一条 INSERT 背后的秘密:揭开 InnoDB 记录结构的神秘面纱
你以为你写了一条 SQL,其实你是在和数据库的一整套存储机制打交道。
一、引言:懂记录结构,真的很重要!
开篇三连击:
当你敲下INSERT时,数据是在磁盘「盖房子」还是「搭积木」?行格式里藏着哪些「加密代码」?一条“莫名其妙”的慢查询,根源可能是行格式选错?这些问题的答案,就藏在 InnoDB 的记录结构里。
我们在写 SQL 的时候,经常只关注“写对了没”、“跑起来没报错”。但真正理解 MySQL 的底层行为,往往要从一句简单的 INSERT 开始。
二、从一条INSERT语句开始说起
当我们执行INSERT INTO users (name, age,address) VALUES (张三, 25,北京.海淀);这条语句时,数据并不会直接 “一股脑” 地塞进磁盘。InnoDB 会按照特定的规则,将数据 “搭建” 成特定的结构,然后再存储到磁盘上。
为了更好地理解这个过程,我们先来对比一下行数据以及行结构。
假设我们有一张users表,包含id、name、age、address四个字段。
当我们插入一条数据(1, 张三, 25,北京.海淀)时,从表面上看,我们看到的行数据是这样的:
id
name
age
address
1
张三
25
北京海淀
然而在 InnoDB 中,一条数据并非简单存储,而是拆分成多个部分:记录头信息保存元数据,变长字段列表记录变长字段及长度,NULL 值列表标记哪些字段为 NULL。
InnoDB目前支持四种行格式:
COMPACT(最常用)REDUNDANT(MySQL 5.0之前)DYNAMIC(MySQL 5.7默认)COMPRESSED(压缩格式)COMPACT 行格式是最常用的“标准模板”,掌握它能帮助你理解 InnoDB 记录结构的核心。
三、COMPACT 行格式详细介绍:数据存储的 “标准模板”
废话不多说,直接看图:

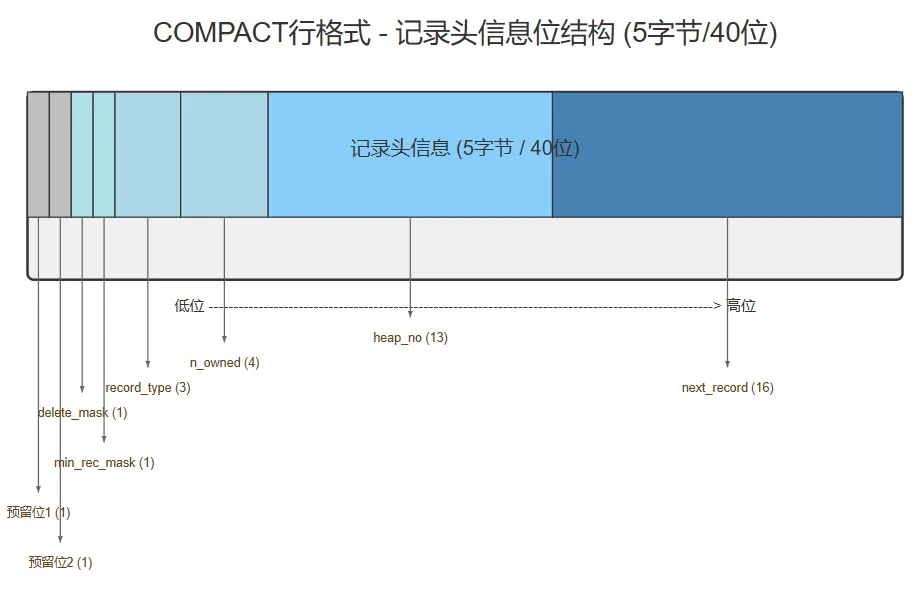
记录头信息仅占5字节,却包含记录类型、删除标记、B+树位置等关键信息,是记录的重要标识。
当我们执行DELETE语句删除一条记录时,InnoDB 并不会立即从磁盘上删除这条记录,而是在记录头信息中设置删除标记,后续再通过专门的机制进行清理。
字段 (Field)
位数 (Bits)
描述 (Description)
预留位1
1
保留位,目前没有用到。
预留位2
1
保留位,目前没有用到。
delete_mask
1
标记该记录是否被删除,1-是,0-否
min_rec_mask
1
标记该记录是否是B+树叶子节点中最小的记录,1-是,0-否
record_type
3
标记记录的类型。000表示普通记录,001表示最小值记录,010表示目录记录,011表示最大值记录。
n_owned
4
表示当前记录拥有的记录数
heap_no
13
标记当前记录在当前页面(Page)中的相对位置(槽号)。
next_record
16
表示下一条记录的相对位置
预留位2
1
保留位,目前没有用到。
2. 变长字段列表:应对 “变化多端” 的数据在实际应用中,很多字段的数据长度是不固定的,比如VARCHAR、TEXT、BLOB等类型的字段。变长字段列表就是为了应对这些 “变化多端” 的数据而设计的。它会记录哪些字段是变长的,以及它们的长度。
变长字段列表采用倒排的方式存储,也就是说,它从右往左存储每个变长字段的长度。
(1) 变长字段列表如何存储实际数据?
当执行插入语句INSERT INTO users VALUES(1, 张三, 25, 北京.海淀);时,我们来分析一下变长字段列表的存储方式。
① 字段分析
id:INT 类型,固定长度 4 字节,不属于变长字段name:VARCHAR (100),实际存储 张三 ,UTF-8 编码下每个汉字占 3 字节,共 6 字节age:INT 类型,固定长度 4 字节,不属于变长字段address:VARCHAR (255),实际存储 北京.海淀 ,共包含 5 个字符(2 个汉字、1 个点、2 个汉字),每个汉字 3 字节,点 1 字节,共 13 字节② 变长字段列表的倒排存储
上面的例子中,有两个变长字段:name和address。它们的长度分别是 6 字节和 13 字节。根据倒排存储规则,变长字段列表会按照从右到左的顺序记录这些长度。
表定义顺序是:name, address倒排后,存的时候顺序是:address, name因此,变长字段列表的内容为:[13,6]。

