在运维和开发中,确保 Elasticsearch、Filebeat、Logstash、Kibana(简称 EFLK)集群的稳定运行至关重要。
本文将详细介绍一套深度巡检方案,包括各组件的监控方法、健康状态检查、性能指标监控,以及一些关键的 DSL 查询示例,帮助大家全面掌握集群状态,及时发现潜在问题,优化 EFLK 的运行。
一、Elasticsearch 深度巡检方案
1. 集群健康检查
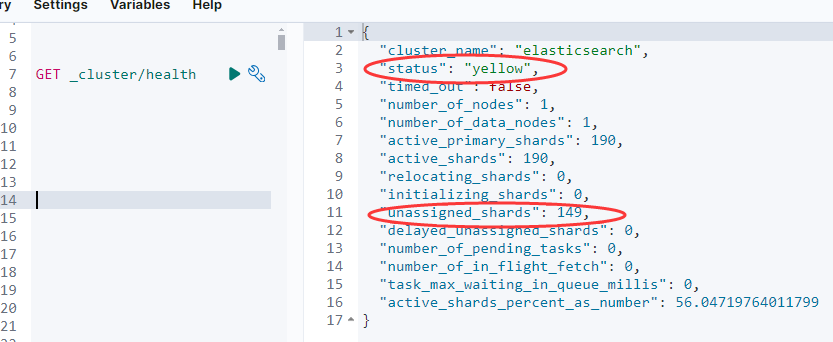
使用 _cluster/health API 获取集群的整体健康状况:
返回的关键字段:
 图片
图片
status:集群状态(green、yellow、red)number_of_nodes:节点数量active_primary_shards:活跃的主分片数active_shards:活跃的总分片数unassigned_shards:未分配的分片数量
2. 节点性能监控
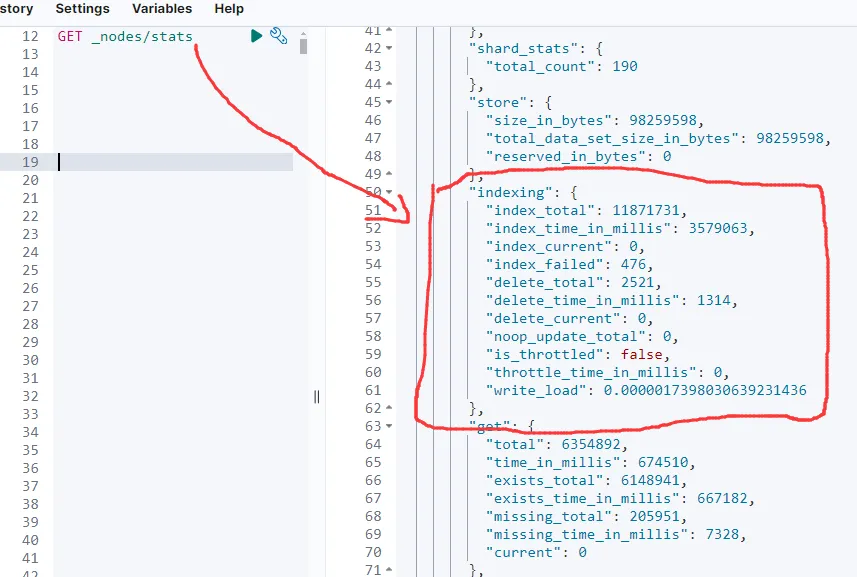
使用 _nodes/stats API 获取各节点的性能指标:
重点关注:
 图片
图片
indices.docs.count:文档数量indices.store.size_in_bytes:索引大小jvm.mem.heap_used_percent:JVM 堆内存使用率os.cpu.percent:CPU 使用率fs.total.available_in_bytes:磁盘可用空间
