从0到1:Linux磁盘I/O性能优化
在Linux 系统的广袤世界里,磁盘 I/O 性能犹如隐藏在幕后却掌控全局的关键角色,对系统整体性能有着举足轻重的影响。想象一下,你正在使用一个基于 Linux 系统搭建的网站服务器,用户点击页面后,需要从磁盘中读取网页文件、数据库数据等信息来呈现页面内容。如果磁盘 I/O 性能不佳,数据读取缓慢,那么用户可能需要长时间等待页面加载,这不仅会严重影响用户体验,还可能导致用户流失,对业务造成损失。再比如在数据分析场景中,数据科学家需要处理大量存储在磁盘上的数据,若磁盘 I/O 性能不给力,数据读取和写入时间大幅增加,会极大地延长数据分析周期,使得分析结果无法及时产出,影响决策效率。
当磁盘 I/O 性能不佳时,会引发一系列令人头疼的问题。系统响应变得迟缓,程序启动时间大幅延长,文件复制、解压等操作耗时漫长。在服务器环境中,还可能导致多个进程因为等待磁盘 I/O 操作完成而处于阻塞状态,使得 CPU 资源闲置,系统整体吞吐量下降,就像一条交通要道上,车辆都堵在收费站等待缴费(磁盘 I/O 操作),导致道路(系统)拥堵,通行效率(性能)降低 。正是因为磁盘 I/O 性能如此重要,且性能不佳会带来诸多严重后果,所以深入了解并优化 Linux 磁盘 I/O 性能显得尤为迫切,接下来,让我们一起揭开磁盘 I/O 性能优化的神秘面纱,从原理到实战,逐步探索其中的奥秘。
Part1.Linux磁盘I/O工作原理
1.1 磁盘的分类与特点
在 Linux 系统中,磁盘主要分为机械磁盘(Hard Disk Drive,HDD)和固态磁盘(Solid State Disk,SSD) ,它们就像两个性格迥异的 “存储伙伴”,各自有着独特的工作原理和性能特点。
机械磁盘的工作原理颇具 “机械感”,它主要由盘片、读写磁头、马达等机械部件组成。数据存储在高速旋转的盘片的环状磁道上,当需要读写数据时,读写磁头就像一个忙碌的 “快递员”,在盘片表面移动,通过改变磁性来记录或读取数据 。不过这个 “快递员” 的效率会受到盘片转速和磁头移动速度的限制,就像在城市中开车送快递,道路拥堵(机械部件的物理限制)会影响送达速度。例如,普通机械硬盘的盘片转速常见的有 5400 转 / 分钟和 7200 转 / 分钟,在读写零散小文件时,由于文件所在扇区不连续,磁头需要不断寻道,导致读写速度很慢,一般顺序读写速度在 100 - 200MB/s 左右,随机读写速度则更低,可能只有几十 KB/s 。
固态磁盘则是依靠闪存芯片(NAND Flash)来存储数据,它的工作方式更加 “电子化”,就像一个反应敏捷的 “电子精灵”,通过电子信号快速读写数据,没有那些慢悠悠的机械部件 。这使得固态硬盘的读写速度极快,顺序读写速度可达 3000MB/s 以上(如 NVMe SSD),随机读写速度也远超机械硬盘,能够在几秒钟内启动操作系统,快速加载应用程序和文件 。而且它抗震性强、无机械延迟、噪音小、功耗低,非常适合对速度和响应要求高的场景,如游戏主机、高性能台式机等 。不过,固态硬盘的闪存芯片有写入次数限制(P/E 周期),频繁写入可能会导致芯片老化,影响使用寿命,并且单位容量价格相对较高 。
对于连续 I/O 和随机 I/O,不同磁盘有着不同的表现。连续 I/O 时,数据在磁盘上是连续存储的,就像图书馆里同一类书籍整齐排列在书架上。机械磁盘不需要频繁寻道,所以连续读写能力并不差,甚至在单碟容量提升和组建磁盘阵列的情况下,连续读写速度可以比固态硬盘更快;而固态硬盘在连续 I/O 时更是发挥其高速读写的优势,数据传输流畅迅速 。在随机 I/O 场景下,数据存储位置零散,如同图书馆里的书籍被打乱放置。机械磁盘需要不停地移动磁头来定位数据,寻道时间长,性能受到很大影响;固态硬盘虽然随机性能比机械硬盘好很多,但由于存在 “先擦除再写入” 的限制,随机读写会导致大量的垃圾回收,所以随机 I/O 性能相比连续 I/O 还是差一些,不过依然比机械磁盘强很多 。
