作者 | frostchen

导语
Linux下开发者习惯在物理机或者虚拟机环境下使用top和free等命令查看机器和进程的内存使用量,近年来越来越多的应用服务完成了微服务容器化改造,过去查看、监控和定位内存使用量的方法似乎时常不太奏效。如果你的应用程序刚刚迁移到K8s中,经常被诸如以下问题所困扰:容器的内存使用率为啥总是接近99%?malloc/free配对没问题,内存使用量却一直上涨?内存使用量超过了限制量却没有被OOM Kill? 登录容器执行top,free看到的输出和平台监控视图完全对不上?... 本文假设读者熟悉Linux环境,拥有常见后端开发语言(C/C++ /Go/Java等)使用经验,希望后面的内容能在读者面临此类疑惑时提供一些有效思路。
K8s中监控数据主要来源是 cadvisor, 容器内存使用量的相关指标有以下:
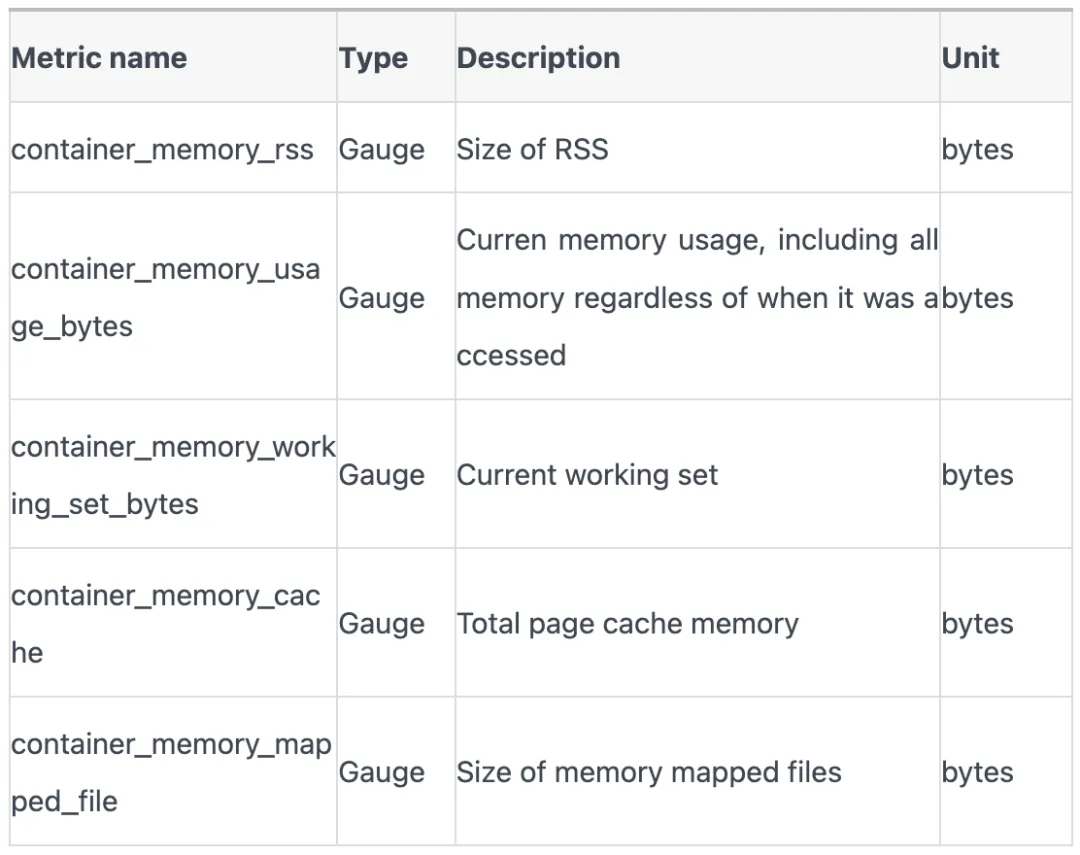
这些指标究竟是什么含义?在不同的应用场景下需要重点关注哪些指标?让我们从回顾linux进程地址空间开始,逐步挖掘容器内存使用奥秘。
一、进程是怎么分配内存的?
回忆一下linux进程虚拟地址空间分布图。
复制
+-------------------------------+ 0xFFFFFFFFFFFFFFFF (64-bit)
| Kernel Space | 内核空间,用于操作系统内核和内核模块
+-------------------------------+ 0x00007FFFFFFFFFFF
| User Space | 用户空间进程的虚拟地址空间
| Shared Libraries | 动态加载的共享库 (.so 文件)
+-------------------------------+ 0x00007FFFC0000000
| Heap | 动态内存分配区域 (malloc, calloc, realloc)
| (malloc, etc.) | 堆的大小可以动态增长或收缩
+-------------------------------+ 0x00007FFFB0000000
| BSS Segment | 未初始化的全局变量和静态变量
| (Uninitialized Data) | 在程序启动时被初始化为零
+-------------------------------+ 0x00007FFFA0000000
| Data Segment | 已初始化的全局变量和静态变量
| (Initialized Data) | 在程序启动时被初始化为特定的值
+-------------------------------+ 0x00007FFF90000000
| Text Segment | 可执行代码段
| (Code) | 通常是只读的,以防止代码被意外修改
+-------------------------------+ 0x00007FFF80000000
| Stack | 用于存储函数调用的局部变量、参数和返回地址
| | 栈通常从高地址向低地址增长
+-------------------------------+ 0x00000000000000001.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.
在linux内核里描述上述图的结构是mm_struct,它还可以展开得更详细:
复制
+-------------------------------+
| task_struct (/bin/gonzo) |
| |
| mm |
| | |
| v |
| +---------------------------+ |
| | mm_struct | |
| | | |
| | mmap | |
| | | | |
| | v | |
| | +-----------------------+ | |
| | | vm_area_struct | | |
| | | VM_READ | VM_EXEC | | |
| | |-----------------------| | |
| | | Text (file-backed) | | |
| | +-----------------------+ | |
| | | | |
| | v | |
| | +-----------------------+ | |
| | | vm_area_struct | | |
| | | VM_READ | VM_WRITE | | |
| | |-----------------------| | |
| | | Data (file-backed) | | |
| | +-----------------------+ | |
| | | | |
| | v | |
| | +-----------------------+ | |
| | | vm_area_struct | | |
| | | VM_READ | VM_WRITE | | |
| | |-----------------------| | |
| | | BSS (anonymous) | | |
| | +-----------------------+ | |
| | | | |
| | v | |
| | +-----------------------+ | |
| | | vm_area_struct | | |
| | | VM_READ | VM_WRITE | | |
| | |-----------------------| | |
| | | Heap (anonymous) | | |
| | +-----------------------+ | |
| | | | |
| | v | |
| | +-----------------------+ | |
| | | vm_area_struct | | |
| | | VM_READ | VM_EXEC | | |
| | |-----------------------| | |
| | | Memory mapping | | |
| | +-----------------------+ | |
| | | | |
| | v | |
| | +-----------------------+ | |
| | | vm_area_struct | | |
| | | VM_READ | VM_WRITE | | |
| | | VM_GROWS_DOWN | | |
| | |-----------------------| | |
| | | Stack (anonymous) | | |
| | +-----------------------+ | |
| +---------------------------+ |+-------------------------------+1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.
