
前文我们介绍了 VictorialMetrics 中是如何接收和传输数据的,接下来我们来分析下当 vmstorage 接收到数据后是如何保存监控指标的。
现在我们使用 csv 来导入一行指标数据,直接使用下面的请求即可:
复制curl-d"GOOG,1.23,4.56,NYSE"http://127.0.0.1:8480/insert/0/prometheus/api/v1/import/csv?format=2:metric:ask,3:metric:bid,1:label:ticker,4:label:market1.
执行上面的请求后,在 vmstorage 组件下面会收到如下所示的一些日志信息:
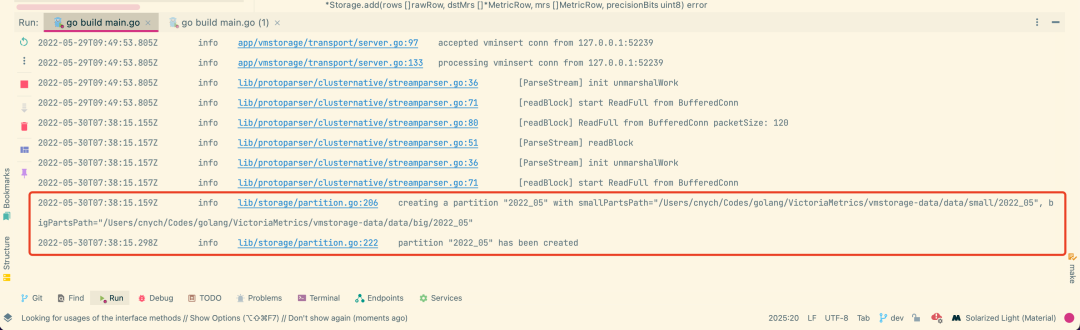
同时在数据目录 vmstorage-data 下面也多了一个 cache 目录,而且 data 下面的 small 目录和 indexdb 目录下面也生成了一些文件,这些文件就是用来存储指标数据的。

接下来我们就来仔细分析下这些文件是干什么的,以及这些文件的存储格式是怎样的。
要想弄明白 vmstorage 是如何去存储数据的,首先我们要先弄明白几个概念。
存储格式
下图是 VictoriaMetrics 支持的 Prometheus 协议的一个写入示例。

VM 在收到写入请求时,会对请求中包含的时序数据做转换处理。首先根据包含 metric 和 labels 的 MetricName 生成一个唯一标识 TSID,然后 metric(指标名称__name__) + labels + TSID 作为索引 index,TSID + timestamp + value 作为数据 data,最后索引 index 和数据 data 分别进行存储和检索。
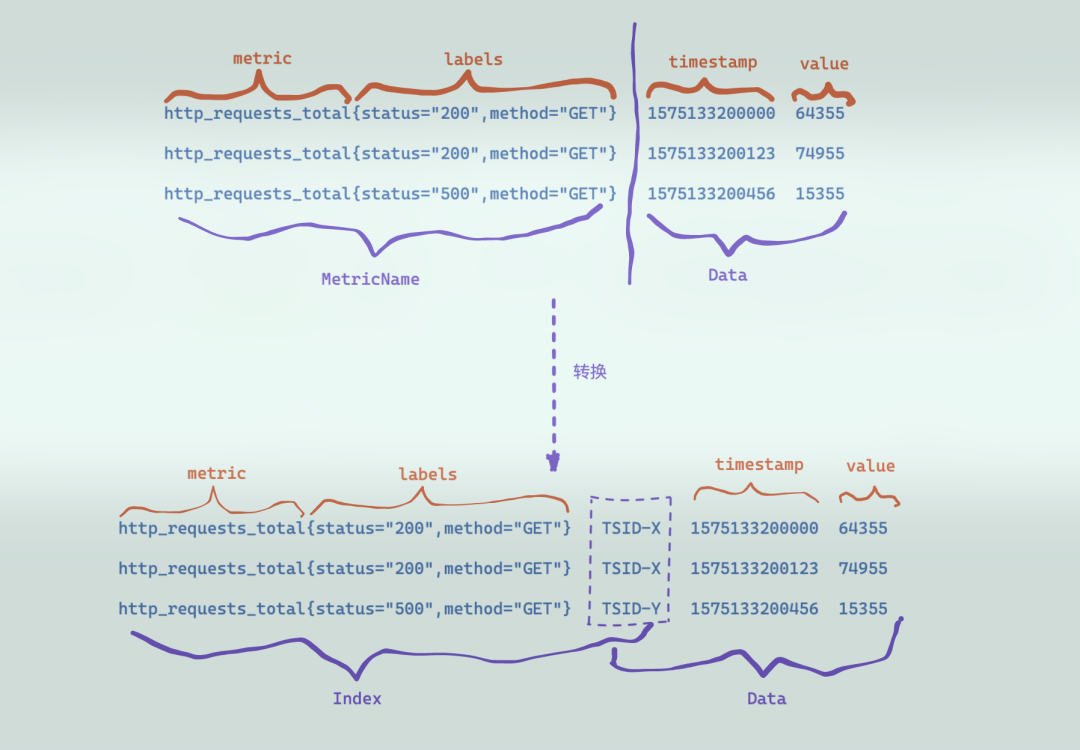
因此 VM 的数据整体上分成索引和数据两个部分,因此文件格式整体上会有两个部分,其中索引部分主要是用于支持按照 label 或者 tag 进行多维检索,数据存储时,先将数据按 TSID 进行分组,然后每个 TSID 包含的数据点各自使用列式压缩存储。
TSID
VictoriaMetrics 的 MetricName 的结构如下所示,包含 MetricGroup(指标名称 __name__) 和 Tag 数组,其中,Tags 是可选的,每个 Tag 由 Key 和 Value 等字节数组构成。
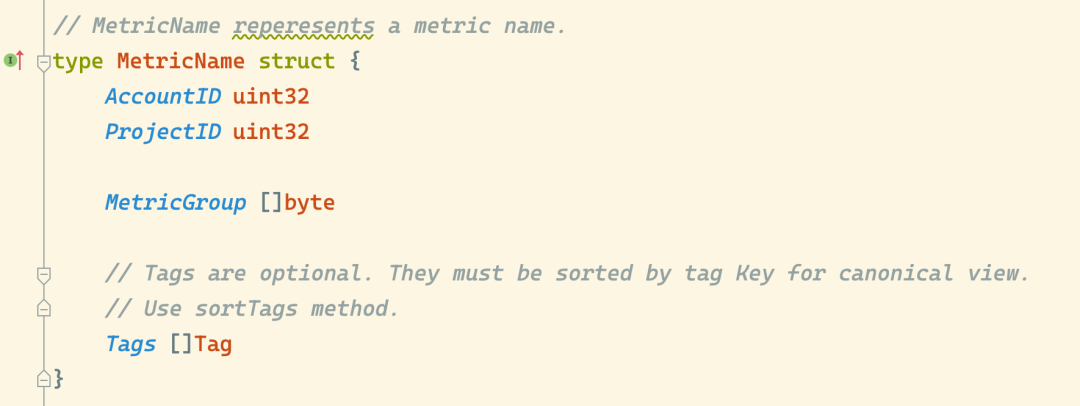
为了规范,Tags 必须按标签 Key 排序,使用 sortTags 方法。
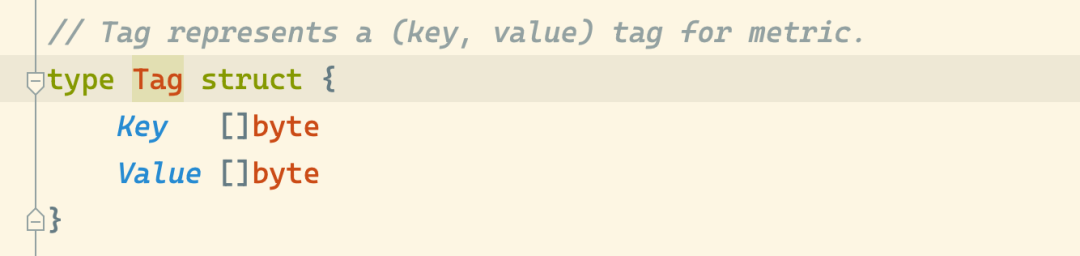
VictoriaMetrics 的 TSID 的结构如下所示,包含 MetricGroupID、JobID、InstanceID、MetricID 等几个字段,其中除了 MetricID 外,其他字段都是可选的。这个几个 ID 的生成方法如下:
