1. 整体架构
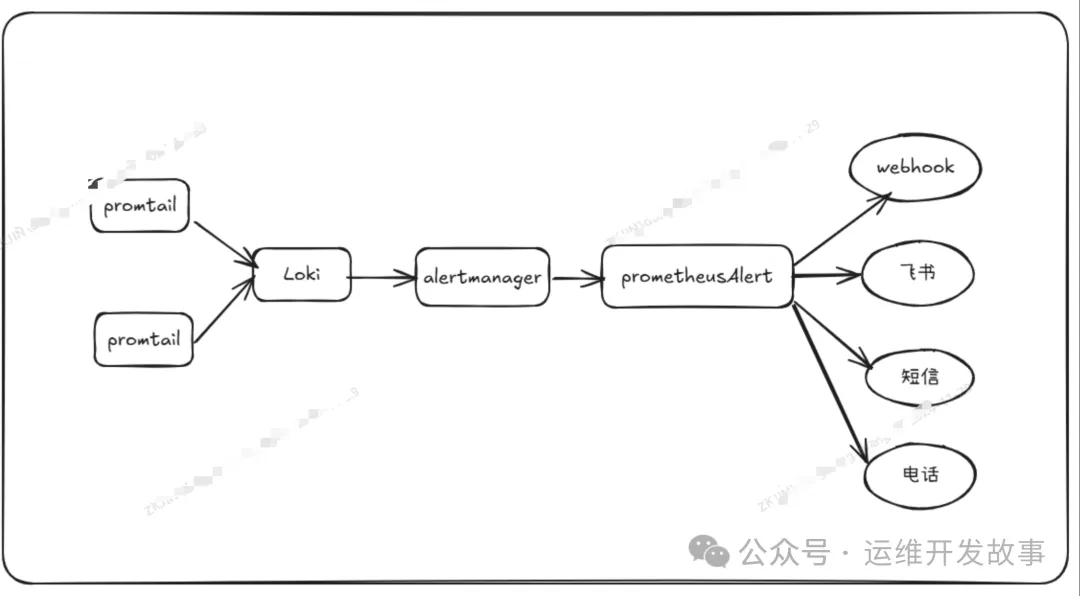
后面介绍部署方式都是二进制部署,这些应用都可以使用容器进行部署,思路都是一样的,本文就不再介绍了。
2. 安装loki
(1)下载地址
https://github.com/grafana/loki/releases
(2)安装
复制
[root@testqwe ~]# mkdir loki
[root@testqwe ~]# cd loki
[root@testqwe ~]# wget https://github.com/grafana/loki/releases/download/v2.7.1/loki-linux-amd64.zip
[root@testqwe ~]# unzip loki-linux-amd64.zip
[root@testqwe ~]# vi loki.yaml1.2.3.4.5.
(3)修改配置文件
主要修改 ruler 内参数。
复制
auth_enabled: false
server:
http_listen_port: 3100
common:
# 根据实际路径修改
path_prefix: /home/xxx/Data/loki-stack/loki
storage:
filesystem:
# 根据实际路径修改
chunks_directory: /home/xxx/Data/loki-stack/loki/chunks
# 根据实际路径修改
rules_directory: /home/xxx/Data/loki-stack/loki/rules
replication_factor: 1
ring:
instance_addr: 127.0.0.1
kvstore:
store: inmemory
query_range:
results_cache:
cache:
embedded_cache:
enabled: true
max_size_mb: 100
schema_config:
configs:
- from: 2020-10-24
store: boltdb-shipper
object_store: filesystem
schema: v11
index:
prefix: index_
period: 24h
limits_config:
enforce_metric_name: false
reject_old_samples: true
reject_old_samples_max_age: 168h
retention_period: 720h
compactor:
retention_enabled: true
compaction_interval: 10m
retention_delete_delay: 5m
retention_delete_worker_count: 150
chunk_store_config:
max_look_back_period: 720h
ruler:
# 触发告警事件后的回调查询地址
# 如果用grafana的话就配置成grafana/explore,根据实际ip修改
alertmanager_url: http://10.xx.xx.xx:9093
external_url: http://10.xx.xx.xx:3000
enable_alertmanager_v2: true
# 启用loki rules API
enable_api: true
# 对rules分片,支持ruler多实例,ruler服务的一致性哈希环配置,用于支持多实例和分片
enable_sharding: true
ring:
kvstore:
store: inmemory
# rules临时规则文件存储路径,根据实际路径修改
rule_path: /home/xxx/Data/loki-stack/loki/tmp_rules
# rules规则存储
# 主要支持本地存储(local)和对象文件系统(azure, gcs, s3, swift)
storage:
type: local
local:
# 根据实际路径修改
directory: /home/xxx/Data/loki-stack/loki/rules
# rules规则加载时间
flush_period: 1m
analytics:
reporting_enabled: false1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.
