小红书新一代数据库代理 RedHub 的设计与实践

在亿级用户规模的业务场景下,数据库作为核心数据载体,其访问链路的稳定性、性能和可维护性,直接决定了系统的健壮性与迭代效率。
然而,随着业务快速发展,数据库接入方式逐渐碎片化:直连、多版本 SDK、自研中间件……不同的接入模式带来了协议兼容性差、故障恢复慢、运维成本高等一系列挑战。
为解决这一系统性难题,小红书数据库团队研发了新一代数据库代理系统 —— RedHub,致力于构建统一、高性能、易运维的数据库接入层,支撑未来十年的数据库架构演进。
本文将分享 RedHub 的设计思考、关键技术突破与生产实践成果。
01、演进动因:从碎片化接入到统一代理的必然选择
在小红书业务快速发展的过程中,为满足不同场景的敏捷迭代需求,数据库接入方式逐渐形成了“多路径并行”的局面。据初步统计,曾存在 6 种以上非标准化接入方式,而符合统一规范的占比不足三分之一。
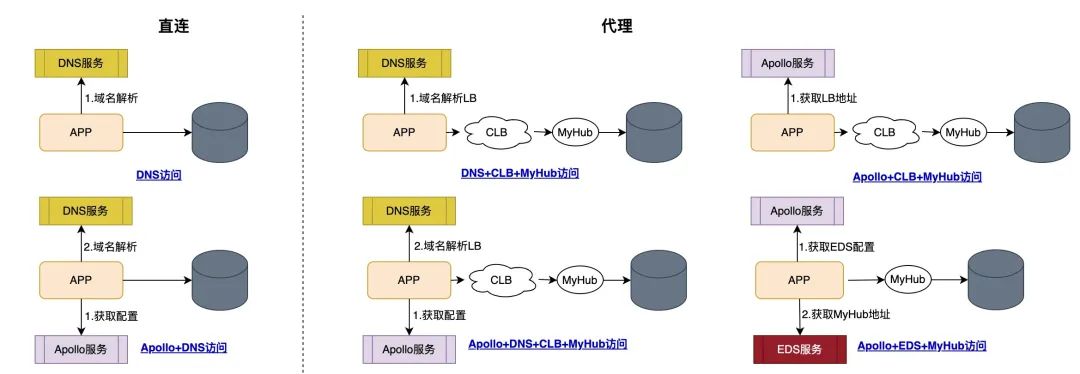
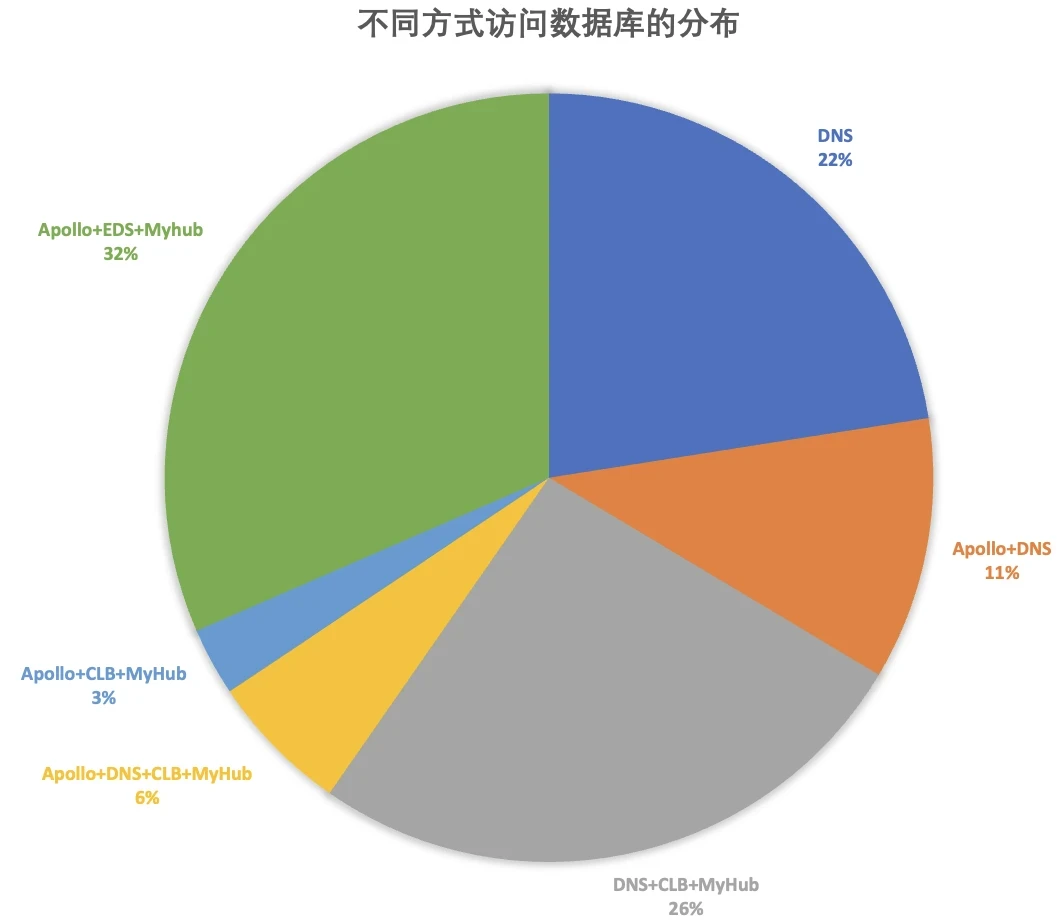
这种快速迭代的业务节奏,在早期有效支撑了业务创新,但由于缺乏统一的长期架构规划,数据库接入方式逐渐演变为多路径并行的局面,带来了后续的治理复杂性和技术债务:
可用性风险高:多种接入模式依赖各异,健康检查与故障切换机制不统一,部分场景下难以及时隔离异常;运维成本高昂:工具链需适配不同路径,问题定位效率低,扩容、变更流程复杂;扩展能力受限:缺乏统一的元数据管理、链路追踪和精细化管控能力;同时,作为前期主要的标准化接入载体,旧版代理(MyHub)在功能上也逐渐暴露短板:SQL解析能力弱、不支持复杂查询(如跨分片 JOIN、子查询)、执行引擎简陋,严重制约了业务对分库分表的使用体验。
