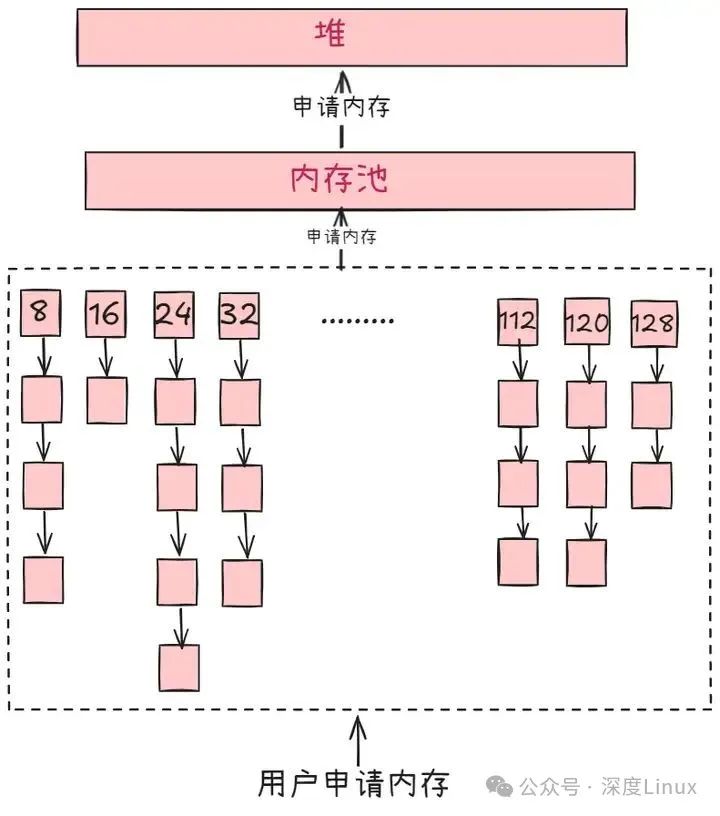
在深入探讨内存碎片之前,让我们先从一个日常生活场景入手。想象你有一个宽敞的房间,最初房间是空的,你可以自由地放置各种家具,让它们整齐排列,充分利用空间。这就好比计算机系统刚启动时,内存是一片连续的空闲空间,程序可以随意申请和使用内存。
随着时间的推移,你开始不断地购买新家具,又时不时地丢弃一些旧家具。有时候,新买的家具尺寸不规则,放置后会在周围留下一些小空间;而丢弃旧家具后,留下的空位又可能因为太小,无法放下新的大型家具。这些零散的、无法被有效利用的小空间,就类似于计算机内存中的碎片。
在计算机世界里,内存就像是这个房间,程序运行时需要向操作系统申请内存空间来存储数据和执行代码 。当程序申请内存时,操作系统会根据程序的需求分配一块内存区域。如果程序频繁地申请和释放内存,就像在房间里频繁地放置和移除家具一样,内存空间会逐渐变得零散,产生内存碎片。
一、内存碎片简介
1.1内存碎片是什么
内存碎片,简单来说,就是内存中由于各种原因产生的不连续的空闲空间 ,这些空间是一部分无法被有效利用、被浪费的内存资源。当程序向操作系统申请内存时,操作系统会根据一定的算法在内存中寻找合适的空闲区域进行分配。如果内存中存在大量的小空闲块,且这些小空闲块无法合并成足够大的连续空间来满足程序的申请需求,这些小空闲块就形成了内存碎片。
1.2内存碎片的类型剖析
内存碎片主要分为外部碎片和内部碎片两种类型,它们各自有着不同的形成机制和特点。
(1)外部碎片
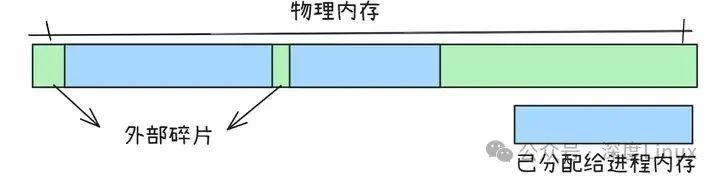 图片
图片
外部碎片是指那些还没有被分配给任何进程的内存空闲区域,但由于这些区域的空间太小,无法分配给申请内存空间的新进程。就好比你有一堆小塑料袋,每个塑料袋都装不满一件大商品,但这些塑料袋的总容量加起来其实是够装下这件大商品的,然而由于它们是分散的小袋子,没办法用来装这件大商品,这些小塑料袋的空余空间就类似于外部碎片。
在内存管理中,当进程频繁地申请和释放不同大小的内存块时,就容易产生外部碎片。例如,系统一开始有一块连续的大内存空间,进程 A 申请了一块较小的内存,之后进程 B 又申请了一块内存,接着进程 A 释放了内存。此时,虽然释放出来的内存和剩余的空闲内存总量可能足够满足一个新进程的需求,但由于它们是不连续的小块,新进程就无法使用这些空闲内存,从而形成了外部碎片 。
(2)内部碎片
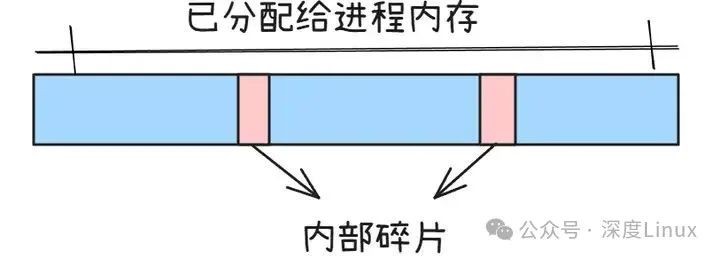 图片
图片
内部碎片是指已经被分配给某个进程,但该进程实际使用的内存小于分配给它的内存空间,这部分多余的、未被利用的内存就是内部碎片。以文字编辑器为例,假设我们开发一个文字编辑器,设定其字数上限为 3000 字,为了保证程序能正常运行,前端和后台数据库用来存储这些内容的空间都设置为 3000 字的容量。
但在实际使用中,用户可能只写了 1000 字,那么剩余的 2000 字的存储空间就被闲置了,这部分闲置的空间就是内部碎片。又比如内存分配单位是固定大小的,当程序申请的内存大小不是分配单位的整数倍时,就会产生内部碎片。假设内存分配单位是 8KB,而程序只需要 6KB 内存,那么分配的 8KB 中有 2KB 是浪费的,这 2KB 就是内部碎片。
1.3反碎片技术
2.6.23 引入成块回收,3.5版本后废除,被碎片整理程序取而代之2.6.33 引入虚拟可移动区域
其中,不管是成块回收还是碎片整理,它们都是在碎片之后进行处理,而这往往对系统性能是有损耗的,尤其是回收热页的时候。而虚拟可移动区域不同,这是一种预防碎片产生的技术。
(1)反碎片的工作原理
内核从2.6.24开始引入反碎片技术,试图从最开始就尽可能的防止碎片的产生。它根据页的可移动性将可分配页分为以下三种不同的类型
不可移动页,比如核心内核分配的大多内存可回收页,不能移动,但可以删除。可移动页,可以随意移动,如用户空间的页。移动之后,需要更新页表项。
导致碎片的原因就是不可移动的页插在很多连续页组之后,导致其他空闲页不能用。而页加入可移动性之后,就可解决这个问题。
(2)虚拟可移动区域
可移动区域(ZONE_MOVABLE)是一个抽象的内存区域,它将物理内存分为两个区域。一个区域用于放置不可移动的页,另一个区域用于放置可移动的页。这样不可移动的页就不能插在移动区域造成碎片了。
那么如何确定两个区域的大小呢?
kernelcore参数用于指定不可移动分配的内存数量,指定值保存在required_kernelcore中。movablecore参数用于指定可移动分配的内存数量,计算值存在required_kernelcore中。如果两个参数都设定,那么required_kernelcore = max(指定值,计算值)。
源码如下:
复制
// mm\page_alloc.c
...
static unsigned long __meminitdata arch_zone_lowest_possible_pfn[MAX_NR_ZONES];
static unsigned long __meminitdata arch_zone_highest_possible_pfn[MAX_NR_ZONES];
static unsigned long __initdata required_kernelcore;
static unsigned long __initdata required_movablecore;
static unsigned long __meminitdata zone_movable_pfn[MAX_NUMNODES];
...
/*
* kernelcore=size sets the amount of memory for use for allocations that
* cannot be reclaimed or migrated.
*/
static int __init cmdline_parse_kernelcore(char *p)
{
return cmdline_parse_core(p, &required_kernelcore);
}
/*
* movablecore=size sets the amount of memory for use for allocations that
* can be reclaimed or migrated.
*/
static int __init cmdline_parse_movablecore(char *p)
{
return cmdline_parse_core(p, &required_movablecore);
}
early_param("kernelcore", cmdline_parse_kernelcore);
early_param("movablecore", cmdline_parse_movablecore);1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.