其中loki 配置文件详解。
复制
server:
http_listen_port: 3100 # http_listen_port: 配置HTTP监听端口号为3100。
graceful_shutdown_timeout: 60s # 配置优雅停机的超时时间为60秒。
http_server_read_timeout: 60s # 配置HTTP服务器读取超时时间为60秒。
http_server_write_timeout: 60s # 配置HTTP服务器写入超时时间为60秒。
ingester: # 配置Loki的ingester部分,用于接收和处理日志数据。
lifecycler: # 配置生命周期管理器,用于管理日志数据的生命周期。
address: 10.0.0.8 # 配置生命周期管理器的地址
ring: # 配置哈希环,用于将日志数据分配给不同的Loki节点
kvstore: # 配置键值存储,用于存储哈希环的节点信息。
store: inmemory # 配置存储引擎为inmemory,即内存中存储
replication_factor: 1 # 配置复制因子为1,即每个节点只存储一份数据。
final_sleep: 0s # 配置最终休眠时间为0秒,即关闭时立即停止。
chunk_idle_period: 1h # 配置日志块的空闲时间为1小时。如果一个日志块在这段时间内没有收到新的日志数据,则会被刷新。
max_chunk_age: 1h # 配置日志块的最大年龄为1小时。当一个日志块达到这个年龄时,所有的日志数据都会被刷新。
chunk_target_size: 2048576 # 配置日志块的目标大小为2048576字节(约为1.5MB)。如果日志块的空闲时间或最大年龄先达到,Loki会首先尝试将日志块刷新到目标大小。
chunk_retain_period: 30s # 配置日志块的保留时间为30秒。这个时间必须大于索引读取缓存的TTL(默认为5分钟)。
max_transfer_retries: 0 # 配置日志块传输的最大重试次数为0,即禁用日志块传输。
schema_config: # 配置Loki的schema部分,用于管理索引和存储引擎。
configs: # 配置索引和存储引擎的信息。
- from: 2020-10-24 # 配置索引和存储引擎的起始时间。
store: boltdb-shipper # 配置存储引擎为boltdb-shipper,即使用BoltDB存储引擎。
object_store: filesystem # 配置对象存储引擎为filesystem,即使用文件系统存储。
schema: v11 # 配置schema版本号为v11。
index: # 配置索引相关的信息。
prefix: index_ # 配置索引文件的前缀为index_。
period: 24h # 配置索引文件的周期为24小时。
storage_config: # 配置Loki的存储引擎相关的信息。
boltdb_shipper: # 配置BoltDB存储引擎的信息。
active_index_directory: /tmp/loki/boltdb-shipper-active # 配置活动索引文件的存储目录为/tmp/loki/boltdb-shipper-active。
cache_location: /tmp/loki/boltdb-shipper-cache # 配置BoltDB缓存文件的存储目录为/tmp/loki/boltdb-shipper-cache。
cache_ttl: 240h # 配置BoltDB缓存的TTL为240小时。
shared_store: filesystem # 配置共享存储引擎为filesystem,即使用文件系统存储。
filesystem: # 配置文件系统存储引擎的信息,即日志数据的存储目录为/tmp/loki/chunks
directory: /tmp/loki/chunks
compactor: # 配置日志压缩器的信息。
working_directory: /tmp/loki/boltdb-shipper-compactor # 配置工作目录为/tmp/loki/boltdb-shipper-compactor。
shared_store: filesystem # 配置共享存储引擎为filesystem,即使用文件系统存储。
limits_config: # 配置Loki的限制策略。
reject_old_samples: true # 配置是否拒绝旧的日志数据。
reject_old_samples_max_age: 168h # 配置拒绝旧的日志数据的最大年龄为168小时。
ingestion_rate_mb: 64 # 配置日志数据的最大摄入速率为64MB/s。
ingestion_burst_size_mb: 128 # 配置日志数据的最大摄入突发大小为128MB。
max_streams_matchers_per_query: 100000 # 配置每个查询的最大流匹配器数量为100000。
max_entries_limit_per_query: 50000 # 配置每个查询的最大条目限制为50000。
chunk_store_config: # 配置日志数据的存储策略。
# max_look_back_period: 1440h
max_look_back_period: 240h # 配置最大回溯时间为240小时。
table_manager: # 配置Loki的表管理器。
retention_deletes_enabled: true # 配置是否启用保留期删除。
# retention_period: 1440h
retention_period: 240h # 配置保留期为240小时。1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.
