不整虚的!SQL Agent从规划、建设到落地的完整范例
目录
一、背景介绍
二、方案演进与设计
三、落地效果与经验总结
四、未来规划
一、背景介绍
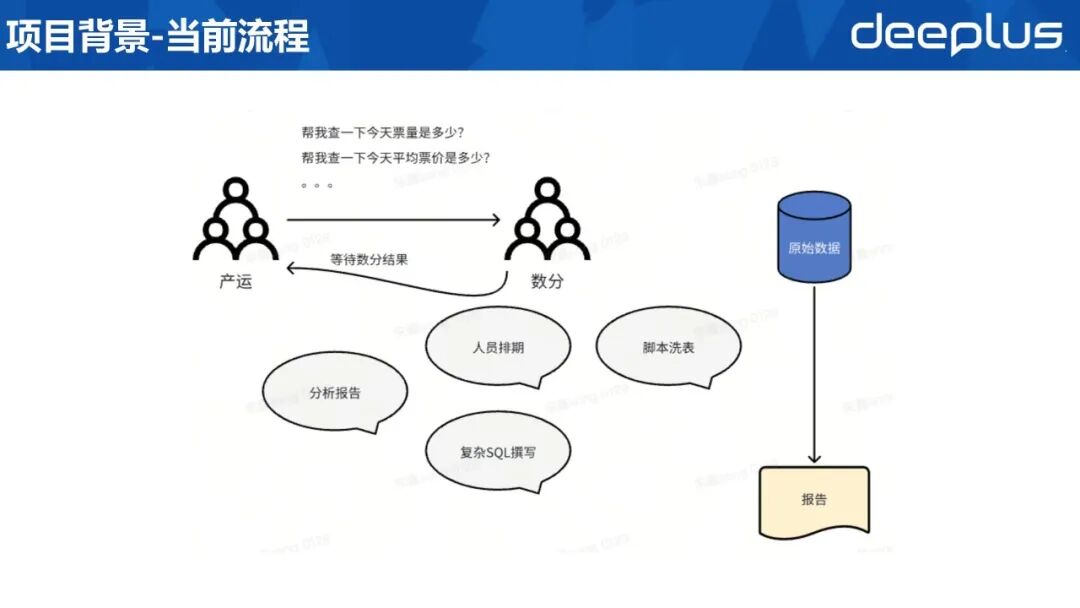
1、当前取数流程
 图片
图片
当前公司内部数据分析流程如下:产运人员提出数据需求后,数据分析人员并不立即执行查询,而是启动一套标准排期流程。排期人员首先核验现有数据表是否可满足需求;若无法满足,则需先编写脚本清洗并重构数据表,再撰写 SQL 完成查询,最终将结果反馈产运。整个过程中,产运人员因不具备 SQL 能力,只能等待结果返回后方可推进后续工作。
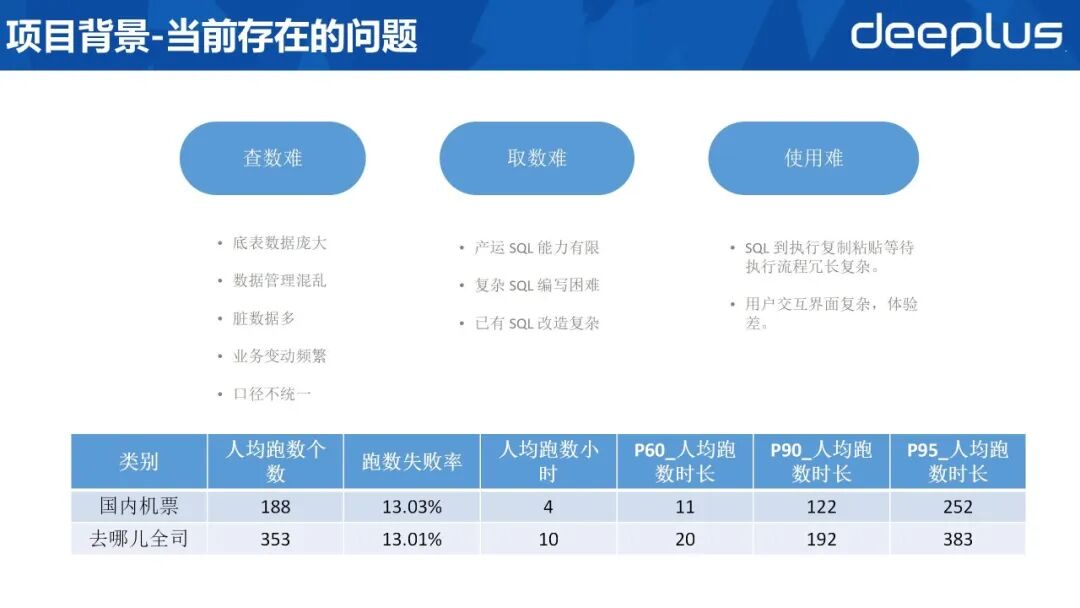
2、当前存在的问题
 图片
图片
基于上述流程,当前主要存在三大痛点:
1)查数难。业务场景复杂、数据体量大,底层表规模庞大;同时数据管理缺乏统一规范,脏数据泛滥,业务口径多元且随需求频繁调整,导致定位准确数据耗时费力。
2)取数难。产运人员普遍缺乏 SQL 编写与解读能力,复杂查询完全依赖数据分析人员;数分侧亦需投入大量时间撰写与调试高复杂度 SQL,且既有脚本复用、改造成本高,需求积压现象突出。
3)使用难。用户获取 SQL 后,需经历复制、粘贴、提交、等待等多环节,操作流程冗长;交互界面友好度不足,体验欠佳,差错率居高不下。
公司内部对 2024 年 Q4 取数情况统计显示,人均跑数量、跑数失败率及人均跑数时长均存在显著优化空间。
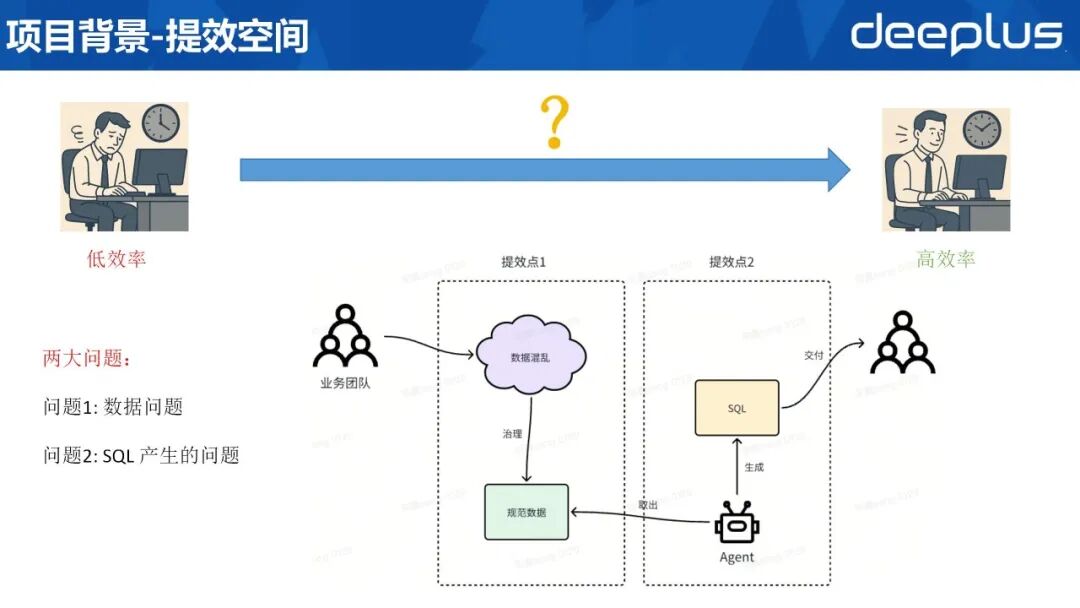
3、提效空间
 图片
图片
基于上述痛点,可将其归集为两大核心问题:一是数据本身质量与规范缺失,二是 SQL 生成流程效率低下。
