在 Linux 内核这片深邃而神秘的技术海洋里,每一个系统进程的运行、每一次资源的调度,都像是在黑暗中上演的复杂剧目。内核开发者们时常面临着棘手难题:系统莫名卡顿,究竟是哪个内核函数在作祟?进程调度出现异常,问题根源又在何处?在漫长的探索历程中,开发者们急需一款强大的工具,能够像聚光灯一样,穿透重重迷雾,照亮内核运行的每一个角落。而 Ftrace,正是这样一款应运而生的 “内核追踪神器”。
它从最初简单的函数跟踪器,逐步成长为功能丰富的跟踪框架,犹如一把万能钥匙,为开发者打开了深入探究内核奥秘的大门。接下来,让我们一同深入到 Ftrace 的世界,探寻它的实现原理,看看它究竟如何施展神奇魔力,助力开发者解决内核开发与调试中的种种难题 。
一、Ftrace是什么?
根据Linux Doc 的介绍,ftrace 是一个 Linux 内部的 trace 工具,能够帮助开发者和系统设计者知道内核当前正在干啥,从而更好的去分析性能问题。在 Linux 内核开发与系统性能优化的广袤领域中,Ftrace 宛如一把神奇的瑞士军刀,发挥着无可替代的关键作用。对于内核开发者而言,它是深入探究内核运行机制、精准定位代码问题的得力助手;对于系统优化者来说,它是剖析系统性能瓶颈、实现高效优化的必备利器。
曾经,在一个高并发的 Web 服务器项目中,服务器在流量高峰时段出现响应延迟的状况。运维团队起初一头雾水,不知问题根源所在。后来,他们借助 Ftrace 工具,对内核函数进行细致跟踪。通过 Function Graph Tracer,清晰呈现出函数调用关系;利用 Irqsoff Tracer,监测中断被禁止的时段。最终,成功定位到一个文件读写函数存在性能瓶颈,经过针对性优化,服务器响应速度大幅提升,成功解决了延迟问题。
Ftrace 能帮我们分析内核特定的事件,譬如调度,中断等,也能帮我们去追踪动态的内核函数,以及这些函数的调用栈还有栈的使用这些。它也能帮我们去追踪延迟,譬如中断被屏蔽,抢占被禁止的时间,以及唤醒一个进程之后多久开始执行的时间。
可以看到,使用 ftrace 真的能做到对系统内核非常系统的剖析,甚至都能通过 ftrace 来学习 Linux 内核,不过在更进一步之前,我们需要学会的是 - 如何使用 ftrace
二、 如何使用 ftrace
要使用 ftrace,首先就是需要将系统的 debugfs 或者 tracefs 给挂载到某个地方,幸运的是,几乎所有的 Linux 发行版,都开启了 debugfs/tracefs 的支持,所以我们也没必要去重新编译内核了。
在比较老的内核版本,譬如 CentOS 7 的上面,debugfs 通常被挂载到 /sys/kernel/debug 上面(debug 目录下面有一个 tracing 目录),而比较新的内核,则是将 tracefs 挂载到 /sys/kernel/tracing,无论是什么,我都喜欢将 tracing 目录直接 link 到 /tracing。后面都会假设直接进入了 /tracing 目录,后面,我会使用 Ubuntu 16.04 来举例子,内核版本是 4.13 来举例子。
在使用ftrace之前,需要内核进行支持,也就是内核需要打开编译中的ftrace相关选项,关于怎么激活ftrace选项的问题,可以google之,下面只说明重要的设置步骤:
mkdir /debug;mount -t debugs nodev /debug; /*挂载debugfs到创建的目录中去*/cd /debug; cd tracing; /*如果没有tracing目录,则内核目前还没有支持ftrace,需要配置参数,重新编译*/。echo nop > current_tracer;//清空tracerecho function_graph > current_tracer;//使用图形显示调用关系echo ip_rcv > set_graph_function;//设置过滤函数,可以设置多个echo 1 > tracing_enabled开始追踪
2.1传统 fracer 的使用
使用传统的 ftrace 需要如下几个步骤:
选择一种 tracer使能 ftrace执行需要 trace 的应用程序,比如需要跟踪 ls,就执行 ls关闭 ftrace查看 trace 文件
用户通过读写 debugfs 文件系统中的控制文件完成上述步骤。使用 debugfs,首先要挂载它。命令如下:
复制
# mkdir /debug
# mount -t debugfs nodev /debug1.2.
此时您将在 /debug 目录下看到 tracing 目录。Ftrace 的控制接口就是该目录下的文件。
选择 tracer 的控制文件叫作 current_tracer 。选择 tracer 就是将 tracer 的名字写入这个文件,比如,用户打算使用 function tracer,可输入如下命令:
复制
#echo ftrace > /debug/tracing/current_tracer1.
文件 tracing_enabled 控制 ftrace 的开始和结束。
复制
#echo 1 >/debug/tracing/tracing_enable1.
上面的命令使能 ftrace 。同样,将 0 写入 tracing_enable 文件便可以停止 ftrace 。
ftrace 的输出信息主要保存在 3 个文件中:
Trace,该文件保存 ftrace 的输出信息,其内容可以直接阅读。latency_trace,保存与 trace 相同的信息,不过组织方式略有不同。主要为了用户能方便地分析系统中有关延迟的信息。trace_pipe 是一个管道文件,主要为了方便应用程序读取 trace 内容。算是扩展接口吧。
我们使用 ls 来看看目录下面到底有什么:
复制
README current_tracer hwlat_detector per_cpu set_event_pid snapshot trace_marker tracing_max_latency
available_events dyn_ftrace_total_info instances printk_formats set_ftrace_filter stack_max_size trace_marker_raw tracing_on
available_filter_functions enabled_functions kprobe_events saved_cmdlines set_ftrace_notrace stack_trace trace_options tracing_thresh
available_tracers events kprobe_profile saved_cmdlines_size set_ftrace_pid stack_trace_filter trace_pipe uprobe_events
buffer_size_kb free_buffer max_graph_depth saved_tgids set_graph_function trace trace_stat uprobe_profile
buffer_total_size_kb function_profile_enabled options set_event set_graph_notrace trace_clock tracing_cpumask1.2.3.4.5.6.
可以看到,里面有非常多的文件和目录,具体的含义,大家可以去详细的看官方文档的解释,后面只会重点介绍一些文件。
2.2功能
我们可以通过 available_tracers 这个文件知道当前 ftrace 支持哪些插件。
复制
cat available_tracers
hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop1.2.
通常用的最多的就是function和function_graph,当然,如果我们不想 trace 了,可以使用nop。我们首先打开function:
复制
echo function > current_tracer
cat current_tracer
function1.2.3.
上面我们将 function 写入到了 current_tracer 来开启 function 的 trace,我通常会在 cat 下 current_tracer 这个文件,主要是防止自己写错了。然后 ftrace 就开始工作了,会将相关的 trace 信息放到 trace 文件里面,我们直接读取这个文件就能获取相关的信息。
复制
cat trace | head -n 15
# tracer: function
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
bash-29409 [002] .... 16158426.215771: mutex_unlock <-tracing_set_tracer
<idle>-0 [039] d... 16158426.215771: call_cpuidle <-do_idle
<idle>-0 [039] d... 16158426.215772: cpuidle_enter <-call_cpuidle
<idle>-0 [039] d... 16158426.215773: cpuidle_enter_state <-cpuidle_enter
bash-29409 [002] .... 16158426.215773: __fsnotify_parent <-vfs_write
<idle>-0 [039] d... 16158426.215773: sched_idle_set_state <-cpuidle_enter_state1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.