(4)编辑启动文件
复制
[root@testqwe ~]# cat /usr/lib/systemd/system/loki.service
[Unit]
Descriptinotallow=loki server
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/root/loki/loki-linux-amd64 -config.file=/root/loki/loki.yaml -target=all
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=loki
[Install]
WantedBy=default.target1.2.3.4.5.6.7.8.9.10.11.12.13.
(5)启动服务
复制
[root@testqwe ~]# systemctl daemon-reload
[root@testqwe ~]# systemctl start loki.service1.2.3.
3. 安装promtail
(1)下载地址
https://github.com/grafana/loki/releases
(2)安装
复制
[root@testqwe ~]# mdkir promtail
[root@testqwe ~]# cd promtail
[root@testqwe ~]# wget https://github.com/grafana/loki/releases/download/v2.7.1/promtail-linux-amd64.zip
[root@testqwe ~]# unzip promtail-linux-amd64.zip1.2.3.4.
(3)修改配置文件
client:loki的地址.
scrape_configs:抓取日志配置。
详细配置参考:https://cloud.tencent.com/developer/article/1824988。
复制
[root@testqwe ~]# cat promtail/promtail.yaml
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /var/log/positions.yaml # This location needs to be writeable by promtail.
client:
# 根据实际情况修改,添加本机ip地址
url: http://xx.xx.xx.xx:3100/loki/api/v1/push
# 可根据实际需要修改job中配置来匹配要采集的日志
scrape_configs:
- job_name: app-log
static_configs:
- targets:
- localhost
labels:
job: app-logs
host: 10.xx.11.xx
__path__: /home/xxx/Logs/*.xxx/*log
pipeline_stages:
- match:
selector: {job="app-logs"}
stages:
- multiline:
firstline: ^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}.\d{1,}
max_lines: 256
max_wait_time: 30s
- regex:
source: filename
expression: "/home/xxx/Logs/(?P<appname>[a-z]*).*$"
- labels:
appname:
- job_name: nginx-log
static_configs:
- targets:
- localhost
labels:
job: nginx-logs
host: 10.xx.11.xx
__path__: /home/xxx/Logs/nginx/*/*log
pipeline_stages:
- match:
selector: {job="nginx-logs"}
stages:
- regex:
source: filename
expression: "/home/xxx/Logs/nginx/(?P<appname>[a-z1-9.]*)/([a-z1-9.]*)_(?P<logtype>[a-z]*).*$"
- labels:
appname:
logtype:1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.
(4)编辑启动文件
复制
[root@testqwe ~]# cat /usr/lib/systemd/system/promtail.service
[Unit]
Descriptinotallow=promtail server
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/root/promtail/promtail-linux-amd64 -config.file=/root/promtail/promtail.yaml
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=promtail
[Install]
WantedBy=default.target1.2.3.4.5.6.7.8.9.10.11.12.13.
(5)启动服务
复制
[root@testqwe ~]# systemctl daemon-reload
[root@testqwe ~]# systemctl start promtail.service1.2.