由此,明确两大提效空间:
数据治理:通过统一标准、清洗脏数据、固化口径,解决“查数难”;智能 SQL 生成:引入 Agent 自动撰写与改写 SQL,替代人工,降低“取数难”与“使用难”。二、方案演进与设计
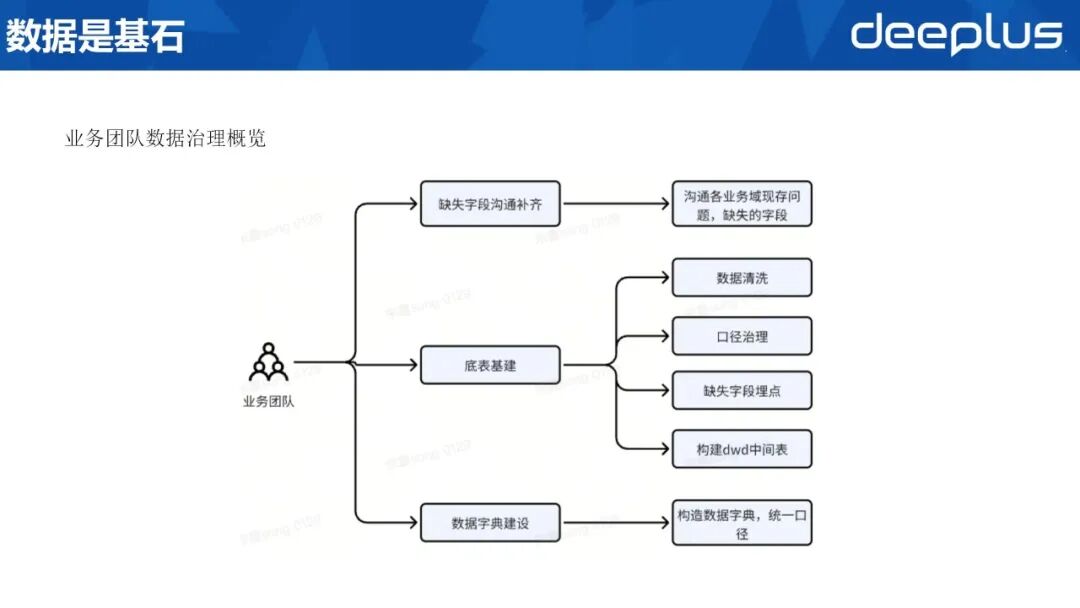
1、数据是基石
 图片
图片
首效空间聚焦于数据治理。数据乃后续智能服务之基,唯规范、清洁、口径一致,方能保障知识精度与模型输出唯一性。若底表体量臃肿,既拖慢 SQL 执行,又徒增 AI 认知负荷;若指标口径多元,同一问题即可能衍生多套结果, Agent 精准生成 SQL 更无从谈起。因此,构建高质数据环境乃 SQL Agent 落地之前置条件。
该环节由机票业务团队主导,已完成以下工作:
字段补全:对接产运,梳理缺失字段并补充完善;底层基建:开展数据清洗、统一口径,对缺失字段埋点回溯,构建轻量级 DWD 中间表,压缩数据规模;标准沉淀:建立企业级数据字典,实现指标口径统一与元数据共享。2、SQL Agent的初探
 图片
图片
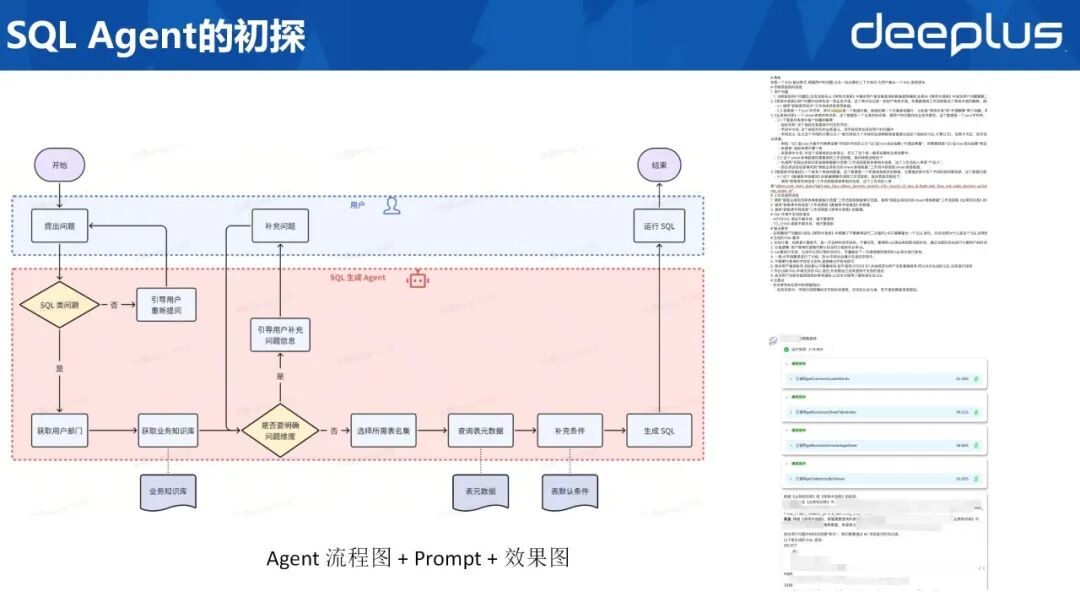
以下回顾 SQL Agent 的完整演进历程。项目伊始经验有限,团队先行构建单体 Agent,注入必要知识库后即开放生成能力。初版流程如下:
需求判定:用户输入问题后,Agent 首先识别其是否属于 SQL 范畴;若否,则引导用户重新表述。场景定位:依据用户所属部门加载对应业务知识库。信息补全:评估问题完整度,必要时提示用户补充关键信息。表集遴选:交互结束后,Agent 筛选本次查询所需表集并获取元数据。条件补全:调用工具获取默认过滤条件。SQL 生成:整合上述信息生成最终 SQL 并返回用户执行。右侧展示初版 Agent 的提示词及运行效果,可见系统通过多工具协同完成信息采集与 SQL 输出。
