在 Linux 系统的庞大体系中,内存管理堪称是最为核心的功能之一,就如同心脏对于人体的重要性,它承担着协调和管理计算机内存资源的重任,确保各个应用程序能够在有限的内存空间中高效、稳定地运行。可以毫不夸张地说,优秀的内存管理机制是 Linux 系统高性能、高稳定性的基石。
在深入探讨 Linux 内存管理的核心内容之前,我们先来认识两个最为基础的概念:虚拟内存与物理内存。物理内存是计算机硬件中实实在在用于存储程序和数据的内存芯片,也被称为主存储器,它就像是一个临时的 “数据仓库”,程序运行时的数据和指令都暂时存放在这里。而虚拟内存则是一种相对抽象的概念,它是 Linux 内存管理中的一项关键技术,让每个进程都仿佛拥有一块连续且独立的内存空间,就好像每个进程都有自己专属的 “大仓库”,可以自由地存放数据和代码,而无需担心其他进程的干扰,也无需考虑物理内存的实际限制 。
内存管理的核心任务主要包含以下几个方面:
内存分配与回收:当应用程序或内核需要使用内存时,内存管理系统就会如同一位严谨的仓库管理员,根据需求合理地分配内存空间,确保每个 “客户” 都能得到合适的 “存储空间”。当某些内存不再被使用时,管理员又会及时将这些内存回收,以便重新分配给其他有需要的程序,避免内存资源的浪费。内存保护:为了保证系统的稳定性和安全性,内存管理需要对不同进程的内存空间进行严格的隔离和保护,防止一个进程不小心 “闯入” 其他进程的内存区域,造成数据混乱或系统崩溃,就好比每个仓库都有严格的门禁系统,只有授权的程序才能进入特定的内存区域。虚拟内存管理:通过巧妙地将虚拟地址映射到物理地址,虚拟内存管理实现了进程对大内存空间的访问,即使物理内存有限,也能让进程以为自己拥有足够大的内存空间,就像是一个智能的空间拓展器,让有限的物理内存发挥出更大的作用。内存缓存:为了提高数据的访问速度,内存管理会将一些经常被访问的数据缓存起来,就像在仓库门口设置了一个 “快速取货区”,当程序需要这些数据时,可以直接从缓存中快速获取,大大减少了数据读取的时间,提高了系统的整体性能。
一、引导内存分配器
linux系统中使用伙伴系统对物理页面进行分配管理,但是伙伴分配系统需要内核完成初始化以及建立相关内核数据结构后才能够正常工作。因此,我们不难看出在内核初始化相关数据结构时需要另一种内存分配器。早期Linux没有较为完善的引导内存分配器,但是随着硬件的发展和日趋复杂,处理不同体系的内存分配代码也渐渐复杂起来,随之就需要引导内存分配器来初始化系统主要内存分配器的数据结构以确保其正常工作。在内核2.3.23版本中bootmem引导内存分配器补丁被加入,使用位图来表示页面使用状况。
然后在内核2.3.48版本时,linux内核移植到IA64时正式使用bootmem作为引导内存分配器。随着时间的流逝,内存检测已经从简单地向BIOS询问扩展内存块的大小演变为处理复杂的表,块,库和群集。这时开始使用memblock作为引导内存分配器。
在bootmem向memblock过渡时,出现nobootmem作为兼容层,提供与bootmem类似api。在内核版本4.17时,在linux所支持的24种架构中,只有5种仍在使用bootmem作为唯一的早期内存分配器,14中将memblock与nobootmem一起使用,其余同时使用memblock和bootmem作为引导内存分配器。
bootmem 的数据结构主要由struct bootmem_data来描述,这个结构体包含了许多关键信息:
node_min_pfn:表示节点的最小物理页号,就像是一个房间号的起始值,确定了内存区域的起始位置。node_low_pfn:代表节点的结束物理页号,标志着这个内存区域的边界,就像房间号的结束值。node_bootmem_map:指向一个位图,这个位图是 bootmem 管理内存的核心,通过它可以快速了解每个物理页的分配状态,就像一份详细的房间使用清单。last_end_off:记录上次分配的内存块的结束位置后面一个字节的偏移,这有助于在分配小内存块时,尽量将它们集中在相同的页面中,提高内存利用率,就像在书架上放置书籍时,尽量将同一类的书放在相邻位置。hint_idx:是上次分配的内存块的结束位置后面的物理页在位图中的索引,下次分配时优先考虑从这个物理页开始,这就像是给下次分配提供了一个 “快捷入口”,提高了分配效率 。
1.1引导内存分配器bootmem
首先查看bootmem_data数据结构,表示每个节点物理内存以及其页面使用情况。
复制
typedef struct bootmem_data {
unsigned long node_min_pfn;
unsigned long node_low_pfn;
void *node_bootmem_map;
unsigned long last_end_off;
unsigned long hint_idx;
struct list_head list;
} bootmem_data_t;1.2.3.4.5.6.7.8.
node_min_pfn和node_low_pfn:表示该节点内存物理页面范围:node_min_pfn为起始页面,node_low_pfn则为结束页面;node_bootmem_map:指向位图,每位表示内存页面使用情况,当页面可以被使用时,所对应的位图设为0,相反则设为1;last_end_off:表示上次所分配内存的物理地址相对bootmem起始页面偏移(以字节计算);hint_idx:记录上次设置位图的索引;list:加入bootmem_data全局链表bdata_list;除了全局链表外,还存在bootmem_node_data所指向的bootmem_data全局数组,索引为内存对应节点号;①初始化bootmem_data
复制
static unsigned long __init init_bootmem_core(bootmem_data_t *bdata,
unsigned long mapstart, unsigned long start, unsigned long end)
{
unsigned long mapsize;
mminit_validate_memmodel_limits(&start, &end);
bdata->node_bootmem_map = phys_to_virt(PFN_PHYS(mapstart));
bdata->node_min_pfn = start;
bdata->node_low_pfn = end;
link_bootmem(bdata);
/*
* Initially all pages are reserved - setup_arch() has to
* register free RAM areas explicitly.
*/
mapsize = bootmap_bytes(end - start);
memset(bdata->node_bootmem_map, 0xff, mapsize);
bdebug("nid=%td start=%lx map=%lx end=%lx mapsize=%lx\n",
bdata - bootmem_node_data, start, mapstart, end, mapsize);
return mapsize;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.
首先调用mminit_validate_memmodel_limits()函数检查指定范围物理页面是否有效,然后初始化bootmem_data结构,其中mapstart指向所分配位图页面。link_bootmem()函数是将bootmem_data加入bdata_list链表中。最后将所有位图设为1,即页面目前不可用。
复制
static void __init link_bootmem(bootmem_data_t *bdata)
{
bootmem_data_t *ent;
list_for_each_entry(ent, &bdata_list, list) {
if (bdata->node_min_pfn < ent->node_min_pfn) {
list_add_tail(&bdata->list, &ent->list);
return;
}
}
list_add_tail(&bdata->list, &bdata_list);
}1.2.3.4.5.6.7.8.9.10.11.12.13.
该函数将bootmem_data加入链表,bdata_list中节点顺序是按照起始页面从小到大排列。
②释放bootmem所保留的页面
复制
static void __init __free(bootmem_data_t *bdata,
unsigned long sidx, unsigned long eidx)
{
unsigned long idx;
bdebug("nid=%td start=%lx end=%lx\n", bdata - bootmem_node_data,
sidx + bdata->node_min_pfn,
eidx + bdata->node_min_pfn);
if (WARN_ON(bdata->node_bootmem_map == NULL))
return;
if (bdata->hint_idx > sidx)
bdata->hint_idx = sidx;
for (idx = sidx; idx < eidx; idx++)
if (!test_and_clear_bit(idx, bdata->node_bootmem_map))
BUG();
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
该函数中sidx表示所释放起始页面偏移,eidx表示结束页面偏移,循环遍历相应位图将其设为0,则该页面可用。
③保留bootmem中页面
复制
static int __init __reserve(bootmem_data_t *bdata, unsigned long sidx,
unsigned long eidx, int flags)
{
unsigned long idx;
int exclusive = flags & BOOTMEM_EXCLUSIVE;
bdebug("nid=%td start=%lx end=%lx flags=%x\n",
bdata - bootmem_node_data,
sidx + bdata->node_min_pfn,
eidx + bdata->node_min_pfn,
flags);
if (WARN_ON(bdata->node_bootmem_map == NULL))
return 0;
for (idx = sidx; idx < eidx; idx++)
if (test_and_set_bit(idx, bdata->node_bootmem_map)) {
if (exclusive) {
__free(bdata, sidx, idx);
return -EBUSY;
}
bdebug("silent double reserve of PFN %lx\n",
idx + bdata->node_min_pfn);
}
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.
该函数sidx和eidx表示锁保留页面的范围,如果flags设置BOOTMEM_EXCLUSIVE标志位则表示将指定范围内页面从bootmem中释放。
④从bootmem中分配内存
复制
static void * __init alloc_bootmem_bdata(struct bootmem_data *bdata,
unsigned long size, unsigned long align,
unsigned long goal, unsigned long limit)
{
unsigned long fallback = 0;
unsigned long min, max, start, sidx, midx, step;
bdebug("nid=%td size=%lx [%lu pages] align=%lx goal=%lx limit=%lx\n",
bdata - bootmem_node_data, size, PAGE_ALIGN(size) >> PAGE_SHIFT,
align, goal, limit);
BUG_ON(!size);
BUG_ON(align & (align - 1));
BUG_ON(limit && goal + size > limit);
if (!bdata->node_bootmem_map)
return NULL;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.
该函数size表示所需要分配多少字节的内存,align表示分配内存按多少字节对齐,goal表示分配内存最小物理地址,limit表示分配内存最大物理地址。首先对参数进行检验,size不能为空,align必须为2的指数,同时分配内存不能超出范围。
复制
min = bdata->node_min_pfn;
max = bdata->node_low_pfn;
goal >>= PAGE_SHIFT;
limit >>= PAGE_SHIFT;
if (limit && max > limit)
max = limit;
if (max <= min)
return NULL;
step = max(align >> PAGE_SHIFT, 1UL);
if (goal && min < goal && goal < max)
start = ALIGN(goal, step);
else
start = ALIGN(min, step);1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.
获取bootmem所保留页面范围并重新计算所分配内存起始物理页面。
复制
sidx = start - bdata->node_min_pfn;
midx = max - bdata->node_min_pfn;
if (bdata->hint_idx > sidx) {
/*
* Handle the valid case of sidx being zero and still
* catch the fallback below.
*/
fallback = sidx + 1;
sidx = align_idx(bdata, bdata->hint_idx, step);
}1.2.3.4.5.6.7.8.9.10.11.
设置起始和结束索引,如果bootmem上次分配内存页面大于sidx则设置fallback。
复制
while (1) {
int merge;
void *region;
unsigned long eidx, i, start_off, end_off;
find_block:
sidx = find_next_zero_bit(bdata->node_bootmem_map, midx, sidx);
sidx = align_idx(bdata, sidx, step);
eidx = sidx + PFN_UP(size);
if (sidx >= midx || eidx > midx)
break;
for (i = sidx; i < eidx; i++)
if (test_bit(i, bdata->node_bootmem_map)) {
sidx = align_idx(bdata, i, step);
if (sidx == i)
sidx += step;
goto find_block;
}
if (bdata->last_end_off & (PAGE_SIZE - 1) &&
PFN_DOWN(bdata->last_end_off) + 1 == sidx)
start_off = align_off(bdata, bdata->last_end_off, align);
else
start_off = PFN_PHYS(sidx);
merge = PFN_DOWN(start_off) < sidx;
end_off = start_off + size;
bdata->last_end_off = end_off;
bdata->hint_idx = PFN_UP(end_off);
/*
* Reserve the area now:
*/
if (__reserve(bdata, PFN_DOWN(start_off) + merge,
PFN_UP(end_off), BOOTMEM_EXCLUSIVE))
BUG();
region = phys_to_virt(PFN_PHYS(bdata->node_min_pfn) +
start_off);
memset(region, 0, size);
/*
* The min_count is set to 0 so that bootmem allocated blocks
* are never reported as leaks.
*/
kmemleak_alloc(region, size, 0, 0);
return region;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.
首先获取bootmem位图在sidx和eidx范围数个为0的索引,然后在进行对齐获取起始索引并重新计算结束索引,验证是否超出bootmem所拥有页面范围,超出则退出循环分配失败。否则进入for循环在sidx和eidx遍历查看是否存在页面被bootmem保留,如果存在则以此索引为新sidx进行设置,重新遍历,相反则继续进行分配。根据bootmem上次分配内存的偏移设置所分配内存起始物理地址以及结束地址,最后设置这些页面的位图为1,即保留页面。
复制
if (fallback) {
2 sidx = align_idx(bdata, fallback - 1, step);
3 fallback = 0;
4 goto find_block;
5 }1.2.3.4.5.
