在 MySQL 的广袤世界中,有一个至关重要的存在,它宛如数据库运行轨迹的忠实记录者,默默见证着每一次数据的变更与操作,它就是 binlog。Binlog 如同一个神秘而强大的宝库,承载着数据库操作的关键信息,为数据的恢复、复制以及系统的稳定性提供着坚实的支撑。当我们深入探索 MySQL 的奥秘时,binlog 无疑是其中闪耀着独特光芒的关键一环。

1. bin log是什么?作用是什么呢?
bin log实际上是一个物理日志,当我们对某个数据页进行修改操作时我们就会将这个操作写到bin log中,当我们数据库需要进行主备、主从复制等操作时,都可以基于bin log保证数据一致性。
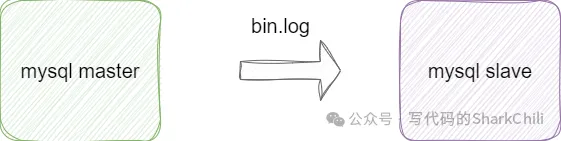
2. bin log缓冲区
bin log缓冲区和我们的redo log和undo log缓冲区有所不同,redo log和undo log缓存都在存储引擎的共享缓冲区缓冲区buffer pool中,而bin log则是为每个工作线程独立分配一个内存作为bin log缓冲区:
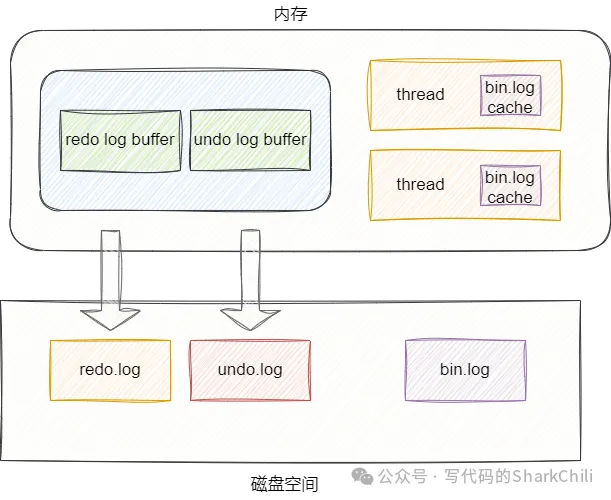
bin log之所以是在每个线程中,是为保证不同存储引擎的兼容性,bin log是innodb独有的,如果将bin log放到共享缓冲区时很可能导致兼容性问题,将bin log缓冲区设置为每个线程独享也保证了事务并发的安全性。
3. bin.log对应的三种记录格式
(1) row:这种格式主要用于保证数据实时性的,例如我们执行下面这段SQL
复制
update table set time=now() where id=1;1.
如果我们将其存到bin log之后很长一段时间才提交事务,那么时间就会有所延迟,所以MySQL为了保证数据实时性,就会将写入bin log中的SQL用row格式,如下图所示,可以看到row格式的SQL语句时间是当前时间的具体值,并且where条件写死了当前条件列,确保数据实时一致性:
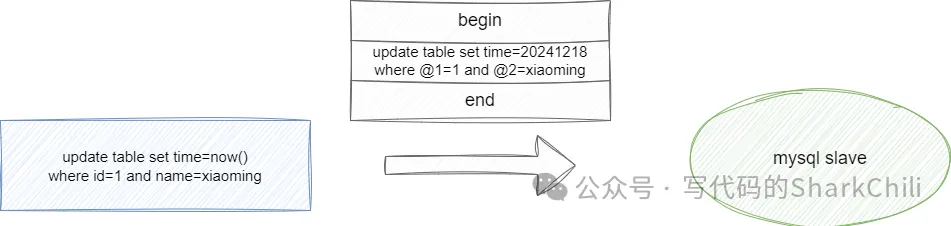
当然这样做的缺点也很明显,如果涉及大批量操作,那么针对每条数据对应的都会生成对应的row语句,那么对于内存的占用就很高,进行恢复和同步时的IO和SQL执行时间也是非常不友好的。
(2) stament:这种同步策略即执行的SQL是什么,对应传输过去的时对应的语句就是什么样的,这就会导致我们上文所说的一致性问题:
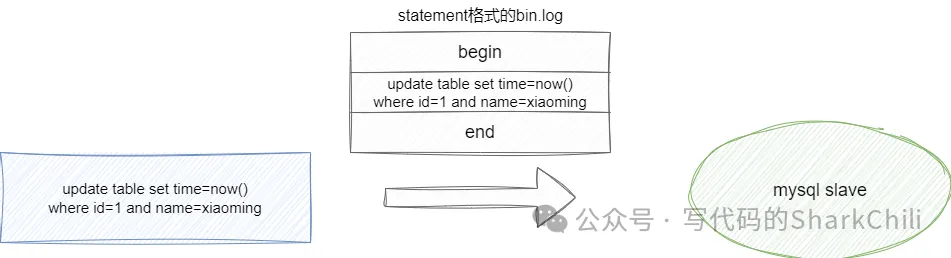
(3) mixed:这种格式就是为了上述两种方案的混合体,如果操作可能出现数据不一致问题则用row格式,反之使用stament格式。
4. bin log文件日志格式
我们可以通过下面这条SQL语句看到我们本地的bin log文件:
输出结果如下所示,可以看到bin log的格式基本都是mysql-bin.0000xxx:
复制
mysql-bin.001606 440052 No
mysql-bin.001607 111520 No1.2.
