面试官:什么是回表,什么是索引下推?
大家好,我是君哥。
使用 MySQL 时,我们经常会听到“回表”、“索引下推”这样的概念,今天就来聊一聊什么是回表,什么是索引下推。
一、回表
1.1 概念
我们看下面这个 SQL:
我们创建一个 test_temp 表,主键是 id,给字段 b 加了一个索引。插入 4 条数据,SQL 如下:
test_temp 表会构建 2 个索引,一个是主键索引,一个是字段 b 的普通索引。
一般主键索引被称为聚集索引,普通索引被称为非聚集索引。
我们执行下面查询 SQL:
这个 SQL 语句的查询过程如下图:
 图片
图片
1.从索引 b 上查询 10,查到主键 id 的值是 400,再用 400 这个 id 去主键索引上取出 row4;
2.从索引 b 上查询 20,没有查到记录,继续下一条;
3.从索引 b 上查询 30,查到主键 id 的值是 300,再用 300 这个 id 去主键索引上取出 row3;
4.从索引 b 上查询 40,查到主键 id 的值是 200,再用 200 这个 id 去主键索引上取出 row2;
5.给客户端返回结果集。
上面 1、3、5 回到主键索引搜索数据的过程,就叫回表。上面查询回表 3 次。
1.2 缺点
回表有什么问题吗?回表次数多了,可能会严重影响查询效率。
1.导致磁盘 I/O 增加:每次回表读取数据行,这些数据分散在磁盘各个地方,导致大量的磁盘 I/O。
2.导致缓存失效:回表的数据如果不在缓存行中,就需要从磁盘加载,新的数据可能会覆盖已有的缓存,影响其他查询。
1.3 措施
那有什么方法可以避免回表吗?下面两个方法可以避免:
1.覆盖索引上面的查询中,如果 SQL 改成:
这样就不用回表查询了。如果需要查询 b、a 两个字段,可以创建 b、a 的覆盖索引,这样就可以从 b、a 这个覆盖索引上查询出结果。
2.只查询必要字段
修改查询范围,不用的字段不查询。如果查询的字段不多,可以把查询语句改成只查联合索引包含的字段。如果查询频率高,又没有覆盖索引,可以加一个包含查询字段的联合索引。
二、索引下推
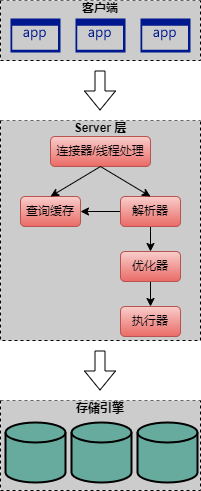
首先回顾一下 MySQL 的逻辑架构:
 图片
图片
Server 层是 MySQL 的核心服务层,这一次包括查询解析、分析、优化、缓存、以及所有内置函数(例如,日期、时间、数学和加密函数),所有跨存储引擎的功能都在这一层实现,包括:存储过程、触发器、视图等。
存储引擎层负责 MySQL 中数据的存储和提取。
首先,我们创建一张表:
插入一批数据:
这时我们看一下下面这条 SQL 的执行计划:
我们看一下执行计划:
 图片
图片
上图中的 Using index condition 就是使用了索引下推。
如果不使用索引下推,比如只对 a 这个字段加了索引,那就会对 a 这个字段筛选出来的 id,依次做回表查询,查到结果后再对 b 字段进行过滤。
而使用了索引下推,SQL 执行过程如下:
1.Server 层向存储引擎查询数据;
2.存储引擎根据 a_b 联合索引首先找到所有 a > 10 的数据,根据联合索引中已经存在的 b 字段对数据做过滤,找出符合条件 b < 50 的数据;
3.存储引擎根据 a_b 联合索引找到所有符合条件的数据后,回表查询,给 Server 层返回结果集。
可以看到,索引下推最大的优势就是在存储引擎层,利用联合索引的优势对查询条件进行了过滤,这样可以减少回表查询次数,从而大大减少 I/O 次数,提升查询性能。
索引下推是在 MySQL 5.6 版本中才引入的,MySQL 5.6 以前版本没有这个功能。
当然使用索引下推也有一定限制:
1.索引下推主要适用于 eq_ref、range、ref、ref_or_null 这几个场景;
2.InnoDB 和 MyISAM 存储引擎都支持索引下推,MySQL 分区表也支持;
3.对 InnoDB 存储引擎来说,索引下推只适用于二级索引,主键索引(聚集索引)不支持,因为主键索引存储了数据,不存在回表这一说;
4.语句中子查询的条件不支持索引下推;
5.使用了存储函数的 SQL,存储函数中的条件不支持索引下推,因为存储引擎无法调用存储函数。
我们再看下面这个查询语句(把条件 b 改成条件 c):
这个语句其实并不能使用联合索引第二个字段在存储引擎层做过滤,还是需要对每一条索引 a_b 上查询到的 id 做回表查询,但是执行计划里面却有索引下推,这也是需要注意的一点。
 图片
图片
总结
本文介绍了 MySQL 的回表和索引下推,这两个概念在 MySQL 中非常重要,希望对你的学习和面试有所帮助。