在 Linux 内核的复杂生态中,内存管理堪称系统稳定运行的 “心脏”。当我们在服务器上部署高并发应用,或是在嵌入式设备上追求极致性能时,内存分配的效率与碎片控制往往决定了系统的最终表现。作为 Linux 内核内存管理的核心组件,伙伴算法(Buddy Algorithm)如同一位精密的 “内存管家”,通过巧妙的伙伴关系与动态拆分合并机制,在保证分配效率的同时,将内存碎片控制在最低水平。
当我们深入探索 Linux 内核的奥秘时,伙伴算法就像是一位默默无闻却又无比可靠的守护者,精心地调配着内存资源,确保每一个程序都能在恰当的时机获得所需的内存空间,同时又能最大限度地减少内存碎片,提高内存的利用率。那么,究竟什么是伙伴算法?它是如何在复杂的内核环境中发挥关键作用的呢?让我们一同开启这场关于 Linux 内核内存伙伴算法的精彩之旅。
一、伙伴算法简介
在Linux系统中,内存的分配与回收速率直接影响系统的存取效率。当内核频繁请求和释放不同大小的一组连续页框时,会导致许多外部空闲碎片,造成空间的浪费。使用伙伴算法可以有效地缓解该问题。伙伴关系机制是操作系统中的一种动态存储管理算法。在进行内存分配时,该算法通过不断平分较大的空闲内存块来获得较小的空闲内存块,直到获得所需要的内存块;在进行内存回收时,该算法尽可能地合并空闲块。
内存管理是应用程序通过硬件和软件协作访问内存的一种方法,当进程请求内存使用时,它给进程分配可用的内存;当进程释放内存时,回收相应的内存,同时负责跟踪系统中内存的使用状态。伙伴算法是一种经典的内存管理算法,在 Linux 操作系统中有着广泛应用。其作用是减少存储空间中的空洞、减少碎片、增加利用率。伙伴算法将所有空闲页框分组为 11 个块链表,每块链表分别包含大小为 1、2、4、8、16、32、64、128、256、512 和 1024 个连续页框的页框块。例如,大小为 16 个页框的块,其起始地址是 16 * 2^12 的倍数。
当有内存分配请求时,伙伴算法先在与请求大小相同的块链表中查找空闲块。如果没有找到,就去更大的块链表中查找。例如,假设要请求一个 256 个页框的块,算法先在 256 个页框的链表中检查是否有空闲块。如果没有这样的块,算法会查找下一个更大的页块,也就是在 512 个页框的链表中找一个空闲块。
如果存在这样的块,内核就把 512 的页框分成两等分,一半用作满足需求,另一半则插入到 256 个页框的链表中。如果在 512 个页框的块链表中也没找到空闲块,就继续找更大的块 ——1024 个页框的块。如果这样的块存在,内核就把 1024 个页框块的 256 个页框用作请求,然后剩余的 768 个页框中拿 512 个插入到 512 个页框的链表中,再把最后的 256 个插入到 256 个页框的链表中。如果 1024 个页框的链表还是空的,算法就放弃并发出错误信号。
在释放内存时,内核试图把大小为 b 的一对空闲伙伴块合并为一个大小为 2b 的单独块。满足以下条件的两个块称为伙伴:两个块具有相同的大小,记作 b;它们的物理地址是连续的;第一块的第一个页框的物理地址是 2 * b * 2^12 的倍数。该算法是迭代的,如果它成功合并所释放的块,它会试图合并 2b 的块,以再次试图形成更大的块。
二、伙伴算法核心原理
2.1什么是 “伙伴关系”?
伙伴算法的核心在于 “伙伴关系” ,这是一种独特的内存块关联方式。假设我们有一块完整的蛋糕,它代表一大块连续的内存。当程序需要不同大小的内存时,就如同要把蛋糕切成不同大小的块。如果把这块 8 页的 “蛋糕” 平均切成两半,每半就是 4 页,这两个 4 页的小块就形成了特殊的 “伙伴” 关系。
伙伴关系可不是随意确定的,它有严格的条件:首先,大小必须相同。就像天平两端,只有重量相等才能平衡,内存块也一样,必须是相同大小的才能成为伙伴,比如 4 页的和 4 页的,8 页的和 8 页的。其次,地址得连续。想象一排房子,相邻的两间房才是紧密相连的,内存块的物理地址也需无缝衔接。最后,它们必须是从同一个大块内存分裂而来,就像同一对父母生出的双胞胎,有着紧密的 “血缘关系”。
这种伙伴关系在内存管理中至关重要。当系统要分配内存时,如果没有刚好合适大小的空闲块,就从大的内存块中拆分。比如程序需要 4 页内存,而当前只有 8 页的空闲块,那就把 8 页块分成两个 4 页块,一个给程序,另一个先留着备用。回收内存时,若发现某个内存块的伙伴也处于空闲状态,就像找到了失散的双胞胎,把它们合并回更大的块,如此循环往复,确保内存始终以 2 的幂次(1/2/4/8…1024 页)的块存在,从根本上减少外部碎片。
2.2数据结构:给内存块 “分门别类”
为了高效管理这些不同大小的内存块,Linux 内核采用了精心设计的数据结构。内核使用一个数组来管理不同大小的空闲块,数组下标 order 表示块大小为 \(2^{\text{order}}\) 页 。简单来说,order 为 0 时,对应 1 页;order 为 1 时,对应 2 页,以此类推,当 order 为 10 时,对应 1024 页,也就是 4MB 。这就像一个有序的书架,每个格子对应一种特定大小的内存块。
每个 order 对应的元素包含两个关键部分:一是空闲链表,它像一条无形的线,把同大小的空闲块用双向链表的形式链接起来,方便快速查找和操作;二是数量统计,记录着当前这种大小的空闲块总数,让系统随时清楚每种规格的 “库存”。
除了对内存块大小的管理,内核还根据内存页的特性,将其分为三类迁移类型 :不可移动页,这类就像是内核的 “定海神针”,存放着内核核心数据,在内存中有固定位置,不能轻易移动;可回收页,如同可循环利用的资源,比如文件映射数据,即使被删除也能从其他地方重新生成;可移动页,主要用于用户空间内存,就像自由迁徙的候鸟,可以自由搬迁,因为用户空间通过页表映射,内存位置变化时页表相应更新,应用程序也不会察觉。
通过 cat /proc/pagetypeinfo 命令,我们能直观看到各迁移类型的内存分布情况,就像查看一份详细的资源清单。这有助于系统在分配内存时,根据不同类型的需求和特性,合理安排,避免因错误分配导致 “牵一发而动全身” 的风险,保障系统稳定高效运行。
2.3伙伴算法管理结构
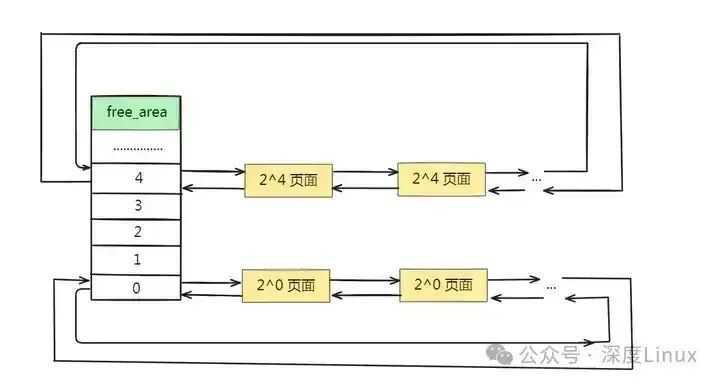
伙伴算法把物理内存分为11个组,第0、1、...10组分别包含2^0、2^1、...2^10个连续物理页面的内存。在zone结构中,有一个free_area数组,数组的每一个成员代表一个组,相关定义如下:
复制
#define MAX_ORDER 11
struct zone {
...
struct free_area free_area[MAX_ORDER];
...
}
struct free_area {
struct list_head free_list;
/*该组类别块空闲的个数*/
unsigned long nr_free;
};1.2.3.4.5.6.7.8.9.10.11.