我们可以设置只跟踪特定的 function
复制
echo schedule > set_ftrace_filter
cat set_ftrace_filter
schedule
cat trace | head -n 15
# tracer: function
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
bash-29409 [010] .... 16158462.591708: schedule <-schedule_timeout
kworker/u81:2-29339 [008] .... 16158462.591736: schedule <-worker_thread
sshd-29395 [012] .... 16158462.591788: schedule <-schedule_hrtimeout_range_clock
rcu_sched-9 [010] .... 16158462.595475: schedule <-schedule_timeout
java-23597 [006] .... 16158462.600326: schedule <-futex_wait_queue_me
java-23624 [020] .... 16158462.600855: schedule <-schedule_hrtimeout_range_clock1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
当然,如果我们不想 trace schedule 这个函数,也可以这样做:
复制
echo !schedule > set_ftrace_filter1.
或者也可以这样做:
复制
echo schedule > set_ftrace_notrace1.
Function filter 的设置也支持 *match,match* ,*match* 这样的正则表达式,譬如我们可以 echo *lock* < set_ftrace_notrace 来禁止跟踪带 lock 的函数,set_ftrace_notrace 文件里面这时候就会显示:
复制
cat set_ftrace_notrace
xen_pte_unlock
read_hv_clock_msr
read_hv_clock_tsc
update_persistent_clock
read_persistent_clock
set_task_blockstep
user_enable_block_step
...1.2.3.4.5.6.7.8.9.
2.3函数图
相比于 function,function_graph 能让我们更加详细的去知道内核函数的上下文,我们打开 function_graph:
复制
echo function_graph > current_tracer
cat trace | head -15
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
10) 0.085 us | sched_idle_set_state();
10) | cpuidle_reflect() {
10) 0.035 us | menu_reflect();
10) 0.288 us | }
10) | rcu_idle_exit() {
10) 0.034 us | rcu_dynticks_eqs_exit();
10) 0.296 us | }
10) 0.032 us | arch_cpu_idle_exit();
10) | tick_nohz_idle_exit() {
10) 0.073 us | ktime_get();
10) | update_ts_time_stats() {1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.
我们也可以只跟踪某一个函数的堆栈。
复制
echo kfree > set_graph_function
cat trace | head -n 15
# tracer: function_graph
#
# CPU DURATION FUNCTION CALLS
# | | | | | | |
16) | kfree() {
16) 0.147 us | __slab_free();
16) 1.437 us | }
10) 0.162 us | kfree();
17) @ 923817.3 us | } /* intel_idle */
17) 0.044 us | sched_idle_set_state();
17) ==========> |
17) | smp_apic_timer_interrupt() {
17) | irq_enter() {
17) | rcu_irq_enter() {
17) 0.049 us | rcu_dynticks_eqs_exit();1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.
2.4事件
上面提到了 function 的 trace,在 ftrace 里面,另外用的多的就是 event 的 trace,我们可以在 events 目录下面看支持那些事件:
复制
ls events/
alarmtimer cma ext4 fs_dax i2c kvm mmc nmi printk regulator smbus task vmscan xdp
block compaction fib ftrace iommu kvmmmu module oom random rpm sock thermal vsyscall xen
bpf cpuhp fib6 gpio irq libata mpx page_isolation ras sched spi thermal_power_allocator wbt xhci-hcd
btrfs dma_fence filelock header_event irq_vectors mce msr pagemap raw_syscalls scsi swiotlb timer workqueue
cgroup enable filemap header_page jbd2 mdio napi percpu rcu signal sync_trace tlb writeback
clk exceptions fs huge_memory kmem migrate net power regmap skb syscalls udp x86_fpu1.2.3.4.5.6.7.
上面列出来的都是分组的,我们可以继续深入下去,譬如下面是查看sched相关的事件:
复制
ls events/sched/
enable sched_migrate_task sched_process_exit sched_process_wait sched_stat_sleep sched_switch sched_wakeup_new
filter sched_move_numa sched_process_fork sched_stat_blocked sched_stat_wait sched_wait_task sched_waking
sched_kthread_stop sched_pi_setprio sched_process_free sched_stat_iowait sched_stick_numa sched_wake_idle_without_ipi
sched_kthread_stop_ret sched_process_exec sched_process_hang sched_stat_runtime sched_swap_numa sched_wakeup1.2.3.4.5.
对于某一个具体的事件,我们也可以查看:
复制
ls events/sched/sched_wakeup
enable filter format hist id trigger1.2.
不知道大家注意到了没有,上述目录里面,都有一个enable的文件,我们只需要往里面写入 1,就可以开始 trace 这个事件。譬如下面就开始 tracesched_wakeup这个事件:
复制
echo 1 > events/sched/sched_wakeup/enable
cat trace | head -15
# tracer: nop
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
bash-29409 [012] d... 16158657.832294: sched_wakeup: comm=kworker/u81:1 pid=29359 prio=120 target_cpu=008
kworker/u81:1-29359 [008] d... 16158657.832321: sched_wakeup: comm=sshd pid=29395 prio=120 target_cpu=010
<idle>-0 [012] dNs. 16158657.835922: sched_wakeup: comm=rcu_sched pid=9 prio=120 target_cpu=012
<idle>-0 [024] dNh. 16158657.836908: sched_wakeup: comm=java pid=23632 prio=120 target_cpu=024
<idle>-0 [022] dNh. 16158657.839921: sched_wakeup: comm=java pid=23624 prio=120 target_cpu=022
<idle>-0 [016] dNh. 16158657.841866: sched_wakeup: comm=java pid=23629 prio=120 target_cpu=0161.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.
我们也可以 tracesched里面的所有事件:
复制
echo 1 > events/sched/enable
cat trace | head -15
# tracer: nop
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
bash-29409 [010] d... 16158704.468377: sched_waking: comm=kworker/u81:2 pid=29339 prio=120 target_cpu=008
bash-29409 [010] d... 16158704.468378: sched_stat_sleep: comm=kworker/u81:2 pid=29339 delay=164314267 [ns]
bash-29409 [010] d... 16158704.468379: sched_wake_idle_without_ipi: cpu=8
bash-29409 [010] d... 16158704.468379: sched_wakeup: comm=kworker/u81:2 pid=29339 prio=120 target_cpu=008
bash-29409 [010] d... 16158704.468382: sched_stat_runtime: comm=bash pid=29409 runtime=360343 [ns] vruntime=131529875864926 [ns]
bash-29409 [010] d... 16158704.468383: sched_switch: prev_comm=bash prev_pid=29409 prev_prio=120 prev_state=S ==> next_comm=swapper/10 next_pid=0 next_prio=1201.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.
