Spring Boot + Redis Streams :构建高效消息系统
前言
在现代微服务架构中,可靠的消息处理系统是保证系统高可用性和扩展性的关键。Redis Streams作为Redis 5.0引入的强大功能,提供了一种日志数据结构,能够高效地处理消息队列和流数据。
简介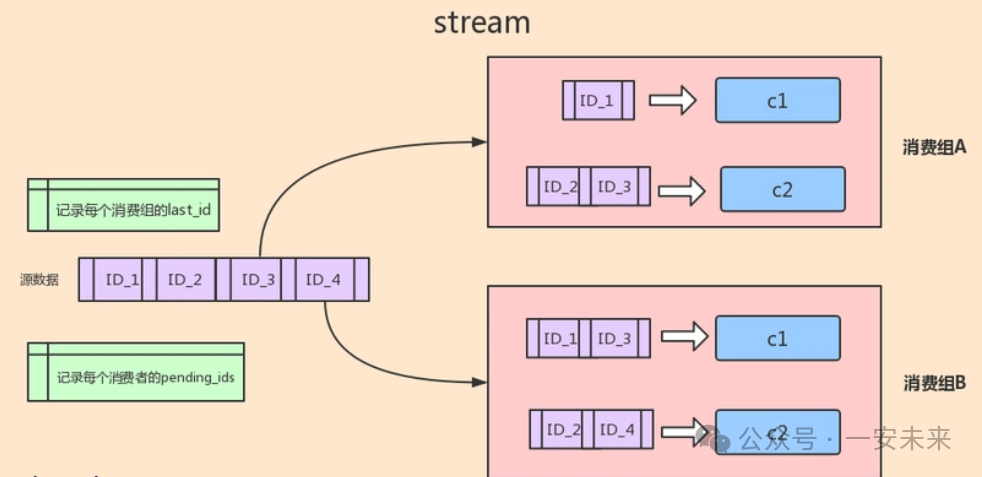 图片
图片
Redis Streams是一种日志数据结构,类似于Apache Kafka中的分区日志,提供了持久化、可回溯、消息分组等特性。它支持生产者消费者模型,允许生产者将消息追加到流的末尾,消费者从流中读取消息进行处理。
Redis Streams的主要特性包括:
消息持久化:消息存储在Redis内存中,并可通过持久化策略(如 RDB、AOF)保证数据不丢失。消息分组:支持将消费者划分为不同的分组,每个分组可以独立消费消息,实现消息的并行处理。消息确认机制:消费者处理完消息后,可以向流发送确认消息,确保消息不会被重复处理。消息回溯:可以从任意位置读取消息,支持历史消息的查询和重放。效果图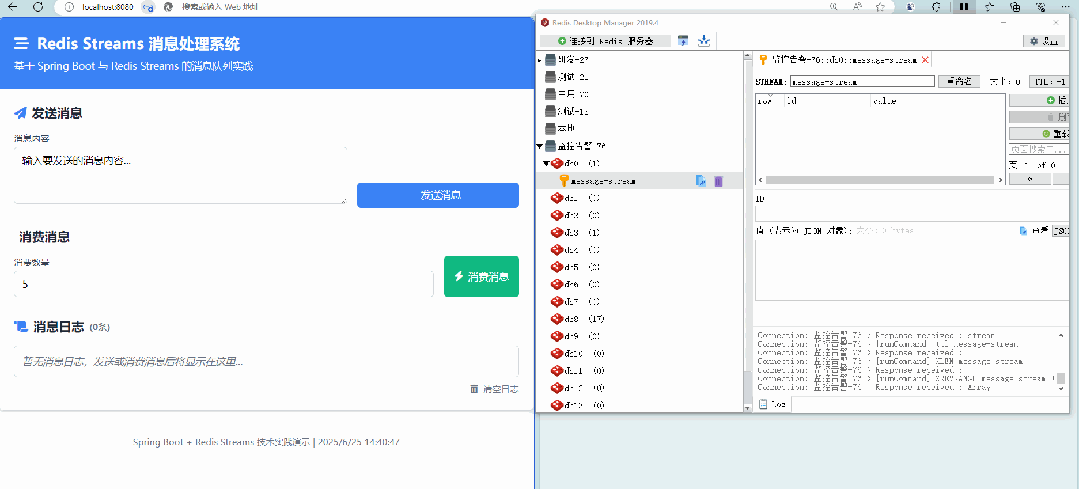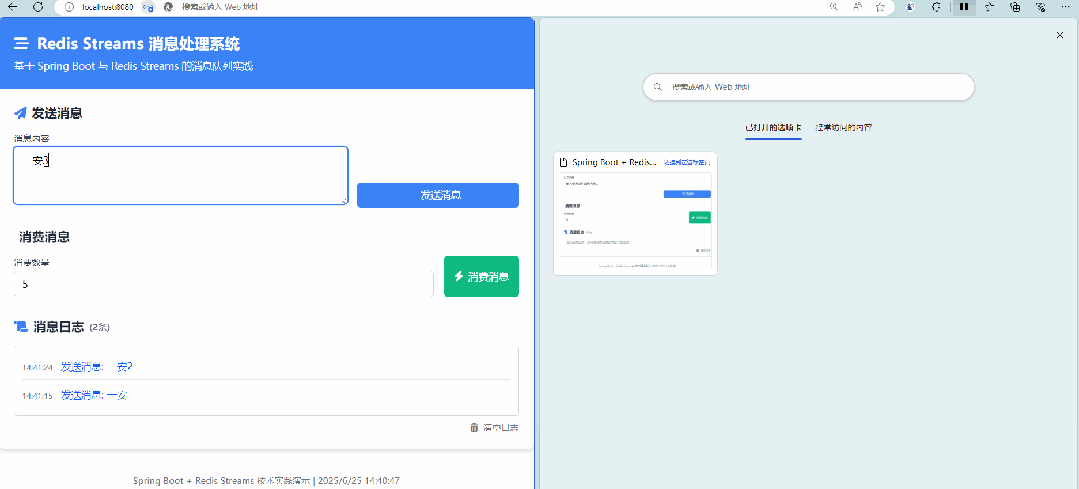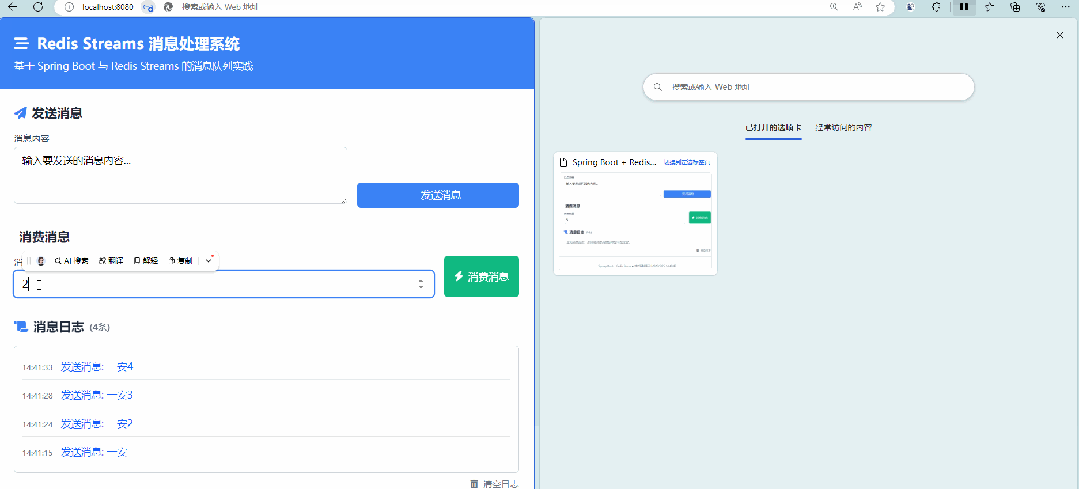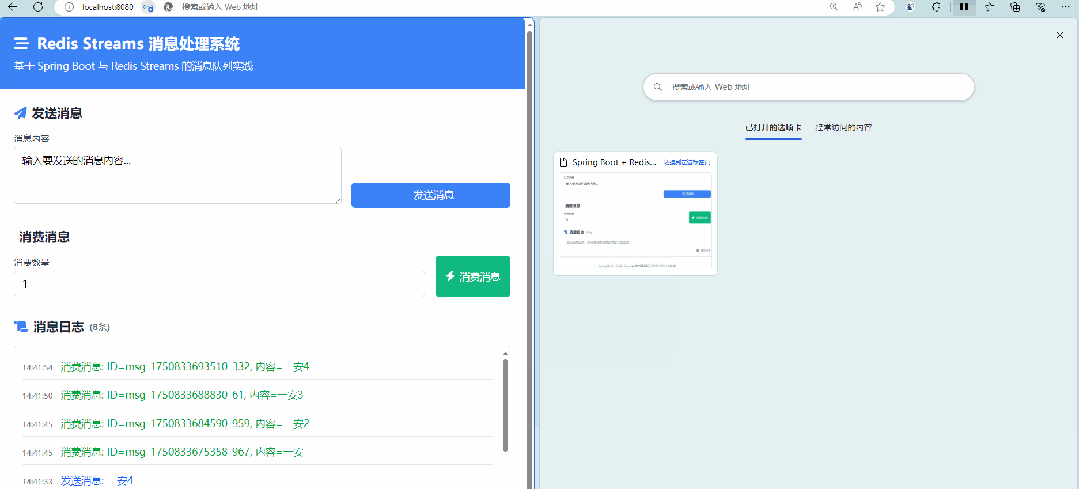 图片
图片
消息生产与消费实践
创建消息实体类复制
@Data
public class Message implements Serializable {
private String id;
private String content;
}1.2.3.4.5.
复制
@Service
public class MessageProducer {
private static final String STREAM_KEY = "message-stream";
private final RedisTemplate<String, Object> redisTemplate;
public MessageProducer(RedisTemplate<String, Object> redisTemplate) {
this.redisTemplate = redisTemplate;
}
public RecordId sendMessage(Message message) {
StreamOperations<String, Object, Object> streamOps = redisTemplate.opsForStream();
Map<String, Object> messageMap = new HashMap<>();
messageMap.put("id", message.getId());
messageMap.put("content", message.getContent());