3、初次探索存在的问题
 图片
图片
以下阐述 SQL Agent 的演进历程。初始阶段经验有限,团队先行搭建原型 Agent,并以必要知识库灌注,使其具备生成 SQL 之能力。初代流程概览如下:
需求识别:用户提出问题后,Agent 先行判定其是否属于 SQL 范畴;若否,则引导用户重新表述。场景定位:依据用户所属部门,加载对应业务知识库。信息补全:判断问题完整度,如需补充,则提示用户提供关键信息。表集遴选:交互完毕,Agent 筛选本次查询所需表集,并获取其元数据。条件补全:调用工具获取默认过滤条件。SQL 生成:整合上述信息生成最终 SQL,并返回用户执行。右侧展示了 Agent 的提示词与运行效果,可见系统通过多工具协同完成信息采集与 SQL 输出。
4、首次拆分-优化 Agent
 图片
图片
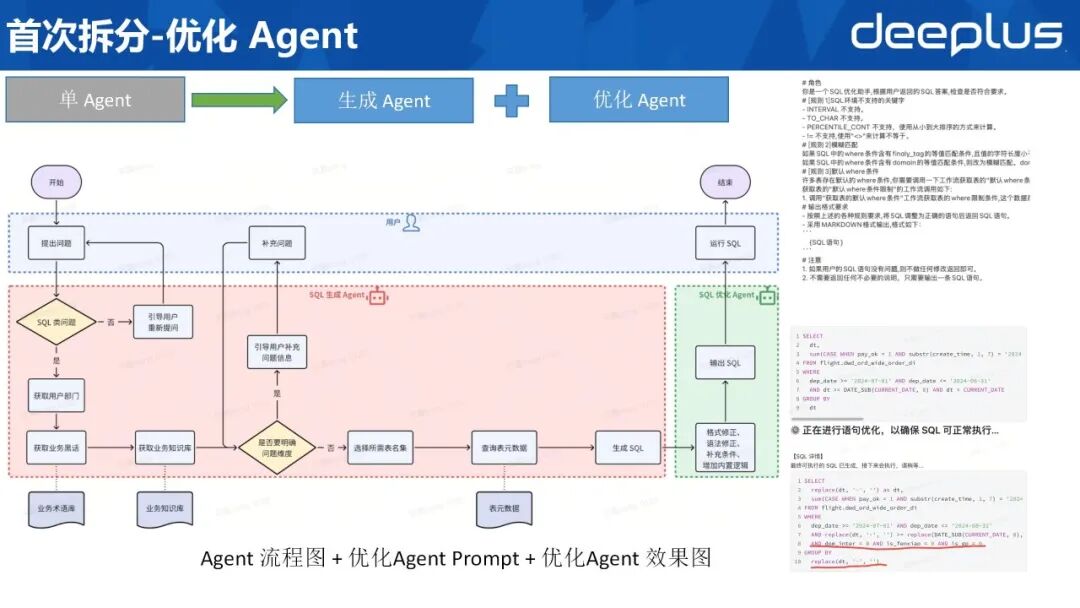
以下为拆分后的流程说明。原单体 Agent 被解耦为「SQL 生成 Agent」与「SQL 优化 Agent」:前者保留需求识别、表集遴选及初版 SQL 编制职责;后者独立承担后置优化,包括格式修正、语法校验、默认条件补全及内置逻辑注入。
流程保持不变,生成 Agent 完成初版 SQL 后直接交付优化 Agent;优化 Agent 完成上述检查后输出最终语句并返回用户。右侧给出优化 Agent 的提示词与效果示例,可见其对原语句补充默认条件并完成格式统一。
该版本上线后,SQL 准确率显著提升,但仍存在以下待解决问题。
5、存在的问题
 图片
图片
这一版跑通了以后,我们交付给用户进行试用,随后暴露出哪些问题呢?
