不知道你有没有注意过,在亚马逊或者京东等电商平台的网站上都提供了准实时的产品分类销售排行榜。例如,以下就是亚马逊上销售排行榜和销售飙升榜的一个截图:
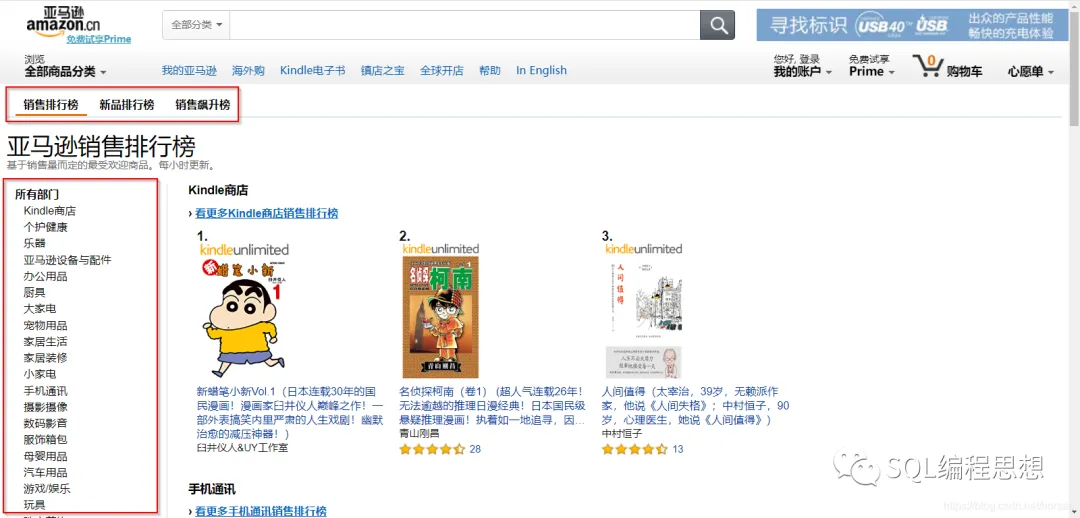
今天我们就来讨论一下如何使用 SQL 排名窗口函数和取值窗口函数实现这类功能。
本文使用的函数和示例经过以下数据库验证:MySQL、Oracle、SQL Server、PostgreSQL 以及 SQLite。它们支持的常用排名窗口函数和取值窗口函数如下:
窗口函数
描述
MySQL
Oracle
SQL Server
PostgreSQL
SQLite
ROW_NUMBER()
为分区中的每行数据分配一个从 1 开始的序列号。
✔️
✔️
✔️
✔️
✔️
RANK()
计算每行数据在分区中的名次,排名可能产生跳跃。
✔️
✔️
✔️
✔️
✔️
DENSE_RANK()
计算每行数据在分区中的名次,排名不会产生跳跃。
✔️
✔️
✔️
✔️
✔️
PERCENT_RANK()
计算每行数据在分区中的相对排名,取值为 (rank - 1) / (rows - 1)。
✔️
✔️
✔️
✔️
✔️
CUME_DIST()
计算每行数据在分区内的累积分布,取值范围大于 0 且小于等于 1。
✔️
✔️
✔️
✔️
✔️
NTILE()
将分区内的数据分为 N 等份,计算每行数据所在的位置。
✔️
✔️
✔️
✔️
✔️
FIRST_VALUE()
返回窗口内第一行对应的数据。
✔️
✔️
✔️
✔️
✔️
LAST_VALUE()
返回窗口内最后一行对应的数据。
✔️
✔️
✔️
✔️
✔️
LAG()
返回分区中在当前行之前第 N 行对应的数据。
✔️
✔️
✔️
✔️
✔️
LEAD()
返回分区中在当前行之后第 N 行对应的数据。
✔️
✔️
✔️
✔️
✔️
NTH_VALUE()
返回窗口内第 N 行对应的数据。
✔️
✔️
❌
✔️
✔️
示例表和数据
本文使用以下简化的示例表和数据(纯属虚拟,不代表实际销量):
复制
create table products(
product_id integer not null primary key,
product_name varchar(100) not null unique,
product_subcategory varchar(100) not null,
product_category varchar(100) not null
);
insert into products values(1, iPhone 11, 手机, 手机通讯);
insert into products values(2, HUAWEI P40, 手机, 手机通讯);
insert into products values(3, 小米10, 手机, 手机通讯);
insert into products values(4, OPPO Reno4, 手机, 手机通讯);
insert into products values(5, vivo Y70s, 手机, 手机通讯);
insert into products values(6, 海尔BCD-216STPT, 冰箱, 大家电);
insert into products values(7, 康佳BCD-155C2GBU, 冰箱, 大家电);
insert into products values(8, 容声BCD-529WD11HP, 冰箱, 大家电);
insert into products values(9, 美的BCD-213TM(E), 冰箱, 大家电);
insert into products values(10, 格力BCD-230WETCL, 冰箱, 大家电);
insert into products values(11, 格力KFR-35GW, 空调, 大家电);
insert into products values(12, 美的KFR-35GW, 空调, 大家电);
insert into products values(13, TCLKFRd-26GW, 空调, 大家电);
insert into products values(14, 奥克斯KFR-35GW, 空调, 大家电);
