再把最后的256个插入到256个页框的链表中。如果1024个页框的链表还是空的,算法就放弃并发出错误信号。
⑴相关数据结构
复制
#define MAX_ORDER 11
struct zone {
……
struct free_area free_area[MAX_ORDER];
……
}
struct free_area {
struct list_head free_list;
unsigned long nr_free;//该组类别块空闲的个数
};1.2.3.4.5.6.7.8.9.10.11.
Zone结构体中的free_area数组的第k个元素,它保存了所有连续大小为2^k的空闲块,具体是通过将连续页的第一个页插入到free_list中实现的,连续页的第一个页的页描述符的private字段表明改部分连续页属于哪一个order链表。
⑵伙伴算法系统初始化
Linux内核启动时,伙伴算法还不可用,linux是通过bootmem来管理内存,在mem_init中会把bootmem位图中空闲的内存块插入到伙伴算法系统的free_list中。
调用流程如下:
mem_init----->__free_all_bootmem()—>free_all_bootmem()>free_all_bootmem_core(NODE_DATA(0))–>free_all_bootmem_core(pgdat)
复制
//利用free_page 将页面分给伙伴管理器
free_all_bootmem
return(free_all_bootmem_core(NODE_DATA(0))); //#define NODE_DATA(nid) (&contig_page_data)
bootmem_data_t *bdata = pgdat->bdata;
page = virt_to_page(phys_to_virt(bdata->node_boot_start));
idx = bdata->node_low_pfn - (bdata->node_boot_start >> PAGE_SHIFT);
map = bdata->node_bootmem_map;
for (i = 0; i < idx; )
unsigned long v = ~map[i / BITS_PER_LONG];
//如果32个页都是空闲的
if (gofast && v == ~0UL)
count += BITS_PER_LONG;
__ClearPageReserved(page);
order = ffs(BITS_PER_LONG) - 1;
//设置32个页的引用计数为1
set_page_refs(page, order)
//一次性释放32个页到空闲链表
__free_pages(page, order);
__free_pages_ok(page, order);
list_add(&page->lru, &list);
//page_zone定义如下return zone_table[page->flags >> NODEZONE_SHIFT];
//接收一个页描述符的地址作为它的参数,它读取页描述符的flags字段的高位,并通过zone_table数组来确定相应管理区描述符的地址,最终将页框回收到对应的管理区中
free_pages_bulk(page_zone(page), 1, &list, order);
i += BITS_PER_LONG;
page += BITS_PER_LONG;
//这32个页中,只有部分是空闲的
else if (v)
for (m = 1; m && i < idx; m<<=1, page++, i++)
if (v & m)
count++;
__ClearPageReserved(page);
set_page_refs(page, 0);
//释放单个页
__free_page(page);
else
i+=BITS_PER_LONG;
page += BITS_PER_LONG;
//释放内存分配位图本身
page = virt_to_page(bdata->node_bootmem_map);
for (i = 0; i < ((bdata->node_low_pfn-(bdata->node_boot_start >> PAGE_SHIFT))/8 + PAGE_SIZE-1)/PAGE_SIZE; i++,page++)
__ClearPageReserved(page);
set_page_count(page, 1);
__free_page(page);1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.
⑶伙伴算法系统分配空间
复制
page = __rmqueue(zone, order);
//从所请求的order开始,扫描每个可用块链表进行循环搜索。
for (current_order = order; current_order < MAX_ORDER; ++current_order)
area = zone->free_area + current_order;
if (list_empty(&area->free_list))
continue;
page = list_entry(area->free_list.next, struct page, lru);
//首先在空闲块链表中删除第一个页框描述符。
list_del(&page->lru);
//清楚第一个页框描述符的private字段,该字段表示连续页框属于哪一个大小的链表
rmv_page_order(page);
area->nr_free--;
zone->free_pages -= 1UL << order;
//如果是从更大的order链表中申请的,则剩下的要重新插入到链表中
return expand(zone, page, order, current_order, area);
unsigned long size = 1 << high;
while (high > low)
area--;
high--;
size >>= 1;
//该部分连续页面插入到对应的free_list中
list_add(&page[size].lru, &area->free_list);
area->nr_free++;
//设置该部分连续页面的order
set_page_order(&page[size], high);
page->private = order;
__SetPagePrivate(page);
__set_bit(PG_private, &(page)->flags)
return page;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.