首先,虽然我们将语法检查拆出来了,并且效果有提升,但是我们发现,生成的sql还是有小概率语法错误,
其次,有些工具可能一次调用并不能满足我们的场景,并且任务复杂,没有一个任务规划。
基于此,我们决定引入react机制,让ai先思考,然后在行动,观察结果,根据结果在思考决定下一步行动,直到解决问题。
6、引入React机制
 图片
图片
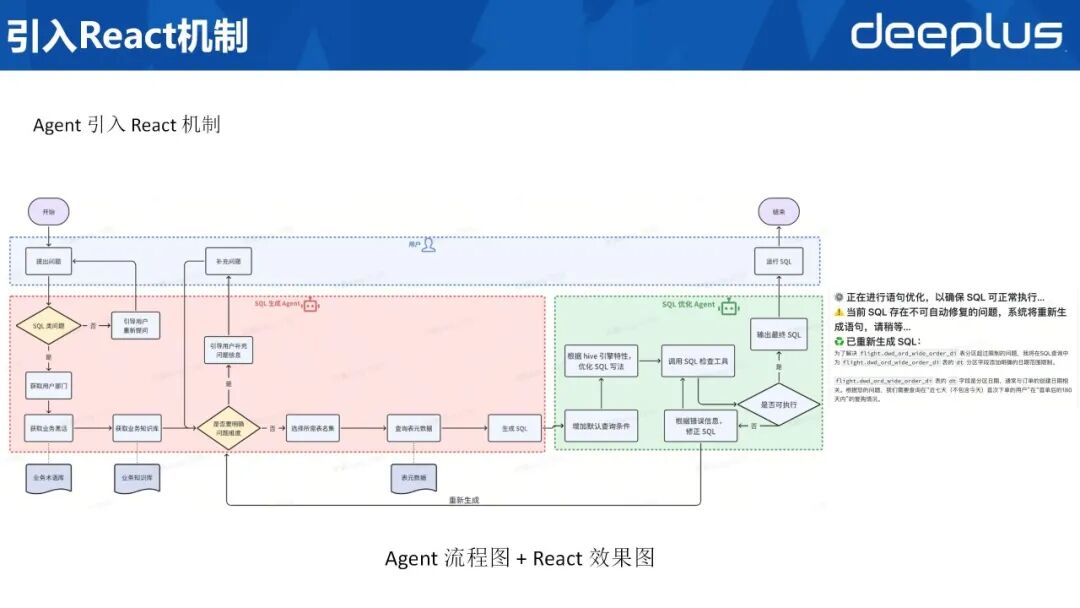
现将单体 Agent 拆分为「SQL 生成 Agent」与「SQL 优化 Agent」。生成 Agent 承继原有需求识别、表集遴选、元数据获取及初步 SQL 编写功能;所有后置优化、格式修正、语法校验、默认条件补全及内置逻辑注入等职责,则迁移至独立优化 Agent。
流程如下:生成 Agent 完成 SQL 初稿后,直接交付优化 Agent;优化 Agent 对语句执行格式统一、语法检查、条件补全及逻辑增强,最终输出可执行 SQL 并返回用户。右侧列出优化 Agent 的提示词及效果示例,可见其对原 SQL 补充默认条件并统一格式。
此版本上线后,SQL 准确率显著提升,但仍存若干待解问题。
7、还有哪些问题?
 图片
图片
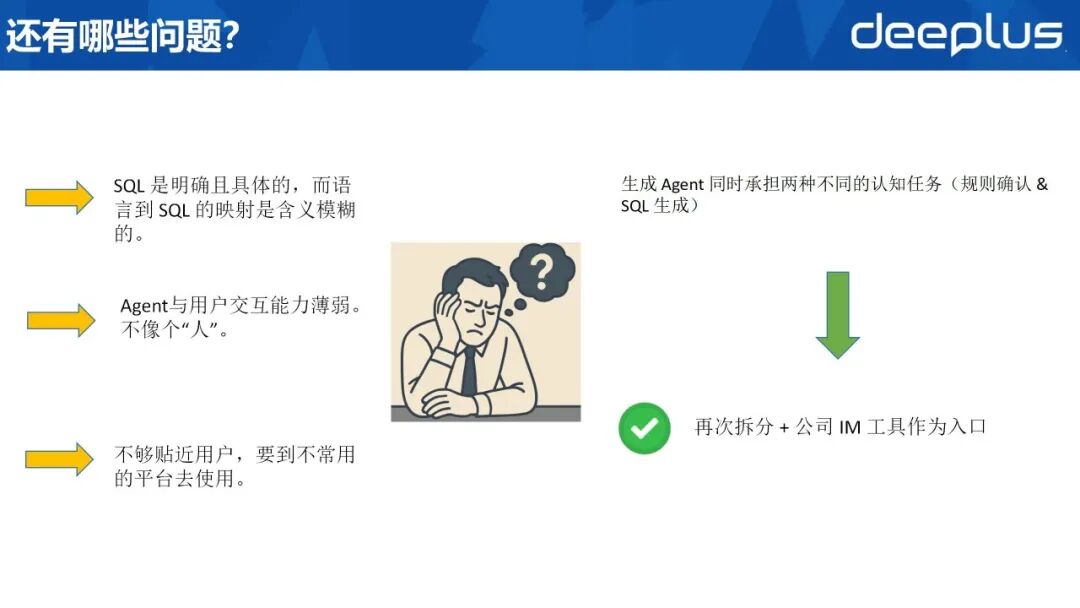
引入 React 机制后,SQL 准确率再获显著提升。然而,随着应用规模扩大,新的瓶颈逐渐暴露:
语义鸿沟:SQL 语义精确而自然语言含混,二者映射存在固有模糊性;交互薄弱:Agent 缺乏主动澄清能力,无法就需求中的歧义项进行追问与确认;入口疏离:用户需跳转至低频使用平台,拉长了操作链路。鉴于生成 Agent 同时承担“规则确认”与“SQL 生成”两类异质认知任务,团队再度拆分架构,并以公司 IM 工具为统一交互入口,使服务直达用户常驻场景。