4. 安装grafana
(1)下载地址
https://github.com/grafana/grafana/releases
(2)安装
复制
[root@testqwe ~]# wget https://dl.grafana.com/enterprise/release/grafana-enterprise-9.3.2-1.x86_64.rpm
[root@testqwe ~]# yum install grafana-enterprise-9.3.2-1.x86_64.rpm1.2.
(3)启动服务
复制
[root@testqwe ~]# systemctl start grafana-server.service1.
5. 安装alertmanager
(1)下载地址
https://github.com/prometheus/alertmanager/releases
(2)安装
复制
[root@testqwe ~]# wget https://github.com/prometheus/alertmanager/releases/download/v0.25.0/alertmanager-0.25.0.linux-amd64.tar.gz
[root@testqwe ~]# tar -zxvf alertmanager-0.25.0.linux-amd64.tar.gz1.2.
(3)修改配置文件
配置告警相关内容:alertmanager.yml.
复制
[root@testqwe alertmanager-0.24.0.linux-amd64]# cat alertmanager.yml
route:
group_by: [alertname]
group_wait: 5s
group_interval: 5s
repeat_interval: 50m
receiver: web.hook
receivers:
- name: web.hook
webhook_configs:
# 该配置是prometheusalert的server地址,然后拼接的告警渠道webhook
- url: http://10.xx.11.xx:8080/prometheusalert?type=fs&tpl=loki&fsurl=http://open.feishu.cn/open-apis/bot/v2/hook/499f95e3-xxxxx
send_resolved: true
inhibit_rules:
- source_match:
severity: critical
target_match:
severity: warning
equal: [alertname, dev, instance]1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
(4)Alertmanager 配置文件参考内容:
参考链接:https://prometheus.io/docs/alerting/latest/configuration/
## Alertmanager 配置文件参考
复制
## Alertmanager 配置文件
global:
resolve_timeout: 5m
# smtp配置
smtp_from: "123456789@qq.com"
smtp_smarthost: smtp.qq.com:465
smtp_auth_username: "123456789@qq.com"
smtp_auth_password: "auth_pass"
smtp_require_tls: true
# 路由分组
route:
receiver: ops
group_wait: 30s # 在组内等待所配置的时间,如果同组内,30秒内出现相同报警,在一个组内出现。
group_interval: 5m # 如果组内内容不变化,合并为一条警报信息,5m后发送。
repeat_interval: 24h # 发送报警间隔,如果指定时间内没有修复,则重新发送报警。
group_by: [alertname] # 报警分组
routes:
- match:
team: operations #根据team标签进行匹配,走不同的接收规则
receiver: ops
- match_re:
service: nginx|apache
receiver: web
- match_re:
service: hbase|spark
receiver: hadoop
- match_re:
service: mysql|mongodb
receiver: db
# 接收器指定发送人以及发送渠道
receivers:
# ops分组的定义
- name: ops
email_configs:
- to: 9935226@qq.com,10000@qq.com
send_resolved: true
headers:
subject: "[operations] 报警邮件"
from: "警报中心"
to: "小煜狼皇"
# 钉钉配置
webhook_configs:
- url: http://localhost:8070/dingtalk/ops/send
# 企业微信配置
wechat_configs:
- corp_id: ww5421dksajhdasjkhj
api_url: https://qyapi.weixin.qq.com/cgi-bin/
send_resolved: true
to_party: 2
agent_id: 1000002
api_secret: Tm1kkEE3RGqVhv5hO-khdakjsdkjsahjkdksahjkdsahkj
# web
- name: web
email_configs:
- to: 9935226@qq.com
send_resolved: true
headers: { Subject: "[web] 报警邮件"} # 接收邮件的标题
webhook_configs:
- url: http://localhost:8070/dingtalk/web/send
- url: http://localhost:8070/dingtalk/ops/send
# db
- name: db
email_configs:
- to: 9935226@qq.com
send_resolved: true
headers: { Subject: "[db] 报警邮件"} # 接收邮件的标题
webhook_configs:
- url: http://localhost:8070/dingtalk/db/send
- url: http://localhost:8070/dingtalk/ops/send
# hadoop
- name: hadoop
email_configs:
- to: 9935226@qq.com
send_resolved: true
headers: { Subject: "[hadoop] 报警邮件"} # 接收邮件的标题
webhook_configs:
- url: http://localhost:8070/dingtalk/hadoop/send
- url: http://localhost:8070/dingtalk/ops/send
# 抑制器配置
inhibit_rules: # 抑制规则
- source_match: # 源标签警报触发时抑制含有目标标签的警报,在当前警报匹配 status: High
status: High
target_match:
status: Warning #
equal: [alertname,operations, instance] # 确保这个配置下的标签内容相同才会抑制,也就是说警报中必须有这三个标签值才会被抑制。1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.