1.2 文件系统的运作机制
文件系统是 Linux 系统中管理文件的重要部分,就像一个有序的图书馆管理员,负责整理和保管文件,而索引节点和目录项则是它管理文件的重要工具。
索引节点(inode),可以看作是文件的 “身份证”,记录了文件的元数据,如文件大小、访问权限、修改日期、数据的位置等 。每个文件都有唯一对应的 inode,它和文件内容一样,会被持久化存储到磁盘中,所以 inode 也占用磁盘空间 。例如,当我们在 Linux 系统中查看一个文件的属性时,显示的文件大小、所有者、权限等信息就来自于 inode 。
目录项(dentry),则像是文件的 “名片”,记录了文件的名字、索引节点指针以及与其他目录项的关联关系 。多个关联的目录项构成了文件系统的目录结构 。它是由内核维护的一个内存数据结构,也被叫做目录项缓存 。比如我们在文件管理器中看到的文件和文件夹名称,这些都是目录项的体现,通过目录项,我们可以快速找到对应的 inode,进而访问文件 。 目录项和索引节点是多对一的关系,这意味着一个文件可以有多个别名,就像一个人可以有多个昵称,比如软链接文件,就是多了一个指向相同 inode 的目录项 。
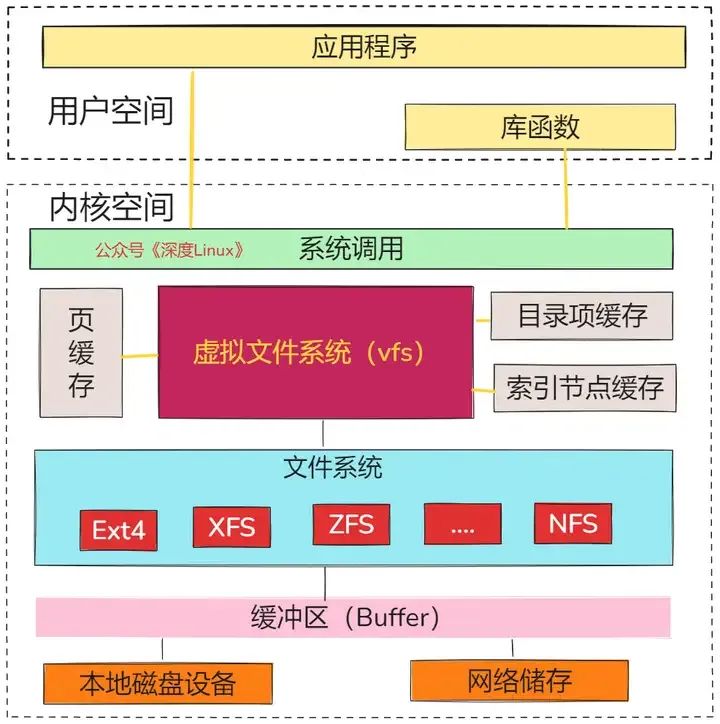
虚拟文件系统(Virtual File System,VFS)是 Linux 内核中一个非常重要的抽象层,它就像一个万能的翻译官,为各种不同的文件系统提供了统一的接口 。由于 Linux 系统支持多种文件系统,如 EXT4、XFS、Btrfs 等,每种文件系统的实现细节都不同,如果没有 VFS,应用程序和内核就需要针对不同的文件系统编写不同的代码,这无疑会大大增加开发和维护的难度 。
 图片
图片
有了 VFS,它定义了一组所有文件系统都支持的数据结构和标准接口,用户进程和内核中的其他子系统只需要跟 VFS 提供的统一接口进行交互,而不需要关心底层各种文件系统的实现细节 。例如,当我们使用 “open”“read”“write” 等系统调用操作文件时,实际上是通过 VFS 这个翻译官,将这些操作转发到底层具体的文件系统去执行 。在系统启动时,VFS 会被建立,在内存中构建起文件系统的树形结构,管理着各种文件系统的挂载点、inode 等信息,直到系统关闭时才会消亡 。
通过这张图可以看到,在 VFS 的下方,Linux 支持各种各样的文件系统,如 Ext4、XFS、NFS 等等。按照存储位置的不同,这些文件系统可以分为三类。
第一类是基于磁盘的文件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。常见的 Ext4、XFS、OverlayFS等,都是这类文件系统。第二类是基于内存的文件系统,也就是我们常说的虚拟文件系统。这类文件系统,不需要任何磁盘分配存储空间,但会占用内存。我们经常用到的 /proc就是一种最常见的虚拟文件系统。第三类是网络文件系统,也就是用来访问其他计算机数据的文件系统,比如 NFS、SMB、iSCSI 等。这些文件系统,要先挂载到 VFS 目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。拿第一类,也就是基于磁盘的文件系统为例,在安装系统时,要先挂载一个根目录(/),在根目录下再把其他文件系统(比如其他的磁盘分区、/proc 文件系统、/sys 文件系统、NFS 等)挂载进来。
1.3 I/O 操作的流程剖析
当应用程序进行 I/O 操作时,数据就像一个忙碌的 “旅行者”,在应用程序、缓存、文件系统和磁盘之间进行复杂的传输过程。
 图片
图片
以读取文件为例,应用程序发起读取文件的请求,这个请求首先会到达内核空间 。内核会先检查页缓存(Page Cache),页缓存就像一个高速的临时仓库,存储着最近访问过的文件片段,这些片段更有可能在近期再次被访问 。如果所需数据已经在页缓存中,那就如同在自家附近的小仓库中找到了需要的物品,直接从页缓存中将数据复制到应用程序的内存空间中,这个过程非常迅速,不需要访问慢速的磁盘 。