由此可知伙伴算法管理结构如下图所示:
 图片
图片
Linux 内核对各个 zone 都有一个 buddy system,通过 free_area 数组来管理空闲块。分配和回收内存时,页面分配代码使用 free_area 数组来寻找和释放页面。在 Linux 中,free_area 数组是一个关键的数据结构,它用于管理不同大小的内存块。数组中的每个元素对应一种大小的内存块,从大小为 1 个页框的块到大小为 1024 个页框的块。每个元素都是一个 struct free_area 结构体,包含一个双向链表 free_list 和一个表示空闲块数量的变量 nr_free。
当进行内存分配时,页面分配代码会首先检查与请求大小相同的块链表。例如,如果请求一个大小为特定值(假设为 N)的内存块,算法会先在与 N 大小相同的块链表中查找空闲块。如果没有找到合适的块,就会去更大的块链表中继续查找。这个过程类似于我们之前讨论过的伙伴算法的分配过程。如果在合适的块链表中找到了空闲块,就会从该链表中取出一个块,并进行相应的处理,例如更新链表和空闲块数量等。
当进行内存回收时,页面分配代码同样会使用 free_area 数组。当一个内存块被释放时,算法会将该块插入到相应大小的块链表中。然后,算法会检查与该内存块相邻的内存是否是同样大小并且同样处于空闲的状态。如果是,就将这两块内存合并,并继续检查是否可以与更大的空闲块合并,这个过程与伙伴算法的释放过程一致。通过这种方式,Linux 内核的 buddy system 能够有效地管理内存,减少内存碎片,提高内存的利用率。
三、分配与回收工作流程
3.1分配流程:从 “找合适的块” 到 “拆出所需”
当内核接到内存分配请求时,伙伴算法就如同接到任务的快递分拣员,迅速而有序地开始工作。假设一个应用程序向内核请求分配 256 页内存,这在伙伴算法的 “世界” 里,就需要找到与之匹配的内存块资源。
首先,算法会在代表 256 页(order = 8 )的空闲链表中查找是否有现成的空闲块 。这就像在快递分拣站的特定区域寻找刚好合适大小的包裹格子。如果运气好,找到了空闲块,那就直接将其分配给请求者,任务轻松完成。但实际情况往往没这么简单,很多时候这个链表中并没有空闲块,这时算法就需要扩大搜索范围。
算法会向上查找更大的内存块链表,比如 order = 9 (512 页)、order = 10 (1024 页) 。当发现一个 1024 页的空闲块时,就像找到了一个大尺寸的包裹格子,但它比实际需求大。这时算法会对这个 1024 页的块进行拆分,将其一分为二,变成两个 512 页的块,这两个 512 页的块就是一对伙伴 。然后,再将其中一个 512 页的块继续拆分,又得到两个 256 页的块。最终,将其中一个 256 页的块分配给请求的应用程序,而剩余的 768 页内存,会分别将 512 页和 256 页的块加入到对应的空闲链表中,等待下一次被分配。
为了进一步提升分配效率,对于单个页面(order = 0 )的分配,Linux 内核采用了特殊的优化策略,即直接从 Per-CPU 缓存分配 。这就好比每个快递员都有自己的小包裹存放区,对于小包裹(单个页面),直接从自己的小区域中拿取,无需去大的分拣站(全局内存链表),避免了全局锁竞争,大大提升了在高并发场景下的内存分配效率,让系统能够快速响应大量的内存请求。
3.2回收流程:从 “标记空闲” 到 “递归合并”
内存回收是伙伴算法的另一个关键环节,它就像一个反向的拼图过程,将零散的空闲内存块重新拼凑成大块,以提高内存的利用率。当一个进程释放 256 页内存块时,伙伴算法会立即介入,检查这块内存的伙伴块状态 。
伙伴块就像是失散的 “孪生兄弟”,有着相同的大小、连续的地址,并且是从同一个大块内存分裂而来。如果发现伙伴块也处于空闲状态,算法就会将这两个 256 页的伙伴块合并成一个 512 页的块 ,就像将两个小拼图碎片拼成一个大的。
合并后的 512 页块并不会就此 “安定”,算法会继续检查这个 512 页块的伙伴块是否空闲。如果其伙伴也空闲,就会继续合并,将两个 512 页的块合并成一个 1024 页的块 ,如此递归下去,直到找不到空闲的伙伴块,无法再合并为止。
通过这种 “逆向拆分” 的回收机制,原本零散分布的小块空闲内存,被不断地 “拼装” 成大块连续内存 。这不仅让内存空间得到了更充分的利用,还确保了物理内存的连续性,为后续可能的大内存块分配请求提供了保障,使得系统在长时间运行过程中,始终能保持高效的内存管理能力。
3.3伙伴算法的初始化和释放
①伙伴算法初始化过程
在start_kernel->mem_init-> free_all_bootmem_node->free_all_bootmem_core-> __free_pages_bootmem-> __free_pages->__free_pages_ok->free_one_page-> __free_one_page函数中,通过对每一个页面进行释放,从而完成对伙伴算法的初始化工作。
②伴算法的具体释放过程
伙伴算法释放的思想:当释放2^order页大小内存时,查看它的伙伴是否空闲,如果空闲就将伙伴从该组链表中删除,并且将这两个空闲的伙伴内存区域合并成一个更高阶的空闲内存区域,依次这样操作下去。
_free_one_page函数分析如下:
复制
static inline void __free_one_page(struct page *page,
struct zone *zone, unsigned int order)
{
unsigned long page_idx;
int order_size = 1 << order;
int migratetype = get_pageblock_migratetype(page);
/*用PFN作为mem_map数组下标就可以索引到对应的page结构*/
page_idx = page_to_pfn(page) & ((1 << MAX_ORDER) - 1);
__mod_zone_page_state(zone, NR_FREE_PAGES, order_size);
/*这个循环主要查看当前释放块伙伴是否空闲,如果空闲则合并它们*/
while (order < MAX_ORDER-1) {
unsigned long combined_idx;
struct page *buddy;
/*找到释放块的伙伴*/
buddy = __page_find_buddy(page, page_idx, order);
/*判断释放块的伙伴是否空闲*/
if (!page_is_buddy(page, buddy, order))
break;
list_del(&buddy->lru);
zone->free_area[order].nr_free--;
rmv_page_order(buddy);
combined_idx = __find_combined_index(page_idx, order);
page = page + (combined_idx - page_idx);
page_idx = combined_idx;
order++;
}
set_page_order(page, order);
list_add(&page->lru,
&zone->free_area[order].free_list[migratetype]);
zone->free_area[order].nr_free++;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.
3.4伙伴算法的内存分配
①伙伴算法内存分配的过程
当内核收到alloc_pages系列函数的分配请求时,首先需要确定是从哪一个节点上分配,然后再确定需要从节点的哪一个zone上分配,最后再根据伙伴算法,确定从zone的哪一个free_area数组成员上分配。在内存不足的情况下,还要回收内存,如果内存还是不够,还要调度kswapd把必要的内存存储到交换分区中。内存分配模块总是试图从代价最小的节点上分配,而对zone的确定则根据alloc_pages()系列函数的gfp_mask用以下规则确定:
如果gfp_mask参数设置了__GFP_DMA位,则只能从ZONE_DMA中分配。如果gfp_mask参数设置了__GFP_HIGHMEM位,则能够从ZONE_DMA、ZONE_NORMAL、ZONE__HIGHMEM中分配。如果__GFP_DMA和__GFP_HIGHMEM都没有设置,则能够从ZONE_DMA和ZONE_NORMAL中分配。
当然,如果没有指定__GFP_DMA标志,则会尽量避免使用ZONE_DMA区的内存,只有当指定的区内存不足,而ZONE_DMA区又有充足的内存时,才会从ZONE_DMA中分配。
②伙伴算法的具体内存分配过程
举例说明:假设请求分配4个页面,根据该算法先到第2(2^2=4)个组中寻找空闲块,如果该组没有空闲块就到第3(2^3=8)个组中寻找,假设在第3个组中找到空闲块,就把其中的4个页面分配出去,剩余的4个页面放到第2个组中。如果第三个组还是没有空闲块,就到第4(2^4=16)个组中寻找,如果在该组中找到空闲块,把其中的4个页面分配出去,剩余的12个页面被分成两部分,其中的8个页面放到第3个组,另外4个页面放到第2个组...依次类推。
alloc_pages系列函数最终会调用__rmqueue函数从free_area中取出内存页面,__rmqueue函数具体分析如下:
复制
//返回申请到的内存空间首页的struct page结构指针
static struct page *__rmqueue(struct zone *zone, unsigned int order)
{
struct free_area * area;
unsigned int current_order;
struct page *page;
/*查询zone中从order到MAX_ORDER-1的各指数值对应的空闲内存区域*/
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
/*连续2^current_order页空闲内存区域的描述结构指针*/
area = zone->free_area + current_order;
/*如果该空闲内存区域为空,则继续查看2^(current_order+1)页空闲内存区域*/
if (list_empty(&area->free_list))
continue;
/*得到该空闲内存区域的首页struct page结构指针*/
page = list_entry(area->free_list.next, struct page, lru);
/*将page所指的连续2^current_order页的空闲区域从其所在的链表中删除*/
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
__mod_zone_page_state(zone, NR_FREE_PAGES, - (1UL << order));
/*
*如果分配的内存比要申请的内存大,则需要把大块剩余的那一部分
*分解并放到对应的队列中去
*/
expand(zone, page, order, current_order, area);
return page;
}
return NULL;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.
