Linux性能分析工具,ftrace的原理与使用
在Linux 内核这片深邃而神秘的技术海洋里,每一个系统进程的运行、每一次资源的调度,都像是在黑暗中上演的复杂剧目。内核开发者们时常面临着棘手难题:系统莫名卡顿,究竟是哪个内核函数在作祟?进程调度出现异常,问题根源又在何处?在漫长的探索历程中,开发者们急需一款强大的工具,能够像聚光灯一样,穿透重重迷雾,照亮内核运行的每一个角落
它能深入追踪内核函数调用流程,为排查棘手的系统问题提供关键线索;还能精准剖析系统延迟信息,助力定位性能瓶颈。无论是优化内核代码,还是提升系统整体性能,ftrace 都发挥着不可替代的作用。接下来,让我们一同深入探索 ftrace 的核心原理,学习如何在实际场景中灵活运用它,挖掘系统潜在的性能提升点 。
Part1.ftrace 是什么?
ftrace,全称 Function Trace,是 Linux 内核自带的一款强大的动态跟踪工具,诞生于 2008 年,由 Steven Rostedt 开发,并在 2.6.27 版本的内核中首次引入 。最初,它只是一个简单的函数跟踪器,主要用于记录内核的函数调用流程。经过多年的发展与完善,如今 ftrace 已演变成一个功能丰富的跟踪框架,采用插件式的设计,支持开发者添加更多类型的跟踪功能,在 Linux 内核的开发与调试中发挥着不可或缺的作用。
从本质上来说,ftrace 是一个内核级别的工具,它深入到 Linux 内核的内部,能够详细地跟踪和记录内核函数的调用、进程的调度、中断的处理等关键信息。这就好比在一个大型工厂里,ftrace 就像是一个无处不在的监控系统,能够记录下每一个生产环节的运行情况,从原材料的进入,到产品的组装,再到最终的出厂,每一个步骤都逃不过它的 “眼睛”。
在 Linux 内核中,ftrace 的作用至关重要。它为内核开发者和系统管理员提供了一种深入了解系统运行时行为的有效方式。通过 ftrace,我们可以清晰地看到内核函数之间的调用关系,了解函数的执行时间,以及进程在系统中的调度情况。这些信息对于优化内核性能、调试系统故障、以及理解系统的整体运行机制都具有极高的价值。
例如,当我们怀疑某个内核模块存在性能问题时,可以使用 ftrace 来跟踪该模块中函数的调用情况,找出执行时间较长的函数,进而分析原因并进行优化。又或者,当系统出现异常崩溃时,ftrace 记录的函数调用栈信息可以帮助我们快速定位到问题的根源,确定是哪个函数在什么情况下出现了错误。
Ftrace 包含两个核心组成部分:
Framework core(框架核心):它主要起到管理各种 tracer(追踪器)的作用,同时利用 tracefs 文件系统对用户空间提供配置选项以及输出 trace 信息,像是在整个流程中扮演着 “指挥官” 的角色,协调着各部分有序工作,确保数据的准确获取与配置的有效实施。例如,它会负责对内核进行必要的修改、完成 Tracer 的注册以及对 Ring Buffer 的控制等操作。Tracers(追踪器):Ftrace 实现了多种类型的 tracer,像 Function tracer(函数调用追踪器)、Function graph tracer(函数调用图跟踪器)等都是其中的成员。每一种 tracer 都负责着不同的功能,并且它们统一由 Framework core 管理。具体来说,tracer 负责将 trace 信息保存到 Ring Buffer 中,例如 Function tracer 可以看出哪个函数何时被调用,开发人员还可以通过过滤器指定想要跟踪的函数;Function graph tracer 则能够清晰展现出函数的调用层次关系以及返回情况。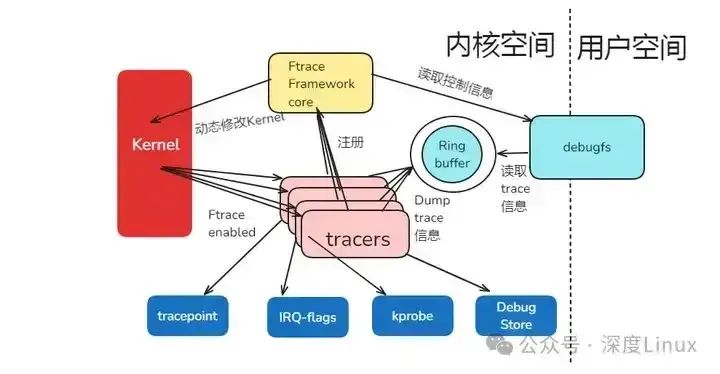 图片
图片
不同的 tracer 可以帮助开发人员从不同角度去分析内核的运行情况,以便更精准地查找问题或者进行性能分析等工作。
Part2.ftrace的工作原理
2.1插桩技术
ftrace 的强大功能离不开其背后精妙的工作原理,而插桩技术则是其实现内核跟踪的核心基础。插桩技术就像是在系统这个庞大的机器中安装了许多精密的 “传感器”,这些 “传感器” 能够实时捕捉系统运行时的各种信息,为我们深入了解系统内部的运行机制提供了关键数据。ftrace 采用了静态插桩和动态插桩两种方式,它们各有特点,相互配合,共同实现了高效的内核跟踪。
 图片
图片