要是页缓存中没有找到所需数据,就会触发缺页错误(Page Fault) 。此时,内核就像一个勤劳的快递员,需要从磁盘中读取数据 。内核会通过文件系统找到数据在磁盘上的位置,向磁盘发出 I/O 请求 。磁盘接收到请求后,开始工作,机械磁盘需要移动磁头定位到数据所在的磁道和扇区,固态磁盘则通过电子信号快速读取数据 。读取到的数据会被加载到页缓存中,然后再从页缓存复制到应用程序的内存空间 。如果页缓存已满,内核会按照一定的算法,如最近最少使用(Least Recently Used,LRU)算法,将最近最少使用的页面刷新到磁盘并从缓存中驱逐,以腾出空间给新页面 。
写入操作的流程也类似,应用程序将数据写入到内核的页缓存中,标记写入的页面为脏页(Dirty Page) 。此时数据并没有立即写入磁盘,而是在内核认为合适的时候,例如系统空闲时或者脏页数量达到一定阈值时,才会将脏页的数据真正写入磁盘,这个过程称为写回(Write Back) 。这样做的好处是可以减少磁盘 I/O 操作的次数,提高系统性能,因为磁盘的写入速度相对较慢,批量写入可以提高效率 。不过,如果系统突然崩溃,可能会导致部分已写入页缓存但未写回磁盘的数据丢失 。
页缓存的存在大大提高了 I/O 操作的性能,它利用了时间局部性原理(最近访问过的页面将在近期再次被访问)和空间局部性原理(物理上相邻的元素很有可能彼此接近) 。通过预读(Read - Ahead)机制,内核会提前加载可能会被访问的数据到页缓存中,预测它们的访问并摊销一些 I/O 成本 。同时,页缓存还通过延迟写入和合并相邻读取来进一步提升 I/O 性能 。
Part2.衡量磁盘I/O性能的关键指标
2.1 IOPS:每秒 I/O 操作次数
IOPS,即 Input/Output Operations Per Second,翻译过来就是每秒 I/O 操作次数 ,它就像是磁盘的 “忙碌程度计数器”,是衡量磁盘性能的重要指标之一 。这个指标主要用于评估存储设备在单位时间内能够处理的 I/O 请求数量,体现了磁盘随机读写的能力 。在实际应用中,IOPS 在随机 I/O 场景下有着不可替代的重要性 。例如在数据库事务处理中,数据库需要频繁地读写大量小数据块,这些数据块的存储位置通常是不连续的,属于典型的随机 I/O 操作 。以电商系统的订单处理为例,当用户下单时,系统需要将订单信息写入数据库的不同表和字段中,这些写入操作的位置是随机分布的 。
如果磁盘的 IOPS 较低,那么在高并发的下单场景下,数据库处理 I/O 请求的速度就会很慢,导致订单处理延迟,用户可能需要长时间等待才能看到下单结果,严重影响用户体验 。再比如在虚拟化环境中,多个虚拟机同时运行,每个虚拟机都可能产生大量的随机 I/O 请求 。如果存储设备的 IOPS 无法满足这些请求,就会导致虚拟机性能下降,出现卡顿、响应迟缓等问题 。
IOPS 的数值受到多种因素的影响 。从硬件方面来看,磁盘类型是一个关键因素,固态硬盘(SSD)由于没有机械寻道时间,其 IOPS 性能远远高于机械硬盘(HDD) 。一般消费级 SSD 的随机 IOPS 可以达到数万甚至数十万,而普通机械硬盘的随机 IOPS 通常只有几十到几百 。此外,硬盘的转速、缓存大小等也会对 IOPS 产生影响,转速越高、缓存越大,IOPS 性能相对越好 。在系统层面,队列深度也会影响 IOPS 。队列深度是指同时向磁盘提交的 I/O 请求数量 。
当队列深度增加时,磁盘可以并行处理更多的 I/O 请求,从而提高 IOPS 。不过,当队列深度超过一定值后,由于磁盘处理能力的限制,IOPS 可能不再提升,甚至会因为资源竞争而下降 。不同的 I/O 请求大小也会影响 IOPS,通常较小的 I/O 请求可以获得更高的 IOPS,因为它们占用磁盘的时间较短,磁盘可以在单位时间内处理更多的此类请求 。