这个函数根据这个函数根据order从最合适的free_area队列中分配,如果不成功就从更大的块中找,找到一个合适的块后把它摘下来,最后需要把大块剩余的那一部分分解并放到对应的队列中去,这个工作是expand函数完成的。
四、伙伴算法优缺点解析
4.1三大核心优势
(1)能够完全避免外部碎片的产生。
伙伴算法将内存划分为不同大小的页框块,并通过特定的分配和释放规则,确保内存的分配和回收过程中不会产生外部碎片。当有内存分配请求时,算法会从合适的块链表中查找空闲块,如果没有找到合适的块,就会去更大的块链表中查找,并在必要时进行分割和分配。而在释放内存时,算法会检查相邻的内存块是否空闲,并进行合并操作,以尽可能地形成更大的连续内存块。这种方式有效地避免了外部碎片的产生,提高了内存的利用率。
(2)可以快速地分配和回收内存,因为它只需要进行简单的位运算和链表操作。
在内存分配过程中,伙伴算法首先从空闲的内存中搜索比申请的内存大的最小的内存块。通过对块链表的遍历和简单的位运算,可以快速确定合适的内存块进行分配。如果需要分割更大的内存块,也可以通过简单的计算和链表操作来实现。在内存回收过程中,同样只需要进行简单的链表操作和相邻内存块的检查,就可以进行合并操作。这种简单高效的操作方式使得伙伴算法能够快速地分配和回收内存,提高了系统的性能。
(3)架构适配性强
现代计算机系统架构日益复杂,多处理器和异构计算场景越来越常见,伙伴算法在这些复杂架构下展现出了良好的适配性,尤其是在 NUMA(非统一内存访问)架构中 。在 NUMA 架构下,系统包含多个处理器节点,每个节点都有自己的本地内存,节点间内存访问延迟不同。伙伴算法能够在每个节点上独立管理内存,根据本地内存的使用情况进行高效的分配和回收 。当一个节点的内存紧张时,它可以通过节点间的通信机制与其他节点协调,合理调配内存资源,确保整个系统在多处理器环境下的高效运行,为复杂计算场景提供了稳定的内存管理支持。
4.2算法缺点
(1)可能会造成内部碎片,因为它总是分配 2 的幂次个物理页,而实际需要的内存可能小于这个值。
Linux 内核内存伙伴算法在分配内存时,总是以 2 的幂次方大小进行分配内存块。例如,当需要一个并非 2 的幂次方大小的内存空间时,伙伴算法会分配一个大于所需大小且是 2 的幂次方的内存块,这就会导致内部碎片的产生。参考资料中提到 “伙伴系统是按 2 的幂次方大小进行分配内存块,如果所需内存大小不是 2 的幂次方,就会有部分页面浪费,有时候还很严重”,比如需要一个 257K 的内存空间,按照其算法,会分配一个 512K 的内存空间,那么就会有 255K 的内存空间浪费。
(2)可能会造成外部碎片,因为它总是合并相邻的空闲内存块,而实际需要的连续内存可能大于这个值。
伙伴算法在释放内存时会进行合并操作,但合并的要求较为严格,只有满足伙伴关系的块才能合并。这就可能导致即使系统中有一些空闲的内存块,但由于它们不满足伙伴关系,无法合并成更大的连续内存块,从而在实际需要较大连续内存时无法满足需求,产生外部碎片。一个系统中,对内存块的分配大小是随机的,一片内存中仅一个小的内存块没有释放,旁边两个大的就不能合并。
(3)拆分和合并涉及到较多的链表和位图操作,开销还是比较大的。
在伙伴算法的分配和释放过程中,需要进行大量的链表和位图操作。当进行内存分配时,如果没有找到合适大小的空闲块,就需要从更大的块链表中查找,并在必要时进行分割和分配,这涉及到对链表的遍历和修改以及位图的更新。在内存释放时,要检查相邻的内存块是否空闲,并进行合并操作,同样需要对链表和位图进行操作。这些操作虽然能够有效地管理内存,但也带来了较大的开销。
五、实战视角:如何观察与优化伙伴算法?
5.1系统状态查看
(1)/proc/buddyinfo:在 Linux 系统中,/proc/buddyinfo 是一个非常有用的文件,它为我们提供了关于伙伴算法中各内存区域(Zone)不同 order 空闲内存块数量的详细信息。通过执行 cat /proc/buddyinfo 命令,我们可以获取到如下格式的数据:
复制
Node 0, zone DMA 399 260 123 86 34 31 16 14 7 9 606
Node 0, zone Normal 1491 1005 233 23 53 28 12 25 91.2.
这里,第一列表示节点编号(Node 0 表示第一个节点,在单节点系统中通常只有一个节点),第二列是内存区域类型,如 DMA 用于直接内存访问设备,Normal 用于普通内存分配,HighMem 用于高端内存 。后面的列则依次对应不同 order 的空闲内存块数量,order 从 0 开始,每一列代表的内存块大小是 \(2^{\text{order}}\) 页 。
通过分析这些数据,我们可以清晰地判断内存碎片化程度 。如果高阶(较大 order )的空闲块数量较少,而低阶空闲块较多,说明内存碎片化严重,系统在分配大块连续内存时可能会遇到困难。比如,在一个频繁进行小内存块分配和释放的数据库服务器中,就可能出现这种情况,导致后续大内存块分配失败,影响数据库性能。
(2)vmstat/sar:vmstat 和 sar 是系统监控的常用工具,在观察伙伴算法性能时也发挥着重要作用。vmstat 可以实时展示系统的虚拟内存状态、进程活动和 CPU 使用情况 。我们可以通过 vmstat 1 10 命令(每 1 秒输出一次,共输出 10 次)查看系统状态,其中 slabs_unreclaimable 字段表示不可回收的 slab 内存,它间接反映了内存分配失败的情况 。如果这个值持续增长,或者在内存分配操作时出现频繁的分配延迟,就可能意味着内存分配遇到问题,需要进一步分析 。
sar 工具则提供了更全面的系统性能统计,包括内存、CPU、I/O 等多个方面 。通过 sar -r 命令,我们可以查看内存相关的统计信息,如内存分配失败率等 。当发现内存分配失败率较高时,我们可以考虑调整内核参数 zone_reclaim_ratio 。这个参数控制着内存回收的策略,它表示当内存不足时,从本地 Zone 回收内存的比例 。如果设置过低,可能导致内存分配失败;设置过高,则可能影响系统整体性能 。
在一个高并发的 Web 服务器环境中,如果发现 vmstat 显示的 slabs_unreclaimable 持续上升,且 sar -r 统计的内存分配失败率增加,就可以尝试适当提高 zone_reclaim_ratio 参数值,观察系统性能是否改善。
5.2内核参数调优
(1)vm.max_order:vm.max_order 是一个关键的内核参数,它控制着伙伴算法中最大分配块的大小 。默认情况下,其值为 11,对应的最大分配块为 1024 页,即 4MB 。在一些高内存场景,如大数据处理集群或高性能计算环境中,可能需要分配更大的内存块,这时可以适当调大 vm.max_order 的值 。但需要注意的是,调大这个参数会增加内存元数据的消耗 。因为随着最大分配块的增大,用于管理内存块的数据结构也会相应变大,从而占用更多内存资源 。
在调整这个参数之前,需要充分评估系统的内存使用情况和应用需求,避免因过度调大导致系统内存紧张 。比如,在一个运行深度学习模型训练任务的服务器上,由于模型参数和中间计算结果需要大量连续内存,可能需要将 vm.max_order 从默认的 11 适当调高到 12 或 13,以满足大内存块分配需求,但同时要密切关注系统内存使用情况,防止内存耗尽。
(2)迁移类型策略:通过调整迁移类型策略,可以有效减少内存碎片,提高内存利用率 。我们可以通过 echo 命令修改 /sys/devices/virtual/memory/zone*/pagesize 文件,来调整内存页的迁移类型 。优先使用可移动页迁移是一个重要原则,因为可移动页主要用于用户空间内存,其内容可以自由搬迁 。在内存回收和分配过程中,尽量将可移动页迁移到合适的位置,避免不可移动页碎片的产生 。例如,在一个多用户的云计算环境中,大量用户进程频繁进行内存分配和释放,通过优先迁移可移动页,能够确保内存始终保持较好的连续性,为后续的内存分配提供更有利的条件,提升系统整体性能和稳定性 。
六、应用场景
6.1服务器高并发:伙伴算法是 Kubernetes 稳定运行的 “幕后英雄”
在云计算和容器编排领域,Kubernetes已成为事实上的标准。在Kubernetes集群中,每个节点运行着多个容器,这些容器频繁地申请和释放内存 。伙伴算法在其中扮演着至关重要的角色,确保内存的高效分配和回收,维持整个集群的稳定性。
当大量容器同时请求内存时,伙伴算法通过快速的内存分配机制,能在短时间内为各个容器提供所需内存 。在一个繁忙的电商网站后端,Kubernetes 集群需要同时处理成千上万的用户请求,每个请求可能会触发多个容器的内存分配操作 。伙伴算法的高效性使得系统能够快速响应这些请求,避免因内存分配延迟导致的服务卡顿。
为了进一步优化内存使用,Kubernetes 结合 Cgroups(Control Groups)技术,对容器的内存使用进行精细限制 。Cgroups 可以为每个容器设置内存请求(request)和内存限制(limit) 。当一个容器的内存使用达到其请求量时,系统会优先保障其内存需求;当超过限制时,容器可能会被 OOM(Out-Of-Memory)杀手终止 。伙伴算法与 Cgroups 协同工作,确保在内存紧张的情况下,系统能合理分配内存,避免因某个容器过度占用内存而导致其他容器 “饿死”,有效防止了 “内存颠簸” 现象,保障了高并发场景下系统的稳定性。
复制
#include <iostream>
#include <vector>
#include <unordered_map>
#include <algorithm>
#include <string>
#include <cmath>
#include <memory>
// 内存块状态枚举
enum class MemoryBlockStatus {
FREE,
ALLOCATED
};
// 内存块类
class MemoryBlock {
private:
size_t size_; // 内存块大小,为2的幂
size_t address_; // 内存块起始地址
MemoryBlockStatus status_; // 内存块状态
std::string container_id_; // 分配给哪个容器
std::unique_ptr<MemoryBlock> left_child_; // 左子块
std::unique_ptr<MemoryBlock> right_child_; // 右子块
public:
// 构造函数
MemoryBlock(size_t size, size_t address, MemoryBlockStatus status = MemoryBlockStatus::FREE)
: size_(size), address_(address), status_(status), container_id_("") {}
// 检查是否为空闲块
bool is_free() const {
return status_ == MemoryBlockStatus::FREE;
}
// 分裂内存块为两个相等的子块
bool split() {
if (size_ <= 1) return false; // 不能再分裂
size_t half_size = size_ / 2;
left_child_ = std::make_unique<MemoryBlock>(half_size, address_);
right_child_ = std::make_unique<MemoryBlock>(half_size, address_ + half_size);
return true;
}
// 获取内存块信息字符串
std::string to_string() const {
std::string status_str;
if (status_ == MemoryBlockStatus::FREE) {
status_str = "FREE";
} else {
status_str = "ALLOCATED to " + container_id_;
}
return "Block(size=" + std::to_string(size_) + ", address=" + std::to_string(address_) + ", " + status_str + ")";
}
// getter和setter方法
size_t get_size() const { return size_; }
size_t get_address() const { return address_; }
MemoryBlockStatus get_status() const { return status_; }
void set_status(MemoryBlockStatus status) { status_ = status; }
const std::string& get_container_id() const { return container_id_; }
void set_container_id(const std::string& id) { container_id_ = id; }
MemoryBlock* get_left_child() const { return left_child_.get(); }
MemoryBlock* get_right_child() const { return right_child_.get(); }
void clear_children() {
left_child_.reset();
right_child_.reset();
}
};
// 伙伴算法内存分配器
class BuddyAllocator {
private:
size_t total_size_;
std::unique_ptr<MemoryBlock> root_;
// 查找父块
MemoryBlock* find_parent(MemoryBlock* child, MemoryBlock* current) {
if (!current || !current->get_left_child()) return nullptr;
if (current->get_left_child() == child || current->get_right_child() == child) {
return current;
}
MemoryBlock* parent = find_parent(child, current->get_left_child());
if (parent) return parent;
return find_parent(child, current->get_right_child());
}
// 合并内存块
void merge(MemoryBlock* block) {
if (!block) return;
MemoryBlock* parent = find_parent(block, root_.get());
if (!parent) return;
MemoryBlock* sibling = (parent->get_left_child() == block) ?
