国产集中库SQL能力评测 – 访问路径
随着国产数据库应用步入深水区,用户开始在更核心、更多元的场景使用国产库。在使用过程之中,用户非常关心的一个问题,就是国产数据库的SQL支持情况怎么样?是不是能如 Oracle 那样,针对复杂多变的 SQL 也能生成相对优秀的执行计划,进而保证良好的执行效率。之前也曾听闻过用户吐槽,国产数据库的优化器存在诸多不足。这也促使笔者考虑针对国产数据库做些 SQL 能力的评测,方便用户有着更深入的了解。这将是一个系列,笔者看个人精力会逐步完成。受限于个人能力水平及时间精力等因素,测试过程及结果仅代表个人,不能完全反映厂商产品能力,欢迎批评指正。
1. 评测方案说明
1)评测对象架构:集中式
从数据库架构上看,考虑到分布式与集中式的差异较大,本次将重点放在集中式数据库上。从之前接触用户到第三方调查机构的报告来看,数据库的集中式架构仍然是主流架构,占据近八成左右的市场份额。因此选择以集中式数据库为评测对象。
2)评测功能标准:Oracle
长期以来,Oracle 数据库一直是数据库业内的标杆性产品,特别是在集中式数据库领域。因此,本次测试会以Oracle 的能力为标准与国内数据库进行对比。此外,考虑到国内大部分已有业务也都是基于 Oracle 去开发的,因此迁移到国产数据库采用与Oracle为参照物也具有很好的参考意义。
3)评测产品范围:主流+代表性
国内数据库厂商及产品非常多,选择哪些厂商及产品是个很头疼的事情。这里本着主流或有代表性的原则进行选择。从现有集中式数据库的市场占有率方面,选择头部的厂商达梦、电科金仓为代表。从生态方面选择 openGauss 生态的海量数据;MySQL生态上没有太好选择,故使用最新社区版本;PG 生态上由之前的电科金仓来代表。自研方面,则采用的崖山数据库,毕竟其主打也是Oracle的兼容能力。最后也选择 Oracle 在国内仍然大规模使用的版本作为参照对象。
4)评测环境&版本
测试环境:采用Docker镜像方式测试版本:采用官方镜像(可能非最新)见下文测试数据:自行构造测试配置:数据库默认配置,未优化 图片
图片
2. Oracle 访问路径能力说明
这里主要谈 Oracle 数据的表及索引的访问路径问题。
1)表访问路径
❖ 全表扫描为实现全表扫描,Oracle读取表中所有的行,并检查每一行是否满足语句的WHERE限制条件。Oracle顺序地读取分配给表的每个数据块,直到读到表的最高水线处。一个多块读操作可以使一次I/O能读取多块数据块,而不是只读取一个数据块,这极大的减少了I/O总次数,提高了系统的吞吐量,所以利用多块读的方法可以十分高效地实现全表扫描,而且只有在全表扫描的情况下才能使用多块读操作。在这种访问模式下,每个数据块只被读一次。这也是最为常规的访问路径,下文将以此方式为主。
❖ ROWID扫描行的ROWID指出了该行所在的数据文件、数据块以及行在该块中的位置,所以通过ROWID来存取数据可以快速定位到目标数据上,是Oracle存取单行数据的最快方法。为了通过ROWID存取表,Oracle首先要获取被选择行的ROWID,或者从语句的WHERE子句中得到,或者通过表的一个或多个索引的索引扫描得到。Oracle然后以得到的ROWID为依据定位每个被选择的行。这种存取方法不会用到多块读操作,一次I/O只能读取一个数据块。我们会经常在执行计划中看到该存取方法,如通过索引查询数据。