我们意识到:当业务规模跨越临界点,基础设施不仅需要“统一入口”,更需要一个功能完整、稳定可控、可持续演进的数据库接入层 —— “统一性”已从可选项,变为必选项。
02、架构转型:走向轻量客户端与中心化代理的融合架构
横向上看,业界的数据接入层架构主要分为两个流派:一种是 SDK 层做(从业务层拦截流量做代理分发),嵌入在业务服务中,这种情况的优点是访问数据库 RT 比较低,但缺点是后续升级不够灵活,推动业务改造难度大;另一种是 SDK 做薄,Proxy 做厚,将以前 SDK 的能力下沉到 Proxy 层,这样 SDK 将流量转发到Proxy 层,由 Proxy 再分发到下游数据库服务。这种情况的优点是后续升级方便,无需业务改造,缺点是会带来一定 RT 上涨(毫秒级)。
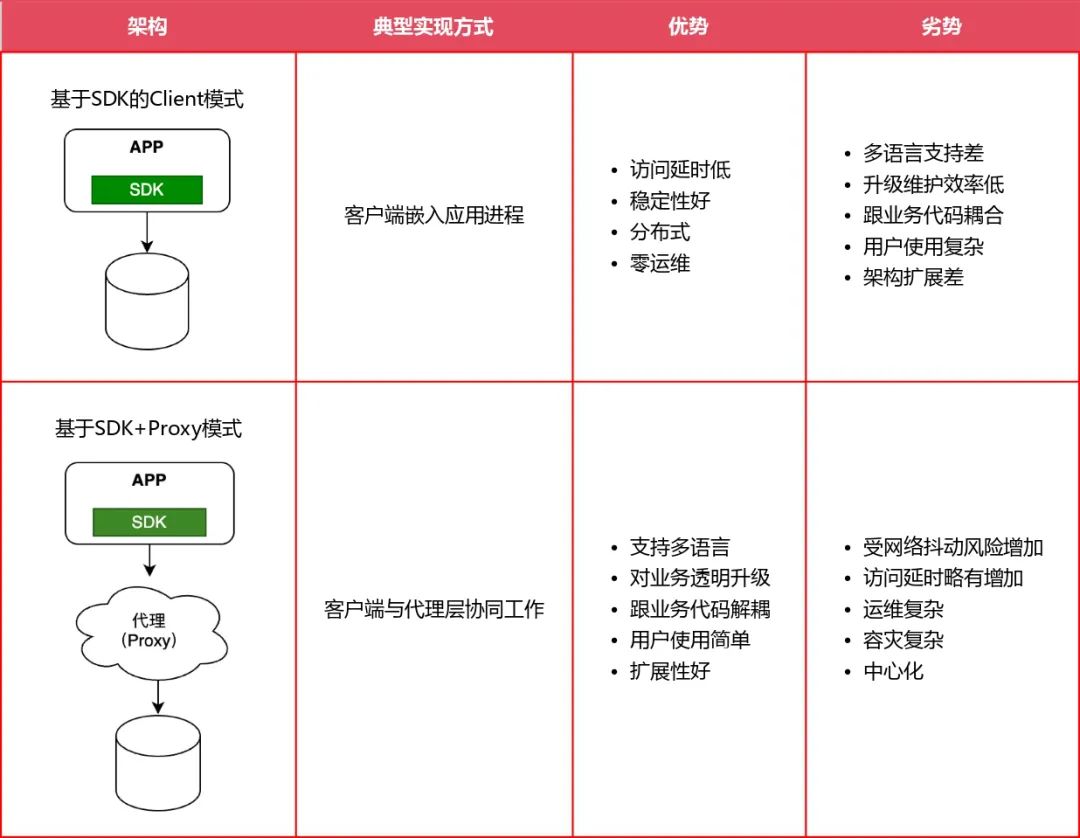
基于 SDK 的方式在早期比较流行,随着 SDK + Proxy 的诞生,目前各大公司已在逐步升级替换,但部分长尾业务依然使用 SDK 的访问形式。从趋势看,基于 SDK + Proxy 的访问方式将会是未来的终态。
因此,小红书也坚定选择了“轻 SDK + 重 Proxy”的技术路径,将数据库访问的复杂性收口到 Proxy 层实现。
03、重构决策:基于开源内核的重新研发之路
面对旧代理 MyHub 在功能、架构与运维上的持续退化,我们面临一个根本性抉择:是继续在其陈旧代码基础上局部优化,还是构建一个面向未来十年演进的新一代数据库接入层?经过系统评估,我们明确放弃“渐进式迭代”路径,转而启动 RedHub 项目,采用“基于成熟开源项目深度二次开发”的技术路线,实现从能力到架构的全面升级。
