实操指南:以无停机方式迁移SQL故障转移集群

译者 | 核子可乐
审校 | 重楼
运行在老旧硬件或操作系统上的SQL Server故障转移集群,往往很难以无宕机方式迁移至现代系统。我之前就面对过这类需求,将一个由HPE SAN支持的实时SQL集群迁移至Windows Server 2022新服务器,同时须保证依赖该集群的应用程序零中断正常运行。以下是我们在完成这项工作中的一点心得体会。
SQL宕机对许多企业来说已经成为严重阻碍。报告管线会报错、ERP系统会崩溃,即使是最简单的用户门户也有可能瘫痪。无法承受这种连锁反应,我们只能选择无缝迁移方案。
业务运行的巨大压力,要求我们最大限度降低高峰运营时段的停机风险。为此我们引入了额外的规划、沟通和回滚验证环节。
为何必须迁移
原因有以下几点:
原始节点已经使用五年,且超出保修期。我们的合规团队将操作系统版本(Windows Server 2019)标记为即将停止支持。我们希望借此调整配置决策,消除偶尔出现的故障转移延迟。这样的基础设施升级肯定不简单,特别是在涉及关键SQL工作负载的情况下。
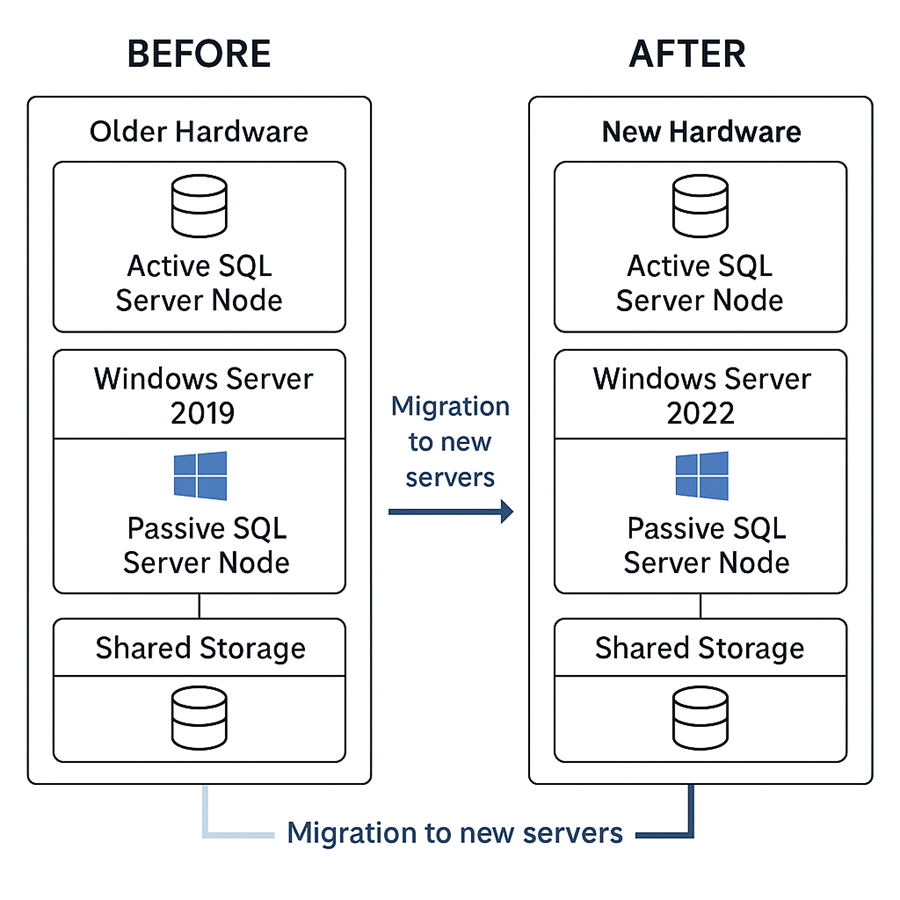
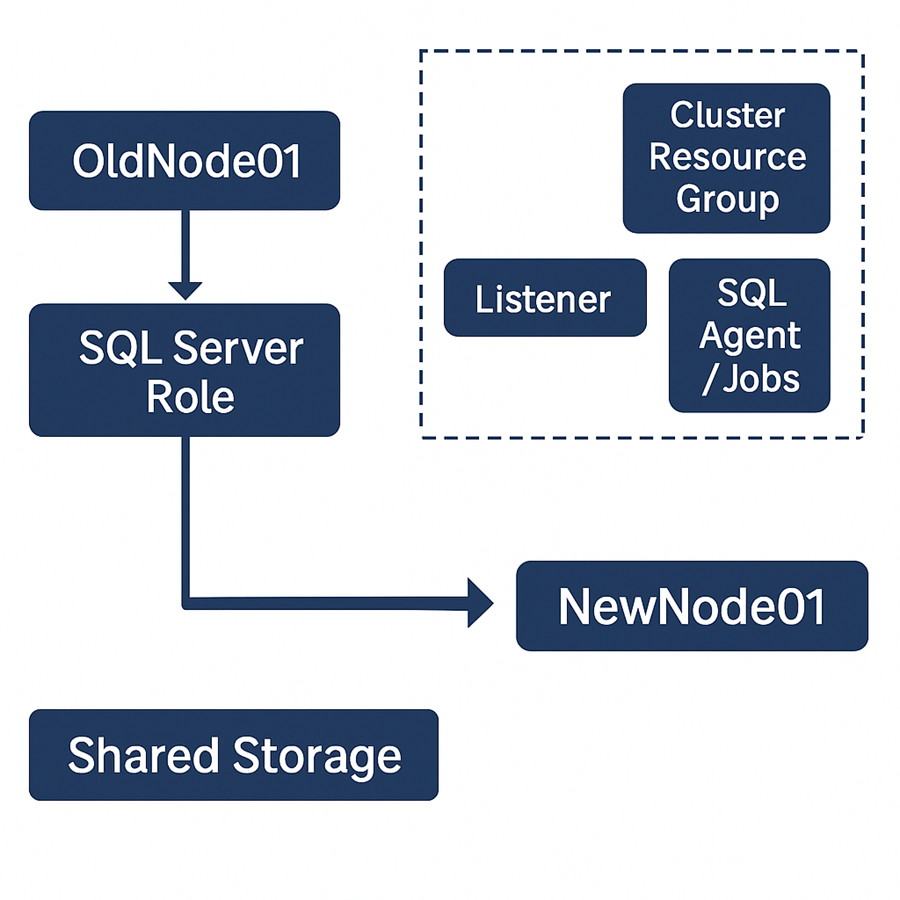
我们的设置(迁移前)
双节点主-被动SQL Server 2019集群。托管在Windows Server 2019系统上。后端:具有多路径I/O的HPE SAN。通过DNS设置集群监听器。.NET与报表工具会全天候访问集群。我们计划引入两个运行有Windows Server 2022的新节点,缓慢迁移所有内容,并在不中断服务的情况下停用旧节点。