静态插桩是 ftrace 实现跟踪功能的基础方式之一 。当我们在 Kernel 中打开 CONFIG_FUNCTION_TRACER 功能后,编译过程中会增加一个 - pg 的编译选项。这个编译选项就像是一个神奇的 “指令注入器”,它会在每个函数入口处插入一条 bl mcount 跳转指令。这意味着,当系统中的每个函数运行时,都会先跳转到 mcount 函数。在 mcount 函数中,会判断函数指针 ftrace_trace_function 是否被注册,默认注册的是空函数 ftrace_stub,只有打开 function tracer 后才会注册具体的处理函数 ftrace_trace_function。
这种静态插桩的方式,就像是在每个函数的必经之路上设置了一个固定的 “检查点”,无论函数何时被调用,都必须经过这个 “检查点”,从而实现对所有函数调用的跟踪。然而,这种方式虽然能够全面地跟踪函数调用,但也带来了一定的性能开销,因为每个函数调用都要额外执行一次跳转和判断操作,这在高负载的系统中可能会对性能产生明显的影响。
为了解决静态插桩带来的性能问题,开发者们推出了 Dynamic ftrace,即动态插桩技术 。动态插桩技术的核心思想是动态修改函数指令,以实现更加灵活和高效的跟踪。在编译时,系统会记录所有被添加跳转指令(即支持追踪)的函数。
在内核启动时,这些函数入口处的跳转指令会被替换为 nop 指令(nop 指令是一种空操作指令,执行它不会产生任何实际的运算或操作,仅占用一个指令周期),这样在非调试状态下,函数的执行就不会受到额外的性能损耗,就像在高速公路上取消了所有不必要的收费站,车辆可以畅行无阻,大大提高了系统的运行效率。而当需要进行跟踪时,根据 function tracer 的设置,系统会动态地将被调试函数的 nop 指令替换为跳转指令,从而实现对特定函数的追踪。
这种动态插桩的方式,就像是一个智能的 “交通管制系统”,只有在需要监控某些特定 “车辆”(函数)时,才会在其行驶路径上设置 “检查点”,而在其他时候,道路则保持畅通,既实现了跟踪功能,又最大限度地减少了对系统性能的影响。
2.2数据记录与存储
当 ftrace 通过插桩技术在函数入口处设置好 “传感器” 后,接下来就需要考虑如何记录这些函数调用过程中产生的数据,并将这些宝贵的信息存储起来,以便后续的分析和处理。
在开启 ftrace 的跟踪功能后,首先会打开编译选项 -pg,为每个函数都增加跳转指令,这就像是为每个函数都安装了一个 “数据采集器”,当函数被调用时,“数据采集器” 就会被触发。
然后,系统会记录这些可追踪的函数,并为了减少性能消耗,将跳转函数替换为 nop 指令,就像暂时关闭了这些 “数据采集器”,让系统能够高效运行。而当需要进行跟踪时,通过 flag 标志位来动态管理,将需要追踪的函数预留的 nop 指令替换回追踪指令,此时 “数据采集器” 重新启动,开始记录调试信息,包括函数的调用时间、调用参数、返回值等关键信息。
ftrace 将这些追踪信息存储到 Ring buffer 缓冲区中 。Ring buffer 是一种环形缓冲区,它就像是一个循环的 “数据仓库”,具有固定的大小。当追踪信息产生时,会按照顺序依次写入 Ring buffer 中。当缓冲区被填满后,新产生的追踪信息会覆盖最早写入的信息,就像一个不断循环的传送带,始终保持最新的追踪数据在缓冲区中。这种设计方式既保证了追踪信息的实时性,又避免了因缓冲区溢出而导致的数据丢失问题。
用户可以通过读取 Ring buffer 中的数据,来获取系统的运行时行为信息,为性能分析和故障排查提供有力的支持。例如,在分析系统性能瓶颈时,开发人员可以从 Ring buffer 中读取函数调用的时间信息,找出那些执行时间较长的函数,进而深入分析这些函数的内部实现,找出性能瓶颈所在;在排查系统故障时,开发人员可以读取函数调用的参数和返回值信息,判断函数是否在某些特定参数下出现异常,从而快速定位问题的根源。
2.3工作流程详解
ftrace 的工作流程可以分为初始化、设置跟踪选项、数据采集和输出四个主要阶段。
在初始化阶段,ftrace 会进行一系列的准备工作,包括创建和初始化各种数据结构,注册跟踪处理函数,以及设置默认的跟踪参数等。这个阶段就像是搭建一个舞台,为后续的跟踪表演做好准备。在这个过程中,ftrace 会在内核中创建函数指针数组和跟踪缓冲区,并将它们初始化为默认状态。同时,ftrace 还会注册一些默认的跟踪处理函数,这些函数将负责处理各种类型的跟踪事件。
设置跟踪选项是 ftrace 工作流程中的一个关键步骤,它允许用户根据自己的需求定制跟踪行为。用户可以通过tracefs文件系统下的一系列控制文件来设置跟踪选项,比如选择要使用的跟踪器类型(如function跟踪器、function_graph跟踪器等),指定要跟踪的函数列表,设置跟踪过滤器等。通过这些灵活的配置选项,用户可以精确地控制 ftrace 收集哪些信息,以及如何收集这些信息。例如,如果用户只关心某个特定内核模块中的函数调用情况,他可以通过设置跟踪过滤器,让 ftrace 只跟踪该模块中的函数,而忽略其他函数的调用。
