2025 DTCC 点滴有感
作为数据库行业的年度盛会,DTCC 2025如期而至。笔者全程参与了本次大会,也与很多老朋友难得一见、相谈甚欢。特别是在第一天晚上的DBA之夜,还有幸拿到了首界IT新媒体的一个奖,算是给自媒体分享的小小鼓励。作为年度会议,各位嘉宾的分享,是行业一年来发展的一个风向标。受个人精力所限,只看了部分场次的分享,下文就是一点点个人感受。
1. 行业趋势篇
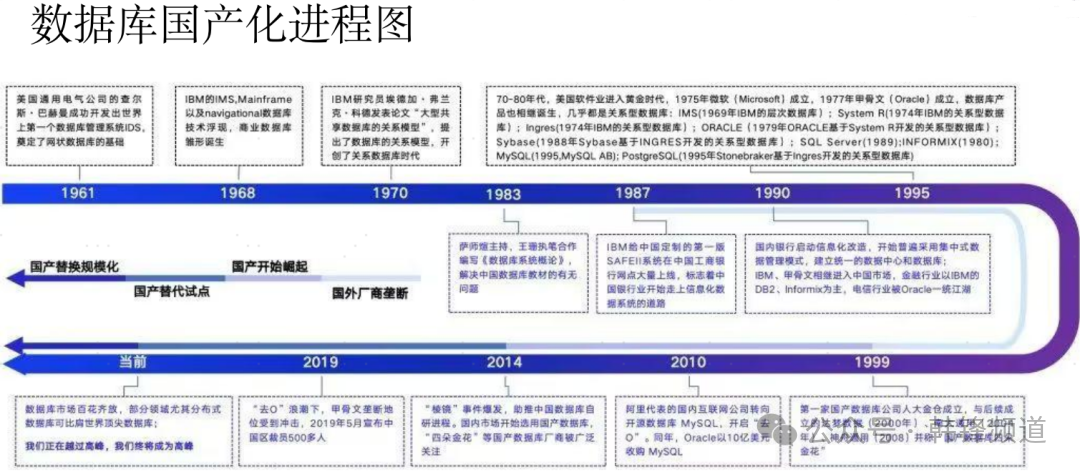
1)数据库国产化进程作为一个数据库多年从业者,看到了这些年来数据库的快速发展。特别是在最近的二十年,国产数据库经历了巨大的变化。从之前“老四家”在苦苦坚持,到之后大批新生力量的涌现,再到信创转型下行业的快速收敛。我们正在经历着这一历史的转型期。就在大会的第二天,数据库国测名录三期的公布,可以说大大出乎了很多人的意料,可谓几家欢喜几家愁。相信在未来的二、三年,行业还存在诸多变数,大浪淘沙,有些企业会脱颖而出,有些则会沉寂掉队。这一变化的结果可能会影响中国未来一二十年乃至更长的数据库行业格局。
 图片
图片
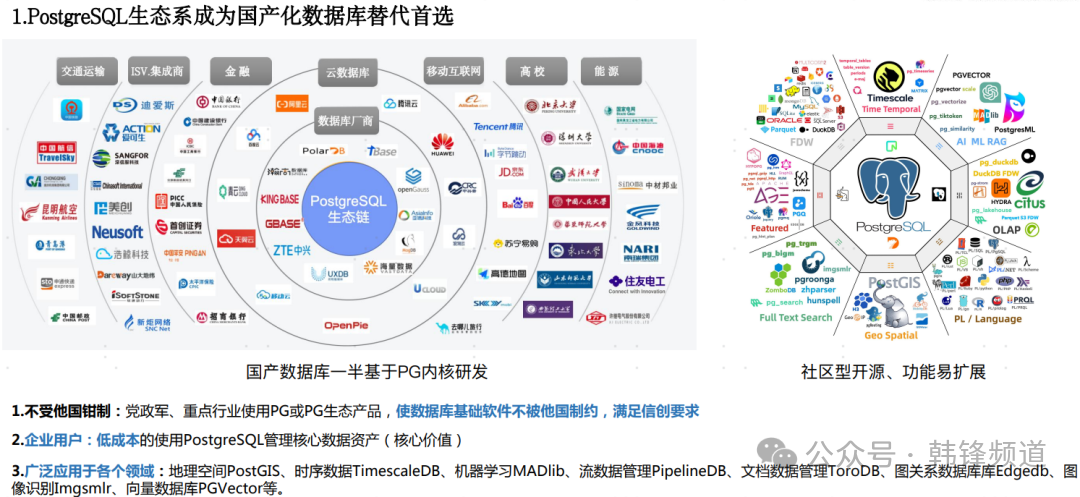