parent->get_right_child() : parent->get_left_child();
// 如果兄弟块也是空闲的且没有子块,则合并
if (sibling && sibling->is_free() &&
!sibling->get_left_child() && !sibling->get_right_child()) {
parent->set_status(MemoryBlockStatus::FREE);
parent->set_container_id("");
parent->clear_children();
merge(parent); // 递归向上合并
}
}
// 递归计算已分配内存
size_t count_allocated(MemoryBlock* block) {
if (!block) return 0;
if (block->get_status() == MemoryBlockStatus::ALLOCATED) {
return block->get_size();
}
return count_allocated(block->get_left_child()) + count_allocated(block->get_right_child());
}
// 递归打印内存布局
void print_memory_layout(MemoryBlock* block, int indent) {
if (!block) return;
for (int i = 0; i < indent; ++i) {
std::cout << " ";
}
std::cout << block->to_string() << std::endl;
print_memory_layout(block->get_left_child(), indent + 1);
print_memory_layout(block->get_right_child(), indent + 1);
}
public:
// 构造函数
BuddyAllocator(size_t total_memory_size) {
// 确保总内存大小是2的幂
total_size_ = 1;
while (total_size_ < total_memory_size) {
total_size_ <<= 1;
}
root_ = std::make_unique<MemoryBlock>(total_size_, 0);
}
// 查找适合大小的空闲块
MemoryBlock* find_free_block(size_t size, MemoryBlock* block = nullptr) {
if (!block) block = root_.get();
// 如果当前块足够大且空闲,且没有子块,返回它
if (block->is_free() && block->get_size() >= size &&
!block->get_left_child() && !block->get_right_child()) {
return block;
}
// 如果有子块,递归查找
if (block->get_left_child()) {
MemoryBlock* left_result = find_free_block(size, block->get_left_child());
if (left_result) return left_result;
MemoryBlock* right_result = find_free_block(size, block->get_right_child());
if (right_result) return right_result;
}
return nullptr;
}
// 分配内存
MemoryBlock* allocate(size_t size, const std::string& container_id) {
// 计算最接近的2的幂
size_t alloc_size = 1;
while (alloc_size < size) {
alloc_size <<= 1;
}
// 查找合适的块
MemoryBlock* block = find_free_block(alloc_size);
if (!block) return nullptr;
// 如果块太大,分裂它
while (block->get_size() > alloc_size) {
block->split();
block = block->get_left_child(); // 使用左子块
}
// 标记为已分配
block->set_status(MemoryBlockStatus::ALLOCATED);
block->set_container_id(container_id);
return block;
}
// 释放内存块
void free(MemoryBlock* block) {
if (!block || block->is_free()) return;
block->set_status(MemoryBlockStatus::FREE);
block->set_container_id("");
merge(block);
}
// 获取已分配内存总量
size_t get_allocated_memory() {
return count_allocated(root_.get());
}
// 打印内存布局
void print_memory_layout() {
print_memory_layout(root_.get(), 0);
}
size_t get_total_size() const { return total_size_; }
};
// 容器类,表示Kubernetes中的容器
class Container {
private:
std::string container_id_;
size_t mem_request_; // 内存请求
size_t mem_limit_; // 内存限制
size_t allocated_memory_; // 当前已分配内存
std::vector<MemoryBlock*> blocks_; // 分配的内存块列表
public:
// 构造函数
Container(const std::string& id, size_t request, size_t limit)
: container_id_(id), mem_request_(request), mem_limit_(limit), allocated_memory_(0) {}
// 检查是否可以分配指定大小的内存
bool can_allocate(size_t size) const {
return allocated_memory_ + size <= mem_limit_;
}
// 添加一个内存块
void add_memory_block(MemoryBlock* block) {
if (block) {
blocks_.push_back(block);
allocated_memory_ += block->get_size();
}
}
// 移除一个内存块
void remove_memory_block(MemoryBlock* block) {
auto it = std::find(blocks_.begin(), blocks_.end(), block);
if (it != blocks_.end()) {
allocated_memory_ -= (*it)->get_size();
blocks_.erase(it);
}
}
// 获取容器信息字符串
std::string to_string() const {
return "Container(id=" + container_id_ + ", request=" + std::to_string(mem_request_) +
", limit=" + std::to_string(mem_limit_) + ", allocated=" + std::to_string(allocated_memory_) + ")";
}
// getter方法
const std::string& get_id() const { return container_id_; }
size_t get_mem_request() const { return mem_request_; }
size_t get_mem_limit() const { return mem_limit_; }
size_t get_allocated_memory() const { return allocated_memory_; }
const std::vector<MemoryBlock*>& get_blocks() const { return blocks_; }
};
// Kubernetes内存管理器,结合伙伴算法和Cgroups
class K8sMemoryManager {
private:
std::unique_ptr<BuddyAllocator> buddy_allocator_;
std::unordered_map<std::string, std::unique_ptr<Container>> containers_;
double oom_killer_threshold_; // OOM杀手触发阈值
// 尝试为目标容器释放所需内存
bool free_memory_for_container(const std::string& target_container_id, size_t required_size) {
size_t total_used = buddy_allocator_->get_allocated_memory();
size_t total_memory = buddy_allocator_->get_total_size();
// 检查是否有足够的空闲内存
if (total_memory - total_used >= required_size) {
return true;
}
// 寻找可以释放内存的容器,优先释放超过其请求的内存
std::vector<std::pair<size_t, std::string>> candidates;
for (const auto& [id, container] : containers_) {
if (id == target_container_id) continue;
size_t excess = container->get_allocated_memory() - container->get_mem_request();
if (excess > 0) {
candidates.emplace_back(excess, id);
}
}
// 按可释放的内存量排序
std::sort(candidates.begin(), candidates.end(),
[](const auto& a, const auto& b) { return a.first > b.first; });
// 尝试释放内存
size_t freed = 0;
for (const auto& [excess, id] : candidates) {
if (freed >= required_size) break;
size_t to_free = std::min(excess, required_size - freed);
freed += free_memory(id, to_free);
}
return freed >= required_size;
}
// 检查是否需要触发OOM killer
void check_oom_conditions() {
size_t total_used = buddy_allocator_->get_allocated_memory();
size_t total_memory = buddy_allocator_->get_total_size();
double usage_ratio = static_cast<double>(total_used) / total_memory;
if (usage_ratio < oom_killer_threshold_) return;
std::cout << "Memory usage high (" << usage_ratio * 100 << "%). Triggering OOM checks..." << std::endl;
// 找出超出内存限制的容器
std::vector<std::pair<size_t, std::string>> over_limit;
for (const auto& [id, container] : containers_) {
if (container->get_allocated_memory() > container->get_mem_limit()) {
size_t over = container->get_allocated_memory() - container->get_mem_limit();
over_limit.emplace_back(over, id);
}
}
// 按超出量排序,超出最多的优先被终止
std::sort(over_limit.begin(), over_limit.end(),
[](const auto& a, const auto& b) { return a.first > b.first; });
// 终止超出限制的容器
for (const auto& [_, id] : over_limit) {
std::cout << "OOM killer terminating container " << id << std::endl;
free_memory(id);
containers_.erase(id);
// 检查内存使用率是否恢复正常
total_used = buddy_allocator_->get_allocated_memory();
usage_ratio = static_cast<double>(total_used) / total_memory;
if (usage_ratio < oom_killer_threshold_) break;
}
}
public:
// 构造函数
K8sMemoryManager(size_t total_memory)
: buddy_allocator_(std::make_unique<BuddyAllocator>(total_memory)),
oom_killer_threshold_(0.9) {}
// 创建容器并设置内存限制
void create_container(const std::string& container_id, size_t mem_request, size_t mem_limit) {
if (containers_.find(container_id) != containers_.end()) {
throw std::invalid_argument("Container " + container_id + " already exists");
}
if (mem_request > mem_limit) {
throw std::invalid_argument("Memory request cannot exceed memory limit");
}
containers_[container_id] = std::make_unique<Container>(container_id, mem_request, mem_limit);
}
// 为容器分配内存
bool allocate_memory(const std::string& container_id, size_t size) {
auto it = containers_.find(container_id);
if (it == containers_.end()) {
throw std::invalid_argument("Container " + container_id + " does not exist");
}
Container* container = it->second.get();
// 检查是否超过容器内存限制