可以发现,linux进程地址空间是由一个个vm_area_struct(vma)组成,每个vma都有自己地址区间。如果你的代码panic或者Segmentation Fault崩溃,最直接的原因就是你引用的指针值不在进程的任意一个vma区间内。你可以通过 /proc/<pid>/maps 来观察进程的vma分布。
1. malloc分配内存
malloc函数增大了进程虚拟地址空间的heap容量,扩大了mm描述符中vma的start和end长度,或者插入了新的vma;但是它刚完成调用后,并没有增大进程的实际内存使用量。
以下是个代码示例证明上述言论。
复制
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/resource.h>
#include <stdio.h>
#include <time.h>
const int64_t GB = 1024 * 1024 * 1024;
const int64_t MB = 1024 * 1024;
const int64_t KB = 1024;
void max_rss() {
struct rusage r_usage;
getrusage(RUSAGE_SELF, &r_usage);
printf("Current max rss %ld kb, pagefault minor %ld, major %ld\n",
r_usage.ru_maxrss, r_usage.ru_minflt, r_usage.ru_majflt);
}
int main() {
printf("Pid %lu\n", getpid());
int number = 128;
void *ptr = malloc(number * MB);
if (ptr == 0) {
printf("Out of memory\n");
exit(EXIT_FAILURE);
}
printf("Allocated %d MB memory by malloc(3), ptr %p\n", number, ptr);
max_rss();
sleep(60);
memset(ptr, 0, number * MB);
printf("Used %d MB memory by memset(3)\n", number);
max_rss();
sleep(60);
free(ptr);
printf("Memory ptr %p freed by free(3)\n", ptr);
max_rss();
sleep(60);
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.
可见输出:
复制
Pid 932451
Allocated 128 MB memory by malloc(3), ptr 0x7f3e6cdff010
Current max rss 3800 kb, pagefault minor 122, major 0
Used 128 MB memory by memset(3)
Current max rss 132732 kb, pagefault minor 187, major 0
Memory ptr 0x7f3e6cdff010 freed by free(3)Current max rss 132732 kb, pagefault minor 187, major 01.2.3.4.5.6.
阶段总结1
当memset 128MB长度的数据完成后,我们立刻观察到进程发生了32768次minor pagefault, 同时RSS内存占用提升到129MB。注意 32768 * 4096正好等于128MB,而4096正好是linux page默认大小。可以在程序sleep的时段用top观察监控统计进一步证实结论。
进一步说,malloc申请到的地址,在得到真实的使用之前,必须经历缺页中断,完成建立虚拟地址到物理地址的映射。完成物理页分配的虚拟地址空间才会被计算到内存使用量中。
二、container_memory_rss
1.. 进程的RSS
进程的RSS(Resident Set Size)是当前使用的实际物理内存大小,包括代码段、堆、栈和共享库等所使用的内存, 实际上就是页表中物理页部分的全部大小。
更精确地说,根据内核的 get_mm_rss, RSS由FilePages, AnnoPages和ShmemPages组成。
以下是一个例子,分别展示了这三种内存的申请和使用方式,FilePages, AnnoPages和ShmemPages 分别为4MiB, 8MiB和10MiB,供给22MiB.
复制
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/shm.h>
#include <fcntl.h>
#include <unistd.h>
#include <string.h>
#define FILE_SIZE (4 * 1024 * 1024) // 4 MiB
#define ANON_SIZE (8 * 1024 * 1024) // 8 MiB
#define SHM_SIZE (10 * 1024 * 1024) // 10 MiB
void allocate_filepages() {
int fd = open("tempfile", O_RDWR | O_CREAT | O_TRUNC, 0600);
if (fd == -1) {
perror("open");
exit(EXIT_FAILURE);
}
if (ftruncate(fd, FILE_SIZE) == -1) {
perror("ftruncate");
close(fd);
exit(EXIT_FAILURE);
}
void *file_mem = mmap(NULL, FILE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (file_mem == MAP_FAILED) {
perror("mmap");
close(fd);
exit(EXIT_FAILURE);
}
memset(file_mem, 0, FILE_SIZE); // 使用内存
printf("Allocated %d MiB of file-mapped memory\n", FILE_SIZE / (1024 * 1024));
// 保持映射,直到程序结束
// munmap(file_mem, FILE_SIZE);
// close(fd);
// unlink("tempfile");
}
void allocate_anonpages() {
void *anon_mem = malloc(ANON_SIZE);
if (anon_mem == NULL) {
perror("malloc");
exit(EXIT_FAILURE);
}
memset(anon_mem, 0, ANON_SIZE); // 使用内存
printf("Allocated %d MiB of anonymous memory\n", ANON_SIZE / (1024 * 1024));
// free(anno_mem);
}
void allocate_shmempages() {
int shmid = shmget(IPC_PRIVATE, SHM_SIZE, IPC_CREAT | 0600);
if (shmid == -1) {
perror("shmget");
exit(EXIT_FAILURE);
}
void *shm_mem = shmat(shmid, NULL, 0);
if (shm_mem == (void *)-1) {
perror("shmat");
shmctl(shmid, IPC_RMID, NULL);
exit(EXIT_FAILURE);
}
memset(shm_mem, 0, SHM_SIZE); // 使用内存
printf("Allocated %d MiB of shared memory\n", SHM_SIZE / (1024 * 1024));
// 保持映射,直到程序结束
// shmdt(shm_mem);
// shmctl(shmid, IPC_RMID, NULL);
}
int main() {
printf("Process %d\n", getpid());
allocate_filepages();
allocate_anonpages();
allocate_shmempages();
sleep(3600);
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.