2.2 吞吐量:数据传输速率
吞吐量,简单来说就是单位时间内成功传输的数据量 ,它就像是数据传输的 “高速公路”,反映了磁盘在单位时间内能够传输数据的能力,是衡量磁盘性能的另一个重要指标 ,单位通常是字节每秒(B/s)、千字节每秒(KB/s)或兆字节每秒(MB/s) 。在顺序 I/O 场景中,吞吐量起着至关重要的作用 。比如在视频流服务中,服务器需要将大量的视频数据连续不断地传输给用户 。假设一个高清视频的码率为 10Mbps(约 1.25MB/s),如果磁盘的吞吐量足够高,能够快速读取视频文件并传输给用户,那么用户就能流畅地观看视频,不会出现卡顿、加载缓慢等问题 。
相反,如果磁盘吞吐量不足,视频数据传输不及时,就会导致视频播放中断,用户体验极差 。再比如在数据备份场景中,需要将大量的文件从一个存储设备复制到另一个存储设备,这个过程涉及到大量的顺序读写操作 。如果磁盘吞吐量高,就能快速完成数据备份,节省时间;否则,备份过程可能会持续很长时间,影响业务的正常运行 。
影响吞吐量的因素有很多 。磁盘的类型和接口速度是重要因素之一,SSD 的顺序读写速度比 HDD 快很多,因此在顺序 I/O 场景下,SSD 的吞吐量通常更高 。例如,SATA 接口的 SSD 顺序读取速度一般在 500 - 600MB/s 左右,而 NVMe 接口的 SSD 顺序读取速度可以达到 3000MB/s 以上 。此外,数据块大小也会对吞吐量产生影响,较大的数据块可以减少 I/O 操作的次数,从而提高吞吐量 。在网络存储环境中,网络带宽也会限制吞吐量,如果网络带宽不足,即使磁盘本身的吞吐量很高,数据传输速度也会受到限制 。
2.3 延迟:I/O 操作的响应时间
I/O 延迟,指的是从应用程序发出 I/O 请求开始,到接收到 I/O 操作完成的响应所经历的时间 ,它就像是快递的 “送货时长”,是衡量磁盘性能的关键指标之一,直接反映了磁盘处理 I/O 请求的速度 。I/O 延迟对应用程序的性能有着深远的影响 。在实时交易系统中,如股票交易软件,每一次交易操作都需要快速读取和写入数据 。如果 I/O 延迟过高,从用户下单到系统确认交易的时间就会变长,可能会导致交易失败或者错过最佳交易时机 。再比如在游戏场景中,游戏需要实时加载各种资源,如地图、角色模型等 。如果 I/O 延迟大,游戏画面的加载就会缓慢,出现卡顿现象,严重影响玩家的游戏体验 。
I/O 延迟产生的原因主要有以下几个方面 。磁盘的物理特性是一个重要因素,对于机械硬盘来说,寻道时间和旋转延迟是导致 I/O 延迟的主要原因 。寻道时间是指磁头移动到数据所在磁道所需的时间,旋转延迟是指盘片旋转将数据所在扇区移动到磁头下方所需的时间 。由于机械硬盘的机械运动速度有限,这两个时间加起来通常会导致较高的 I/O 延迟 。而固态硬盘虽然没有机械运动部件,但也存在闪存芯片的读写延迟以及内部控制器的处理时间 。
此外,系统的负载情况也会影响 I/O 延迟 。当系统中有大量的 I/O 请求同时发生时,磁盘需要排队处理这些请求,等待时间就会增加,从而导致 I/O 延迟上升 。文件系统的设计和实现也会对 I/O 延迟产生影响,例如文件系统的元数据管理方式、缓存机制等 。
Part3.实用的磁盘I/O性能测试工具
在优化 Linux 磁盘 I/O 性能的过程中,选择合适的性能测试工具至关重要。这些工具就像是精准的 “性能探测器”,能够帮助我们深入了解磁盘 I/O 的性能状况,为优化提供有力的数据支持。接下来,让我们一起探索两款常用的磁盘 I/O 性能测试工具。
3.1 fio:灵活的 I/O 测试工具