3.1 旧系统已不具备可演进性MyHub 作为六年前的技术产物,长期缺乏系统性维护,核心模块耦合严重、扩展困难,暴露出三大不可逆缺陷:
功能层面:SQL 解析能力薄弱,复杂查询(如跨分片 JOIN、子查询)支持率不足 20%,严重制约分库分表落地;架构层面:高可用链路依赖非标组件,探活机制无法覆盖磁盘故障等真实异常,连接池无刚性限制,存在打爆 DB 的风险;运维层面:缺乏全局会话视图与精细化限流能力,问题定位效率低,变更流程高度依赖人工。这些问题已非局部修补所能解决。我们判定:MyHub 不仅是一个落后的系统,更是一个阻碍长期演进的架构负资产。
3.2 技术路径选择:从头自研 or 基于开源二次开发?数据库代理系统复杂度高,涉及协议解析、分布式执行、连接管理、高可用控制等多个关键模块 。我们重点评估了两条核心路径:

进一步分析发现,从头自研虽然理论上可控性强,但面临“时间成本高、试错代价大、人才投入密集”三大挑战。尤其是在数据库这类基础设施领域,协议兼容性、执行引擎优化、并发控制等底层能力需要长期打磨,难以在短期内达到生产级稳定。
而基于开源项目二次开发,尽管前期需要投入大量时间阅读源码、理解架构,但可以快速获得经过验证的分布式执行引擎、SQL 优化器、元数据管理等核心能力。只要选型得当,并在关键路径上做深度增强,完全能够构建出满足企业级需求的定制化系统。
因此,我们选择基于开源项目 PolarDB-X 计算层进行深度二次开发的技术路径。在保证技术自主性的同时,复用其成熟的分布式 SQL 执行引擎与优化器能力,有效规避重复造轮子的风险,实现研发效率与系统质量的平衡。同时,针对小红书作为云原生、多云架构下的高并发、多租户业务特点,在关键链路进行深度定制增强:
