国产集中库SQL能力评测 – 排序和分组聚合

这里谈谈排序与分组聚合。这两类操作往往存在一定相关性。
1. 排序
排序是数据库内比较消耗资源的一类操作,特别是在结果比较大的情况下。因此在数据库处理上,应尽量规避排序的行为。这里讲的排序,不仅仅是指 ORDER BY 的操作,很多操作都会引发排序行为。常见操作包括:生成索引的操作(因为索引是有序结构)、某些SQL(如带有DISTINCT、ORDER BY、GROUP BY、UNION、MINUS、INTERSET、CONNECT BY和CONNECT BY ROLLUP子句)、排序合并连接(两个结果集排序后关联)、收集统计信息、其他如位图变换、分析函数等。在上面这些操作中,有些是为了进行排序,有些是为了其他目的(如去重等);因此数据库是可以考虑优化此类排序行为的。例如Oracle数据库,在10g以前的版本是通过SORT GROUP BY完成分组的,但在10g之后默认提供了HASH GROUP BY,这样效率更高,当然其结果集不保证有序了。
(1)常见排序操作
下面针对常见的排序类操作,抽象出一组测例,看看Oracle和国产数据库的行为如何。
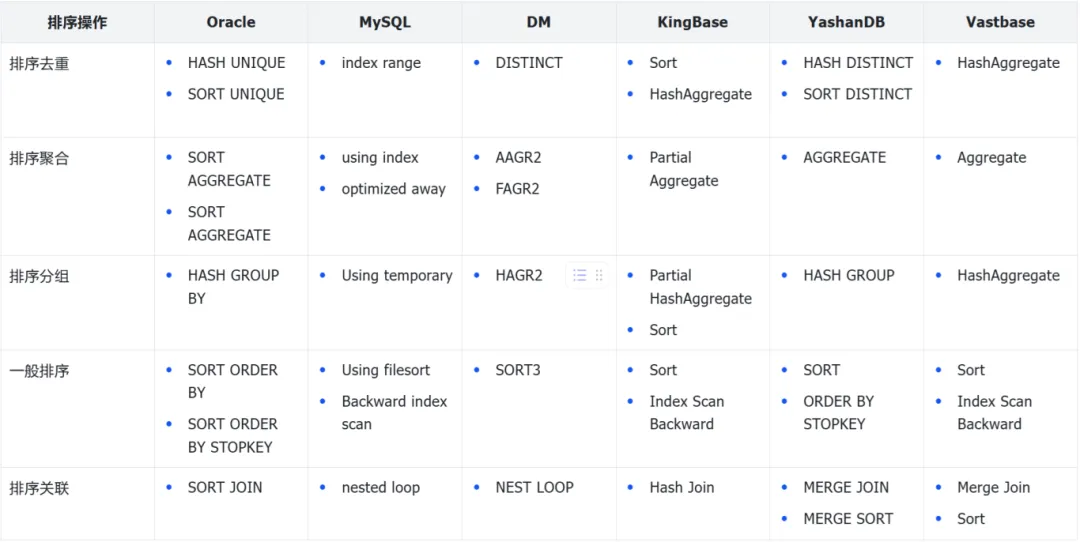
SORT UNIQUE排序去重类,把查询语句的输出结果变为唯一集合的过程。使用场景包括:语句中使用了DISTINCT、子查询向主查询提供执行结果。在Oracle 10g以后的版本中,SORT UNIQUE 变成 HASH UNIQUE,利用新的HASH算法代替了传统的排序。但在使用子查询的场景下,因为优先执行子查询,子查询放在主查询之前。由于主查询的结果必须存在于子查询的结果中。在这里要将作为"M"集合的子查询转换为不允许重复元素存在的"1"集合,所以执行了SORT(UNIQUE)。
SORT AGGREGATE这是指在没有 GROUP BY 的前提下,使用统计函数对全部数据对象进行计算时所显示出来的执行计划。在使用SUM、COUNT、MIN、MAX、AVG等统计函数时并不执行一般排序动作。实际上是读取每一行数据为对象进行求和、计数、比较大小等操作,可通过一个全局变量+全表/全索引扫描来实现。
SORT GROUP BY该操作是将数据行向不同分组中聚集的操作,即依据查询语句中所使用的GROUP BY而进行相关操作,为了进行分组就只能排序。需要分组的数据量越大,代价就越大。在10gR2以后的版本中,哈希分组-HASH (GROUPBY)。在处理海量数据时使用哈希处理比使用排序处理更有效。