return streamOps.add(MapRecord.create(STREAM_KEY, messageMap));
}
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.
复制
@Slf4j
@Service
public class MessageConsumer implements StreamListener<String, MapRecord<String, String, String>> {
private static final String STREAM_KEY = "message-stream";
private static final String GROUP_NAME = "message-group";
private static final String CONSUMER_NAME = "consumer-1";
private final RedisTemplate<String, Object> redisTemplate;
private StreamMessageListenerContainer<String, MapRecord<String, String, String>> container;
public MessageConsumer(RedisTemplate<String, Object> redisTemplate) {
this.redisTemplate = redisTemplate;
}
@PostConstruct
public void init() {
String script = "if redis.call(EXISTS, KEYS[1]) == 0 then " +
" return 1 " +
"else " +
" return 0 " +
"end";
RedisScript<Long> redisScript = RedisScript.of(script, Long.class);
Long result = redisTemplate.execute(redisScript, Collections.singletonList(streamKey));
if (result != null && result == 1) {
redisTemplate.opsForStream().createGroup(streamKey, ReadOffset.latest(), groupName);
log.info("消费者组 {} 创建成功", groupName);
} else {
log.info("消费者组 {} 已存在", groupName);
}
// 配置消息监听容器
StreamMessageListenerContainer.StreamMessageListenerContainerOptions<String,
MapRecord<String, String, String>> options =