MetricGroupID 是根据MetricName 中的MetricGroup 使用xxhash 的 sum64 算法生成。JobID 和InstanceID 分别由MetricName 中的第一个 tag 和第二个 tag 使用xxhash 的 sum64 算法生成。为什么使用第一个 tag 和第二个 tag?这是因为 VictoriaMetrics 在写入时,将写入请求中的 JobID 和 InstanceID 放在了 Tag 数组的第一个和第二个位置。MetricID,使用 VictoriaMetrics 进程启动时的系统纳秒时间戳自增生成。
复制
//lib/storage/tsid.go//TSID是一个时间序列的唯一ID,实际上就是唯一标识一个时间序列的结构体。////时间序列会根据TSID进行排序。////除了MetricID之外其他属性都是可选的。它们的存在仅仅是为了更好地对相关指标进行分组。//如果它们的含义与它们的命名不同,那也没关系。typeTSIDstruct{ AccountIDuint32 ProjectIDuint32//下面分析的时候可以暂时忽略这两个属性,用于多租户标识的属性 //MetricGroupID(指标组ID)对于指定的(AccountID,ProjectID)必须是唯一的。 // //MetricGroup包含具有相同名称的指标,例如“memory_usage”、“http_requests”,但具有不同的标签。 //例如,下面的这些指标属于memory_usage这个指标组
:
// //memory_usage{datacenter=
"foo1",job=
"bar1",instance=
"baz1:
1234"} //memory_usage{datacenter=
"foo1",job=
"bar1",instance=
"baz2:
1234"} //memory_usage{datacenter=
"foo1",job=
"bar2",instance=
"baz1:
1234"} //memory_usage{datacenter=
"foo2",job=
"bar1",instance=
"baz2:
1234"} MetricGroupIDuint64 //JobID是给定项目的单个作业(又名服务)的ID。 // //JobID对于指定的(AccountID,ProjectID)必须是唯一的。 // //一个Job任务可能由多个实例组成。 //Seehttps:
//prometheus.io/docs/concepts/jobs_instances/fordetails. JobIDuint32 //InstanceID是实例(进程)ID,对于特定的(AccountID,ProjectID)必须是唯一的。 InstanceIDuint32 //MetricID是指标(时间序列)的唯一ID。 // //其他所有的TSID字段都可以通过MetricID获取。 MetricIDuint64}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.