另外函数find_zone_movable_pfns_for_nodes 用于计算进入可移动区域的内存数量,对一个每个结点来说,zone_movable_pfn[node_id] 表示movable_zone内存域的起始地址,同required_kernelcore一样, 这也是一个关键的变量。
二、内存碎片是如何产生的
2.1频繁的内存分配与释放
内存分配和释放操作就像在图书馆书架上不断地放置和拿走书籍。如果我们频繁地进行这样的操作,书架上的书籍摆放就会变得杂乱无章,出现一些零散的空位,这些空位就类似于内存碎片。
以制作下雪场景程序为例,我们需要不断地创建和删除代表雪花的对象 。每创建一个雪花对象,程序就会向操作系统申请一块内存来存储该对象的相关信息,如位置、大小、颜色等;当雪花对象不再需要时(比如雪花超出了屏幕范围),程序会释放这块内存。如果这个过程非常频繁,比如在一个密集的下雪场景中,每秒可能要创建和销毁成百上千个雪花对象,就会导致内存频繁地分配和释放。随着时间的推移,内存中就会出现许多零散的空闲小块,这些小块由于太小或者不连续,无法被后续的内存分配请求所利用,从而形成了外部碎片 。
2.2内存对齐的要求
内存对齐是指系统和硬件对内存地址的一种要求,为了提升内存访问的效率和性能,数据在内存中的起始地址需要按照一定的边界(如 2、4、8、16 等字节的整数倍)进行对齐 。不同的硬件架构对内存对齐的要求有所不同,例如 x86 和 x64 架构在内存对齐要求方面相对宽松,而 ARM、RISC-V 等架构则较为严格。某些特定的硬件平台(如 MIPS、PowerPC 以及某些 DSP)甚至不支持非对齐的内存访问,如果发生非对齐的内存访问,可能会导致性能下降、硬件异常甚至程序崩溃。
假设我们有一个结构体,其中包含一个 char 类型的变量(占 1 字节)和一个 int 类型的变量(占 4 字节)。按照内存对齐规则,为了保证 int 类型变量从 4 字节的整数倍地址开始存储,在 char 类型变量后面会填充 3 个字节的空闲空间。这样,当我们为这个结构体分配内存时,实际分配的内存大小就会大于结构体中所有变量实际占用的内存大小,多出来的这部分空闲空间就是内部碎片 。
三、内存碎片整理
从内存区域的底部扫描已分配的可移动页,从内存区域的顶部扫描空闲页,把底部的可移动页移动到顶部空闲页,在底部形成连续的空闲页。
整理算法:首先从内存区域底部向顶部以页块为扫描单位,在页块内部起始页向结束页扫描,把这个页块里面的可移动页组成一条链表,然后从内存区域顶部向底部以页块为单位扫描,在页块内部从起始页向结束页扫描,把空闲页组成一条链表,最后把底部的可移动页的数据复制到顶部的空闲页,修改进程的页表,把虚拟页映射到新物理页。
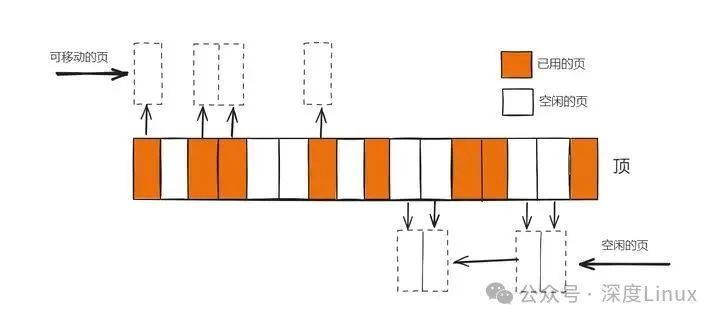 图片
图片
假如有16个页,白色表示空闲页。这个内存区域已经碎片化,最大的连续页是两页。从这个区域内存分配3页就会失败,甚至分配两页也会失败,因为连续的空闲页的起始地址没有对齐到两页的整数倍。
3.1内存碎片整理优先级
完全同步模式(COMPACT_PRIO_SYNC_FULL):允许阻塞,允许把脏的文件页回写到存储设备上,并且等回写完成轻量级同步模式(COMPACT_PRIO_SYNC_LIGHT):允许大多数操作阻塞,但是不允许把脏数据回写到存储设备上;异步模式(COMPACT_PRIO_ASYNC):不允许阻塞。成本:完全同步模式>轻量级同步>异步模式
3.2碎片整理的开始时机
页分配器使用最低水线分屏页失败以后,如果调用者允许直接回收页和写存储设备,并且是最昂贵的分配或者申请不可移动类型的连续页,那么在尝试直接回收页之前,先尝试执行异步模式的内存碎片整理。页分配器直接回收以后连续分配页仍然失败,如果调用者允许写存储设备,尝试执行轻量级同步模式的内存碎片整理。每个内存节点有一个页回收线程和一个内存碎片整理线程,页回收线程准备睡眠小段时间的时候,唤醒内存碎片整理线程,内存碎片整理线程执行轻量级同步模式的内存碎片整理。系统管理员向文件/proc/sys/vm/compact_memory写入任何整数值的时候,在所有内存节点的所有区域上执行完全同步的内存碎片整理。内存碎片整理线程名“kcompactd<node_id>”,内存节点的pglist_data的实例成员"kcompactd"指向内存碎片整理线程的进程描述符。
3.3碎片整理结束条件
如果迁移扫描器和空闲扫描器相遇,那么内存碎片整理结束。
如果迁移扫描器和空闲扫描器没有相遇,但是申请或备用的迁移类型至少有一个足够大的空闲页块,那么内存碎片整理结束。
判断一个内存区域是否适合执行内存碎片整理的标准:
①如果管理员通过写文件/proc/sys/vm/compact_memory触发内存碎片整理,那么这个内存区域强制执行内存碎片;
②如果内存区域同时满足以下三个条件,适合执行内存碎片整理
如果(空闲页数-申请页数)低于水线,或者虽然大于或等于水线,但是没有一个足够大的空闲页块如果(空闲页数-2倍申请页数)大于或等于水线,说明有足够的空闲页作为迁移目的地,那么这个内存区域适合执行内存碎片整理;对于昂贵的分配(阶数大于3)计算碎片指数,如果碎片指数范围[0,外部碎片的阈值]以内,说明内存分配失败是内存不足导致的,不是外部碎片导致的,那么这个内存区域不适合执行内存碎片整理;
③碎片计算
如果不存在空闲页块,那么碎片指数=0;如果至少存在一个足够大的空闲页块,那么碎片指数=-1000其他情况:碎片指数=1000-(1000+1000*空闲页数/申请页数)/空闲页块总数;
碎片阈值是内存不足和外部碎片的分界线:如果碎片指数小于或等于阈值,分配失败的内存不足,应该直接回收页;如果碎片指数大于阈值,分配失败原因是外部碎片,应该执行碎片整理。
3.4具体使用方式
①编译内核时:如果需要内存碎片整理功能,需要配置CONFIG_COMPACTION
②命令行下
复制
//设置外部碎片的阈值
root@ubuntu:/home/wy/misc/net# cat /proc/sys/vm/extfrag_threshold
500
//是否允许内部碎片整理移动不可回收的页,1 允许
root@ubuntu:/home/wy/misc/net# cat /proc/sys/vm/compact_unevictable_allowed
1
//写入任何值触发内存碎片整理
root@ubuntu:/home/wy/misc/net# cat /proc/sys/vm/compact_memory
cat: /proc/sys/vm/compact_memory: Permission denied1.2.3.4.5.6.7.8.9.
内存碎片整理成功标准(空闲页数-申请页数)大于或等于水线,并且申请或备用的迁移类型至少有一个足够大的空闲页块。如果迁移扫描器和空闲扫描器相遇,没有达到成功标准;则延迟整理。
四、内存碎片带来的影响
4.1内存利用率降低
内存碎片的存在使得可用内存空间变得不连续,导致实际可用于分配的内存总量减少 。即使系统显示还有足够的内存,但由于碎片的存在,程序可能无法分配到足够大的连续内存块,从而影响程序的正常运行。在一个需要大量连续内存的图形处理程序中,假设程序要处理一张高分辨率的图像,图像数据量非常大,需要申请一块连续的大内存来存储图像的像素信息。
然而,由于内存中存在大量的碎片,尽管系统的总空闲内存量可能足够,但这些空闲内存以零散的小块形式分布,无法合并成满足图像数据存储需求的连续大内存块。这就导致图形处理程序无法正常分配到足够的内存,无法加载和处理图像,进而影响程序的性能,甚至导致程序崩溃 。
4.2程序运行速度减慢
内存碎片会导致内存分配和释放操作变得更加复杂和耗时。当程序需要分配内存时,系统需要花费更多的时间来查找合适的内存块。因为内存碎片使得内存空间变得零散,系统不能像内存连续时那样快速找到满足需求的内存区域,而是需要在众多零散的空闲块中进行搜索和匹配 。在释放内存时,也需要进行一些额外的操作来合并相邻的空闲块,以减少碎片。
这些额外的操作会增加程序的运行时间,降低程序的执行效率。例如,在一个频繁进行内存分配和释放的数据库管理系统中,由于内存碎片的存在,每次内存分配操作都需要更长的时间来定位合适的内存块,释放内存时也需要花费更多时间进行合并操作。这使得数据库的读写操作速度变慢,用户查询数据的响应时间变长,严重影响了数据库系统的性能和用户体验 。
4.3增加内存泄漏风险
内存碎片可能会掩盖内存泄漏问题。由于碎片的存在,即使程序中存在内存泄漏,系统可能仍然显示有足够的内存可用 。因为内存泄漏导致的内存占用增加可能被分散在各个碎片中,不容易被察觉。这使得内存泄漏问题更加难以被发现和解决,长期积累下来,可能会导致程序崩溃或性能严重下降。
比如,在一个长时间运行的服务器程序中,某个模块存在内存泄漏问题,但由于内存碎片的干扰,内存泄漏的迹象被隐藏起来。随着时间的推移,内存泄漏越来越严重,服务器的可用内存逐渐减少,最终可能导致服务器因内存不足而崩溃,影响整个服务的正常运行 。
五、内存分配算法优化
首次适应算法(First Fit):从空闲分区表的第一个表目起查找该表,把最先能够满足要求的空闲区分配给作业,这种方法的目的在于减少查找时间。为适应这种算法,空闲分区表(空闲区链)中的空闲分区要按地址由低到高进行排序。该算法优先使用低址部分空闲区,在低址空间造成许多小的空闲区,在高地址空间保留大的空闲区。
最佳适应算法(Best Fit):从全部空闲区中找出能满足作业要求的、且大小最小的空闲分区,这种方法能使碎片尽量小。为适应此算法,空闲分区表(空闲区链)中的空闲分区要按从小到大进行排序,自表头开始查找到第一个满足要求的自由分区分配。该算法保留大的空闲区,但造成许多小的空闲区。
最差适应算法(Worst Fit):从全部空闲区中找出能满足作业要求的、且大小最大的空闲分区,从而使链表中的结点大小趋于均匀,适用于请求分配的内存大小范围较窄的系统。为适应此算法,空闲分区表(空闲区链)中的空闲分区按大小从大到小进行排序,自表头开始查找到第一个满足要求的自由分区分配。该算法保留小的空闲区,尽量减少小的碎片产生。
伙伴算法(buddy):使用二进制优化的思想,将内存以2的幂为单位进行分配,合并时只能合并是伙伴的内存块,两个内存块是伙伴的三个条件是:
大小相等(很好判断)地址连续(也很好判断)两个内存块分裂自同一个父块(其实只要判断低地址的内存块首地址是否是与父块地址对齐,即合并后的首地址为父块大小的整数倍)使用lowbit等位运算可以o(1)判断。
伙伴算法在实现的时候可以使用数组+链表的形式(有点像邻接表那种),因为内存上限是固定的,比较容易确定。下列代码使用的是二维链表(写起来就没有数组加链表简洁)。在分配调整内存块时使用了递归,如果需要提高效率可以改为循环(递归更能体现出思想且代码简单,循环效率更高但是复杂一丢丢,自行选取)。
复制
#include<bits/stdc++.h>
using namespace std;
/*进程分配内存块链表的首指针*/
struct allocated_block *allocated_block_head = NULL;
#define PROCESS_NAME_LEN 32 /*进程名长度*/
#define MIN_SLICE 10 /*最小碎片的大小*/
#define DEFAULT_MEM_SIZE 1024 /*内存大小*/
#define DEFAULT_MEM_START 0 /*起始位置*/
/* 内存分配算法 */
#define MA_FF 1 //first fit
#define MA_BF 2
#define MA_WF 3
#define Buddy 4 //伙伴算法
/*描述每一个空闲块的数据结构*/
struct free_block_type{
int size;
int start_addr;
struct free_block_type *next;
};
typedef struct free_block_type FB;
/*指向内存中空闲块链表的首指针*/
struct free_block_type *free_block;//此处尽量按内存地址顺序排列 ,
/*每个进程分配到的内存块的描述*/
struct allocated_block{
int pid; int size;
int start_addr;
char process_name[PROCESS_NAME_LEN];
struct allocated_block *next;
};