当然也可以 trace 所有的事件:
复制
echo 1 > events/enable
cat trace | head -15
# tracer: nop
#
# _-----=> irqs-off
# / _----=> need-resched
# | / _---=> hardirq/softirq
# || / _--=> preempt-depth
# ||| / delay
# TASK-PID CPU# |||| TIMESTAMP FUNCTION
# | | | |||| | |
bash-29409 [010] .... 16158761.584188: writeback_mark_inode_dirty: bdi (unknown): ino=3089 state=I_DIRTY_SYNC|I_DIRTY_DATASYNC|I_DIRTY_PAGES flags=I_DIRTY_SYNC|I_DIRTY_DATASYNC|I_DIRTY_PAGES
bash-29409 [010] .... 16158761.584189: writeback_dirty_inode_start: bdi (unknown): ino=3089 state=I_DIRTY_SYNC|I_DIRTY_DATASYNC|I_DIRTY_PAGES flags=I_DIRTY_SYNC|I_DIRTY_DATASYNC|I_DIRTY_PAGES
bash-29409 [010] .... 16158761.584190: writeback_dirty_inode: bdi (unknown): ino=3089 state=I_DIRTY_SYNC|I_DIRTY_DATASYNC|I_DIRTY_PAGES flags=I_DIRTY_SYNC|I_DIRTY_DATASYNC|I_DIRTY_PAGES
bash-29409 [010] .... 16158761.584193: do_sys_open: "trace" 8241 666
bash-29409 [010] .... 16158761.584193: kmem_cache_free: call_site=ffffffff8e862614 ptr=ffff91d241fa4000
bash-29409 [010] .... 16158761.584194: sys_exit: NR 2 = 31.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.
2.5trace-cmd
从上面的例子可以看到,其实使用 ftrace 并不是那么方便,我们需要手动的去控制多个文件,但幸运的是,我们有 trace-cmd,作为 ftrace 的前端,trace-cmd 能够非常方便的让我们进行 ftrace 的操作,譬如我们可以使用 record 命令来 trace sched 事件:
复制
trace-cmd record -e sched1.
然后使用report命令来查看 trace 的数据:
复制
trace-cmd report | head -10
version = 6
CPU 27 is empty
cpus=40
trace-cmd-29557 [003] 16159201.985281: sched_waking: comm=kworker/u82:3 pid=28507 prio=120 target_cpu=037
trace-cmd-29557 [003] 16159201.985283: sched_migrate_task: comm=kworker/u82:3 pid=28507 prio=120 orig_cpu=37 dest_cpu=5
trace-cmd-29557 [003] 16159201.985285: sched_stat_sleep: comm=kworker/u82:3 pid=28507 delay=137014529 [ns]
trace-cmd-29585 [023] 16159201.985286: sched_stat_runtime: comm=trace-cmd pid=29585 runtime=217630 [ns] vruntime=107586626253137 [ns]
trace-cmd-29557 [003] 16159201.985286: sched_wake_idle_without_ipi: cpu=5
trace-cmd-29595 [037] 16159201.985286: sched_stat_runtime: comm=trace-cmd pid=29595 runtime=213227 [ns] vruntime=105364596011783 [ns]
trace-cmd-29557 [003] 16159201.985287: sched_wakeup: kworker/u82:3:28507 [120] success=1 CPU:0051.2.3.4.5.6.7.8.9.10.11.
当然,在report的时候也可以加入自己的 filter 来过滤数据,譬如下面,我们就过滤出sched_wakeup事件并且是success为 1 的。
复制
trace-cmd report -F sched/sched_wakeup: success == 1 | head -10
version = 6
CPU 27 is empty
cpus=40
trace-cmd-29557 [003] 16159201.985287: sched_wakeup: kworker/u82:3:28507 [120] success=1 CPU:005
trace-cmd-29557 [003] 16159201.985292: sched_wakeup: trace-cmd:29561 [120] success=1 CPU:007
<idle>-0 [032] 16159201.985294: sched_wakeup: qps_json_driver:24669 [120] success=1 CPU:032
<idle>-0 [032] 16159201.985298: sched_wakeup: trace-cmd:29590 [120] success=1 CPU:026
<idle>-0 [010] 16159201.985300: sched_wakeup: trace-cmd:29563 [120] success=1 CPU:010
trace-cmd-29597 [037] 16159201.985302: sched_wakeup: trace-cmd:29595 [120] success=1 CPU:039
<idle>-0 [010] 16159201.985302: sched_wakeup: sshd:29395 [120] success=1 CPU:0101.2.3.4.5.6.7.8.9.10.11.
大家可以注意下success == 1,这其实是一个对事件里面 field 进行的表达式运算了,对于不同的事件,我们可以通过查看其format 来知道它的实际 fields 是怎样的,譬如:
复制
cat events/sched/sched_wakeup/format
name: sched_wakeup
ID: 294
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:char comm[16]; offset:8; size:16; signed:1;
field:pid_t pid; offset:24; size:4; signed:1;
field:int prio; offset:28; size:4; signed:1;
field:int success; offset:32; size:4; signed:1;
field:int target_cpu; offset:36; size:4; signed:1;
print fmt: "comm=%s pid=%d prio=%d target_cpu=%03d", REC->comm, REC->pid, RE1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.