高可用层面,适配多云网络异构环境,提升故障识别精度;连接与元数据层面,去中心化配置管理,保障跨云部署的一致性与韧性;治理层面,产品化参数级限流、逻辑会话管理等能力,支撑统一可观测与精细化管控。RedHub 并非简单“拿来主义”,而是“站在巨人肩膀上,走出自己的路”——既借力开源,又超越通用,打造真正服务于小红书未来十年架构演进的数据库接入层。
04、能力突破:高可用、智能执行与透明治理的系统实现
RedHub 的价值不仅在于替代旧系统,更在于构建一套完整的能力体系。围绕稳定性、功能性和可观测性三大目标,我们在多个关键技术维度实现了系统性突破。
4.1 稳定性:从“脆弱依赖”到“闭环高可用”MyHub 的高可用链路像一条“长链条”,任何一个环节出问题,整个系统就卡住。而 RedHub 的设计哲学是:核心路径最短,依赖最少,自愈最快。

关键改进:
探活独立:使用短连接独立探活,磁盘故障也能秒级感知;Leader 仲裁:仅由 Leader 节点探活,避免集群放大问题;<滑动查看 MyHub 和 RedHub 的对比>
基于 MyHub 的访问
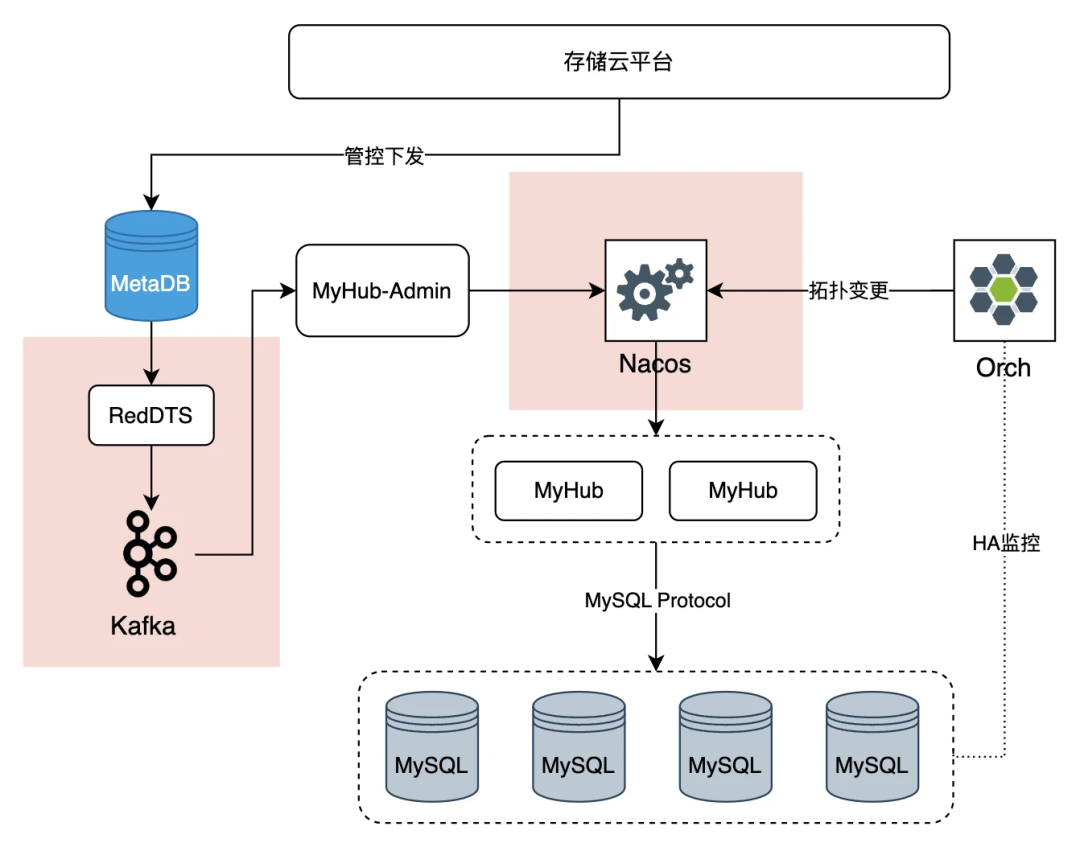
1. 不合理的组件依赖:配置变更路径上存在 binlog 订阅链路,导致依赖了 RedDTS 和 Kafka,从架构层级上看不合理、可用性上达不到高可用系统的要求,存在稳定性风险
2. 强依赖不可靠的配置中心:高可用切换核心链路上依赖了中心化的 Nacos 配置中心,非公司标准化组件,属于自运维的开源产品,可用性保障弱
基于 RedHub 的访问
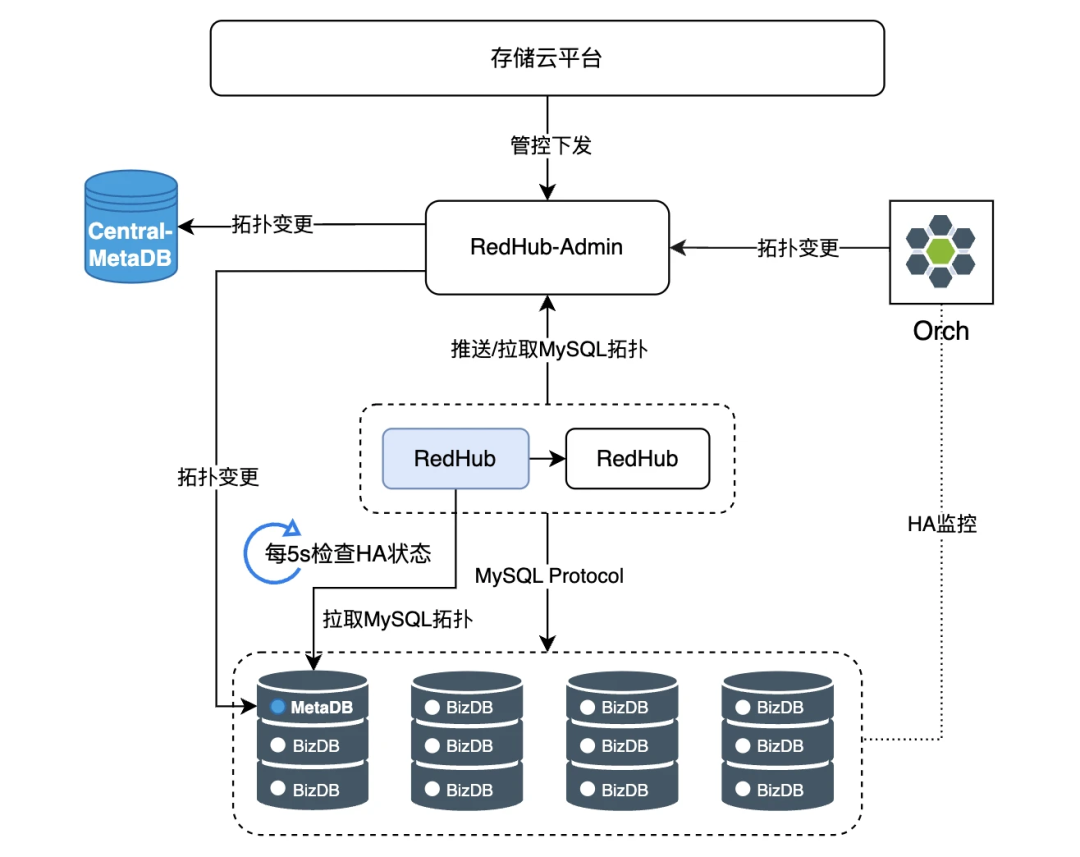
3. 外部依赖简洁清晰:仅依赖 orch、redhub-admin、metaDB 等几个核心组件,内部闭环,且变更路径短