typedef struct allocated_block allocated_block_type;
//buddy
typedef struct b_free_block_type
{
int size;
free_block_type *list;
b_free_block_type *next;
}b_free_block_type;
b_free_block_type *b_free_block=NULL;//空的时候要设置为NULL
//end of buddy
typedef struct allocated_block AB;
int mem_size=DEFAULT_MEM_SIZE; /*内存大小*/
int ma_algorithm = Buddy; /*当前分配算法*/ //------------------------>>>>>>>>>
static int pid = 0; /*初始pid*/
int flag = 0; /*设置内存大小标志*/
//init_free_block(int mem_size);
int display_mem_usage();
int b_creat_free_blocks(free_block_type *ab);
int rearrange_Buddy();
int rearrange(int algorithm);
int allocate_mem(struct allocated_block *ab);
int free_mem(struct allocated_block *ab);
int dispose(struct allocated_block *free_ab);
int disfree(FB *free_ab);
void free_f();
void free_b();
/*初始化空闲块,默认为一块,可以指定大小及起始地址*/
struct free_block_type* init_free_block(int mem_size)
{
free_f();
free_b();
struct free_block_type *fb;
fb=(struct free_block_type *)malloc(sizeof(struct free_block_type));
if(fb==NULL){
printf("Error.\n");
getchar();
return NULL;
}
fb->size = mem_size;
fb->start_addr = DEFAULT_MEM_START;
fb->next = NULL;
free_block=(struct free_block_type *)malloc(sizeof(struct free_block_type));
*free_block=*fb; //free_block供rearrange_Buddy使用,会被销毁
rearrange_Buddy();//初始化buddy算法
return fb; //会在main中重新赋值free_block
}
/*显示菜单*/
void display_menu(){
printf("\n");
printf("1 - Set memory size (default=%d)\n", DEFAULT_MEM_SIZE);
printf("2 - Select memory allocation algorithm\n");
printf("3 - New process \n");
printf("4 - Terminate a process \n");
printf("5 - Display memory usage \n");
printf("0 - Exit\n");
}
/*设置内存的大小*/
int set_mem_size(){ //只能设置一次, 清除现有所有链表,重新分配
int size;
if(flag!=0){ //防止重复设置
printf("Cannot set memory size again\n");
return 0;
}
printf("Total memory size =");
scanf("%d", &size);
if(size>0) {
mem_size = size;
// free_block->size = mem_size;
init_free_block(mem_size);
flag=1;
return 1;
}
cout<<"输入不合法"<<endl;
return 0;
}
/* 设置当前的分配算法 */
int set_algorithm(){
int algorithm;
printf("\t1 - First Fit\n");
printf("\t2 - Best Fit \n");
printf("\t3 - Worst Fit \n");
printf("\t4 - Buddy \n");
scanf("%d", &algorithm);
//按指定算法重新排列空闲区链表
if(algorithm==Buddy)
{
if(ma_algorithm!=Buddy)
rearrange(algorithm);
}
else
{
if(ma_algorithm==Buddy)
rearrange(algorithm);
}
if(algorithm>=1 && algorithm <=4)
{
ma_algorithm=algorithm;
pid=0;
}
else
cout<<"输入错误!!!"<<endl;
display_mem_usage();
}
/*按FF算法重新整理内存空闲块链表*/
int rearrange_FF(){
//请自行补充
//将buddy的二级制表示法展开,按地址排序
b_free_block_type *p=b_free_block;
free_block_type *work,*twork;
allocated_block_type *t=(allocated_block_type*)malloc(sizeof(allocated_block_type)); //最后要销毁此临时块
//不排除其他函数调用此函数来完成内存列表的切换,需要暂时改变算法,结束之前再进行还原。
int ma_algorithm_temp=ma_algorithm;//备份
ma_algorithm=MA_FF; //保证free_mem()的按照FF的方式工作
free_f();
for(p=b_free_block;p!=NULL;p=p->next)
{
for(work=p->list;work!=NULL;work=work->next)//在f系列列表里增加内存而不销毁b算法列表
{
t->size=work->size;
t->start_addr=work->start_addr;
free_mem(t); //不会删除work
}
}
//还原算法
ma_algorithm=ma_algorithm_temp;
//不销毁buddy.free内存列表
free(t);
}
/*按BF算法重新整理内存空闲块链表*/
int rearrange_BF(){
//请自行补充
/*
如果按地址排,则分配时复杂,free时方便
如果按内存大小排,则分配时方便,free复杂
综合考虑,按地址排序还可以重用代码,本程序选择按地址排序 ——wbt
*/
return rearrange_FF();
}
/*按WF算法重新整理内存空闲块链表*/
int rearrange_WF(){
//请自行补充
return rearrange_FF();
}
int rearrange_Buddy()
{
//尽量将ff,bf,wf的内存表示方式转换(不足2的幂的补足,若无法补足返回0表示无法切换)
//算了,太麻烦了还是按照只能开机设置设定吧。
int i;
free_b();
b_free_block_type *p,*tp;//工作指针
p=b_free_block;
while(p!=NULL) //释放掉之前的
{
tp=p->next;
free(p);
p=tp;
}
//将最大内存mem_size建立头链表
int size=1;
while(size<mem_size)
size<<=1;
b_free_block=NULL;//头插法,按从小到大排序
while(size)
{
p=(b_free_block_type*)malloc(sizeof(b_free_block_type));
p->next=b_free_block;
b_free_block=p;
p->size=size;
p->list=NULL;
size>>=1;
}
//将free_block链表变换成b_free_block链表
free_block_type *work,*twork;
while(free_block!=NULL) //边转换边删除
{
work=free_block;
free_block=free_block->next;
b_creat_free_blocks(work); //新建一个 并插入 销毁原来的free_block
}
return 1;
}
//将free_block_type ab展开成buddy形式 销毁原来的free_block 并进行合并检查和操作
int b_creat_free_blocks(free_block_type *ab) //wbt class 3 grade 2016
{
b_free_block_type *p=b_free_block;
free_block_type *work,*fwork,*twork;
int i=0;
while(p!=NULL && ab->size)
{
if(ab->size>>i&1)
{
if(p->list==NULL)//如果还没有节点,则添加一个新节点
{
work=p->list=(free_block_type*)malloc(sizeof(free_block_type));
work->size=p->size;
ab->size-=work->size;
work->start_addr=ab->start_addr;
ab->start_addr+=work->size;
work->next=NULL;
continue;
}
//从列表里选取合适的位置插入并上寻找伙伴合并(保证列表按地址排序)
//两个块由一个块分裂而来的伙伴条件:判断地址是不是2的幂次就可以
fwork=NULL;
for(work=p->list;/*work!=NULL,此处要考虑挂在尾巴上*/;work=work->next)
{
if(work==NULL || work->start_addr > ab->start_addr)//把一部分(p->size)插在work和fwork之间
{ //找到了位置,准备插入节点
twork=(free_block_type*)malloc(sizeof(free_block_type));//新增的块不用free
twork->size = p->size;
twork->start_addr=ab->start_addr;
ab->start_addr+=p->size; //留下低地址的部分,带着高地址部分继续寻找插入点
ab->size-=p->size;
if(work==NULL)//挂在尾巴上 twork插在fwork和NULL(wrok)之间
{//特点是work=NULL,fwork!=NULL
fwork->next=twork;
twork->next=NULL;
//看看能不能和前面的合并
work=twork;//合并统一性要求 (因为work==NULL,所以将twork替换work,即相当于对next之后的不会改动)
}
else if(work==p->list)//第一个(没有前驱)
{//特点是fwork==NULL ,work==p->list不等于NULL
twork->next=p->list;
p->list=twork;//头插法直接插在头部
//只检查后面的能不能合并
}
else//有前驱和后继 插在fwork之后,work之前
{//特点是fwork和work都不为NULL
twork->next=work;
fwork->next=twork;
//和前面合并
}
//两个块由一个块分裂而来的伙伴条件:判断地址是不是2的幂次就可以
//和前面合并 (如果有前驱的话) 合并fwork 和 twork 其中twork->next= work fwork的地址必须是size*2的倍数