三、Ftrace 工作原理
3.1插桩技术
Ftrace 主要采用了静态插桩和动态插桩两种方式来实现其强大的跟踪功能。
静态插桩,简单来说,就是在编译内核时,借助编译器的特定选项,在目标代码中插入额外的代码片段。具体而言,当内核配置打开CONFIG_FUNCTION_TRACER功能后,会添加一个-pg编译选项 ,这就如同在每个函数入口处埋下了一个 “小标记”—— 插入bl mcount跳转指令。
如此一来,当每个函数运行时,都会先进入mcount函数。这种方式的优点是可靠性高,只要内核编译时配置好,所有相关函数都会被插桩,能全面地记录函数调用信息。然而,它的缺点也很明显,由于对内核中所有函数都进行插桩,会带来较大的性能开销,在一些对性能要求极高的场景下,可能会导致系统运行效率大幅下降,甚至影响系统的正常运行。
为了克服静态插桩的性能问题,动态插桩应运而生。这里的 “动态”,体现在动态修改函数指令。在编译时,会记录所有支持追踪的函数,这些函数原本被添加了跳转指令。但在内核启动后,为了减少性能损耗,内核会将所有跳转指令替换为nop指令(nop指令表示空操作,不执行任何实际运算,对系统性能几乎没有影响),此时系统处于非调试状态,性能损失几乎为零。
当需要进行跟踪时,根据function tracer的设置,Ftrace 会动态地将需要调试的函数的nop指令替换为跳转指令,从而实现对这些特定函数的追踪。动态插桩就像是一个智能的 “追踪开关”,只有在需要时才开启对特定函数的追踪,大大减少了不必要的性能开销,使得 Ftrace 在生产环境中的使用更加灵活和高效。
3.2追踪器类型
Ftrace 拥有丰富多样的追踪器,每个追踪器都有其独特的功能和适用场景。
Function tracer 是最基础的追踪器之一,主要用于跟踪内核函数的执行情况。它可以清晰地记录下每个内核函数的调用时间、调用顺序以及返回值等信息。在调试内核代码时,如果怀疑某个函数的执行逻辑存在问题,就可以使用 Function tracer,通过分析它记录的函数执行信息,快速定位到问题所在。比如,在开发一个新的内核模块时,发现某个功能无法正常实现,利用 Function tracer 跟踪相关函数的调用过程,可能会发现某个函数没有按照预期被调用,或者返回值不符合预期,从而找到问题的根源。
Function graph tracer 则以更加直观的方式展示函数调用关系。它不仅能记录函数的调用情况,还能以类似 C 语言函数调用关系图的形式,展示出函数的调用层次关系以及返回情况 。这对于理解复杂的内核代码逻辑非常有帮助。在分析系统性能瓶颈时,如果发现某个功能的执行效率较低,使用 Function graph tracer 可以清晰地看到该功能涉及的函数调用链,找出哪些函数的执行时间较长,哪些函数的调用次数过于频繁,从而有针对性地进行优化。例如,在一个文件系统的性能优化中,通过 Function graph tracer 发现文件读写函数在调用过程中,存在一些不必要的函数嵌套调用,通过优化这些调用关系,大大提高了文件系统的读写性能。
除了上述两种追踪器,还有其他一些追踪器也各有其用。Sched_switch 追踪器主要用于跟踪系统中进程调度情况,记录进程的切换时间、切换原因等信息,对于分析系统的调度性能和进程间的资源竞争问题非常有用;Irqsoff 追踪器专注于跟踪禁止中断的函数及相关信息,能够记录中断被禁止的时长,帮助开发者定位那些可能导致系统响应延迟的中断操作;Preemptoff 追踪器则用于跟踪禁止内核抢占的函数及相关信息,对于优化系统的实时性和响应速度具有重要意义。
3.3数据记录与存储
当 Ftrace 通过插桩技术收集到各种跟踪信息后,这些信息需要被有效地记录和存储起来,以便用户后续查看和分析。Ftrace 采用了 Ring buffer 缓冲区来存储这些跟踪数据。
Ring buffer,也称为环形缓冲区,是一种特殊的数据结构,它就像一个首尾相连的环形数组。在 Ftrace 中,Ring buffer 的工作原理如下:当有新的跟踪信息产生时,Ftrace 会将其依次写入 Ring buffer 中。当 Ring buffer 被写满后,新的数据会覆盖最早写入的数据,就像一个循环的队列一样。这种设计方式可以确保 Ring buffer 能够持续地记录最新的跟踪信息,同时又不会因为数据过多而占用大量的内存空间。在读取数据时,用户可以从 Ring buffer 的头部开始读取,读取完的数据不会被立即删除,而是等待被新的数据覆盖。这样,用户可以根据自己的需求,多次读取 Ring buffer 中的数据,进行不同角度的分析。
为了方便用户操作和管理 Ring buffer 中的数据,Ftrace 通过debugfs文件系统向用户空间提供了一系列的接口文件。用户可以通过这些文件,轻松地开启或停止跟踪、选择使用的追踪器、设置跟踪的过滤条件,以及读取 Ring buffer 中存储的跟踪信息。在/sys/kernel/debug/tracing目录下,有许多与 Ftrace 相关的文件,其中trace文件用于以人类可读的格式展示当前追踪的内容,用户可以通过cat trace命令查看这些内容;tracing_on文件则用于控制追踪的开启和停止,向该文件写入1表示启用追踪,写入0表示停止追踪 。通过这些简单的文件操作,用户就可以灵活地使用 Ftrace 进行各种内核跟踪和分析工作。
四、ftrace的实现
研究 tracer 的实现是非常有乐趣的。理解 ftrace 的实现能够启发我们在自己的系统中设计更好的 trace 功能。
4.1ftrace 的整体构架
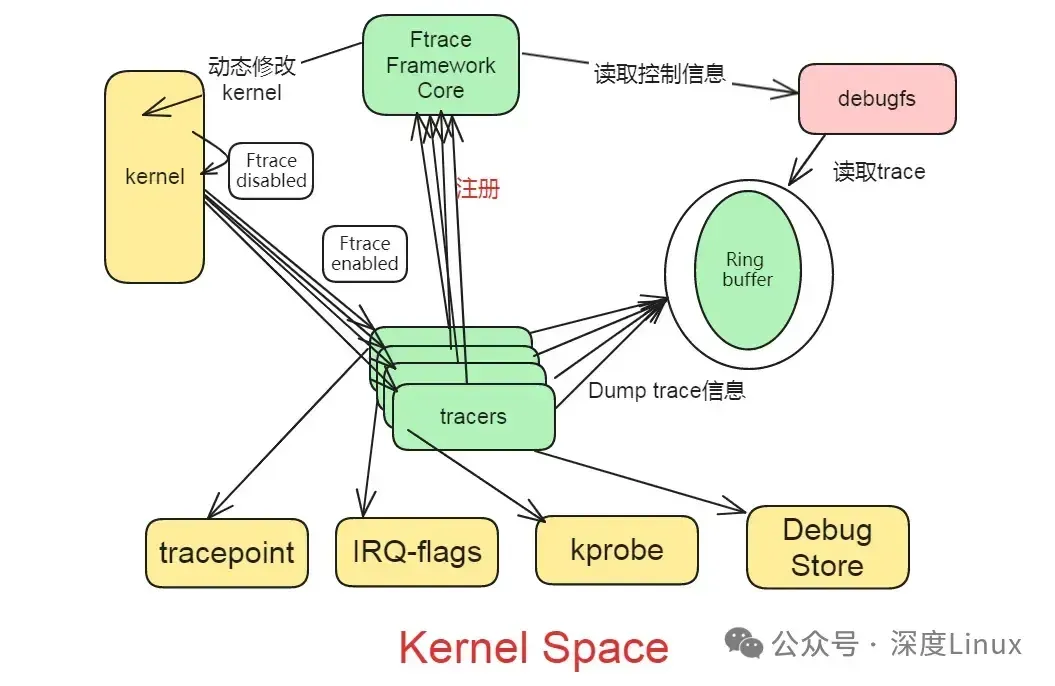 图片
图片
Ftrace 有两大组成部分,一是 framework,另外就是一系列的 tracer 。每个 tracer 完成不同的功能,它们统一由 framework 管理。ftrace 的 trace 信息保存在 ring buffer 中,由 framework 负责管理。Framework 利用 debugfs 系统在 /debugfs 下建立 tracing 目录,并提供了一系列的控制文件。
一句话总结:各类tracer往ftrace主框架注册,不同的trace则在不同的probe点把信息通过probe函数给送到ring buffer中,再由暴露在用户态debufs实现相关控制。对不同tracer来说:
1)需要实现probe点(需要跟踪的代码侦测点),有的probe点需要静态代码实现,有的probe点借助编译器在运行时动态替换,event tracing属于前者;2)还要实现具体的probe函数,把需要记录的信息送到ring buffer中;3)增加debugfs 相关的文件,实现信息的解析和控制。
而ring buffer 和debugfs的通用部分的管理由框架负责。
4.2Function tracer 的实现
Ftrace 采用 GCC 的 profile 特性在所有内核函数的开始部分加入一段 stub 代码,ftrace 重载这段代码来实现 trace 功能。gcc 的 -pg 选项将在每个函数入口处加入对 mcount 的调用代码。比如下面的 C 代码。
清单 1. test.c
复制
//test.c
void foo(void)
{
printf( “ foo ” );
}1.2.3.4.5.
用 gcc 编译:
反汇编如下:
清单 2. test.c 不加入 pg 选项的汇编代码
复制
_foo:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
movl $LC0, (%esp)
call _printf
leave
ret1.2.3.4.5.6.7.8.
再加入 -gp 选项编译:
得到的汇编如下:
清单 3. test.c 加入 pg 选项后的汇编代码
复制
_foo:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
LP3:
movl $LP3,%edx
call _mcount
movl $LC0, (%esp)
call _printf
leave
ret1.2.3.4.5.6.7.8.9.10.11.