inhibit_rules:
Alertmanager的抑制机制可以避免当某种问题告警产生之后用户接收到大量由此问题导致的一系列的其它告警通知。例如当集群不可用时,用户可能只希望接收到一条告警,告诉他这时候集群出现了问题,而不是大量的如集群中的应用异常、中间件服务异常的告警通知。
当已经发送的告警通知匹配到target_match和target_match_re规则,当有新的告警规则如果满足source_match或者定义的匹配规则,并且已发送的告警与新产生的告警中equal定义的标签完全相同,则启动抑制机制,新的告警不会发送。
通过上面的配置,可以在alertname/operations/instance相同的情况下,high的报警会抑制warning级别的报警信息。
(5)编辑启动文件
复制
[root@testqwe ]# cat /usr/lib/systemd/system/alertmanager.service
[Unit]
Descriptinotallow=alertmanager
Documentatinotallow=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=root
ExecStart=/root/alertmanager-0.24.0.linux-amd64/alertmanager --config.file=/root/alertmanager-0.24.0.linux-amd64/alertmanager.yml
Restart=on-failure
[Install]
WantedBy=multi-user.target1.2.3.4.5.6.7.8.9.10.11.12.13.14.
(6)启动服务
复制
[root@testqwe ~]# systemctl daemon-reload
[root@testqwe ~]# systemctl start alertmanager.service1.2.
6. 安装prometheusAlert告警中心配置告警通道
告警明细上报到alertmanager后,alertmanager会调用统一告警中心prometheusAlert的webhook来接收告警内容,并按上报内容的标签:告警级别--severity ,业务条线--bussiness,告警来源--type 来匹配在统一告警中心配置的告警通道,并将告警内容推送到飞书群中的webhook机器人
(1)下载地址
复制
#打开PrometheusAlert releases页面,根据需要选择需要的版本下载到本地解压并进入解压后的目录
如linux版本(https://github.com/feiyu563/PrometheusAlert/releases/download/v4.9.1/linux.zip)
# wget https://github.com/feiyu563/PrometheusAlert/releases/download/v4.9.1/linux.zip && unzip linux.zip && cp -r linux /usr/local/prometheusAlert && chmod +x /usr/local/prometheusAlert/PrometheusAlert1.2.3.
(2)编辑启动文件
复制
[root@testqwe]# cat prometheusalert.service
[Service]
ExecStart=/usr/local/prometheusAlert/PrometheusAlert
WorkingDirectory=/usr/local/prometheusAlert
Restart=always
[Install]
WantedBy=multi-user.target
[Unit]
Descriptinotallow=Prometheus Alerting Service
After=network.target
[root@testqwe system]# pwd
/usr/lib/systemd/system1.2.3.4.5.6.7.8.9.10.11.12.
(3)启动服务
启动后可使用浏览器打开以下地址查看:http://127.0.0.1:8080。
默认登录帐号和密码在app.conf中有配置.
如果需要将日志输出到控制台,请修改 app.conf 中 logtype=console。
复制
[root@testqwe ~]# systemctl daemon-reload
[root@testqwe ~]# systemctl start prometheusalert.service1.2.
