MySQL 基础知识点小结
本文针对MySQL一些常见比较重要的知识点进行了详细的总结,希望对你有帮助。

参考笔者这篇文章进行了详细的总结:《深入剖析 MySQL 某条执行过程》
MySQL支持的存储引擎有哪些通过下面show engines;这段命令即查看MySQL默认的存储引擎。对应的查询结果如下图所示,可以看到MySQL默认采用InnoDB作为存储引擎。而且InnoDB是MySQL中唯一一个支持事务性存储的存储引擎。

同时MySQL早期用的存储引擎就是MyISAM ,然后变成InnoDB,因为MySQL采用的是插件时存储引擎,所以存储引擎是可以任意切换的,
注意:存储引擎配置所针对的维度是针对表的,而不是针对某张数据库的,如下建表语句,我们就将存储引擎设置为innodb :
MyISAM的特点:
它在性能方面表现出色,例如全文索引、压缩、空间函数等都没问题。只支持表级锁。不支持事务。不支持故障后安全恢复。因为不支持行级锁,所以就不支持MVCC。MyISAM存储引擎数据和索引文件是分开。不支持外键。InnoDB的特点:
支持行级锁。因为行级锁,所以支持MVCC,通过MVCC保证了repeat read(可重复读)的效率,并通过间隙锁防止幻行插入所导致的幻读的问题。支持事务,所以并发读写的情况下性能优异。同时支持故障后安全恢复(依赖redolog),也支持外键,但是一般情况下我们不太建议开发数据表使用外键。特定情况下的索引和数据都在同一个文件上,也就是我们常说的聚簇索引,通过聚簇索引可以保证高效快速的主键查询,因为二级索引包含主键列,所以但如果主键占用物理空间过大的话,二级索引占用的空间也会很大,所以如果存在多个索引的情况下,建议适当调小主键索引的大小。
什么是多版本并发控制(MVCC)可以参考笔者这篇关于mvcc的讲解,解释的比较全面:《详解 undoLog 在 MySQL 多版本并发控制 MVCC 中的运用》
如何选择MyISAM和InnoDB大部分情况下都建议使用InnoDB,很多人认为MyISAM性能要好于InnoDB,事实并非如此,在《高性能MySQL》中提及过:
不要轻易相信“MyISAM 比 InnoDB 快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB 的速度都可以让 MyISAM 望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
现代应用软件系统大部分都是用于处理一些短期的事务,且大部分情况下是不需要回滚的,所以InnoDB是个不错的选择,况且InnoDB是可以通过redo.log完成数据崩溃后恢复,这一点是MyISAM所不具备的,这也就是为了MySQL8.0之后将InnoDB作为默认的存储引擎。
MySQL字段char和varchar 的区别我们先来说说varchar,varchar 常用于存储一些不定长的字段数据,它会通过1-2字节来记录字段长度,后续字节用于记录可变长字符串:
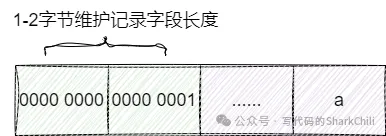
因为是可变长的缘故,所以在于字符串区间变化较大的场景下,相对于char它会更加节省存储空间,同样的缺点也很明显,如果涉及大量修改varchar字段导致原有空间无法容纳varchar时,就可能导致页分裂来容纳行。
所以varchar可能更适合字段长度不一定大量趋近于平均长度,且更新较少长度变化不大(不容易产生碎片)的场景。
而char则时定长的空间,如果字符长度不足则用结束符标记字符串结束,对于字符串较短或者长度几乎相同、修改较少的场景,使用char性能表现会比前者更出色一些,因为char长度固定,碎片较少,可以很少的利用局部性原理IO大量数据。
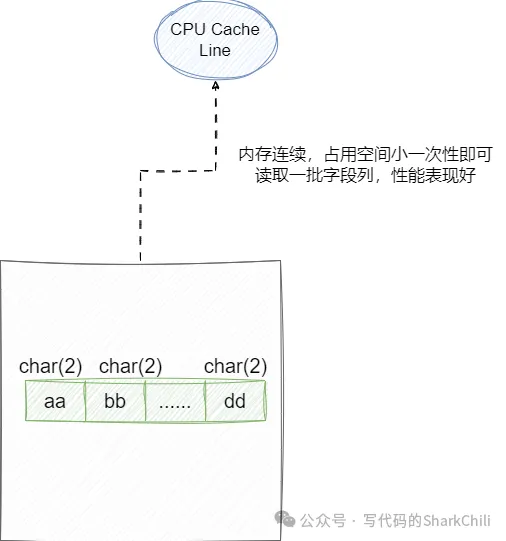