fio 是一款功能极其强大且灵活的 I/O 测试工具,堪称 I/O 测试领域的 “瑞士军刀”,它支持多种操作系统,包括 Linux、Windows 等 ,并且可以模拟多种不同的 I/O 模式 ,是系统管理员和存储工程师评估存储性能的得力助手 。在 Linux 系统中,可以通过包管理器轻松安装,对于 Debian/Ubuntu 系统,使用命令 “sudo apt - get install fio”;对于 CentOS 系统,则使用 “sudo yum install fio” 。
fio 之所以如此强大,是因为它拥有丰富的参数选项,能够满足各种复杂的测试需求 。比如 “--name” 用于定义作业名称,方便在测试结果中区分不同的测试任务;“--ioengine” 用于指定 I/O 引擎,常见的有 sync、mmap、pvsync、libaio 等,不同的 I/O 引擎适用于不同的测试场景 。“--rw” 用来指定读写方式,如 randread(随机读)、randwrite(随机写)、read(顺序读)、write(顺序写)等 。“--bs” 表示块大小,“--size” 指定测试文件大小,“--numjobs” 设置工作线程数,“--runtime” 规定测试运行时间,“--time_based” 确定测试运行模式(时间模式或者 I/O 模式),“--direct” 决定是否使用直接 I/O 。“--iodepth” 代表 I/O 队列深度,“--group_reporting” 用于指定是否按照组进行测试结果的报告,“--output - format” 可以指定测试结果的输出格式,如 json、csv、xml 等 。
下面通过几个具体的例子来看看如何使用 fio 进行常见 I/O 场景测试 。假设我们要测试磁盘的顺序读性能,可以使用这样的命令:“fio --name = seq_read --ioengine = libaio --iodepth = 1 --rw = read --bs = 4k --size = 1G --numjobs = 1” 。在这个命令中,“--name = seq_read” 设定作业名称为 seq_read ;“--ioengine = libaio” 选择异步 I/O 引擎 libaio ,它能提供高效的异步 I/O 操作,适合模拟实际应用中的异步读写场景 ;“--iodepth = 1” 设置 I/O 队列深度为 1 ,表示每个工作线程同时只进行 1 个 I/O 操作 ;“--rw = read” 指定测试类型为顺序读 ;“--bs = 4k” 将块大小设置为 4KB ,这是一个常见的块大小,很多文件系统和应用程序在处理小文件时会使用这个大小 ;“--size = 1G” 表示测试文件大小为 1GB ;“--numjobs = 1” 代表使用 1 个工作线程 。执行这个命令后,fio 会按照设定的参数进行顺序读测试,并输出详细的测试结果,包括 IOPS、带宽、延迟等信息 。
再比如,要测试磁盘的随机读写混合性能,命令可以是:“fio --name = rand_rw_mix --ioengine = libaio --iodepth = 16 --rw = randrw --rwmixread = 70 --bs = 4k --size = 2G --numjobs = 4 --runtime = 60 --group_reporting” 。这里 “--rw = randrw” 指定为随机读写混合模式 ,“--rwmixread = 70” 表示读操作占 70% ,写操作占 30% ,这样可以模拟一些实际应用中读写比例不同的场景 ,如数据库的读写操作 ;“--iodepth = 16” 增大了 I/O 队列深度,以测试磁盘在高并发 I/O 请求下的性能 ;“--numjobs = 4” 使用 4 个工作线程并发进行测试 ;“--runtime = 60” 设置测试运行时间为 60 秒 ;“--group_reporting” 使测试结果按照组进行报告,方便查看和分析多个工作线程的整体性能 。通过这些不同参数的组合,fio 能够模拟出各种各样复杂的 I/O 场景,为我们深入了解磁盘性能提供了有力的支持 。
