如何设计一个易扩展、易运维的内容下发服务架构?
内容为王时代,任何一个To C的App都会有内容下发服务,内容包含商品、图文、视频等,比如在淘系App上,首页和各个垂类频道页充满了各类内容,这些页面业务变化非常较快,如何设计一个易扩展、稳定、低延迟的内容下发接口,需要开发同学不断思考摸索。作者总结内容下发服务遇到的常见问题和挑战,设计出一套灵活架构来支持不断变化的业务,重点梳理在内容服务下发内容时需要关注的点、拆分内容下发服务各个环节,通过分层架构,最终达到易扩展、易运维的业务效果。
重要术语解释
内容:包括商品、图文、视频等,服务端通过算法推荐,最终下发给客户端消费的内容补齐数据源:对于内容id,提供一个或多个维度的关联信息内容补齐:获取到内容id后,请求不同补齐数据源,获取内容周边素材,用于客户端展示常见服务分类
作者在阿里做过和学习过不少服务实现,如下,给阿里服务体系中常见服务大致分一个类,每个类别有些是应用层,有些是中间层,这里不作赘述,这里我们重点讨论内容型服务

主要关注点
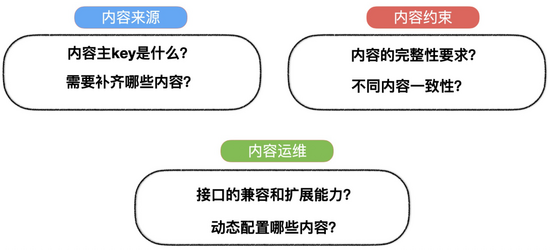
比如对于我们淘系业务,搭建一套服务,我们需要先想清楚下面的几个点
内容来源:从算法、运营配置或者其他渠道来,唯一标识内容id的key向量是哪些,基于这些id,如何进行相关内容补齐内容约束:算法推荐比较稳定,但是运营配置的内容,可能会过期,不能满足客户端展示需求,我们需要保证内容完整性,校验内容的一致性内容运维:内容下发服务上线后,业务会不断变化,内容筛选条件的增减,客户端也在不断迭代,接口设计需要考虑灵活性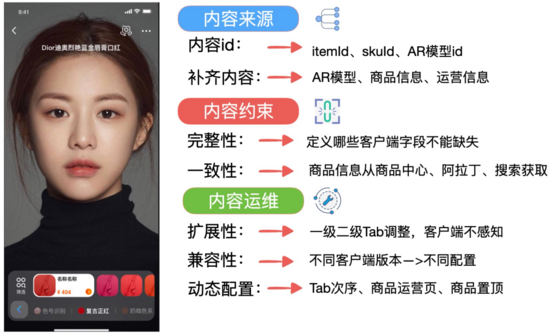
常见问题及解决方案
面临问题各种字段需要补齐:不同字段来源于不同数据源,容易出现面条式代码,需要灵活的架构来处理这种复杂度不同场景对于下发字段的校验要求不同:需要基于标注的Validator模块来处理字段粒度判断运营和产品的需求经常变化:对于tab排序、筛选条件,接口设计要考虑扩展性,提供运营能力解决方案构建一套pipeline,每个处理节点关注一个问题解决
Datasource:数据来源(算法推荐、数据库、缓存、运营配置、置顶数据)。方法名:fromXXXTransfer:类型转换。方法名:toXXXFilter:数据过滤(黑白名单,字段约束)。方法名:byXXXSorter:数据排序。方法名:topXXX、shuffleXXXCompleter:补数据。方法名:addXXXValidator:有效性验证,过滤不符合要求的数据,比如商品某个字段缺失。方法名:checkXXXFactory:基于基本元素,数据拼接生产。方法名:createXXXIterator:保存各类遍历过程是不是看起来有点类似Java8中stream的API,但这套pipeline具体还是偏内容下发业务,比Java原生API要更丰富,以淘宝的AR淘业务为例,pipeline如下:
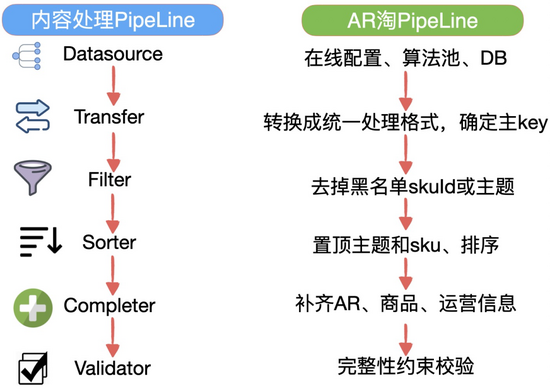
下面代码实现一套基于运营配置数据源的pipeline
1.首先,自定义Pipeline,没有使用Lambada,对java7及以下也适用
{
private List<PipeLineFunction<D, C>> functionList = new ArrayList<>();
public PipeLine<D, C> add(PipeLineFunction<D, C> pipeLineFunction) {
functionList.add(pipeLineFunction);
return this;
}
public D execute(D data, C context) throws Exception{
for (PipeLineFunction function : functionList) {
data = (D) function.execute(data, context);
}
return data;
}
}
1.2.3.4.5.6.7.8.9.10.11.12.13.2.其次管线,对于处理次序和节点进行指定:包括从配置读取数据--->通过arType过滤--->随机打乱数据--->置顶主题类数据--->翻页--->增加sku和item信息--->增加AR模型信息--->完整性校验
() {
PipeLine<SkuResultVO, SkuQuery> skuResultHotRecommendPipeLine = new PipeLine();