(4)访问服务
程序运行后,访问默认地址 http://xxxx:8080 的效果如下。
7. loki配置日志告警
因为上面loki启动参数中数据存储是在: /home/xxx/Data/loki-stack/loki/
告警规则存储目录:/home/xxx/Data/loki-stack/loki/rules/fake
因此告警规则添加到该目录即可,Loki每分钟自动刷新规则生效,下面是几个简单的服务告警demo,可以根据实际情况进行添加对应服务的告警,为了区分服务,所以每个单独配置的规则,expr规则,可以在grafana大盘,进行查询,然后调整
dzjava-app1-alerts.yml
复制
groups:
- name: POC演示环境-dzjava-app1告警组
rules:
- alert: 【P1】POC演示环境dzjava-app1服务日志存在Error和Exception关键字告警
expr: sum by (host,appname)(count_over_time({appname="dzjava-app1"} |~ "ERROR|Exception" [3m])) > 0
for: 1m
labels:
severity: critical
type: loki
bussiness: POC
annotations:
summary: "服务:{{ $labels.appname }} 实例: {{ $labels.host }} 3分钟内触发Error和Exception关键字告警次数统计阈值0 ,当前值:value: {{ $value}}"1.2.3.4.5.6.7.8.9.10.11.12.
dzjava-app2-alerts.yml
复制
[root@testqwe fake]# cat dzjava-app2-alerts.yml
groups:
- name: POC演示环境-dzjava-app2告警组
rules:
- alert: 【P1】POC演示环境dzjava-app2服务日志存在Error和Exception关键字告警
expr: sum by (host,appname)(count_over_time({appname="dzjava-app2"} |~ "ERROR|Exception" [3m])) > 0
for: 1m
labels:
severity: critical
type: loki
bussiness: POC
annotations:
summary: "服务:{{ $labels.appname }} 实例: {{ $labels.host }} 3分钟内触发Error和Exception关键字告警次数统计阈值0 ,当前值:value: {{ $value}}"
- alert: 【P1】POC演示环境dzjava-app2服务日志存在handleBaseService.error关键字告警
expr: sum by(appname, host) (count_over_time({appname="dzjava-app2"} |= `handleBaseService.error` [3m])) > 0
for: 1m
labels:
severity: critical
type: loki
bussiness: POC
annotations:
summary: "服务:{{ $labels.appname }} 实例: {{ $labels.host }} 3分钟内触发handleBaseService.error关键字告警次数统计阈值0 ,当前值:value: {{ $value}}"
- alert: 【P1】POC演示环境dzjava-app2服务日志存在502 Bad Gateway关键字告警