检查fallback是否为0,如果不为0则返回继续进行查找。
⑤释放bootmem中页面
复制
static unsigned long __init free_all_bootmem_core(bootmem_data_t *bdata)
{
struct page *page;
unsigned long *map, start, end, pages, cur, count = 0;
if (!bdata->node_bootmem_map)
return 0;
map = bdata->node_bootmem_map;
start = bdata->node_min_pfn;
end = bdata->node_low_pfn;
bdebug("nid=%td start=%lx end=%lx\n",
bdata - bootmem_node_data, start, end);1.2.3.4.5.6.7.8.9.10.11.12.13.14.
获取bootmem页面范围以及位图。
复制
while (start < end) {
unsigned long idx, vec;
unsigned shift;
idx = start - bdata->node_min_pfn;
shift = idx & (BITS_PER_LONG - 1);
/*
* vec holds at most BITS_PER_LONG map bits,
* bit 0 corresponds to start.
*/
vec = ~map[idx / BITS_PER_LONG];
if (shift) {
vec >>= shift;
if (end - start >= BITS_PER_LONG)
vec |= ~map[idx / BITS_PER_LONG + 1] <<
(BITS_PER_LONG - shift);
}
/*
* If we have a properly aligned and fully unreserved
* BITS_PER_LONG block of pages in front of us, free
* it in one go.
*/
if (IS_ALIGNED(start, BITS_PER_LONG) && vec == ~0UL) {
int order = ilog2(BITS_PER_LONG);
__free_pages_bootmem(pfn_to_page(start), start, order);
count += BITS_PER_LONG;
start += BITS_PER_LONG;
} else {
cur = start;
start = ALIGN(start + 1, BITS_PER_LONG);
while (vec && cur != start) {
if (vec & 1) {
page = pfn_to_page(cur);
__free_pages_bootmem(page, cur, 0);
count++;
}
vec >>= 1;
++cur;
}
}
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.
循环遍历位图释放bootmem未进行保留的页面,即相应位图设为0的页面。
1.2引导内存分配器memblock
随着硬件的发展以及复杂化,内存检测已经从简单地向BIOS询问扩展内存块的大小演变为处理复杂的表,块,库和群集。在x86架构上, 内核启动初期首先使用early_res机制接替BIOS e820的工作, 然后再交给架构独立的bootmem分配器, 最后转由伙伴分配系统进行页面管理。然后有人认为可以去掉bootmem以此简化该过程并提交patch,最终人们提议使用PowerPC, SuperH和SPARC架构上的LMB内存分配器作为系统启动初期的内存分配器。内核数据结构:
复制
struct memblock_type {
unsigned long cnt; /* number of regions */
unsigned long max; /* size of the allocated array */
phys_addr_t total_size; /* size of all regions */
struct memblock_region *regions;
char *name;
};1.2.3.4.5.6.7.
memblock数据结构是LMB内存分配器核心;bottom_up:表示内存分配方向;current_limit:表示memblock所管理页面最大物理地址;memory:表示memblock所管理全部内存;reserved:表示已经分配出去的内存;phymem:表示进行物理地址映射的内存;
复制
struct memblock_type {
unsigned long cnt; /* number of regions */
unsigned long max; /* size of the allocated array */
phys_addr_t total_size; /* size of all regions */
struct memblock_region *regions;
char *name;
};1.2.3.4.5.6.7.
cnt:表示memblock_region数组中元素个数;max:表示memblock_type所具有的memblock_region数组元素最大数目;total_size:表示全部memblock_region数组保存页面数;regions:指向memblock_region数组;name:指向memblock_type名;
复制
struct memblock_region {
phys_addr_t base;
phys_addr_t size;
unsigned long flags;
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
int nid;
#endif
};1.2.3.4.5.6.7.8.
base:表示memblock_region所具有内存起始物理地址;size:表示memblock_region所具有内存大小;flags:标志位;nid:表示memblock_region所具有内存的节点号;①获取memblock_region
复制
void __init_memblock __next_mem_range(u64 *idx, int nid, ulong flags,
struct memblock_type *type_a,
struct memblock_type *type_b,
phys_addr_t *out_start,
phys_addr_t *out_end, int *out_nid)
{
int idx_a = *idx & 0xffffffff;
int idx_b = *idx >> 32;
if (WARN_ONCE(nid == MAX_NUMNODES,
"Usage of MAX_NUMNODES is deprecated. Use NUMA_NO_NODE instead\n"))
nid = NUMA_NO_NODE;
for (; idx_a < type_a->cnt; idx_a++) {
struct memblock_region *m = &type_a->regions[idx_a];
phys_addr_t m_start = m->base;
phys_addr_t m_end = m->base + m->size;
int m_nid = memblock_get_region_node(m);
/* only memory regions are associated with nodes, check it */
if (nid != NUMA_NO_NODE && nid != m_nid)
continue;
/* skip hotpluggable memory regions if needed */
if (movable_node_is_enabled() && memblock_is_hotpluggable(m))
continue;
/* if we want mirror memory skip non-mirror memory regions */
if ((flags & MEMBLOCK_MIRROR) && !memblock_is_mirror(m))
continue;
/* skip nomap memory unless we were asked for it explicitly */
if (!(flags & MEMBLOCK_NOMAP) && memblock_is_nomap(m))
continue;
if (!type_b) {
if (out_start)
*out_start = m_start;
if (out_end)
*out_end = m_end;
if (out_nid)
*out_nid = m_nid;
idx_a++;
*idx = (u32)idx_a | (u64)idx_b << 32;
return;
}
/* scan areas before each reservation */
for (; idx_b < type_b->cnt + 1; idx_b++) {
struct memblock_region *r;
phys_addr_t r_start;
phys_addr_t r_end;
r = &type_b->regions[idx_b];
r_start = idx_b ? r[-1].base + r[-1].size : 0;
r_end = idx_b < type_b->cnt ?
r->base : ULLONG_MAX;
/*
* if idx_b advanced past idx_a,
* break out to advance idx_a
*/
if (r_start >= m_end)
break;
/* if the two regions intersect, were done */
if (m_start < r_end) {
if (out_start)
*out_start =
max(m_start, r_start);
if (out_end)
*out_end = min(m_end, r_end);
if (out_nid)
*out_nid = m_nid;
/*
* The region which ends first is
* advanced for the next iteration.
*/
if (m_end <= r_end)
idx_a++;
else
idx_b++;
*idx = (u32)idx_a | (u64)idx_b << 32;
return;
}
}
}
/* signal end of iteration */
*idx = ULLONG_MAX;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.
该函数idx为type_a和type_b中起始索引组合,nid为寻找内存区域所在节点号,flags为标志位,out_start、out_end和out_nid为输出符合调节的内存区域物理地址范围及所在节点号,type_a为寻找内存区域必须处于其拥有内存范围内,type_b为寻找目标内存不在其拥有内存范围内。函数首先获取type_a和type_b中region数组起始索引,然后循环遍历寻找属于type_a但不属于type_b的首个内存区域。
复制
void __init_memblock __next_mem_range_rev(u64 *idx, int nid, ulong flags,
struct memblock_type *type_a,
struct memblock_type *type_b,
phys_addr_t *out_start,
phys_addr_t *out_end, int *out_nid)
{
int idx_a = *idx & 0xffffffff;
int idx_b = *idx >> 32;
if (WARN_ONCE(nid == MAX_NUMNODES, "Usage of MAX_NUMNODES is deprecated. Use NUMA_NO_NODE instead\n"))
nid = NUMA_NO_NODE;
if (*idx == (u64)ULLONG_MAX) {
idx_a = type_a->cnt - 1;
if (type_b != NULL)
idx_b = type_b->cnt;
else
idx_b = 0;
}
for (; idx_a >= 0; idx_a--) {
struct memblock_region *m = &type_a->regions[idx_a];
phys_addr_t m_start = m->base;
phys_addr_t m_end = m->base + m->size;
int m_nid = memblock_get_region_node(m);
/* only memory regions are associated with nodes, check it */
if (nid != NUMA_NO_NODE && nid != m_nid)
continue;
/* skip hotpluggable memory regions if needed */
if (movable_node_is_enabled() && memblock_is_hotpluggable(m))
continue;
/* if we want mirror memory skip non-mirror memory regions */
if ((flags & MEMBLOCK_MIRROR) && !memblock_is_mirror(m))
continue;
/* skip nomap memory unless we were asked for it explicitly */
if (!(flags & MEMBLOCK_NOMAP) && memblock_is_nomap(m))
continue;
if (!type_b) {
if (out_start)
*out_start = m_start;
if (out_end)
*out_end = m_end;
if (out_nid)
*out_nid = m_nid;
idx_a--;
*idx = (u32)idx_a | (u64)idx_b << 32;
return;
}
/* scan areas before each reservation */
for (; idx_b >= 0; idx_b--) {
struct memblock_region *r;
phys_addr_t r_start;
phys_addr_t r_end;
r = &type_b->regions[idx_b];
r_start = idx_b ? r[-1].base + r[-1].size : 0;
r_end = idx_b < type_b->cnt ?
r->base : ULLONG_MAX;
/*
* if idx_b advanced past idx_a,
* break out to advance idx_a
*/
if (r_end <= m_start)
break;
/* if the two regions intersect, were done */
if (m_end > r_start) {
if (out_start)
*out_start = max(m_start, r_start);
if (out_end)
*out_end = min(m_end, r_end);
if (out_nid)
*out_nid = m_nid;
if (m_start >= r_start)
idx_a--;
else
idx_b--;
*idx = (u32)idx_a | (u64)idx_b << 32;
return;
}
}
}
/* signal end of iteration */
*idx = ULLONG_MAX;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.
该函数与__next_mem_range()过程大致一致,只不过遍历方向是从高物理地址向低物理地址遍历。
②寻找空闲内存区域
复制
phys_addr_t __init_memblock memblock_find_in_range_node(phys_addr_t size,
phys_addr_t align, phys_addr_t start,
phys_addr_t end, int nid, ulong flags)
{
phys_addr_t kernel_end, ret;
/* pump up @end */
if (end == MEMBLOCK_ALLOC_ACCESSIBLE)
end = memblock.current_limit;
/* avoid allocating the first page */
start = max_t(phys_addr_t, start, PAGE_SIZE);
end = max(start, end);
kernel_end = __pa_symbol(_end);1.2.3.4.5.6.7.8.9.10.11.12.13.14.
该函数中size表示寻找物理内存大小(字节),align为物理内存对齐,start表示所寻找内存区域最小物理地址,end为最大物理地址,nid为节点号,flags为标志位。检查end是否等于MEMBLOCK_ALLOC_ACCESSIBLE,相等则设置end为memblock.current_limit,重新计算所查询物理地址范围。
复制
/*
* try bottom-up allocation only when bottom-up mode
* is set and @end is above the kernel image.
*/
if (memblock_bottom_up() && end > kernel_end) {
phys_addr_t bottom_up_start;
/* make sure we will allocate above the kernel */
bottom_up_start = max(start, kernel_end);
/* ok, try bottom-up allocation first */
ret = __memblock_find_range_bottom_up(bottom_up_start, end,
size, align, nid, flags);
if (ret)
return ret;
/*
* we always limit bottom-up allocation above the kernel,
* but top-down allocation doesnt have the limit, so
* retrying top-down allocation may succeed when bottom-up
* allocation failed.
*
* bottom-up allocation is expected to be fail very rarely,
* so we use WARN_ONCE() here to see the stack trace if
* fail happens.
*/
WARN_ONCE(1, "memblock: bottom-up allocation failed, memory hotunplug may be affected\n");
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.
检查memblock.bottom_up和end>kenel_end是否均为真,即内存查询是否为从低地址项高地址且end高与内核最大虚拟地址所对应的物理地址,重新获取查询范围并进行查询。
复制
1return __memblock_find_range_top_down(start, end, size, align, nid, 2 flags);1.
最后进行从高地址到低地址进行查询。
复制
static phys_addr_t __init_memblock
__memblock_find_range_bottom_up(phys_addr_t start, phys_addr_t end,
phys_addr_t size, phys_addr_t align, int nid,
ulong flags)
{
phys_addr_t this_start, this_end, cand;
u64 i;
for_each_free_mem_range(i, nid, flags, &this_start, &this_end, NULL) {
this_start = clamp(this_start, start, end);
this_end = clamp(this_end, start, end);
cand = round_up(this_start, align);
if (cand < this_end && this_end - cand >= size)
return cand;
}
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
该函数会通过for_each_free_mem_range()宏对memblock中进行遍历(由低物理地址到高物理地址),寻找属于memblock.memory但不属于memblock.reserved且符合添加的物理内存区域。
复制
static phys_addr_t __init_memblock
__memblock_find_range_top_down(phys_addr_t start, phys_addr_t end,
phys_addr_t size, phys_addr_t align, int nid,
ulong flags)
{
phys_addr_t this_start, this_end, cand;
u64 i;
for_each_free_mem_range_reverse(i, nid, flags, &this_start, &this_end,
NULL) {
this_start = clamp(this_start, start, end);
this_end = clamp(this_end, start, end);
if (this_end < size)
continue;
cand = round_down(this_end - size, align);
if (cand >= this_start)
return cand;
}
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.