就在数年前,开源数据库的市场占有率已经超过商业数据库,那时候开源大火。如果要选择近一年来最火的数据库,无疑是PostgreSQL(也许DuckDB算另一个)。过去几年,国内的PostgreSQL相对有些沉寂,随着两千年之后互联网应用的快速发展,MySQL成为开源圈的代表性产品。但就在最近的一年,PostgreSQL可以说大了一个翻身仗。其中之原因,可以归功于三点:AI加持、多模趋势与开源模式。
 图片
图片
AI及多模,是源于PostgreSQL的插件化架构,可以快速扩展能力。其实这也不是国内的特例,国外基于PostgreSQL的公司也成为资本方的新宠。而相对宽松的开源协议则成为PostgreSQL大受欢迎的另一个原因。国内大量基于其内核构建的国产数据库层出不穷。从已通过国测目录的产品溯源来看,基于PostgreSQL的产品远多于基于另一款开源数据库MySQL的产品。
然而在高兴之余,也存在一些隐忧。开源数据库具备良好底座,是企业快速构建产品的基础,但同时也考验了企业消化吸收,进而改进优化的能力。以PostgreSQL为例,其传统的几个弊端仍未消除,这也大大影响了其进入企业核心系统。如下图为例,只有极少数的企业有实力去解决开源内核问题,绝大多数企业还是简单套壳。这无疑会为大规模的推广造成困扰,甚至产生隐患。