观察top -p $pid的输出:
复制
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3881259 root 20 0 28540 24184 15872 S 0.0 0.1 0:00.01 a.out1.2.
通过top发现,进程的RSS 是24184KiB, 比我们申请的22MiB,也就是22528KiB, 要大1656KiB。
进一步观察/proc/$pid/status,发现:
复制
....
VmRSS: 24184 kB
RssAnon: 8312 kB
RssFile: 5632 kB
RssShmem: 10240 kB
VmData: 8436 kB
VmStk: 132 kB
VmExe: 4 kB
VmLib: 1576 kB
VmPTE: 100 kB
VmSwap: 0 kB
....1.2.3.4.5.6.7.8.9.10.11.12.
VmRSS和top里看到RES完全一致。RssAnno 比8092KiB多了120KiB,因为它还包括了stack。RssFile比 4096KiB多了1536KiB,因为它还包括了共享库。内核mm_struct计数并不总是完全及时和精准的。
阶段总结2
进程RSS组成
描述
匿名页
通常来源于 malloc,进入 brk 或者 mmap 匿名映射
共享内存
来自 shmget 系列调用
mmap 文件映射
通过 mmap 调用映射文件到进程地址空间
栈 (stack)
进程的调用栈
二进制文件
加载进程本身的二进制文件占用的内存
动态链接库
加载的动态链接库(共享库)占用的内存
页表
内核中存储页表的部分
2. 容器(memcg)的RSS
K8s容器环境下,容器里的进程都归属同一个cgroup控制组,本文只关注内存控制组(memcg)。把刚才的代码做成容器镜像,部署在TKEx环境里, 观察容器内存使用相关指标。

观察到container_memory_rss只有2047 * 4096 Bytes, 略小于8MiB, 远远低于上一节top观察到的24MiB,这是为什么?
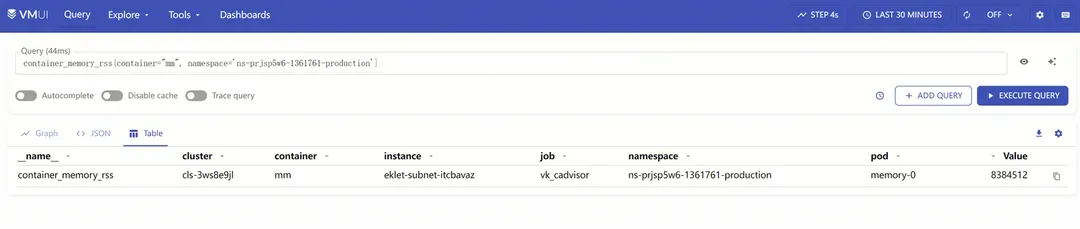
1.1中通过观察/proc/$pid/status和top的输出,我们得出了进程的RSS估算方法,即:
占主要部分的 malloc导致的匿名页(brk/mmap匿名映射) + 使用shmem共享内存 + mmap文件映射;stack部分,text部分和动态链接库部分,页表部分,通常占比很小。
那memory cgroup的RSS的计算方法是不是就是简单地把memcg下归属的所有的进程RSS简单求和呢?显然不是。通过追溯cadvisor相关代码, 发现这个数值来来自容器所属cgroup path下的memory.stat文本中的rss字段。
(1) 如何找到容器对应的memcg path?
每个容器的 Memory Cgroup 路径根据其 QoS 类别和唯一标识符来确定。路径的基本格式如下:
Burstable:
复制
/sys/fs/cgroup/memory/kubepods/burstable/pod<uid>/<container-id>1.
BestEffort:
复制
/memory/kubepods/besteffort/pod<uid>/<container-id>1.
Guaranteed:
复制
/sys/fs/cgroup/memory/kubepods/pod<uid>/<container-id>1.
可以通过查看Pod Yaml里的Status来确认Pod的Qos类别。
找到memcg path后,可以发现目录下有很多记录文件,这里关注memory.stat:
复制
root@memory-0:~# ls /sys/fs/cgroup/memory/kubepods/burstable/pod2d08e58b-50f7-41fa-bd42-946402c34646/b366c08f2ecedd6acdb38e4ec24913aea0ca3babeed297abbcfafafa4e8027de
cgroup.clone_children memory.bind_blkio memory.kmem.tcp.max_usage_in_bytes memory.memsw.max_usage_in_bytes memory.pressure memory.usage_in_bytes
cgroup.event_control memory.failcnt memory.kmem.tcp.usage_in_bytes memory.memsw.usage_in_bytes memory.pressure_level memory.use_hierarchy
cgroup.priority memory.force_empty memory.kmem.usage_in_bytes memory.move_charge_at_immigrate memory.priority_wmark_ratio memory.use_priority_oom
cgroup.procs memory.kmem.failcnt memory.limit_in_bytes memory.numa_stat memory.sli memory.vmstat
memory.alloc_bps memory.kmem.limit_in_bytes memory.max_usage_in_bytes memory.oom.group memory.sli_max notify_on_release
memory.async_distance_factor memory.kmem.max_usage_in_bytes memory.meminfo memory.oom_control memory.soft_limit_in_bytes tasks
memory.async_high memory.kmem.slabinfo memory.meminfo_recursive memory.pagecache.current memory.stat
memory.async_low memory.kmem.tcp.failcnt memory.memsw.failcnt memory.pagecache.max_ratio memory.swappiness
memory.async_ratio memory.kmem.tcp.limit_in_bytes memory.memsw.limit_in_bytes memory.pagecache.reclaim_ratio memory.sync1.2.3.4.5.6.7.8.9.10.
(2) memory.stat里的 rss 是怎么计算的?
追溯linux memory cgroup(后面记做memcg)的相关源码,memcg统计了以下内存使用:
复制
static const unsigned int memcg1_stats[] = {
MEMCG_CACHE,
MEMCG_RSS,
MEMCG_RSS_HUGE,
NR_SHMEM,
NR_FILE_MAPPED,
NR_FILE_DIRTY,
NR_WRITEBACK,
MEMCG_SWAP,
};1.2.3.4.5.6.7.8.9.10.
跟踪MEMCG_RSS的记录情况,发现只有匿名页的数量被统计到MEMCG_RSS里,这和前面观察的进程的RSS不一样。共享内存page只被计入MEMCG_CACHE,即便它位于匿名LRU。
复制
static void mem_cgroup_charge_statistics(struct mem_cgroup *memcg,
struct page *page,
bool compound, int nr_pages)
{
/*
* Here, RSS means mapped anon and anons SwapCache. Shmem/tmpfs is
* counted as CACHE even if its on ANON LRU.