该函数与__memblock_find_range_bottom_up()工作过程类似,只是遍历方向为高地址到低地址。
③向memblock_type添加memblock_region
复制
int __init_memblock memblock_add_range(struct memblock_type *type,
phys_addr_t base, phys_addr_t size,
int nid, unsigned long flags)
{
bool insert = false;
phys_addr_t obase = base;
phys_addr_t end = base + memblock_cap_size(base, &size);
int idx, nr_new;
struct memblock_region *rgn;
if (!size)
return 0;
/* special case for empty array */
if (type->regions[0].size == 0) {
WARN_ON(type->cnt != 1 || type->total_size);
type->regions[0].base = base;
type->regions[0].size = size;
type->regions[0].flags = flags;
memblock_set_region_node(&type->regions[0], nid);
type->total_size = size;
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.
该函数base为添加内存起始物理地址,size为添加的物理内存大小(字节数目),nid为添加内存所在节点号,flasg为添加region标志位。首先计算获取所添加物理内存所在物理地址范围,然后检查memblock_type中region数组是否为空。如果为空则初始化region数组首个元素并返回。
复制
repeat:
/*
* The following is executed twice. Once with %false @insert and
* then with %true. The first counts the number of regions needed
* to accommodate the new area. The second actually inserts them.
*/
base = obase;
nr_new = 0;
for_each_memblock_type(idx, type, rgn) {
phys_addr_t rbase = rgn->base;
phys_addr_t rend = rbase + rgn->size;
if (rbase >= end)
break;
if (rend <= base)
continue;
/*
* @rgn overlaps. If it separates the lower part of new
* area, insert that portion.
*/
if (rbase > base) {
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
WARN_ON(nid != memblock_get_region_node(rgn));
#endif
WARN_ON(flags != rgn->flags);
nr_new++;
if (insert)
memblock_insert_region(type, idx++, base,
rbase - base, nid,
flags);
}
/* area below @rend is dealt with, forget about it */
base = min(rend, end);
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.
遍历memblock_type所具有的region数组,获取数组中基地址处于base~end之间的元素,如果寻找到并且insert为真则将处于base~rbase之间的内存插入数组中,nr_new表示新插入的元素会增加1,继续遍历。
复制
/* insert the remaining portion */
if (base < end) {
nr_new++;
if (insert)
memblock_insert_region(type, idx, base, end - base,
nid, flags);
}
if (!nr_new)
return 0;1.2.3.4.5.6.7.8.9.10.
经过遍历后,检查内存区域是否完全插入,如果有部分区域并未插入则检查insert是否为真,为真则将剩余部分也插入region数组中,否则继续运行。
复制
/*
* If this was the first round, resize array and repeat for actual
* insertions; otherwise, merge and return.
*/
if (!insert) {
while (type->cnt + nr_new > type->max)
if (memblock_double_array(type, obase, size) < 0)
return -ENOMEM;
insert = true;
goto repeat;
} else {
memblock_merge_regions(type);
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.
检查insert是否为真,若为真则将memblock_type中的region数组进行合并,否则检查nr_new+type->cnt是否超出type中region数组最大数,超出则对type中region数组进行扩充,设置insert为真继续重复以上操作。
复制
static void __init_memblock memblock_insert_region(struct memblock_type *type,
int idx, phys_addr_t base,
phys_addr_t size,
int nid, unsigned long flags)
{
struct memblock_region *rgn = &type->regions[idx];
BUG_ON(type->cnt >= type->max);
memmove(rgn + 1, rgn, (type->cnt - idx) * sizeof(*rgn));
rgn->base = base;
rgn->size = size;
rgn->flags = flags;
memblock_set_region_node(rgn, nid);
type->cnt++;
type->total_size += size;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.
该函数idx表示插入region数组索引,base表示内存物理起始地址,size表示内存大小(字节数目)。首先获取idx所对应memblock_region指针,再将索引处于idx~type->cnt范围的region元素复制到idx+1~cnt+1所对应数组中,最后进行初始化并增加type相应计数。
复制
static void __init_memblock memblock_merge_regions(struct memblock_type *type)
{
int i = 0;
/* cnt never goes below 1 */
while (i < type->cnt - 1) {
struct memblock_region *this = &type->regions[i];
struct memblock_region *next = &type->regions[i + 1];
if (this->base + this->size != next->base ||
memblock_get_region_node(this) !=
memblock_get_region_node(next) ||
this->flags != next->flags) {
BUG_ON(this->base + this->size > next->base);
i++;
continue;
}
this->size += next->size;
/* move forward from next + 1, index of which is i + 2 */
memmove(next, next + 1, (type->cnt - (i + 2)) * sizeof(*next));
type->cnt--;
}
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.
该函数遍历type中region数组,将内存区域连续的region合并。
④扩充memblock_type中region数组空间
复制
static int __init_memblock memblock_double_array(struct memblock_type *type,
phys_addr_t new_area_start,
phys_addr_t new_area_size)
{
struct memblock_region *new_array, *old_array;
phys_addr_t old_alloc_size, new_alloc_size;
phys_addr_t old_size, new_size, addr;
int use_slab = slab_is_available();
int *in_slab;
/* We dont allow resizing until we know about the reserved regions
* of memory that arent suitable for allocation
*/
if (!memblock_can_resize)
return -1;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.
该函数中new_area_start表示向type中添加物理内存区域起始物理地址,new_area_start表示内存区域大小。收件检查是否使用slab缓存以及是否可以扩充type中region数组大小。
复制
/* Calculate new doubled size */
old_size = type->max * sizeof(struct memblock_region);
new_size = old_size << 1;
/*
* We need to allocated new one align to PAGE_SIZE,
* so we can free them completely later.
*/
old_alloc_size = PAGE_ALIGN(old_size);
new_alloc_size = PAGE_ALIGN(new_size);
/* Retrieve the slab flag */
if (type == &memblock.memory)
in_slab = &memblock_memory_in_slab;
else
in_slab = &memblock_reserved_in_slab;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.
获取原region数组大小并将其乘以2作为将要分配region数组大小,按页面对齐并根据type类型获取相应slab缓存使用标志位。
复制
if (use_slab) {
new_array = kmalloc(new_size, GFP_KERNEL);
addr = new_array ? __pa(new_array) : 0;
} else {
/* only exclude range when trying to double reserved.regions */
if (type != &memblock.reserved)
new_area_start = new_area_size = 0;
addr = memblock_find_in_range(new_area_start + new_area_size,
memblock.current_limit,
new_alloc_size, PAGE_SIZE);
if (!addr && new_area_size)
addr = memblock_find_in_range(0,
min(new_area_start, memblock.current_limit),
new_alloc_size, PAGE_SIZE);
new_array = addr ? __va(addr) : NULL;
}
if (!addr) {
pr_err("memblock: Failed to double %s array from %ld to %ld entries !\n",
type->name, type->max, type->max * 2);
return -1;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.
开始分配新region数组内存空间,如果使用slab,则从slab缓存中分配,否则从memblock中分配。
复制
memcpy(new_array, type->regions, old_size);
memset(new_array + type->max, 0, old_size);
old_array = type->regions;
type->regions = new_array;
type->max <<= 1;
/* Free old array. We neednt free it if the array is the static one */
if (*in_slab)
kfree(old_array);
else if (old_array != memblock_memory_init_regions &&
old_array != memblock_reserved_init_regions)
memblock_free(__pa(old_array), old_alloc_size);
/*
* Reserve the new array if that comes from the memblock. Otherwise, we
* neednt do it
*/
if (!use_slab)
BUG_ON(memblock_reserve(addr, new_alloc_size));
/* Update slab flag */
*in_slab = use_slab;
return 0;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.
最后复制原来region数组并将剩余空间设为0并释放原数组所在内存空间。
⑤移除memblock_type中相应内存区域
复制
static int __init_memblock memblock_isolate_range(struct memblock_type *type,
phys_addr_t base, phys_addr_t size,
int *start_rgn, int *end_rgn)
{
phys_addr_t end = base + memblock_cap_size(base, &size);
int idx;
struct memblock_region *rgn;
*start_rgn = *end_rgn = 0;
if (!size)
return 0;
/* well create at most two more regions */
while (type->cnt + 2 > type->max)
if (memblock_double_array(type, base, size) < 0)
return -ENOMEM;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.
该函数从type中region数组分离指定范围物理内存,base表示分离内存区域起始物理地址,size为分离物理内存大小,start_rgn为输出分离后的内存区域起始region,end_rgn为结束region。如果type中region数组空间不足则扩充region数组。
复制
for_each_memblock_type(idx, type, rgn) {
phys_addr_t rbase = rgn->base;
phys_addr_t rend = rbase + rgn->size;
if (rbase >= end)
break;
if (rend <= base)
continue;
if (rbase < base) {
/*
* @rgn intersects from below. Split and continue
* to process the next region - the new top half.
*/
rgn->base = base;
rgn->size -= base - rbase;
type->total_size -= base - rbase;
memblock_insert_region(type, idx, rbase, base - rbase,
memblock_get_region_node(rgn),
rgn->flags);
} else if (rend > end) {
/*
* @rgn intersects from above. Split and redo the
* current region - the new bottom half.
*/
rgn->base = end;
rgn->size -= end - rbase;
type->total_size -= end - rbase;
memblock_insert_region(type, idx--, rbase, end - rbase,
memblock_get_region_node(rgn),
rgn->flags);
} else {
/* @rgn is fully contained, record it */
if (!*end_rgn)
*start_rgn = idx;
*end_rgn = idx + 1;
}
}
return 0;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.
循环遍历type中region数组,对于处于分离内存区域的region进行分割并重新插入到数组中,最后返回索引。
复制
static void __init_memblock memblock_remove_region(struct memblock_type *type, unsigned long r)
{
type->total_size -= type->regions[r].size;
memmove(&type->regions[r], &type->regions[r + 1],
(type->cnt - (r + 1)) * sizeof(type->regions[r]));
type->cnt--;
/* Special case for empty arrays */
if (type->cnt == 0) {
WARN_ON(type->total_size != 0);
type->cnt = 1;
type->regions[0].base = 0;
type->regions[0].size = 0;
type->regions[0].flags = 0;
memblock_set_region_node(&type->regions[0], MAX_NUMNODES);
}
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.
将type中指定索引region移除数组。
复制
static int __init_memblock memblock_remove_range(struct memblock_type *type,
phys_addr_t base, phys_addr_t size)
{
int start_rgn, end_rgn;
int i, ret;
ret = memblock_isolate_range(type, base, size, &start_rgn, &end_rgn);
if (ret)
return ret;
for (i = end_rgn - 1; i >= start_rgn; i--)
memblock_remove_region(type, i);
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.