3.2 iostat:系统 I/O 统计信息查看工具
iostat 是 Linux 系统中一个非常实用的工具,它就像是系统 I/O 的 “健康检测仪”,主要用于监控系统设备的 I/O 负载情况 ,能够提供关于磁盘使用情况、读写操作和等待时间等丰富的 I/O 性能状态数据 。iostat 命令首次运行时,会显示自系统启动开始的各项统计信息,之后运行则显示自上次运行该命令以后的统计信息 。我们可以通过指定统计的次数和时间来获取所需的统计信息 。在大多数 Linux 发行版中,iostat 命令包含在 sysstat 包中 。对于 Debian/Ubuntu 系统,可以使用 “sudo apt - get install sysstat” 命令进行安装;对于 CentOS 系统,使用 “sudo yum install sysstat” 来安装 。
使用 iostat 查看磁盘 I/O 统计信息的方法较为简单 。基本命令格式为 “iostat [OPTION] [INTERVAL] [COUNT]” ,其中 “OPTION” 是选项参数,用于指定输出的特定信息,“INTERVAL” 指定数据刷新间隔,单位为秒,“COUNT” 指定显示数据的次数 。例如,要查看系统所有磁盘设备每秒的 I/O 情况,并以扩展格式显示详细信息,可以使用命令 “iostat -x 1” 。这里 “-x” 选项表示显示扩展统计信息,它会展示诸如每秒合并的读请求数量(rrqm/s)、每秒合并的写请求数量(wrqm/s)、每秒读取的操作数(r/s)、每秒写入的操作数(w/s)、每次请求的平均等待时间(await)、磁盘当前的使用率(% util)等详细数据 ,“1” 表示每秒更新一次数据 。
执行该命令后,会实时输出磁盘 I/O 的各项统计信息,通过这些信息,我们可以直观地了解磁盘的工作状态 。比如,如果看到 “% util” 接近 100% ,说明磁盘产生的 I/O 请求太多,I/O 系统已经满负荷,该磁盘可能存在瓶颈 ;如果 “await” 远大于平均每次设备 I/O 操作的服务时间(svctm),说明 I/O 队列太长,I/O 响应太慢,可能需要进行优化 。
如果只想查看指定磁盘设备(如 sda)的I/O统计信息,可以使用 “iostat -d -x sda 2” 命令 。“-d”选项表示仅显示设备(磁盘)使用状态,“-x” 依然是显示扩展信息,“sda” 指定要监控的磁盘设备,“2”表示每2秒刷新一次数据 。这样就能专注于特定磁盘的性能监控,方便我们对单个磁盘进行详细的分析和排查问题 。此外,还可以结合其他选项来满足不同的需求,比如“-k”选项使某些使用 block 为单位的列强制使用 Kilobytes 为单位显示,“-m”选项则是以兆字节每秒为单位显示传输速率,让我们能更直观地理解数据的大小和传输速度 。
Part4.Linux磁盘I/O性能优化实战策略
4.1 应用程序层面的优化
在应用程序层面,优化 I/O 请求模式是提升磁盘 I/O 性能的关键策略之一 。尽量使用顺序 I/O 代替随机 I/O,因为顺序 I/O 就像在一条畅通无阻的高速公路上行驶,数据读取或写入的位置是连续的,避免了磁盘磁头频繁寻道的开销 。例如,在数据写入场景中,按顺序将数据写入文件,而不是随机地在文件的不同位置进行写入操作 。对于数据库应用,可以通过合理设计表结构和索引,使得数据的读写操作尽可能顺序化 。以电商数据库中的订单表为例,按照订单时间顺序存储订单数据,在查询一段时间内的订单时,就可以利用顺序 I/O 快速读取数据 。
减少不必要的 I/O 操作也是提高性能的重要方法 。在程序中避免频繁地打开和关闭文件,因为每次打开和关闭文件都涉及到系统资源的分配和释放,会增加 I/O 开销 。可以将多次小的 I/O 操作合并为一次大的 I/O 操作,减少 I/O 请求的次数 。比如在日志记录场景中,不要每次有新的日志信息就立即写入文件,而是先将日志信息缓存起来,当缓存达到一定数量或一定时间间隔后,再一次性写入文件 。