 图片
图片
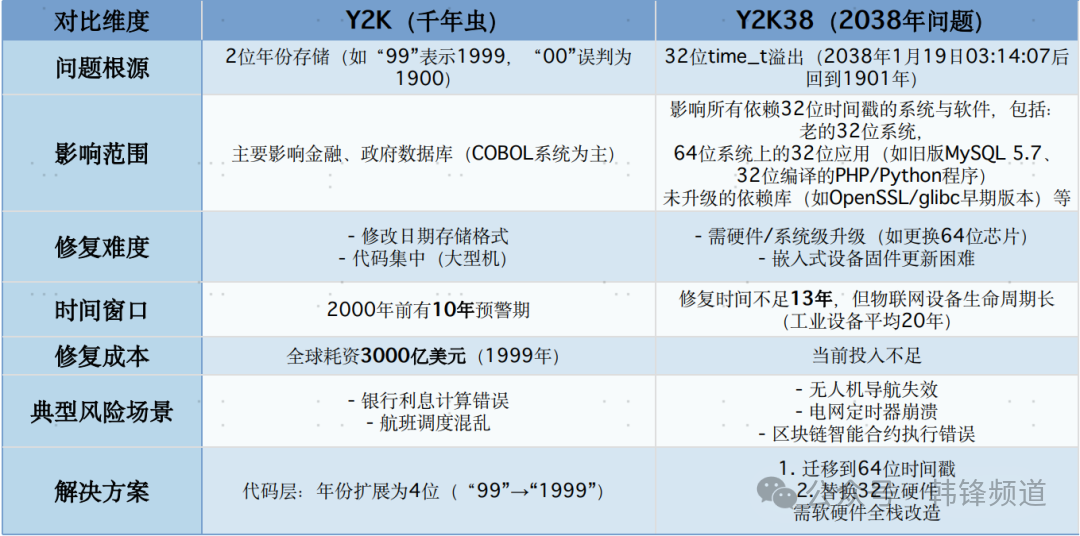
近期行业内已经发生多起针对PostgreSQL、MySQL等开源产品内核出现的问题,也给很多用户敲响了警钟。下面是大会分享中谈到的另一个MySQL的Y2K38问题,即使在最新版64位MySQL的版本下,Y2K38 危机依然存在。解决的方法不是没有,但要么代价很大,要么存在技术瑕疵。这不禁让我想起对自主可控的朴素诉求,未来还有多少企业能真正担负起这个责任。
 图片
图片
 图片
图片
2. 架构技术篇
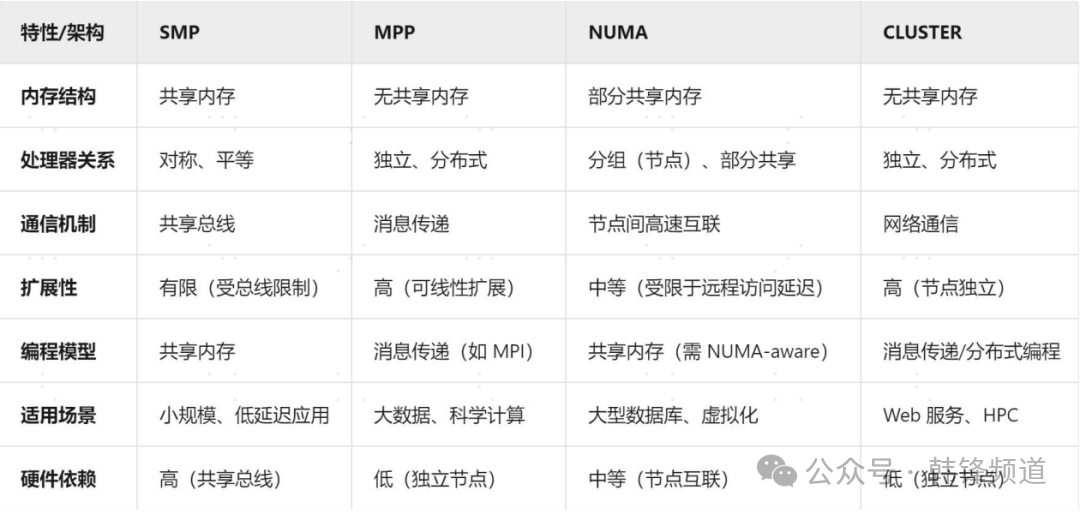
1)换个角度看架构我们先来跟随李海翔老师的分享,看看他对数据库架构的理解。我们可以从更多维度去看待现有这些架构及产品。有句话讲,没有完美的架构,更没有完美的产品。不同架构与产品各有其鲜明的优劣势和对应场景。
 图片
图片
这是这一特点,我们也看到国内很多数据库厂商都纷纷走向了多架构的趋势。单机、主备、共享集群、分布式等,可以说殊途同归。近期几家分布式厂商都开始回归传统,推出了单机版本,也是为迎合市场需要,满足之前分布式无法解决的场景;反之亦然。