数据采集阶段是 ftrace 发挥其核心功能的阶段。当系统运行时,ftrace 会根据用户设置的跟踪选项,在内核函数执行过程中实时采集相关的运行时信息。通过插桩技术,ftrace 在函数调用的关键位置触发跟踪处理函数,这些函数会收集函数的参数、返回值、调用时间等信息,并将这些信息存储到跟踪缓冲区中。在这个过程中,ftrace 会高效地处理大量的跟踪数据,确保数据的准确性和完整性。
最后是数据输出阶段,用户可以通过tracefs文件系统下的trace文件或者其他相关工具(如trace-cmd、kernelshark等)来读取跟踪缓冲区中的数据,并进行分析和处理。trace文件以一种可读的文本格式存储着跟踪数据,用户可以直接使用文本编辑器打开该文件,查看系统的运行时信息。而trace-cmd和kernelshark等工具则提供了更加方便和强大的数据分析功能,它们可以将跟踪数据以图表、图形等形式展示出来,帮助用户更直观地理解系统的运行状态,快速定位性能问题。
Part3.Ftrace的探测技术
3.1静态探针机制
静态探测是在内核代码中调用 Ftrace 提供的相应接口来实现的,之所以称之为静态,是因为这种探测方式是在内核代码里写死的,会静态编译到内核代码中。一旦内核编译完成,就没办法再进行动态修改了。
这些在内核代码里插入的用于探测的 tracepoint(跟踪点),主要是为了支持 Event tracing(事件跟踪)。并且,这些 tracepoint 有着对应的开关,而这个开关是由内核配置选项来进行控制的。值得一提的是,内核开发人员已经提前在一些关键的地方设置好了静态探测点,当使用者有相应需求,开启相关功能后,就可以查看这些地方的探测信息了,方便对内核特定关键环节进行分析和调试。
3.2动态探针机制
动态探测则利用了 GCC 编译的 profile 特性来发挥作用。在 Linux 内核编译之时,会在每个函数入口处预留数个字节。等到实际使用 Ftrace 时,就可以将之前预留的这些字节替换为所需要的指令,例如替换为能够跳转到需要执行探测操作代码处的指令,从而实现探测功能。
像我们熟知的 function tracer(函数调用追踪器)、function graph tracer(函数调用图跟踪器)等追踪器,都是基于这种动态探测机制实现的。通过这样的动态探测机制,开发人员可以更加灵活地根据具体需求去对内核函数进行跟踪,获取相应的运行信息,为查找性能问题、分析代码执行逻辑等工作提供有力支持。
Part4.Ftrace如何使用
要使用 ftrace,首先就是需要将系统的 debugfs 或者 tracefs 给挂载到某个地方,幸运的是,几乎所有的 Linux 发行版,都开启了 debugfs/tracefs 的支持,所以我们也没必要去重新编译内核了。
在比较老的内核版本,譬如 CentOS 7 的上面,debugfs 通常被挂载到 /sys/kernel/debug 上面(debug 目录下面有一个 tracing 目录),而比较新的内核,则是将 tracefs 挂载到 /sys/kernel/tracing,无论是什么,我都喜欢将 tracing 目录直接 link 到 /tracing。后面都会假设直接进入了 /tracing 目录,后面,我会使用 Ubuntu 16.04 来举例子,内核版本是 4.13 来举例子。
在使用ftrace之前,需要内核进行支持,也就是内核需要打开编译中的ftrace相关选项,关于怎么激活ftrace选项的问题,可以google之,下面只说明重要的设置步骤:
使用传统的 ftrace 需要如下几个步骤:
选择一种 tracer使能 ftrace执行需要 trace 的应用程序,比如需要跟踪 ls,就执行 ls关闭 ftrace查看 trace 文件用户通过读写 debugfs 文件系统中的控制文件完成上述步骤。使用 debugfs,首先要挂载它。命令如下:
此时您将在 /debug 目录下看到 tracing 目录。Ftrace 的控制接口就是该目录下的文件。
选择 tracer 的控制文件叫作 current_tracer 。选择 tracer 就是将 tracer 的名字写入这个文件,比如,用户打算使用 function tracer,可输入如下命令:
文件 tracing_enabled 控制 ftrace 的开始和结束。
上面的命令使能 ftrace 。同样,将 0 写入 tracing_enable 文件便可以停止 ftrace 。
ftrace 的输出信息主要保存在 3 个文件中。