3. 分片状态监控
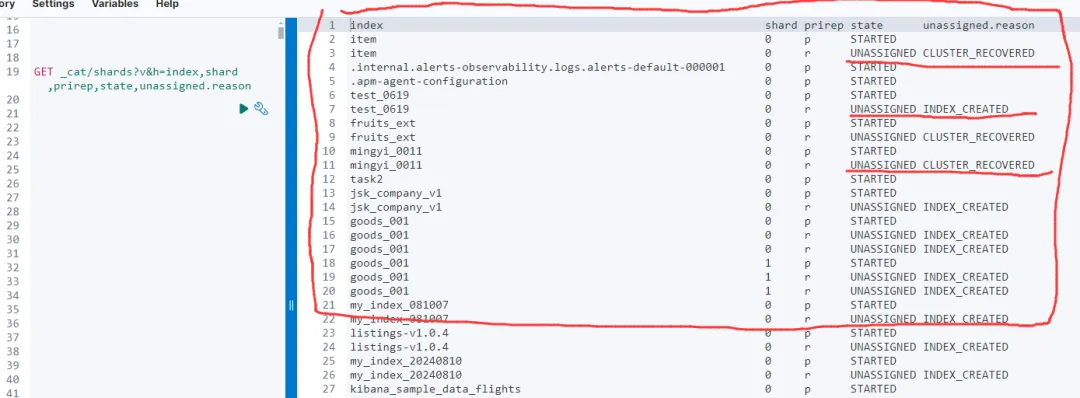
使用 _cat/shards API 查看所有分片的详细信息:
复制
GET _cat/shards?v&h=index,shard,prirep,state,unassigned.reason1.
重点检查 unassigned.reason 字段,确保没有未分配的分片。如果发现未分配的分片,可以使用以下命令重新分配:
 图片
图片
复制
POST /_cluster/reroute
{
"commands": [
{
"allocate_stale_primary": {
"index": "your-index",
"shard": 0,
"node": "node-name",
"accept_data_loss": true
}
}
]
}1.2.3.4.5.6.7.8.9.10.11.12.13.
4. 索引状态巡检
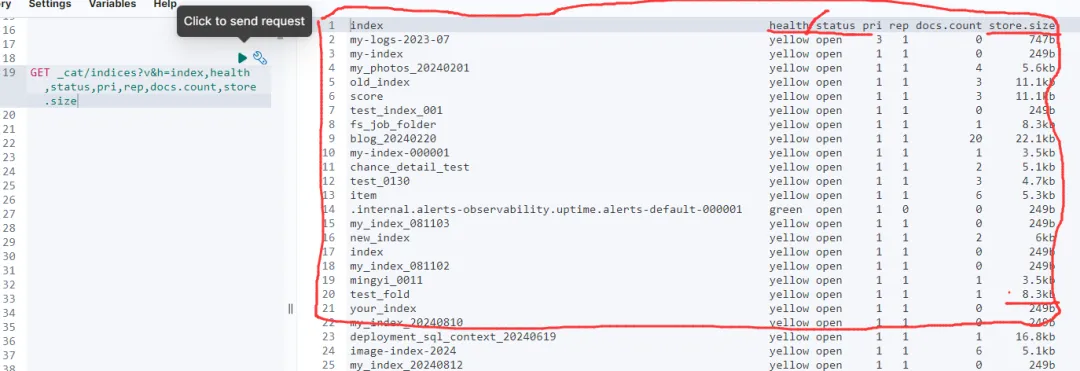
定期检查索引的健康状态,特别是大型或活跃的索引:
复制
GET _cat/indices?v&h=index,health,status,pri,rep,docs.count,store.size1.