4. 配置管理分布式化:不依赖中心化的配置中心,集群配置通过数据库实现,下沉到各套集群并结合中心化 metaDB 实现双备,可靠性高
连接可控:刚性连接池,最大连接数可配,彻底杜绝DB被打爆。<滑动查看 MyHub 和 RedHub 的对比>
基于 MyHub 的访问
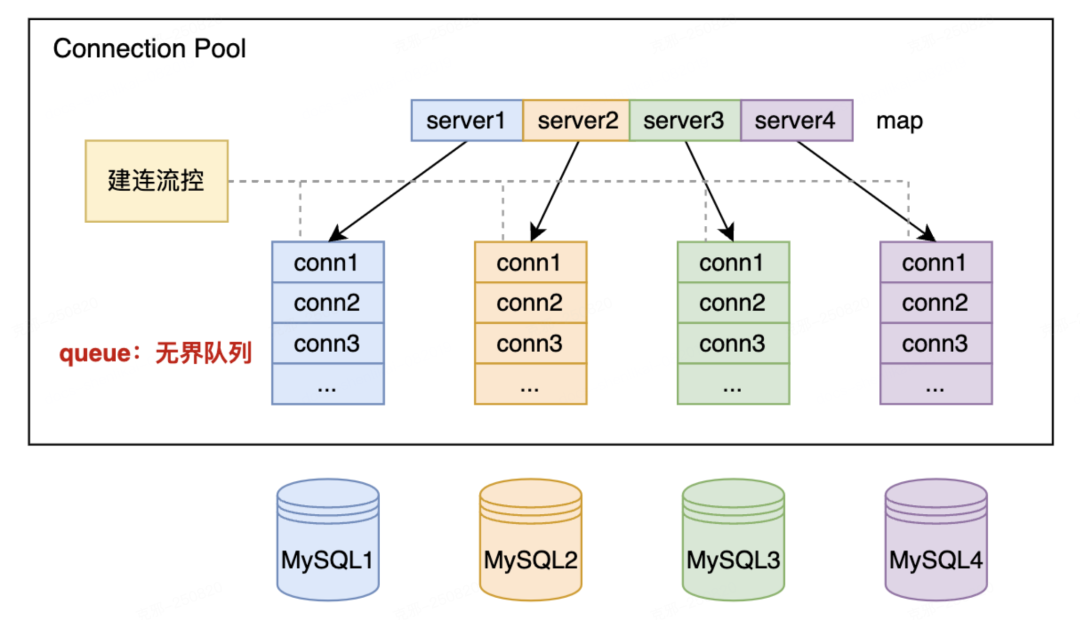
连接上限不可控:MyHub 与 MySQL 之间的连接无上限,获取连接时如果无空闲连接则触发建连,通过控制建连的并发度来软性限制,遇到流量洪峰和大量慢查场景,容易导致 MySQL 连接数打满甚至直接宕机
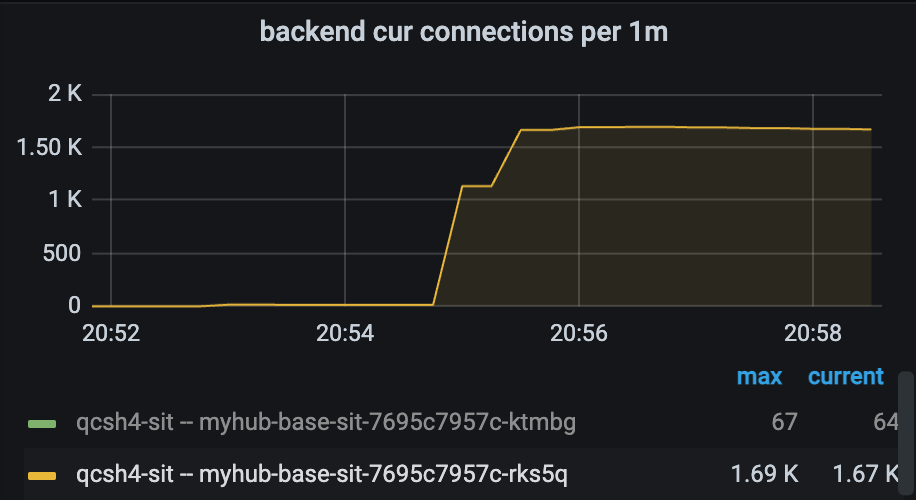
随着洪峰流量达到,MyHub 的后端连接数快速飙升到了1600+,直到达到 MySQL 配置的连接数上限,此时如果 MySQL 配置不足以应对这些连接开销,将会被直接打挂。
基于 RedHub 的访问
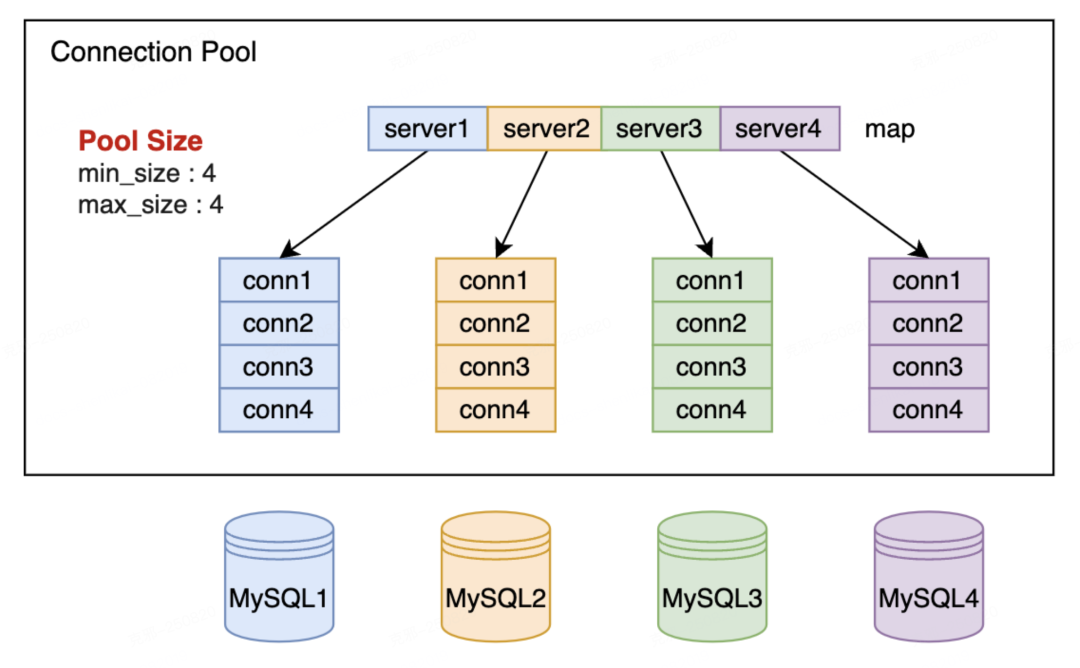
连接上限可控可调:通过最小和最大连接数参数控制 RedHub 与 MySQL 的连接数上限,有效保护 MySQL ,支持动态调节连接数限制,来实现性能调优、流量洪峰预热等能力
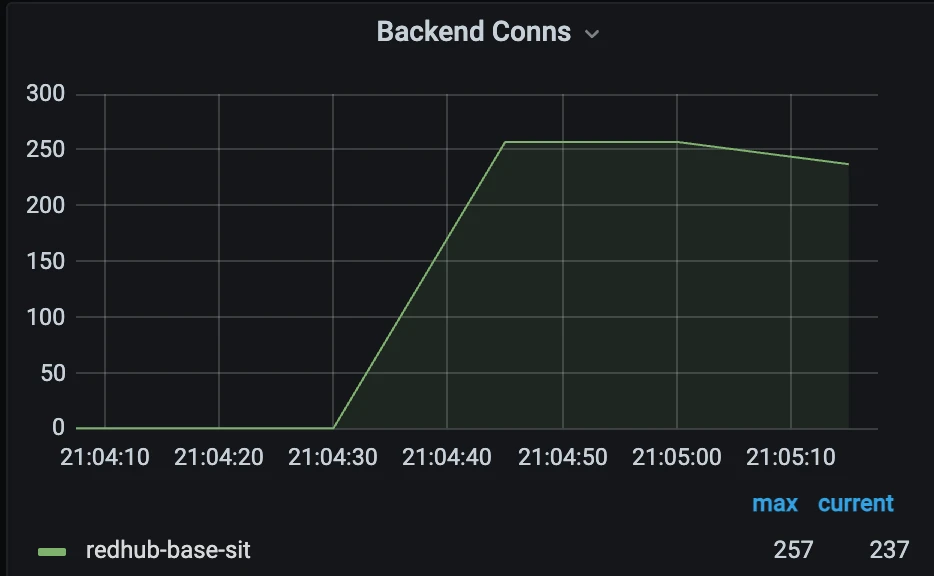
RedHub 的后端连接数被严格控制在了连接池上限之下,MySQL 上的连接数得到了良好的控制,避免了被打挂的风险。
4.2 能力升级:从“SQL 转发器”到“智能 SQL 引擎”MyHub 的本质是“流量搬运工”,而 RedHub 是一个具备分布式数据库能力的智能代理。
SQL 兼容性:从“写不了”到“基本不用改”