增加 pg 选项后,gcc 在函数 foo 的入口处加入了对 mcount 的调用:call _mcount 。原本 mcount 由 libc 实现,但您知道内核不会连接 libc 库,因此 ftrace 编写了自己的 mcount stub 函数,并借此实现 trace 功能。
在每个内核函数入口加入 trace 代码,必然会影响内核的性能,为了减小对内核性能的影响,ftrace 支持动态 trace 功能。
当 CONFIG_DYNAMIC_FTRACE 被选中后,内核编译时会调用一个 perl 脚本:recordmcount.pl 将每个函数的地址写入一个特殊的段:__mcount_loc
在内核初始化的初期,ftrace 查询 __mcount_loc 段,得到每个函数的入口地址,并将 mcount 替换为 nop 指令。这样在默认情况下,ftrace 不会对内核性能产生影响。
当用户打开 ftrace 功能时,ftrace 将这些 nop 指令动态替换为 ftrace_caller,该函数将调用用户注册的 trace 函数。其具体的实现在相应 arch 的汇编代码中,以 x86 为例,在 entry_32.s 中:
清单 4. entry_32.s
复制
ENTRY(ftrace_caller)
cmpl $0, function_trace_stop
jne ftrace_stub
pushl %eax
pushl %ecx
pushl %edx
movl 0xc(%esp), %eax
movl 0x4(%ebp), %edx
subl $MCOUNT_INSN_SIZE, %eax
.globl ftrace_call
ftrace_call:
call ftrace_stubline 10popl %edx
popl %ecx
popl %eax
.globl ftrace_stub
ftrace_stub:
ret
END(ftrace_caller)1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
Function tracer 将 line10 这行代码替换为 function_trace_call() 。这样每个内核函数都将调用 function_trace_call() 。
在 function_trace_call() 函数内,ftrace 记录函数调用堆栈信息,并将结果写入 ring buffer,稍后,用户可以通过 debugfs 的 trace 文件读取该 ring buffer 中的内容。
4.3 Irqsoff tracer 的实现
Irqsoff tracer 的实现依赖于 IRQ-Flags 。IRQ-Flags 是 Ingo Molnar 维护的一个内核特性。使得用户能够在中断关闭和打开时得到通知,ftrace 重载了其通知函数,从而能够记录中断禁止时间。即,中断被关闭时,记录下当时的时间戳。此后,中断被打开时,再计算时间差,由此便可得到中断禁止时间。
IRQ-Flags 封装开关中断的宏定义:
清单 5. IRQ-Flags 中断代码
复制
#define local_irq_enable() \
do { trace_hardirqs_on (); raw_local_irq_enable(); } while (0)1.2.
ftrace 在文件 ftrace_irqsoff.c 中重载了 trace_hardirqs_on 。具体代码不再罗列,主要是使用了 sched_clock()函数来获得时间戳。
4.4hw-branch 的实现
Hw-branch 只在 IA 处理器上实现,依赖于 x86 的 BTS 功能。BTS 将 CPU 实际执行到的分支指令的相关信息保存下来,即每个分支指令的源地址和目标地址。
软件可以指定一块 buffer,处理器将每个分支指令的执行情况写入这块 buffer,之后,软件便可以分析这块 buffer 中的功能。
Linux 内核的 DS 模块封装了 x86 的 BTS 功能。Debug Support 模块封装了和底层硬件的接口,主要支持两种功能:Branch trace store(BTS) 和 precise-event based sampling (PEBS) 。ftrace 主要使用了 BTS 功能。
4.5branch tracer 的实现
内核代码中常使用 likely 和 unlikely 提高编译器生成的代码质量。Gcc 可以通过合理安排汇编代码最大限度的利用处理器的流水线。合理的预测是 likely 能够提高性能的关键,ftrace 为此定义了 branch tracer,跟踪程序中 likely 预测的正确率。
为了实现 branch tracer,重新定义了 likely 和 unlikely 。具体的代码在 compiler.h 中。
清单 6. likely/unlikely 的 trace 实现
复制
# ifndef likely
# define likely(x) (__builtin_constant_p(x) ? !!(x) : __branch_check__(x, 1))
# endif
# ifndef unlikely
# define unlikely(x) (__builtin_constant_p(x) ? !!(x) : __branch_check__(x, 0))
# endif1.2.3.4.5.6.
其中 __branch_check 的实现如下:
清单 7. _branch_check_ 的实现
复制
#define __branch_check__(x, expect) ({\
int ______r; \
static struct ftrace_branch_data \
__attribute__((__aligned__(4))) \
__attribute__((section("_ftrace_annotated_branch"))) \
______f = { \
.func = __func__, \
.file = __FILE__, \
.line = __LINE__, \
}; \
______r = likely_notrace(x);\
ftrace_likely_update(&______f, ______r, expect); \
______r; \
})1.2.3.4.5.6.7.8.9.10.11.12.13.14.
ftrace_likely_update() 将记录 likely 判断的正确性,并将结果保存在 ring buffer 中,之后用户可以通过 ftrace 的 debugfs 接口读取分支预测的相关信息。从而调整程序代码,优化性能。
五、Ftrace 的实战应用
5.1性能优化
在性能优化领域,Ftrace 的作用不可小觑,尤其是在优化文件系统性能方面。假设我们在一个数据存储服务器上发现文件读写操作的速度明显变慢,严重影响了业务的正常运行。这时,我们可以利用 Ftrace 的 Function graph tracer 来深入分析文件系统相关函数的执行情况。
通过设置跟踪器为 Function graph tracer,并将需要跟踪的文件读写函数(如vfs_read、vfs_write等)添加到set_graph_function文件中,然后启动跟踪。在服务器进行文件读写操作的过程中,Ftrace 会记录下这些函数的调用关系和执行时间。从跟踪结果中,我们可能会发现vfs_read函数在调用ext4_readpage函数时花费了大量时间,进一步分析发现是因为文件系统的块分配策略不合理,导致频繁的磁盘 I/O 操作。基于这些发现,我们可以针对性地优化块分配算法,减少不必要的磁盘 I/O,从而显著提升文件系统的读写性能。
5.2故障排查
当系统出现响应延迟、进程卡顿等问题时,Ftrace 能够成为我们定位问题的关键工具。例如,在一个运行着多个服务的服务器上,用户反馈系统响应变得迟缓。此时,我们可以使用 Ftrace 的 Irqsoff Tracer 来跟踪中断被禁止的情况。因为长时间禁止中断可能会导致系统无法及时响应外部事件,从而出现延迟现象。
启用 Irqsoff Tracer 后,Ftrace 会记录下所有禁止中断的函数以及中断被禁止的时长。通过分析这些记录,我们可能会发现某个设备驱动程序中的中断处理函数存在问题,它在处理中断时长时间占用 CPU 资源,导致其他中断无法及时得到处理,进而影响了系统的整体响应速度。找到问题后,我们可以对该驱动程序进行优化,例如调整中断处理逻辑,将一些耗时操作放到线程中执行,以减少对中断的影响,从而解决系统响应延迟的问题。
5.3内核开发与调试
在开发新的内核模块时,开发者需要确保模块中的函数调用正确无误。例如,开发一个新的网络协议模块,使用 Ftrace 的 Function tracer,开发者可以清晰地看到该模块中各个函数的调用顺序和参数传递情况。如果发现某个函数没有按照预期被调用,或者参数传递出现错误,就可以及时调整代码,确保函数调用的正确性。