 图片
图片
查看以下字段:
health:索引健康状态status:索引状态pri:主分片数量rep:副本分片数量docs.count:文档数量store.size:索引大小
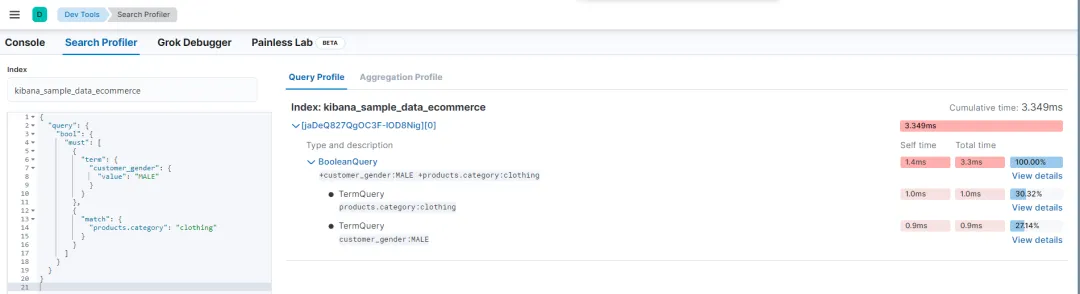
5. 集群性能分析(使用 Profile 查询)
为了深入分析查询性能,可以在查询时使用 profile 参数,返回每个查询阶段的执行时间,帮助定位性能瓶颈:
复制
GET /your-index/_search?pretty
{
"profile": true,
"query": {
"match": {
"field": "value"
}
}
}1.2.3.4.5.6.7.8.9.
返回结果中包含每个查询的执行时间,识别最耗时的部分(如分片级别操作)。
kibana 的 Search Profile 工具要用好!
 图片
图片
二、Filebeat 巡检方案
1. Filebeat 配置检查
确保 Filebeat 正确安装并运行:
复制
systemctl status filebeat1.
检查配置文件 /etc/filebeat/filebeat.yml,确保以下关键部分:
输入源(如日志文件、系统日志)配置正确输出目标(Elasticsearch 或 Logstash)配置正确
2. Filebeat 日志检查
查看 Filebeat 日志文件(通常位于 /var/log/filebeat/filebeat)以确保没有错误信息:
复制
tail -f /var/log/filebeat/filebeat1.
常见错误:
无法连接到 Elasticsearch 或 Logstash由于权限问题无法读取日志文件
3. Filebeat 配置测试
测试 Filebeat 配置文件的正确性:
使用 -e 参数启动 Filebeat,输出调试日志:
三、Logstash 巡检方案
1. Logstash 进程检查
检查 Logstash 是否正常运行:
复制
systemctl status logstash1.
2. Logstash 管道配置检查
检查 Logstash 的管道配置,通常位于 /etc/logstash/conf.d/ 下:
复制
cat /etc/logstash/conf.d/*.conf1.
确保以下部分配置正确:
输入(如 Filebeat、Kafka)过滤(如 Grok 解析、日期处理)输出(如 Elasticsearch、文件)
3. Logstash 日志检查
查看 Logstash 的日志文件(通常位于 /var/log/logstash/):
复制
tail -f /var/log/logstash/logstash-plain.log1.
重点检查:
连接失败(如无法连接到 Elasticsearch)解析错误(如 Grok 模式不匹配)
四、Kibana 巡检方案
1. Kibana 进程状态检查
检查 Kibana 服务是否正常运行:
复制
systemctl status kibana1.
2. Kibana 配置检查
检查 Kibana 配置文件(通常位于 /config/kibana.yml):
复制
cat /config/kibana.yml1.
确保以下配置正确:
elasticsearch.hosts: ["http://localhost:9200"](或集群地址)server.host: 0.0.0.0(确保 Kibana 可被外部访问)
3. Kibana 日志检查
查看 Kibana 的日志文件(通常位于 /logs/kibana.log):
复制
tail -f logs/kibana.log1.
重点检查:
 图片
图片
无法连接 ElasticsearchKibana 启动失败
4. Kibana UI 巡检
登录 Kibana 界面,检查以下功能是否正常:
Discover:能否正常搜索和查看日志数据Dashboards:仪表板是否正常显示Visualizations:可视化图表是否加载正常
五、DSL 查询示例
为了更深入的巡检,可以使用一些常见的 DSL 查询来检查系统的日志和性能。
1. 查询慢查询日志
查找慢查询,定位性能瓶颈:
复制
GET /_search
{
"query": {
"range": {
"@timestamp": {
"gte": "now-1d/d",
"lt": "now/d"
}
}
},
"sort": [
{
"took": {
"order": "desc"
}
}
],
"size": 10
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
Elasticsearch高级调优方法论之——根治慢查询!为什么Elasticsearch查询变得这么慢了?