*/
if (PageAnon(page))
__mod_memcg_state(memcg, MEMCG_RSS, nr_pages);
else {
__mod_memcg_state(memcg, MEMCG_CACHE, nr_pages);
if (PageSwapBacked(page))
__mod_memcg_state(memcg, NR_SHMEM, nr_pages);
}
....
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.
而我们之前观察到 container_memory_cache接近14MiB, 包括了Shmem和mmap文件映射的部分。这样得出的结论是,memory cgroup的RSS只统计了上述代码中malloc分配出的内存,不包含另外两部分。
阶段总结3
类别
进程的 RSS
容器的 RSS
brk 分配
✔
✔
mmap 匿名映射
✔
✔
共享内存
✔
mmap 文件映射
✔
栈 (stack)
✔
✔
二进制文件
✔
✔
动态链接库
✔
✔
页表
✔
✔
三、container_memory_cache
1. 初识PageCache
Page cache 是操作系统内核用来缓存文件系统数据的一种机制。它通过将文件数据缓存到内存中,从而减少磁盘 I/O 操作,提高文件读取的性能。当应用程序读取文件时,内核会首先检查 page cache,如果数据已经在缓存中,则直接从内存中读取,避免了磁盘访问。
以下是一个C语言小程序来演示如何通过读写文件来产生PageCache, 这个程序写100MiB数据到指定的文本文件中。
复制
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#define BUFFER_SIZE 4096
#define FILE_SIZE_MB 100
void generate_page_cache(const char *filename) {
int fd;
char buffer[BUFFER_SIZE];
ssize_t bytes_written, bytes_read;
size_t total_bytes_written = 0;
// 初始化缓冲区
for (int i = 0; i < BUFFER_SIZE; i++) {
buffer[i] = A + (i % 26); // 填充缓冲区以生成一些数据
}
// 打开文件进行写操作
fd = open(filename, O_WRONLY | O_CREAT | O_TRUNC, S_IRUSR | S_IWUSR);
if (fd == -1) {
perror("open");
exit(EXIT_FAILURE);
}
// 写入文件,直到文件大小达到 FILE_SIZE_MB
while (total_bytes_written < FILE_SIZE_MB * 1024 * 1024) {
bytes_written = write(fd, buffer, BUFFER_SIZE);
if (bytes_written == -1) {
perror("write");
close(fd);
exit(EXIT_FAILURE);
}
total_bytes_written += bytes_written;
}
// 关闭文件
close(fd);
}
int main(int argc, char *argv[]) {
if (argc != 2) {
fprintf(stderr, "Usage: %s <filename>\n", argv[0]);
exit(EXIT_FAILURE);
}
generate_page_cache(argv[1]);
printf("Page cache generated for file: %s\n", argv[1]);
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.
在执行这个程序前,做一次drop cache操作,用来清理系统已有的pagecache:
复制
# sync && echo 3 > /proc/sys/vm/drop_caches1.
然后记录此时系统pagecache的信息。
复制
# free -m
total used free shared buff/cache available
Mem: 32096 2470 29742 872 1152 29626
Swap: 0 0 0
# cat /proc/meminfo
...
Buffers: 4760 kB
Cached: 1096448 kB
SwapCached: 0 kB
Active: 766032 kB
Inactive: 1263964 kB
Active(anon): 590144 kB
Inactive(anon): 1231776 kB
Active(file): 175888 kB
Inactive(file): 32188 kB1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.
编译运行小程序,再次查看系统 pagecache信息。
复制
# ./a.out cache.txt
Page cache generated for file: cache.txt
# free -m
total used free shared buff/cache available
Mem: 32096 2469 29640 872 1256 29627
Swap: 0 0 0
# cat /proc/meminfo
Buffers: 5116 kB
Cached: 1199444 kB
SwapCached: 0 kB
Active: 766652 kB
Inactive: 1366800 kB
Active(anon): 590216 kB
Inactive(anon): 1231776 kB
Active(file): 176436 kB
Inactive(file): 135024 kB1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.
观察发现 /proc/meminfo中的Cached增加了102996KiB,约100.5MiB;free -m中buff/cache输出增长了104MiB,两者都约等于我们写入的文件大小, 之所以略有不同,是因为系统还有其他进程也在运行影响pagecache。
2. Active File和 Inactive File
仔细观察刚才/proc/meminfo的内容可以发现, 增加的100MiB pagecache全部体现在Inactive(File)这一项, Active(File) 基本没有变化。
事实上,第一次读写文件产生的pagecache,都是Inactive的,只有当它再次被读写后,才会被对应的page放在Active LRU链表里。Linux使用了2个LRU链表来分别管理Active 和Inactive pagecache,当系统内存不足时,处于Inactive LRU上的pagecache会优先被回收释放,有很多情况下文件内容往往只被读一次,比如日志文件,它们占用的pagecache需要首先被回收掉。
下面我们再测试一个小程序,创建一个文件并写入100MiB数据,然后连续两次读文件,观察/proc/meminfo前后变化。
复制
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/mman.h>
#include <string.h>
#define FILE_SIZE (100 * 1024 * 1024) // 100 MiB
void read_file(const char *filename) {
int fd = open(filename, O_RDONLY);
if (fd == -1) {
perror("open");
exit(EXIT_FAILURE);
}
char *buffer = malloc(FILE_SIZE);
if (buffer == NULL) {
perror("malloc");
close(fd);
exit(EXIT_FAILURE);
}
ssize_t bytes_read = read(fd, buffer, FILE_SIZE);
if (bytes_read == -1) {
perror("read");
free(buffer);
close(fd);
exit(EXIT_FAILURE);
}
printf("Read %zd bytes from file\n", bytes_read);
free(buffer);
close(fd);
}
int main() {
const char *filename = "testfile";
// 创建一个测试文件
int fd = open(filename, O_RDWR | O_CREAT | O_TRUNC, 0600);
if (fd == -1) {
perror("open");
exit(EXIT_FAILURE);
}
if (ftruncate(fd, FILE_SIZE) == -1) {
perror("ftruncate");
close(fd);
exit(EXIT_FAILURE);
}
char *file_mem = mmap(NULL, FILE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (file_mem == MAP_FAILED) {
perror("mmap");
close(fd);
exit(EXIT_FAILURE);
}
memset(file_mem, A, FILE_SIZE); // 初始化文件内容
munmap(file_mem, FILE_SIZE);
close(fd);
// 第一次读取文件内容
read_file(filename);
// 第二次读取文件内容
read_file(filename);
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.