Ftrace 还可以用于跟踪系统调用,帮助开发者了解应用程序与内核之间的交互过程。当应用程序调用系统调用时,Ftrace 可以记录下系统调用的入口函数、参数以及返回值等信息。在调试一个新的文件操作函数时,通过跟踪系统调用,开发者可以发现函数在处理文件权限验证时出现错误,导致文件操作失败,进而对权限验证逻辑进行修正。
在调试内核模块时,Ftrace 同样发挥着重要作用。当内核模块出现异常时,Ftrace 记录的函数调用栈信息可以帮助开发者快速定位到问题所在。例如,一个内核模块在加载时崩溃,通过查看 Ftrace 的跟踪记录,开发者可以找到导致崩溃的函数以及该函数的调用路径,从而深入分析问题的原因,进行针对性的调试和修复。
六、Ftrace 的使用方法与技巧
6.1环境配置
在使用 Ftrace 之前,首先需要确保内核启用了相关的配置选项。这一步至关重要,因为只有正确配置内核,Ftrace 才能发挥其强大的功能。在编译内核时,可以通过make menuconfig命令进入内核配置界面。在该界面中,找到 “Kernel hacking” 选项,进入后再找到 “Tracers” 选项 。
在这里,需要确保 “Tracing support” 以及其他与 Ftrace 相关的选项(如 “Kernel Function Tracer”“Kernel Function Graph Tracer” 等)被勾选。这些选项分别对应着 Ftrace 的不同功能,勾选后才能启用相应的跟踪功能。
除了内核配置,还需要挂载debugfs文件系统。debugfs是一种特殊的文件系统,Ftrace 通过它向用户空间提供访问接口。挂载debugfs文件系统的方法有两种。一种是将其添加到/etc/fstab文件中,实现自动挂载。具体操作是在/etc/fstab文件中添加一行 “debugfs /sys/kernel/debug debugfs defaults 0 0”,这样在系统启动时,debugfs文件系统就会自动挂载到/sys/kernel/debug目录下。
另一种方法是手动挂载,使用命令 “mount -t debugfs none /sys/kernel/debug” ,该命令会将debugfs文件系统临时挂载到/sys/kernel/debug目录,这种方式适用于临时使用 Ftrace 进行调试的场景。
6.2常用命令与参数
在/sys/kernel/debug/tracing目录下,有许多用于控制和使用 Ftrace 的文件,这些文件对应着各种常用命令和参数。
echo 1 > tracing_on用于启用追踪,当需要开始记录内核函数调用和系统事件时,执行这个命令,Ftrace 就会开始工作,将跟踪信息写入 Ring buffer 中;而echo 0 > tracing_on则用于停止追踪,当不需要继续跟踪时,执行该命令可以停止 Ftrace 的记录操作,避免不必要的性能开销和数据占用。
echo function > current_tracer用于设置当前使用的追踪器为 Function tracer,通过修改current_tracer文件的内容,可以切换不同的追踪器,以满足不同的跟踪需求。例如,若要使用 Function graph tracer,就可以执行echo function_graph > current_tracer 。
echo vfs_read > set_ftrace_filter用于设置过滤条件,只跟踪特定的函数。在这个例子中,只有vfs_read函数的调用信息会被记录,其他函数的信息将被忽略。这在需要专注分析某个特定函数的行为时非常有用,可以减少大量无关信息的干扰,使分析更加高效和准确。
6.3使用技巧与注意事项
在使用 Ftrace 时,合理设置过滤条件可以大大提高分析效率。除了可以通过set_ftrace_filter指定要跟踪的函数外,还可以使用正则表达式来匹配多个函数。echo *lock* > set_ftrace_filter表示跟踪所有包含 “lock” 字样的函数,这样可以一次性跟踪多个相关函数,方便对特定功能模块的分析。
控制追踪范围也是一个重要技巧。可以通过set_ftrace_pid文件指定要跟踪的进程 ID,从而只跟踪特定进程的函数调用。echo 1234 > set_ftrace_pid表示只跟踪进程 ID 为 1234 的进程,这样可以避免其他进程的干扰,更精准地分析目标进程的行为。
处理大量追踪数据时,需要注意数据的存储和分析。由于 Ftrace 生成的跟踪数据可能会占用大量磁盘空间,因此可以定期清理trace文件,或者将数据导出到其他存储设备进行长期保存。在分析数据时,可以结合其他工具,如trace-cmd或bpftrace ,这些工具能够对 Ftrace 生成的数据进行更深入的分析和可视化处理,帮助用户更直观地理解系统行为和性能瓶颈。
同时,还需注意 Ftrace 对系统性能的影响。由于 Ftrace 会在内核中插入额外的代码来实现跟踪功能,因此在开启 Ftrace 时,可能会对系统性能产生一定的影响,特别是在跟踪大量函数时。所以,在生产环境中使用 Ftrace 时,应谨慎开启,并尽量缩短跟踪时间,以减少对系统正常运行的影响。
七、实战案列:隐藏的电灯开关
7.1 iosnoop
首先,Gregg 使用 iosnoop 工具进行检查,iosnoop 用来跟踪 I/O 的详细信息,当然也包括 latency,结果如下:
复制
# ./iosnoop -ts
STARTs ENDs COMM PID TYPE DEV BLOCK BYTES LATms
13370264.614265 13370264.614844 java 8248 R 202,32 1431244248 45056 0.58
13370264.614269 13370264.614852 java 8248 R 202,32 1431244336 45056 0.58
13370264.614271 13370264.614857 java 8248 R 202,32 1431244424 45056 0.59
13370264.614273 13370264.614868 java 8248 R 202,32 1431244512 45056 0.59
[...]
# ./iosnoop -Qts
STARTs ENDs COMM PID TYPE DEV BLOCK BYTES LATms
13370410.927331 13370410.931182 java 8248 R 202,32 1596381840 45056 3.85
13370410.927332 13370410.931200 java 8248 R 202,32 1596381928 45056 3.87
13370410.927332 13370410.931215 java 8248 R 202,32 1596382016 45056 3.88
13370410.927332 13370410.931226 java 8248 R 202,32 1596382104 45056 3.89
[...]1.2.3.4.5.6.7.8.9.10.11.12.13.14.
上面看不出来啥,一个繁忙的 I/O,势必会带来高的 latency。我们来说说 iosnoop 是如何做的。
iosnoop 主要是处理的 block 相关的 event,主要是:
block:block_rq_issue - I/O 发起的时候的事件block:block_rq_complete - I/O 完成事件block:block_rq_insert - I/O 加入队列的时间
复制
如果使用了 -Q 参数,我们对于 I/O 开始事件就用 block:block_rq_insert,否则就用的 block:block_rq_issue 。下面是我用 FIO 测试 trace 的输出:
fio-30749 [036] 5651360.257707: block_rq_issue: 8,0 WS 4096 () 1367650688 + 8 [fio]
<idle>-0 [036] 5651360.257768: block_rq_complete: 8,0 WS () 1367650688 + 8 [0]1.2.3.4.
我们根据1367650688 + 8能找到对应的 I/O block sector,然后根据 issue 和 complete 的时间就能知道 latency 了。
7.2 t点
为了更好的定位 I/O 问题,Gregg 使用 tpoint 来追踪 block_rq_insert,如下:
复制
# ./tpoint -H block:block_rq_insert
Tracing block:block_rq_insert. Ctrl-C to end.