if(fwork!=NULL && fwork->size + fwork->start_addr==twork->start_addr && fwork->start_addr%(p->size<<1)==0)
{
fwork->next=twork->next;
fwork->size+=twork->size;
//删除fwork,因为合并一定能向上冒泡
if(p->list==fwork)//如果fwork为第一个
{
p->list=fwork->next;//删除第一个
}
else
{
//twork初值为第一个
for(work=p->list;work->next!=fwork;work=twork->next)
;
//此时twork为fwork的前驱
work->next=fwork->next;
}
b_creat_free_blocks(fwork);//递归调用
free(twork);
}
//检查后面的能不能合并(如果有后继的话)
if(twork->next!=NULL && twork->start_addr+twork->size == twork->next->start_addr && twork->start_addr%(p->size<<1)==0)
{
work=twork->next;
twork->next=work->next;
twork->size+=work->size;
//twork为新块 现在要删掉twork向上冒泡
if(twork==p->list)//如果twork是第一个,即没有前驱
{
p->list=twork->next;
}
else
{
fwork->next=twork->next;
}
b_creat_free_blocks(twork);
free(work); //和后面的二合一
}
// free(twork);
break;//break for
}
else//设置前驱,继续寻找
{
fwork=work;
}
}//end of for
}//end of if
p=p->next;
i++;
}//end of while
free(ab);
ab=NULL;
return 1;
}
/*创建新的进程,主要是获取内存的申请数量*/
int new_process(){
struct allocated_block *ab;
int size; int ret;
ab=(struct allocated_block *)malloc(sizeof(struct allocated_block));
if(!ab) exit(-5);
ab->next = NULL;
pid++;
sprintf(ab->process_name, "PROCESS-%02d", pid);
ab->pid = pid;
printf("Memory for %s:", ab->process_name);
scanf("%d", &size);
if(size>0) ab->size=size;
ret = allocate_mem(ab); /* 从空闲区分配内存,ret==1表示分配ok*/
/*如果此时allocated_block_head尚未赋值,则赋值*/
if((ret==1) &&(allocated_block_head == NULL)){
allocated_block_head=ab;
return 1; }
/*分配成功,将该已分配块的描述插入已分配链表*/
else if (ret==1) {
ab->next=allocated_block_head;//头插法
allocated_block_head=ab;
return 2; }
else if(ret==-1){ /*分配不成功*/
printf("Allocation fail\n");
free(ab);
return -1;
}
return 3;
}
/*分配内存模块*/
int allocate_mem(struct allocated_block *ab){ //ff bf
struct free_block_type *fbt, *pre;
int request_size=ab->size;
fbt = pre = free_block;
//根据当前算法在空闲分区链表中搜索合适空闲分区进行分配,分配时注意以下情况:
// 1. 找到可满足空闲分区且分配后剩余空间足够大,则分割
// 2. 找到可满足空闲分区且但分配后剩余空间比较小,则一起分配
// 3. 找不可满足需要的空闲分区但空闲分区之和能满足需要,则采用内存紧缩技术,进行空闲分区的合并,然后再分配
// 4. 在成功分配内存后,应保持空闲分区按照相应算法有序
// 5. 分配成功则返回1,否则返回-1
// 请自行补充。。。。。
if(ma_algorithm==MA_FF) //FF 从低地址往高地址分配
{
for(FB* p=free_block;p!=NULL;p=p->next)
{
if(p->size >= request_size)//遇到即分配 FF
{
ab->start_addr=p->start_addr;
p->start_addr+=request_size;
p->size-=request_size;
if(p->size<MIN_SLICE)
{
ab->size+=p->size;
//删除free block
disfree(p);
}
/* 从高往低
ab->start_addr=p->start_addr;
p->size-=request_size;
*/
return 1;
}
}
printf("FF装载失败\n");
return 0;
}
else if(ma_algorithm==MA_BF)//free block按地址排
{
FB *p=free_block;
FB *mini;
int minv;
int fg=0;
for(;p!=NULL;p=p->next)//遍历找到差距最小能装载的free block 从低地址开始装载
{
if(p->size>=request_size)
{
if(fg==0)
{
minv=p->size - request_size;
mini=p;
fg=1;
}
else
{
if(p->size-request_size<minv)
{
minv=p->size-request_size;
mini=p;
}
}
}
}
if(fg)
{
//ab 为要分配的
ab->start_addr=mini->start_addr;
mini->start_addr+=request_size;
mini->size-=request_size;
if(mini->size<MIN_SLICE)
{
ab->size+=mini->size;
//删除free block
disfree(mini);
}
return 1;
}
printf("BF装载失败\n");
return 0;
}
else if(ma_algorithm==MA_WF) //free block按地址排
{
FB *p=free_block;
FB *maxi;
int maxv;
int fg=0;
for(;p!=NULL;p=p->next)//遍历找到差距最小能装载的free block 从低地址开始装载
{
if(p->size>=request_size)
{
if(fg==0)
{
maxv=p->size - request_size;
maxi=p;
fg=1;
}
else
{
if(p->size-request_size>maxv)
{
maxv=p->size-request_size;
maxi=p;
}
}
}
}
if(fg)
{
//ab 为要分配的
ab->start_addr=maxi->start_addr;
maxi->start_addr+=request_size;
maxi->size-=request_size;
if(maxi->size<MIN_SLICE)
{
ab->size+=maxi->size;
//删除free block
disfree(maxi);
}
return 1;
}
printf("WF装载失败\n");
return 0;
}
else if(ma_algorithm==Buddy)
{
if((ab->size)&(ab->size-1))
{
long long i=1;
//不是2的幂次 将ab->size向上寻找一个2的幂次
for(;i<ab->size;i<<=1)
;
ab->size=i;
}
//从b_free_block中从小到大找到一个能装下的2的次方
b_free_block_type *p=b_free_block;
while(p!=NULL)
{
if(p->size>=ab->size && p->list!=NULL)
{
break;
}
p=p->next;
}
if(p!=NULL)//找到了可用块
{
//list按照地址排序的,现在按小地址优先的原则分配
free_block_type *work=p->list;
work->size-=ab->size;
ab->start_addr=work->start_addr;
work->start_addr+=ab->size;
p->list=work->next;
b_creat_free_blocks(work); //将剩余的分割挂在链表合适位置
return 1;
}
else
{
printf("Buddy装载失败\n");
return 0;
}
}//end of buddy
// return 1;
}
struct allocated_block* find_process(int pid)
{
int i;
struct allocated_block *p=allocated_block_head;
for(;p!=NULL;p=p->next)
{
if(p->pid==pid)
return p;
}
return NULL;
}
/*删除进程,归还分配的存储空间,并删除描述该进程内存分配的节点*/
int kill_process(){
struct allocated_block *ab;
int pid;
printf("Kill Process, pid=");
scanf("%d", &pid);
ab=find_process(pid);
if(ab!=NULL){
free_mem(ab); /*释放ab所表示的分配区*/
dispose(ab); /*释放ab数据结构节点*/
}
else
{
cout<<"不存在"<<endl;
}
}
/*将ab所表示的已分配区归还,并进行可能的合并*/
int free_mem(struct allocated_block *ab){ //不会删除ab
struct free_block_type *fbt=NULL, *pre, *work;
// fbt=(struct free_block_type*) malloc(sizeof(struct free_block_type));
// if(!fbt) return -1;
// 进行可能的合并,基本策略如下
// 1. 将新释放的结点插入到空闲分区队列末尾
// 2. 对空闲链表按照地址有序排列
// 3. 检查并合并相邻的空闲分区
// 4. 将空闲链表重新按照当前算法排序 /-> 本程序不做次操作
//请自行补充……
if(ma_algorithm==MA_FF || ma_algorithm== MA_BF || ma_algorithm== MA_WF)//free链表都是按地址排序,所以可以用同一种方式free
{
FB *fp=NULL,*p=NULL;
for(p=free_block;p!=NULL && p->start_addr < ab->start_addr;p=p->next)//寻找block属于哪一个free block
{
fp=p;
//前一个小于,后一个大于
}
//fp为前一个free_block ab为当前要free的block p为下一个
if(fp!=NULL && fp->start_addr+fp->size==ab->start_addr)
{ //当前面还有东西,就往前合并。。。,//???但如果,已经是最低地址的块了 就不往前找了 我好像说了个废话 ???