expr: sum by(appname, host) (count_over_time({appname="dzjava-app2"} |= "502 Bad Gateway" [3m])) > 0
for: 1m
labels:
severity: critical
type: loki
bussiness: POC
annotations:
summary: "服务:{{ $labels.appname }} 实例: {{ $labels.host }} 3分钟内触发502 Bad Gateway关键字告警次数统计阈值0 ,当前值:value: {{ $value}}"1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.
8. prometheusAlert配置告警模板
配置高级模版之后,需要修改alertmanager.yml配置文件中的webhook_configs的url地址,在模版的路径后拼接上飞书机器人地址,然后重启alertmanager,即可调试告警通道是否正常
添加模板
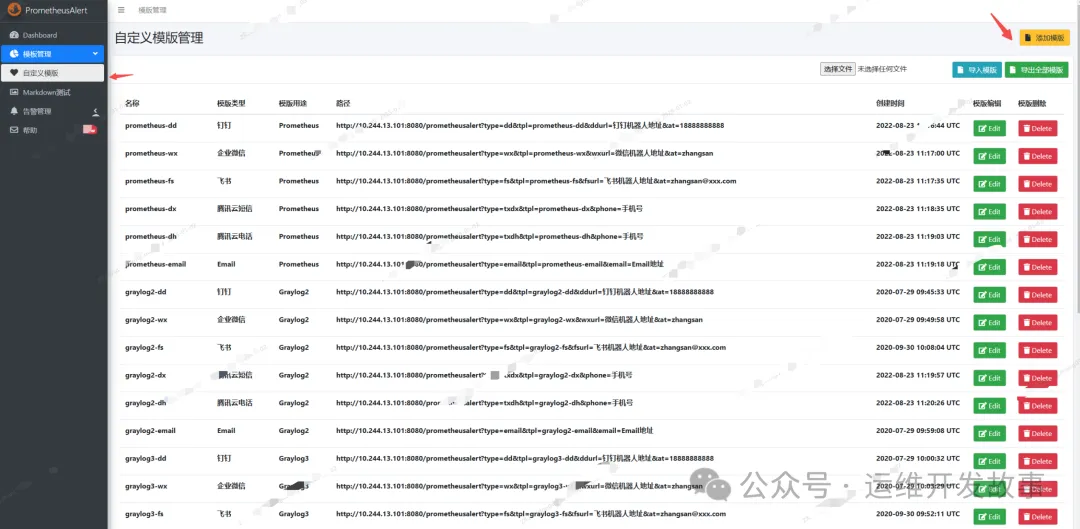
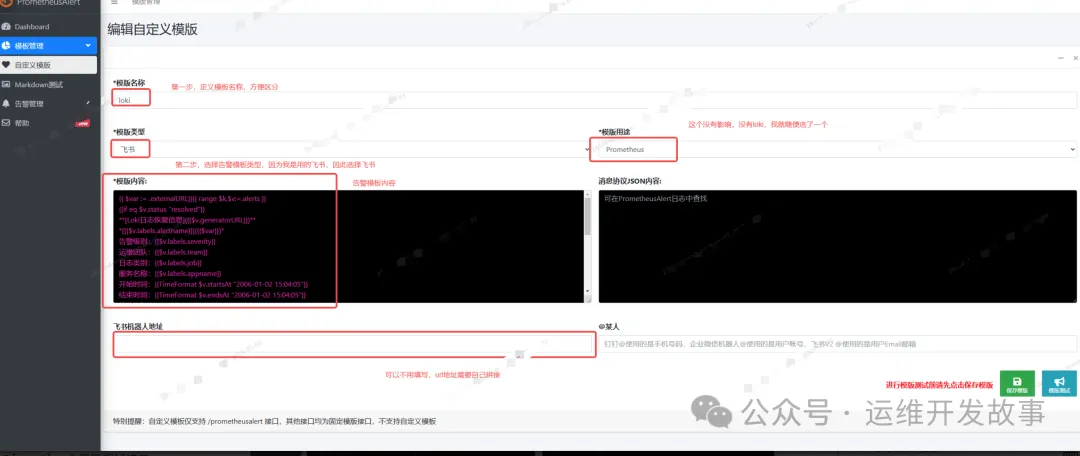
告警模板:
告警红色恢复绿色告警级别我用的severity,可以修改为level。请自己定义labels使用host,请自己定义labelssummary是自定义的告警详细信息
复制
{{ $var := .externalURL}}{{ range $k,$v:=.alerts }}
{{if eq $v.status "resolved"}}
✅**[Loki日志恢复通知]({{$v.generatorURL}})**
告警名称:{{$v.labels.alertname}}
告警级别:{{$v.labels.severity}}
告警状态:{{$v.status}}
服务名称:{{$v.labels.appname}}
开始时间:{{GetCSTtime $v.startsAt}}
结束时间:{{ GetCSTtime $v.endsAt }}
故障主机IP:{{$v.labels.host}}
**{{$v.annotations.summary}}**
{{else}}
🔥**[Loki日志报警通知]({{$v.generatorURL}})**
{{ if eq $v.labels.severity "warning" }}🟡告警名称:{{$v.labels.alertname}}
告警级别🟡:{{$v.labels.severity}}
{{ else if eq $v.labels.severity "critical" }}❌告警名称:{{$v.labels.alertname}}
告警级别❌:{{ $v.labels.severity }}
{{ else if eq $v.labels.severity "emergency" }}❌🔥🔥告警名称:{{ $v.labels.alertname }}
告警级别❌🔥🔥:{{ $v.labels.severity }}
{{ end }}
告警状态:{{$v.status}} > {{$v.labels.severity}}
告警级别:{{$v.labels.severity}}
服务名称:{{$v.labels.appname}}
开始时间:{{GetCSTtime $v.startsAt}}
结束时间:{{ GetCSTtime $v.endsAt }}
故障主机IP:{{$v.labels.host}}
**{{$v.annotations.summary}}**
{{end}}
{{ end }}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.