基于 Druid 重构 SQL 解析器,支持复杂子查询、ORDER BY、聚合函数;引入 Session Context,支持事务隔离级别等会话变量;经 SQLancer 工具测试,分库分表场景 SQL 通过率从19%提升至92%。
分库分表:终于能写 JOIN 了
内置分布式优化器(RBO + CBO),自动拆解并优化跨分片查询;支持跨分片 JOIN、聚合、排序,语义正确,性能可控。发号器:从“手动取号”到“无感自增”
支持 AUTO_INCREMENT BY SEQUENCE,建表时指定,插入时自动填充;业务代码不再手动获取 ID 或者填写发号器函数;多种序列类型可选:号段、Snowflake、时间序列,灵活适配。4.3 运维体验:从“黑盒排查”到“透明治理”以前查慢查询,要登录多个 MySQL 实例,手动拼 SQL;现在,RedHub 提供了真正的“全局视角”。
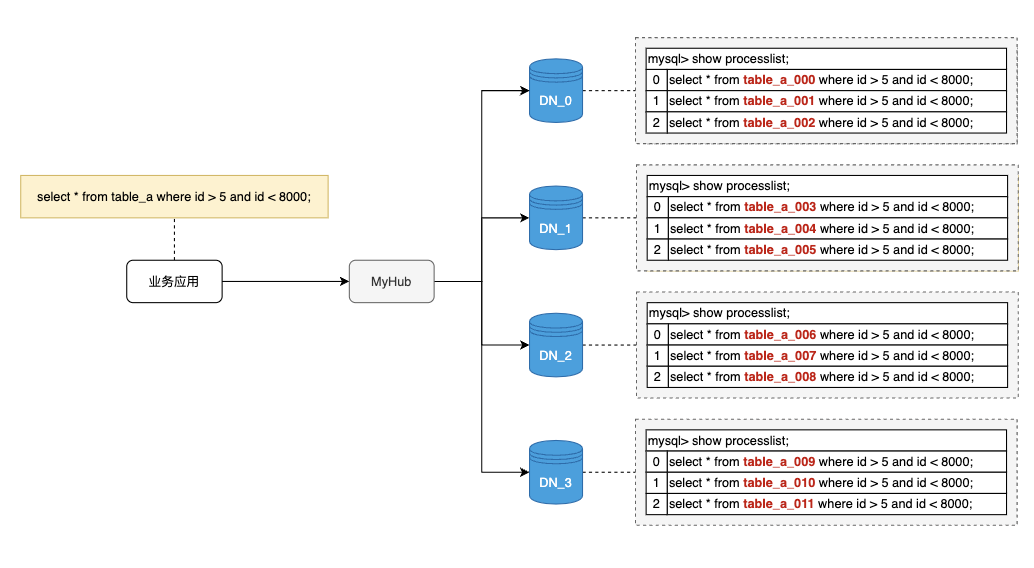
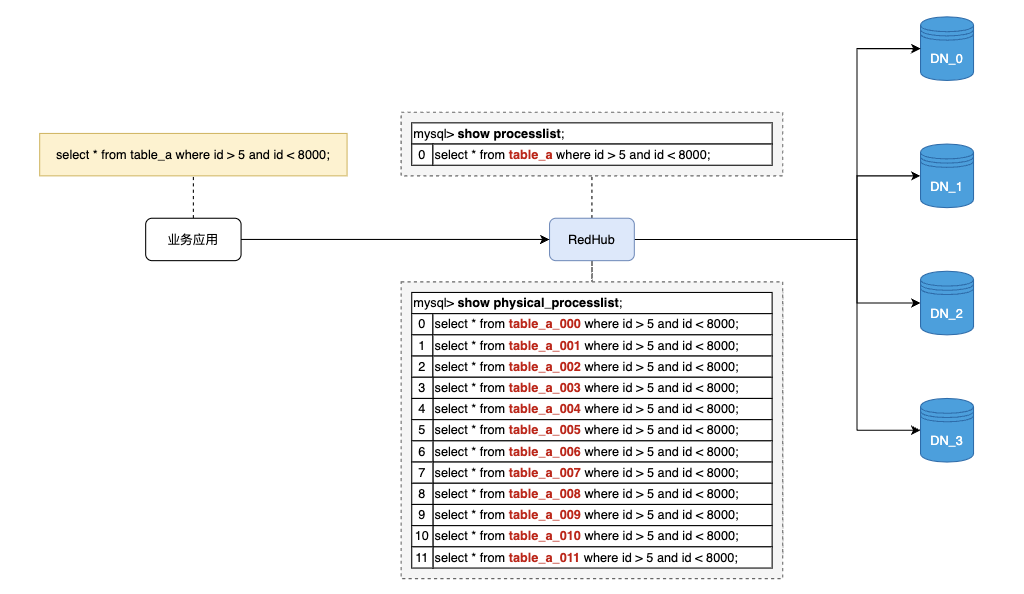
实时会话管理
SHOW PROCESSLIST 查看到的是逻辑 SQL,一键 KILL 即可终止所有关联的物理查询;SHOW PHYSICAL_PROCESSLIST 查看底层实际执行,排障效率提升数倍。<滑动查看 MyHub 和 RedHub 的对比>
基于 MyHub 的访问
基于 RedHub 的访问
精细化限流:精准打击“热点SQL”
MyHub 只能按SQL模板限流,而 RedHub 支持:a.按库、表、用户、IP、SQL类型
b.按SQL模板和参数关键字(如 oid=2)精准限流
配置一条规则,即可熔断特定热点请求,避免雪崩。RedHub热点限流样例
热点SQL:

配置限流规则:

05、实践验证:低侵入迁移与关键场景闭环检验
我们深知技术再好,升级成本高也白搭。因此RedHub 的迁移设计核心是:业务无感、风险可控、支持到位。
5.1 平滑迁移:流量回放 + 渐进灰度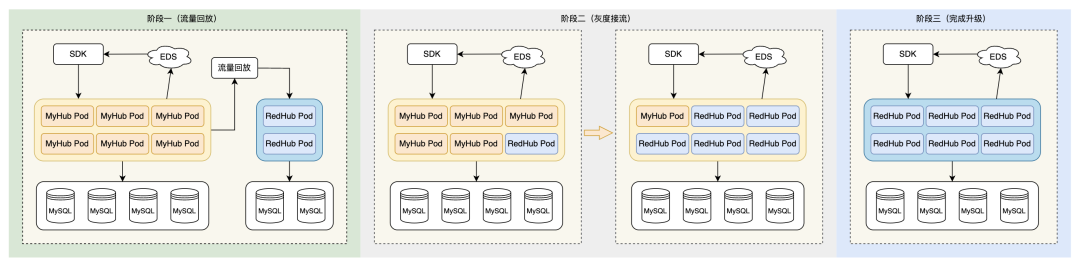
从 MyHub 升级到 RedHub,整体分为三个阶段,业务侧基本无改造:
流量回放:在 MyHub Pod 上部署流量录制组件,录制业务SQL模板部署独立的 RedHub 集群,复制原集群的库表结构将录制的业务 SQL 模板在 RedHub 集群上回放,完成 SQL 兼容性验证2. 灰度接流:将集群标记为迁移状态,并在 MyHub 的集群中加入 RedHub Pod,灰度承接业务流量,逐步增加 RedHub Pod 占比
3. 完成升级:将所有 MyHub Pod 节点全部下线,仅保留 RedHub Pod,将集群状态标记为迁移完成,集群类型变更为 RedHub。
5.2 真实场景验证,助力稳定与高效✅ 案例一:从库磁盘故障自动隔离
某次线上从库因磁盘写满导致服务不可用,RedHub 通过短连接探活机制在 15 秒内精准识别异常,自动将其从负载列表中摘除,业务查询无抖动、无报错,实现了故障“静默自愈”。
✅ 案例二:热点 SQL 快速限流恢复
某内部应用,因为热点消息推送导致一个高频查询 SQL 扫描过多的数据,产生了大量的慢查询。通过 RedHub 的精细化限流能力,我们在 2 分钟内配置规则,精准拦截特定用户 + 关键参数的请求,系统负载迅速回落,避免了服务雪崩。
与此同时,RedHub 的高 SQL 兼容性与完整功能支持,打破了过去“因能力不足无法接入代理”的僵局,让原本只能直连数据库的业务,也能以标准化方式接入。这为未来实现全量数据库流量统一治理奠定了坚实基础。