fp->size+=ab->size;
//fp为前面的块,p为后面的块
printf("和前一个合并\n");//不新增free_blocks
if(p!=NULL && p->start_addr == fp->start_addr + fp->size)//用前面的free block尝试往后合并
{
// fp->start_addr = p->start_addr;
fp->size += p->size;
fp->next=p->next;
free(p);//前后合并,删除后面的free block
printf("和后一个合并");
return 1;
}
return 1;
}
else if(p!=NULL && p->start_addr == ab->start_addr + ab->size)//尝试往后合并 p为后面的
{
p->start_addr = ab->start_addr;
p->size += ab->size;
printf("和后一个合并");
return 1;
}
//无法合并,直接释放,free链表插入节点 fp为前一个,p为后一个 fbt为新的free block
// display_mem_usage();
fbt=(struct free_block_type*) malloc(sizeof(struct free_block_type));
fbt->size=ab->size;
fbt->start_addr=ab->start_addr;
fbt->next=p;
if(fp==NULL)
{
fbt->next=free_block;//头插法
free_block=fbt;
}
else
{
fp->next=fbt;
}
printf("没法合并,直接释放");
}
else if(ma_algorithm==Buddy)
{
fbt=(struct free_block_type*) malloc(sizeof(struct free_block_type));
if(!fbt) return -1;
fbt->size=ab->size;
fbt->start_addr=ab->start_addr;
return b_creat_free_blocks(fbt);//会销毁fbt
}
return 1;
}
/*释放ab数据结构节点*/
int dispose(struct allocated_block *free_ab){
struct allocated_block *pre, *ab;
if(free_ab == allocated_block_head) { /*如果要释放第一个节点*/
allocated_block_head = allocated_block_head->next;
free(free_ab);
return 1;
}
pre = allocated_block_head;
ab = allocated_block_head->next;
while(ab!=free_ab){ pre = ab; ab = ab->next; }
pre->next = ab->next;
free(ab);
return 2;
}
int disfree(FB *free_ab){
FB *pre, *ab;
if(free_ab == free_block) { /*如果要释放第一个节点*/
free_block = free_block->next;
free(free_ab);
return 1;
}
pre = free_block;
ab = free_block->next;
while(ab!=free_ab){ pre = ab; ab = ab->next; }
pre->next = ab->next;
free(ab);
return 2;
}
/* 显示当前内存的使用情况,包括空闲区的情况和已经分配的情况 */
int display_mem_usage(){
if(ma_algorithm==Buddy)
{
cout<<"free blocks:"<<endl;
b_free_block_type *p=b_free_block;
while(p!=NULL)
{
printf("list:%d-----------<\n",p->size);
free_block_type *work=p->list;
while(work!=NULL)
{
printf("·start_adress:%-3d size:%-3d\n",work->start_addr,work->size);
work=work->next;
}
p=p->next;
}
struct free_block_type *fbt=free_block;
struct allocated_block *ab=allocated_block_head;
printf("\nUsed Memory:\n");
printf("%10s %20s %10s %10s\n", "PID", "ProcessName", "start_addr", " size");
while(ab!=NULL){
printf("%10d %20s %10d %10d\n", ab->pid, ab->process_name, ab->start_addr, ab->size);
ab=ab->next;
}
}
else
{
struct free_block_type *fbt=free_block;
struct allocated_block *ab=allocated_block_head;
if(fbt==NULL) return(-1);
printf("\tw.%s.t.\n","b");
printf("----------------------------------------------------------\n");
/* 显示空闲区 */
printf("Free Memory:\n");
printf("%20s %20s\n", " start_addr", " size");
while(fbt!=NULL){
printf("%20d %20d\n", fbt->start_addr, fbt->size);
fbt=fbt->next;
}
/* 显示已分配区 */
printf("\nUsed Memory:\n");
printf("%10s %20s %10s %10s\n", "PID", "ProcessName", "start_addr", " size");
while(ab!=NULL){
printf("%10d %20s %10d %10d\n", ab->pid, ab->process_name, ab->start_addr, ab->size);
ab=ab->next;
}
printf("----------------------------------------------------------\n");
return 0;
}
}
/*按指定的算法整理内存空闲块链表*/
int rearrange(int algorithm){
switch(algorithm){
case MA_FF: rearrange_FF(); break;
case MA_BF: rearrange_BF(); break;
case MA_WF: rearrange_WF(); break;
case Buddy:rearrange_Buddy();break;
}
}
void free_f()
{
struct allocated_block *f,*p;
f=allocated_block_head;
for(;f!=NULL;f=p)
{
p=f->next;
free(f);
}
allocated_block_head=NULL;
struct free_block_type *fn,*fp;
fp=free_block;
for(;fp!=NULL;fp=fn)
{
fn=fp->next;
free(fp);
}
free_block=NULL;
}
void free_b()
{
b_free_block_type *p,*tp;
free_block_type *work,*t;
p=b_free_block;
while(p!=NULL)
{
tp=p;
p=p->next;
work=tp->list;
while(work!=NULL)
{
t=work;
work=work->next;
free(t);
}
free(tp);
}
b_free_block=NULL;
}
void do_exit()
{
free_f();
free_b();
}
main(){
char choice; pid=0;
free_block = init_free_block(mem_size); //初始化空闲区
while(1) {
display_menu(); //显示菜单
cout<<"当前算法编号:"<<ma_algorithm<<endl;
fflush(stdin);
choice=getchar(); //获取用户输入
switch(choice)
{
case 1: set_mem_size(); break; //设置内存大小 //开机只能设置一次,且只能在分配之前设置
case 2: set_algorithm();flag=1; break;//设置算法
case 3: new_process(); flag=1; break;//创建新进程
case 4: kill_process(); flag=1; break;//删除进程
case 5: display_mem_usage(); flag=1; break; //显示内存使用
case 0: do_exit(); exit(0); //释放链表并退出
default: break;
}
}
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.98.99.100.101.102.103.104.105.106.107.108.109.110.111.112.113.114.115.116.117.118.119.120.121.122.123.124.125.126.127.128.129.130.131.132.133.134.135.136.137.138.139.140.141.142.143.144.145.146.147.148.149.150.151.152.153.154.155.156.157.158.159.160.161.162.163.164.165.166.167.168.169.170.171.172.173.174.175.176.177.178.179.180.181.182.183.184.185.186.187.188.189.190.191.192.193.194.195.196.197.198.199.200.201.202.203.204.205.206.207.208.209.210.211.212.213.214.215.216.217.218.219.220.221.222.223.224.225.226.227.228.229.230.231.232.233.234.235.236.237.238.239.240.241.242.243.244.245.246.247.248.249.250.251.252.253.254.255.256.257.258.259.260.261.262.263.264.265.266.267.268.269.270.271.272.273.274.275.276.277.278.279.280.281.282.283.284.285.286.287.288.289.290.291.292.293.294.295.296.297.298.299.300.301.302.303.304.305.306.307.308.309.310.311.312.313.314.315.316.317.318.319.320.321.322.323.324.325.326.327.328.329.330.331.332.333.334.335.336.337.338.339.340.341.342.343.344.345.346.347.348.349.350.351.352.353.354.355.356.357.358.359.360.361.362.363.364.365.366.367.368.369.370.371.372.373.374.375.376.377.378.379.380.381.382.383.384.385.386.387.388.389.390.391.392.393.394.395.396.397.398.399.400.401.402.403.404.405.406.407.408.409.410.411.412.413.414.415.416.417.418.419.420.421.422.423.424.425.426.427.428.429.430.431.432.433.434.435.436.437.438.439.440.441.442.443.444.445.446.447.448.449.450.451.452.453.454.455.456.457.458.459.460.461.462.463.464.465.466.467.468.469.470.471.472.473.474.475.476.477.478.479.480.481.482.483.484.485.486.487.488.489.490.491.492.493.494.495.496.497.498.499.500.501.502.503.504.505.506.507.508.509.510.511.512.513.514.515.516.517