那么从用户来讲,还是要回归本质,理解不同架构产品的特点,根据自身场景需要谨慎选择。从哪些角度来考虑这个问题呢,我们可以参考下图的几个维度来看。当然,现在也有所谓一体化的架构产品,似乎是一个“银弹”,将不同架构打平,用户无需关心。但我个人认为,要完美地做到这点,还是需要相当长的一段道路。
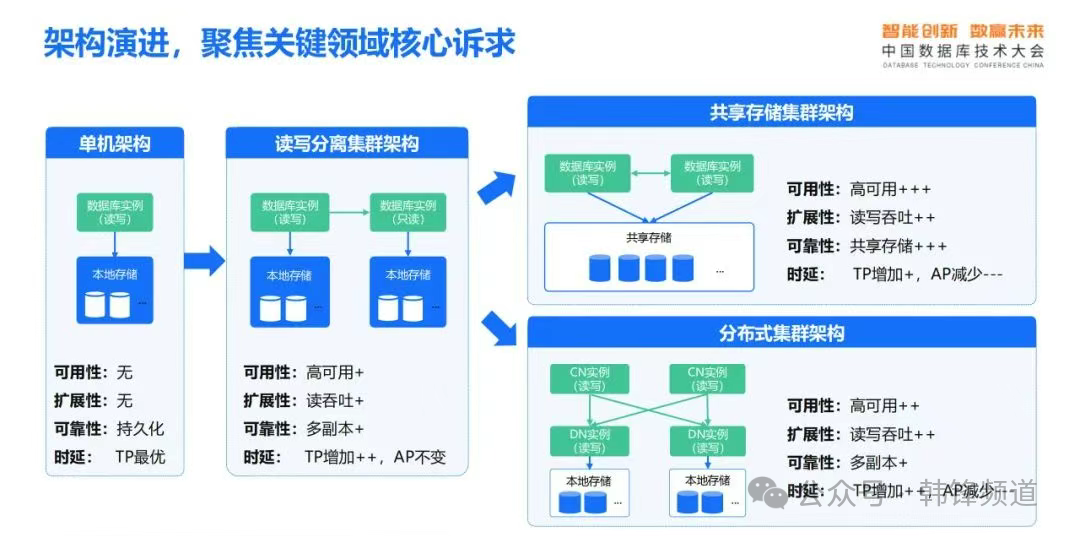 图片
图片
超融合的概念,可以说是另一个大火的技术名词。说实话,我对超融合的理解不深,也无法给出一个准确的定义。我观察国内主打这一理念的公司及产品,发现大家也是理解不同的。这里我们看看大会上,对于超融合数据库的理解,看看与你心目中的超融合是否吻合?这里真心希望能有一个所谓“标准”的出现,能够重塑大家对超融合概念的理解,也能加速这一定位产品的规范化发展。
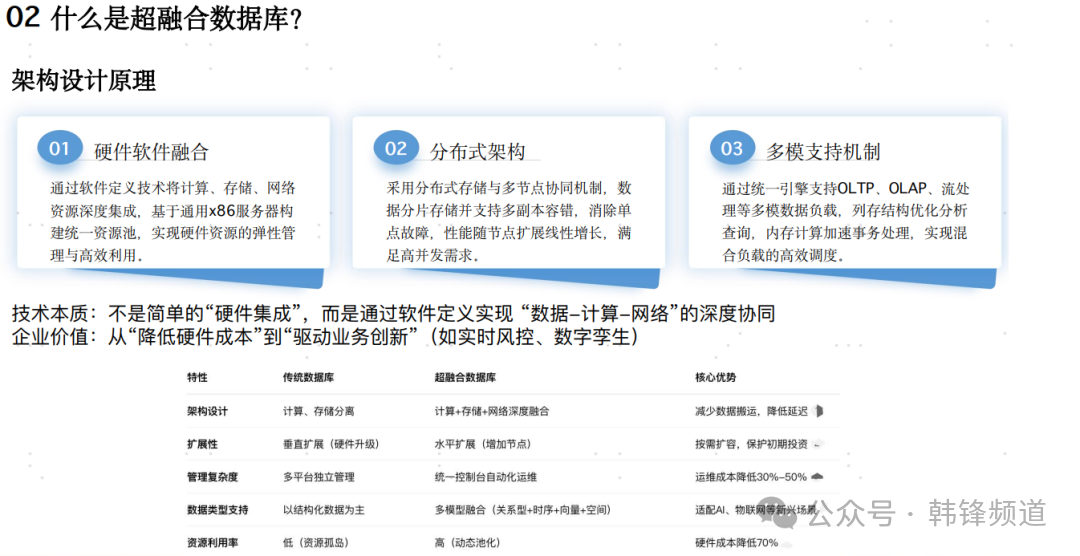 图片
图片
如果说超融合,还存在很多不同理解,那么多模化则已经是事实标准了。可以说多模化在数据库中的集成,成为应用最迫切的需求之一。于是乎,我们看到从数据库巨头-Oracle,到国产数据库一众厂商,纷纷把多模能力作为产品必备的能力之一。