从type移除处于给定范围内物理内存区域。
二、伙伴分配器
当引导内存分配器完成它的使命后,伙伴分配器便接过了管理物理内存的重任,成为 Linux 内存管理中的中流砥柱。伙伴分配器在物理内存分配中占据着基础性的关键地位,它主要负责管理连续的物理内存页,为系统中对大块内存有需求的部分提供支持 。
伙伴分配器的工作原理极具特色,它以 2 的幂次方为单位来管理内存块,将物理内存划分成一系列大小不同的页块(page block)。这里引入了一个重要的概念 —— 阶(order),2^n 个连续的页被称为 n 阶页块,例如,1 个页是 0 阶页块,2 个连续页是 1 阶页块,4 个连续页则是 2 阶页块,以此类推 。
在伙伴分配器的管理体系中,内存块之间存在着一种特殊的 “伙伴关系”。满足以下条件的两个 n 阶页块被称为伙伴:首先,它们的物理地址必须是连续的,就像邻居一样紧紧相邻;其次,页块的第一页的物理页号必须是 2^n 的整数倍,这是一种特定的位置规则;最后,如果将它们合并成(n+1)阶页块,合并后的页块第一页的物理页号必须是 2^(n+1) 的整数倍 。例如,假设一个系统的页大小为 4KB,那么 0 号页和 1 号页(它们组成 1 阶页块,每个页块包含 2 个页,即 8KB)是伙伴,因为它们地址连续,0 号页的页号是 2^0(也就是 1)的整数倍,且它们合并成 2 阶页块(包含 4 个页,16KB)时,第一页 0 号页的页号也是 2^1(即 2)的整数倍 。
当系统需要分配内存时,伙伴分配器会按照一定的策略进行操作。如果请求分配 n 阶页块,它首先会查看是否有空闲的 n 阶页块,如果有,就如同从货架上直接取下一件商品一样,直接将其分配出去;若没有空闲的 n 阶页块,它就会去查看是否存在空闲的(n+1)阶页块。若有,就会将(n+1)阶页块巧妙地分裂为两个 n 阶页块,一个插入空闲 n 阶页块链表,以备后续分配使用,另一个则分配给需要的程序 。如果连(n+1)阶页块也没有空闲的,那就继续查看更高阶的页块,直到找到合适的页块进行分配或者确定无法满足分配需求为止 。
释放内存的过程则是分配的逆过程。当释放一个 n 阶页块时,伙伴分配器会仔细检查它的伙伴是否空闲。如果伙伴不空闲,就将该 n 阶页块插入到空闲的 n 阶页块链表中;如果伙伴空闲,那么就如同将两个相邻的积木块合并成一个更大的积木块一样,将它们合并为 n+1 阶页块,然后再对这个合并后的 n+1 阶页块重复上述释放检查操作,直到不能合并或者已经合并到最大的块为止 。
伙伴分配器在内存管理方面具有显著的优点。由于它将物理内存按照物理页号(PFN)将不同的页放入到不同阶的链表中,根据需要分配内存的大小,能够快速计算出当前分配应该在哪个阶去找空闲的内存块,如果当前阶中没有空闲块,就可以迅速到更高阶的链表中去查找,因此分配效率相较于bootmem的线性扫描位图有了大幅提升 。这种方式就像是在一个精心分类的图书馆中找书,每个书架都按照特定的规则摆放书籍,读者可以快速定位到自己需要的书籍所在的书架区域 。
然而,伙伴分配器也并非完美无缺。在释放内存时,调用方必须记住之前该页分配的阶数,然后释放从该页开始的 2^order 个页,这对于调用者来说是一个不小的负担,容易出错且使用不够便捷 。
另外,由于伙伴分配器每次分配必须是 2^order 个页同时分配,当实际需要的内存大小小于 2^order 时,就会不可避免地造成内存浪费,产生内部碎片 。例如,如果一个程序只需要 5KB 的内存,但伙伴分配器按照规则可能会分配 8KB 的内存块(1 阶页块,假设页大小为 4KB),那么就会有 3KB 的内存被浪费,这在对内存使用效率要求极高的场景下,可能会成为一个制约因素 。
满足以下条件 的两个n阶页块称为伙伴:
1)两个页块是相邻的,即物理地址是连续的;2)页块的第一页的物理页号必须是2^n 的整数倍;3)如果合并成(n+1)阶页块,第一页的物理页号必须是2^(n+1) 的整数倍。
2.2伙伴分配器原理
伙伴分配器分配和释放物理页的数量单位为阶。分配n阶页块的过程如下:
查看是否有空闲的n阶页块,如果有直接分配;否则,继续执行下一步;查看是否存在空闲的(n+1)阶页块,如果有,把(n+1)阶页块分裂为两个n阶页块,一个插入空闲n阶页块链表,另一个分配出去;否则继续执行下一步。查看是否存在空闲的(n+2)阶页块,如果有把(n+2)阶页块分裂为两个(n+1)阶页块,一个插入空闲(n+1)阶页块链表,另一个分裂为两个n阶页块,一个插入空间(n阶页块链表,另一个分配出去;如果没有,继续查看更高阶是否存在空闲页块。
上图的buddy分配和回收可以简单叙述成:需要分配内存时如果没有合适的内存块,会对半切分内存块直到分离出合适大小的内存块为止,最后再将其返回。需要释放内存时,会寻找相邻的块,如果其已经释放了,就将这俩合并,再递归这个过程,直到无法再合并为止。
2.2数据结构
分区的伙伴分配器专注于某个内存节点的某个区域。内存区域的结构体成员free_area用来维护空闲页块,数组下标对应页块的阶数。 系统内存中的每个物理内存页(页帧),都对应于一个struct page实例, 每个内存域都关联了一个struct zone的实例,其中保存了用于管理伙伴数据的主要数数组,内核源码结构
复制
/include/linux/mmzone.h
struct zone
{
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
};
......
/* Free memory management - zoned buddy allocator. */
#ifndef CONFIG_FORCE_MAX_ZONEORDER
#define MAX_ORDER 11
#else
#define MAX_ORDER CONFIG_FORCE_MAX_ZONEORDER
#endif
#define MAX_ORDER_NR_PAGES (1 << (MAX_ORDER - 1))1.2.3.4.5.6.7.8.9.10.11.12.13.14.
struct free_area是一个伙伴系统的辅助数据结构:
复制
struct free_area {
struct list_head free_list[MIGRATE_TYPES];//是用于连接空闲页的链表. 页链表包含大小相同的连续内存区
unsigned long nr_free;//指定了当前内存区中空闲页块的数目(对0阶内存区逐页计算,对1阶内存区计算2页的数目,对2阶内存区计算4页集合的数目,依次类推
};1.2.3.4.
伙伴系统的明显缺点是:由于圆整到下一个 2 的幂,很可能造成分配段内的碎片。例如,33KB 的内存请求只能使用 64KB 段来满足。事实上,我们不能保证因内部碎片而浪费的单元一定少于 50%。
2.3伙伴分配器的优缺点
优点:由于将物理内存按照PFN将不同的page放入到不同order中,根据需要分配内存的大小,计算当前这次分配应该在哪个order中去找空闲的内存块,如果当前order中没有空闲,则到更高阶的order中去查找,因此分配的效率比boot memory的线性扫描bitmap要快很多。
缺点:
1)释放page的时候调用方必须记住之前该page分配的order,然后释放从该page开始的2order 个page,这对于调用者来说有点不方便2)因为buddy allocator每次分配必须是2order 个page同时分配,这样当实际需要内存大小小于2order 时,就会造成内存浪费,所以Linux为了解决buddy allocator造成的内部碎片问题,后面会引入slab分配器。(1)伙伴分配器的分配释放流程
伙伴分配器分配和释放物理页的数量单位为阶。分配n阶页块的过程如下:
1)查看是否有空闲的n阶页块,如果有直接分配;否则,继续执行下一步;2)查看是否存在空闲的(n+1)阶页块,如果有,把(n+1)阶页块分裂为两个n阶页块,一个插入空闲n阶页块链表,另一个分配出去;否则继续执行下一步。3)查看是否存在空闲的(n+2)阶页块,如果有把(n+2)阶页块分裂为两个(n+1)阶页块,一个插入空闲(n+1)阶页块链表,另一个分裂为两个n阶页块,一个插入空间n阶页块链表,另一个分配出去;如果没有,继续查看更高阶是否存在空闲页块。(2)伙伴分配器的数据结构
分区的伙伴分配器专注于某个内存节点的某个区域。内存区域的结构体成员free_area用来维护空闲页块,数组下标对应页块的阶数。
 图片
图片
内核源码结构:
复制
struct zone {
.......
/*free areas of different sizes */
struct free_areafree_area [MAx_ORDER];
/*zone flags, see below*/
unsigned long flags ;
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};1.2.3.4.5.6.7.8.9.10.
内核使用GFP_ZONE_TABLE 定义了区域类型映射表的标志组合,其中GFP_ZONES_SHIFT是区域类型占用的位数,GFP_ZONE_TABLE 把每种标志组合映射到32位整数的某个位置,偏移是(标志组合*区域类型位数),从这个偏移开始的GFP_ZONES_SHIFT个二进制存放区域类型。
复制
#define GFP_ZONE_TABLE ( \
(ZONE_NORMAL << 0 * GFP_ZONES_SHIFT) \
| (OPT_ZONE_DMA << ___GFP_DMA * GFP_ZONES_SHIFT) \
| (OPT_ZONE_HIGHMEM << ___GFP_HIGHMEM * GFP_ZONES_SHIFT) \
| (OPT_ZONE_DMA32 << ___GFP_DMA32 * GFP_ZONES_SHIFT) \
| (ZONE_NORMAL << ___GFP_MOVABLE * GFP_ZONES_SHIFT) \
| (OPT_ZONE_DMA << (___GFP_MOVABLE | ___GFP_DMA) * GFP_ZONES_SHIFT) \
| (ZONE_MOVABLE << (___GFP_MOVABLE | ___GFP_HIGHMEM) * GFP_ZONES_SHIFT)\
| (OPT_ZONE_DMA32 << (___GFP_MOVABLE | ___GFP_DMA32) * GFP_ZONES_SHIFT)\
)
//根据flags标志获取首选区域
#define ___GFP_DMA 0x01u
#define ___GFP_HIGHMEM 0x02u
#define ___GFP_DMA32 0x04u
#define ___GFP_MOVABLE 0x081.2.3.4.5.6.7.8.9.10.11.12.13.14.15.
备用区域列表
备用区域这个东西很重要,但是我现在也不能完完全全的了解他,只知道他可以加快我们申请内存的速度,下面的快速路径会用到他。
如果首选的内存节点或区域不能满足分配请求,可以从备用的内存区域借用物理页。借用必须遵守相应的规则。
借用规则:
1)一个内存节点的某个区域类型可以从另外一个内存节点的相同区域类型借用物理页,比如节点0的普通区域可以从节点为1的普通区域借用物理页。2)高区域类型的可以从地区域类型借用物理页,比如普通区域可以从DMA区域借用物理页3)地区域类型的不可以从高区域类型借用物理页,比如DMA区域不可以从普通区域借用物理页
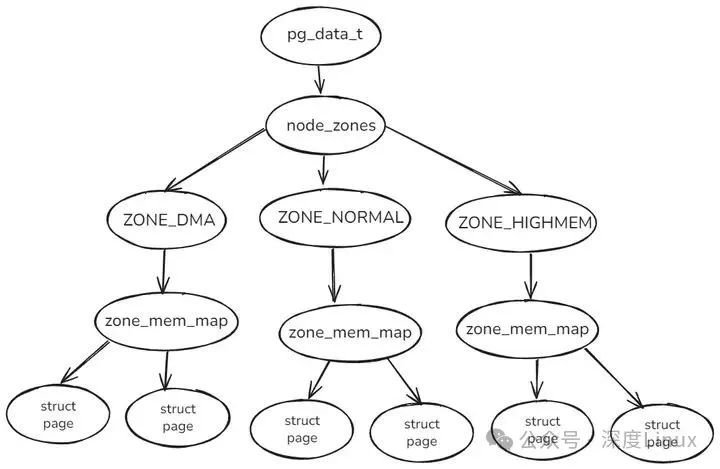
内存节点的结构体pg_data_t实例已定义备用区域列表node_zonelists。
2.4伙伴分配器的结构
内核源码如下:
复制
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];//内存区域数组
struct zonelist node_zonelists[MAX_ZONELISTS];//MAX_ZONELISTS个备用区域数组
int nr_zones;//该节点包含的内存区域数量
......
}
//struct zone在linux内存管理(一)中
struct zonelist {
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
};
struct zoneref {
struct zone *zone;//指向内存区域数据结构
int zone_idx;//成员zone指向内存区域的类型
};
enum {
ZONELIST_FALLBACK,//包含所有内存节点的的备用区域列表
#ifdef CONFIG_NUMA
/*
* The NUMA zonelists are doubled because we need zonelists that
* restrict the allocations to a single node for __GFP_THISNODE.
*/
ZONELIST_NOFALLBACK,//只包含当前节点的备用区域列表(NUMA专用)
#endif
MAX_ZONELISTS//表示备用区域列表数量
};1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.
UMA系统只有一个备用区域的列表,按照区域类型从高到低顺序排列。假设UMA系统中包含普通区域和DMA区域,则备用区域列表为:(普通区域、MDA区域)。NUMA系统中每个内存节点有两个备用区域列表:一个包含所有节点的内存区域,另一个仅包含当前节点的内存区域。
ZONELIST_FALLBACK(包含所有内存节点的备用区域)列表有两种排序方法:
a.节点优先顺序
先根据节点距离从小到大排序, 然后在每个节点里面根据区域类型从高到低排序。优点是优先选择距离近的内存, 缺点是在高区域耗尽以前使用低区域。
b.区域优先顺序
先根据区域类型从高到低排序, 然后在每个区域类型里面根据节点距离从小到大排序。优点是减少低区域耗尽的概率, 缺点是不能保证优先选择距离近的内存。默认的排序方法就是自动选择最优的排序方法:比如是64位系统,因为需要DMA和DMA32区域的备用相对少,所以选择节点优先顺序;如果是32位系统,选择区域优先顺序。内存区域水线
首选的内存区域什么情况下从备用区域借用物理页呢?每个内存区域有3个水线:
a.高水线(high):如果内存区域的空闲页数大于高水线,说明内存区域的内存非常充足;b.低水线(low):如果内存区域的空闲页数小于低水线,说明内存区域的内存轻微不足;c.最低水线(min):如果内存区域的空闲页数小于最低水线,说明内存区域的内存严重不足。
而且每个区域的水位线是初始化的时候通过每个区域的物理页情况计算出来的。计算后存到struct zone的watermark数组中,使用的时候直接通过下面的宏定义获取:
复制
#define min_wmark_pages(z) (z->watermark[WMARK_MIN])
#define low_wmark_pages(z) (z->watermark[WMARK_LOW])
#define high_wmark_pages(z) (z->watermark[WMARK_HIGH])1.2.3.
struct zone的数据结构:


复制
spanned_pages = zone_end_pfn - zone_start_pfn;//区域结束的物理页减去起始页=当前区域跨越的总页数(包括空洞)
present_pages = spanned_pages - absent_pages(pages in holes)//当前区域跨越的总页数-空洞页数=当前区域可用物理页数
managed_pages = present_pages - reserved_pages//当前区域可用物理页数-预留的页数=伙伴分配器管理物理页数1.2.3.