5. bin log是如何完成写入
当我们开始事务时,将修改写入bin log cache中,一旦事务提交,就会将bin log通过write写入到文件系统缓存的page cache中,然后根据我们配置的刷盘参数将cache内容调用操作系统内核方法fsync将结果写入到bin log 物理文件中:
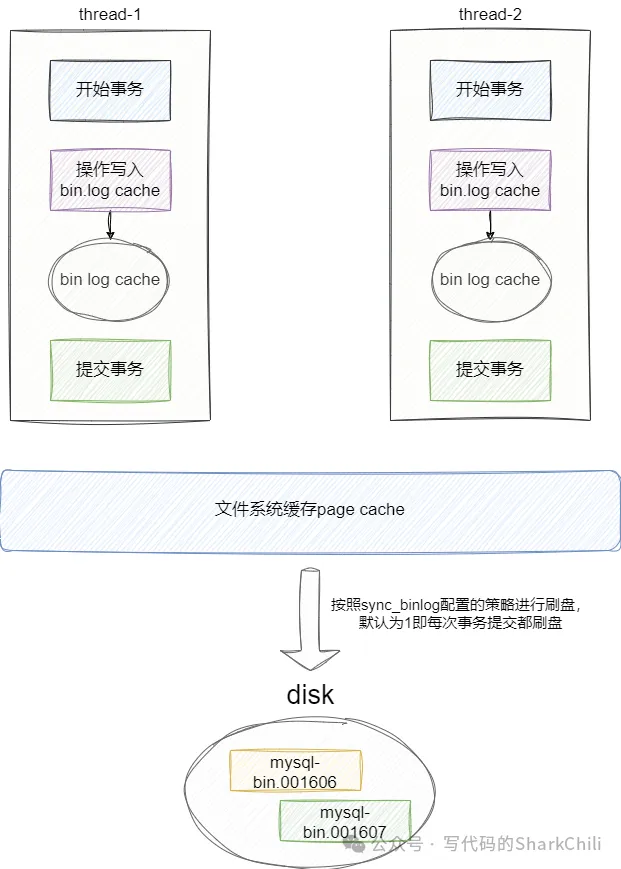
而调用系统函数fsync的实际是根据MySQL系统参数决定的,这个系统变量查询SQL如下:
复制
SHOW VARIABLES LIKE sync_binlog;1.