使用异步 I/O(Asynchronous I/O)可以显著提升 I/O 性能 。异步 I/O 允许应用程序在发起 I/O 请求后,不需要等待 I/O 操作完成就可以继续执行其他任务,就像在餐厅点餐时,点完餐可以先去做其他事情,而不是一直等待食物上桌 。在 Linux 系统中,可以使用 libaio 库来实现异步 I/O 。以 C 语言为例,通过调用 libaio 库中的函数,如 io_submit、io_getevents 等,可以实现高效的异步 I/O 操作 。在高并发的 Web 服务器应用中,使用异步 I/O 可以让服务器在处理 I/O 操作的同时,继续响应其他客户端的请求,大大提高服务器的并发处理能力 。
合理运用缓存技术也能有效减少磁盘I/O操作 。在应用程序内部构建缓存机制,将经常访问的数据存储在内存缓存中,当再次需要访问这些数据时,直接从缓存中获取,避免了磁盘I/O 。例如,在 Web 应用中,可以使用 Memcached或Redis等内存缓存系统,缓存网页片段、数据库查询结果等数据 。当用户请求相同的数据时,应用程序首先检查缓存,如果缓存中有数据,就直接返回给用户,减少了从磁盘读取数据的时间 。同时,还可以利用操作系统的页缓存,通过适当的文件访问模式和系统调用,让操作系统更好地管理页缓存,提高数据访问效率 。
4.2 文件系统层面的优化
选择合适的文件系统是文件系统层面优化的基础 。不同的文件系统有着各自独特的特性,适用于不同的应用场景 。EXT4 是 Linux 系统中广泛使用的文件系统,它具有成熟稳定、兼容性好的特点 ,在小文件处理方面表现出色,适合一般的桌面应用和小型服务器场景 。比如在个人电脑的 Linux 系统中,使用 EXT4 文件系统来存储日常的文档、图片、视频等文件,能够满足用户的基本需求 。XFS 文件系统则更适合大文件和高并发的应用场景 ,它具有高性能、可扩展性强的优点,支持超大文件和大容量存储设备 。
在大型数据中心中,用于存储海量数据的服务器,如视频存储服务器,采用 XFS 文件系统可以充分发挥其优势,快速处理大量的大文件读写请求 。Btrfs 文件系统则提供了一些高级功能,如快照、数据压缩、错误检测与修复等 ,适用于对数据管理和可靠性有较高要求的场景 ,如企业级数据存储和备份系统 。
调整文件系统的挂载选项和参数可以进一步优化性能 。在挂载文件系统时,可以使用 “noatime” 和 “nodiratime” 选项 。“noatime” 禁止更新文件的访问时间戳,“nodiratime” 禁止更新目录的访问时间戳 。这两个选项可以减少文件系统的 I/O 操作,因为每次文件或目录被访问时,默认情况下会更新其访问时间戳,这会产生额外的 I/O 开销 。例如,对于一些只需要读取数据,而不需要关注文件访问时间的应用场景,如静态文件服务器,可以在挂载文件系统时使用这两个选项,提高系统性能 。
对于使用 EXT4 文件系统的设备,可以使用 tune2fs 命令来调整文件系统的参数 。比如使用 “tune2fs -o journal_data_writeback /dev/sda1” 命令,可以将文件系统的日志模式设置为 data=writeback,这种模式下,数据的写入操作会更加激进,性能更高,但在系统崩溃时可能会导致数据丢失的风险增加 ,适用于对性能要求较高且对数据一致性要求相对较低的场景 。还可以合理设置文件系统的日志大小,使用 “mkfs.ext4 -J size=1g /dev/sda1” 命令可以在创建 EXT4 文件系统时,将日志大小设置为 1GB ,根据实际需求调整日志大小,可以平衡文件系统的性能和数据安全性 。
4.3 磁盘层面的优化