SORT ORDER BY当对一个不能满足索引列进行排序时,就需要一个SORT ORDER BY。这里可以有个优化,针对取出排序结果前几条的场景,是可以提前结束排序动作,节省资源。
SORT JOIN在表关联的场景中,如果行按照连接键排序,在排序合并连接时将会发生SORT JOIN。SORT JOIN 发生在出现MERGE JOIN的情况下,两张关联的表要各自做SORT,然后在MERGE。
(2)Oracle 测试示例
(3)国产库测试示例
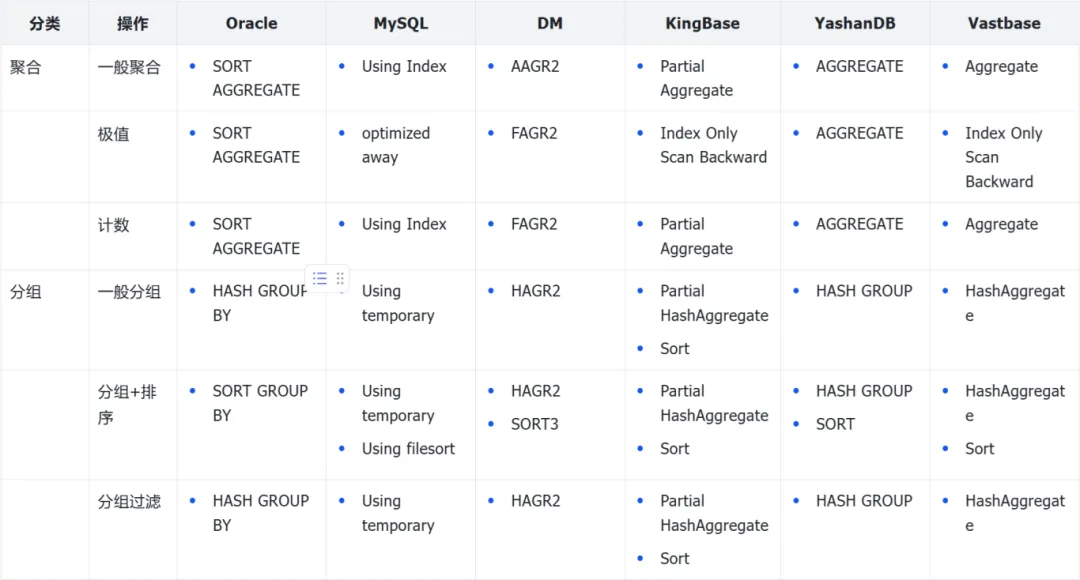
下面是针对上述测例,国产库的行为如何?先来看看整体结果。
2.分组聚合
数据库中的分组聚合是两类操作:分组操作是指用SQL语句将一个结果集分为若干组,并对这样每一组进行聚合计算;聚合操作则是基于多行记录返回数据数据:平均、最大、最小值等,聚合操作必须处理输入数据的每一行记录,因此通常和全表扫描联系在一起。
(1)常见分组聚合操作
针对常见的分组聚合类操作,抽象出一组测例,看看Oracle和国产库的行为如何。
聚合:一般聚合对整个结果集进行计算,一般都是走的全表扫描,如果有索引则会走索引快速全扫描。
聚合:极值针对结果集的最大、最小值等计算,如果是索引列,可采用一些更优的做法,因为后者是有序的。
聚合:计数对整个结果集进行计数,一般走全表扫描,如果有不可为空的列索引,优化器也是可以采用的。
分组:一般分组一般分组下,可采用排序分组的方式,也可采用更为推荐的哈希分组,这样代价更小。
分组:分组+排序如果针对分组后的结果还需要排序操作,上面说的哈希分组就不太合适。如果通过 SORT GROUP BY能解决分组问题的同时,还能提供有序的结果集输出,无疑效率是要比 HASH GROUP BY 更高的。
分组:分组过滤针对分组数据进行过滤,可以有两种方式 WHERE 或 HAVING。如果记录可以通过WHERE来排除,应该在聚合发生之前就已经被排除。相比之下,HAVING在聚合完成之后对记录进行排除。参与聚合的记录越少,效果就越好,所以一般情况下WHERE子句在这方面比HAVING子句更可取。
(2)Oracle 测试示例
(3)国产库测试示例
下面是针对上述测例,国产库的行为如何?先来看看整体结果