⑷伙伴算法系统回收空间
复制
free_pages_bulk
//linux内核将空间分为三个区,分别是ZONE_DMA、ZONE_NORMAL、ZONR_HIGH,zone_mem_map字段就是指向该区域第一个页描述符
struct page *base = zone->zone_mem_map;
while (!list_empty(list) && count--)
page = list_entry(list->prev, struct page, lru);
list_del(&page->lru);
__free_pages_bulk
int order_size = 1 << order;
//该段空间的第一个页的下标
page_idx = page - base;
zone->free_pages += order_size;
//最多循环10 - order次。每次都将一个块和它的伙伴进行合并。
while (order < MAX_ORDER-1)
//寻找伙伴,如果page_idx=128,order=4,则buddy_idx=144
buddy_idx = (page_idx ^ (1 << order));
buddy = base + buddy_idx;
/**
* 判断伙伴块是否是大小为order的空闲页框的第一个页。
* 首先,伙伴的第一个页必须是空闲的(_count == -1)
* 同时,必须属于动态内存(PG_reserved被清0,PG_reserved为1表示留给内核或者没有使用)
* 最后,其private字段必须是order
*/
if (!page_is_buddy(buddy, order))
break;
list_del(&buddy->lru);
area = zone->free_area + order;
//原先所在的区域空闲页减少
area->nr_free--;
rmv_page_order(buddy);
__ClearPagePrivate(page);
page->private = 0;
page_idx &= buddy_idx;
order++;
/**
* 伙伴不能与当前块合并。
* 将块插入适当的链表,并以块大小的order更新第一个页框的private字段。
*/
coalesced = base + page_idx;
set_page_order(coalesced, order);
list_add(&coalesced->lru, &zone->free_area[order].free_list);
zone->free_area[order].nr_free++;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.
4.3分配过程
现内存总容量为16KB,用户请求分配4KB大小的内存空间,且规定最小的内存分配单元是2KB。于是位图分为8个区域,用1表示已分配,用0表示未分配,则初始位图和空闲链表如图所示。从上到下依次是位图、内存块、空闲链表。
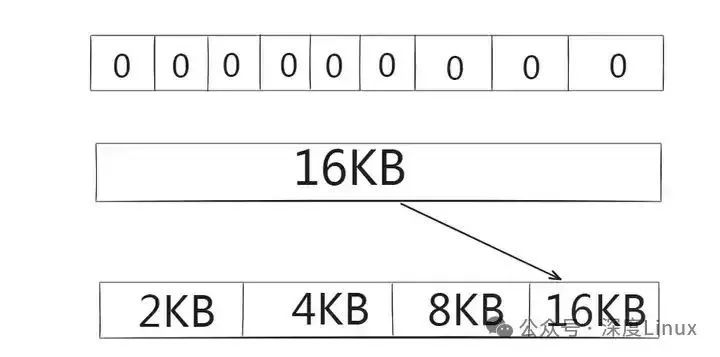 图片
图片
由于需要分配4KB内存,数显到链表中4KB位置进行查看,发现为空,于是继续向后查找8KB位置,发现仍为空,直到到达链表尾16KB位置不为空。16KB块分裂成两个8KB的块,其中一块插入到链表相应位置,另一块继续分裂成两个4KB的块,其中一个交付使用,另一个插入到链表中,结果如下图所示:
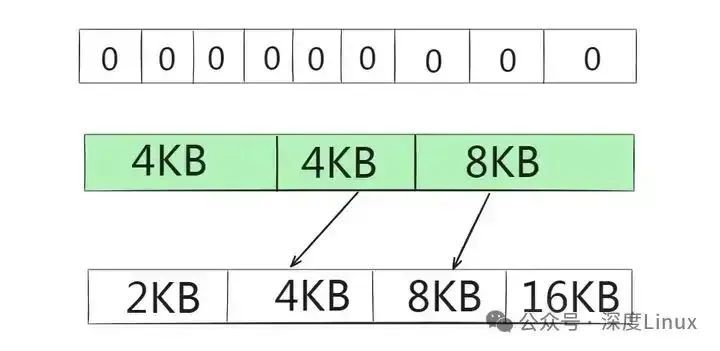 图片
图片
内存回收是内存分配的逆过程,假设以上存储要释放4KB内存,首先到链表中4KB位置查看是否有它的“伙伴”,发现该位置不为空,于是合并成一个8KB的块,继续寻找它的“伙伴”,然后合并成一个16KB的块,插入链表中。若在查找过程中没有发现“伙伴”,则直接插入到链表中,然后将位图中的标记清零,表示内存可用。
当程序请求内存时,Linux 内核内存伙伴算法会按照以下步骤进行分配:
首先从空闲的内存中搜索比申请的内存大的最小的内存块。例如,如果程序请求一个大小为特定值(假设为 N)的内存块,伙伴算法会先在与 N 大小相同的块链表中查找空闲块。如果没有找到合适的块,就会去更大的块链表中继续查找。
如果这样的内存块存在,则将这块内存标记为 “已用”,同时将该内存分配给应用程序。比如,假设程序请求的内存大小处于某个特定范围(比如 129 - 256 个页框),算法会先在 256 个页框的链表中检查是否有空闲块。若存在这样的块,就可以直接分配给程序使用。
如果这样的内存不存在,则操作系统将寻找更大块的空闲内存,然后将这块内存平分成两部分,一部分返回给程序使用,另一部分作为空闲的内存块等待下一次被分配。例如,若在特定大小的链表中(如 256 个页框的链表)没有找到空闲块,算法会查找下一个更大的页块,如在 512 个页框的链表中找一个空闲块。如果存在这样的块,内核就把 512 的页框分成两等分,一半用作满足需求,另一半则插入到 256 个页框的链表中。如果在 512 个页框的块链表中也没找到空闲块,就继续找更大的块,如 1024 个页框的块。如果这样的块存在,内核就把 1024 个页框块的一部分(满足程序需求的大小)用作请求,然后将剩余部分按照大小插入到相应的链表中等待后续分配。
4.4释放过程
当程序释放内存时,Linux 内核内存伙伴算法会执行以下操作:
操作系统首先将该内存回收,然后检查与该内存相邻的内存是否是同样大小并且同样处于空闲的状态。例如,当释放一个特定大小的内存块(假设为 256 个页框的块)时,算法就把其插入到 256 个页框的链表中,然后检查与该内存相邻的内存。
如果是,则将这两块内存合并,然后程序递归进行同样的检查,试图合并更大的块。如果存在同样大小为 256 个页框的并且空闲的内存,就将这两块内存合并成 512 个页框,然后插入到 512 个页框的链表中。如果合并后的 512 个页框的内存存在大小为 512 个页框的相邻且空闲的内存,则将两者合并,然后插入到 1024 个页框的链表中。如果不存在合适的伙伴块,就直接把要释放的块挂入链表头等待后续可能的合并操作。
五、CMA算法
在应用程序中,我们申请的内存从虚拟地址角度看是连续的,因为虚拟地址本身具有连续性。但在实际的物理内存空间中,所申请的这片内存未必是连续的。不过对于有内存管理单元(MMU)的系统来说,这并不会影响应用程序的正常运行,因为 MMU 可以将物理地址映射成虚拟地址,应用程序无需关心实际的内存情况。
但如果是没有 MMU 的情况呢?当设备需要通过 DMA 直接访问内存时,就迫切需要一片连续的内存空间,而 CMA 机制正是为了解决这一棘手问题而诞生的。DMA zone 区域并非 DMA 设备专属,其他程序也可以申请该区域的内存。当设备要申请 DMA zone 空间中的一大片连续内存时,如果此时已经没有连续的大片内存,只有 1 页、2 页、4 页等连续的小内存,CMA 机制就会发挥作用。