模板可以参考这个issues中的讨论:https://github.com/feiyu563/PrometheusAlert/issues/30
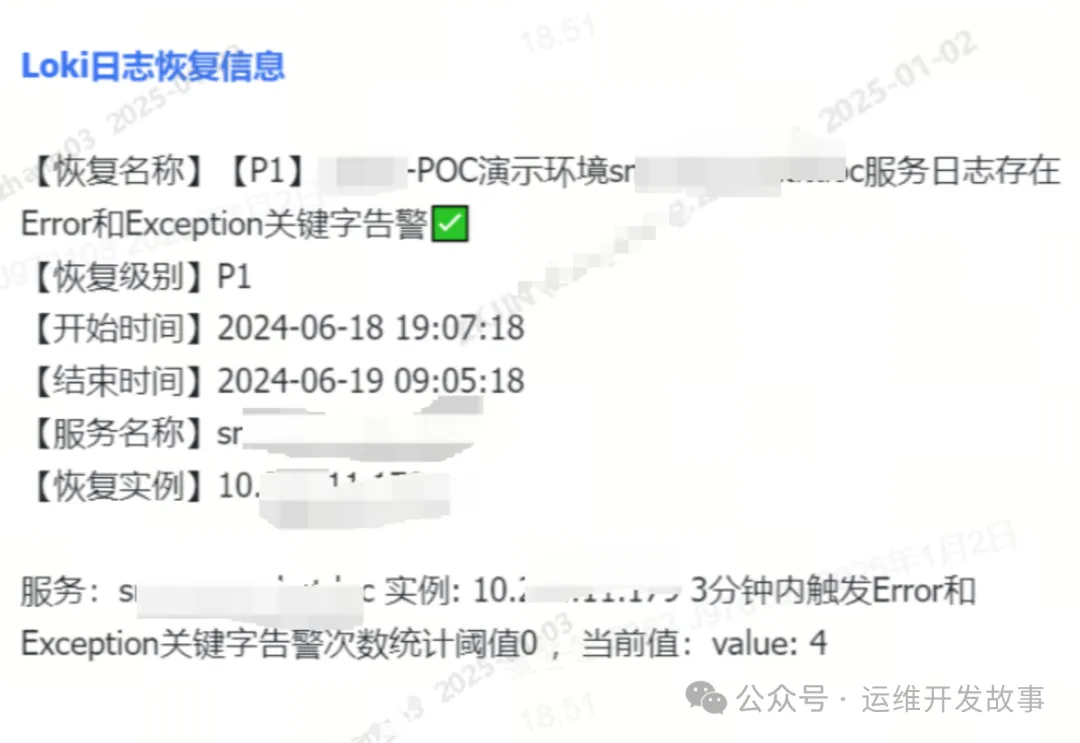
(1)告警效果展示
飞书群中,收到告警如下,可以简单的实现服务日志的采集和告警功能展示。

(2)日志效果展示
可以在grafana上添加数据源。
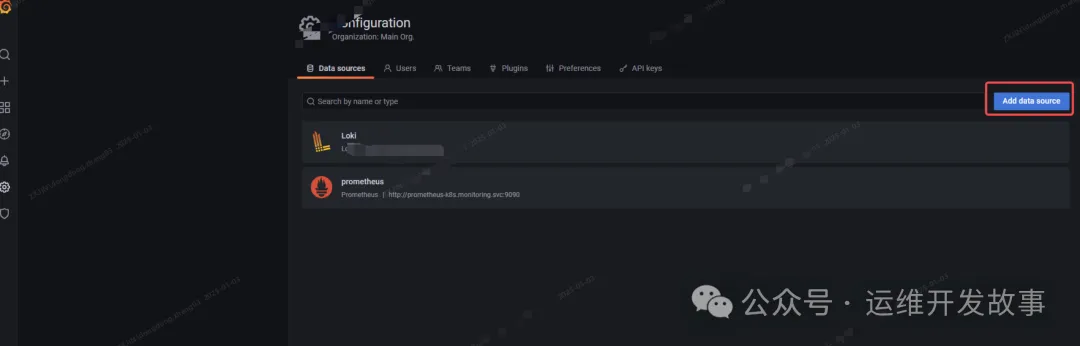
然后点击侧面栏的Explore就可以查看应用服务日志了。