而sync_binlog值分别三种:
当配置为了0时,每次事务提交都只会write,fsync调用时机是由系统决定的。当配置设置为1时,每次事务提交都会调用fsync。当配置为N,代表提交了N个事务之后就会将page cache中的数据通过fsync进行刷盘。6. bin log和redo log的区别
这个问题我们可以从以下几个场景来表述一下:
从使用场景来说:bin log常用于数据灾备或数据同步到其他异构程序中的场景。redo log常用于故障恢复保证数据持久性。从数据内容来说:redo log存储的物理日志,即修改的数据内容,对应的redo block结构体针对各种偏移量和修改涉及的页都有及其复杂的涉及,这里就不多做赘述。 而bin log则是记录可以是statment语句也可以是原生修改的row,具体可以通过查看binlog_format知晓。生成范围:bin log是MySQL server生成的事务日志,任何存储引擎都可以使用redo log只有innodb这个存储引擎支持。7. (实践)基于flink cdc同步数据
接下来我们就基于spring boot演示一下如何基于flink cdc订阅bin.log完成db库中的tb_1和tb_2的数据订阅和同步:
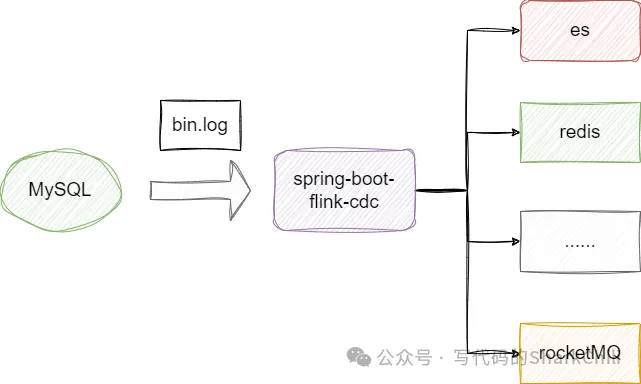
之所以笔者使用flink cdc而不是canel大体有以下几个原因:
flink cdc支持全量和增量同步以及断点续传等功能,尤其是断点续传这一点对于需要保证异构数据库的数据一致性是非常好的。性能表现更出色,按照阿里云的说法:
我们将全增量一体化框架与 Debezium 1.6 版本做 简单的 TPC-DS 读取测试对比,customer 单表数据量 6500 万,在 Flink CDC 用 8 个并发的情况下,吞吐提升了 6.8 倍,耗时仅 13 分钟,得益于并发读取的支持,如果用户需要更快的读取速度,用户可以增加并发实现。

话不说我们给出基础的集成步骤,首先是引入flink cdc和MySQL的依赖,这里笔者为了文章的简练只给出的flink cdc相关的pom依赖:
复制
<properties>
<flink.version>1.13.6</flink.version>
</properties>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!--mysql -cdc-->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.0</version>
</dependency>1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.
然后我们在yml或者properties文件中给出MySQL配置即可,然后我们声明一个CdcInfo记录从bin.log中同步的数据:
复制
@Data
publicclass CdcInfo {
/**
* 变更前数据
*/
private JSONObject beforeData;
/**
* 变更后数据
*/
private JSONObject afterData;
private String operation;
/**
* binlog 文件名
*/
private String binLogName;
/**
* binlog当前读取点位
*/
private Integer filePos;
/**
* 数据库名
*/
private String dbName;
/**
* 表名
*/
private String tbName;
/**
* 变更时间
*/
private Long changeTime;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.
然后我们编写一个关于bin.log通知事件的监听,针对flink cdc配置笔者都基于CommandLineRunner 这个拓展点完成配置,这里面涉及众多的flink cdc配置参数,可以看到笔者的程序同步模式配置的是initial即启动后会进行全量同步再进行增量同步,同时通过表达式db.tb_[1-2]+指明仅仅处理tb_1和tb_2表的数据更新变化。
复制
@Component
publicclass MysqlCdcEventListener implements CommandLineRunner {
//数据接收器用于应用架构更改和将更改数据写入外部系统
privatefinal CdcSink cdcSink;
public MysqlCdcEventListener(CdcSink cdcSink) {
this.cdcSink = cdcSink;
}
@Override
public void run(String... args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(Runtime.getRuntime().availableProcessors());
DebeziumSourceFunction<CdcInfo> debeziumSource = buildDebeziumSource();
DataStream<CdcInfo> streamSource = env
.addSource(debeziumSource, "mysql-source")
.setParallelism(1);
//将流数据交给
streamSource.addSink(cdcSink);
env.execute("mysql-stream-cdc");
}
/**
* 构造变更数据源
*/
private DebeziumSourceFunction<CdcInfo> buildDebeziumSource() {
Properties debeziumProperties = new Properties();
//设置快照为无锁
debeziumProperties.put("snapshot.locking.mode", "none");
return MySqlSource.<CdcInfo>builder()
.hostname("xxxx")
.port(3306)
.databaseList("db")
//监听db库中的[1-2]表
.tableList("db.tb_[1-2]+")
.username("xxxx")
.password("xxxx")
//设置为 initial:在第一次启动时对受监视的数据库表执行初始快照,并继续读取最新的 binlog
.startupOptions(StartupOptions.initial())
//设置序列化配置
.deserializer(new MysqlDeserialization())
.serverTimeZone("GMT+8")
.debeziumProperties(debeziumProperties)
.build();
}
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.