❖ 采样扫描将从全部数据块中读取指定比例的数据之后,然后再通过过滤返回满足条件的行。在每次执行时,都会从全部的数据块中读取指定比例的数据块。所以每次读取的数据块都是不同的,当某个数据块被选定为读取对象时,块中所有行将被全部读取。此种访问路径常见于统计信息收集等场景之中。
2)索引访问路径
❖ 索引唯一扫描通过唯一索引查找一个数值经常返回单个ROWID。如果存在UNIQUE或PRIMARY KEY约束(它保证了语句只存取单行)的话,Oracle经常实现唯一性扫描。在大部分情况下该扫描方式主要被使用在检索唯一ROWID的查询中,为了进行索引唯一扫描而必须基于主键来创建索引或者创建唯一索引,且在SQL语句中必须为索引列使用"="比较运算符。否则即使基于具有唯一值的列创建了索引,在执行时优化器也不能可能选择索引唯一扫描,而会选择范围扫描。
❖ 索引范围扫描索引最普遍的数据读取方式,优化器选择该扫描方式的情况有两种,即由开始值与结束值的情况和有一个以上的行但没有结束的情况。索引范围扫描在寻找开始位置的时候使用随机读取,但之后所执行的全部都是连续扫描。如果再精确描述,即在查找分支块时使用的是随机读取,在经过分支块查找到开始的叶块之后所执行的就是连续扫描。在扫描方向上,又可分为升序扫描和降序扫描。
❖ 索引全扫描索引全扫描不读取索引结构中的每个块,这与其名称表面上相悖。索引全扫描处理索引的所有叶块,但为了查找到第一个叶块需要处理足够多的分支块。一旦在索引中获得一个叶块,则其前和后的叶块将按顺序被链接起来。即,叶块不仅可以通过分支块导航;而且,一旦获得一个叶块,也可以随指针获得下一个叶块。事实上,使用这种双向链表可以在索引结构中前进或后退。索引全扫描使用单块IO按顺序读取索引,它从根开始,通过分支块到达第一个叶块。这些块都是每次读取一块。当获取第一个叶块时,可按顺序读取每个叶块,同样是一次一块。索引全扫描从索引中按顺序读取数据。因此,索引全扫描可以避免排序。
❖ 索引快速全扫描索引快速全扫描将索引等同于表的一个缩小版本。它一次读取索引多个数据块,处理叶块数据,并忽略分支块。它能够比索引全扫描更快地读取索引结构,因为它是使用了多块io。扫描索引中的所有的数据块,与索引全扫描很类似,但是一个显著的区别就是它不对查询出的数据进行排序,即数据不是以排序顺序被返回。在这种存取方法中,可以使用多块读功能,也可以使用并行读入,以便获得最大吞吐量与缩短执行时间。索引快速全扫描每次I/O读取的是多个数据块,这也是该方式与索引全扫描之间的主要区别。
❖ 索引跳跃扫描索引跳过扫描改进了非前缀列的索引扫描。通常,扫描索引块比扫描表数据块更快。跳过扫描允许将复合索引在逻辑上拆分为更小的子索引。在跳过扫描中,查询中未指定复合索引的初始列。换句话说,它被跳过了。逻辑子索引的数量由初始列中不同值的数量决定。如果复合索引的前导列中只有很少的不同值,而索引的非前导键中有很多不同值,则跳过扫描是有利的。
3)Oracle 测试示例
3. 国产库访问路径能力评测
下文将对国产数据库(含MySQL)做测试对比。在之前先看下结论,国产数据库在访问路径方面能力都还可以,部分数据库还是稍有不足,具体可参考下面及之后的测试步骤。
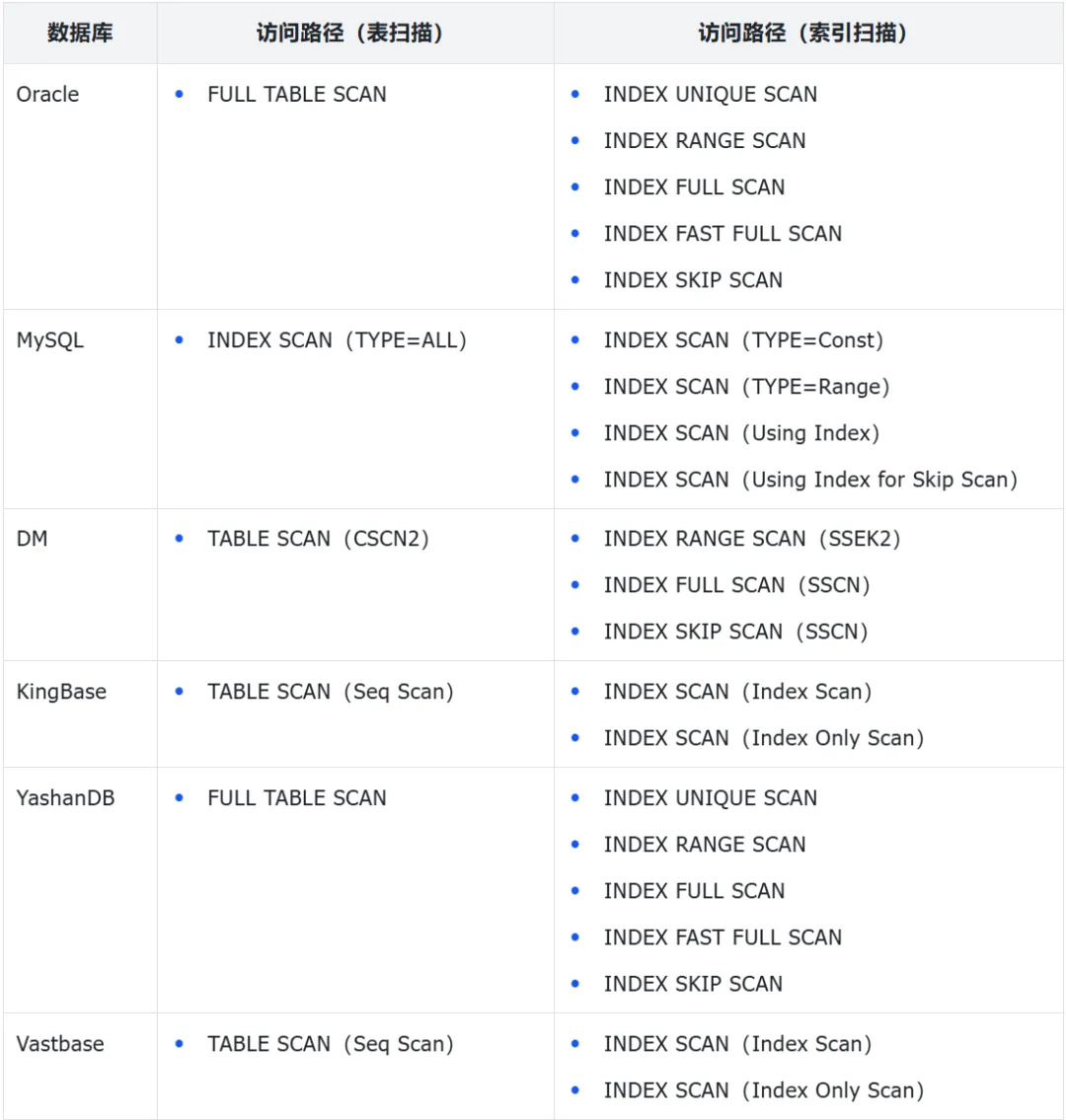 图片
图片