因为 TSID 中除了 MetricID 外,其他字段都是可选的,因此 TSID 中可以始终作为有效信息的只有 MetricID,因此 VictoriaMetrics 的在构建 tag 到 TSID 的字典过程中,是直接存储的 tag 到 MetricID 的字典。
以写入 http_requests_total{status="200", method="GET"} 为例,则 MetricName 为 http_requests_total{status="200", method="GET"},假设生成的 TSID 为 {metricGroupID=0, jobID=0, instanceID=0, metricID=51106185174286},则 VictoriaMetrics 在写入时就构建了如下几种类型的索引 item,其他类型的索引 item 是在后台或者查询时构建的。
metricName -> TSID, 即http_requests_total{status="200", method="GET"} -> {metricGroupID=0, jobID=0, instanceID=0, metricID=51106185174286}。metricID -> metricName,即51106185174286 -> http_requests_total{status="200", method="GET"}。metricID -> TSID,即51106185174286 -> {metricGroupID=0, jobID=0, instanceID=0, metricID=51106185174286}。tag -> metricID,即status="200" -> 51106185174286、method="GET" -> 51106185174286、"__name__" = http_requests_total -> 51106185174286(其实还有一个联合索引)。
有了这些索引的 item 后,就可以支持基于 tag 的多维检索了,在当给定查询条件 http_requests_total{status="200"} 时,VictoriaMetrics 先根据给定的 tag 条件,找出每个 tag 的 metricID 列表,然后计算所有 tag 的 metricID 列表的交集,然后根据交集中的 metricID,再到索引文件中检索出 TSID,根据 TSID 就可以到数据文件中查询数据了,在返回结果之前,再根据 TSID 中的 metricID,到索引文件中检索出对应的写入时的原始 MetircName。
但是由于 VictoriaMetrics 的 tag 到 metricID 的字典,没有将相同 tag 的所有 metricID 放在一起存储,在检索时,一个 tag 可能需要查询多次才能得到完整的 metricID 列表。另外查询出 metricID 后,还要再到索引文件中去检索 TSID 才能去数据文件查询数据,又增加了一次 IO 开销。这样来看的话,VictoriaMetrics 的索引文件在检索时,如果命中的时间线比较多的情况下,其 IO 开销会比较大,查询延迟也会比较高。
这里我们了解了 TSID 这个非常重要的概念,还有几个结构体需要我们了解下,比如 rawRow 表示一个原始的时间序列行,MetricRow 表示插入到存储中的指标数据:
复制//lib/storage/raw_row.go//rawRow表示一个原始的时间序列行typerawRowstruct{ TSIDTSID//时间序列ID Timestampint64//时间戳 Valuefloat64//给定时间戳的时间序列值 //PrecisionBits是要存储的值中的有效位数,可能值为[1..64] //1表示最大.50%error,2-25%,3-12.5%,64没有错误,i.e. //存储的值不会丢失精度 PrecisionBitsuint8}//libe/storage/storage.go//MetricRow插入到存储中的指标typeMetricRowstruct{ //MetricNameRaw包含原始的指标名称,必须使用metricne.UnmarshalRaw对其进行解码。 MetricNameRaw[]byte Timestampint64 Valuefloat64}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
插入指标
有了上面几个概念的认识,现在我们回过头再去看下 vmstorage 中对 vminsert 请求的处理:
复制//app/vmstorage/transport/server.gofunc(s*Server)processVMInsertConn(bc*handshake.BufferedConn)error{ returnclusternative.ParseStream(bc,func(rows[]storage.MetricRow)error{ vminsertMetricsRead.Add(len(rows)) returns.storage.AddRows(rows,uint8(*precisionBits)) },s.storage.IsReadOnly)}1.2.3.4.5.6.7.