.518.519.520.521.522.523.524.525.526.527.528.529.530.531.532.533.534.535.536.537.538.539.540.541.542.543.544.545.546.547.548.549.550.551.552.553.554.555.556.557.558.559.560.561.562.563.564.565.566.567.568.569.570.571.572.573.574.575.576.577.578.579.580.581.582.583.584.585.586.587.588.589.590.591.592.593.594.595.596.597.598.599.600.601.602.603.604.605.606.607.608.609.610.611.612.613.614.615.616.617.618.619.620.621.622.623.624.625.626.627.628.629.630.631.632.633.634.635.636.637.638.639.640.641.642.643.644.645.646.647.648.649.650.651.652.653.654.655.656.657.658.659.660.661.662.663.664.665.666.667.668.669.670.671.672.673.674.675.676.677.678.679.680.681.682.683.684.685.686.687.688.689.690.691.692.693.694.695.696.697.698.699.700.701.702.703.704.705.706.707.708.709.710.711.712.713.714.715.716.717.718.719.720.721.722.723.724.725.726.727.728.729.730.731.732.733.734.735.736.737.738.739.740.741.742.743.744.745.746.747.748.749.750.751.752.753.754.755.756.757.758.759.760.761.762.763.764.765.766.767.768.769.770.771.772.773.774.775.776.777.778.779.780.781.782.783.784.785.
六、应对内存碎片的策略
6.1内存池技术
内存池(Memory Pool)是一种内存分配方式。 通常我们习惯直接使用new、malloc等API申请分配内存,这样做的缺点在于:由于所申请内存块的大小不定,当频繁使用时会造成大量的内存碎片并进而降低性能。
内存池则是在真正使用内存之前,先申请分配一定数量的、大小相等(一般情况下)的内存块留作备用。当有新的内存需求时,就从内存池中分出一部分内存块,若内存块不够再继续申请新的内存。这样做的一个显著优点是尽量避免了内存碎片,使得内存分配效率得到提升。
在c++程序设计中,一般在没有什么特殊要求时,都是使用new 与 delete 来分配和释放动态内存,这几乎时直接在与操作系统的内存管理系统进行交互。当应用程序需要的动态内存很小的时候,这不是什么问题,但如果应用程序需要的动态内存不仅量很大,而且对动态内存的申请和释放又极其频繁,那么问题就很大。
操作系统对系统内存的管理是一件极其繁琐的事,用户对动态内存的每一次请求都要经过一道繁琐的手续才能获得成功,就是销毁内存也是一件不太容易的事,因为每次系统的内存管理系统都要对内存的使用情况进行整理和记录。简单的说就是,每次系统的内存管理系统来使用内存,既费时又费力。
那么解决这个这个问题的方法就是“批发”,即一次申请一大块内存,把这大块内存作为应用程序的内存储备,每当需要一小块内存的时候就到这个储备的内存中来取用,不用了就归还给这个内存,程序就快捷多了。总有一些意外会使初始申请的这块内存储备也不够,那么就再申请一块内存,然后把它与原有的内存块用链表连接起来组成更大的内存储备。这种由应用程序储备的内存就叫做内存池。
使用内存池另一个好处就是能够有效的防治内存碎片华,因为他总是大块大块的申请内存,因此对于系统内存管理系统来讲,这是个省时省力的好事。
以游戏开发中频繁创建和销毁子弹对象为例,假设每个子弹对象大小为 32 字节。如果使用传统的内存分配方式,每次创建子弹都调用new,销毁时调用delete,随着游戏中子弹数量的增多,内存碎片会迅速增加。而使用内存池技术,在游戏初始化时,就预先分配一块大内存,比如 1024 字节。将这块大内存按照 32 字节的大小划分成 32 个内存块,组成一个内存池。
当需要创建子弹对象时,直接从内存池中取出一个空闲的内存块来使用,而不需要向操作系统申请新的内存。当子弹对象销毁时,将其占用的内存块放回内存池,而不是直接归还给操作系统。这样,因为内存池中的内存块大小通常是固定的,所以可以避免内部碎片的产生。同时,当内存块被释放时,可以直接放回内存池中,而不需要进行复杂的内存合并操作,从而减少外部碎片的产生 。
6.2选择合适的内存分配策略
不同的内存分配策略对内存碎片的产生有不同的影响 。在 C++ 中,我们可以根据程序的特点选择合适的内存分配策略。例如,对于需要频繁分配和释放小对象的程序,可以考虑使用基于对象池的分配策略;对于需要分配大量连续内存的程序,可以考虑使用线性分配器等。此外,还可以使用一些智能的内存分配算法,如伙伴系统(buddy system)、slab 分配器等。这些算法可以根据内存需求的大小自动选择合适的内存块进行分配,从而减少内存碎片的产生 。
在一个网络通信程序中,会频繁地接收和发送小的数据包,每个数据包大小可能在几十到几百字节不等。这时使用基于对象池的分配策略就很合适。预先创建一个包含多个固定大小内存块的对象池,每个内存块的大小刚好能容纳一个最大尺寸的数据包。当有数据包到来时,直接从对象池中获取一个空闲内存块来存储数据包,处理完后再将内存块放回对象池。
而在一个 3D 建模软件中,可能需要分配大量连续内存来存储模型的顶点数据、纹理数据等。这种情况下,使用线性分配器,一次性从内存中分配一大块连续的内存区域,然后按照需求在这块区域内进行分配和管理,就可以满足对大量连续内存的需求,同时减少内存碎片的产生 。
6.3及时释放不再使用的内存
及时释放不再使用的内存是减少内存碎片的重要方法之一 。在 C++ 中,我们可以使用智能指针等技术来自动管理内存的分配和释放,避免内存泄漏问题。同时,在程序中要注意及时清理不再使用的对象,释放其占用的内存。例如,在使用std::vector等容器时,如果不再需要容器中的元素,可以使用clear()方法清空容器,释放内存。对于动态分配的内存,可以在使用完毕后及时使用delete或delete[]运算符释放内存 。
在一个图像编辑程序中,当用户关闭一个图像文件时,程序应该及时释放用于存储该图像数据的内存。如果使用智能指针来管理图像数据的内存,当智能指针超出作用域时,它会自动释放所指向的内存。比如std::unique_ptr<ImageData> image(new ImageData());,当image变量离开其作用域时,ImageData对象所占用的内存会被自动释放,这样就避免了内存泄漏,也减少了内存碎片的产生 。
6.4避免频繁的内存分配和释放操作
频繁的内存分配和释放操作是导致内存碎片产生的主要原因之一 。在编写程序时,可以尽量减少不必要的内存分配和释放操作。例如,可以在程序启动时一次性分配足够的内存,然后在程序运行过程中根据需要进行复用,而不是每次需要时都进行新的内存分配。此外,还可以使用对象缓存等技术,将不再使用的对象缓存起来,以便下次需要时直接复用,而不需要进行新的内存分配 。
在一个数据库管理系统中,连接数据库是一个比较耗时的操作,同时也会涉及到内存的分配和释放。如果每次执行数据库查询都重新建立连接,就会频繁地进行内存分配和释放操作。可以在系统启动时建立一个数据库连接池,一次性分配好多个数据库连接对象所需的内存。
当有查询请求时,从连接池中获取一个空闲的连接,使用完毕后再放回连接池,而不是每次都重新分配和释放连接对象的内存。这样不仅减少了内存分配和释放的次数,降低了内存碎片产生的可能性,还提高了系统的性能 。
七、解决内存碎片方法
7.1内部碎片的解决
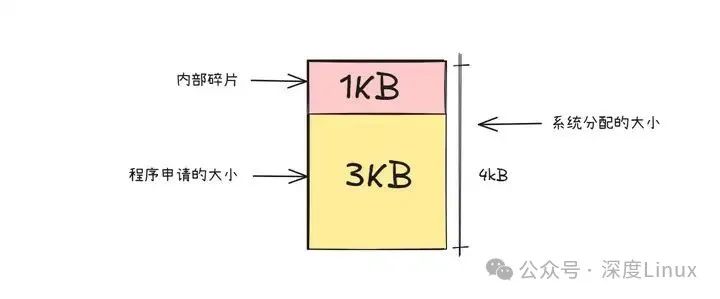
在操作系统的内存管理体系中,内部碎片就像是一个如影随形的 “顽疾”。目前,大多数操作系统采用以页(通常为 4KB)为单位的内存分配策略,这种固定粒度的分配方式,从根源上决定了内部碎片无法被彻底消除。
打个比方,内存分配就像在超市购物后用固定规格的塑料袋装物品。当程序向系统请求 3KB 的内存时,就好比你只买了少量物品,系统却必须给你一个能装 4KB “货物” 的塑料袋 —— 它无法拆分出一个刚好容纳 3KB 内存的 “小袋子”,只能分配一整页 4KB 的内存空间。如此一来,就有 1KB 的内存空间被闲置,这 “多出来” 的 1KB,便是内部碎片。
由于程序对内存的需求千差万别,有的程序需要几十 KB,有的则需要几百 MB,无论操作系统如何优化,都很难让每次分配的内存都能被程序精准 “填满”。这就如同用标准大小的塑料袋去装各式各样的物品,总会出现袋子装不满的情况。所以在当前以页为单位的内存分配机制下,内部碎片的存在几乎是必然的,它就像内存管理领域的 “黑洞”,默默吞噬着部分宝贵的内存资源。
尽管内部碎片如同内存管理领域的 “幽灵”,无法被彻底驱逐,但我们仍能通过巧妙的策略和技术,将其带来的负面影响降至最低。在 C/C++ 编程世界中,经典的malloc内存分配函数与强大的 STL(标准模板库),就像两位 “内存管理大师”,各自施展着独特的 “功夫”,在减少内存碎片的战场上大展身手。接下来,就让我们深入探究它们是如何与内存碎片 “过招”,守护程序的内存健康的。
第一种解决方法——malloc内存分配函数。
想要理解malloc如何优化内存碎片问题,首先需要对它的内存分配机制有个基础认知。虽然malloc在不同的系统和库实现中存在多种版本(如 glibc 中的 ptmalloc、jemalloc 等,各自有复杂精妙的实现逻辑),但我们可以通过一个简化模型,快速抓住它的核心原理。
malloc就像一位精明的 “内存管家”,在程序内部精心维护着一座专属的 “内存仓库”—— 内存池。当程序启动,或是第一次调用malloc函数时,这位 “管家” 就会主动出击,向操作系统申请一块面积可观的连续内存区域。此后,程序中所有的内存分配请求,都将从这座 “内存仓库” 中按需提取,而不再频繁地与操作系统 “打交道”。

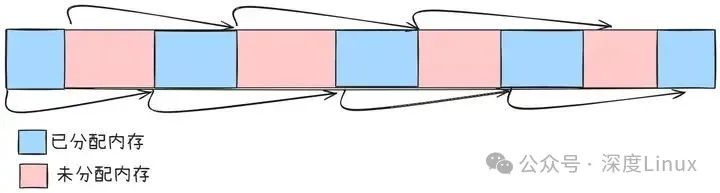
程序运行时,频繁的内存分配与释放会把内存池 “切割” 成一块块不连续的碎片。为了管理这些碎片,malloc会在内存池里维护一张 “状态清单”,用隐式链表法记录每个内存块是已被占用还是空闲可用。这种方法就像在图书馆里标记每本书的借阅状态一样,让malloc能快速找到合适的内存块分配给程序。
 图片
图片
malloc管理的内存块就像用链条串起来的珠子,已分配和空闲的内存块都通过指针首尾相连。每个内存块的具体结构是这样的:
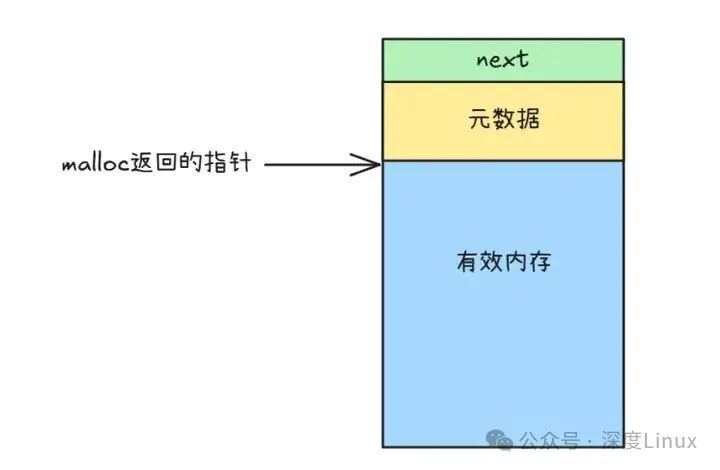 图片
图片
每个内存块里除了存放用户要用的数据,还 “藏” 着一些关键信息,比如块的大小、有没有被占用。另外,每个块都带一个 “小尾巴”(指针),指向下一个内存块。靠着这些设计,不管内存块是闲着还是正在被用,都能像火车车厢一样串联起来。
当程序调用malloc申请内存时,它会优先在自己的内存池里 “翻箱倒柜”,找一块大小合适的空闲内存块分配出去,而不是每次都麻烦操作系统重新划拨内存。
为了找到大小合适的空闲内存块,malloc有几种常用的 “寻宝策略”:
首次适应算法(First Fit):从空闲分区表的第一个表目起查找该表,把最先能够满足要求的空闲区分配给作业,这种方法的目的在于减少查找时间。为适应这种算法,空闲分区表(空闲区链)中的空闲分区要按地址由低到高进行排序。该算法优先使用低址部分空闲区,在低址空间造成许多小的空闲区,在高地址空间保留大的空闲区。最佳适应算法(Best Fit):从全部空闲区中找出能满足作业要求的、且大小最小的空闲分区,这种方法能使碎片尽量小。为适应此算法,空闲分区表(空闲区链)中的空闲分区要按从小到大进行排序,自表头开始查找到第一个满足要求的自由分区分配。该算法保留大的空闲区,但造成许多小的空闲区。最差适应算法(Worst Fit):从全部空闲区中找出能满足作业要求的、且大小最大的空闲分区,从而使链表中的结点大小趋于均匀,适用于请求分配的内存大小范围较窄的系统。为适应此算法,空闲分区表(空闲区链)中的空闲分区按大小从大到小进行排序,自表头开始查找到第一个满足要求的自由分区分配。该算法保留小的空闲区,尽量减少小的碎片产生。
要是内存池里的 “存货” 不够用了,malloc就会去找操作系统 “补货”。这时候,它会通过调用brk或者mmap这两个 “采购员”,向操作系统申请更多内存资源 。
brk系统调用:brk用于将进程的数据段(堆)的边界向上扩展(增加)或向下收缩(减少)。它通过设置进程的break指针来实现内存的分配和释放。当调用brk时,内核会调整break指针的位置,将堆空间扩大或缩小。如果是扩大堆空间,新分配的内存就在原来堆的顶部连续增加;如果是缩小堆空间,内核会释放break指针以下的部分内存。mmap系统调用:mmap用于将一个文件或设备的内存区域映射到进程的虚拟地址空间中。它可以将磁盘文件的内容直接映射到进程的地址空间,使得进程可以像访问内存一样访问文件内容,也可以用于分配匿名内存(即不与任何文件关联的内存)。当使用mmap分配内存时,内核会在进程的虚拟地址空间中找到一段合适的空闲区域,并将其与物理内存建立映射关系。
为什么malloc对大块内存(≥128KB)和小块内存(<128KB)采用不同的分配策略?