Trace,该文件保存 ftrace 的输出信息,其内容可以直接阅读。latency_trace,保存与 trace 相同的信息,不过组织方式略有不同。主要为了用户能方便地分析系统中有关延迟的信息。trace_pipe 是一个管道文件,主要为了方便应用程序读取 trace 内容。算是扩展接口吧。我们使用 ls 来看看目录下面到底有什么:
可以看到,里面有非常多的文件和目录,具体的含义,大家可以去详细的看官方文档的解释,后面只会重点介绍一些文件。
4.1 ftrace功能
我们可以通过 available_tracers 这个文件知道当前 ftrace 支持哪些插件。
通常用的最多的就是function和function_graph,当然,如果我们不想 trace 了,可以使用nop。我们首先打开function:
上面我们将 function 写入到了 current_tracer 来开启 function 的 trace,我通常会在 cat 下 current_tracer 这个文件,主要是防止自己写错了。然后 ftrace 就开始工作了,会将相关的 trace 信息放到 trace 文件里面,我们直接读取这个文件就能获取相关的信息。
我们可以设置只跟踪特定的 function
当然,如果我们不想 trace schedule 这个函数,也可以这样做:
或者也可以这样做:
Function filter 的设置也支持 *match,match* ,*match* 这样的正则表达式,譬如我们可以 echo *lock* < set_ftrace_notrace 来禁止跟踪带 lock 的函数,set_ftrace_notrace 文件里面这时候就会显示:
4.2函数图
相比于 function,function_graph 能让我们更加详细的去知道内核函数的上下文,我们打开 function_graph:
我们也可以只跟踪某一个函数的堆栈
4.3事件
上面提到了 function 的 trace,在 ftrace 里面,另外用的多的就是 event 的 trace,我们可以在 events 目录下面看支持哪些事件:
上面列出来的都是分组的,我们可以继续深入下去,譬如下面是查看sched相关的事件:
对于某一个具体的事件,我们也可以查看:
不知道大家注意到了没有,上述目录里面,都有一个enable的文件,我们只需要往里面写入 1,就可以开始 trace 这个事件。譬如下面就开始 tracesched_wakeup这个事件:
我们也可以 tracesched里面的所有事件:
当然也可以 trace 所有的事件:
4.4trace-cmd
从上面的例子可以看到,其实使用 ftrace 并不是那么方便,我们需要手动的去控制多个文件,但幸运的是,我们有 trace-cmd,作为 ftrace 的前端,trace-cmd 能够非常方便的让我们进行 ftrace 的操作,譬如我们可以使用 record 命令来 trace sched 事件:
然后使用report命令来查看 trace 的数据:
当然,在report的时候也可以加入自己的 filter 来过滤数据,譬如下面,我们就过滤出sched_wakeup事件并且是success为 1 的。
大家可以注意下success == 1,这其实是一个对事件里面 field 进行的表达式运算了,对于不同的事件,我们可以通过查看其 format 来知道它的实际 fields 是怎样的,譬如:
Part5.ftrace 的使用指南
5.1准备工作
在使用 ftrace 之前,需要确保内核配置中启用了相关选项。主要的配置选项包括CONFIG_FTRACE、CONFIG_FUNCTION_TRACER、CONFIG_FUNCTION_GRAPH_TRACER等 。这些选项在编译内核时进行设置,如果你的系统已经安装好了内核,并且不确定是否启用了这些选项,可以通过查看/boot/config-$(uname -r)文件来确认。如果文件中包含类似CONFIG_FTRACE=y、CONFIG_FUNCTION_TRACER=y的配置项,就说明相应的选项已经启用。如果没有启用,你可能需要重新编译内核并开启这些选项。
完成内核配置后,还需要挂载debugfs文件系统。debugfs是一种特殊的文件系统,用于提供内核调试信息的接口,ftrace 就是通过debugfs来实现与用户空间的交互。挂载debugfs文件系统非常简单,只需要执行以下命令:
执行上述命令后,debugfs文件系统就会被挂载到/sys/kernel/debug目录下。在这个目录下,你可以找到ftrace相关的控制文件和跟踪数据文件,后续对 ftrace 的操作都将通过这些文件来完成。
5.2常用文件及操作/sys/kernel/debug/tracing目录下包含了许多与 ftrace 相关的文件,这些文件是我们使用 ftrace 的关键。下面介绍一些常用的文件及其操作:
①tracing_on:这个文件用于启用或禁用跟踪功能。当你将1写入该文件时,ftrace 会开始向跟踪缓冲区写入数据,即启用跟踪;当写入0时,跟踪功能将被禁用 。例如,要启用跟踪功能,可以执行以下命令:
②trace:该文件以文本格式存储着内核跟踪缓冲区中的内容,是我们查看跟踪结果的主要文件。你可以使用cat命令来读取其中的内容,例如:
如果需要清空跟踪缓冲区的内容,可以向该文件写入空字符串,命令如下:
③set_ftrace_filter:通过向这个文件写入函数名,可以指定只跟踪特定的函数。例如,如果你只想跟踪do_sys_open函数,可以执行以下命令:
此外,该文件还支持通配符匹配,比如echo irq* > /sys/kernel/debug/tracing/set_ftrace_filter可以跟踪所有以irq开头的函数。
5.3实际操作示例
为了更直观地了解 ftrace 的使用方法,我们以跟踪/dev/tty0设备节点的tty_open和tty_write函数调用流程为例,详细展示 ftrace 的使用过程。
首先,编写一个简单的应用程序serial.c,用于打开和写入/dev/tty0设备节点:
将上述代码保存为serial.c文件,并使用交叉编译器将其编译成可执行文件,例如:
接下来,编写一个脚本trace_pid.sh,用于操作tracefs节点来配置和启动 ftrace 跟踪:
将上述脚本保存为trace_pid.sh文件,并赋予其可执行权限:
最后,执行脚本:
执行完成后,通过查看/sys/kernel/debug/tracing/trace文件,就可以看到tty_open和tty_write函数的调用流程信息,类似如下输出:
通过这些信息,我们可以清晰地了解到tty_open和tty_write函数的调用顺序、执行时间以及它们与其他函数之间的关系,从而帮助我们分析和优化相关的代码逻辑。
5.4进阶使用技巧
掌握了 ftrace 的基本使用方法后,我们还可以学习一些进阶技巧,以更灵活、高效地使用 ftrace 进行性能分析。
(1)查看函数调用栈:在分析复杂的系统问题时,查看函数调用栈信息非常有用。ftrace 提供了相关的功能来满足这一需求。你可以通过设置trace_options文件中的stacktrace选项来启用函数调用栈的记录。例如:
启用后,在trace文件的输出中,每个函数调用记录都会附带其调用栈信息,帮助你更好地理解函数的调用关系和执行上下文。
(2)跟踪短时间执行的命令:对于一些执行时间非常短的命令,普通的跟踪方式可能无法捕捉到完整的信息。这时,可以使用trace-cmd工具结合-p function_graph选项来进行跟踪。trace-cmd是一个基于 ftrace 的命令行工具,它提供了更便捷的操作方式和更丰富的功能。例如,要跟踪ls命令的执行过程,可以执行以下命令:
执行完成后,使用trace-cmd report命令查看跟踪结果,就可以看到ls命令在执行过程中涉及的内核函数调用信息。
(3)过滤技巧:ftrace 的过滤功能非常强大,除了前面提到的通过set_ftrace_filter文件按函数名进行过滤外,还可以结合模块名进行更精准的过滤。例如,要跟踪ext3模块中所有以write开头的函数,可以执行以下命令:
此外,还可以通过设置set_ftrace_notrace文件来排除某些函数的跟踪,例如:
(4)用户态内核态联动:在实际的性能分析中,有时需要同时跟踪用户态和内核态的函数调用,以全面了解系统的运行情况。ftrace 通过uprobes和kprobes机制实现了用户态和内核态的联动跟踪。uprobes用于在用户空间的函数中插入探测点,kprobes则用于在内核函数中插入探测点。例如,要在用户态的main函数和内核态的do_sys_open函数中插入探测点,可以按照以下步骤操作:
首先,获取main函数的地址。假设应用程序为test,可以使用readelf命令获取其地址:
然后,将探测点信息写入uprobe_events文件,例如:
对于内核态的do_sys_open函数,将探测点信息写入kprobe_events文件:
最后,启用跟踪并查看结果:
通过这种方式,就可以同时跟踪用户态和内核态的函数调用,为深入分析系统性能问题提供更全面的数据支持。
(5)灵活控制 trace 开关:在实际应用中,有时需要根据特定的条件来灵活控制 ftrace 的跟踪开关。例如,当某个特定的函数被调用时,自动开启或关闭跟踪。ftrace 提供了触发器(triggers)功能来实现这一需求。你可以通过set_ftrace_filter文件设置触发器,例如:
上述命令表示当do_fault函数被调用时,关闭跟踪功能。你还可以设置触发次数,例如:
这表示当do_trap函数被调用时,最多关闭跟踪功能 3 次。通过这种灵活的触发机制,我们可以根据实际需求更精准地控制 ftrace 的跟踪行为,提高性能分析的效率和准确性。
Part6.Ftrace的应用场景
6.1性能优化方面
在系统性能优化工作中,Ftrace 是一个得力的助手。例如,当开发人员想要优化某个软件系统的性能时,可利用 Ftrace 来找出系统中的性能瓶颈所在。
假设开发一款大型的网络服务应用,在高并发场景下响应时间较长,怀疑是某些核心模块的函数执行效率问题。这时就可以使用 Ftrace 的 function 追踪器,通过在 /sys/kernel/debug/tracing 目录下操作,将 function 写入 current_tracer 文件启用该追踪器。如果只想关注特定模块(比如网络通信模块)里涉及的函数,还能通过 set_ftrace_filter 文件来指定,像 echo module:network_communication* > set_ftrace_filter 这样的命令(假设网络通信模块相关函数命名有特定前缀),就可以筛选出对应函数进行跟踪。
然后开启追踪功能,让系统在高并发场景下运行一段时间后,查看 trace 文件或者实时通过 trace_pipe 文件来获取跟踪信息。从这些信息中,可以清晰看到每个被跟踪函数的调用时间戳、所在 CPU 等情况,进而对比分析出哪些函数的执行耗时较长。比如发现 handle_network_request 函数每次执行时间都远超预期,那么开发人员就可以针对这个函数进行代码优化,比如检查算法复杂度是否过高、是否存在频繁的资源申请释放等情况,通过优化这个函数来提升整个网络服务应用在高并发场景下的性能表现。
6.2故障排查方面
在系统出现故障,尤其是内核相关故障时,Ftrace 能发挥重要作用。比如系统突然崩溃,开发人员需要弄清楚崩溃前的函数调用情况来定位问题根源。
Ftrace 可以记录崩溃前的函数调用栈,为开发人员提供崩溃时的上下文信息。例如,当系统出现内核崩溃,怀疑是某个驱动模块在执行过程中出现了异常导致的。通过之前配置好的 Ftrace(确保已经挂载好相关文件系统并且设置好了合适的追踪器等,如使用 function_graph 追踪器来详细查看函数调用关系和执行流程),在系统下次复现崩溃问题前开启追踪功能,等崩溃发生后,查看记录下来的跟踪数据。
从 trace 文件中,能够看到在崩溃前各个函数是如何依次被调用的,哪个函数可能是最后执行的,或者有没有出现反复调用某个函数却无法返回等异常情况。像是看到 driver_init_function 函数调用后,紧接着就出现了一系列系统报错并最终崩溃,那开发人员就可以重点排查这个驱动初始化函数内部的代码逻辑,检查是否存在内存越界访问、空指针引用等常见的导致内核崩溃的问题,大大提高定位内核故障问题的效率,帮助更快地修复系统故障。
6.3内核开发方面
在内核开发过程中,Ftrace 的应用十分广泛且重要。
比如开发一个新的内核模块,需要验证函数调用的正确性。可以启用 Ftrace 的 function 追踪器,在模块加载和运行过程中,跟踪相关函数的调用情况。查看 trace 文件里记录的函数被调用的顺序、时间以及对应的参数情况(如果有相关记录的话),来确认是否和预期的函数调用逻辑一致。若开发的是一个和系统调用相关的内核功能,想要了解其执行过程中涉及的系统调用细节,利用 Ftrace 的系统调用跟踪功能,就能清晰看到具体触发了哪些系统调用,每个系统调用的传入参数以及返回结果等情况,方便判断是否符合设计预期,有没有出现不该出现的系统调用或者参数传递错误等问题。
再举例来说,在对内核中某个复杂的任务调度模块进行开发优化时,通过 Ftrace 的相关调度追踪器(像 sched_switch 追踪器等),可以观察到不同进程在调度过程中的切换情况、各个进程等待调度的时间等信息,基于这些信息来优化任务调度算法,确保内核能高效合理地进行任务调度,使得系统整体运行更加流畅稳定,由此可见 Ftrace 对于内核开发工作的重要支撑作用。
6.4Ftrace 使用的注意事项
⑴性能影响在使用 Ftrace 时,需要留意它可能对系统性能产生的影响。由于 Ftrace 的工作机制是对内核函数进行跟踪记录相关信息,尤其是当开启它去跟踪大量函数时,这种数据收集和记录的操作会占用一定的系统资源,比如会消耗 CPU 的运算能力以及占用内存空间来存储跟踪数据等。
例如,在一个高负载运行且本身对性能要求极为苛刻的服务器环境中,如果不加选择地启用 Ftrace 去跟踪众多函数,可能会导致系统响应速度变慢,影响正常业务的开展。所以,建议大家仅在确实有必要进行内核相关分析、调试或者性能排查等情况下才启用 Ftrace,避免因不必要的跟踪给系统性能带来不良影响。