最低水线以下的内存称为紧急保留内存,一般用于内存回收,其他情况不可以动用紧急保留内存,在内存严重不足的紧急情况下,给承诺"分给我们少量的紧急保留内存使用,我可以释放更多的内存"的进程使用。
可以通过/proc/zoneinfo看到系统zone的水位线和物理页情况:
复制
jian@ubuntu:~/share/linux-4.19.40-note$ cat /proc/zoneinfo
Node 0, zone DMA
pages free 3912
min 7
low 8
high 10
scanned 0
spanned 4095
present 3997
managed 3976
...
Node 0, zone DMA32
pages free 6515
min 1497
low 1871
high 2245
scanned 0
spanned 1044480
present 782288
managed 762172
...
Node 0, zone Normal
pages free 2964
min 474
low 592
high 711
scanned 0
spanned 262144
present 262144
managed 241089
...1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.
2.5伙伴分配器分配过程分析
当向内核请求分配 (2(i-1),2i]数目的页块时,按照 2^i 页块请求处理。如果对应的页块链表中没有空闲页块,那我们就在更大的页块链表中去找。当分配的页块中有多余的页时,伙伴系统会根据多余的页块大小插入到对应的空闲页块链表中。
例如,要请求一个 128 个页的页块时,先检查 128 个页的页块链表是否有空闲块。如果没有,则查 256 个页的页块链表;如果有空闲块的话,则将 256 个页的页块分成两份,一份使用,一份插入 128 个页的页块链表中。如果还是没有,就查 512 个页的页块链表;如果有的话,就分裂为 128、128、256 三个页块,一个 128 的使用,剩余两个插入对应页块链表。
伙伴分配器进行页分配的时候首先调用alloc_pages,alloc_pages 会调用 alloc_pages_current,alloc_pages_current会调用__alloc_pages_nodemask函数,他是伙伴分配器的核心函数:
复制
/* The ALLOC_WMARK bits are used as an index to zone->watermark */
#define ALLOC_WMARK_MIN WMARK_MIN //使用最低水线
#define ALLOC_WMARK_LOW WMARK_LOW //使用低水线
#define ALLOC_WMARK_HIGH WMARK_HIGH //使用高水线
#define ALLOC_NO_WATERMARKS 0x04 //完全不检查水线
#define ALLOC_WMARK_MASK (ALLOC_NO_WATERMARKS-1)//得到水位线的掩码
#ifdef CONFIG_MMU
#define ALLOC_OOM 0x08 //允许内存耗尽
#else
#define ALLOC_OOM ALLOC_NO_WATERMARKS//允许内存耗尽
#endif
#define ALLOC_HARDER 0x10 //试图更努力分配
#define ALLOC_HIGH 0x20 //调用者是高优先级
#define ALLOC_CPUSET 0x40 //检查 cpuset 是否允许进程从某个内存节点分配页
#define ALLOC_CMA 0x80 //允许从CMA(连续内存分配器)迁移类型分配1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.
上面是alloc_pages的第一个参数分配标志位,表示分配的允许情况,alloc_pages的第二个参数表示分配的阶数:
复制
static inline struct page *
alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_current(gfp_mask, order);
}
struct page *alloc_pages_current(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;
struct page *page;
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));
else
page = __alloc_pages_nodemask(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;
}
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
{
...
/* First allocation attempt */ //快速路径分配函数
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
...
//快速路径分配失败,会调用下面的慢速分配函数
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
out:
if (memcg_kmem_enabled() && (gfp_mask & __GFP_ACCOUNT) && page &&
unlikely(memcg_kmem_charge(page, gfp_mask, order) != 0)) {
__free_pages(page, order);
page = NULL;
}
trace_mm_page_alloc(page, order, alloc_mask, ac.migratetype);
return page;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.
从伙伴分配器的核心函数__alloc_pages_nodemask可以看到函数主要两部分,一是执行快速分配函数get_page_from_freelist,二是执行慢速分配函数__alloc_pages_slowpath。现在先看快速分配函数get_page_from_freelist:
复制
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z = ac->preferred_zoneref;
struct zone *zone;
struct pglist_data *last_pgdat_dirty_limit = NULL;
//扫描备用区域列表中每一个满足条件的区域:区域类型小于等于首选区域类型
for_next_zone_zonelist_nodemask(zone, z, ac->zonelist, ac->high_zoneidx,
ac->nodemask) {
struct page *page;
unsigned long mark;
if (cpusets_enabled() && //如果编译了cpuset功能
(alloc_flags & ALLOC_CPUSET) && //如果设置了ALLOC_CPUSET
!__cpuset_zone_allowed(zone, gfp_mask)) //如果cpu设置了不允许从当前区域分配内存
continue; //那么不允许从这个区域分配,进入下个循环
if (ac->spread_dirty_pages) {//如果设置了写标志位,表示要分配写缓存
//那么要检查内存脏页数量是否超出限制,超过限制就不能从这个区域分配
if (last_pgdat_dirty_limit == zone->zone_pgdat)
continue;
if (!node_dirty_ok(zone->zone_pgdat)) {
last_pgdat_dirty_limit = zone->zone_pgdat;
continue;
}
}
mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];//检查允许分配水线
//判断(区域空闲页-申请页数)是否小于水线
if (!zone_watermark_fast(zone, order, mark,
ac_classzone_idx(ac), alloc_flags)) {
int ret;
/* Checked here to keep the fast path fast */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
//如果没有水线要求,直接选择该区域
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
//如果没有开启节点回收功能或者当前节点和首选节点距离大于回收距离
if (node_reclaim_mode == 0 ||
!zone_allows_reclaim(ac->preferred_zoneref->zone, zone))
continue;
//从节点回收“没有映射到进程虚拟地址空间的内存页”,然后检查水线
ret = node_reclaim(zone->zone_pgdat, gfp_mask, order);
switch (ret) {
case NODE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case NODE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
if (zone_watermark_ok(zone, order, mark,
ac_classzone_idx(ac), alloc_flags))
goto try_this_zone;
continue;
}
}
try_this_zone://满足上面的条件了,开始分配
//从当前区域分配页
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
//分配成功,初始化页
prep_new_page(page, order, gfp_mask, alloc_flags);
/*
* If this is a high-order atomic allocation then check
* if the pageblock should be reserved for the future
*/
//如果这是一个高阶的内存并且是ALLOC_HARDER,需要检查以后是否需要保留
if (unlikely(order && (alloc_flags & ALLOC_HARDER)))
reserve_highatomic_pageblock(page, zone, order);
return page;
} else {
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/* Try again if zone has deferred pages */
//如果分配失败,延迟分配
if (static_branch_unlikely(&deferred_pages)) {
if (_deferred_grow_zone(zone, order))
goto try_this_zone;
}
#endif
}
}
return NULL;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.
每一个 zone,都有伙伴系统维护的各种大小的队列,就像上面伙伴系统原理里讲的那样。这里调用 rmqueue 就很好理解了,就是找到合适大小的那个队列,把页面取下来。接下来的调用链是 rmqueue->__rmqueue->__rmqueue_smallest。在这里,我们能清楚看到伙伴系统的逻辑。
复制
static inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = &(zone->free_area[current_order]);
page = list_first_entry_or_null(&area->free_list[migratetype],
struct page, lru);
if (!page)
continue;
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.
从当前的 order,也即指数开始,在伙伴系统的 free_area 找 2^order 大小的页块。如果链表的第一个不为空,就找到了;如果为空,就到更大的 order 的页块链表里面去找。找到以后,除了将页块从链表中取下来,我们还要把多余部分放到其他页块链表里面。expand 就是干这个事情的。area–就是伙伴系统那个表里面的前一项,前一项里面的页块大小是当前项的页块大小除以 2,size 右移一位也就是除以 2,list_add 就是加到链表上,nr_free++ 就是计数加 1。
然后看看慢速分配函数__alloc_pages_slowpath:
复制
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM;
const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER;
struct page *page = NULL;
unsigned int alloc_flags;
unsigned long did_some_progress;
enum compact_priority compact_priority;
enum compact_result compact_result;
int compaction_retries;
int no_progress_loops;
unsigned int cpuset_mems_cookie;
int reserve_flags;
/*
* We also sanity check to catch abuse of atomic reserves being used by
* callers that are not in atomic context.
*/
if (WARN_ON_ONCE((gfp_mask & (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)) ==
(__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)))
gfp_mask &= ~__GFP_ATOMIC;
retry_cpuset:
compaction_retries = 0;
no_progress_loops = 0;
compact_priority = DEF_COMPACT_PRIORITY;
//后面可能会检查cpuset是否允许当前进程从哪些内存节点申请页
cpuset_mems_cookie = read_mems_allowed_begin();
/*
* The fast path uses conservative alloc_flags to succeed only until
* kswapd needs to be woken up, and to avoid the cost of setting up
* alloc_flags precisely. So we do that now.
*/
//把分配标志位转化为内部的分配标志位
alloc_flags = gfp_to_alloc_flags(gfp_mask);
/*
* We need to recalculate the starting point for the zonelist iterator
* because we might have used different nodemask in the fast path, or
* there was a cpuset modification and we are retrying - otherwise we
* could end up iterating over non-eligible zones endlessly.
*/
//获取首选的内存区域,因为在快速路径中使用了不同的节点掩码,避免再次遍历不合格的区域。
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
if (!ac->preferred_zoneref->zone)
goto nopage;
//异步回收页,唤醒kswapd内核线程进行页面回收
if (gfp_mask & __GFP_KSWAPD_RECLAIM)
wake_all_kswapds(order, gfp_mask, ac);
/*
* The adjusted alloc_flags might result in immediate success, so try
* that first
*/
//调整alloc_flags后可能会立即申请成功,所以先尝试一下
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/*
* For costly allocations, try direct compaction first, as its likely
* that we have enough base pages and dont need to reclaim. For non-
* movable high-order allocations, do that as well, as compaction will
* try prevent permanent fragmentation by migrating from blocks of the
* same migratetype.
* Dont try this for allocations that are allowed to ignore
* watermarks, as the ALLOC_NO_WATERMARKS attempt didnt yet happen.
*/
//申请阶数大于0,不可移动的位于高阶的,忽略水位线的
if (can_direct_reclaim &&
(costly_order ||
(order > 0 && ac->migratetype != MIGRATE_MOVABLE))
&& !gfp_pfmemalloc_allowed(gfp_mask)) {
//直接页面回收,然后进行页面分配
page = __alloc_pages_direct_compact(gfp_mask, order,
alloc_flags, ac,
INIT_COMPACT_PRIORITY,
&compact_result);
if (page)
goto got_pg;
/*
* Checks for costly allocations with __GFP_NORETRY, which
* includes THP page fault allocations
*/
if (costly_order && (gfp_mask & __GFP_NORETRY)) {
/*
* If compaction is deferred for high-order allocations,
* it is because sync compaction recently failed. If
* this is the case and the caller requested a THP
* allocation, we do not want to heavily disrupt the
* system, so we fail the allocation instead of entering
* direct reclaim.
*/
if (compact_result == COMPACT_DEFERRED)
goto nopage;
/*
* Looks like reclaim/compaction is worth trying, but
* sync compaction could be very expensive, so keep
* using async compaction.
*/
//同步压缩非常昂贵,所以继续使用异步压缩
compact_priority = INIT_COMPACT_PRIORITY;
}
}
retry:
/* Ensure kswapd doesnt accidentally go to sleep as long as we loop */
//如果页回收线程意外睡眠则再次唤醒
if (gfp_mask & __GFP_KSWAPD_RECLAIM)
wake_all_kswapds(order, gfp_mask, ac);
//如果调用者承若给我们紧急内存使用,我们就忽略水线
reserve_flags = __gfp_pfmemalloc_flags(gfp_mask);
if (reserve_flags)
alloc_flags = reserve_flags;
/*
* Reset the nodemask and zonelist iterators if memory policies can be
* ignored. These allocations are high priority and system rather than
* user oriented.