我们还与网络和存储团队密切合作,在启动操作之前先行验证iSCSI配置与多路径稳定性。
我们的迁移计划
相较于直接迁移,我们决定:
将新服务器添加至现有集群。以“添加节点”模式在新服务器中安装SQL Server。将集群角色迁移至新节点。在完全验证后移除旧节点。这样,我们就能在迁移底层基础设施时,保证SQL实例、监听器名称与磁盘均保持不变。
我们的分步操作流程
1. 准备新服务器我们将新服务器添加至域内,对其进行全面修复,并认真检查了多路径驱动程序是否支持SAN访问。期间我们还差点忽略了一个重要细节:某个节点上的iSCSI启动器服务未设置为自动。这个小小的配置问题一旦爆发,很可能会耗费几小时的排查时间。
我们在故障转移集群管理器添加了两个新节点,PowerShell功能不受影响:
每次加入后,必须验证仲裁与见证设置。
在每个新节点上,我们使用SQL安装UI“将节点添加至现有故障转移集群”。我们对齐了现有实例名称与安装路径,以避免后续出现问题。这里提醒大家,安装程序在检查集群角色时可能会短暂挂起,耐心等待即可。
4. 转移SQL角色我们使用PowerShell完成了简洁切换:
我们密切关注CPU/内存及应用程序日志。切换过程很快完成——应用层大约挂起了30秒,但没有出现事务失败。
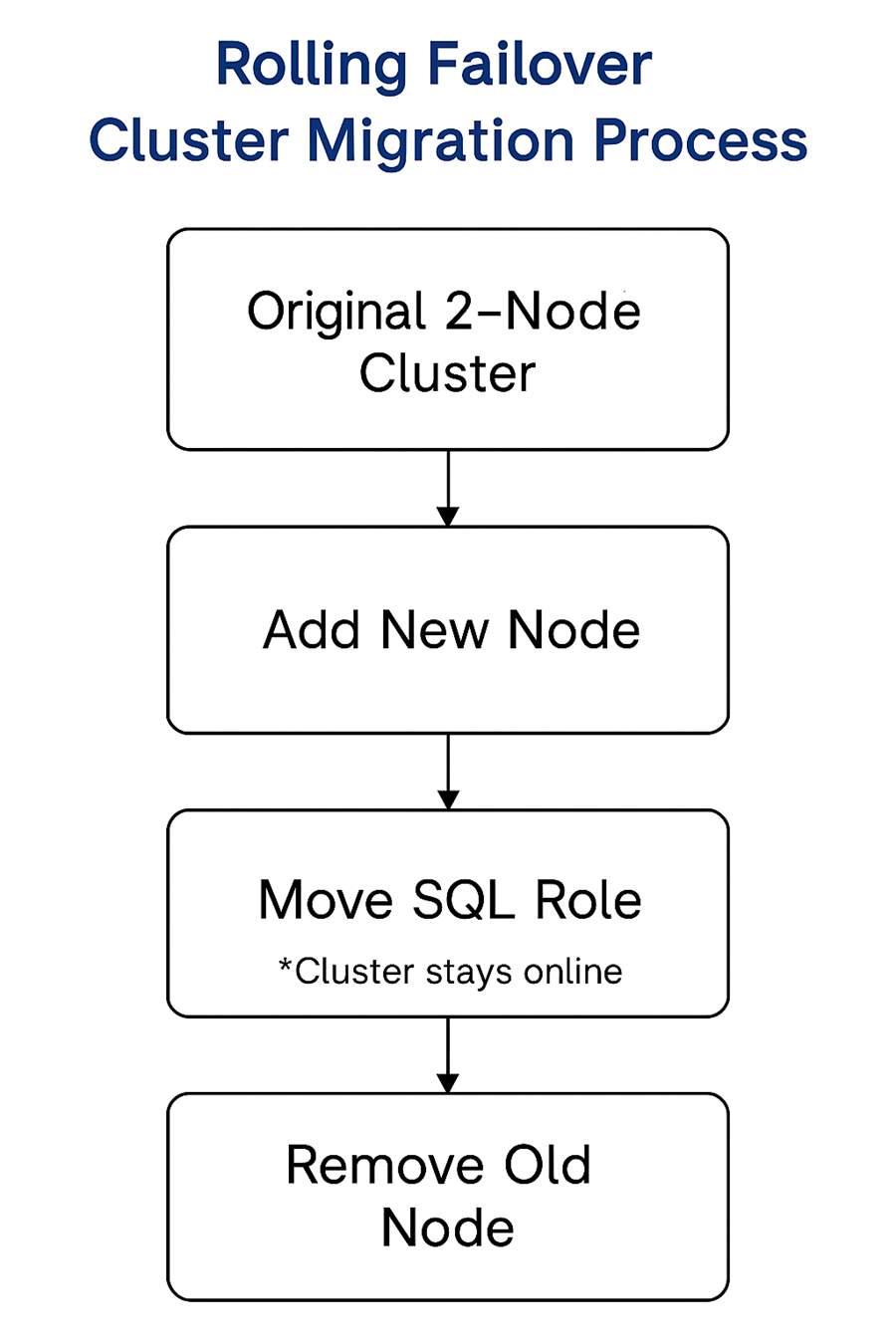
经过几天的性能观察与故障转移,我们开始剔除旧节点:
在移除第二个节点之前,我们备份了集群配置并记录了磁盘所有关系,以防发生意外。
而后使用PowerShell移除了第二个节点:
最终我们成功迁移到两个新的SQL Server节点,未引发任何停机时间,高可用性亦未受到影响。
6. 清理工作我们清理了过时的DNS条目,重新注册了监控代理,并验证了所有作业仍在SQL代理中正常运行。我们还激活了完整集群验证报告,确保所有操作均顺利通过。