⑵安全问题安全方面至关重要,对于 Ftrace 而言,要确保只有获得授权的用户能够访问 Ftrace 相关文件。因为 Ftrace 涉及到内核层面的信息跟踪,如果权限把控不当,恶意用户有可能通过获取这些跟踪文件中的数据,分析出系统内核的运行逻辑、函数调用关系等关键信息,进而找到系统潜在的漏洞或者实施其他攻击行为。
比如,在一个企业内部的多用户服务器环境中,若没有对 Ftrace 文件设置合理的访问权限,可能会出现普通用户甚至外部非法用户获取到敏感的内核跟踪数据,这无疑会给整个系统带来严重的安全隐患。所以,在使用过程中,一定要严格配置好权限,保障使用的安全性。
⑶数据存储管理Ftrace 在运行过程中,跟踪数据会快速增加。这是因为它会持续记录内核函数调用等相关信息,随着时间的推移以及跟踪函数数量的增多,所占用的存储空间会越来越大。
倘若不及时进行清理,当存储空间被大量的跟踪数据占满后,不仅会影响后续 Ftrace 继续正常记录数据。
Part7.Ftrace应用案例
7.1性能优化
假设我们正在开发一个文件系统相关的内核模块,近期发现系统在进行大量文件读写操作时,性能出现了明显的下降。为了找出性能瓶颈,我们决定使用 ftrace 来进行深入分析。
首先,我们需要确保 ftrace 已经正确配置并启用。通过前面介绍的方法,挂载 debugfs 文件系统,并进入 /sys/kernel/debug/tracing 目录。
接下来,我们使用 Function graph tracer 来跟踪文件系统相关函数的调用情况。因为 Function graph tracer 能够以图形化的方式展示函数调用关系和执行时间,这对于我们分析性能瓶颈非常有帮助。我们执行以下命令:
然后,我们设置只跟踪与文件系统相关的函数,这里以 “vfs_read” 和 “vfs_write” 函数为例,执行以下命令:
完成上述设置后,我们开始进行文件读写操作,模拟实际的业务场景。操作完成后,我们停止追踪,执行命令:
接着,我们查看 trace 文件,获取跟踪结果:
在 trace 文件中,我们可以看到类似以下的信息:
从这些信息中,我们可以清晰地看到函数的调用层次和每个函数的执行时间。通过分析,我们发现 “page_cache_sync_readahead” 函数的执行时间较长,进一步查看其内部调用的函数,发现 “ra_submit” 函数以及其下的一系列函数调用也占用了不少时间。经过深入研究代码逻辑,我们发现 “ra_submit” 函数在某些情况下会进行不必要的磁盘 I/O 操作,导致性能下降。
针对这个问题,我们对代码进行了优化,减少了不必要的磁盘 I/O 操作。再次使用 ftrace 进行跟踪测试,发现 “vfs_read” 和 “vfs_write” 函数的执行时间明显缩短,系统的文件读写性能得到了显著提升。
7.2故障排查
某一天,运维人员发现生产系统出现了响应延迟的问题,用户反馈在访问系统时,页面加载速度明显变慢,一些操作甚至需要等待很长时间才能完成。为了找出问题的根源,我们决定使用 ftrace 来进行故障排查。
首先,我们怀疑是中断相关的问题导致了系统响应延迟,因为当中断被禁止时,系统无法及时响应外部事件,可能会导致响应延迟。所以我们使用 Irqsoff tracer 来跟踪中断禁止的情况。进入 /sys/kernel/debug/tracing 目录,执行以下命令:
然后,我们等待系统响应延迟问题再次出现,在问题出现期间,ftrace 会记录下中断禁止的相关信息。问题出现后,我们停止追踪,执行命令:
接着,查看 trace 文件,获取跟踪结果:
在 trace 文件中,我们看到了类似以下的信息:
从这些信息中,我们可以看到中断禁止的最长延迟时间为 12345 微秒,并且记录了导致中断禁止的函数调用栈。通过分析函数调用栈,我们发现 “some_function_3” 函数在执行过程中禁止了中断,并且禁止时间较长,很可能是这个函数导致了系统响应延迟。
进一步查看 “some_function_3” 函数的代码,发现该函数在进行一些复杂的数据处理时,为了保证数据的一致性,错误地禁止了中断,而且处理过程中存在一些低效的算法,导致执行时间过长。我们对该函数进行了优化,将数据处理过程中的中断禁止时间尽量缩短,并优化了算法,提高了执行效率。
经过优化后,再次观察系统运行情况,响应延迟问题得到了有效解决,用户反馈系统恢复正常。通过这个案例,我们可以看到 ftrace 在故障排查中的强大作用,它能够帮助我们快速定位问题的根源,为解决系统故障提供有力的支持。
Part8.ftrace 与其他性能分析工具对比
在 Linux 性能分析的工具库中,ftrace 并非孤立存在,它与其他工具如 perf、SystemTap、LTTng 等共同构成了一个全面的性能分析生态系统,各自在不同的场景中发挥着独特的作用。