*/
//如果可以忽略内存策略,则重置nodemask和zonelist
if (!(alloc_flags & ALLOC_CPUSET) || reserve_flags) {
ac->nodemask = NULL;
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->high_zoneidx, ac->nodemask);
}
/* Attempt with potentially adjusted zonelist and alloc_flags */
//尝试使用可能调整的区域备用列表和分配标志
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/* Caller is not willing to reclaim, we cant balance anything */
//如果不可以直接回收,则申请失败
if (!can_direct_reclaim)
goto nopage;
/* Avoid recursion of direct reclaim */
if (current->flags & PF_MEMALLOC)
goto nopage;
/* Try direct reclaim and then allocating */
//直接页面回收,然后进行页面分配
page = __alloc_pages_direct_reclaim(gfp_mask, order, alloc_flags, ac,
&did_some_progress);
if (page)
goto got_pg;
/* Try direct compaction and then allocating */
//进行页面压缩,然后进行页面分配
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
/* Do not loop if specifically requested */
//如果调用者要求不要重试,则放弃
if (gfp_mask & __GFP_NORETRY)
goto nopage;
/*
* Do not retry costly high order allocations unless they are
* __GFP_RETRY_MAYFAIL
*/
//不要重试代价高昂的高阶分配,除非它们是__GFP_RETRY_MAYFAIL
if (costly_order && !(gfp_mask & __GFP_RETRY_MAYFAIL))
goto nopage;
//重新尝试回收页
if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags,
did_some_progress > 0, &no_progress_loops))
goto retry;
/*
* It doesnt make any sense to retry for the compaction if the order-0
* reclaim is not able to make any progress because the current
* implementation of the compaction depends on the sufficient amount
* of free memory (see __compaction_suitable)
*/
//如果申请阶数大于0,判断是否需要重新尝试压缩
if (did_some_progress > 0 &&
should_compact_retry(ac, order, alloc_flags,
compact_result, &compact_priority,
&compaction_retries))
goto retry;
/* Deal with possible cpuset update races before we start OOM killing */
//如果cpuset允许修改内存节点申请就修改
if (check_retry_cpuset(cpuset_mems_cookie, ac))
goto retry_cpuset;
/* Reclaim has failed us, start killing things */
//使用oom选择一个进程杀死
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
/* Avoid allocations with no watermarks from looping endlessly */
//如果当前进程是oom选择的进程,并且忽略了水线,则放弃申请
if (tsk_is_oom_victim(current) &&
(alloc_flags == ALLOC_OOM ||
(gfp_mask & __GFP_NOMEMALLOC)))
goto nopage;
/* Retry as long as the OOM killer is making progress */
//如果OOM杀手正在取得进展,再试一次
if (did_some_progress) {
no_progress_loops = 0;
goto retry;
}
nopage:
/* Deal with possible cpuset update races before we fail */
if (check_retry_cpuset(cpuset_mems_cookie, ac))
goto retry_cpuset;
/*
* Make sure that __GFP_NOFAIL request doesnt leak out and make sure
* we always retry
*/
if (gfp_mask & __GFP_NOFAIL) {
/*
* All existing users of the __GFP_NOFAIL are blockable, so warn
* of any new users that actually require GFP_NOWAIT
*/
if (WARN_ON_ONCE(!can_direct_reclaim))
goto fail;
/*
* PF_MEMALLOC request from this context is rather bizarre
* because we cannot reclaim anything and only can loop waiting
* for somebody to do a work for us
*/
WARN_ON_ONCE(current->flags & PF_MEMALLOC);
/*
* non failing costly orders are a hard requirement which we
* are not prepared for much so lets warn about these users
* so that we can identify them and convert them to something
* else.
*/
WARN_ON_ONCE(order > PAGE_ALLOC_COSTLY_ORDER);
/*
* Help non-failing allocations by giving them access to memory
* reserves but do not use ALLOC_NO_WATERMARKS because this
* could deplete whole memory reserves which would just make
* the situation worse
*/
//允许它们访问内存备用列表
page = __alloc_pages_cpuset_fallback(gfp_mask, order, ALLOC_HARDER, ac);
if (page)
goto got_pg;
cond_resched();
goto retry;
}
fail:
warn_alloc(gfp_mask, ac->nodemask,
"page allocation failure: order:%u", order);
got_pg:
return page;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.98.99.100.101.102.103.104.105.106.107.108.109.110.111.112.113.114.115.116.117.118.119.120.121.122.123.124.125.126.127.128.129.130.131.132.133.134.135.136.137.138.139.140.141.142.143.144.145.146.147.148.149.150.151.152.153.154.155.156.157.158.159.160.161.162.163.164.165.166.167.168.169.170.171.172.173.174.175.176.177.178.179.180.181.182.183.184.185.186.187.188.189.190.191.192.193.194.195.196.197.198.199.200.201.202.203.204.205.206.207.208.209.210.211.212.213.214.215.216.217.218.219.220.221.222.223.224.225.226.227.228.229.230.231.232.233.234.235.236.237.238.239.240.241.242.243.244.245.246.247.248.249.250.251.252.253.254.255.256.257.258.259.260.261.262.263.264.265.266.267.268.269.270.271.272.273.
alloc_page和__get_free_page都是从Buddy分配页面,只是最终返回值类型不同而已,前者返回page指针,后者返回该page所在的虚拟地址。
两者最终都会调用到核心函数__alloc_pages_nodemas
复制
#define __GFP_WAIT ((__force gfp_t)0x10u) /* 可以等待和重调度? */
#define __GFP_HIGH ((__force gfp_t)0x20u) /* 应该访问紧急分配池? */
#define __GFP_IO ((__force gfp_t)0x40u) /* 可以启动物理IO? */
#define __GFP_FS ((__force gfp_t)0x80u) /* 可以调用底层文件系统? */
#define __GFP_COLD ((__force gfp_t)0x100u) /* 需要非缓存的冷页 */
#define __GFP_NOWARN ((__force gfp_t)0x200u) /* 禁止分配失败警告 */
#define __GFP_REPEAT ((__force gfp_t)0x400u) /* 重试分配,可能失败 */
#define __GFP_NOFAIL ((__force gfp_t)0x800u) /* 一直重试,不会失败 */
#define __GFP_NORETRY ((__force gfp_t)0x1000u) /* 不重试,可能失败 */
#define __GFP_NO_GROW ((__force gfp_t)0x2000u) /* slab内部使用 */
#define __GFP_COMP ((__force gfp_t)0x4000u) /* 增加复合页元数据 */
#define __GFP_ZERO ((__force gfp_t)0x8000u) /* 成功则返回填充字节0的页 */
#define __GFP_NOMEMALLOC ((__force gfp_t)0x10000u) /* 不使用紧急分配链表 */
#define __GFP_HARDWALL ((__force gfp_t)0x20000u) /* 只允许在进程允许运行的CPU所关联的结点分配内存 */
#define __GFP_THISNODE ((__force gfp_t)0x40000u) /* 没有备用结点,没有策略 */
#define __GFP_RECLAIMABLE ((__force gfp_t)0x80000u) /* 页是可回收的 */
#define __GFP_MOVABLE ((__force gfp_t)0x100000u) /* 页是可移动的 */1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.
_GFP_WAIT 表示分配内存的请求可以中断。也就是说,调度器在该请求期间可随意选择另一个过程执行,或者该请求可以被另一个更重要的事件中断。分配器还可以在返回内存之前,在队列上等待一个事件(相关进程会进入睡眠状态)。如果请求非常重要,则设置 __GFP_HIGH ,即内核急切地需要内存时。在分配内存失败可能给内核带来严重后果时(比如威胁到系统稳定性或系统崩溃),总是会使用该标志。__GFP_IO 说明在查找空闲内存期间内核可以进行I/O操作。实际上,这意味着如果内核在内存分配期间换出页,那么仅当设置该标志时,才能将选择的页写入硬盘。__GFP_FS 允许内核执行VFS操作。在与VFS层有联系的内核子系统中必须禁用,因为这可能引起循环递归调用。如果需要分配不在CPU高速缓存中的“冷”页时,则设置 __GFP_COLD 。__GFP_NOWARN 在分配失败时禁止内核故障警告。在极少数场合该标志有用。__GFP_REPEAT 在分配失败后自动重试,但在尝试若干次之后会停止。__GFP_NOFAIL 在分配失败后一直重试,直至成功。__GFP_ZERO 在分配成功时,将返回填充字节0的页。__GFP_HARDWALL 只在NUMA系统上有意义。它限制只在分配到当前进程的各个CPU所关联的结点分配内存。如果进程允许在所有CPU上运行(默认情况),该标志是无意义的。只有进程可以运行的CPU受限时,该标志才有效果。__GFP_THISNODE 也只在NUMA系统上有意义。如果设置该比特位,则内存分配失败的情况下不允许使用其他结点作为备用,需要保证在当前结点或者明确指定的结点上成功分配内存。__GFP_RECLAIMABLE 和 __GFP_MOVABLE 是页迁移机制所需的标志。顾名思义,它们分别将分配的内存标记为可回收的或可移动的。这影响从空闲列表的哪个子表获取内存。
组合:
复制
#define GFP_ATOMIC (__GFP_HIGH)
#define GFP_NOIO (__GFP_WAIT)
#define GFP_NOFS (__GFP_WAIT | __GFP_IO)
#define GFP_KERNEL (__GFP_WAIT | __GFP_IO | __GFP_FS)
#define GFP_USER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_HIGHUSER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL | \
__GFP_HIGHMEM)
#define GFP_HIGHUSER_MOVABLE (__GFP_WAIT | __GFP_IO | __GFP_FS | \
__GFP_HARDWALL | __GFP_HIGHMEM | \
__GFP_MOVABLE)
#define GFP_DMA __GFP_DMA
#define GFP_DMA32 __GFP_DMA321.2.3.4.5.6.7.8.9.10.11.12.
GFP_ATOMIC 用于原子分配,在任何情况下都不能中断,可能使用紧急分配链表中的内存。GFP_NOIO 和 GFP_NOFS 分别明确禁止I/O操作和访问VFS层,但同时设置了 __GFP_WAIT ,因此可以被中断。GFP_KERNEL 和 GFP_USER 分别是内核和用户分配的默认设置。二者的失败不会立即威胁系统稳定性。 GFP_KERNEL 绝对是内核源代码中最常使用的标志。GFP_HIGHUSER 是 GFP_USER 的一个扩展,也用于用户空间。它允许分配无法直接映射的高端内存。使用高端内存页是没有坏处的,因为用户过程的地址空间总是通过非线性页表组织的。GFP_HIGHUSER_MOVABLE 用途类似于 GFP_HIGHUSER ,但分配将从虚拟内存域 ZONE_MOVABLE进行。GFP_DMA 用于分配适用于DMA的内存,当前是 __GFP_DMA 的同义词。 GFP_DMA32 也是__GFP_GMA32 的同义词。
三、slab分配器
在 Linux 内存管理的大家庭中,slab 分配器犹如一位贴心的助手,专门负责管理小对象(通常是小于一个页面大小,即小于 4KB 的对象)的内存分配,为系统中众多对小内存有频繁需求的模块提供了高效的支持 。
slab 分配器的设计目标明确,旨在提高内存分配的速度和效率,同时减少内存碎片的产生,并减轻内核内存管理的负担。它通过巧妙的设计,将内核中常用的数据结构和对象分成若干个大小相等的 slab 缓存,每个 slab 缓存就像是一个专门存放特定物品的小仓库,对应一种大小的数据结构或对象 。当系统需要分配内存时,就如同从相应的小仓库中直接取出一块空闲内存,当不需要使用时,又将其放回对应的小仓库,大大提高了内存分配和回收的效率 。
在 Linux 内核中,常见的 slab、slub、slob 这三种分配器虽然都属于 slab 分配器家族,但它们在实现和应用场景上存在着一些差异 。slab 分配器是最早出现的,它将内核中常用的数据结构和对象分成若干个大小相等的 slab 缓存,每个 slab 缓存对应一种大小的数据结构或对象,通过维护空闲对象链表、部分空 slab 链表和已满 slab 链表来管理内存 。
slob 分配器则是一种轻量级的内存分配器,通常用于嵌入式设备,它的代码量较小,实现相对简单,通过维护一个简单的内存块链表来管理内存,在分配内存时使用最新适配算法 。而 slub 分配器是对 slab 分配器的改进,它采用了更加高效的算法,在大型机上表现出色,并且能更好地适应 NUMA 系统,相对于 slab 有 5%-10% 的性能提升和减小 50% 的内存占用 。由于 slub 分配器在现代 Linux 内核中使用最为广泛,下面我们将重点对其进行深入探讨 。
3.1slab核心思想
为每种对象类型创建一个内存缓存,每个内存缓存由多个大块组成,一个大块是一个或多个连续的物理页,每个大块包含多个对象。slab采用面向对象的思想,基于对象类型管理内存,每种对象被划分为一个类,比如进程描述符(task_struct)是一个类,每个进程描述符实现是一个对象。内存缓存组成结构如下:
在 Linux 中,slab 可以处于三种可能状态之一:
满的:slab 的所有对象标记为使用。空的:slab 上的所有对象标记为空闲。部分:slab 上的对象有的标记为使用,有的标记为空闲。
slab 分配器首先尝试在部分为空的 slab 中用空闲对象来满足请求。如果不存在,则从空的 slab 中分配空闲对象。如果没有空的 slab 可用,则从连续物理页面分配新的 slab,并将其分配给 cache;从这个 slab 上,再分配对象内存。
3.2slab分配器的作用
a.能够分配更小块的内存,可以帮助消除伙伴分配器原本会造成的内部碎片问题b.缓存常用的object,因此内核不会在分配, 初始化和销毁object上浪费时间。c.作为一个高速缓存,它用来存储内核中那些经常分配并释放的对象。通过着色技术调整对象以更好的使用硬件高速缓存slab分配器的原理
slab 分配器由kmem_cache --> kmem_cache_node --> object三个结构相结合地方式来描述,其中cache由 struct kmem_cache来描述,struct kmem_cache.中的成员struct kmem_cache_node,lists数组包含三个slab list:full,part,free, 这三个list是有struct slab结构组成的链表。其中struct slab中的s_mem是第一个object的起始地址,因此就可以通过kmem_cache --> kmem_cache_node --> object找到空闲的object。其中slab中的page 的prev指向cache,next指向slab。
而slab还分为on-slab 和off-slab,是指当object的size特别大的时候,slab中新分配的page就全部放object,而struct slab结构单独从通用slab中进行分配,如果object的size比较小,则可以将struct slab放置在新分配的page开头,然后再放置object。
slab 分配器提供两个主要优点:
没有因碎片而引起内存浪费。碎片不是问题,因为每个内核数据结构都有关联的 cache,每个 cache 都由一个或多个 slab 组成,而 slab 按所表示对象的大小来分块。因此,当内核请求对象内存时,slab 分配器可以返回刚好表示对象的所需内存。
可以快速满足内存请求。因此,当对象频繁地被分配和释放时,如来自内核请求的情况,slab 分配方案在管理内存时特别有效。分配和释放内存的动作可能是一个耗时过程。然而,由于对象已预先创建,因此可以从 cache 中快速分配。再者,当内核用完对象并释放它时,它被标记为空闲并返回到 cache,从而立即可用于后续的内核请求。
通过命令sudo cat /proc/slabinfo可查看系统当前 slab 使用情况。slab 分配器的实现源码:
复制
include/linux/slab_def.h
include/linux/slab.h
mm/slab.c1.2.3.