系统会事先标记某一片连续区域为 CMA 区域,在没有大片连续内存申请时,这片区域只给可移动(moveable)的程序使用。当有大片连续内存请求到来时,系统会前往这片 CMA 区域,将所有可移动的小片内存移动到其它的非 CMA 区域,并更改对应的程序页表,然后把空出来的 CMA 区域分配给设备,从而完美实现了 DMA 大片连续内存的分配。CMA 机制并非孤立存在,它通常是为 DMA 设备服务的。当设备调用dma_alloc_coherent函数申请内存后,为了确保得到一片连续的内存,CMA 机制就会被触发调用,以保证申请内存的连续性。此外,CMA 区域通常被分配在高端内存,以满足特定的内存需求场景 。
六、slab算法
当在驱动程序中,遇到反复分配、释放同一大小的内存块时(例如,inode、task_struct等),建议使用内存池技术(对象在前后两次被使用时均分配在同一块内存或同一类内存空间,且保留了基本的数据结构,这大大提高了效率)。在linux中,有一个叫做slab分配器的内存池管理技术,内存池使用的内存区叫做后备高速缓存。
salb相关头文件在linux/slab.h中,在使用后备高速缓存前,需要创建一个kmem_cache的结构体。
6.1创建slab缓存区
该函数创建一个slab缓存(后备高速缓冲区),它是一个可以驻留任意数目全部同样大小的后备缓存。其原型如下:
复制
struct kmem_cache *kmem_cache_create(const char *name, size_t size, \
size_t align, unsigned long flags,\
void (*ctor)(void *, struct kmem_cache *, unsigned long),\
void (*dtor)(void *, struct kmem_cache *, unsigned ong)));1.2.3.4.
其中:
name:创建的缓存名;size:可容纳的缓存块个数;align:后备高速缓冲区中第一个内存块的偏移量(一般置为0);flags:控制如何进行分配的位掩码,包括 SLAB_NO_REAP(即使内存紧缺也不自动收缩这块缓存)、SLAB_HWCACHE_ALIGN ( 每 个 数 据 对 象 被 对 齐 到 一 个 缓 存 行 )、SLAB_CACHE_DMA(要求数据对象在 DMA 内存区分配)等);ctor:是可选的内存块对象构造函数(初始化函数);dtor:是可选的内存对象块析构函数(释放函数)。
6.2分配slab缓存函数
一旦创建完后备高速缓冲区后,就可以调用kmem_cache_alloc()在缓存区分配一个内存块对象了,其原型如下:
复制
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags);1.
cachep指向开始分配的后备高速缓存,flags与传给kmalloc函数的参数相同,一般为GFP_KERNEL。
6.3释放slab缓存
该函数释放一个内存块对象:
复制
void *kmem_cache_free(struct kmem_cache *cachep, void *objp);1.
6.4销毁slab缓存
与kmem_cache_create对应的是销毁函数,释放一个后备高速缓存:
复制
int kmem_cache_destroy(struct kmem_cache *cachep);1.