虽然我们还没有看到多模场景的大规模爆发,但是这一能力的竞赛早已开始。其实通过插件简单集成个多模能力似乎不难,但想要与优化器、执行引擎完美适配,打通上下游生态链,还需要有大量工作要做。至于成本与收益,短期内还是无法准确衡量的。
 图片
图片
AI与DB的结合,是近年来的又一热点。无论是AI4DB,还是DB4AI,都有大量的想象空间。相较于DB4AI的场景相对明确,AI4DB更多还在探索之中,虽然大家能想到很多可能利用的场景,但具体落地仍然存在诸多不足。如果仅仅是“建议”,也许还可以尝试,但真到生产可用还有很长路要走。就如同自动驾驶领域,也许L2级别还是会长期存在的。
 图片
图片
 图片
图片
MCP,是近期另一个热点,各个数据库厂商都希望集成MCP的能力。虽然个人对这一能力真正在生产中能产生多大价值尚存疑问,但去探索、去尝试还是很值得的。于是乎,我们看到一大批数据库厂商都快速具备这一能力,一方面难度应该不高,一方面也有利于提升公司技术品牌。但我们也要看到,此MCP非彼MCP,虽然都是MCP,但各家实现的能力层次补齐,差异很大。
 图片
图片
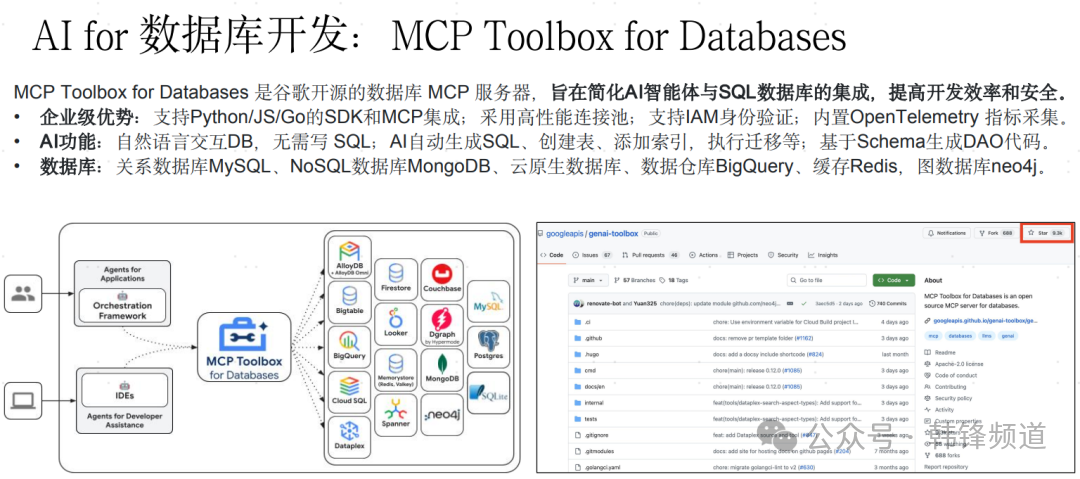 图片
图片