让我们措手不及的意外:
分区不匹配:一个LUN映射不正确——通过手动比较WWN解决了此问题。SQL代理:故障转移后,由于脚本中包含硬编码的节点名称,因此一项作业静默失败。防火墙规则滞后:尽管端口已经打开,但GPO需要一段时间才能应用;我们不得不手动启动gpupdate /force。监控误判:我们的监控工具将正常的故障转移误判为需要手动重新配置的情况。几点小提示
在安装SQL前验证MPIO与SAN的访问权限。使用PowerShell执行可重复操作。手动故障转移前,务必进行测试。如果已部署有虚拟化环境,请创建集群配置快照。在启动前,记录每个节点拥有哪些磁盘。专门测试SQL代理作业,留意其中硬编码形式的路径或节点名称。使用cluster log /g 捕捉历史故障转移事件,以便日后进行故障排查。将各个阶段告知应用团队——即使是短暂的故障转移也可能触发警报。写在最后
整个迁移过程并不简单,令人紧张、细节繁琐,但又无比重要。干净利落地完成迁移,完全不引发用户注意,正是区分优秀基础设施团队和卓越团队的关键差异。
我们还发现,事后编写一份内部快速行动手册会很有帮助。现在,组织内的其他团队可以轻松重复整个过程,规避我们之前犯过的错误。
在生产环境中,整个迁移过程只有一次机会。所以务必整理好回滚计划,知会值班人员,也绝不能乐观认定预发布阶段中奏效的方法可以直接在生产环境中成功。希望这篇文章能给大家一点启发,帮助各位顺利完成自己的迁移任务。
原文标题:Migrating SQL Failover Clusters Without Downtime: A Practical Guide,作者:Kishore Thota