它必须等待所有已经分配的内存块对象被释放后才能释放后备高速缓存区。
6.5slab缓存使用举例
创建一个存放线程结构体(struct thread_info)的后备高速缓存,因为在linux中涉及频繁的线程创建与释放,如果使用__get_free_page()函数会造成内存的大量浪费,效率也不高。所以在linux内核的初始化阶段就创建了一个名为thread_info的后备高速缓存,代码如下:
复制
/* 创建slab缓存 */
static struct kmem_cache *thread_info_cache;
thread_info_cache = kmem_cache_create("thread_info", sizeof(struct thread_info), \
SLAB_HWCACHE_ALIGN|SLAB_PANIC, NULL, NULL);
/* 分配slab缓存 */
struct thread_info *ti;
ti = kmem_cache_alloc(thread_info_cache, GFP_KERNEL);
/* 使用slab缓存 */
...
/* 释放slab缓存 */
kmem_cache_free(thread_info_cache, ti);
kmem_cache_destroy(thread_info_cache);1.2.3.4.5.6.7.8.9.10.11.12.13.14.
七、内存池
在 Linux 内核中还包含对内存池的支持,内存池技术也是一种非常经典的用于分配大量小对象的后备缓存技术。
7.1创建内存池
复制
mempool_t *mempool_create(int min_nr, mempool_alloc_t *alloc_fn, \
mempool_free_t *free_fn, void *pool_data);1.2.
mempool_create()函数用于创建一个内存池,min_nr 参数是需要预分配对象的数目,alloc_fn 和 free_fn 是指向内存池机制提供的标准对象分配和回收函数的指针,其原型分别为:
复制
typedef void *(mempool_alloc_t)(int gfp_mask, void *pool_data);
typedef void (mempool_free_t)(void *element, void *pool_data);1.2.
pool_data 是分配和回收函数用到的指针,gfp_mask 是分配标记。只有当_ _GFP_WAIT 标记被指定时,分配函数才会休眠。
7.2分配和回收对象
在内存池中分配和回收对象需由以下函数来完成:
复制
void *mempool_alloc(mempool_t *pool, int gfp_mask);
void mempool_free(void *element, mempool_t *pool);1.2.
mempool_alloc()用来分配对象,如果内存池分配器无法提供内存,那么就可以用预分配的池。
7.3销毁内存池
复制
void mempool_destroy(mempool_t *pool);1.
mempool_create()函数创建的内存池需由 mempool_destroy()来回收。
八、应用案例分析
8.1实际场景中的应用
在服务器运维领域,内存分配方式的选择对系统性能有着显著影响。以运行数据库服务的服务器为例,数据库系统需要频繁地读写数据,对内存的需求十分庞大且复杂。在这种场景下,Buddy 算法就发挥着重要作用,它能够为数据库分配连续的大块内存,确保数据的快速存储和读取。同时,slab 算法也不可或缺,数据库中存在许多频繁使用的小数据结构,如数据库连接池中的连接对象、缓存中的数据块描述符等,slab 算法能够高效地管理这些小内存块的分配和回收,大大提高了数据库系统的运行效率。
在嵌入式开发场景中,CMA 算法的应用则尤为关键。比如在开发一款基于 Linux 系统的智能摄像头设备时,摄像头需要通过 DMA 将拍摄的图像数据快速传输到内存中进行处理。由于图像数据量较大,需要连续的内存空间来保证数据传输的稳定性和高效性。此时,CMA 算法就可以提前预留出一片连续的内存区域作为 CMA 区域,当摄像头设备需要申请内存时,系统能够及时从 CMA 区域中分配出连续的内存,满足摄像头对 DMA 连续内存的需求,确保图像数据的正常传输和处理,为智能摄像头的稳定运行提供了有力保障 。
8.2遇到的问题及解决办法