if (!container->can_allocate(size)) {
std::cout << "Container " << container_id << " cannot allocate " << size
<< " bytes - exceeds memory limit" << std::endl;
return false;
}
// 使用伙伴算法分配内存
MemoryBlock* block = buddy_allocator_->allocate(size, container_id);
if (!block) {
// 尝试释放一些内存
std::cout << "Memory allocation failed for " << container_id << ". Trying to free memory..." << std::endl;
if (!free_memory_for_container(container_id, size)) {
std::cout << "Failed to allocate " << size << " bytes for container " << container_id << std::endl;
return false;
}
// 再次尝试分配
block = buddy_allocator_->allocate(size, container_id);
if (!block) {
std::cout << "Failed to allocate " << size << " bytes for container " << container_id << std::endl;
return false;
}
}
container->add_memory_block(block);
std::cout << "Allocated " << block->get_size() << " bytes to container " << container_id << std::endl;
// 检查是否需要触发OOM killer
check_oom_conditions();
return true;
}
// 释放容器的内存
size_t free_memory(const std::string& container_id, size_t size = 0) {
auto it = containers_.find(container_id);
if (it == containers_.end()) {
throw std::invalid_argument("Container " + container_id + " does not exist");
}
Container* container = it->second.get();
const auto& blocks = container->get_blocks();
if (blocks.empty()) {
std::cout << "No allocated memory for container " << container_id << std::endl;
return 0;
}
// 如果指定了大小,尝试释放相应大小的内存
if (size > 0) {
size_t freed = 0;
std::vector<MemoryBlock*> blocks_to_free;
for (MemoryBlock* block : blocks) {
if (freed < size) {
blocks_to_free.push_back(block);
freed += block->get_size();
} else {
break;
}
}
for (MemoryBlock* block : blocks_to_free) {
container->remove_memory_block(block);
buddy_allocator_->free(block);
}
std::cout << "Freed " << freed << " bytes from container " << container_id << std::endl;
return freed;
} else {
// 释放所有内存
size_t total_freed = container->get_allocated_memory();
for (MemoryBlock* block : blocks) {
buddy_allocator_->free(block);
}
// 清除容器的内存块列表
// 注意:C++中不能直接修改容器的私有成员,这里通过重新创建容器来实现
containers_[container_id] = std::make_unique<Container>(
container_id, container->get_mem_request(), container->get_mem_limit()
);
std::cout << "Freed all " << total_freed << " bytes from container " << container_id << std::endl;
return total_freed;
}
}
// 打印系统状态
void print_status() {
size_t total_used = buddy_allocator_->get_allocated_memory();
size_t total_memory = buddy_allocator_->get_total_size();
std::cout << "\n=== System Memory Status ===" << std::endl;
std::cout << "Total memory: " << total_memory << " bytes" << std::endl;
std::cout << "Used memory: " << total_used << " bytes ("
<< (static_cast<double>(total_used) / total_memory) * 100 << "%)" << std::endl;
std::cout << "\n=== Containers ===" << std::endl;
for (const auto& [id, container] : containers_) {
std::cout << container->to_string() << std::endl;
}
std::cout << "\n=== Memory Layout ===" << std::endl;
buddy_allocator_->print_memory_layout();
std::cout << "===========================\n" << std::endl;
}
};
// 主函数,演示内存管理功能
int main() {
// 创建一个总内存为1024字节的Kubernetes内存管理器
K8sMemoryManager k8s_manager(1024);
// 创建几个容器,设置不同的内存请求和限制
try {
k8s_manager.create_container("app-1", 200, 300);
k8s_manager.create_container("app-2", 150, 250);
k8s_manager.create_container("app-3", 100, 200);
// 为容器分配内存
k8s_manager.allocate_memory("app-1", 150);
k8s_manager.allocate_memory("app-2", 100);
k8s_manager.allocate_memory("app-3", 80);
// 打印当前状态
k8s_manager.print_status();
// 尝试分配更多内存,导致内存紧张
k8s_manager.allocate_memory("app-1", 100);
k8s_manager.allocate_memory("app-2", 120);
// 打印状态
k8s_manager.print_status();
// 再分配更多内存,触发OOM killer
k8s_manager.allocate_memory("app-1", 100);
// 打印最终状态
k8s_manager.print_status();
} catch (const std::exception& e) {
std::cerr << "Error: " << e.what() << std::endl;
return 1;
}
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.98.99.100.101.102.103.104.105.106.107.108.109.110.111.112.113.114.115.116.117.118.119.120.121.122.123.124.125.126.127.128.129.130.131.132.133.134.135.136.137.138.139.140.141.142.143.144.145.146.147.148.149.150.151.152.153.154.155.156.157.158.159.160.161.162.163.164.165.166.167.168.169.170.171.172.173.174.175.176.177.178.179.180.181.182.183.184.185.186.187.188.189.190.191.192.193.194.195.196.197.198.199.200.201.202.203.204.205.206.207.208.209.210.211.212.213.214.215.216.217.218.219.220.221.222.223.224.225.226.227.228.229.230.231.232.233.234.235.236.237.238.239.240.241.242.243.244.245.246.247.248.249.250.251.252.253.254.255.256.257.258.259.260.261.262.263.264.265.266.267.268.269.270.271.272.273.274.275.276.277.278.279.280.281.282.283.284.285.286.287.288.289.290.291.292.293.294.295.296.297.298.299.300.301.302.303.304.305.306.307.308.309.310.311.312.313.314.315.316.317.318.319.320.321.322.323.324.325.326.327.328.329.330.331.332.333.334.335.336.337.338.339.340.341.342.343.344.345.346.347.348.349.350.351.352.353.354.355.356.357.358.359.360.361.362.363.364.365.366.367.368.369.370.371.372.373.374.375.376.377.378.379.380.381.382.383.384.385.386.387.388.389.390.391.392.393.394.395.396.397.398.399.400.401.402.403.404.405.406.407.408.409.410.411.412.413.414.415.416.417.418.419.420.421.422.423.424.425.426.427.428.429.430.431.432.433.434.435.436.437.438.439.440.441.442.443.444.445.446.447.448.449.450.451.452.453.454.455.456.457.458.459.460.461.462.463.464.465.466.467.468.469.470.471.472.473.474.475.476.477.478.479.480.481.482.483.484.485.486.487.488.489.490.491.492.493.494.495.496.497.498.499.500.501.502.503.504.505.506.507.508.509.510.511.512.513.514.515.516.517.
在 Linux 环境下,可以使用 g++ 编译此程序:
复制
g++ -std=c++17 k8s_memory_manager.cpp -o k8s_memory_manager1.
程序运行后将模拟 Kubernetes 集群中的内存管理过程,展示内存分配、回收以及 OOM killer 的工作机制,输出与 Python 版本类似的系统状态信息。
6.2嵌入式设备:在 “螺蛳壳里做道场” 的内存管理大师
在嵌入式设备领域,尤其是物联网(IoT)设备,内存资源往往十分有限 。这些设备通常运行着实时操作系统(RTOS),对内存的利用率和碎片化控制有着极高的要求,伙伴算法在这样的环境中发挥着关键作用。
以智能手环为例,它的内存容量可能只有几 MB,却需要同时运行传感器数据采集、蓝牙通信、显示驱动等多个任务 。伙伴算法通过将内存划分为不同大小的块,并以 2 的幂次进行分配和回收,最大限度地减少了内存碎片 。当传感器任务需要读取数据并进行临时存储时,伙伴算法能迅速分配合适大小的内存块;当数据处理完成后,又能及时回收内存,确保内存始终保持较高的利用率 。
在电池供电的嵌入式设备中,内存管理的效率直接影响设备的续航能力 。由于内存分配和回收过程需要消耗一定的能量,伙伴算法的高效性使得设备在频繁的内存操作中消耗更少的能量 。通过减少不必要的内存分配和回收次数,降低了系统的功耗,从而延长了设备的续航时间,为用户提供更持久的使用体验 。
复制
#include <cstddef>
#include <cstdint>
#include <cstring>
#include <algorithm>
#include <new>
#include <stdexcept>
// 嵌入式设备通常内存有限,定义最大内存块大小(可根据实际设备调整)
const size_t MAX_MEMORY_SIZE = 65536; // 64KB,适合智能手环等设备
const size_t MIN_BLOCK_SIZE = 16; // 最小块大小,根据系统需求调整
// 内存块状态
enum class BlockStatus {
FREE,
ALLOCATED
};
// 内存块元数据结构(尽量紧凑以减少内存开销)
struct MemoryBlock {
size_t size; // 块大小(总是2的幂)
BlockStatus status; // 块状态
MemoryBlock* prev; // 前向指针,用于链表管理
MemoryBlock* next; // 后向指针,用于链表管理
bool is_split; // 标记块是否已分裂
MemoryBlock* left_child; // 左子块
MemoryBlock* right_child; // 右子块
// 内存块头部大小,用于计算实际可用内存
static constexpr size_t header_size() {
return sizeof(MemoryBlock);
}
};
// 嵌入式环境伙伴算法内存管理器
class BuddyAllocator {
private:
uint8_t* memory_pool; // 内存池起始地址
size_t total_size; // 总内存大小
MemoryBlock* free_lists; // 不同大小的空闲块链表数组
size_t max_order; // 最大阶数(log2(total_size))
// 计算阶数(log2)
size_t get_order(size_t size) const {
if (size == 0) return 0;
return 31 - __builtin_clz(size);
}
// 找到第一个大于等于size的2的幂
size_t round_up_to_power_of_two(size_t size) const {