# tracer: nop
#
# TASK-PID CPU# TIMESTAMP FUNCTION
# | | | | |
java-16035 [000] 13371565.253582: block_rq_insert: 202,16 WS 0 () 550505336 + 88 [java]
java-16035 [000] 13371565.253582: block_rq_insert: 202,16 WS 0 () 550505424 + 56 [java]
java-8248 [007] 13371565.278372: block_rq_insert: 202,32 R 0 () 660621368 + 88 [java]
java-8248 [007] 13371565.278373: block_rq_insert: 202,32 R 0 () 660621456 + 88 [java]
java-8248 [007] 13371565.278374: block_rq_insert: 202,32 R 0 () 660621544 + 24 [java]
java-8249 [007] 13371565.311507: block_rq_insert: 202,32 R 0 () 660666416 + 88 [java]
[...]1.2.3.4.5.6.7.8.9.10.11.12.13.
然后也跟踪了实际的堆栈:
复制
# ./tpoint -s block:block_rq_insert rwbs ~ "*R*" | head -1000
Tracing block:block_rq_insert. Ctrl-C to end.
java-8248 [005] 13370789.973826: block_rq_insert: 202,16 R 0 () 1431480000 + 8 [java]
java-8248 [005] 13370789.973831: <stack trace>
=> blk_flush_plug_list
=> blk_queue_bio
=> generic_make_request.part.50
=> generic_make_request
=> submit_bio
=> do_mpage_readpage
=> mpage_readpages
=> xfs_vm_readpages
=> read_pages
=> __do_page_cache_readahead
=> ra_submit
=> do_sync_mmap_readahead.isra.24
=> filemap_fault
=> __do_fault
=> handle_pte_fault
=> handle_mm_fault
=> do_page_fault
=> page_fault
java-8248 [005] 13370789.973831: block_rq_insert: 202,16 R 0 () 1431480024 + 32 [java]
java-8248 [005] 13370789.973836: <stack trace>
=> blk_flush_plug_list
=> blk_queue_bio
=> generic_make_request.part.50
[...]1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.
tpoint 的实现比较简单,譬如上面的 block:block_rq_insert,它直接会找events/block/block_rq_insert 是否存在,如果存在,就是找到了对应的 event。然后给这个 event 的 enable 文件写入 1,如果我们要开启堆栈,就往 options/stacktrace 里面也写入 1。
从上面的堆栈可以看到,有 readahead 以及 page fault 了。在 Netflix 新升级的 Ubuntu 系统里面,默认的 direct map page size 是 2 MB,而之前的 系统是 4 KB,另外就是默认的 readahead 是 2048 KB,老的系统是 128 KB。看起来慢慢找到问题了。
7.3函数计数
为了更好的看函数调用的次数,Gregg 使用了 funccount 函数,譬如检查 submit_bio :
复制
# ./funccount -i 1 submit_bio
Tracing "submit_bio"... Ctrl-C to end.
FUNC COUNT
submit_bio 27881
FUNC COUNT
submit_bio 28478
# ./funccount -i 1 filemap_fault
Tracing "filemap_fault"... Ctrl-C to end.
FUNC COUNT
filemap_fault 2203
FUNC COUNT
filemap_fault 3227
[...]1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.
上面可以看到,有 10 倍的膨胀。对于 funccount 脚本,主要是需要开启 function profile 功能,也就是给 function_profile_enabled 文件写入 1,当打开之后,就会在 trace_stat 目录下面对相关的函数进行统计,可以看到 function0,function1 这样的文件,0 和 1 就是对应的 CPU。cat 一个文件:
复制
cat function0
Function Hit Time Avg s^2
-------- --- ---- --- ---
schedule 56 12603274 us 225058.4 us 4156108562 us
do_idle 51 4750521 us 93147.47 us 5947176878 us
call_cpuidle 51 4748981 us 93117.27 us 5566277250 us1.2.3.4.5.6.
就能知道各个函数的 count 了。
7.4功能变慢
为了更加确定系统的延迟是先前堆栈上面看到的函数引起的,Gregg 使用了 funcslower 来看执行慢的函数:
复制
# ./funcslower -P filemap_fault 1000
Tracing "filemap_fault" slower than 1000 us... Ctrl-C to end.
0) java-8210 | ! 5133.499 us | } /* filemap_fault */
0) java-8258 | ! 1120.600 us | } /* filemap_fault */
0) java-8235 | ! 6526.470 us | } /* filemap_fault */
2) java-8245 | ! 1458.30 us | } /* filemap_fault */
[...]1.2.3.4.5.6.7.
可以看到,filemap_fault 这个函数很慢。对于 funcslower,我们主要是用 tracing_thresh 来进行控制,给这个文件写入 threshold,如果函数的执行时间超过了 threshold,就会记录。
7.5funccount(再次)
Gregg 根据堆栈的情况,再次对 readpage 和 readpages 进行统计:
复制
# ./funccount -i 1 *mpage_readpage*
Tracing "*mpage_readpage*"... Ctrl-C to end.
FUNC COUNT
mpage_readpages 364
do_mpage_readpage 122930
FUNC COUNT
mpage_readpages 318
do_mpage_readpage 110344
[...]1.2.3.4.5.6.7.8.9.10.11.
仍然定位到是 readahead 的写放大引起,但他们已经调整了 readahead 的值,但并没有起到作用。
7.6k探头
因为 readahead 并没有起到作用,所以 Gregg 准备更进一步,使用 dynamic tracing。他注意到上面堆栈的函数 __do_page_cache_readahead() 有一个 nr_to_read 的参数,这个参数表明的是每次 read 需要读取的 pages 的个数,使用 kprobe:
复制
# ./kprobe -H p:do __do_page_cache_readahead nr_to_read=%cx
Tracing kprobe m. Ctrl-C to end.
# tracer: nop
#
# TASK-PID CPU# TIMESTAMP FUNCTION
# | | | | |
java-8714 [000] 13445354.703793: do: (__do_page_cache_readahead+0x0/0x180) nr_to_read=200
java-8716 [002] 13445354.819645: do: (__do_page_cache_readahead+0x0/0x180) nr_to_read=200
java-8734 [001] 13445354.820965: do: (__do_page_cache_readahead+0x0/0x180) nr_to_read=200
java-8709 [000] 13445354.825280: do: (__do_page_cache_readahead+0x0/0x180) nr_to_read=200
[...]1.2.3.4.5.6.7.8.9.10.11.
可以看到,每次 nr_to_read 读取了 512 (200 的 16 进制)个 pages。在上面的例子,他并不知道 nr_to_read 实际的符号是多少,于是用 %cx 来猜测的,也真能蒙对,太猛了。
关于 kprobe 的使用,具体可以参考 kprobetrace 文档,kprobe 解析需要 trace 的 event 之后,会将其写入到 kprobe_events 里面,然后在 events/kprobes/<EVENT>/ 进行对应的 enable 和 filter 操作。
7.7函数图
为了更加确认,Gregg 使用 funcgraph 来看 filemap_fault 的实际堆栈,来看 nr_to_read 到底是从哪里传进来的。
复制
# ./funcgraph -P filemap_fault | head -1000
2) java-8248 | | filemap_fault() {
2) java-8248 | 0.568 us | find_get_page();
2) java-8248 | | do_sync_mmap_readahead.isra.24() {
2) java-8248 | 0.160 us | max_sane_readahead();
2) java-8248 | | ra_submit() {
2) java-8248 | | __do_page_cache_readahead() {
2) java-8248 | | __page_cache_alloc() {
2) java-8248 | | alloc_pages_current() {
2) java-8248 | 0.228 us | interleave_nodes();
2) java-8248 | | alloc_page_interleave() {
2) java-8248 | | __alloc_pages_nodemask() {
2) java-8248 | 0.105 us | next_zones_zonelist();
2) java-8248 | | get_page_from_freelist() {
2) java-8248 | 0.093 us | next_zones_zonelist();
2) java-8248 | 0.101 us | zone_watermark_ok();
2) java-8248 | | zone_statistics() {
2) java-8248 | 0.073 us | __inc_zone_state();
2) java-8248 | 0.074 us | __inc_zone_state();
2) java-8248 | 1.209 us | }
2) java-8248 | 0.142 us | prep_new_page();
2) java-8248 | 3.582 us | }
2) java-8248 | 4.810 us | }
2) java-8248 | 0.094 us | inc_zone_page_state();1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.