测试前进行dropcache并记录数据。
复制
# cat /proc/meminfo
Buffers: 4000 kB
Cached: 1108280 kB
SwapCached: 0 kB
Active: 778248 kB
Inactive: 1274056 kB
Active(anon): 599416 kB
Inactive(anon): 1241900 kB
Active(file): 178832 kB
Inactive(file): 32156 kB1.2.3.4.5.6.7.8.9.10.
完成测试,再次记录数据。
复制
# ./a.out
Read 104857600 bytes from file
Read 104857600 bytes from file
# cat /proc/meminfo
Buffers: 6340 kB
Cached: 1215868 kB
SwapCached: 0 kB
Active: 884284 kB
Inactive: 1277620 kB
Active(anon): 599088 kB
Inactive(anon): 1241900 kB
Active(file): 285196 kB
Inactive(file): 35720 kB1.2.3.4.5.6.7.8.9.10.11.12.13.
这时发现,Active(File)增长了103MiB,说明第二次读文件后,对应的pagecache被移动到Active LRU中。
3. 容器中的pagecache
追溯cadvisor的源码可以发现,container_memory_cache 来自memcg中memory.stat里的cache字段。再追溯linux源码,可以发现cache的取值源自memcg中的MEMCG_CACHE统计字段。注意memcg中的MEMCG_CACHE不仅包含了前面提到的ActiveFile和InactiveFile pagecache,它还包括了前面1.1中提到的共享内存。
将2.2中的程序稍作修改令其常驻不退出,然后制作成容器镜像,部署在TKEx平台中,观察内容监控数据如下。

可以发现接近pagecache占了接近100MiB,而rss使用量非常少。必须认识到,pagecache也属于容器内存使用量。
开发者可能很少感知自身程序pagecache的使用情况,容器平台会对程序的内存使用做限制,那么是否需要担心pagecache的上涨导致程序内存使用量超过容器内存限制,导致程序被OOM Kill?
实验探索这个问题。在一个1GiB Memory Limit容器中,已经通过malloc/memset使用了0.8GiB的rss内存,然后通过读100MiB磁盘文件产生100MiB左右的pagecache,此时容器内存使用量大约为0.9GiB,距离1GiB的限制量还差100MiB。
这时候程序还能malloc/memset 150Mi内存吗? 程序是否会因为超过memcg limit而被Kill?
编写如下程序然后制作容器镜像,部署到TKEx平台,将容器内存限制设置为1GiB。
复制
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
#define ONE_GIB (1024 * 1024 * 1024)
#define EIGHT_TENTHS_GIB (0.8 * ONE_GIB)
#define ONE_HUNDRED_MIB (100 * 1024 * 1024)
#define ONE_FIFTY_MIB (150 * 1024 * 1024)
#define FILE_PATH "/root/test.txt"
void allocate_memory(size_t size) {
char *buffer = (char *)malloc(size);
if (buffer == NULL) {
perror("malloc");
exit(EXIT_FAILURE);
}
memset(buffer, 0, size);
}
void create_file(const char *filename, size_t size) {
int fd = open(filename, O_WRONLY | O_CREAT | O_TRUNC, S_IRUSR | S_IWUSR);
if (fd == -1) {
perror("open");
exit(EXIT_FAILURE);
}
char *buffer = (char *)malloc(size);
if (buffer == NULL) {
perror("malloc");
close(fd);
exit(EXIT_FAILURE);
}
// Fill the buffer with random data
for (size_t i = 0; i < size; i++) {
buffer[i] = rand() % 256;
}
if (write(fd, buffer, size) != size) {
perror("write");
free(buffer);
close(fd);
exit(EXIT_FAILURE);
}
free(buffer);
close(fd);
}
void read_file(const char *filename, size_t size) {
FILE *file = fopen(filename, "r");
if (file == NULL) {
perror("fopen");
exit(EXIT_FAILURE);
}
char *buffer = (char *)malloc(size);
if (buffer == NULL) {
perror("malloc");
fclose(file);
exit(EXIT_FAILURE);
}
fread(buffer, 1, size, file);
fclose(file);
free(buffer);
}
int main() {
printf("Allocating 0.8 GiB of RSS memory...\n");
allocate_memory(EIGHT_TENTHS_GIB);
printf("Waiting for 3 minutes...\n");
sleep(180);
printf("Creating a 100 MiB file with random data...\n");
create_file(FILE_PATH, ONE_HUNDRED_MIB);
printf("Waiting for 3 minutes...\n");
sleep(180);
printf("Reading 100 MiB from the file to generate pagecache...\n");
read_file(FILE_PATH, ONE_HUNDRED_MIB);
printf("Waiting for 3 minutes...\n");
sleep(180);
printf("Trying to allocate 150 MiB of memory...\n");
allocate_memory(ONE_FIFTY_MIB);
printf("Successfully allocated 150 MiB of memory.\n");
sleep(3600);
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.
运行发现最后这150MiB内存是可以分配使用的,程序并没有被Kill。
这是申请150MiB内存前,容器的内存使用监控记录:

这是申请150MiB内存后,容器的内存使用监控记录。

发现rss确实增长了150MiB,pagecache少了45MiB,总内存达到1023MiB, 并没有超过1GiB的限制。原因是在memset进入缺页中断分配物理页时,系统发现内存使用量会超过memcg limit的情况下,会先尝试回收pagecache以满足分配需求, 优先回收前面提到的Inactive File。由此可知,进程的rss不超过memcg limit的前提下, 可以放心申请使用内存,系统会及时释放pagecache来满足需求。pagecache属于内核,不属于用户,当用户需要内存时,内核会通过回收pagecache来归还内存,但这可能是有代价的。
代价是什么?