if (size <= MIN_BLOCK_SIZE) return MIN_BLOCK_SIZE;
return 1 << (get_order(size - 1) + 1);
}
// 从链表中移除块
void remove_from_list(MemoryBlock* block, size_t order) {
if (block->prev) {
block->prev->next = block->next;
} else {
free_lists[order] = block->next;
}
if (block->next) {
block->next->prev = block->prev;
}
}
// 添加块到链表
void add_to_list(MemoryBlock* block, size_t order) {
block->prev = nullptr;
block->next = free_lists[order];
if (free_lists[order]) {
free_lists[order]->prev = block;
}
free_lists[order] = block;
}
// 分裂块
MemoryBlock* split_block(MemoryBlock* block, size_t target_order) {
size_t current_order = get_order(block->size);
// 从当前链表移除
remove_from_list(block, current_order);
// 分裂直到达到目标阶数
while (current_order > target_order) {
current_order--;
size_t half_size = 1 << current_order;
// 计算右子块地址
uint8_t* right_block_ptr = reinterpret_cast<uint8_t*>(block) + half_size;
MemoryBlock* right_block = new (right_block_ptr) MemoryBlock;
right_block->size = half_size;
right_block->status = BlockStatus::FREE;
right_block->is_split = false;
right_block->left_child = nullptr;
right_block->right_child = nullptr;
// 更新当前块作为左子块
block->size = half_size;
block->is_split = true;
block->right_child = right_block;
// 将右子块添加到对应阶数的空闲链表
add_to_list(right_block, current_order);
// 继续分裂左子块
block = block;
}
// 将最终的左子块添加到目标阶数链表
add_to_list(block, target_order);
return block;
}
// 合并块
void merge_blocks(MemoryBlock* block) {
if (block->status != BlockStatus::FREE || block->size == total_size) {
return; // 已分配块或根块不能合并
}
size_t order = get_order(block->size);
size_t buddy_offset = block->size;
// 计算伙伴块地址
uint8_t* block_ptr = reinterpret_cast<uint8_t*>(block);
uint8_t* pool_start = memory_pool;
size_t block_index = (block_ptr - pool_start) / block->size;
MemoryBlock* buddy;
if (block_index % 2 == 0) {
// 当前块是左伙伴
buddy = reinterpret_cast<MemoryBlock*>(block_ptr + buddy_offset);
} else {
// 当前块是右伙伴
buddy = reinterpret_cast<MemoryBlock*>(block_ptr - buddy_offset);
}
// 检查伙伴是否可以合并
if (buddy->status == BlockStatus::FREE &&
buddy->size == block->size &&
!buddy->is_split) {
// 从链表中移除两个块
remove_from_list(block, order);
remove_from_list(buddy, order);
// 确定父块(左块)
MemoryBlock* parent = (block_index % 2 == 0) ? block : buddy;
parent->size *= 2;
parent->is_split = false;
parent->left_child = nullptr;
parent->right_child = nullptr;
// 添加到更高阶的链表
add_to_list(parent, order + 1);
// 递归合并
merge_blocks(parent);
}
}
public:
// 构造函数,使用指定内存池
BuddyAllocator(void* pool, size_t size) {
// 确保内存大小是2的幂且不超过最大值
total_size = round_up_to_power_of_two(size);
if (total_size > MAX_MEMORY_SIZE) {
total_size = MAX_MEMORY_SIZE;
}
// 如果未提供内存池,则在堆上分配
if (pool == nullptr) {
memory_pool = new uint8_t[total_size];
} else {
memory_pool = static_cast<uint8_t*>(pool);
}
// 计算最大阶数
max_order = get_order(total_size);
// 初始化空闲链表数组
free_lists = new MemoryBlock*[max_order + 1]();
// 创建初始内存块
MemoryBlock* initial_block = new (memory_pool) MemoryBlock;
initial_block->size = total_size;
initial_block->status = BlockStatus::FREE;
initial_block->is_split = false;
initial_block->left_child = nullptr;
initial_block->right_child = nullptr;
// 将初始块添加到最大阶数的空闲链表
add_to_list(initial_block, max_order);
}
// 析构函数
~BuddyAllocator() {
delete[] free_lists;
// 只释放自己分配的内存池
// 如果是外部提供的内存池,则由用户负责释放
}
// 分配内存
void* allocate(size_t size) {
if (size == 0) return nullptr;
// 加上块头部大小
size_t total_needed = size + MemoryBlock::header_size();
if (total_needed > total_size) {
return nullptr; // 超出总内存
}
// 计算所需块大小和阶数
size_t block_size = round_up_to_power_of_two(total_needed);
size_t target_order = get_order(block_size);
// 寻找合适的块
size_t order;
for (order = target_order; order <= max_order; ++order) {
if (free_lists[order] != nullptr) {
break;
}
}
if (order > max_order) {
return nullptr; // 没有足够大的块
}
// 如果找到的块大于需要的块,进行分裂
MemoryBlock* block = free_lists[order];
if (order > target_order) {
block = split_block(block, target_order);
}
// 从空闲链表移除并标记为已分配
remove_from_list(block, target_order);
block->status = BlockStatus::ALLOCATED;
// 返回可用内存地址(跳过块头部)
return reinterpret_cast<uint8_t*>(block) + MemoryBlock::header_size();
}
// 释放内存
void deallocate(void* ptr) {
if (ptr == nullptr) return;
// 计算块头部地址
MemoryBlock* block = reinterpret_cast<MemoryBlock*>(
static_cast<uint8_t*>(ptr) - MemoryBlock::header_size()
);
// 检查块是否在内存池范围内
uint8_t* block_ptr = reinterpret_cast<uint8_t*>(block);
if (block_ptr < memory_pool || block_ptr >= memory_pool + total_size) {
throw std::invalid_argument("Invalid pointer to deallocate");
}
// 标记为空闲
block->status = BlockStatus::FREE;
size_t order = get_order(block->size);
// 添加到空闲链表
add_to_list(block, order);
// 尝试合并
merge_blocks(block);
}
// 获取内存使用统计
void get_stats(size_t& total, size_t& used, size_t& free) const {
total = total_size;
// 计算已使用内存
used = 0;
// 遍历所有块(简化实现,实际嵌入式系统可能需要更高效的统计方式)
// 这里使用递归方式计算已分配内存
used = calculate_used(memory_pool);
free = total - used;
}
// 递归计算已使用内存
size_t calculate_used(void* block_ptr) const {
MemoryBlock* block = static_cast<MemoryBlock*>(block_ptr);
if (block->status == BlockStatus::ALLOCATED) {
return block->size;
}
if (block->is_split && block->left_child) {
return calculate_used(block->left_child) + calculate_used(block->right_child);
}
return 0;
}
// 获取内存池起始地址
const void* get_memory_pool() const {
return memory_pool;
}
};
// 嵌入式任务基类
class EmbeddedTask {
protected:
BuddyAllocator& allocator;
const char* name;
bool running;
public:
EmbeddedTask(BuddyAllocator& alloc, const char* task_name)
: allocator(alloc), name(task_name), running(false) {}
virtual ~EmbeddedTask() = default;
virtual void start() {
running = true;
}
virtual void stop() {
running = false;
}
virtual void run() = 0;
const char* get_name() const {
return name;
}
bool is_running() const {
return running;
}
};
// 传感器数据采集任务(模拟)
class SensorTask : public EmbeddedTask {
private:
size_t data_buffer_size;
uint8_t* data_buffer;
public:
SensorTask(BuddyAllocator& alloc)
: EmbeddedTask(alloc, "SensorTask"), data_buffer_size(512), data_buffer(nullptr) {}
void run() override {
if (!running) return;
// 分配内存用于存储传感器数据
data_buffer = static_cast<uint8_t*>(allocator.allocate(data_buffer_size));
if (data_buffer) {
// 模拟采集传感器数据
memset(data_buffer, 0xAA, data_buffer_size);
printf("SensorTask: Collected data into %zu bytes buffer\n", data_buffer_size);
// 模拟数据处理延迟
for (volatile int i = 0; i < 100000; i++);
// 处理完成,释放内存
allocator.deallocate(data_buffer);
data_buffer = nullptr;
printf("SensorTask: Released data buffer\n");
} else {
printf("SensorTask: Failed to allocate data buffer\n");
}
}
};
// 蓝牙通信任务(模拟)
class BluetoothTask : public EmbeddedTask {
private:
size_t packet_size;
uint8_t* packet_buffer;
public:
BluetoothTask(BuddyAllocator& alloc)
: EmbeddedTask(alloc, "BluetoothTask"), packet_size(256), packet_buffer(nullptr) {}
void run() override {
if (!running) return;
// 分配内存用于蓝牙数据包
packet_buffer = static_cast<uint8_t*>(allocator.allocate(packet_size));
if (packet_buffer) {
// 模拟接收蓝牙数据
memset(packet_buffer, 0xBB, packet_size);
printf("BluetoothTask: Received data into %zu bytes packet\n", packet_size);
// 模拟数据传输延迟
for (volatile int i = 0; i < 50000; i++);
// 传输完成,释放内存
allocator.deallocate(packet_buffer);
packet_buffer = nullptr;
printf("BluetoothTask: Released packet buffer\n");
} else {