当 vmstorage 节点接收到数据后,最后会通过回调执行 s.storage.AddRows(rows, uint8(*precisionBits)),该函数将数据添加到底层存储去:
复制
//lib/storage/storage.go//AddRows添加mrs集合到存储sfunc(s*Storage)AddRows(mrs[]MetricRow,precisionBitsuint8)error{ iflen(mrs)==
0{ returnnil } //限制可能向存储添加行的并发goroutine数量 //当太多的goroutine调用AddRows时,这应该可以防止内存不足错误和CPU抖动。 select{ //如果写入channel成功,说明并发小于CPU最大核数,然后就可以走插入逻辑 //如果没写入成功(也就是满了),则执行defaultcase caseaddRowsConcurrencyCh<-struct{}{}
:
default:
//如果插入channel失败,说明某个insert操作的协程被阻塞,这时需要通知select协程去让出。 atomic.AddUint64(&s.addRowsConcurrencyLimitReached,1) t:=
timerpool.Get(addRowsTimeout)//获取一个30s超时的timer //数据摄取优先级高于并发搜索 //pacelimiter(步长限制器)中有个原子累加的变量,表示有多少个insert操作在等待 //走到这里证明有一个insert操作被阻塞了,调用Inc,表示需要(Search操作)等待 storagepacelimiter.Search.Inc() select{//写入不成功或者还未超时就会阻塞在这里了 //在超时的30s时间内,尝试去写入channel队列 caseaddRowsConcurrencyCh<-struct{}{}
:
timerpool.Put(t)//把timer放回对象池,减少GC //可以成功写入channel了,那么可以执行insert操作了,则执行限制器的Dec操作,减一 storagepacelimiter.Search.Dec() //当限制器的等待数量为0的时候,会调用cond.Broadcast()去通知select协程开始工作。 case<-t.C:
//到30s超时时间了 //把timer放回对象池,减少GCtimerpool.Put(t) //超时了那么当前的insert就报错了,等待的数量就可以减一了 storagepacelimiter.Search.Dec() atomic.AddUint64(&s.addRowsConcurrencyLimitTimeout,1)//记录下超时次数 atomic.AddUint64(&s.addRowsConcurrencyDroppedRows,uint64(len(mrs)))//记录没有被插入成功的mr数量 //等待了30秒仍然没有CPU资源,只能报错 returnfmt.Errorf("cannotadd%drowstostoragein%s,sinceitisoverloadedwith%dconcurrentwriters;addmoreCPUsorreduceload", len(mrs),addRowsTimeout,cap(addRowsConcurrencyCh)) } } //下面是插入逻辑 //一次插入不要太大 varfirstErrerror ic:=
getMetricRowsInsertCtx() maxBlockLen:=
len(ic.rrs) forlen(mrs)>0{ mrsBlock:=
mrs //如果要插入的mrs超过了最大长度 iflen(mrs)>maxBlockLen{ //则先插入最大长度的mrsmrsBlock=
mrs[:
maxBlockLen] //剩下的mrs下次循环去处理 mrs=
mrs[maxBlockLen:
] }else{ mrs=
nil } //执行真正的add操作 iferr:=
s.add(ic.rrs,ic.tmpMrs,mrsBlock,precisionBits);err!=
nil{ iffirstErr==
nil{ firstErr=
err } continue } //记录下插入成功的mrs数量 atomic.AddUint64(&rowsAddedTotal,uint64(len(mrsBlock))) } //放回对象池 putMetricRowsInsertCtx(ic) <-addRowsConcurrencyCh//insert逻辑执行完成后,出队 returnfirstErr}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.
该函数的实现非常经典,会限制可能向存储添加数据的并发 goroutine 数量,当太多的 goroutine 调用 AddRows 时,可以防止内存不足错误和 CPU 抖动。这里实现了插入比查询更高的优先级,当资源不足时,查询操作会挂起让出资源给到插入操作使用。
获取 TSID
真正实现添加数据是下面的 add 函数,其中 rawRow 是原始的时序数据行,MetricRow 是要插入到存储中的行数据,该函数的核心就是要生成指标序列的 TSID 数据,如下所示:
复制//lib/storage/storage.gofunc(s*Storage)add(rows[]rawRow,dstMrs[]*MetricRow,mrs[]MetricRow,precisionBitsuint8)error{ //当前使用的索引 idb:=s.idb() j:=0 var( //这些变量用于加速同一metricName的多个相邻行的批量导入。 prevTSIDTSID prevMetricNameRaw[]byte ) varpmrs*pendingMetricRows //获取该数据块的最小时间和最大时间 minTimestamp,maxTimestamp:=s.tb.getMinMaxTimestamps() //带有第几代索引信息的TSID对象 vargenTSIDgenerationTSID //只返回第一个错误,因为它返回所有错误没有意义 varfirstWarnerror //循环数据行,其实就是填充rawRow中的TSID数据 fori:=rangemrs{ mr:=&mrs[i] ifmath.IsNaN(mr.Value){//值为NaN if!decimal.IsStaleNaN(mr.Value){ //跳过Prometheusstaleness标记以外的NaN //因为底层编码不知道如何使用它们。 continue } } //如果指标的时间戳小于最小的时间戳 //则跳过保留期外时间戳过小的行 ifmr.Timestamp<minTimestamp{ ...... continue } //同样跳过超过最大时间戳的数据 ifmr.Timestamp>maxTimestamp{ ...... continue } dstMrs[j]=mr r:=&rows[j] j++ r.Timestamp=mr.Timestamp r.Value=mr.Value r.PrecisionBits=precisionBits //快速路径-当前mr包含与前一mr相同的指标名称,因此它包含相同的TSID。 ifstring(mr.MetricNameRaw)==string(prevMetricNameRaw){ //当许多行包含相同的MetricNameRaw时,应在批量导入时触发此路径。 r.TSID=prevTSID continue } //判断TSID是否在缓存中(命中缓存) ifs.getTSIDFromCache(&genTSID,mr.MetricNameRaw){ r.TSID=genTSID.TSID //跳过该行,因为已超出唯一序列数的限制。 