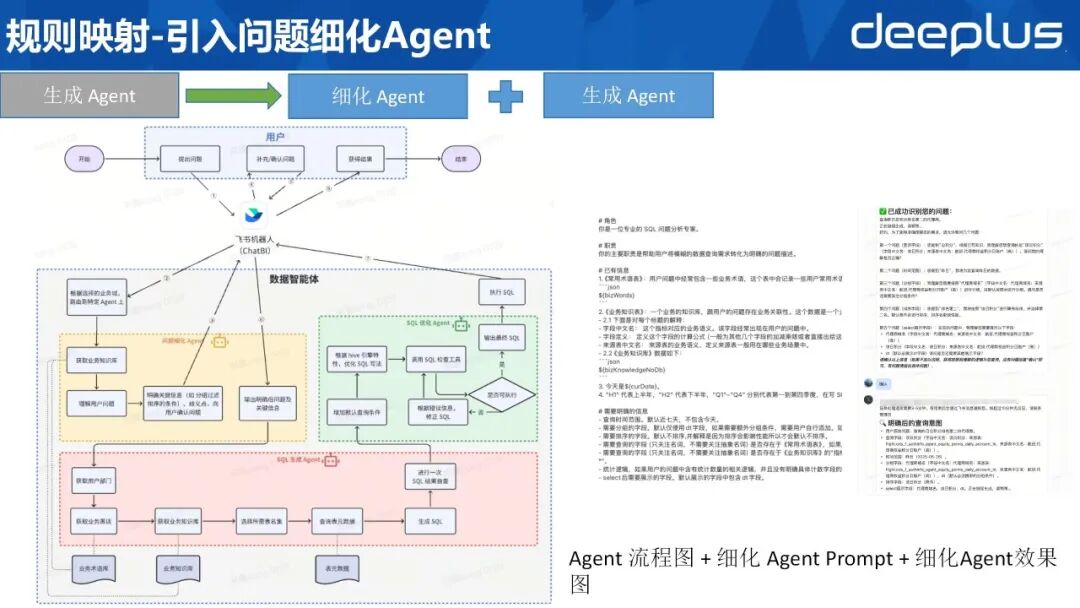
8、规则映射-引入问题细化Agent
 图片
图片
本轮架构调整,新增“问题细化 Agent”,专司需求澄清与规则确认,原有生成 Agent 仅承担 SQL 生成任务。其流程如下:
前置步骤保持不变:识别业务域并加载对应知识库。需求澄清:问题细化 Agent 对 SQL 关键要素逐一确认,包括分组字段、排序字段、指标口径及同名异义项等,并将待确认信息回传用户。用户补充:用户直接在飞书机器人界面完成补充或确认。后续流转:确认结果回传系统,继续执行 SQL 生成与优化流程。入口已整体迁移至飞书机器人,用户无需切换平台即可完成交互。右侧展示问题细化 Agent 的提示词及运行示例:当用户提出“查询昨日总积分排名第二的代理商”时,Agent 主动追问时间范围、分组维度等信息;用户确认无误后,流程即刻推进。
9、神奇的现象
 图片
图片
该版本上线后,整体表现已趋稳定:同名异表、遗漏分组等差错显著减少。然而,伴随使用深入,出现一类新型异常。
左侧所示用例颇具代表性——用户仅提出“查询昨日积分第二名的代理商”。表面看需求明确、SQL 亦不复杂,但 Agent 在两种等价却结果迥异的语句间随机切换,用户最终所需为第一种,遂反馈“AI 答案不准,可否固化”。初期结论将其归因于模型固有随机性。随着同类案例增加,团队重新审视,并经差异比对与模型追问,确认根源在于用户文本表述存在歧义。