slab结构分析
slub 分配器主要由 kmem_cache、kmem_cache_cpu、kmem_cache_node、slab 和 object 等关键数据结构组成,它们相互协作,共同完成内存的分配和管理工作 。我们来仔细看看,缓存区 struct kmem_cache 到底是什么样子。\include\linux\slab_def.h
复制
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retriving partial slabs etc */
unsigned long flags;
unsigned long min_partial;
int size; /* The size of an object including meta data */
int object_size; /* The size of an object without meta data */
int offset; /* Free pointer offset. */
#ifdef CONFIG_SLUB_CPU_PARTIAL
int cpu_partial; /* Number of per cpu partial objects to keep around */
#endif
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *);
......
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */
......
struct kmem_cache_node *node[MAX_NUMNODES];
};1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.
kmem_cache 结构体:这是 Linux 内核中用于实现 slub 内存分配器的核心数据结构,它就像是一个仓库管理员的 “工作手册”,描述了一个内存缓存池的各种属性。其中包括缓存池的名称(name),就像给仓库取了一个独特的名字,方便识别和管理;缓存池中每个元素的大小(size)以及实际大小(object_size),这两个参数明确了每个 “物品” 的尺寸,有助于合理规划仓库空间;缓存池的容量(oo),表示这个仓库能容纳多少个 “物品”;缓存池中每个元素的对齐方式(align),保证内存访问的高效性;还有用于连接全局链表的 list 成员,通过它可以将所有的 kmem_cache 对象连接起来,方便统一管理 。例如,在文件系统中,每个 inode 对象都有自己对应的 kmem_cache,通过这个结构体来管理 inode 对象的内存分配 。kmem_cache_cpu 结构体:这个结构体用于描述与 CPU 相关的 slab 缓存池信息,它是每个 CPU 的专属 “小仓库”。其中,freelist 指针指向当前 CPU slab 缓存池空闲对象链表的头节点,就像仓库中指向空闲货架的指示牌;tid 记录最后一个分配或释放对象的 CPU 编号,用于判断是否需要重新填充空闲对象链表;page 指向当前 CPU 上正在使用的 slab 缓存池,就像定位到当前 CPU 正在操作的仓库区域;partial 则指向当前 CPU 备用的 slab 缓存池,当主缓存池不够用时,可以从这里获取资源 。在多 CPU 系统中,每个 CPU 都有自己的 kmem_cache_cpu,这样可以减少 CPU 之间的竞争,提高内存分配的效率 。kmem_cache_node 结构体:它是 numa node 内存节点空闲 slab 链表,用于存储空闲的 slab 缓存池,是整个内存管理系统中的一个重要 “储备仓库”。其中,nr_partial 记录了内存节点 partial 链表中 slab 缓存池的数量,让管理员清楚了解储备资源的数量;partial 则是 node 节点空闲 slab 链表的表头,通过它可以方便地访问和管理这些空闲的 slab 缓存池 。在 NUMA 系统中,不同的节点可能有不同的内存访问速度,kmem_cache_node 结构体可以根据节点的特点来合理分配内存资源 。slab 缓存池:它实际上就是页(page),是内存分配的实际载体。一个 slab 缓存池可以理解为多个物理页的集合,就像一个大型的货架,将其根据 size 大小划分成一个个 object,这些 object 就是内存分配的最小单元,也就是我们要存放的 “物品” 。在 slab 缓存池中,freelist 指向第一个空闲的 object 对象,就像货架上指向第一个空闲位置的标签;slab_cache 指向 kmem_cache 对象,建立了与缓存池属性的联系;inuse 表示 slab 缓存池中已经分配的 object 对象数量,方便管理员掌握使用情况;objects 则表示 slab 缓存池可以容纳的 object 对象总数,明确了货架的总容量 。object 对象:这是 slub 分配器内存分配的最小单元,是真正存放数据的地方,就像货架上的一个个小格子 。object 对象的格式较为复杂,它由 red left pad(红色左填充区,用于检测内存越界等错误)、object 内存区域(实际存放数据的地方)、red zone(红色区域,同样用于检测错误)、freepinter(指向下一个空闲 object 对象的指针,通过它将所有 object 对象连接成链表)、track(用于跟踪对象的使用情况)、padding(填充区,用于对齐和优化内存布局)等部分组成 。通过这种精心设计的结构,object 对象能够高效地管理内存,并保证数据的安全性和完整性 。
在 struct kmem_cache 里面,有个变量 struct list_head list,这个结构很重要。我们可以想象一下,对于操作系统来讲,要创建和管理的缓存绝对不止 task_struct,还有 mm_struc,fs_struct 都需要。因此,所有的缓存最后都会放在一个链表里面,也就是 LIST_HEAD(slab_caches)。对于缓存来讲,其实就是分配了连续几页的大内存块,然后根据缓存对象的大小,切成小内存块。
接下来就是最重要的两个成员变量出场的时候了。kmem_cache_cpu 和 kmem_cache_node,它们都是每个 NUMA 节点上有一个,我们只需要看一个节点里面的情况。
在分配缓存块的时候,要分两种路径,fast path 和 slow path,也就是快速通道和普通通道。其中 kmem_cache_cpu 就是快速通道,kmem_cache_node 是普通通道。每次分配的时候,要先从 kmem_cache_cpu 进行分配。如果 kmem_cache_cpu 里面没有空闲的块,那就到 kmem_cache_node 中进行分配;如果还是没有空闲的块,才去伙伴系统分配新的页。
我们来看一下,kmem_cache_cpu 里面是如何存放缓存块的:
复制
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *partial; /* Partially allocated frozen slabs */
#endif
......
};1.2.3.4.5.6.7.8.9.
在这里,page 指向大内存块的第一个页,缓存块就是从里面分配的。freelist 指向大内存块里面第一个空闲的项。按照上面说的,这一项会有指针指向下一个空闲的项,最终所有空闲的项会形成一个链表。partial 指向的也是大内存块的第一个页,之所以名字叫 partial(部分),就是因为它里面部分被分配出去了,部分是空的。这是一个备用列表,当 page 满了,就会从这里找。
我们再来看 kmem_cache_node 的定义:
复制
struct kmem_cache_node {
spinlock_t list_lock;
......
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial;
......
#endif
};1.2.3.4.5.6.7.8.9.
这里面也有一个 partial,是一个链表。这个链表里存放的是部分空闲的内存块。这是 kmem_cache_cpu 里面的 partial 的备用列表,如果那里没有,就到这里来找。
3.3slub 分配器的工作流程
slub 分配器的工作流程严谨而高效,主要包括内存分配和内存释放两个关键环节 ,下面我们就来看看这个分配过程。kmem_cache_alloc_node 会调用 slab_alloc_node。你还是先重点看这里面的注释,这里面说的就是快速通道和普通通道的概念:
复制
/*
* Inlined fastpath so that allocation functions (kmalloc, kmem_cache_alloc)
* have the fastpath folded into their functions. So no function call
* overhead for requests that can be satisfied on the fastpath.
*
* The fastpath works by first checking if the lockless freelist can be used.
* If not then __slab_alloc is called for slow processing.
*
* Otherwise we can simply pick the next object from the lockless free list.
*/
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
......
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
......
object = c->freelist;
page = c->page;
if (unlikely(!object || !node_match(page, node))) {
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
}
......
return object;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.
快速通道很简单,取出 cpu_slab 也即 kmem_cache_cpu 的 freelist,这就是第一个空闲的项,可以直接返回了。如果没有空闲的了,则只好进入普通通道,调用 __slab_alloc。
复制
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *freelist;
struct page *page;
......
redo:
......
/* must check again c->freelist in case of cpu migration or IRQ */
freelist = c->freelist;
if (freelist)
goto load_freelist;
freelist = get_freelist(s, page);
if (!freelist) {
c->page = NULL;
stat(s, DEACTIVATE_BYPASS);
goto new_slab;
}
load_freelist:
c->freelist = get_freepointer(s, freelist);
c->tid = next_tid(c->tid);
return freelist;
new_slab:
if (slub_percpu_partial(c)) {
page = c->page = slub_percpu_partial(c);
slub_set_percpu_partial(c, page);
stat(s, CPU_PARTIAL_ALLOC);
goto redo;
}
freelist = new_slab_objects(s, gfpflags, node, &c);
......
return freeli1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.
在这里,我们首先再次尝试一下 kmem_cache_cpu 的 freelist。为什么呢?万一当前进程被中断,等回来的时候,别人已经释放了一些缓存,说不定又有空间了呢。如果找到了,就跳到 load_freelist,在这里将 freelist 指向下一个空闲项,返回就可以了。如果 freelist 还是没有,则跳到 new_slab 里面去。这里面我们先去 kmem_cache_cpu 的 partial 里面看。
如果 partial 不是空的,那就将 kmem_cache_cpu 的 page,也就是快速通道的那一大块内存,替换为 partial 里面的大块内存。然后 redo,重新试下。这次应该就可以成功了。如果真的还不行,那就要到 new_slab_objects 了。
复制
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags,
int node, struct kmem_cache_cpu **pc)
{
void *freelist;
struct kmem_cache_cpu *c = *pc;
struct page *page;
freelist = get_partial(s, flags, node, c);
if (freelist)
return freelist;
page = new_slab(s, flags, node);
if (page) {
c = raw_cpu_ptr(s->cpu_slab);
if (c->page)
flush_slab(s, c);
freelist = page->freelist;
page->freelist = NULL;
stat(s, ALLOC_SLAB);
c->page = page;
*pc = c;
} else
freelist = NULL;
return freelis1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.
在这里面,get_partial 会根据 node id,找到相应的 kmem_cache_node,然后调用 get_partial_node,开始在这个节点进行分配。
复制
/*
* Try to allocate a partial slab from a specific node.