printf("BluetoothTask: Failed to allocate packet buffer\n");
}
}
};
// 显示驱动任务(模拟)
class DisplayTask : public EmbeddedTask {
private:
size_t frame_buffer_size;
uint8_t* frame_buffer;
public:
DisplayTask(BuddyAllocator& alloc)
: EmbeddedTask(alloc, "DisplayTask"), frame_buffer_size(1024), frame_buffer(nullptr) {}
void run() override {
if (!running) return;
// 分配内存用于显示帧缓冲
frame_buffer = static_cast<uint8_t*>(allocator.allocate(frame_buffer_size));
if (frame_buffer) {
// 模拟绘制显示内容
memset(frame_buffer, 0xCC, frame_buffer_size);
printf("DisplayTask: Rendered frame into %zu bytes buffer\n", frame_buffer_size);
// 模拟显示刷新延迟
for (volatile int i = 0; i < 150000; i++);
// 显示完成,释放内存
allocator.deallocate(frame_buffer);
frame_buffer = nullptr;
printf("DisplayTask: Released frame buffer\n");
} else {
printf("DisplayTask: Failed to allocate frame buffer\n");
}
}
};
// 主函数,模拟嵌入式设备内存管理
int main() {
// 在嵌入式系统中,这通常是一个固定的内存区域
uint8_t memory_pool[MAX_MEMORY_SIZE];
// 创建伙伴分配器,使用预分配的内存池
BuddyAllocator allocator(memory_pool, MAX_MEMORY_SIZE);
printf("Embedded Buddy Allocator initialized with %zu bytes\n", MAX_MEMORY_SIZE);
// 创建嵌入式任务
SensorTask sensor_task(allocator);
BluetoothTask bt_task(allocator);
DisplayTask display_task(allocator);
// 启动任务
sensor_task.start();
bt_task.start();
display_task.start();
// 模拟RTOS调度器,循环执行任务
for (int i = 0; i < 5; i++) {
printf("\n--- Cycle %d ---\n", i + 1);
// 运行传感器任务
sensor_task.run();
// 运行蓝牙任务
bt_task.run();
// 运行显示任务
display_task.run();
// 打印内存使用情况
size_t total, used, free_mem;
allocator.get_stats(total, used, free_mem);
printf("Memory stats - Total: %zu, Used: %zu (%.1f%%), Free: %zu (%.1f%%)\n",
total, used, (float)used/total*100, free_mem, (float)free_mem/total*100);
}
// 停止任务
sensor_task.stop();
bt_task.stop();
display_task.stop();
printf("\nAll tasks completed\n");
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.98.99.100.101.102.103.104.105.106.107.108.109.110.111.112.113.114.115.116.117.118.119.120.121.122.123.124.125.126.127.128.129.130.131.132.133.134.135.136.137.138.139.140.141.142.143.144.145.146.147.148.149.150.151.152.153.154.155.156.157.158.159.160.161.162.163.164.165.166.167.168.169.170.171.172.173.174.175.176.177.178.179.180.181.182.183.184.185.186.187.188.189.190.191.192.193.194.195.196.197.198.199.200.201.202.203.204.205.206.207.208.209.210.211.212.213.214.215.216.217.218.219.220.221.222.223.224.225.226.227.228.229.230.231.232.233.234.235.236.237.238.239.240.241.242.243.244.245.246.247.248.249.250.251.252.253.254.255.256.257.258.259.260.261.262.263.264.265.266.267.268.269.270.271.272.273.274.275.276.277.278.279.280.281.282.283.284.285.286.287.288.289.290.291.292.293.294.295.296.297.298.299.300.301.302.303.304.305.306.307.308.309.310.311.312.313.314.315.316.317.318.319.320.321.322.323.324.325.326.327.328.329.330.331.332.333.334.335.336.337.338.339.340.341.342.343.344.345.346.347.348.349.350.351.352.353.354.355.356.357.358.359.360.361.362.363.364.365.366.367.368.369.370.371.372.373.374.375.376.377.378.379.380.381.382.383.384.385.386.387.388.389.390.391.392.393.394.395.396.397.398.399.400.401.402.403.404.405.406.407.408.409.410.411.412.413.414.415.416.417.418.419.420.421.422.423.424.425.426.427.428.429.430.431.432.433.434.435.436.437.438.439.440.441.442.443.444.445.446.447.448.449.450.451.452.453.454.455.456.457.458.459.460.461.462.463.464.465.466.467.468.469.470.471.472.473.474.475.476.477.478.479.480.
在嵌入式 Linux 环境中,可以使用以下命令编译:
复制
g++ -std=c++11 -Os embedded_buddy_allocator.cpp -o embedded_allocator1.
程序运行后将模拟智能手环等 IoT 设备的内存使用情况,展示伙伴算法如何在资源受限环境中高效管理内存,确保多个并发任务能够合理共享有限的内存资源。
6.3实时操作系统:为工业控制提供确定性的 “时间保障”
在实时操作系统中,伙伴算法的确定性内存分配和回收时间特性尤为重要 。以工业自动化生产线为例,各种控制器需要精确地控制电机的运转、机械臂的动作等,对响应时间的要求极高,哪怕是几毫秒的延迟都可能导致产品质量问题甚至生产事故 。
实时操作系统利用伙伴算法的确定性,确保在任何时刻进行内存分配和回收时,都能在可预测的时间内完成 。当一个控制任务需要分配内存来存储传感器数据或执行控制算法时,伙伴算法能迅速响应,并且分配时间是固定的,不受内存碎片化程度的影响 。这使得整个控制系统能够按照预定的时间序列运行,满足工业控制对实时性和可靠性的苛刻要求 。在航空航天、医疗设备等对安全性和实时性要求极高的领域,伙伴算法同样发挥着不可或缺的作用,为关键任务的稳定执行提供了坚实的内存管理保障 。
main.cpp
复制
#include "buddy_allocator.h"
#include <iostream>
#include <cassert>
int main() {
try {
// 创建一个总大小为1MB,最小块大小为64字节的伙伴分配器
BuddyAllocator allocator(1024 * 1024, 64);
std::cout << "伙伴分配器初始化成功:" << std::endl;
std::cout << "总内存大小: " << allocator.getTotalSize() << " 字节" << std::endl;
std::cout << "最小块大小: " << allocator.getMinBlockSize() << " 字节" << std::endl;
std::cout << "阶数数量: " << allocator.getOrderCount() << std::endl;
// 测试内存分配和释放
void* ptr1 = allocator.allocate(100);
assert(ptr1 != nullptr);
std::cout << "\n分配 100 字节成功: " << ptr1 << std::endl;
void* ptr2 = allocator.allocate(512);
assert(ptr2 != nullptr);
std::cout << "分配 512 字节成功: " << ptr2 << std::endl;
void* ptr3 = allocator.allocate(1024);
assert(ptr3 != nullptr);
std::cout << "分配 1024 字节成功: " << ptr3 << std::endl;
// 释放内存
allocator.deallocate(ptr1);
std::cout << "释放内存: " << ptr1 << std::endl;
allocator.deallocate(ptr2);
std::cout << "释放内存: " << ptr2 << std::endl;
// 再次分配,应该能重用刚才释放的内存
void* ptr4 = allocator.allocate(600);
assert(ptr4 != nullptr);
std::cout << "再次分配 600 字节成功: " << ptr4 << std::endl;
allocator.deallocate(ptr3);
std::cout << "释放内存: " << ptr3 << std::endl;
allocator.deallocate(ptr4);
std::cout << "释放内存: " << ptr4 << std::endl;
// 测试分配一个较大的块
void* ptr5 = allocator.allocate(512 * 1024);
if (ptr5) {
std::cout << "分配 512KB 成功: " << ptr5 << std::endl;
allocator.deallocate(ptr5);
std::cout << "释放内存: " << ptr5 << std::endl;
} else {
std::cout << "分配 512KB 失败" << std::endl;
}
std::cout << "\n所有测试完成" << std::endl;
} catch (const std::exception& e) {
std::cerr << "错误: " << e.what() << std::endl;
return 1;
}
return 0;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.
buddy_allocator.h
复制
#ifndef BUDDY_ALLOCATOR_H
#define BUDDY_ALLOCATOR_H
#include <cstddef>
#include <cstdint>
#include <vector>
#include <mutex>
// 伙伴内存分配器类
class BuddyAllocator {
public:
// 构造函数:指定总内存大小和最小块大小
BuddyAllocator(size_t totalSize, size_t minBlockSize);
// 析构函数
~BuddyAllocator();
// 分配内存块
void* allocate(size_t size);
// 释放内存块
void deallocate(void* ptr);
// 获取分配器信息
size_t getTotalSize() const { return m_totalSize; }
size_t getMinBlockSize() const { return m_minBlockSize; }
size_t getOrderCount() const { return m_orderCount; }
private:
// 块描述符结构
struct Block {
bool isFree; // 块是否空闲
size_t order; // 块的阶数,块大小 = minBlockSize * 2^order
Block* next; // 下一个块(用于空闲链表)
Block* prev; // 上一个块(用于空闲链表)
Block() : isFree(true), order(0), next(nullptr), prev(nullptr) {}
};
// 计算块大小
size_t blockSize(size_t order) const { return m_minBlockSize * (1ULL << order); }
// 计算给定大小所需的最小阶数
size_t calculateOrder(size_t size) const;
// 找到块的伙伴
Block* findBuddy(Block* block);
// 分裂块
void split(Block* block, size_t targetOrder);
// 合并块
void merge(Block* block);
// 从空闲链表中移除块
void removeFromFreeList(Block* block);
// 将块添加到空闲链表
void addToFreeList(Block* block);
// 转换指针:从块指针到数据指针
void* blockToData(Block* block) const;
// 转换指针:从数据指针到块指针
Block* dataToBlock(void* ptr) const;
// 检查指针是否属于此分配器管理的内存
bool isPointerValid(void* ptr) const;
size_t m_totalSize; // 总内存大小
size_t m_minBlockSize; // 最小块大小
size_t m_orderCount; // 阶数数量
uint8_t* m_memoryPool; // 内存池起始地址
Block* m_blocks; // 块描述符数组
std::vector<Block*> m_freeLists; // 空闲块链表,按阶数组织
// 互斥锁,确保线程安全
mutable std::mutex m_mutex;
};
#endif // BUDDY_ALLOCATOR_H1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.