在实际使用过程中,内存分配可能会引发各种问题。例如,在一个长时间运行的服务器应用中,由于频繁地进行内存分配和释放操作,可能会导致内存碎片过多。当内存碎片达到一定程度时,即使系统中存在足够的空闲内存,也可能无法分配出连续的大块内存,从而导致某些需要大块连续内存的操作失败,如数据库的大规模数据加载。为了解决这个问题,可以采用内存整理工具,如defragment命令(需 root 权限运行),对内存进行碎片整理,使内存空间变得更加连续,提高内存的利用率 。
再比如,在嵌入式设备开发中,可能会遇到内存分配失败的情况。这可能是由于设备内存资源有限,而应用程序对内存的需求过大导致的。当这种情况发生时,可以通过优化应用程序的内存使用方式来解决。例如,采用内存池技术,预先分配一块连续的内存空间,在需要时从内存池中分配内存,避免频繁地进行系统级的内存分配和释放操作,从而减少内存碎片的产生,提高内存分配的成功率。同时,合理调整应用程序的功能和数据结构,减少不必要的内存占用,也是解决内存分配失败问题的有效途径 。
8.3教你如何查看内存分配情况
了解了 Linux 内存的常见分配方式后,学会如何查看内存分配情况也是非常重要的,这有助于我们实时监控系统内存的使用状态,及时发现潜在的问题 。
在 Linux 系统中,我们可以通过/proc/buddyinfo文件来查看 Buddy 算法的内存分配情况。这个文件详细记录了每个内存节点和区域中不同阶的空闲内存块数量 。例如,在一个单节点系统中,/proc/buddyinfo文件的内容可能如下:
复制
Node 0, zone DMA1 2 1 0 1 0 1 0 1 0 1
Node 0, zone DMA32100 200 150 80 40 20 10 5 2 1 0
Node 0, zone Normal500 400 300 200 100 50 20 10 5 2 11.2.3.
从这些数据中,我们可以清晰地看到不同区域(如 DMA、DMA32、Normal)中不同大小内存块(从 order0 到 order10,对应不同的 2 的幂次方大小)的可用数量。通过分析这些数据,我们可以判断系统内存的碎片化程度。如果高阶块(如 order10)的可用块较少,可能表明内存碎片化严重,难以分配到大块连续内存;如果低阶块(如 order0 或 order1)的可用块较少,则可能表示系统内存紧张 。
对于 slab 算法的内存分配情况,我们可以使用cat /proc/slabinfo命令来查看。执行该命令后,会输出一系列的信息,每一行代表一个 slab 缓存 。例如:
复制
slabinfo - version: 2.1
# name <active_objs> <num_objs> <objsize> <objperslab> <pagesperslab> : tunables <limit> <batchcount> <sharedfactor> : slabdata <active_slabs> <num_slabs> <sharedavail>
kmalloc-16 9284 9284 16 256 1 : tunables 0 0 0 : slabdata 36 36 0
kmalloc-32 4567 4567 32 128 1 : tunables 0 0 0 : slabdata 36 36 01.2.3.4.
在这些输出信息中,active_objs表示当前活跃的对象数量,num_objs表示对象总数,objsize表示每个对象的大小,objperslab表示每个 slab 中包含的对象数量,pagesperslab表示每个 slab 占用的页数。通过这些数据,我们可以了解到各个 slab 缓存的使用情况,判断是否存在内存分配不合理的情况 。比如,如果某个 slab 缓存中active_objs数量长期很高,而num_objs与active_objs相差不大,可能说明该 slab 缓存中的对象频繁被使用,需要进一步优化内存分配策略 。
除了上述方法外,我们还可以使用free命令查看系统的物理内存和交换空间使用情况,包括空闲和已用内存的数量、缓冲区和缓存的大小等信息。运行free -h可以以易于阅读的方式显示结果 。top命令也是一个实时监测系统资源的工具,它可以显示当前系统的进程、CPU、内存、磁盘等使用情况,在top的输出中,我们能够查看内存使用情况的相关信息,包括总内存、已用内存、空闲内存等 。
htop命令是一个增强版的top命令,提供了更多的交互式功能和可视化显示,允许我们查看进程的内存使用情况,以及各个进程所占用的内存大小 。这些工具和命令相互配合,能够帮助我们全面、深入地了解 Linux 系统的内存分配情况,为系统的优化和管理提供有力的支持 。