2. 查询错误日志
如果怀疑系统有错误,可以查询错误日志:
Elasticsearch 日志能否把全部请求打印出来?
复制
GET /filebeat-*/_search
{
"query": {
"match": {
"message": "error"
}
}
}1.2.3.4.5.6.7.8.
3. 查询特定节点性能问题
根据节点的 ID 或名称查询该节点上的所有日志:
复制
GET /_search
{
"query": {
"term": {
"host.name": {
"value": "node-1"
}
}
}
}1.2.3.4.5.6.7.8.9.10.
六、企业级参考:自动化监控 Elasticsearch 集群
为了持续监控 Elasticsearch 集群的健康状态、CPU、内存、负载、磁盘使用率等指标,可以使用 Python 脚本结合定时任务实现自动化采集。我早期项目是借助 shell 脚本实现,原理一致
1. Elasticsearch 指标采集 Python 脚本
1.1 准备工作
确保安装了 requests 库:
复制
1.2 脚本代码(可运行版本)import json
from datetime import datetime
import configparser
import warnings
from elasticsearch import Elasticsearch
warnings.filterwarnings("ignore")
# 初始化 Elasticsearch 客户端
def init_es_client(config_path=./conf/config.ini):
"""初始化并返回Elasticsearch客户端"""
config = configparser.ConfigParser()
config.read(config_path)
es_host = config.get(elasticsearch, ES_HOST)
es_user = config.get(elasticsearch, ES_USER)
es_password = config.get(elasticsearch, ES_PASSWORD)
es = Elasticsearch(
hosts=[es_host],
basic_auth=(es_user, es_password),
verify_certs=False,
ca_certs=conf/http_ca.crt
)
return es
# 日志文件配置
LOG_FILE = elasticsearch_metrics.log
# 使用初始化的客户端
es = init_es_client()
# 获取集群健康状况
def get_cluster_health():
return es.cluster.health().body # 获取字典格式的数据
# 获取节点统计信息
def get_node_stats():
return es.nodes.stats().body # 获取字典格式的数据
# 获取集群指标
def get_cluster_metrics():
metrics = {}
cluster_health = get_cluster_health()
metrics[cluster_health] = cluster_health
node_stats = get_node_stats()
nodes = node_stats.get(nodes, {})
metrics[nodes] = {}
for node_id, node_info in nodes.items():
node_name = node_info.get(name)
metrics[nodes][node_name] = {
cpu_usage: node_info[os][cpu][percent],
load_average: node_info[os][cpu].get(load_average, {}).get(1m),
memory_used: node_info[os][mem][used_percent],
heap_used: node_info[jvm][mem][heap_used_percent],
disk_available: node_info[fs][total][available_in_bytes] / (1024 ** 3),
disk_total: node_info[fs][total][total_in_bytes] / (1024 ** 3),
disk_usage_percent: 100 - (
node_info[fs][total][available_in_bytes] * 100 / node_info[fs][total][total_in_bytes]
)
}
return metrics
# 记录集群状态到日志文件
def log_metrics():
metrics = get_cluster_metrics()
timestamp = datetime.now().strftime(%Y-%m-%d %H:%M:%S)
with open(LOG_FILE, a) as f:
f.write(f"Timestamp: {timestamp}\n")
f.write(json.dumps(metrics, indent=4))
f.write(\n\n)
# 主函数
if __name__ == "__main__":
log_metrics()
print("Elasticsearch cluster metrics logged successfully.")1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.