ifs.isSeriesCardinalityExceeded(r.TSID.MetricID,mr.MetricNameRaw){ j-- continue } //快速路径-给定MetricNameRaw的TSID已在缓存中找到,并且未删除。 //不需要检查r.TSID.MetricID是否已删除,因为tsidCache不包含已删除时间序列的MetricName->TSID条目,可以查看Storage.DeleteMetrics的代码 prevTSID=r.TSID//设置前一个TSID的值 prevMetricNameRaw=mr.MetricNameRaw//设置前一个MetricNameRaw的值 //找到的TSID不是当前代的索引(来自上一代缓存下来的索引) ifgenTSID.generation!=idb.generation{ //索引需要尝试使用该TSID重新填充当前代的索引数据 //https://github.com/VictoriaMetrics/VictoriaMetrics/issues/1401 created,err:=idb.maybeCreateIndexes(&genTSID.TSID,mr.MetricNameRaw) iferr!=nil{ returnfmt.Errorf("cannotcreateindexesinthecurrentindexdb:%w",err) } ifcreated{ //如果填充成功,则将当前的TSID设置为当前代索引 genTSID.generation=idb.generation //重新将该TSID->MetricNameRaw数据放回缓存,方便后面的序列处理 s.putTSIDToCache(&genTSID,mr.MetricNameRaw) } } continue } //慢速路径-缓存中缺少TSID //在下面的循环中推迟搜索 j-- ifpmrs==nil{ //初始化pendingMetricRows pmrs=getPendingMetricRows() } //将mr数据添加到pendingMetricRows中去待处理 iferr:=pmrs.addRow(mr);err!=nil{ //错误时不要停止添加数据-只需跳过无效行即可。 //这保证了无效行不会阻止将有效行添加到存储中去。 iffirstWarn==nil{ firstWarn=err } continue } } //有指标的TSID没有在缓存中(上面的慢速路径) ifpmrs!=nil{ //按指标名称对pendingMetricRows进行排序,以便通过下面循环中的“is”加快搜索速度。 pendingMetricRows:=pmrs.pmrs sort.Slice(pendingMetricRows,func(i,jint)bool{ returnstring(pendingMetricRows[i].MetricName)<string(pendingMetricRows[j].MetricName) }) // is:=idb.getIndexSearch(0,0,noDeadline) prevMetricNameRaw=nil//接收前一个MetricNameRaw varslowInsertsCountuint64 fori:=rangependingMetricRows{ pmr:=&pendingMetricRows[i] mr:=pmr.mr//MetricRaw dstMrs[j]=mr r:=&rows[j] j++ r.Timestamp=mr.Timestamp r.Value=mr.Value r.PrecisionBits=precisionBits //快速路径-当前mr包含与前一个mr相同的指标名称,因此它包含相同的TSID。 ifstring(mr.MetricNameRaw)==string(prevMetricNameRaw){ //当许多行包含相同的MetricNameRaw时,在批量导入时会触发该路径。 r.TSID=prevTSID ifs.isSeriesCardinalityExceeded(r.TSID.MetricID,mr.MetricNameRaw){ //跳过该行,因为已超出唯一序列数的限制 j-- continue } continue } //慢速路径 slowInsertsCount++//记录慢插入次数 //通过MetricName去获取(没有就创建)TSID数据 iferr:=is.GetOrCreateTSIDByName(&r.TSID,pmr.MetricName);err!=nil{ iffirstWarn==nil{ firstWarn=fmt.Errorf("cannotobtainorcreateTSIDforMetricName%q:%w",pmr.MetricName,err) } j-- continue } //设置genTSID为当前生成的TSID genTSID.generation=idb.generation genTSID.TSID=r.TSID //返回缓存 s.putTSIDToCache(&genTSID,mr.MetricNameRaw) //缓存当前的TSID和MetricNameRaw,方便下一条序列快速处理 prevTSID=r.TSID prevMetricNameRaw=mr.MetricNameRaw ifs.isSeriesCardinalityExceeded(r.TSID.MetricID,mr.MetricNameRaw){ //跳过该行,因为已超出唯一序列数的限制 j-- continue } } //回收对象 idb.putIndexSearch(is) putPendingMetricRows(pmrs) atomic.AddUint64(&s.slowRowInserts,slowInsertsCount) } //提示错误信息 iffirstWarn!=nil{ logger.WithThrottler("storageAddRows",5*time.Second).Warnf("warnoccurredduringrowsaddition:%s",firstWarn) } dstMrs=dstMrs[:j] rows=rows[:j] //TSID填充完成,可以插入数据了 varfirstErrorerror iferr:=s.tb.AddRows(rows);err!=nil{ firstError=fmt.Errorf("cannotaddrowstotable:%w",err) } iferr:=s.updatePerDateData(rows,dstMrs);err!=nil&&firstError==nil{ firstError=fmt.Errorf("cannotupdateper-datedata:%w",err) } iffirstError!=nil{ returnfmt.Errorf("erroroccurredduringrowsaddition:%w",firstError) } returnnil}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.98.99.100.101.102.103.104.105.106.107.108.109.110.111.112.113.114.115.116.117.118.119.120.121.122.123.124.125.126.127.128.129.130.131.132.133.134.135.136.137.138.139.140.141.142.143.144.145.146.147.148.149.150.151.152.153.154.155.156.157.158.159.160.161.162.163.164.165.166.167.168.169.170.171.172.173.174.175.176.177.178.179.180.