skuResultHotRecommendPipeLine .add((data, context) -> skuResultDataSource.fromConfig(context))
.add((data, context) -> skuResultSorter.shuffle(data))
.add((data, context) -> skuResultSorter.topTheme(data, context))
.add((data, context) -> skuResultSorter.page(data, context))
.add((data, context) -> skuResultCompleter.addSkuInfo(data))
.add((data, context) -> skuResultCompleter.addAREffect(data, context))
.add((data, context) -> skuResultValidator.check(data));
}
1.2.3.4.5.6.7.8.9.10.11.3.最后,搭建pipeline,接口收到请求后,通过管线处理,下发对应内容
) {
try{
SkuResultVO skuResultVO = skuResultHotRecommendPipeLine .execute(new SkuResultVO(), skuQuery);
} catch (Exception e) {
log.error("", e.fillInStackTrace());
return ResultVO.failOf(e.getMessage());
}
return ResultVO.failOf(CameraArCause.No_Valid_Ar_Type .toMessage(skuQuery.toString()));
}
1.2.3.4.5.6.7.8.9.10.11.4.我们再讨论一下对于有固定的遍历逻辑的情况,遍历方式也可以抽象成一个iterator,在不同的filter作为参数传入下,完成遍历功能,下图就是对商品的一种遍历,这个特性用到FunctionalInterface标注,需要java8及以上
(1) 定义遍历器
{
boolean execute(T t) throws Exception;
}
@FunctionalInterfacepublic interface IterateFunction<T>{
T execute(T t, FilterFunction filterFunction);
}
1.2.3.4.5.6.7.8.{
List<SkuFeedUnitVO> skuFeedUnitVOList = skuResultVO.getSkuFeedUnitVOList()
.stream().filter(skuFeedUnitVO ->{
List<SkuVO> filterSkuVOList = skuFeedUnitVO.getSkuVOList()
.stream().filter(skuVO ->{
try{
return filter.execute(skuVO);
} catch (Exception e) {
log.warn("", e);
return false;
}
}).collect(toList());
if (filterSkuVOList.size() == 0) {
return false;
}
skuFeedUnitVO.setSkuVOList(filterSkuVOList);
return true;
}).collect(toList());
if (skuFeedUnitVOList.size() == 0) {
log.warn(CameraArCause.No_Valid_Sku_Feed_Unit_List .toMessage(skuResultVO.toString()));
}
skuResultVO.setSkuFeedUnitVOList(skuFeedUnitVOList);
return skuResultVO;
};
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.(2) 在Filter模块中使用遍历器,如果把skuResultVO换成一个返回SkuResultVO的Supplier,是不是有点柯里化的味道啦?