pagecache用于提升磁盘文件读写性能,pagecache被回收意味着程序IO性能下降,延迟增加。因此生产环境一般严禁dropcache操作。缺页中断进入更复杂的流程,page申请变慢, 直接阻塞用户进程,造成应用程序性能下降。
频繁进行文件读写的容器经常会遇到内存使用率一直接近99%的情况,就是由于linux为了提升文件读写性能,在memcg的限制内,尽可能地分配更多的pagecache。
阶段总结4
容器中的cache占用统计既包含了读写文件产生的pagecache,也包括了使用共享内存的大小。
容器环境下, 内存使用量接近memcg限制时候,继续尝试申请分配内存会先触发pagecache回收,以满足分配需求。
四、container_memory_mapped_file
1. mmap文件映射
mmap不仅可以为程序分配匿名页, 它还是一种内存映射文件的方法,允许将文件或设备的内容映射到进程的地址空间中。通过 mmap,可以直接访问甚至修改文件内容,就像访问内存一样,这通常比传统的文件 I/O 操作更高效。例如以下程序:
复制
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/stat.h>
#define FILE_PATH "/root/test.txt"
#define FILE_SIZE (100 * 1024 * 1024) // 100 MiB
void create_file(const char *filename, size_t size) {
int fd = open(filename, O_WRONLY | O_CREAT | O_TRUNC, S_IRUSR | S_IWUSR);
if (fd == -1) {
perror("open");
exit(EXIT_FAILURE);
}
char *buffer = (char *)malloc(size);
if (buffer == NULL) {
perror("malloc");
close(fd);
exit(EXIT_FAILURE);
}
// Fill the buffer with A
memset(buffer, A, size);
if (write(fd, buffer, size) != size) {
perror("write");
free(buffer);
close(fd);
exit(EXIT_FAILURE);
}
free(buffer);
close(fd);
}
int main() {
// Step 1: Create a 100 MiB file with A
printf("Creating a 100 MiB file with A...\n");
create_file(FILE_PATH, FILE_SIZE);
// Step 2: Open the file for reading and writing
int fd = open(FILE_PATH, O_RDWR);
if (fd == -1) {
perror("open");
exit(EXIT_FAILURE);
}
// Step 3: Memory-map the file
char *mapped = (char *)mmap(NULL, FILE_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (mapped == MAP_FAILED) {
perror("mmap");
close(fd);
exit(EXIT_FAILURE);
}
// Step 4: Modify the file content through the memory-mapped region
printf("Modifying the file content to B...\n");
memset(mapped, B, FILE_SIZE);
printf("File content successfully modified to B.\n");
sleep(240);
// Step 5: Clean up
if (munmap(mapped, FILE_SIZE) == -1) {
perror("munmap");
}
close(fd);
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.
先初始化一个100MiB的文本文件,内容全部是字母A; 然后通过mmap将文件映射到程序地址空间里,通过memset将文件内容全改成字母B。借助mmap文件映射,使用内存操作就能完成文件读写。相较于标准buffered io, mmap文件映射会拥有更好的性能,因为它避开了用户空间和内核空间的相互拷贝,这个优势在一次读写几十上百MiB的场景下尤为突出。
将这个程序制作成容器镜像,部署在TKEx平台中,观察内存监控记录。

可以发现, mmap, 即container_memory_mmaped_file的监控值接近100MiB,而容器的rss依然非常低。观察/proc/<pid>/status:
复制
...
VmRSS: 103932 kB
...1.2.3.
发现进程的rss依然约101MiB。因此和前面提到的共享内存一样,mmap文件映射部分的大小属于进程的rss而不属于容器的rss。
2. mmap共享内存
(1) 共享文件映射
基于4.1的启发,只要多个进程mmap相同一个文件,就可以通过这个文件实现共享内存,完成多进程通信,这种方式叫做共享文件映射。
调用 mmap 进行文件映射的时候,内核首先会在进程的虚拟内存空间中创建一个新的虚拟内存区域 VMA 用于映射文件,通过 vm_area_struct->vm_file 将映射文件的 struct flle 结构与虚拟内存映射关联起来。
复制
struct vm_area_struct {
struct file * vm_file; /* File we map to (can be NULL). */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE */
}1.2.3.4.
在缺页中断处理过程中,如果vma非匿名(即文件映射),linux首先通过 vm_area_struct->vm_pgoff激活对应的pagecache并预读部分磁盘文件内容到pagecache中,然后在页表中创建PTE并与pagecache文件页关联,完成缺页中断,此后对vma的访问实质上都是对pagecache的访问。进程1和进程2的共享文件映射,实质上是各自vma里的file字段最终指向了相同的文件,即相同的inode。进程1和进程2对各自vma的访问也实质上是对相同的pagecache进行访问,这就是基于文件映射实现共享内存的原理。当然,对vma的内容修改也会导致对pagecache的修改,最终通过脏页回写完成对磁盘文件的修改,因此这种共享内存的方式会产生真实的磁盘IO。
(2) 共享匿名映射
相对于共享文件映射,共享匿名映射也能实现共享内存,但只适用于父子进程之间。实现原理相对于共享文件映射略有类似,同样依赖了pagecache,但这里的文件不再是具体的磁盘文件,而是tmpfs。tmpfs是一个基于内存实现的文件系统,因此基于tmpfs的共享内存不会产生真实的磁盘IO。后面会了解到,基于ipc的共享内存,即1.1里通过shmget和shmat实现的共享内存,也是依靠tmpfs完成的。
3. 容器中的mapped file
回到cadvisor源码里,container_memory_mapped_file取值于memcg memory.stat里的mapped_file字段,实际上就是memcg中的NR_FILE_MAPPED字段。所有mmap调用产生的文件页,都会被统计到container_memory_mapped_file中。根据3.2.1的描述,mmap文件映射的原理与pagecache的行为紧密相关, mapped_file也会伴随着pagecache一起出现。
此外,mapped_file还包括tmpfs的使用量,下面来介绍tmpfs和shmem。
五、tmpfs与shmem
1. emptyDir的问题
emptyDir允许用户选择内存作为挂载介质。

当这么做的时候,会发现挂载点(下图的/data)对应的文件系统是tmpfs,这意味着/data里的数据实际上都存储在内存中。
复制
# df -h
Filesystem Size Used Available Use% Mounted on
overlay 49.1G 2.7G 46.4G 5% /
tmpfs 8.0G 0 8.0G 0% /data1.2.3.4.