主要有两个原因:
①效率权衡
brk:通过移动堆顶指针分配内存,操作轻量但只能释放堆顶内存(类似栈结构)。小块内存频繁分配释放时,这种方式更高效。mmap:每次创建独立的内存映射,释放时可立即回收,但创建映射的开销较大。大块内存使用 mmap 避免长期占用堆空间,导致碎片累积。
②碎片控制
大块内存若用 brk 分配,会导致堆顶长期被占用,后续释放时无法回收中间的空闲空间,形成外部碎片。mmap 分配的内存独立于堆,释放后可完全回收,避免碎片影响堆的连续性。
简单说:小块用 brk(快),大块用 mmap(避免碎片),这是性能与内存利用率的平衡之道。
第二种解决方法——STL二级空间配置器。
STL(标准模板库)为了更高效地管理内存,对new运算符进行了 “魔改”,引入了二级空间配置器(__default_alloc_template)。这个配置器有两种 “工作模式”:
第一级空间配置器:直接使用 malloc/free 分配内存。第二级空间配置器:当要分配内存大于 128 字节由第一级空间分配器分配。当要分配内存小于 128 字节,从内存池中分配。
第二级空间配置器分为两部分:空闲链表(free_list)与内存池。
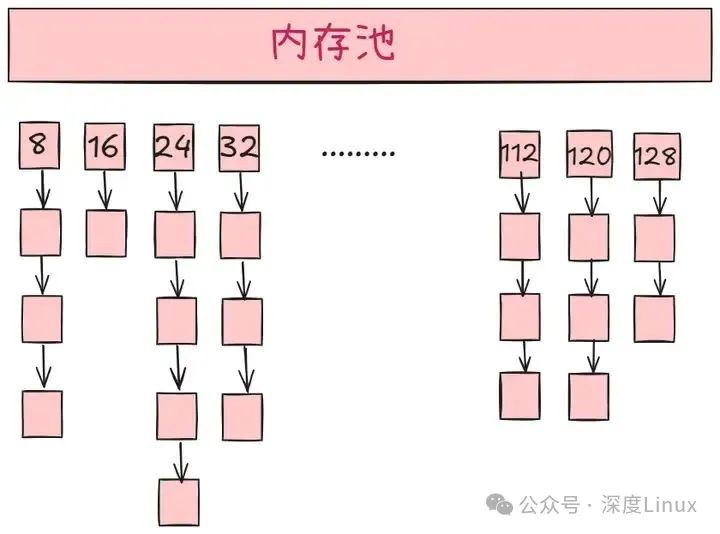 图片
图片
第二级空间配置器就像是一个精密的 “内存便利店”,内部维护着 16 个 “货架”(空闲链表),每个货架专门存放一种固定尺寸的 “商品”(内存块)。这些 “商品” 的规格从 8 字节开始,以 8 字节为一档递增,最大到 128 字节。每个 “货架” 上的内存块都通过指针串成了一条 “链子”,就像超市里挂着的一排挂钩,方便快速取用和归还。
查找合适的空闲链表:根据所需分配的内存大小,计算出对应的空闲链表编号。例如,若要分配 20 字节的内存,会将其调整为 24 字节(8 的倍数),然后找到对应 24 字节的空闲链表。
检查空闲链表是否为空:
不为空:从链表头部取出一个节点,将其从链表中移除,然后返回该节点的地址给用户。为空:调用 refill 函数重新填充该空闲链表。refill 函数会调用 chunk_alloc 从内存池分配一大块内存,接着将其分割成多个小块,插入到空闲链表中,最后返回其中一个小块给用户。
refill和chunk_alloc就像是内存池的 “搬运工”,专门负责从系统申请内存。其中refill函数的工作流程是这样的:
调用 chunk_alloc 分配内存:尝试从内存池分配一定数量(通常为 20 个)的指定大小的内存块。分割内存块:将分配到的大块内存分割成多个小块。插入空闲链表:把除第一个小块之外的其他小块插入到对应的空闲链表中,第一个小块返回给用户。
chunk_alloc函数是内存池的 “材料供应商”,它的工作流程主要包括:
检查内存池剩余空间:足够:直接从内存池分配所需数量的内存块。部分足够:分配尽可能多的内存块,调整剩余空间。不足:尝试从堆中分配更多内存,更新内存池的起始和结束指针。如果堆内存不足,会尝试从其他空闲链表中寻找可用的内存块。
 图片
图片
当程序释放内存时,二级空间配置器会像图书管理员整理书架一样,执行以下操作:
查找合适的空闲链表:根据释放的内存块大小,找到对应的空闲链表。将内存块插入链表头部:把释放的内存块转换为空闲内存块类型,将其空闲链表头指针指向当前链表头部,然后更新链表头部指针为该内存块。
STL 二级空间配置器通过空闲链表管理小内存块,将内存按 8 字节对齐分类存储(8B~128B 共 16 类)。这种设计就像图书馆的书架系统,不同大小的 “书籍”(内存块)存放在专属区域,分配 / 回收时直接从对应链表取 / 还,无需频繁向操作系统申请内存,既减少了系统调用开销,又避免了内存碎片,显著提升了小对象的内存管理效率。
7.2外部碎片的解决
外部碎片的治理主要依赖操作系统的物理内存管理策略。以 Linux 为例,它运用伙伴系统算法对物理页进行管理,通过将内存块按 2 的幂次大小划分,在内存分配与回收时合并相邻空闲块,以此有效减少外部碎片问题。
第一种解决方法——伙伴系统算法。
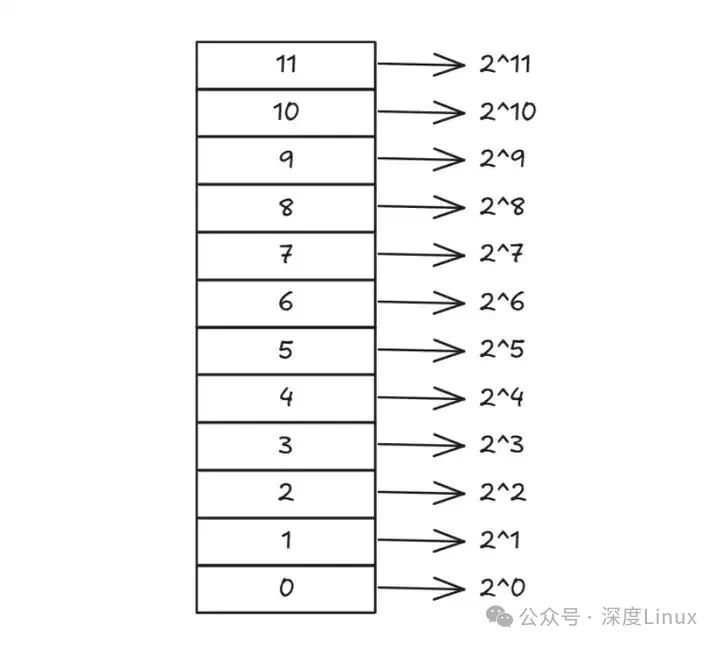
在 Linux 系统里,物理内存以页为最小单位分配,由伙伴系统算法统一管理。系统维护着 12 条空闲块链表,专门用来记录所有可用的物理页。
Linux 伙伴系统的 12 个空闲块链表,按内存块大小由小到大排列:
list[0]存放 1 页(2^0)大小的空闲块list[1]存放 2 页(2^1)大小的空闲块依此类推,每个链表的内存块大小都是前一个的 2 倍
 图片
图片
当系统收到内存分配请求时,会按这样的步骤快速响应:
计算页数:将请求大小(如 16KB)除以页框大小(如 4KB),得到所需页数(4 页)确定链表索引:通过公式log2(页数)找到对应链表索引(log2 (4)=2,即list[2])分配内存:直接从list[2]提取一个 4 页的空闲块
找到对应空闲链表后,操作系统就开始 “取货”:如果链表中有存货(存在空闲内存块),就直接拿走一块分配出去,同时更新链表状态,标记这块内存已被占用。
要是对应链表没 “货”(为空),系统就从 “大仓库” 里拆内存:去下一个更大的空闲链表找内存块,找到后一分为二,一半用来满足当前需求,另一半放回对应大小的链表。这新分出的两块内存就像 “孪生兄弟”,被称为伙伴块。
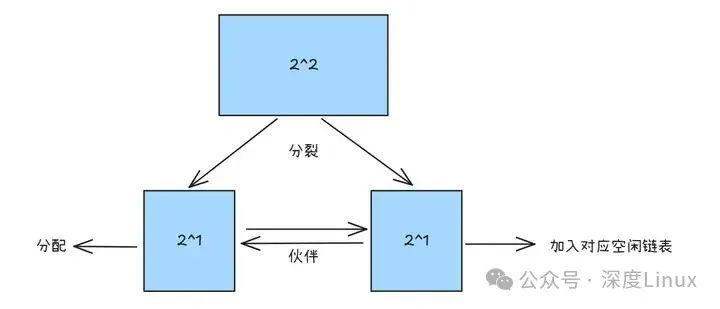 图片
图片
分配内存时,如果当前链表没空闲块,系统会 “层层上找”,直到找到有空闲块的链表,或者找遍所有链表。要是最大的链表都没可用内存,那就只能提示内存不足、分配失败了。
释放内存时,系统先把内存块标记为空闲,再减少其引用计数。当计数归零,这块内存就能被回收。回收时,系统会根据内存块的地址和大小,算出它的 “伙伴” 地址 —— 所谓 “伙伴”,就是当初一起从大内存块拆分出来、大小相同且紧挨着的另一块内存。
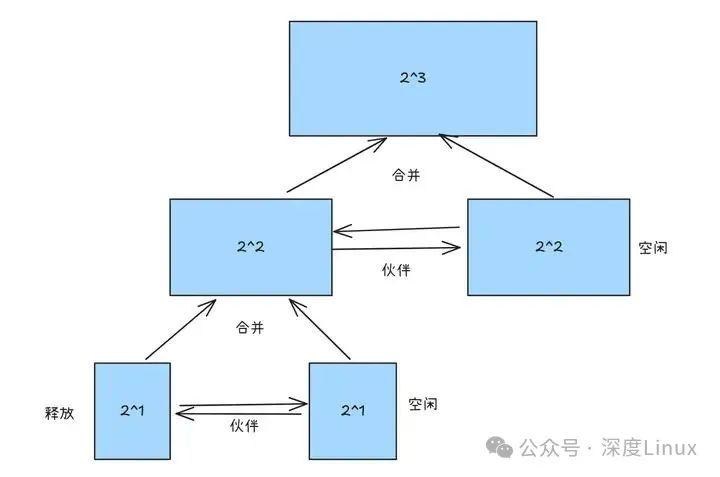 图片
图片
回收内存时,系统会先查看目标内存块的 “伙伴” 状态:
伙伴空闲:立即将两者合并成更大的块,放入对应链表,接着检查新块的伙伴是否也空闲,循环合并,直到没有可合并的伙伴。伙伴被占用:直接把释放的内存块放进对应大小的空闲链表。
伙伴系统这种 “找搭档 - 合并” 的设计,让内存分配又快又准,回收时还能把相邻的空闲块 “拼” 起来,减少碎片。不管是分配小页还是大连续区域,都能高效搞定,大幅提升内存使用效率。
第二种解决方法——slab分配器。