首先循环数据,把时间戳过小或过大的都过滤掉,然后就是想办法尽可能快地获取到指标的 TSID:
快速路径- 当前 MetricRow 包含与前一 MetricRow 相同的指标名称,因此它们具有相同的 TSID,所以直接将当前对象的 TSID 设置成前一个 TSID,这是最快的方式。如果和前一个指标名称不一样,则去查看 genTSID 是否在缓存中(命中缓存)。如果命中缓存则 genTSID 中的 TSID 就是我们需要的,同时也将其设置为前一个 prevTSID。如果该 TSID 不是当代的索引(来自上一代缓存下来的索引),则需要尝试使用该 TSID 重新填充当代的索引数据,这和索引轮换有关,后面会详细说明。如果没有命中缓存,则属于慢速路径,将当前数据添加到pendingMetricRows 中去待处理。循环了所有指标数据后,接下来需要处理pendingMetricRows 中的数据,也就是缓存中没有对应的 TSID,此时就需要我们去生成对应的 TSID 数据。快速路径- 同样是当前 MetricRow 与前一个 MetricRow 的指标名称相同,因此它包含相同的 TSID,直接设置成前一个 TSID 即可。慢速路径- 走到这个分支则只能去创建 TSID 了,通过 MetricName 去获取(没有就创建)TSID 数据,也就是上面GetOrCreateTSIDByName 函数。获取后记得放到缓存中去。
上面费了很大的功夫就是为了获取时间序列对应的 TSID 数据的,这也是插入数据过程中最可能出现慢插入的地方,因为该过程涉及到索引,比较耗时间,如果你插入的数据出现大量的高基数序列(比如包含一些随机生成的 ID 作为标签),则会大大降低 vmstorage 的插入性能。
我们可以去查看下 GetOrCreateTSIDByName 函数的实现。
复制//lib/storage/index_db.go//GetOrCreateTSIDByName使用指定metricName的TSID填充dst。func(is*indexSearch)GetOrCreateTSIDByName(dst*TSID,metricName[]byte)error{ //hack:在多次连续未命中后跳过TSID的搜索 //这将提高大批量新时间序列的插入性能。 ifis.tsidByNameMisses<100{ err:=is.getTSIDByMetricName(dst,metricName) iferr==nil{ is.tsidByNameMisses=0 returnnil } iferr!=io.EOF{ returnfmt.Errorf("cannotsearchTSIDbyMetricName%q:%w",metricName,err) } is.tsidByNameMisses++ }else{ is.tsidByNameSkips++ ifis.tsidByNameSkips>10000{ is.tsidByNameSkips=0 is.tsidByNameMisses=0 } } //找不到给定名称的TSID,创建它。 //如果mn的重复TSID是由并发goroutines创建的,那么这也是可以的。 //指标结果将在表搜索TableSearch后由mn合并。 iferr:=is.db.createTSIDByName(dst,metricName);err!=nil{ returnfmt.Errorf("cannotcreateTSIDbyMetricName%q:%w",metricName,err) } returnnil}//根据metricName去搜索TSIDfunc(is*indexSearch)getTSIDByMetricName(dst*TSID,metricName[]byte)error{ dmis:=is.db.s.getDeletedMetricIDs() ts:=&is.ts//TableSearch kb:=&is.kb kb.B=append(kb.B[:0],nsPrefixMetricNameToTSID)//MetricName->TSID的前缀 kb.B=append(kb.B,metricName...) kb.B=append(kb.B,kvSeparatorChar) ts.Seek(kb.B)//Seek查找ts中大于或等于k的第一项 forts.NextItem(){//循环查找 if!bytes.HasPrefix(ts.Item,kb.B){//ts.Item不是以kb.B为前缀 //没找到 returnio.EOF } v:=ts.Item[len(kb.B):]//获得尾部的值 tail,err:=dst.Unmarshal(v)//填充dst iferr!=nil{ returnfmt.Errorf("cannotunmarshalTSID:%w",err) } iflen(tail)>0{//尾部还有值 returnfmt.Errorf("unexpectednon-emptytailleftafterunmarshalingTSID:%X",tail) } ifdmis.Len()>0{//有标记删除的MetricID列表 //验证dst是否标记为已删除。 ifdmis.Has(dst.MetricID){ //dst被删除了,继续搜索。 continue } } //找到了有效的dst returnnil } iferr:=ts.Error();err!=nil{ returnfmt.Errorf("errorwhensearchingTSIDbymetricName;searchPrefix%q:%w",kb.B,err) } //什么都没发现 returnio.EOF}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.