如果没有为emptyDir卷设置sizeLimit,/data目录下的文件将占用Pod的内存;如果Pod没有设置内存limit,则/data可能消耗掉Node上全部的内存。
日常排障中经常收到客户的工单疑惑,进程似乎没有内存泄漏的情况,但内存使用量一直在上涨。通过面板发现pagecache一路上涨,最后发现挂载在tmpfs的/data/目录一直在输出程序log。 因此,请注意不要将emptyDir以内存为介质挂载后,将其作为输出日志目录。
2. System V IPC 共享内存
公司内部存在大量的IPC共享内存的使用场景,比如spp服务端框架。例如以下C语言程序例子:
(1) Writer
复制
#include <stdio.h>
#include <stdlib.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <string.h>
#define SHM_SIZE 36 * 1024 * 1024 // 36 MiB
int main() {
key_t key = ftok("shmfile", 65); // 生成一个唯一的key
int shmid = shmget(key, SHM_SIZE, 0666 | IPC_CREAT); // 创建共享内存段
if (shmid == -1) {
perror("shmget failed");
exit(1);
}
char *data = (char *)shmat(shmid, (void *)0, 0); // 连接到共享内存段
if (data == (char *)(-1)) {
perror("shmat failed");
exit(1);
}
// 写入数据到共享内存
strcpy(data, "Hello, this is a message from the writer process!");
printf("Data written to shared memory: %s\n", data);
sleep(3600);
// 断开连接
if (shmdt(data) == -1) {
perror("shmdt failed");
exit(1);
}
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.
(2) Reader
复制
#include <stdio.h>
#include <stdlib.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <string.h>
#define SHM_SIZE 36 * 1024 * 1024 // 36 MiB
int main() {
key_t key = ftok("shmfile", 65); // 生成一个唯一的key
int shmid = shmget(key, SHM_SIZE, 0666); // 获取共享内存段
if (shmid == -1) {
perror("shmget failed");
exit(1);
}
char *data = (char *)shmat(shmid, (void *)0, 0); // 连接到共享内存段
if (data == (char *)(-1)) {
perror("shmat failed");
exit(1);
}
// 读取共享内存中的数据
printf("Data read from shared memory: %s\n", data);
sleep(3600);
// 断开连接
if (shmdt(data) == -1) {
perror("shmdt failed");
exit(1);
}
// 删除共享内存段
if (shmctl(shmid, IPC_RMID, NULL) == -1) {
perror("shmctl failed");
exit(1);
}
return 0;
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.
分辨编译执行5.2.1和5.2.2,会发现5.2.2能读取到来自5.2.1的 Hello, this is a message from the writer process!。
同时执行 ipcs -m可以看到我们分配到的36MiB共享内存。
复制
# ipcs -m
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
...
0xffffffff 7 root 666 37748736 21.2.3.4.5.
这时需要注意的是,当Writer和Reader进程都退出后,这部分内存依然在机器的tmpfs中,必须通过ipcrm命令来显示删除释放。
来到容器环境中,某个容器退出后,原进程中共享内存中的数据同样不会消失。如果剩余的容器没有使用该共享内存,这部分内存用量则只计入Pod Level Memcg的使用量。
如果你发现Pod的内存使用量明显大于所有容器内存使用量之和,可以通过ipcs查看是否存在Shmem数据。
六、监控实践
1. 程序自监控内存用量的小技巧
linux提供了一个系统调用getrusage(2)用于获取进程自身以及其子进程的资源使用情况,在1.1中我们已经初步接触过了,再提供一个go语言的调用示例。
复制
package main
import (
"fmt"
"syscall"
"time"
)
func main() {
// 调用 getrusage 系统调用
var usage syscall.Rusage
err := syscall.Getrusage(syscall.RUSAGE_SELF, &usage)
if err != nil {
fmt.Printf("Error getting resource usage: %v\n", err)
return
}
// 打印资源使用情况
fmt.Printf("User CPU time used: %+v \n", usage.Utime)
fmt.Printf("System CPU time used: %+v \n", usage.Stime)
fmt.Printf("Maximum resident set size: %v \n", usage.Maxrss)
fmt.Printf("Integral shared memory size: %v \n", usage.Ixrss)
fmt.Printf("Integral unshared data size: %v \n", usage.Idrss)
fmt.Printf("Integral unshared stack size: %v \n", usage.Isrss)
fmt.Printf("Page reclaims (soft page faults): %v\n", usage.Minflt)
fmt.Printf("Page faults (hard page faults): %v\n", usage.Majflt)
fmt.Printf("Swaps: %v\n", usage.Nswap)
fmt.Printf("Block input operations: %v\n", usage.Inblock)
fmt.Printf("Block output operations: %v\n", usage.Oublock)
fmt.Printf("IPC messages sent: %v\n", usage.Msgsnd)
fmt.Printf("IPC messages received: %v\n", usage.Msgrcv)
fmt.Printf("Signals received: %v\n", usage.Nsignals)
fmt.Printf("Voluntary context switches: %v\n", usage.Nvcsw)
fmt.Printf("Involuntary context switches: %v\n", usage.Nivcsw)
// 模拟一些 CPU 负载
for i := 0; i < 1e8; i++ {
_ = i * i
}
time.Sleep(2 * time.Second)
// 再次调用 getrusage 系统调用
err = syscall.Getrusage(syscall.RUSAGE_SELF, &usage)
if err != nil {
fmt.Printf("Error getting resource usage: %v\n", err)
return
}
// 打印资源使用情况
fmt.Printf("\nAfter sleep:\n")
fmt.Printf("User CPU time used: %+v \n", usage.Utime)
fmt.Printf("System CPU time used: %+v \n", usage.Stime)
fmt.Printf("Maximum resident set size: %v \n", usage.Maxrss)
fmt.Printf("Integral shared memory size: %v \n", usage.Ixrss)
fmt.Printf("Integral unshared data size: %v \n", usage.Idrss)
fmt.Printf("Integral unshared stack size: %v \n", usage.Isrss)
fmt.Printf("Page reclaims (soft page faults): %v\n", usage.Minflt)
fmt.Printf("Page faults (hard page faults): %v\n", usage.Majflt)
fmt.Printf("Swaps: %v\n", usage.Nswap)
fmt.Printf("Block input operations: %v\n", usage.Inblock)
fmt.Printf("Block output operations: %v\n", usage.Oublock)
fmt.Printf("IPC messages sent: %v\n", usage.Msgsnd)
fmt.Printf("IPC messages received: %v\n", usage.Msgrcv)
fmt.Printf("Signals received: %v\n", usage.Nsignals)
fmt.Printf("Voluntary context switches: %v\n", usage.Nvcsw)
fmt.Printf("Involuntary context switches: %v\n", usage.Nivcsw)
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.