兼容性,已经是个老生常谈的问题,国内大部分厂商产品都将兼容性能力作为产品竞争力之一。于是我们可以在各企业的宣传中提到各种“零改造”、“平替”、“无感”等等。可以说兼容性已经卷到骨子里,没有兼容性的产品完全拿不出手。但同时我们也观察到,兼容性的竞争有慢慢从点到面的趋势。一方面,SQL语法的兼容,大家都在卷9x%之后的微小差异;另一方面,大量非SQL语法的兼容性需求被抛了出来。前者用户已经开始不相信厂商的宣传,更多还是要看实测结果;后者,则上升到对架构、运维、管理提出了更高的所谓兼容要求。于是乎,我们看到,性能兼容、管理兼容、成本兼容、生态兼容...,一个个兼容名词被提了出来,兼容性的卷开始进入一个新的境界。
 图片
图片
如果说上面卷的是“广度”,那么针对“深度”的卷,仍然存在大量细致入微的工作。厂商们还在为那百分比后的那一两位数字在奋斗。
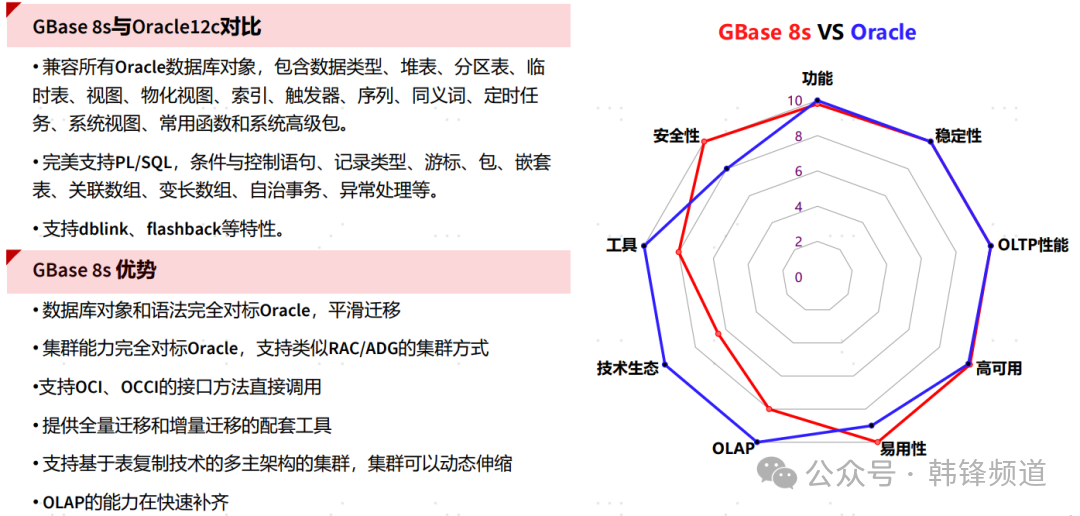 图片
图片
3. 用户实践篇
1)国产化路径思考随着数据库国产化深入,广大用户已经慢慢做的更有经验。经过过去数年的风雨洗礼,用户对国产数据库的能力有个相对客观的认识。一方面,如选型矩阵的出现,就是用户在充分实践后做出的最优自己的选择(当然也有成本因素);另一方面,在实践过程也有了一整套方法和体系。毕竟随着2027年的大限临近,还有还有大量的系统等待转型改造,用户自己摸索出来的路径正在快速复制。