上文代码示例中给出一个涉及反序列化生产CdcInfo的操作,笔者指明了MysqlDeserialization 这里也给出对应的源码示例:
复制
public class MysqlDeserialization implements DebeziumDeserializationSchema<CdcInfo> {
publicstaticfinal String TS_MS = "ts_ms";
publicstaticfinal String BIN_FILE = "file";
publicstaticfinal String POS = "pos";
publicstaticfinal String CREATE = "CREATE";
publicstaticfinal String BEFORE = "before";
publicstaticfinal String AFTER = "after";
publicstaticfinal String SOURCE = "source";
publicstaticfinal String UPDATE = "UPDATE";
@Override
public void deserialize(SourceRecord sourceRecord, Collector<CdcInfo> collector) {
//获取bin.log订阅到的信息
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
String database = fields[1];
String tableName = fields[2];
Struct struct = (Struct) sourceRecord.value();
final Struct source = struct.getStruct(SOURCE);
CdcInfo tbCdcInfo = new CdcInfo();
//获取前后变化数据
tbCdcInfo.setBeforeData(convert2JsonObj(struct, BEFORE));
tbCdcInfo.setAfterData(convert2JsonObj(struct, AFTER));
//5.获取操作类型 CREATE UPDATE DELETE
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
String type = operation.toString().toUpperCase();
tbCdcInfo.setOperation(type);
tbCdcInfo.setBinLogName(Optional.ofNullable(source.get(BIN_FILE)).map(Object::toString).orElse(""));
tbCdcInfo.setFilePos(Optional.ofNullable(source.get(POS)).map(x -> Integer.parseInt(x.toString())).orElse(0));
tbCdcInfo.setDbName(database);
tbCdcInfo.setTbName(tableName);
tbCdcInfo.setChangeTime(Optional.ofNullable(struct.get(TS_MS)).map(x -> Long.parseLong(x.toString())).orElseGet(System::currentTimeMillis));
//7.输出数据
collector.collect(tbCdcInfo);
}
/**
* 从原始数据获取出变更之前或之后的数据
*/
private JSONObject convert2JsonObj(Struct value, String fieldElement) {
Struct element = value.getStruct(fieldElement);
JSONObject jsonObject = new JSONObject();
if (element != null) {
Schema afterSchema = element.schema();
List<Field> fieldList = afterSchema.fields();
for (Field field : fieldList) {
Object afterValue = element.get(field);
jsonObject.put(field.name(), afterValue);
}
}
return jsonObject;
}
@Override
public TypeInformation<CdcInfo> getProducedType() {
return TypeInformation.of(CdcInfo.class);
}
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.
此时我们启动程序后针对数据表进行修改操作就会收到数据消息的订阅了:
复制
订阅到的数据:CdcInfo(beforeData={"id":1,"name":"xiaoming"}, afterData={"id":1,"name":"xiaoming1"}, operation=UPDATE, binLogName=binlog.000156, filePos=1256, dbName=db, tbName=tb_2, changeTime=1734622269654)1.
小结
MySQL Binlog(二进制日志)作为 MySQL 数据库中至关重要的组成部分,蕴含着众多奥秘且具备丰富多样的应用场景。
从原理层面来看,Binlog 以二进制的形式记录了数据库中数据变更的相关事件,如 INSERT、UPDATE、DELETE 等操作。它采用顺序追加的方式写入,这种特性不仅保证了日志记录的完整性和连续性,还为后续的恢复和复制提供了坚实基础。不同的日志格式(STATEMENT、ROW、MIXED)各有优劣,开发人员和数据库管理员可以根据实际需求进行灵活选择,以平衡数据一致性、性能和存储空间等多方面因素。 在应用领域,Binlog 展现出了巨大的价值。在数据恢复场景中,基于全量备份结合 Binlog 可以实现精准的时间点恢复(PITR),确保在面对数据丢失或损坏时,能够将数据库还原到指定的历史时刻,最大程度减少数据损失。在主从复制方面,主库将 Binlog 发送给从库,从库通过重放这些日志来同步数据,从而实现数据的多副本存储和读写分离,提升系统的可用性和性能。此外,Binlog 还在数据迁移、数据审计以及实时数据处理等领域发挥着重要作用。例如,通过解析 Binlog 可以获取数据的实时变化,将这些变化推送至其他系统进行进一步处理,实现系统间的数据同步和业务逻辑的联动。
然而,在使用 Binlog 的过程中,也需要关注一些问题。例如,Binlog 的记录会占用一定的磁盘空间,需要合理规划存储空间和清理策略;同时,在进行主从复制时,Binlog 的传输和重放可能会受到网络延迟、服务器性能等因素的影响,导致数据同步延迟或出现错误,这就需要建立有效的监控和故障处理机制。
总之,深入理解 MySQL Binlog 的奥秘,并合理运用其各项特性,对于保障数据库的高可用性、数据一致性以及实现多样化的业务需求都具有重要意义。无论是数据库管理员进行日常运维管理,还是开发人员设计架构和开发应用程序,都应该充分认识到 Binlog 的价值,并谨慎处理与之相关的各种问题。