可见,getrusage(2) 还能帮助开发者自监控CPU使用率。
2. Top和Pid Namespace
在容器内执行top查看到的cpu和memory使用率通常并不是容器的真实使用率,因为/proc/stat和/proc/meminfo的视野是整个机器而非Pod或者容器。详情见以下。
Node类型
CVM Node
TKE Serverless Node
CPU/内存使用率范围
Node全部,包括其他Pod
包括自身容器和虚机其他进程,如洋葱安全,eklet-agent等
如果你的容器部署在TKE Serverless节点中,TKEx和TKE AppFabric也提供了Pod所在虚机的基础监控,如下图所示。
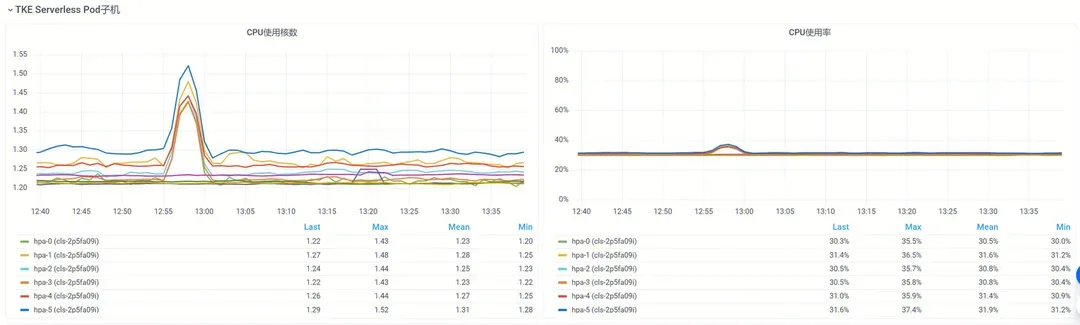
虚机的监控数据与Top的输出吻合。
如果你在容器内使用top观察进程的监控数据,需要明确的是Pod内不同容器的Pid Namespace默认是不共享的,你无法观察另一个容器的进程数据。
开启Pid Namespace共享可以获得更多的观测手段,比如使用带有dlv, gdb等调试工具的sidecar容器来调试主容器进程。但需要开启对应的特权,比如ptrace,以及不能使用Systemd拉起富容器的模式部署业务。
3. 我的容器内存使用率超过了100%
我好像白薅了平台的内存,这是怎么回事?
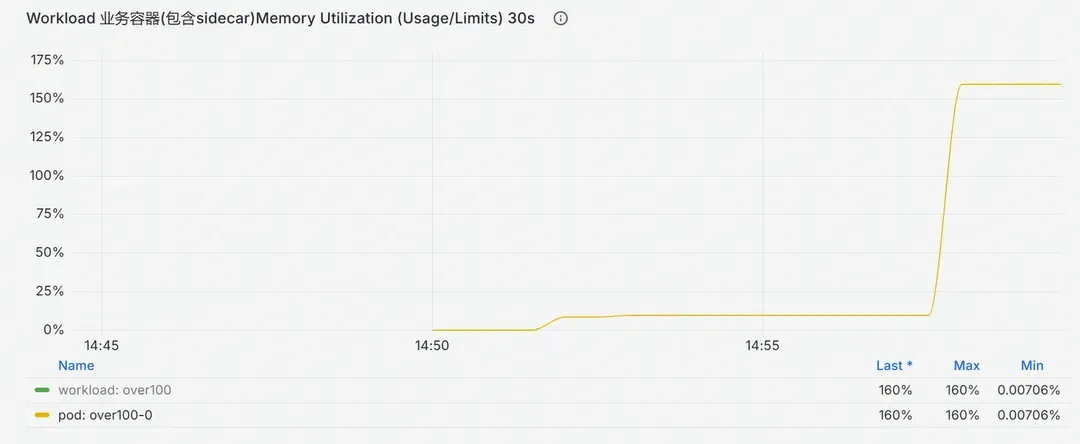
如上图所示,内存使用量已经大幅度超过了容器本身的内存限制量,按照常识,容器会被OOM Kill。然而现网中存在一些明显超过内存限制量却依然在正常运行的容器。
前文说过,K8s为容器设置了Pod和Container级的memcg内存限制,任何一个容器内存使用量突破了Container层级的限制,会触发OOM Kill; 所有容器内存使用和突破了Pod层级的限制,也会触发OOM Kill。出现超限使用意味着这两道限制都已经失效。
排查发现,这类超限运行Pod普遍存在2个特征:
存在一个用Systemd拉起的富容器,Systemd版本早于236;存在一个未配置Limit的sidecar容器。
两个特征同时满足的时候,K8s设置的两层限制都会失效。如果容器开启特权并且/sys/fs/cgroup被挂载,Systemd会覆盖K8s为容器设置的cgroup limit;任意一个未配置Limit的容器会使得Pod的QOS降级到Burstable甚至BestEffort, Pod层级的内存限制变成无穷大。
超限使用内存会导致Node的内存被占用,滋生稳定性风险。建议使用较新的ubuntu/centos/tlinux基础镜像,搭载较新版本的Systemd拉起业务容器,避免超限使用内存。
4. 我担心OOM Kill,配置哪个指标做内存使用告警?
通常基于container_memory_working_set_bytes做内存使用告警,内存使用率的计算公式为:
复制
100 * container_memory_working_set_bytes{container="$container", pod="$pod", namespace="$namespace"}
/ kube_pod_container_resource_limits{resource="memory", container="$container", pod="$pod", namespace="$namespace"} %1.2.
container_memory_working_set_bytes在memcg的全部使用量的基础上,减去了Inactive File部分, 认为这部分pagecache可以迅速回收而不会给业务进程造成显著的负载压力,可以不计入容器的内存使用量。如下是cadvisor的统计代码细节。
复制
workingSet := ret.Memory.Usage
if v, ok := s.MemoryStats.Stats[inactiveFileKeyName]; ok {
ret.Memory.TotalInactiveFile = v
if workingSet < v {
workingSet = 0
} else {
workingSet -= v
}
}
ret.Memory.WorkingSet = workingSet1.2.3.4.5.6.7.8.9.10.
七、结尾
一路过来,我们了解缺页中断的概念,RSS的统计,认识了Linux Memcg内存控制组,观察了pagecache的分配和回收,初识了tmpfs,以及在容器中使用共享内存等等。读到这里,文章开头提到的几个问题应该有了清晰的答案。祝大家的程序稳如泰山,永不OOM。