面试官:如何设计一个分布式 ID 生成器
分布式系统中设计分布式 ID 对于确保订单、用户或记录等实体的唯一性至关重要。
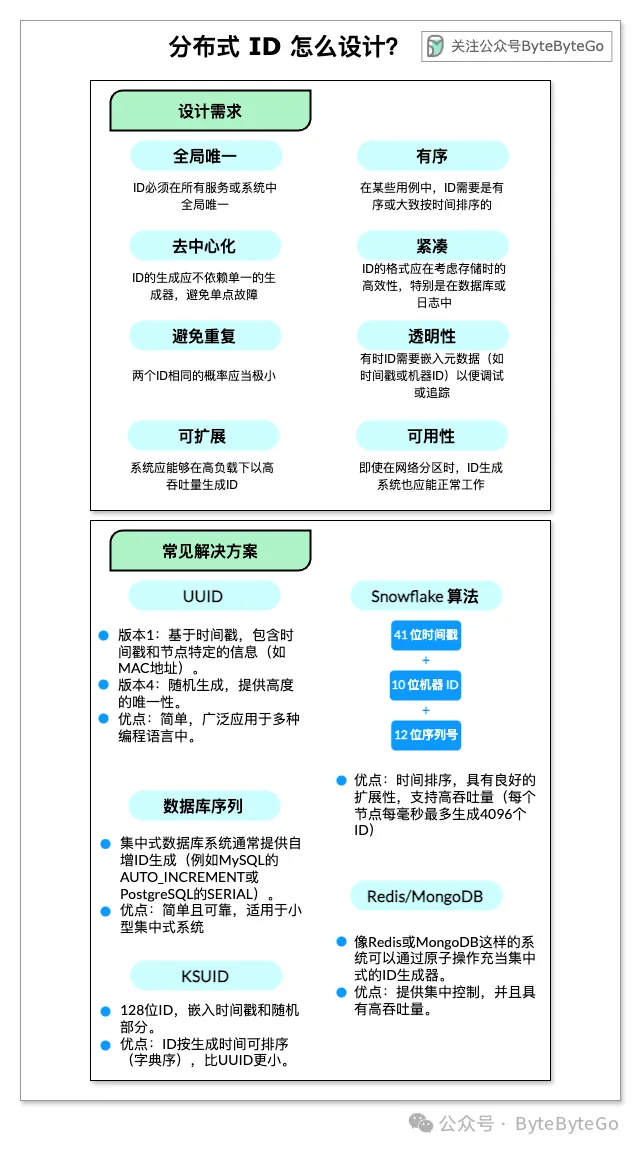
(1) UUID(通用唯一标识符)
版本1:基于时间戳,包含时间戳和节点特定的信息(如 MAC 地址)。版本4:随机生成,提供高度的唯一性。优点:简单,广泛应用于多种编程语言中。缺点:无序,较大(128位),不能轻易按生成时间排序。适用场景:适用于排序要求不高的分布式系统,如对象存储或用户 ID。(2) Snowflake 算法(Twitter)
一个 64 位的 ID,包含以下部分:
41 位用于时间戳(从某个自定义的纪元开始的毫秒数)。10 位用于机器 ID(数据中心或节点 ID)。12 位用于序列号(确保同一毫秒内生成的多个 ID 是唯一的)。优点:时间排序,具有良好的扩展性,支持高吞吐量(每个节点每毫秒最多生成 4096 个 ID)。缺点:需要节点间时间同步。适用场景:常用于分布式系统,如微服务或订单管理系统。(3) 数据库序列
数据库系统通常提供自增 ID 生成(例如 MySQL 的 AUTO_INCREMENT 或 PostgreSQL 的 SERIAL)。
优点:简单且可靠,适用于小型集中式系统。缺点:无法很好地扩展到分布式系统,会引入单点故障。适用场景:适用于无需高扩展性的简单应用。(4) KSUID(K-可排序的唯一标识符)
128 位 ID,嵌入时间戳和随机部分。
优点:ID 按生成时间可排序(字典序),比 UUID 更小。缺点:稍微比 UUID 复杂,空间效率不如 Snowflake。适用场景:适用于需要字典序排序和较长生命周期的场景,如日志聚合系统。(5) Redis / MongoDB 的序列生成器
像 Redis 或 MongoDB 这样的系统可以通过原子操作充当集中式的 ID 生成器。
优点:提供集中控制,并且具有高吞吐量。缺点:存在单点故障,依赖 Redis/MongoDB 的可用性。适用场景:适用于分布式系统,中央节点可以在没有高可用性要求的情况下生成 ID。选择解决方案的考虑因素吞吐量需求:如果系统需要每秒生成数百万个 ID,Snowflake 或 Redis-based 方案比 UUID 更合适。有序还是随机:如果 ID 需要按时间排序,可以考虑 Snowflake、KSUID。存储限制:与 KSUID 相比,Snowflake ID 更小,如果存储大小至关重要,可以选择更紧凑的格式。元数据:如果需要在ID中包含元数据,Snowflake ID 或自定义哈希方案可以编码时间戳或机器 ID 等信息。每种解决方案适合不同的用例,具体选择取决于扩展性、排序和存储大小等因素。Snowflake 和 UUID 是现代分布式系统中最常采用的方案。
THE END