StreamMessageListenerContainer.StreamMessageListenerContainerOptions.builder()
.batchSize(10)
.pollTimeout(Duration.ofMillis(100))
.build();
container = StreamMessageListenerContainer.create(redisTemplate.getConnectionFactory(), options);
/**
* ReadOffset.latest():指定组的起始位置为 “当前最新消息”
* ReadOffset.lastConsumed():从消费者组的最后确认位置开始读取。如果是新组,默认从$(最新位置)开始,确保消息至少被消费一次(At Least Once)
* ReadOffset.from(String id):从指定的消息 ID 开始读取
* id="0-0":从流的起始位置(第一条消息)开始读取所有历史消息
* id="$":等价于ReadOffset.latest(),从尾部开始读取新消息
* id="具体消息ID":从指定 ID 的下一条消息开始读取
**/
container.receive(
Consumer.from(GROUP_NAME, CONSUMER_NAME),
StreamOffset.create(STREAM_KEY, ReadOffset.lastConsumed()),this);
container.start();
// 验证容器是否启动成功
if (container.isRunning()) {
log.info("消息监听容器已启动");
} else {
log.warn("消息监听容器启动失败");
}
}
@Override
public void onMessage(MapRecord<String, String, String> message) {
try {
Map<String, String> value = message.getValue();
String id = value.get("id");
String content = value.get("content");
// 处理消息
System.out.println("收到消息: ID=" + id + ", 内容=" + content);
// 业务处理逻辑...
// 确认消息处理完成
redisTemplate.opsForStream().acknowledge(STREAM_KEY, GROUP_NAME, message.getId());
} catch (Exception e) {
// 处理异常,可以记录日志或实现重试逻辑
System.err.println("消息处理失败: " + e.getMessage());
}
}
@PreDestroy
public void destroy() {
if (container != null) {
container.stop();
}
}