 图片
图片
至于数据库选型,很多头部用户已经尘埃落定,中小型用户也在快速决策,毕竟时间不等人。在思考的维度上,也开始逐步理性和简化。所谓理性,是用户对国产数据库不再抱有过高的预期,开始慢慢接受国产数据库的现状,并通过其他方面填补可能出现的空白。后者则倾向于选择简化策略,将数据库依赖能力弱化,避免未来可能出现的再次选择痛点。于此同时,用户在选型策略上开始考虑其他一些因素,如安全合规(关乎长久发展和风险兜底)、生态服务(关乎实践效果和推进风险)、兼容迁移(关乎真金白银的花费)、稳定可靠(关乎数据库基础能力)、性能扩展(关乎未来发展空间)。这些维度正成为用户需要考虑选型要点。
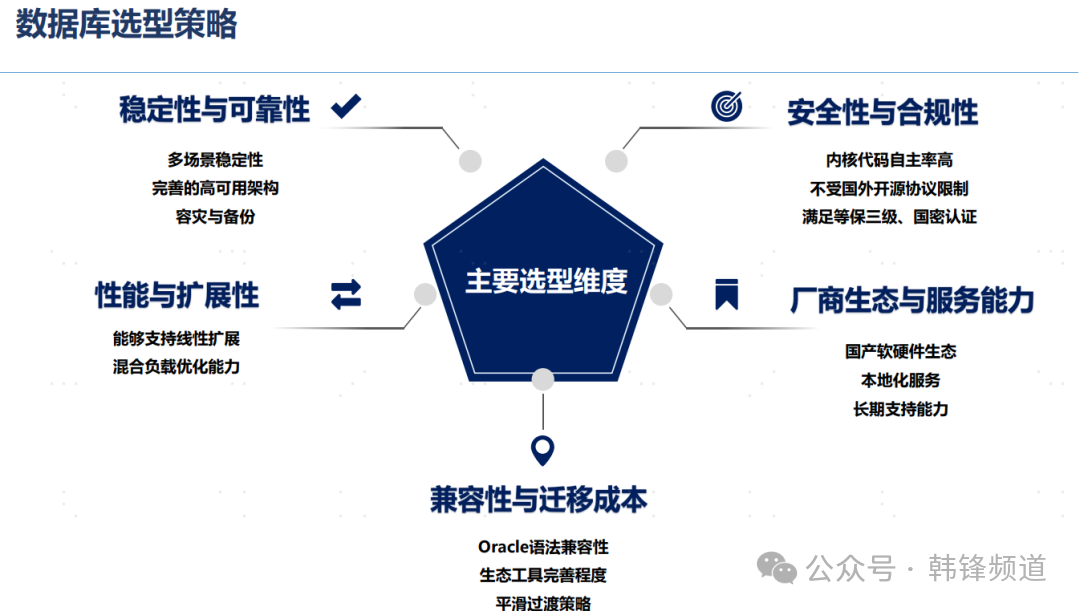 图片
图片
国产数据库选型之后,真正投入在核心场景实践,这其中还有很多工作要考虑。下图是会上来自罗敏老师,针对Oracle分区功能的实施内容,从中可见大量步骤与细节。Oracle数据库经过多年发展,其功能相对完善,即使这样还有如此之多的实践过程,说明要想用好数据库是需要真正理解产品与用户业务场景。