在磁盘层面,升级硬件是提升 I/O 性能最直接有效的方法之一 。将机械硬盘升级为固态硬盘(SSD)能带来质的飞跃 。SSD 凭借其快速的读写速度、极低的寻道时间和高随机 I/O 性能,成为对 I/O 性能要求苛刻场景的首选 。在数据中心中,许多高性能数据库服务器纷纷采用 SSD 作为存储设备 。以 Oracle 数据库为例,将原本使用机械硬盘的存储系统更换为 SSD 后,数据库的查询响应时间大幅缩短,事务处理能力显著提升 。在一些对数据读写速度要求极高的实时分析系统中,SSD 的优势也得以充分体现,能够快速处理大量的实时数据,为决策提供及时准确的支持 。
优化磁盘阵列配置也能显著提高性能 。RAID(Redundant Arrays of Independent Disks)技术通过将多个磁盘组合成一个逻辑单元,实现数据冗余、提高数据访问速度以及增强数据保护能力 。不同的 RAID 级别适用于不同的场景 。RAID 0采用条带化技术,将数据分散存储在多个磁盘上,读写性能极高,但没有数据冗余,一旦其中一个磁盘出现故障,整个阵列的数据都会丢失 ,适用于对数据安全性要求不高,但对读写速度要求极高的场景,如视频编辑工作站,在处理大型视频文件时,可以利用 RAID 0的高速读写性能快速加载和保存视频数据 。RAID 1 是镜像模式,将数据完全复制到多个磁盘上,具有很高的数据冗余能力,任何一块磁盘的故障都不会影响数据的访问,但写入性能相对较低,因为每次写操作都需要同时写入多个磁盘 ,常用于对数据安全性要求极高的场景,如银行的核心业务系统,确保客户数据的安全可靠 。
RAID 5结合了数据分条和分布式奇偶校验技术,读性能接近 RAID 0,写性能处于平均水准,允许一块磁盘损坏,利用剩下的数据和奇偶校验信息可以恢复被损坏的数据 ,适用于对性能和安全都有一定要求的场景,如企业的文件服务器,既能保证数据的安全性,又能满足日常文件读写的性能需求 。RAID 10则是 RAID 0和 RAID 1的组合体,首先创建多个RAID 1 镜像对,然后将这些镜像对条带化成 RAID 0 阵列,读写性能都非常高,且具有较高的容错能力 ,适用于对性能和数据安全性都有极高要求的场景,如大型电商网站的数据库主库,在高并发的业务场景下,既能保证数据的安全,又能快速响应大量的读写请求 。
调整 I/O 调度器也是优化磁盘性能的重要手段 。Linux 系统提供了多种 I/O 调度器,如 noop、deadline、cfq(完全公平队列)等 。noop 调度器实现了一个简单的 FIFO 队列,像电梯一样对 I/O 请求进行组织,将新请求合并到最近的请求之后 ,它非常适合 SSD 等快速存储设备,因为 SSD 的读写速度快,寻道时间几乎可以忽略不计,noop 调度器简单高效的特性能够充分发挥 SSD 的优势 。在使用 SSD 的服务器中,将 I/O 调度器设置为 noop,可以减少调度器的开销,提高 I/O 性能 。
deadline 调度器通过时间以及硬盘区域进行分类,确保在一个截止时间内服务请求,默认读期限短于写期限,防止写操作因为不能被读取而饿死 ,它对数据库环境非常友好,在数据库服务器中,使用 deadline 调度器可以保证数据库的 I/O 请求能够得到及时处理,减少 I/O 延迟,提高数据库的性能 。
cfq 调度器试图均匀地分布对 I/O 带宽的访问,避免进程被饿死并实现较低的延迟 ,它是一种比较通用的调度器,对于通用的服务器和桌面系统是一个不错的选择 ,在日常办公的 Linux 桌面系统中,cfq 调度器能够公平地分配 I/O 资源,保证各个应用程序都能获得合理的 I/O 带宽 。可以通过修改 “/sys/block/sdX/queue/scheduler” 文件来调整 I/O 调度器,例如 “echo noop > /sys/block/sda/queue/scheduler” 命令可以将 sda 磁盘的 I/O 调度器设置为 noop 。