06、长期远景:构建数据库统一控制面与智能中枢
RedHub 的定位,从来不只是一个“流量转发层”。我们正在将其打造为小红书数据库生态的统一控制面 —— 一个集 流量治理、安全管控、可观测性与智能优化 于一体的数据库中枢。
接下来,我们将围绕四个方向持续演进:
统一访问治理:构建细粒度权限模型,支持字段级脱敏、行级访问控制,满足多租户与合规场景需求;增强型数据安全:集成动态脱敏、SQL审计与敏感操作熔断,让每一次数据库访问都可管、可控、可追溯;智能化运维能力:基于SQL执行数据构建性能画像,自动识别慢查询模式、推荐索引、预测容量瓶颈;HTAP 能力探索:支持冷热数据自动分离,热数据留存行存引擎保障事务性能,冷数据归档至列存引擎;通过 SQL 路由自动将分析型查询导向列存,实现 AP 与 TP 资源隔离与统一入口,逐步迈向轻量级 HTAP 架构。未来,RedHub 将不仅是业务访问数据库的“必经之路”,更会成为我们实现数据库自治、可观测、合规闭环与混合负载支持的核心枢纽。
07、作者简介
Core Contributors克邪(沈力锴)
小红书数据库中间件研发负责人,主要负责小红书数据库代理、数据库 SDK 和数据传输服务等数据库中间件产品的整体架构和技术演进。
程普(沈文浩)
小红书数据库中间件研发工程师,聚焦数据库代理研发,主攻数据分片、SQL 解析、流量染色与识别等核心技术,打造支持单元化架构的流量治理闭环,保障大规模场景下数据库访问的稳定与可控。
正雪(李宇辰)
小红书数据库中间件研发工程师,负责数据库代理研发,聚焦高可用机制(探活摘流、故障隔离)、多云流量路由、SQL 性能优化及平滑升级、自动扩容等自动化运维能力建设,支撑大规模、多云环境下数据库系统的稳定与高效运维。