该函数会获取 metricName 对应的 TSID,但是可能会出现多次连续未命中的情况,为了提高性能,这里做了一点 hack,如果连续未查询到 TSID 100 次则跳过搜索,就只能去创建 TSID 了,如果跳过了 10000 次则又重置可以重新去搜索。
搜索 TSID 是通过下面的 getTSIDByMetricName 函数来实现的,创建 TSID 是通过 createTSIDByName 函数实现的。
TSID 的生成方法如下所示:
复制//lib/storage/index_db.go//根据指定的metricName创建TSIDfunc(db*indexDB)createTSIDByName(dst*TSID,metricName[]byte)error{ mn:=GetMetricName() deferPutMetricName(mn) iferr:=mn.Unmarshal(metricName);err!=nil{ returnfmt.Errorf("cannotunmarshalmetricName%q:%w",metricName,err) } //创建TSID created,err:=db.getOrCreateTSID(dst,metricName,mn) iferr!=nil{ returnfmt.Errorf("cannotgenerateTSID:%w",err) } //TSID创建后要创建索引,这一步是最耗时的 iferr:=db.createIndexes(dst,mn);err!=nil{ returnfmt.Errorf("cannotcreateindexes:%w",err) } //不需要使tag缓存无效,因为它在db上无效,tb通过传递给OpenTable的invalidateTagFiltersCacheflushCallback刷新。 ifcreated{ //仅当indexDB中未找到tsid时,才增加newTimeseriesCreated计数器 atomic.AddUint64(&db.newTimeseriesCreated,1) iflogNewSeries{ logger.Infof("newseriescreated:%s",mn.String()) } } returnnil}//getOrCreateTSID在db.extDB中查找指定metricName的TSID//如果找不到任何内容,则创建新的TSID////如果TSID已创建,则返回true;如果TSID在extDB中,则返回falsefunc(db*indexDB)getOrCreateTSID(dst*TSID,metricName[]byte,mn*MetricName)(bool,error){ //在外部存储中搜索TSID //这个db通常来自上一个时期 varerrerror //相当于去上一个索引db中查找TSID ifdb.doExtDB(func(extDB*indexDB){ err=extDB.getTSIDByNameNoCreate(dst,metricName) }){ iferr==nil{ //已在外部存储中找到TSID returnfalse,nil } iferr!=io.EOF{ returnfalse,fmt.Errorf("externalsearchfailed:%w",err) } } //在外部存储中找不到TSID,在本地生成。 generateTSID(dst,mn) returntrue,nil}//生成TSID数据funcgenerateTSID(dst*TSID,mn*MetricName){ dst.AccountID=mn.AccountID dst.ProjectID=mn.ProjectID //根据MetricName中的MetricGroup使用xxhash的sum64算法生成。 dst.MetricGroupID=xxhash.Sum64(mn.MetricGroup) //假设job-likemetric放在mn.Tags[0],而instance-likemetric放在mn.Tags[1] //这个假设是正确的,因为mn.Tags必须在调用generateTSID()函数之前使用mn.sortTags()进行排序。 //这允许对磁盘上彼此靠近的相同(job、instance)的数据块进行分组。 //当从磁盘读取相同job和/或instance的数据块时,这会减少磁盘寻道和磁盘读取IO。 //例如,与`process_resident_memory_bytes{job="vmstorage"}`匹配的时间序列的数据块在磁盘上是物理相邻的。 iflen(mn.Tags)>0{ dst.JobID=uint32(xxhash.Sum64(mn.Tags[0].Value))//第一个Tag规定为JobID } iflen(mn.Tags)>1{ dst.InstanceID=uint32(xxhash.Sum64(mn.Tags[1].Value))//第二个Tag规定为InstanceID } dst.MetricID=generateUniqueMetricID()//生成唯一的指标ID}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.
MetricID 通过 generateUniqueMetricID() 生成, 在重启时, nextUniqueMetricID 被赋值为当时的时间戳, 随后每次新的 TSID 的创建都会在此基础之上+1。
复制//lib/storage/index_db.go//生成唯一的MetricIDfuncgenerateUniqueMetricID()uint64{ //期望的是从此函数返回的metricID必须是密集的。 //如果它们是稀疏的,那么这可能会损害metric_ids与uint64set.Set的交集性能。 returnatomic.AddUint64(&nextUniqueMetricID,1)}//该数在重新启动时不能倒退,否则可能会发生metricID冲突。//所以不要在VictoriaMetrics重新启动期间更改服务器上的时间。varnextUniqueMetricID=uint64(time.Now().UnixNano())1.2.3.4.5.6.7.8.9.10.