反之,国产数据库存在大量自己的“个性”,需要原厂才能实施好,甚至需要原厂研发才能找到最优的路径。随着信创规模化铺开,是需要大量的此类“最佳实践”被积累、被沉淀,形成解决方案、场景白皮书等等,加速实施过程。
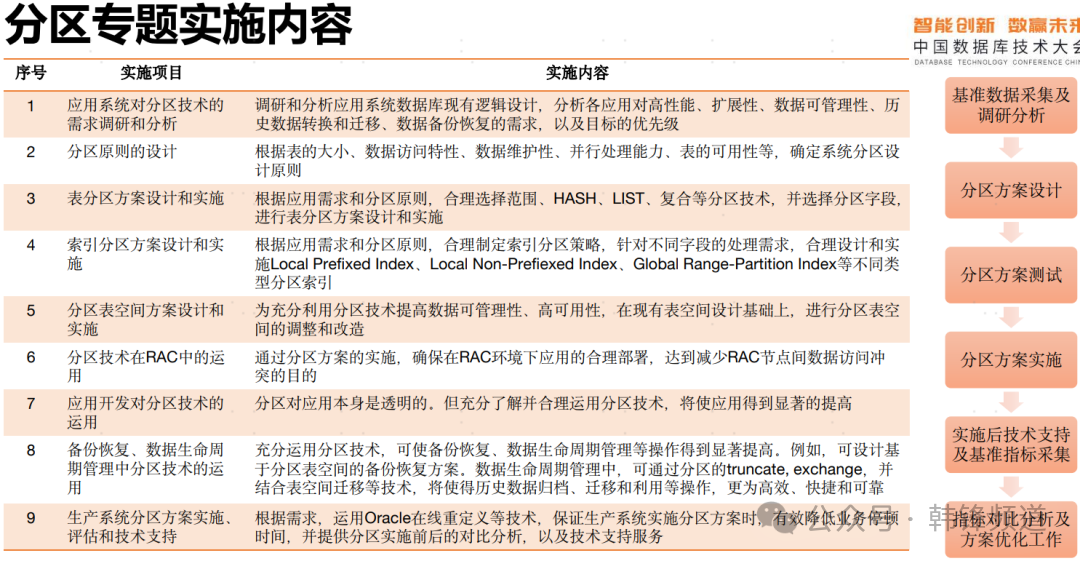 图片
图片
4. 个人发展篇
1)AI大潮下的发展思辨AI大潮下,对DBA这一岗位会带来什么影响?是很多DBA所关注的问题,这关乎到这一群体的整体发展。下图是梁敬彬老师带来的他的思考,让人印象深刻的“DBA平方”。大会线下,我和梁老师也针对这个话题做了沟通,也理解了梁老师对这一问题的深刻思考。过去的DBA角色,可以简单理解为“数据库管理员”,那么新的第一则演化为“数据+业务+管理/架构”的升级。一方面,我们的主发体生了变化,不再是数据的载体数据库,而是更为关注其本质数据;另一方面,从简单的管理行为升级为管理+架构;第三,在这一过程中要更多融入对业务的思考,并最终以产生业务价值为核心。梁老师这个总结,融于了AI对未来数据的影响,升华了对DBA这个词的理解,可以说印象深刻。
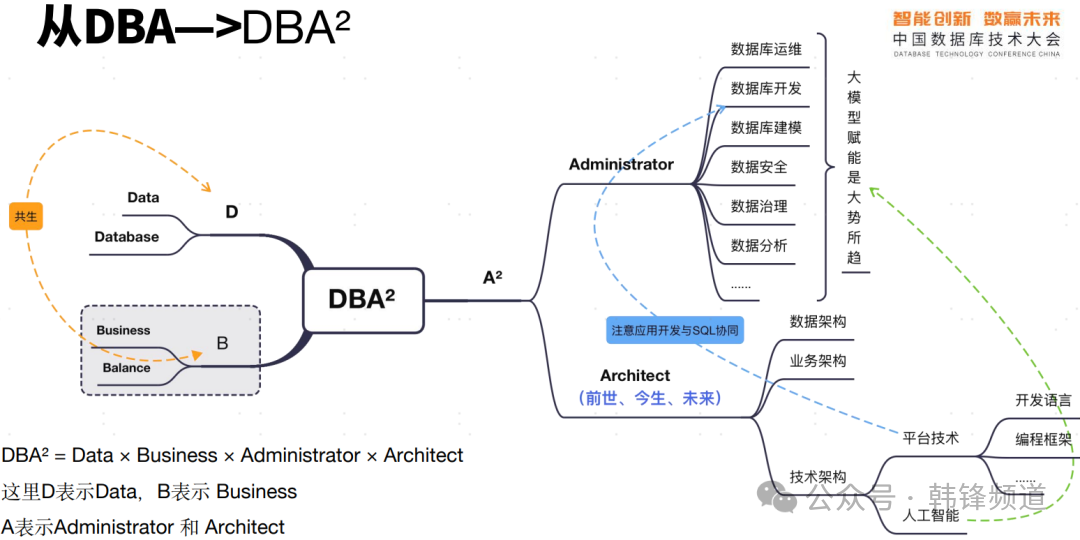 图片
图片