找到了一个比较明显的函数 max_sane_readahead。对于 funcgraph,主要就是将需要关注的函数放到 set_graph_function 里面,然后在 current_tracer 里面开启 function_graph。
7.8 k探针(再次)
然后,Gregg 继续使用 kprobe 来 trace max_sane_readahead 函数,这次不用猜测寄存器了,直接用 $retval 来看返回值:
复制
# ./kprobe r:m max_sane_readahead $retval
Tracing kprobe m. Ctrl-C to end.
java-8700 [000] 13445377.393895: m: (do_sync_mmap_readahead.isra.24+0x62/0x9c <- \
max_sane_readahead) arg1=200
java-8723 [003] 13445377.396362: m: (do_sync_mmap_readahead.isra.24+0x62/0x9c <- \
max_sane_readahead) arg1=200
java-8701 [001] 13445377.398216: m: (do_sync_mmap_readahead.isra.24+0x62/0x9c <- \
max_sane_readahead) arg1=200
java-8738 [000] 13445377.399793: m: (do_sync_mmap_readahead.isra.24+0x62/0x9c <- \
max_sane_readahead) arg1=200
java-8728 [000] 13445377.408529: m: (do_sync_mmap_readahead.isra.24+0x62/0x9c <- \
max_sane_readahead) arg1=200
[...]1.2.3.4.5.6.7.8.9.10.11.12.13.
发现仍然是 0x200 个 pages,然后他在发现,readahead 的属性其实是在 file_ra_state_init 这个函数就设置好了,然后这个函数是在文件打开的时候调用的。但他在进行 readahead tune 的时候,一直是让 Cassandra 运行着,也就是无论怎么改 readahead,都不会起到作用,于是他把 Cassandra 重启,问题解决了。
复制
# ./kprobe r:m max_sane_readahead $retval
Tracing kprobe m. Ctrl-C to end.
java-11918 [007] 13445663.126999: m: (ondemand_readahead+0x3b/0x230 <- \
max_sane_readahead) arg1=80
java-11918 [007] 13445663.128329: m: (ondemand_readahead+0x3b/0x230 <- \
max_sane_readahead) arg1=80
java-11918 [007] 13445663.129795: m: (ondemand_readahead+0x3b/0x230 <- \
max_sane_readahead) arg1=80
java-11918 [007] 13445663.131164: m: (ondemand_readahead+0x3b/0x230 <- \
max_sane_readahead) arg1=80
[...]1.2.3.4.5.6.7.8.9.10.11.
这次只会读取 0x80 个 pages 了。
上面就是一个完完整整使用 ftrace 来定位问题的例子,可以看到,虽然 Linux 系统在很多时候对我们是一个黑盒,但是有了 ftrace,如果在黑暗中开启了一盏灯,能让我们朝着光亮前行。我们内部也在基于 ftrace 做很多有意思的事情。
八、Ftrace 与其他追踪工具的比较
在 Linux 性能分析与调试领域,除了 Ftrace,还有 SystemTap、LTTng 等知名的追踪工具,它们各自有着独特的特点,适用于不同的场景。
8.1功能对比
Ftrace 作为 Linux 内核自带的跟踪工具,主要聚焦于内核函数的调用、系统事件以及内核行为的跟踪。它提供了丰富的追踪器,如 Function Tracer 用于记录内核函数调用情况,Function Graph Tracer 以图形化展示函数调用关系 ,这些功能使得开发者能够深入了解内核的运行机制,对于内核开发和性能优化非常有帮助。
SystemTap 则功能更为强大和灵活,它允许开发者使用脚本语言编写复杂的跟踪脚本。通过这些脚本,SystemTap 可以对内核行为进行深度分析,不仅能跟踪内核函数,还能对系统调用、用户空间程序与内核的交互等进行全面的跟踪和分析。在分析复杂的系统性能问题时,SystemTap 可以通过编写脚本来统计特定系统调用的执行次数、执行时间等,从而找出性能瓶颈所在。
LTTng 的功能侧重于提供详细的事件跟踪,包括 CPU 调度、中断处理、系统调用、信号传递等众多方面。它支持同时跟踪内核空间和用户空间的活动,并且提供了高效的二进制接口和独立的缓冲设计,适合进行深入的性能分析和故障诊断。在分析多线程应用程序的性能问题时,LTTng 可以精确地记录每个线程的调度时间、执行时间以及线程之间的同步操作,帮助开发者找出线程相关的性能瓶颈。
8.2使用难度对比
Ftrace 的使用相对较为简单。用户主要通过debugfs文件系统与 Ftrace 进行交互,通过对/sys/kernel/debug/tracing目录下的文件进行简单的读写操作,就能实现跟踪器的设置、跟踪的启动与停止以及跟踪数据的查看等功能 。对于熟悉 Linux 文件操作的开发者来说,很容易上手。
SystemTap 的使用难度则较高。由于它需要开发者编写脚本,而这些脚本涉及到特定的语法和函数调用,学习成本相对较大。编写一个能够准确获取所需信息的 SystemTap 脚本,需要开发者对系统的运行机制有深入的了解,并且熟练掌握 SystemTap 的脚本语言。对于初学者来说,可能需要花费一定的时间和精力来学习和掌握。
LTTng 的使用难度介于 Ftrace 和 SystemTap 之间。它提供了一套命令行工具来控制跟踪会话,如启动 / 停止跟踪、配置跟踪点等。虽然命令行操作相对复杂一些,但相比于编写脚本,还是较为容易掌握的。不过,在进行复杂的跟踪配置和数据分析时,仍然需要开发者对 LTTng 的原理和使用方法有一定的了解。
8.3性能影响对比
Ftrace 采用静态代码插装技术,在不进行跟踪时,对系统性能的影响极小。因为在非跟踪状态下,它通过将跳转指令替换为nop指令,几乎不占用系统资源 。而在开启跟踪时,虽然会有一定的性能开销,但由于其设计的轻量级特性,这种影响在大多数情况下是可以接受的,特别是在只跟踪少量关键函数时,对系统性能的影响微乎其微。
SystemTap 在运行时,会将脚本语句翻译成 C 语句并编译成内核模块,这个过程会消耗一定的 CPU 资源。而且,由于其功能强大,可能会对系统性能产生较大的影响,特别是在编写的脚本较为复杂或者跟踪的范围较广时。在生产环境中使用 SystemTap 时,需要谨慎评估其对系统性能的影响,避免因性能问题导致系统不稳定。
LTTng 在设计时就考虑到了对系统性能的最小影响,采用了锁定最小化、CPU 本地缓存和批量处理等技术,确保在高负载下也能保持较低的开销。它能够在不显著影响系统性能的前提下,收集大量的跟踪数据,这使得它在生产环境中的应用较为广泛。不过,在极端情况下,如跟踪大量事件且系统资源紧张时,LTTng 仍可能对系统性能产生一定的影响。