public void consumeMessages() {
StreamOperations<String, String, String> streamOps = redisTemplate.opsForStream();
List<MapRecord<String, String, String>> messages = streamOps.read(
Consumer.from(GROUP_NAME, CONSUMER_NAME),
StreamReadOptions.empty().count(10).block(Duration.ofSeconds(10)),
StreamOffset.create(STREAM_KEY, ReadOffset.lastConsumed())
);
messages.forEach(message -> {
Map<String, String> value = message.getValue();
String id = value.get("id");
String content = value.get("content");
System.out.println("Received message: id=" + id + ", cnotallow=" + content);
// 确认消息已处理
streamOps.acknowledge(STREAM_KEY, GROUP_NAME, message.getId());
});
}
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.98.99.100.101.102.103.104.105.106.
复制
# 查看流信息
XLEN message-stream
# 查看消费者组信息
XINFO GROUPS message-stream
# 查看组消费情况
XINFO CONSUMERS message-stream message-group1.2.3.4.5.6.7.8.
注意:
在创建Redis Streams消费者组时,不能使用ReadOffset.lastConsumed(),当你创建一个新的消费者组时,Redis要求你明确指定组的初始读取位置(即从哪个消息ID开始消费)组的状态尚未初始化:新组没有任何消费记录,lastConsumed()无法确定起始位置
Redis API设计:创建组的命令(XGROUP CREATE)必须包含一个固定的偏移量参数(如0-0或$)
Redis Streams 和 Redis Pub-Sub 之间的主要区别特性
Redis Streams
Redis Pub-Sub
消息持久性
支持
不支持
投递保证
即使消费者离线也能投递
无(未被消费的消息会丢失)
重放能力
支持(可通过 ID 读取历史消息)
不支持(仅支持实时消息)
消息有序性
有保证(基于消息 ID)
无保证
消费者协调
支持(通过消费者组实现)
不支持
多消费者支持
支持(通过消费者组实现并发消费)
支持(消息广播至所有订阅者)
阅读剩余
THE END