buddy_allocator.cpp
复制
#include "buddy_allocator.h"
#include <cstring>
#include <stdexcept>
#include <iostream>
BuddyAllocator::BuddyAllocator(size_t totalSize, size_t minBlockSize)
: m_totalSize(totalSize), m_minBlockSize(minBlockSize) {
// 检查最小块大小是否为2的幂
if ((minBlockSize & (minBlockSize - 1)) != 0) {
throw std::invalid_argument("最小块大小必须是2的幂");
}
// 计算所需的最大阶数
size_t maxBlockSize = minBlockSize;
m_orderCount = 0;
while (maxBlockSize * 2 <= totalSize) {
maxBlockSize *= 2;
m_orderCount++;
}
m_orderCount++; // 包含maxBlockSize本身
// 计算总块数
size_t totalBlocks = 0;
size_t currentOrder = m_orderCount - 1;
size_t remainingSize = totalSize;
while (remainingSize > 0 && currentOrder >= 0) {
size_t bs = blockSize(currentOrder);
if (bs <= remainingSize) {
totalBlocks++;
remainingSize -= bs;
} else {
currentOrder--;
}
}
if (remainingSize > 0) {
throw std::invalid_argument("总内存大小无法用指定的最小块大小的2的幂次组合表示");
}
// 分配内存池:数据区 + 块描述符区
size_t descriptorSize = totalBlocks * sizeof(Block);
m_memoryPool = new uint8_t[totalSize + descriptorSize];
m_blocks = reinterpret_cast<Block*>(m_memoryPool + totalSize);
// 初始化块描述符和空闲链表
m_freeLists.resize(m_orderCount, nullptr);
// 初始化所有块
uint8_t* dataPtr = m_memoryPool;
remainingSize = totalSize;
currentOrder = m_orderCount - 1;
size_t blockIndex = 0;
while (remainingSize > 0 && currentOrder >= 0) {
size_t bs = blockSize(currentOrder);
if (bs <= remainingSize) {
m_blocks[blockIndex].isFree = true;
m_blocks[blockIndex].order = currentOrder;
m_blocks[blockIndex].next = nullptr;
m_blocks[blockIndex].prev = nullptr;
// 将块添加到相应的空闲链表
addToFreeList(&m_blocks[blockIndex]);
dataPtr += bs;
remainingSize -= bs;
blockIndex++;
} else {
currentOrder--;
}
}
}
BuddyAllocator::~BuddyAllocator() {
delete[] m_memoryPool;
}
void* BuddyAllocator::allocate(size_t size) {
std::lock_guard<std::mutex> lock(m_mutex);
// 加上块头的大小
size_t requiredSize = size + sizeof(Block);
// 计算所需的阶数
size_t order = calculateOrder(requiredSize);
if (order >= m_orderCount) {
return nullptr; // 无法满足分配请求
}
// 查找合适的空闲块
size_t currentOrder = order;
while (currentOrder < m_orderCount) {
if (m_freeLists[currentOrder] != nullptr) {
// 找到可用块
Block* block = m_freeLists[currentOrder];
removeFromFreeList(block);
// 如果当前块大于所需,分裂它
while (currentOrder > order) {
split(block, currentOrder - 1);
currentOrder--;
}
block->isFree = false;
return blockToData(block);
}
currentOrder++;
}
return nullptr; // 没有可用块
}
void BuddyAllocator::deallocate(void* ptr) {
std::lock_guard<std::mutex> lock(m_mutex);
if (!ptr || !isPointerValid(ptr)) {
throw std::invalid_argument("无效的指针");
}
// 转换为块指针
Block* block = dataToBlock(ptr);
if (block->isFree) {
throw std::invalid_argument("指针已经被释放");
}
// 标记为空闲
block->isFree = true;
addToFreeList(block);
// 尝试合并
merge(block);
}
size_t BuddyAllocator::calculateOrder(size_t size) const {
if (size == 0) {
return 0;
}
size_t order = 0;
size_t currentSize = m_minBlockSize;
while (currentSize < size && order < m_orderCount - 1) {
currentSize *= 2;
order++;
}
return order;
}
BuddyAllocator::Block* BuddyAllocator::findBuddy(Block* block) {
// 计算块在内存池中的偏移量
size_t blockSize = blockSize(block->order);
size_t blockOffset = reinterpret_cast<uint8_t*>(blockToData(block)) - m_memoryPool;
// 计算伙伴块的偏移量
size_t buddyOffset = (blockOffset ^ blockSize);
// 检查伙伴块是否在内存池范围内
if (buddyOffset >= m_totalSize) {
return nullptr;
}
// 查找伙伴块的描述符
uint8_t* buddyData = m_memoryPool + buddyOffset;
return dataToBlock(buddyData);
}
void BuddyAllocator::split(Block* block, size_t targetOrder) {
if (block->order <= targetOrder) {
return; // 不需要分裂
}
size_t currentOrder = block->order;
Block* first = block;
// 找到第二个块
size_t halfSize = blockSize(currentOrder - 1);
uint8_t* secondData = reinterpret_cast<uint8_t*>(blockToData(first)) + halfSize;
Block* second = dataToBlock(secondData);
// 更新块信息
first->order = currentOrder - 1;
second->order = currentOrder - 1;
second->isFree = true;
// 将两个块添加到空闲链表
addToFreeList(first);
addToFreeList(second);
}
void BuddyAllocator::merge(Block* block) {
size_t currentOrder = block->order;
// 只能合并到最大阶数
while (currentOrder < m_orderCount - 1) {
Block* buddy = findBuddy(block);
// 检查伙伴是否存在、空闲且同阶
if (!buddy || !buddy->isFree || buddy->order != currentOrder) {
break;
}
// 从空闲链表中移除当前块和伙伴块
removeFromFreeList(block);
removeFromFreeList(buddy);
// 确定合并后的父块
Block* parent = block;
size_t blockOffset = reinterpret_cast<uint8_t*>(blockToData(block)) - m_memoryPool;
size_t buddyOffset = reinterpret_cast<uint8_t*>(blockToData(buddy)) - m_memoryPool;
if (buddyOffset < blockOffset) {
parent = buddy;
}
// 更新父块信息
parent->order = currentOrder + 1;
parent->isFree = true;
// 将父块添加到空闲链表
addToFreeList(parent);
// 继续尝试合并更大的块
block = parent;
currentOrder++;
}
}
void BuddyAllocator::removeFromFreeList(Block* block) {
size_t order = block->order;
if (block->prev) {
block->prev->next = block->next;
} else {
// 是链表头
m_freeLists[order] = block->next;
}
if (block->next) {
block->next->prev = block->prev;
}
block->next = nullptr;
block->prev = nullptr;
}
void BuddyAllocator::addToFreeList(Block* block) {
size_t order = block->order;
// 添加到链表头部
block->next = m_freeLists[order];
block->prev = nullptr;
if (m_freeLists[order]) {
m_freeLists[order]->prev = block;
}
m_freeLists[order] = block;
}
void* BuddyAllocator::blockToData(Block* block) const {
// 计算块索引
size_t blockIndex = block - m_blocks;
// 找到该块在内存池中的数据区起始地址
uint8_t* dataPtr = m_memoryPool;
size_t remainingSize = m_totalSize;
for (size_t i = 0; i < blockIndex; i++) {
size_t bs = blockSize(m_blocks[i].order);
dataPtr += bs;
remainingSize -= bs;
}
return dataPtr;
}
BuddyAllocator::Block* BuddyAllocator::dataToBlock(void* ptr) const {
uint8_t* dataPtr = reinterpret_cast<uint8_t*>(ptr);
// 计算数据指针在内存池中的偏移量
size_t offset = dataPtr - m_memoryPool;
if (offset >= m_totalSize) {
return nullptr;
}
// 查找对应的块描述符
uint8_t* currentPtr = m_memoryPool;
for (size_t i = 0; ; i++) {
size_t bs = blockSize(m_blocks[i].order);
if (dataPtr >= currentPtr && dataPtr < currentPtr + bs) {
return &m_blocks[i];
}
currentPtr += bs;
}
}
bool BuddyAllocator::isPointerValid(void* ptr) const {
uint8_t* dataPtr = reinterpret_cast<uint8_t*>(ptr);
return (dataPtr >= m_memoryPool && dataPtr < m_memoryPool + m_totalSize);
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.98.99.100.101.102.103.104.105.106.107.108.109.110.111.112.113.114.115.116.117.118.119.120.121.122.123.124.125.126.127.128.129.130.131.132.133.134.135.136.137.138.139.140.141.142.143.144.145.146.147.148.149.150.151.152.153.154.155.156.157.158.159.160.161.162.163.164.165.166.167.168.169.170.171.172.173.174.175.176.177.178.179.180.181.182.183.184.185.186.187.188.189.190.191.192.193.194.195.196.197.198.199.200.201.202.203.204.205.206.207.208.209.210.211.212.213.214.215.216.217.218.219.220.221.222.223.224.225.226.227.228.229.230.231.232.233.234.235.236.237.238.239.240.241.242.243.244.245.246.247.248.249.250.251.252.253.254.255.256.257.258.259.260.261.262.263.264.265.266.267.268.269.270.271.272.273.274.275.276.277.278.279.280.281.282.283.284.285.286.287.288.289.290.291.292.293.294.295.296.297.298.299.300.301.302.303.304.