主流AI平台擅自共享用户个人信息 ,用户掌控权严重缺失
根据Incogni的研究报告,包括Meta、谷歌和微软在内的多家主流生成式AI和大语言模型(LLM)平台正在收集敏感数据并与不明第三方共享,导致用户对自身信息的存储、使用和共享方式既缺乏透明度,也几乎没有任何控制权。
谷歌Gemini、Meta AI、DeepSeek和Pi.ai等平台均未提供退出机制来阻止用户输入内容被用于AI模型训练。一旦输入个人或敏感数据,实际上无法从AI训练数据集中删除这些信息。尽管《通用数据保护条例》(GDPR)等法律赋予个人要求删除数据的权利,但如何从机器学习模型中实际移除信息仍不明确。因此,许多公司目前既无义务也缺乏技术能力来事后删除此类数据。用户的联系信息或商业机密可能在未经明确告知或同意的情况下,被永久嵌入模型训练数据中。
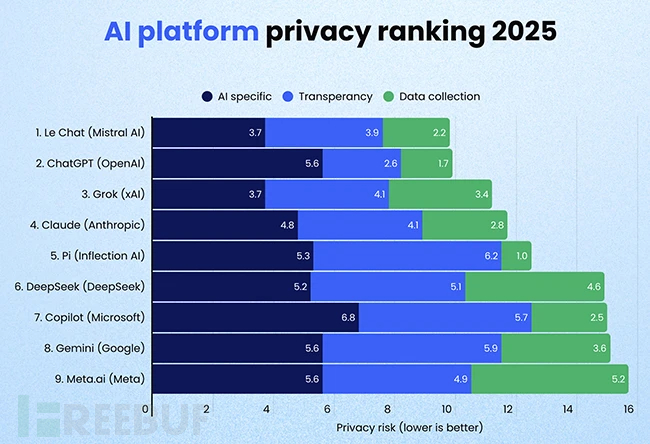
数据收集行为全景扫描随着生成式AI日益融入日常生活,用户往往不清楚这些工具收集了哪些个人数据、如何使用以及最终流向何处。研究人员从三个维度分析了主流AI平台的数据实践:用户数据在模型训练中的使用情况、平台隐私政策的透明度、数据收集与第三方共享的范围。
Meta.ai和Gemini会收集用户的精确定位数据和实体地址Claude根据其Google Play商店页面显示,会向第三方共享电子邮件、电话号码和应用交互数据Grok(xAI)可能将用户提供的照片和应用交互数据共享给第三方Meta.ai会与外部实体(包括研究合作伙伴和企业集团成员)共享姓名、电子邮件和电话号码微软的隐私政策暗示用户输入内容可能被共享给涉及在线广告或使用微软广告技术的第三方Gemini、DeepSeek、Pi.ai和Meta.ai很可能未提供退出模型训练的选择权ChatGPT在说明哪些输入内容会用于模型训练方面最为透明,并制定了清晰的隐私政策即便用户主动寻求解释,相关细节也往往隐藏在零散的帮助页面或用晦涩的法律术语书写。Incogni发现所有被分析的隐私政策都需要大学水平的阅读能力才能理解。
员工使用AI或致商业机密外泄除个人隐私外,企业面临的风险更为严峻。员工常使用生成式AI工具协助起草内部报告或通讯,却未意识到这可能导致专有数据成为模型训练集的一部分。这种保护机制的缺失不仅使个人面临非自愿数据共享,还可能导致敏感商业数据在未来与其他用户的交互中被重复利用,从而引发隐私、合规和竞争风险。
"多数人以为只是在与可信助手对话,并未泄露联系信息或商业机密。"Incogni负责人Darius Belejevas指出,"实际情况更具侵入性,而企业并未让用户轻松理解数据的真实流向。用户有权知晓哪些数据被收集、谁能查看以及如何阻止。目前这些答案往往难以寻觅,甚至根本不存在。"