在以 “页” 为单位的大尺度内存管理上,Linux 依靠伙伴系统避免碎片化;但面对一页内存内部的 “小空间”,伙伴系统就力不从心了。这时,Linux 会启用 slab 分配器,专门处理页内内存,进一步减少碎片问题。
slab 分配器就像一个 “小型内存管家”,专门负责管理小尺寸的内存对象。它的核心策略是:把内核常用的对象预先 “存” 在 slab 缓存里,随时待命。当程序需要内存时,直接从缓存拿对象,不用每次都找伙伴系统 “要新页”。slab 分配器由缓存、slab 和对象三层结构组成:
缓存:针对不同类型对象(如文件描述符结构体),建立专属 “仓库”;slab:每个 “仓库” 里有多个 “货架”,存放固定大小的对象;对象:具体的数据结构,像整齐码放在 “货架” 上的商品,随取随用 。
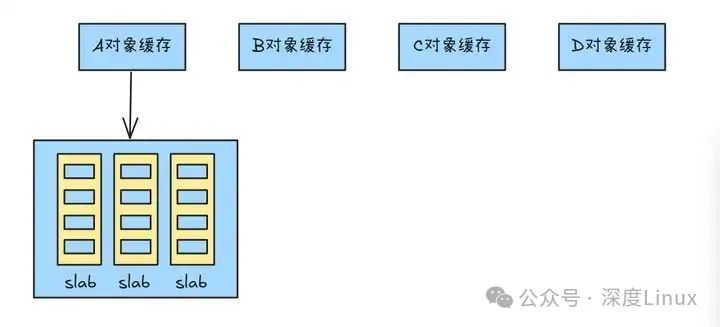 图片
图片
slab 就像不同状态的 “内存小仓库”,主要有这三种情况:
FULL(满):所有对象已被分配,无法再分配新对象。PARTIAL(部分空):部分对象在用,部分是空闲的,优先从此分配内存。EMPTY(空):所有对象均未使用,系统内存不足时可回收释放。
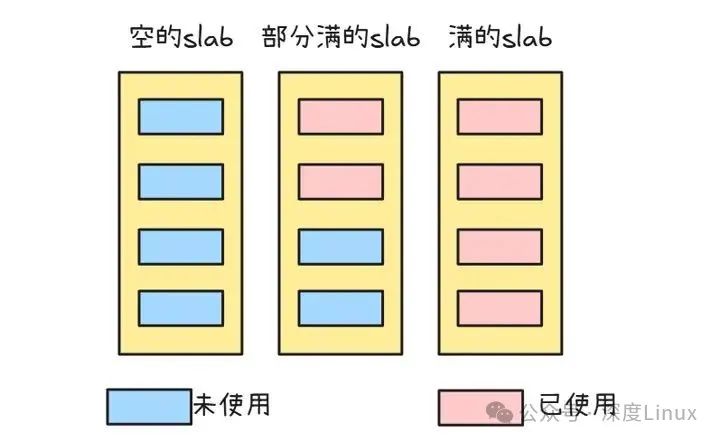 图片
图片
在 Linux 内核里,slab 分配器堪称 “小对象管家”,专门负责管理进程控制块(PCB)、文件描述符、内存页结构体这类 “常客”。这些对象尺寸固定,还经常被反复创建、销毁,用 slab 分配器管理,既能快速响应需求,又能避免内存浪费。
当内核模块需要分配对象时,slab 分配器分三步完成任务:
快速检索:根据对象类型定位专属缓存,在缓存内的多个 slab 中查找是否有空闲对象。由于分类存储,能迅速锁定目标。补充资源:若缓存无可用对象,检查是否存在空闲 slab。若有,直接从中取出一个对象交付;若没有,则向内存申请新的 slab,新 slab 由连续内存页构成,并分割成固定大小的对象单元。交付标记:无论从现有空闲资源还是新分配的 slab 中获取对象,都会立即分配给请求模块,并将对象标记为已使用状态。
对象使用完释放时,slab 分配器会这样处理:
回收对象:将对象标记为空闲,放回原本缓存的 slab 里,就像把用过的工具放回专属抽屉。检查抽屉状态:释放后,查看这个 slab 里还有多少空闲对象。如果所有对象都空出来了,就把整个 slab 标记为空闲。这些空闲 slab 后续可能会被重新拿出来用;要是内存紧张,还会被归还给内存池 “二次利用”。
slab 分配器解决内存碎片的核心思路可以概括为:“预分配 + 固定规格 + 循环利用”。它提前在连续内存上建立对象缓存,划分成统一大小的对象单元。当内核需要频繁创建、销毁小对象时,直接从缓存拿取或归还,避免零散分配释放造成外部碎片;固定尺寸的对象分配模式,又防止了按需切割引发的内部碎片。而且释放的对象会被复用回原缓存,减少内存频繁操作,让内存空间始终保持整齐高效。
八、附录:其他内存技术
8.1垃圾回收机制
程序在创建对象或者数组等引用类型实体的时候,系统会在堆内存上为之分配一段内存区,用来保存这些对象,当这些对象永久地失去引用后,就会变成垃圾,等待系统垃圾回收机制进行回收。
垃圾回收机制只会回收堆内存中的对象,不会回收物理资源(网络io)
垃圾回收机制是由系统控制的,程序是无法精准控制垃圾回收机制的时机的,程序只能指导对象什么时候不再被引用,当一个对象永久性地失去引用后,会由可达状态变为可恢复状态,程序会通知系统进行垃圾回收,但只是通知,最终是否回收是不确定的。
因为系统进行垃圾回收之前,会调用finalize()方法,这个 方法可能会使对象被重新引用,变为可达状态,此时垃圾回收就会取消,
当系统调用了所有finalize()方法后,该对象仍然是可恢复状态,也就是说此时的对象真正的失去了作用,这个时候该对象就会由可恢复状态转变位不可达状态,最终会被系统作为垃圾回收掉该对象所占用的资源。
finalize()方法时系统进行垃圾回收之前调用的方法。当系统要对某个不再被引用的对象所占用的资源进行回收时,会要求程序调用适当的方法来进行资源的清理,在java中提供了默认的机制来进行该资源的清理,也就是finalize()方法;finalize()方法时由系统的垃圾回收机制来调用的,这个方法的调用会使恢复状态的对象重新被引用,所以它具有不确定性,最好不要人为的调用它来清理某个系统资源。
对象在垃圾回收机制有三种状态:可达性、可恢复性、不可达性。
当一个对象被创建后,只要有一个以上的引用变量引用它,这个状态就处于可达状态;当一个对象失去了所有的引用之后,它就进入了可恢复状态,这个状态下,系统的垃圾回收机制会随时调用finalize()方法对它占用的资源进行回收,此时只要由引用变量引用对该对象,这个对象又变成可达状态,否则进入不可达状态。处于不可达状态的对象,就会等待系统弄随时对它所占的资源进行回收。
8.2内存压缩与紧缩
为节省存储空间或传输带宽,人们已经在计算机系统中广泛地使用了数据压缩技术。在磁介质存储数据或网络传输数据时,人们使用基于硬件或软件的各种压缩技术。当压缩技术在各个领域都很流行时,内存压缩技术却由于其复杂性而一直未得到广泛使用。近年来,由于在并行压缩一解压算法以及在硅密度及速度方面取得的进展,使得内存压缩技术变得可行。
内存压缩技术的主要思想是将数据按照一定的算法压缩后存入压缩内存中,系统从压缩内存中找到压缩过的数据,将其解压后即可以供系统使用。这样既可以增加实际可用的内存空间,又可以减少页面置换所带来的开销,从而以较小的成本提高系统的整体性能。
内存压缩机制是在系统的存储层次中逻辑地加入一层——压缩内存层。系统在该层中以压缩的格式保存物理页面,当页面再次被系统引用时,解压该压缩页后,即可使用。我们将管理这一压缩内存层的相关硬件及软件的集合统称为内存压缩系统。内存压缩系统对于CPU、I/O设备、设备驱动以及应用软件来说是透明的,但是操作系统必须具有管理内存大小变化以及压缩比率变化的功能。
对于大多数的操作系统而言,要实现内存压缩,大部分体系结构都不需要改动。在标准的操作系统中,内存都是通过固定数目的物理页框(page frame)来描述的,由操作系统的VMM来管理。要支持内存压缩,OS要管理的实际内存大小和页框数目是基于内存的压缩比率来确定的。
这里的实现内存是指操作系统可的内存大小,它与物理内存的关系如下:假设PM是物理内存,RM(t)是系统在t时刻的实际内存,而CR(t)是压缩比率,在给定时刻t可支持的最大实际内存为RM(t)=CR1(t)×PM。然而,由于应用程序的数据压缩率是不依赖于OS而动态变化的,未压缩的数据可能会耗尽物理内存,因此当物理内存接近耗尽时,操作系统必须采取行动来解决这个问题。