这些值并不是直接以十进制存入,而是编码成 1~2 字节的二进制形式(依字段长度大小决定)。
3. NULL 值列表:节省空间的 “小能手”在 InnoDB 中,NULL 值列表是一种节省空间的巧妙设计。它不存储 NULL 的实际值,而是用每个字段对应的一位二进制位来标记:
1 表示该字段为 NULL;0 表示不为 NULL。在计算 InnoDB 记录结构中的 NULL 值列表时,只有那些“允许为 NULL”的字段才会被纳入统计。
以 users 表为例:
id 是主键,不能为 NULL;name 被 NOT NULL 明确声明,也不能为 NULL;age 和 address 没有限定 NOT NULL,默认是可以为 NULL 的。所以,NULL 值列表中只包含 age 和 address 这两个字段的状态位。

NULL 值列表的位顺序,是按照表结构中允许 NULL 字段的出现顺序排列的,且仅包含这些字段。
四、行溢出:当数据太大时会发生什么?
1. 为什么会出现行溢出?InnoDB 的数据存储以 “页” 为基本单位,每页默认大小为 16KB。当我们插入的数据(如一篇几万字的文章、高清图片的二进制数据)长度超过一页能容纳的空间时,InnoDB 就会遇到 “空间不够用” 的难题。就像你想把 100 本书塞进只能装 50 本书的箱子,自然装不下。
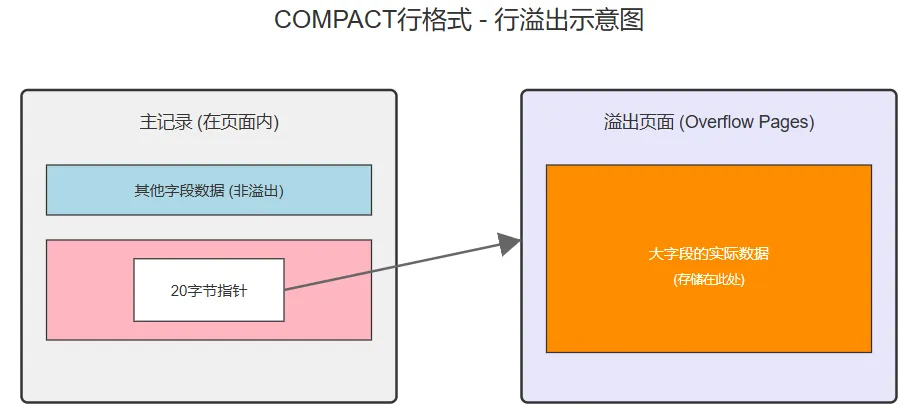
2. 什么是行溢出?为了解决上述问题,InnoDB 引入了行溢出机制:
当数据过长时,它会把超出数据页容量的部分 “搬” 到额外的溢出页中存储;并在原数据页保留一个指向溢出页的指针(通常是20字节)。这就好比把装不下的书先放在旁边的临时箱子,再在原本的箱子贴上标签注明 “其余书在隔壁箱”。
行溢出虽解决大字段存储,但带来性能隐患,如查询慢、空间管理复杂、碎片增多。优化可从多方面入手:拆大字段表、选适配数据类型与行格式,控制字段长度,同时避免在大字段建索引,以此提升数据库性能。
五、结语:深入底层,才能掌控全局
数据库的 “高性能密码” 藏在底层结构里。从 INSERT 语句到磁盘存储,COMPACT 行格式的字段管理、行溢出的优化逻辑,都是提升数据库能力的关键。懂记录结构,才能在面试中从容应答,在优化时直击痛点。
记住:深挖底层原理,才能让技术成长 “知其所以然”。欢迎留言交流,一起解锁更多数据库奥秘!