*/
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n,
struct kmem_cache_cpu *c, gfp_t flags)
{
struct page *page, *page2;
void *object = NULL;
int available = 0;
int objects;
......
list_for_each_entry_safe(page, page2, &n->partial, lru) {
void *t;
t = acquire_slab(s, n, page, object == NULL, &objects);
if (!t)
break;
available += objects;
if (!object) {
c->page = page;
stat(s, ALLOC_FROM_PARTIAL);
object = t;
} else {
put_cpu_partial(s, page, 0);
stat(s, CPU_PARTIAL_NODE);
}
if (!kmem_cache_has_cpu_partial(s)
|| available > slub_cpu_partial(s) / 2)
break;
}
......
return object;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.
acquire_slab 会从 kmem_cache_node 的 partial 链表中拿下一大块内存来,并且将 freelist,也就是第一块空闲的缓存块,赋值给 t。并且当第一轮循环的时候,将 kmem_cache_cpu 的 page 指向取下来的这一大块内存,返回的 object 就是这块内存里面的第一个缓存块 t。如果 kmem_cache_cpu 也有一个 partial,就会进行第二轮,再次取下一大块内存来,这次调用 put_cpu_partial,放到 kmem_cache_cpu 的 partial 里面。
如果 kmem_cache_node 里面也没有空闲的内存,这就说明原来分配的页里面都放满了,就要回到 new_slab_objects 函数,里面 new_slab 函数会调用 allocate_slab。
复制
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
{
struct page *page;
struct kmem_cache_order_objects oo = s->oo;
gfp_t alloc_gfp;
void *start, *p;
int idx, order;
bool shuffle;
flags &= gfp_allowed_mask;
......
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page)) {
oo = s->min;
alloc_gfp = flags;
/*
* Allocation may have failed due to fragmentation.
* Try a lower order alloc if possible
*/
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page))
goto out;
stat(s, ORDER_FALLBACK);
}
......
return page;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.
在这里,我们看到了 alloc_slab_page 分配页面。分配的时候,要按 kmem_cache_order_objects 里面的 order 来。如果第一次分配不成功,说明内存已经很紧张了,那就换成 min 版本的 kmem_cache_order_objects。
3.4slub分配器的API使用
与 libc 提供的内存申请 API (malloc 和 free )类似,Slab 分配器提供的 API 为 kmalloc()和 kfree()。kmalloc()函数定义在include/linux/slab.h文件中,接收两个参数,并调用__kmalloc()函数。最终分配内存的实现是__do_kmalloc()函数。
分配内存:void * kmalloc (size_t size,gfp_t flags);重新分配内存:void *krealloc(const void *p, size_t new_size, gfp_t flags)释放内存:void kfree ( const void * objp);size:申请的内存大小flags:参数使用 GFP_XXX来指定分配内存的具体内存域,例如 GFP_DMA 指定分配适合于DMA的内存区.
复制
//include/linux/slab.h
static __always_inline void *kmalloc(size_t size, gfp_t flags)
{
......
return __kmalloc(size, flags);
}
// in mm/slab.c
void *__kmalloc(size_t size, gfp_t flags)
{
return __do_kmalloc(size, flags, _RET_IP_);
}
static __always_inline void *__do_kmalloc(size_t size, gfp_t flags,
unsigned long caller)
{
...
}
/*
* Common kmalloc functions provided by all allocators
*/
void * __must_check __krealloc(const void *, size_t, gfp_t);
void * __must_check krealloc(const void *, size_t, gfp_t);
void kfree(const void *);
void kzfree(const void *);
size_t ksize(const void *);1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.
创建内存缓存:struct kmem_cache *kmem_cache_create(const char , size_t,size_t,unsigned long, void ()(void *));指定的内存缓存分配对象:void *kmem_cache_alloc(struct kmem_cache *, gfp_t);释放对象:void kmem_cache_free(struct kmem_cache *, void *);销毁内存缓存:void kmem_cache_destroy(struct kmem_cache *);
复制
struct kmem_cache *kmem_cache_create(const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void *))
{
struct kmem_cache *s = NULL;
const char *cache_name;
int err;1.2.3.4.5.6.
3.5数据结构
每个内存缓存对应一个kmem_cache实例。每个内存节点对应一个kmem_cache_node实例。
kmem_cache实例的成员cpu_slab指向array_cache实例,每个处理器对应一个array_cache实例,称为数组缓存,用来缓存刚刚释放的对象,分配时首先从当前处理器的数据缓存分配,避免每次都要从slab分配,减少链表操作的锁操作,提高分配的速度。
由于slab的缓存特性,slab 分配器从 buddy 分配器中获取的物理内存称为 内存缓存使用结构体struct kmem_cache(定义在include/linux/slab_def.h文件中)描述。 一个高速缓存中可以含有多个kmem_cache对应的高速缓存,就拿L1高速缓存来举例,一个L1高速缓存对应一个kmem_cache链表,这个链表中的任何一个kmem_cache类型的结构
体均描述一个高速缓存,而这些高速缓存在L1 cache中各自占用着不同的区域。
SLAB分配器由可变数量的缓存组成,这些缓存由称为“缓存链”的双向循环链表链接在一起(如下图中的 kmem_cache 链表)。 在slab分配器的上下文中,缓存是特定类型的多个对象的管理器,例如使用cat /proc/slabinfo命令输出的mm_struct 或fs_cache缓存,其名字保存在kmem_cache->name中(Linux 支持单个最大的 slab 缓存大小为32MB )。kmem_cache 中所有对象的大小是相同的(object_size),并且此 kmem_cache 中所有SLAB的大小也是相同的(gfporder、num)。
每个缓存节点在内存中维护称为slab的连续页块,这些页面被切成小块,用于缓存数据结构和对象。 kmem_cache的 kmem_cache_node 成员记录了该kmem_cache 下的所有 slabs 列表。形成的结构如下图所示。
复制
struct kmem_cache {
//为了提高效率,每个CPU都有一个slab空闲对象缓存
struct array_cache __percpu *cpu_cache;
/* 1) Cache tunables. Protected by slab_mutex */
unsigned int batchcount;//从本地高速缓存批量移入或移出对象的数量
unsigned int limit;//本地高速缓存中空闲对象的最大数量
unsigned int shared;
unsigned int size;
struct reciprocal_value reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend */
unsigned int flags; /* constant flags */
unsigned int num; //每个slab的obj对象个数
/* 3) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder; //每个slab中连续页框的数量
/* force GFP flags, e.g. GFP_DMA */
gfp_t allocflags;
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
struct kmem_cache *freelist_cache;
unsigned int freelist_size;
/* constructor func */
void (*ctor)(void *obj);
/* 4) cache creation/removal */
const char *name;
struct list_head list;
int refcount;
int object_size;
int align;
/* 5) statistics */
#ifdef CONFIG_DEBUG_SLAB
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
/*
* If debugging is enabled, then the allocator can add additional
* fields and/or padding to every object. size contains the total
* object size including these internal fields, the following two
* variables contain the offset to the user object and its size.
*/
int obj_offset;
#endif /* CONFIG_DEBUG_SLAB */
#ifdef CONFIG_MEMCG_KMEM
struct memcg_cache_params memcg_params;
#endif
struct kmem_cache_node *node[MAX_NUMNODES]; //内存节点实例个数
};1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.
复制
struct array_cache {
unsigned int avail; //本地高速缓存中可用对象的个数,也是空闲数组位置的索引
unsigned int limit; //本地高速缓存大小
unsigned int batchcount; //本地高速缓存天长或者清空时是用到的对象个数
unsigned int touched;//如果本地高速缓存最近被使用过,设置成1
void *entry[]; /* 对象的地址
* Must have this definition in here for the proper
* alignment of array_cache. Also simplifies accessing
* the entries.
*
* Entries should not be directly dereferenced as
* entries belonging to slabs marked pfmemalloc will
* have the lower bits set SLAB_OBJ_PFMEMALLOC
*/
};1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.
复制
/*
* The slab lists for all objects.
*/
struct kmem_cache_node {
spinlock_t list_lock;
#ifdef CONFIG_SLAB
struct list_head slabs_partial; //部分分配的slab
struct list_head slabs_full; //已经完全分配的 slab
struct list_head slabs_free; //空slab,或者没有对象被分配
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
struct array_cache *shared; /* shared per node */
struct alien_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
#endif
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial;
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.
以上3个链表保存的是slab 描述符,Linux kernel 使用 struct page 来描述一个slab。单个slab可以在slab链表之间移动,例如如果一个半满slab被分配了对象后变满了,就要从 slabs_partial 中被删除,同时插入到 slabs_full 中去。
page 结构体关于 slab 的部分。struct page定义在include/linux/mm_types.h文件中,与slab相关的结构体成员如下所示:
复制
struct page {
/* First double word block */
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
union {
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
void *s_mem; /* slab first object */
};
/* Second double word */
struct {
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* sl[aou]b first free object */
};1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.
void *s_mem: 指向该页框中第一个object 的地址 。void *freelist: 用于指向页框中空闲对象链表。空闲对象链表包含页框中每个空闲对象的索引。
内存缓存为每个处理器创建一个数组缓存(结构体array_cache)。释放对象时,把对象存放到当前处理器对应的数组缓存中;分配对象的时候,先从当前处理器的数组缓存分配对象,采用后进先出(LIFO)原则,可以提高性能。
于所有对象空间的slab,没有立即释放,而是放在空闲slab链表中。只有内存节点上空闲对象的数量超过限制,才开始回收空闲slab,直到空闲对象的数量小于或等于限制。
四、三大分配器的协作与应用场景
在 Linux 内存管理这个庞大而复杂的系统中,引导内存分配器、伙伴分配器和 slab 分配器并非孤立存在,它们各司其职,又相互协作,共同为系统的稳定运行提供了强大的内存支持。在不同的内存需求场景下,这三大分配器展现出了各自的优势和特点,协同完成内存分配与管理的任务 。
在系统启动阶段,引导内存分配器率先登场,它就像是一场大型演出的开场嘉宾,为后续的精彩表演搭建起了舞台。在这个阶段,系统的内存管理机制还未完全建立,引导内存分配器承担起了为内核初始化提供内存的重任 。它通过简单而直接的方式,将物理内存划分为不同的区域,为内核的启动和基本数据结构的创建提供了必要的内存空间 。
例如,在 x86 架构的系统启动过程中,引导内存分配器会根据 BIOS 提供的内存信息,将内存划分为不同的块,标记出哪些区域是可用的,哪些是被系统保留的 。当内核开始初始化时,就可以从引导内存分配器分配的内存中获取所需的空间,用于创建进程控制块(PCB)、文件描述符表等重要的数据结构 。引导内存分配器的存在,为后续更复杂、更高效的内存分配器的初始化和运行奠定了基础 。
随着系统的启动完成,伙伴分配器和 slab 分配器开始发挥核心作用 。当系统中某个进程需要分配大量连续内存时,伙伴分配器就成为了最佳选择 。比如,在进行大数据处理时,需要一次性读取大量的数据到内存中进行分析计算 。假设要处理一个 1GB 大小的数据集,由于数据的连续性对于提高处理效率至关重要,此时就可以向伙伴分配器申请一块连续的 1GB 内存空间 。
伙伴分配器会根据其独特的算法,从物理内存中找到合适大小的连续页块进行分配 。它首先会查看是否有足够大的空闲页块直接满足请求,如果没有,就会从更大的页块中进行分裂,直到找到合适的内存块分配给进程 。这样,大数据处理程序就能够在分配到的连续内存空间中高效地进行数据读取和计算操作 。
而当系统中频繁出现对小对象的内存分配需求时,slab分配器就展现出了它的优势 。以网络通信为例,在网络数据包的处理过程中,会频繁地创建和销毁各种小的结构体,如套接字描述符、网络协议头部等 。这些小对象的大小通常小于一个页面大小(一般为 4KB) 。如果每次都使用伙伴分配器来分配内存,会因为其按照页块分配的特性,导致大量的内存浪费,并且分配和释放的效率也较低 。而 slab 分配器针对这种情况进行了优化,它预先为这些小对象创建了特定的缓存池 。
当需要分配一个套接字描述符时,slab 分配器可以直接从对应的缓存池中快速获取一个空闲的对象,无需进行复杂的内存搜索和分配操作 。当这个套接字描述符不再使用时,又可以迅速将其释放回缓存池,供下次使用 。这样,在高并发的网络通信场景下,slab 分配器能够大大提高内存分配和释放的速度,减少内存碎片的产生,保证网络通信的高效性和稳定性 。
在实际的 Linux 系统中,这三大分配器的协作是非常紧密的 。例如,slab 分配器在创建缓存池时,需要向伙伴分配器申请内存页块 。当 slab 分配器的某个缓存池需要扩充或收缩时,也会与伙伴分配器进行交互,获取或释放内存页块 。
而伙伴分配器在进行内存分配时,如果遇到内存不足的情况,可能会通过回收一些不常用的内存页来满足分配需求,这些被回收的内存页中可能就包含了 slab 分配器中一些空闲的对象 。通过这种相互协作的方式,三大分配器能够充分发挥各自的优势,满足系统中各种不同的内存需求,确保 Linux 系统在各种复杂的应用场景下都能高效、稳定地运行 。