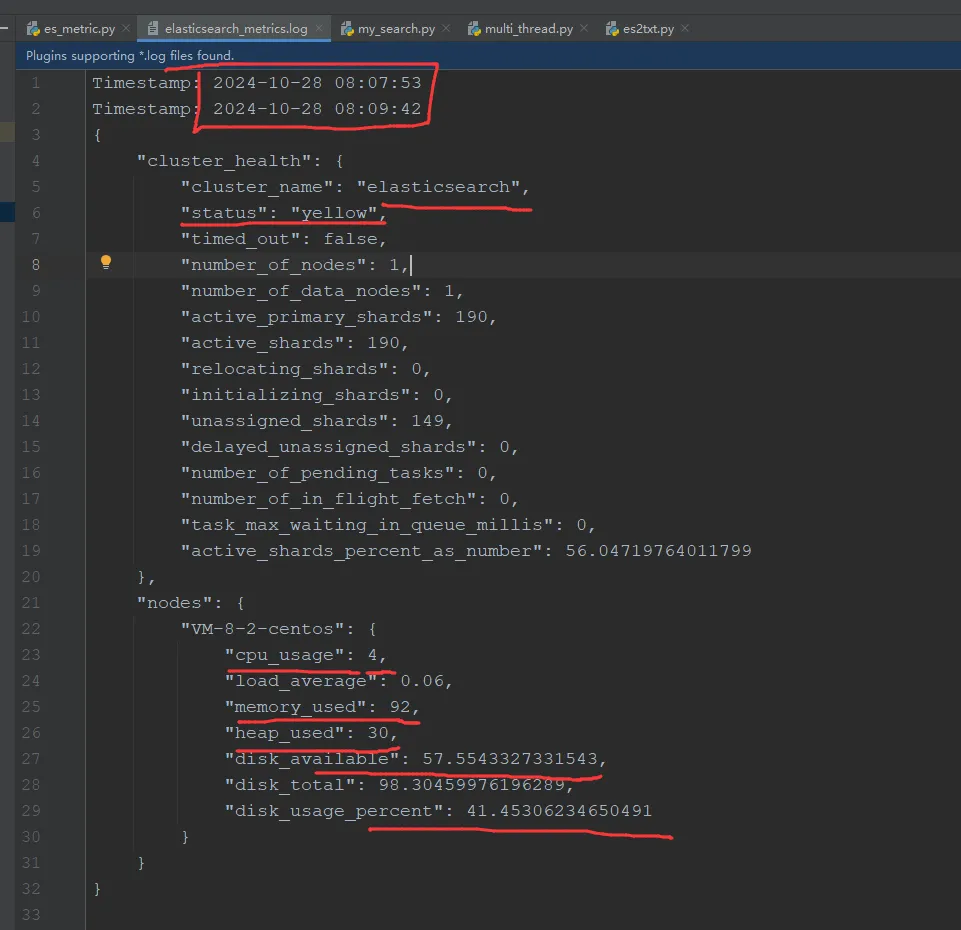
1.3 关键指标说明cluster_health:集群健康状态(green、yellow、red)cpu_usage:每个节点的 CPU 使用率load_average:系统负载平均值memory_used:每个节点的内存使用率heap_used:JVM 堆内存使用率disk_available:磁盘可用空间(GB)disk_total:磁盘总空间(GB)disk_usage_percent:磁盘使用率
日志将以 JSON 格式保存,记录每次获取到的集群和节点状态。(如下图所示)
 图片
图片
2. 定时执行任务脚本
为了每天早上6点自动执行脚本,可以使用 cron 设置定时任务。
2.1 编辑定时任务
假设脚本位于 /home/user/scripts/es_metrics.py,使用以下命令编辑 crontab:
添加以下行:
复制
0 6 * * * /usr/bin/python3 /home/user/scripts/es_metrics.py >> /home/user/scripts/es_metrics_cron.log 2>&11.
解释:
0 6 * * *:每天早上6点执行/usr/bin/python3:Python 3 的完整路径,需根据实际情况调整>> /home/user/scripts/es_metrics_cron.log 2>&1:将输出和错误信息重定向到日志文件
七、结论
通过以上深度巡检方案,能够全面掌握 EFLK 各组件的健康状态和性能指标。定期巡检和自动化监控有助于及时发现潜在问题,保障集群的稳定运行。
Elasticsearch:重点关注集群健康、节点性能、分片状态和索引状况Filebeat、Logstash、Kibana:检查服务状态、配置文件和日志,确保数据采集和展示正常
持续的监控和优化,才能让我们的 EFLK 集群始终保持最佳状态。
当然,我们推荐优先借助监控指标工具 Prometheus、Zabbix、Grafana 等巡查。