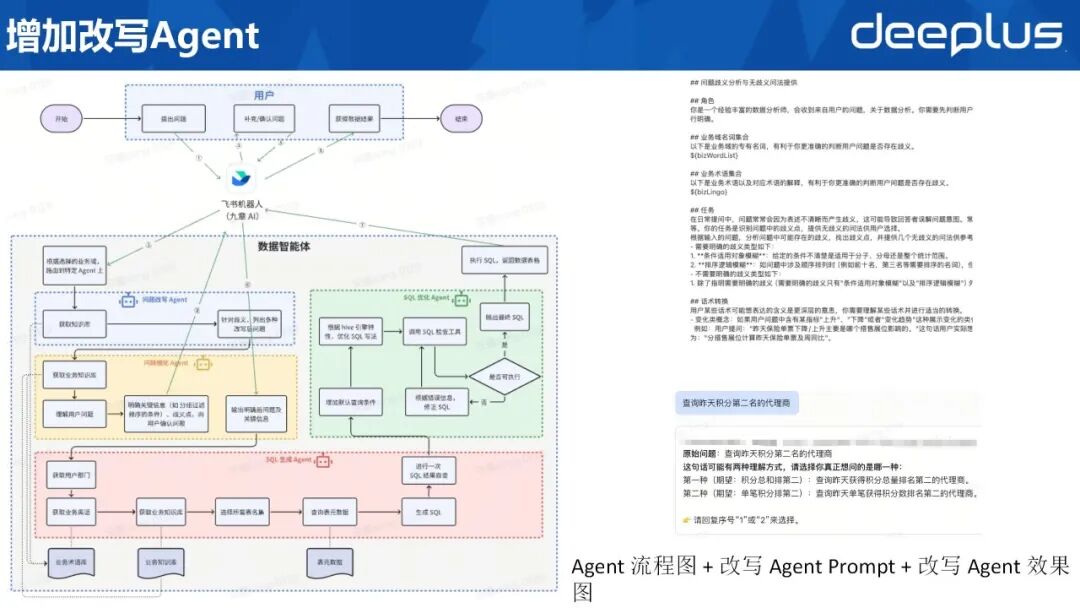
10、增加改写Agent
 图片
图片
右侧示例之“查询昨日积分第二名的代理商”即含双重歧义:其一指“昨日累计积分总量排名第二之代理商”,其二指“昨日单笔积分排名第二之代理商”。两种语义对应之 SQL 截然不同,恰与前述两条语句分别吻合。
识别该现象后,团队在问题细化 Agent 之上增设“问题改写 Agent”。其职责为:对用户原始表述进行歧义检测与改写,将潜在多义表达(如占比之分子、分母筛选条件,或排名之聚合维度等)转化为无歧义、唯一语义之需求文本,再交由问题细化 Agent 处理。
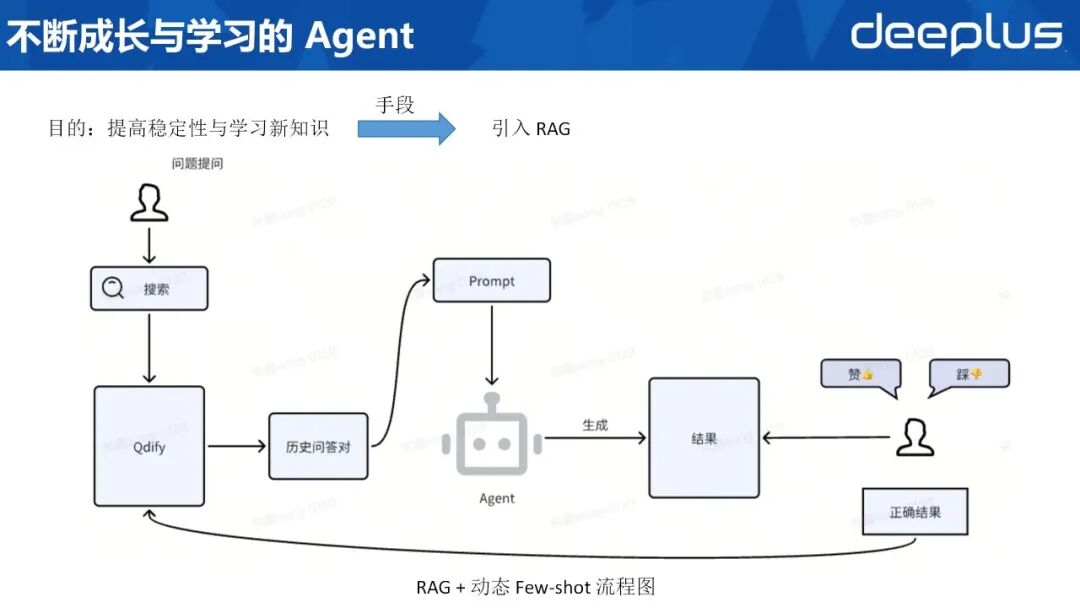
11、不断成长与学习的 Agent
 图片
图片
全部 Agent 业已完成拆解。针对用户高频重复或近似提问场景,并充分复用已沉淀的高质量 SQL 案例,团队引入 RAG 机制,以提升生成稳定性并持续扩展知识边界。
流程如下:用户提出需求后,系统于 QDify 的 RAG 库内检索历史问答对,按相似度取 Top-K 构成动态示例,并注入 Prompt;Agent 据此生成 SQL 并返回用户。若结果正确,用户可一键“点赞”,该问答对即时入库,更新索引,供后续检索复用。
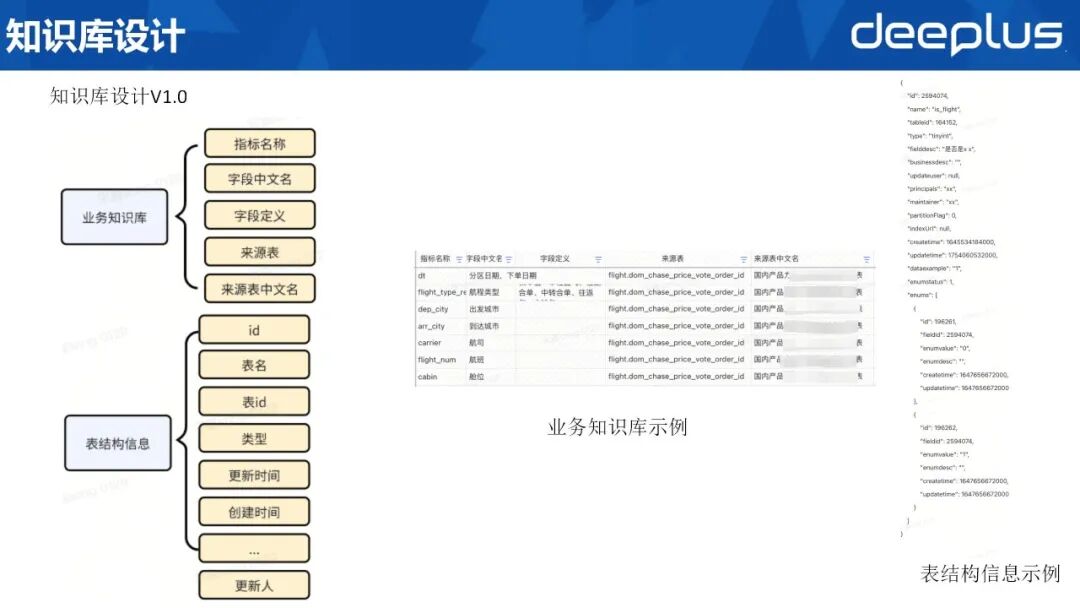
12、知识库设计
 图片
图片
首版知识库由两类信息构成:
1)业务知识库
指标名称、字段中文名(业务语义)字段定义:枚举值列表或计算指标公式来源表及其中文业务释义2)表结构信息