需要了解的是varchar(30) 代表存30个字符,其中中文占3字节,所以30个字符要占用90字节。英文是1字节。
我们可以键入下面sql,这里补充一下char_length获取的字符长度,有几个字符长度就是多少,length算的是字节数,查看可以看到length(哈哈)为6,length(hh)为2。
中文字符串长度的输出结果:
英文字符长度查询SQL:
英文字符长度输出结果:
通过修改my.cnf中加入下面这段配置即可:
我们需要根据不同的原因进行相应的处理:
数据量暴增:这就得多方面考虑了,为什么会暴增,暴增是否因为业务涉及不合理,我们是否可以从功能上进行优化,例如某些日志分表存储着一些过期的稽核数据,我们是否可以适当的将这些表空间数据释放,若实在无法进行空间释放,可以考虑服务进行磁盘扩容了。日志:日志导致容量暴增基本就bin log或者error日志没有及时清理了,这种情况我们只能删除一些binlog即可了。临时文件:数据库某些查询结果都会放在内存的,当内存空间不足时就会为查询结果生成一个临时文件(例如对并发场景下各种大表进行select * from table),就很可能产生大量临时文件,进而出现CPU爆满和IO次数激增。针对临时文件爆满问题,对应的解决方式也很简单,首先找到临时文件的位置:
然后到达对应的位置将临时文件内容置空:
注意:我们此时可能还需清除慢查询SQL,查看是否有time数据很大的慢查询
如果有则杀掉:
回答这个问题我们不妨做个实验,首先建立数据表:
然后键入以下SQL进行查询,可以看到前面两条不会忽略null值,最后count(列名)会忽略null值。
而性能在性能方面,很多人认为count(1)>count(*)>count(id)实际上前两者性能表现基本是一样的,按照《高性能MySQL》的说法:
通配符*并不会像我们所想的那样扩展成所有的列,实际上,它会忽略所有的列而返回统计的行数。
而count(1)传入的是常量,所以只做扫描行数,所以实际上性能表现为:count(1)≈count(*)>count(id)
如何定位慢查询SQL针对慢SQL问题,如果业务上可以感知我们直接通过接口定位就好了,但是针对界面不可见的后端调度任务,就必须进行实时监控了。 要想定位慢查询SQL首先自然是要开启慢查询日志,对应的我们可以在my.cnf/my.ini中增加如下配置
后续想要获取慢查询的日志信息,我们可以通过如下指令导出,亦或者通过通过监控工具导出告警:
而slow.log日志的内容,大体如下所示,对应字段含义分别是:
Query_time:查询耗时Lock_time:等待表锁的时间Rows_sent:返回给客户端的行数Rows_examined:扫描了 50万行 数据最后就是执行的SQL和时间:
优先考虑TIDB,这是一个具备关系型数据库和NOSQL数据库的优点,旨在提供高可用、强一致性的的分布式数据库,总的来说,它具备以下几个优点:
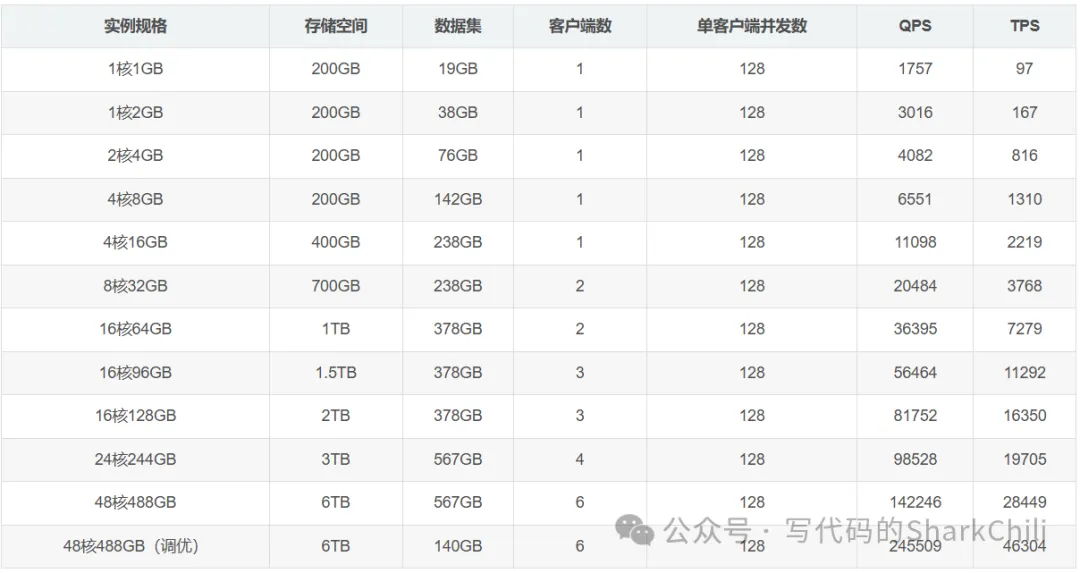
支持水平拓展,Tidb可以通过增加节点实现扩展,支持大规模数据存储和高并发访问。数据库会自行完成分片并存储在不同节点上,避免我们业务逻辑上的分表的实现的复杂度。TiDB支持ACID事务,确保数据一致性和完整性。它通过raft保证高可用和一致性。支持大多数MySQL的SQL语法。使用MySQL主从架构时,需要注意那些问题在进行分库分表时,我们必须结合硬件条件对应的MySQL压测结果针对业务需求评估资源,例如我们的业务需求要求QPS是10w,对应的数据库给定的服务器配置是4C8G,按照下图给出的压测报告,我们至少是需要30台(15台master和15台slave)数据库服务器保证高并发和高可用:
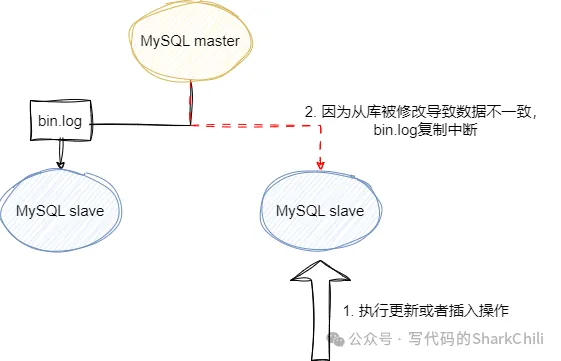
主从同步期间,要保证写操作都是在主库上,一旦写入操作不小心写入到从库,就会因为主从数据不一致导致bin.log同步复制数据中断。