8.1 ftrace 与perf对比
perf 是 Linux 内核提供的另一个强大的性能分析工具,它与 ftrace 既有相似之处,也有明显的区别。
从功能上看,perf 更侧重于性能统计和事件采样,它能够收集 CPU 性能计数器、硬件性能事件等数据,帮助用户分析系统的性能瓶颈,比如找出 CPU 使用率高的函数、分析缓存命中率等。而 ftrace 则专注于函数调用跟踪和内核事件跟踪,能够详细记录内核函数的调用顺序、执行时间,以及进程的调度情况等信息 。例如,当我们想要了解某个应用程序在 CPU 上的运行效率,分析其指令执行次数、缓存未命中次数等性能指标时,perf 是一个很好的选择;而当我们需要深入探究内核中函数之间的调用关系,以及函数的执行流程时,ftrace 则能提供更详细的信息。
在使用方式上,perf 通过命令行工具进行操作,支持多种命令选项和参数组合,以满足不同的分析需求。它的输出结果通常是经过统计和汇总的数据,需要一定的分析能力才能从中提取有价值的信息。而 ftrace 主要通过tracefs文件系统与用户交互,用户通过修改/sys/kernel/debug/tracing目录下的文件来配置和启动跟踪,操作相对直观简单。ftrace 的输出结果是详细的跟踪日志,记录了系统运行时的各种事件,用户可以直接查看这些日志来了解系统的运行情况。
8.2 ftrace 与 SystemTap 对比
SystemTap 是一个动态跟踪工具,它允许用户使用脚本语言编写复杂的跟踪脚本,实现对内核和用户空间代码的深度分析。与 ftrace 相比,SystemTap 的优势在于其强大的脚本功能和灵活的自定义能力。用户可以通过编写 SystemTap 脚本,在系统运行时动态地插入探测点,收集各种系统状态信息,并进行复杂的数据分析和处理。例如,使用 SystemTap 可以编写一个脚本,实时监测系统中所有进程的内存使用情况,并在内存使用率超过一定阈值时发出警报 。
然而,SystemTap 的复杂性也带来了一些挑战。由于其脚本语言相对复杂,学习成本较高,对于初学者来说上手难度较大。而且,SystemTap 的脚本在运行时需要动态加载内核模块,这可能会对系统的稳定性产生一定的影响,在一些对稳定性要求极高的生产环境中,使用 SystemTap 需要谨慎考虑。相比之下,ftrace 设计轻量且功能直接,它不需要额外加载内核模块,对系统的影响较小,具有更好的稳定性和可靠性 。
8.3 ftrace与LTTng对比
LTTng 是一个高性能的事件跟踪框架,它提供了高效的二进制接口和独立的缓冲设计,适合进行深入的系统级跟踪和分析。LTTng 支持多种类型的事件跟踪,包括内核事件、用户空间事件等,并且能够在高负载的情况下保持较低的性能开销 。
在性能方面,LTTng 经过优化,能够在不显著影响系统性能的前提下,收集大量的跟踪数据,这使得它在一些对性能要求苛刻的场景中表现出色。而 ftrace 虽然也具有较低的系统开销,但在处理大规模数据收集时,可能不如 LTTng 高效。在数据存储和分析方面,LTTng 采用二进制格式存储跟踪数据,这种格式占用空间小,便于快速存储和传输,但也需要专门的工具来解析和分析数据。ftrace 则以文本格式存储跟踪数据,数据可读性强,用户可以直接使用文本编辑器查看和分析数据,但文本格式的数据占用空间相对较大,在处理大量数据时可能会面临存储和传输的挑战。
8.4工具选择建议
在实际的性能分析工作中,选择合适的工具至关重要。如果您只是想简单了解系统的性能概况,分析 CPU、内存等资源的使用情况,那么 top、vmstat 等基本的性能分析工具就可以满足需求;如果您需要深入分析系统的性能瓶颈,找出热点函数和性能关键路径,perf 是一个不错的选择;当您关注内核函数的调用流程、进程的调度情况,以及需要对内核行为进行详细的跟踪和调试时,ftrace 则是首选工具;如果您需要进行复杂的自定义分析,编写脚本实现特定的跟踪需求,SystemTap 可以提供强大的支持;而对于那些对性能要求极高,需要在高负载环境下进行系统级跟踪和分析的场景,LTTng 则更具优势 。
在很多情况下,单一的工具可能无法满足所有的分析需求,我们可以结合使用多种工具,充分发挥它们各自的优势。例如,在分析一个复杂的性能问题时,可以先使用 perf 进行性能统计和采样,找出可能存在问题的热点区域,然后使用 ftrace 对这些热点区域的内核函数调用进行详细跟踪,进一步分析问题的根源;还可以使用 SystemTap 编写脚本来收集更多的上下文信息,或者使用 LTTng 进行更深入的系统级跟踪,以全面了解系统的运行状态,最终找到解决性能问题的有效方案。