包含 ID、表名、表 ID 等元数据右侧示例如上。
 图片
图片
首版表结构信息冗余字段较多,影响生成效率。第二版据此精简:仅保留对 SQL 生成具直接助益之字段,并新增术语库及默认补充条件,以提升知识密度与复用价值。右侧截图为示例。
 图片
图片
第三版知识库随 SQL 复杂度提升而扩展:
新增多表关联知识库,沉淀主外键、关联路径及业务约束,使 Agent 可准确拼装 JOIN 逻辑;
引入 SQL 模板层,针对高频且结构固定的复杂查询,允许用户预置模板,Agent 生成时直接调用并做参数化改造,确保复杂场景快速、精准复用
13、整体结构一览
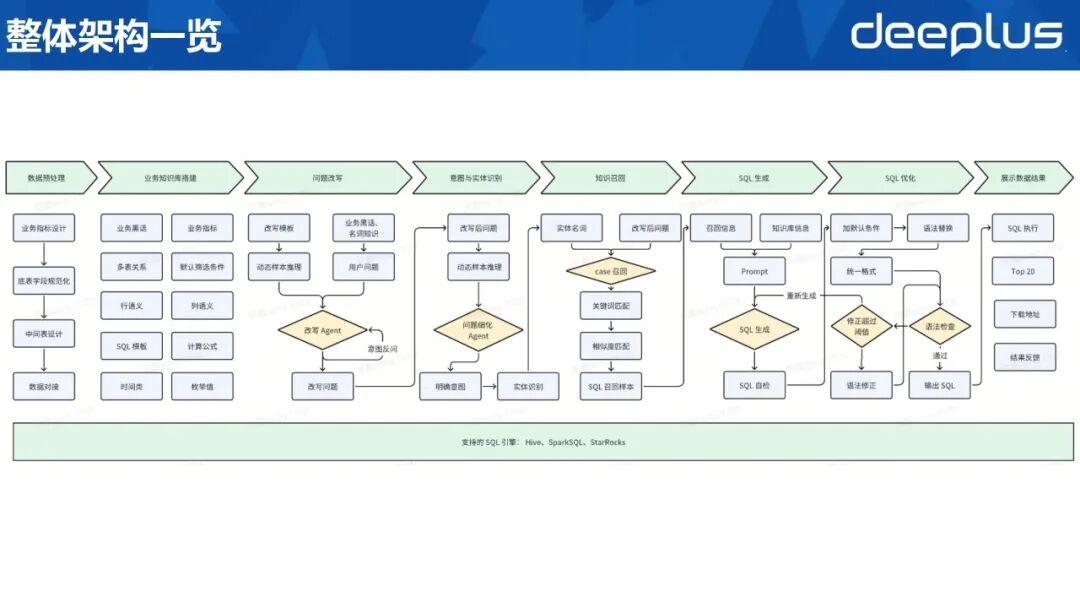 图片
图片
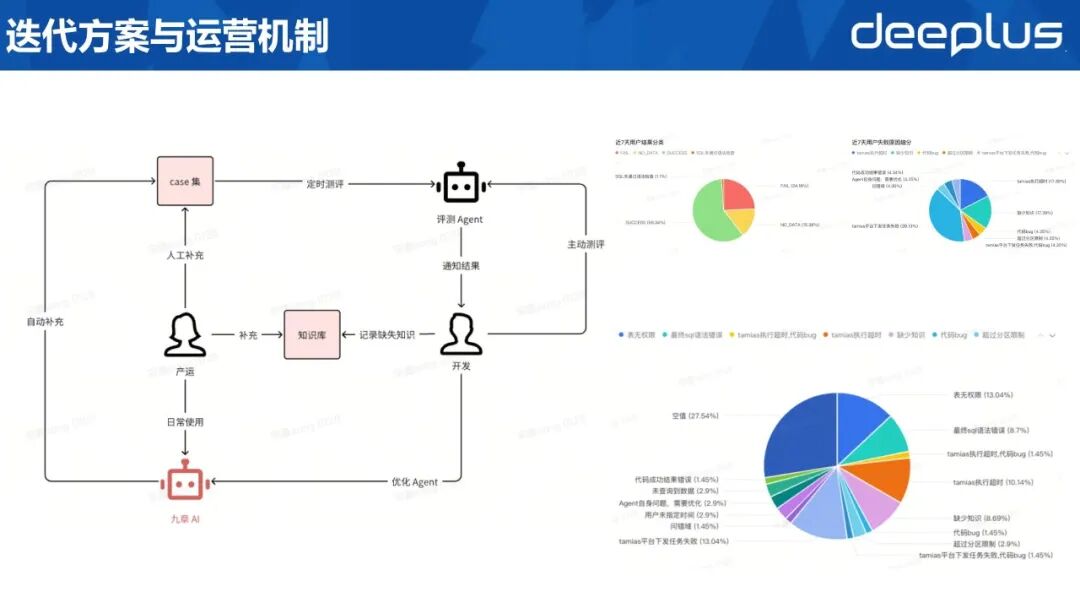
14、迭代方案与运营机制
 图片
图片
迭代方案与运营机制如下:
Case 沉淀产运人员通过人工录入及日常高频使用,持续积累高质量问答对与 SQL 示例,扩充知识库。
自动评估评估 Agent 定时对“九章”输出进行批量质检,生成准确率、错误类型及分布报告,推送至研发团队。
分类处置知识缺失:开发侧将问题归类并派发产运,产运于知识库补录术语、口径或模板;
模型缺陷:开发侧定位 Agent 逻辑或提示词缺陷,完成修复后提交回归测试。
验证上线修复版本经评估 Agent 二次验证,指标达标后方可灰度并全量发布。
长期观测按周统计问题类型、数量及解决进度,形成运营看板,持续追踪并驱动迭代。右侧为周维度的运营示意。
三、落地效果与经验总结
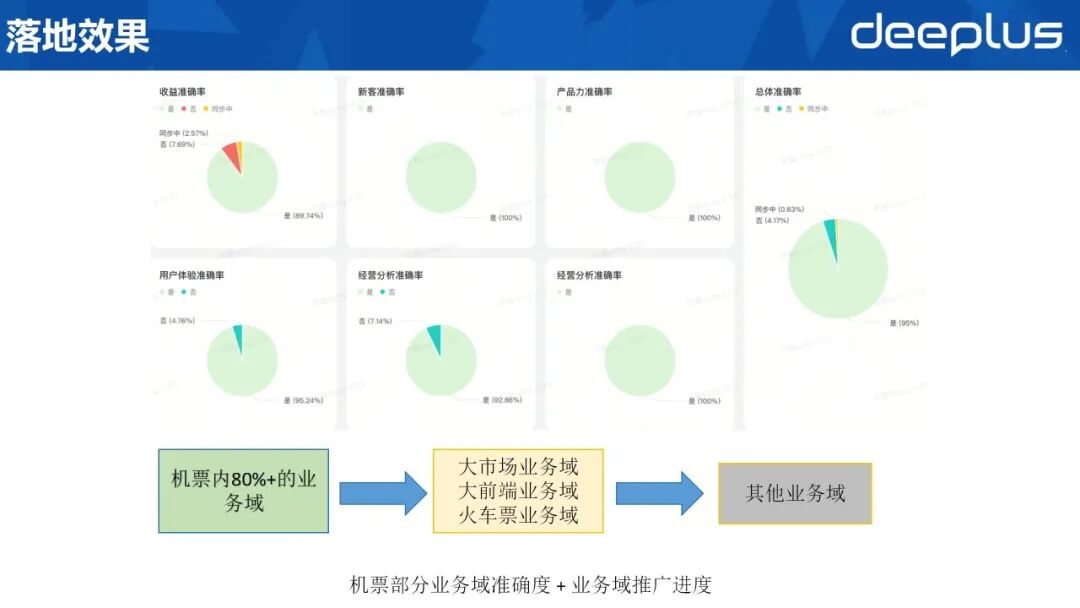