但是我们可能在这里看不懂 TSID 是如何去搜索或者创建的,这就需要我们去了解下 VM 中的倒排索引了。
倒排索引
当创建完 TSID 后, 需要建立一系列的索引供查找时使用。在 VM 中不同类型的索引都是通过 KV 关系来描述,在代码中称为 Item , Item 的结构如下:
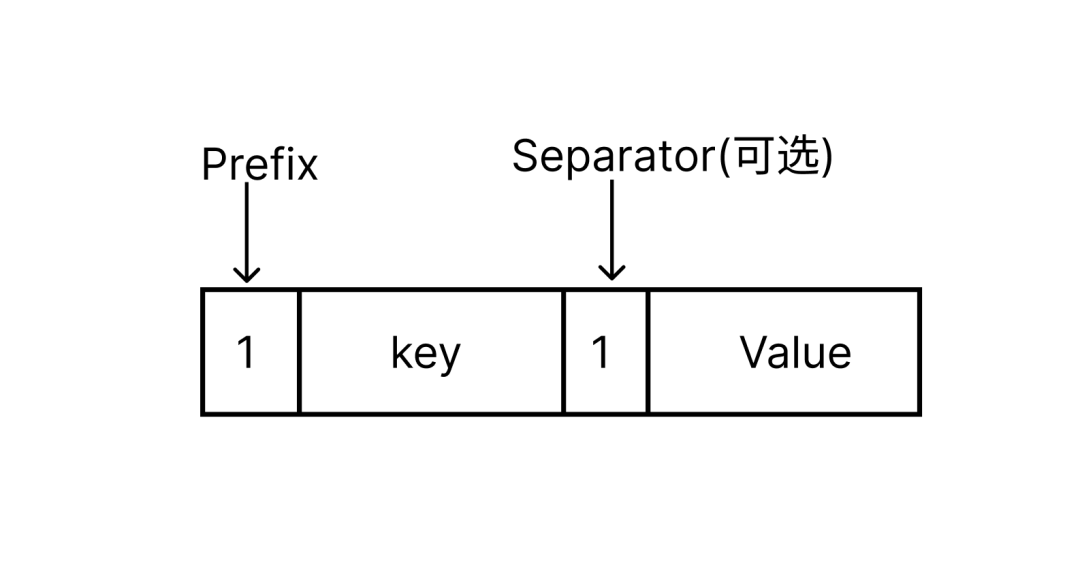
在 VM 中 Item 的整体上是一个 KV 结构的字节数组,共计有 7 种类型,每种类型的 Item 通过固定前缀来区分,前缀类型如下图所示。

在 storage/index_db.go: createIndexes 函数中,去分别建立了各个索引,生成 Items,代码如下所示:
复制//lib/storage/index_db.go//创建索引func(db*indexDB)createIndexes(tsid*TSID,mn*MetricName)error{ //索引items的顺序很重要,它保证了索引的一致性。 ii:=getIndexItems() deferputIndexItems(ii) //创建MetricName->TSID的索引。 ii.B=append(ii.B,nsPrefixMetricNameToTSID)//前缀 ii.B=mn.Marshal(ii.B) ii.B=append(ii.B,kvSeparatorChar)//分隔符 ii.B=tsid.Marshal(ii.B) ii.Next() //创建MetricID->MetricName索引。 ii.B=marshalCommonPrefix(ii.B,nsPrefixMetricIDToMetricName,mn.AccountID,mn.ProjectID) ii.B=encoding.MarshalUint64(ii.B,tsid.MetricID) ii.B=mn.Marshal(ii.B) ii.Next() //创建MetricID->TSID索引 ii.B=marshalCommonPrefix(ii.B,nsPrefixMetricIDToTSID,mn.AccountID,mn.ProjectID) ii.B=encoding.MarshalUint64(ii.B,tsid.MetricID) ii.B=tsid.Marshal(ii.B) ii.Next() //创建Tag->MetricID索引 prefix:=kbPool.Get() prefix.B=marshalCommonPrefix(prefix.B[:0],nsPrefixTagToMetricIDs,mn.AccountID,mn.ProjectID) ii.registerTagIndexes(prefix.B,mn,tsid.MetricID) kbPool.Put(prefix) //将Items添加到Table中去 returndb.tb.AddItems(ii.Items)}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.
对于 ask{market="NYSE",ticker="GOOG"} 1.23 的时序指标,对应的 MetricName 为 AccountID=0, ProjectID=0, ask{market="NYSE",ticker="GOOG"},假设生成的 TSID 为:
复制{ AccountID:0 ProjectID:0 MetricGroupID:6661248876682682060 JobID:3817370224 InstanceID:4166188337 MetricID:1654132102944898001}1.2.3.4.5.6.7.8.
则生成的索引 Item 逻辑结构如下图所示:

上图为构建的 MetricName -> TSID 的索引,前缀为 nsPrefixMetricNameToTSID=0,整个索引项就是一个 key: value 的形式,key 为 MetricName 编码后的值,value 为 TSID 编码后的值,中间通过一个 kvSeparator 的分隔符进行连接,当然这些值真正的存储形式都是 []byte。除了上图的这个索引之外还有几个其他的索引:MetricID -> MetricName、MetricID -> TSID、Tag -> MetricID,方式都是一样的,只是要注意每种索引的前缀是不一样的。最后得到的索引就是上面构建的几种索引的集合数组。
索引构建完成后又是如何去持久化数据的呢?保存的数据又是怎样的格式呢?