) {
return skuResultIterator.getSkuVOFilterIterator()
.execute(skuResultVO, (FilterFunction<SkuVO>) skuVO -> !CameraArSwitch.Black_List_Config.getArType()
.contains(skuVO.getArType()));
}
1.2.3.4.5.6.整体架构
API & View层:为各类客户端、服务端提供接口Controller层:不同来源的调用适配,权限控制Manager层:每个接口pipeline的各个节点实现、二方和三方包封装Middleware层:集团常见中间件Model层:按照阿里Java规范的各个层级POJOCommon层:自研公共组件,主要是切面类、native命令执行类等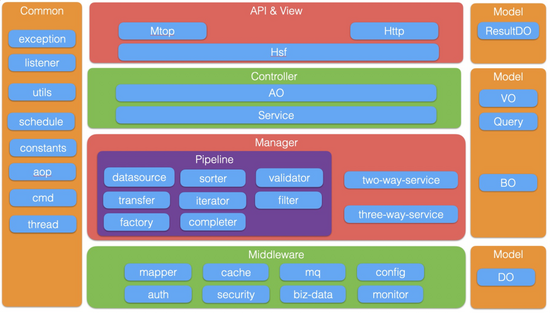
Tips
淘系商品信息补全对于补齐数据源的选择,要详细了解上游各个补齐数据源的业务定位和业务边界,选择合适的补齐数据源。比如淘系商品补全数据源常见服务有以下几个,要根据业务自身需求
数据补齐二方服务
优势
劣势
商品中心(IC)
最底层的数据源,有item和sku维度的信息
维度不够多,比如一些商品的运营信息
阿拉丁
维度比较多,比如商品白底图
只有item维度信息,但是有些数据源不稳定,比如品牌信息有些商品会缺失
搜索的Summary
跟主搜的信息保持一致,信息比较实时,比如优惠、销量信息
只有item维度信息,维度不够多
筛选能力内容下发除了做好个性化,如果是一个公域产品,对内容的筛选能力决定用户是否能主动找到自己想要的商品,我们需要设计一个易扩展的筛选器接口,常见的垂直频道类产品,一级和二级tab页就满足业务诉求,但对应比较大的公域,比如搜索,需要支持多维度筛选+多筛选能力,都需要实现两个接口,这时,我们需要设计一个通用的接口格式,做好两件事。
下发筛选器上传用户选择的筛选项一级和二级tab页只需要下发一级和二级的tab树状接口即可,用户通过先后选择一级和二级tab来过滤内容,这里不作过多的讨论。
多维度筛选器需要下发多维度筛选器,如果有一级Tab,多维度筛选器放在每个Tab内部,例子如下:
1.筛选器下发接口,格式如下,其中Name结尾的字段为前端展示,Id结尾的字段作为筛选上传的接口字段
复制{
"tabList": [
{
"tabName": "tab1",
"tabId": "xxx",
"filterList": [
{
"filterName": "xxx",
"filterId": "xxx",
"filterItemList": [
{
"filterItemName": "fitler1",
"filterItemId": "xxx"},
{
"filterItemName": "fitler2",
"filterItemId": "xxx"}
]
}
]
},
{
"tabName": "tab2",
"tabId": "xxx",
"filterList": [
{
"filterName": "xxx",
"filterId": "xxx",
"filterItemList": [
{
"filterItemName": "fitler1",
"filterItemId": "xxx"},
{
"filterItemName": "fitler2",
"filterItemId": "xxx"}
]
}
]
}
]
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.2.上传用户选择的筛选项,接口格式如下,tabId可以作为单独的字段传,filterList是另外一个字段
复制{
"tabId": "xxx",
"filterList": [
{
"filterId": "xxx",
"filterItemList": [
{
"filterItemId": "xxx"},
{
"filterItemId": "xxx"}
]
},
{
"filterId": "xxx",
"filterItemList": [
{
"filterItemId": "xxx"},
{
"filterItemId": "xxx"}
]
}
]
}
1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.总结和展望
总结本文通过大淘宝业务的例子,梳理出一套内容服务下发内容时面临的问题和挑战、设计一套内容处理链路,用模块化的设计来控制系统的复杂度,并且对接口上线后,如何灵活运维进行了讨论,重点研究了保证易扩展、易运维的思路,希望对各位有所启发。
展望内容下发服务已经有些团队推出了前后端一体的方案,客户端不用请求应用服务来拿商品数据,通过统一的平台接口,把客户端布局和内容填充一起请求来返回,这么做的好处是效率比较高,迭代起来快,带来的不便是客户端和平台耦合比较紧,灵活性变差,比如客户端有一块内容源不走平台,就会比较麻烦