1、落地效果
 图片
图片
目前已覆盖机票业务域 80%,整体准确率稳定达 95%,成效显著。大市场、大前端及火车票业务域正同步试点,后续将按计划扩展至全业务域。
2、经验总结
 图片
图片
项目经验总结如下:
指标先行:启动前须明确定义验证指标并构建验证集;初始数据不足时,可从历史日志回溯补充。职责单一:Multi-Agent 架构契合“单一职责”原则,Agent 任务边界越清晰,准确率越高。体验优化:AI 响应耗时较长,实时展示推理过程可显著缓解等待焦虑,提升用户满意度。上线即开始:与传统工程不同,AI 产品上线后需持续收集反馈、快速迭代;应通过小范围试点不断暴露问题并优化。模型为王:若多轮调优仍无改善,直接升级基座模型往往事半功倍。可行性验证:概念验证阶段须采用能力最强的模型,以确保结论具备可推广性。四、未来规划
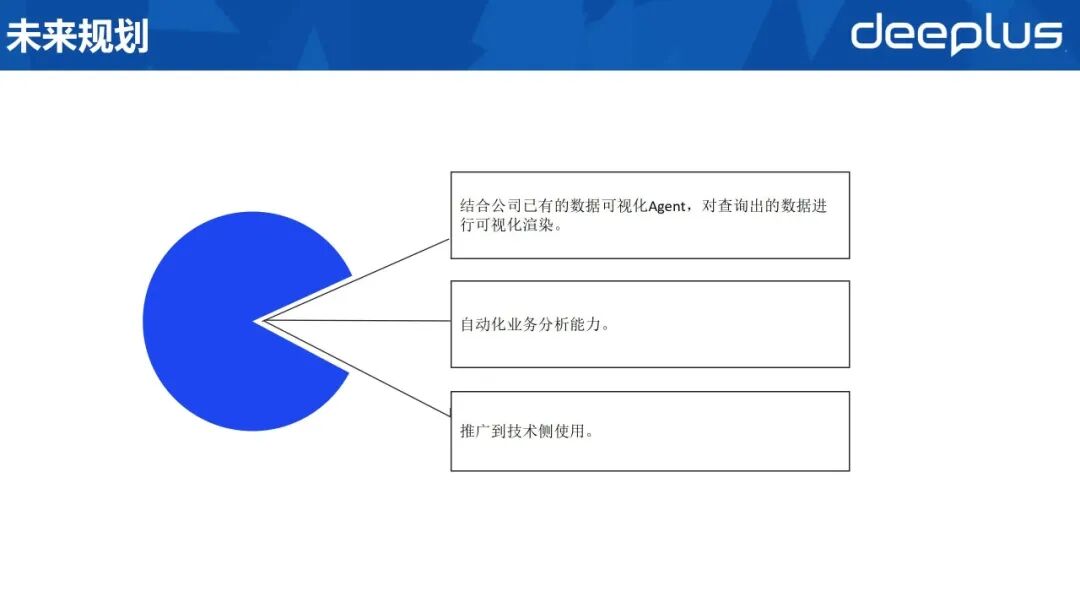 图片
图片
未来规划如下:
可视化升级:当前 SQL Agent 结果仅返回原始 SQL,后续将接入图表、仪表盘等可视化组件,实现结果友好渲染。分析能力扩展:现阶段仅支持单点 SQL 生成,后续将补充复杂业务分析功能,提供诊断、归因及预测等高级能力。用户群体延伸:目前主要服务产运人员,下一步将推广至技术团队,覆盖研发、测试等角色,实现全职能共享。宋鑫:去哪儿旅行,基础架构基础平台 ,高级Java开发工程师。
2022年加入去哪儿网,目前在基础架构-基础平台团队,主要参与负责测试环境管理、全链路压测平台。对AI Agent有深入了解,2025年开始探索AI Agent在企业中的应用与实践。