insert into products values(15, 海尔KFR-35GW, 空调, 大家电);
create table sales(
product_id integer not null,
sale_time timestamp not null,
quantity integer not null
);
insert into sales
with recursive s(product_id, sale_time, quantity) as (
select product_id, 2020-07-23 00:01:00, floor(10*rand(0)) from products
union all
select product_id, sale_time + interval 1 minute, floor(10*rand(0))
from s
where sale_time < 2020-07-23 10:00:00
)
select * from s;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.
其中,products 是产品表,包含产品编号、产品名称、产品子类和产品分类;sales 是销量表,按照不同产品每分钟统计一次销量,我们生成了 2020 年 7 月 23 日 0 点到 10 点之间的模拟数据。
按照产品分类的销售排行榜
对于销售排行榜,我们需要按照产品的分类,计算最近一小时的销量排名。假如用户是 2020 年 7 月 23 日 10 点多查看排行榜,可以使用以下语句获取不同分类下销量排名前 3 的产品:
复制
with hourly_sales(product_id, ymdh, quantity) as (
select product_id, date_format(sale_time, %Y%m%d%H), sum(quantity)
from sales
where sale_time between 2020-07-23 09:00:00 and 2020-07-23 09:59:00
group by product_id, date_format(sale_time, %Y%m%d%H)
),
hourly_rank as(
select product_category, product_subcategory, product_name, quantity,
rank() over (partition by ymdh, product_category order by quantity desc) as rk
from hourly_sales s
join products p on (p.product_id = s.product_id)
)
select *, repeat(🔥, 4- rk) as hotness
from hourly_rank
where rk <= 3
order by product_category, rk;
product_category|product_subcategory|product_name |quantity|rk|hotness|
----------------|-------------------|---------------|--------|--|-------|
大家电 |冰箱 |美的BCD-213TM(E)| 315| 1|🔥🔥🔥 |
大家电 |空调 |海尔KFR-35GW | 293| 2|🔥🔥 |
大家电 |冰箱 |康佳BCD-155C2GBU| 291| 3|🔥 |
手机通讯 |手机 |vivo Y70s | 298| 1|🔥🔥🔥 |
手机通讯 |手机 |HUAWEI P40 | 273| 2|🔥🔥 |
手机通讯 |手机 |iPhone 11 | 261| 3|🔥 |1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.
查询返回了按照产品分类“大家电”和“手机通讯”显示的 Top3 销量产品。该查询执行的过程如下:
首先,通用表表达式 hourly_sales 是不同产品按照小时统计的销量,我们只需要返回最新一小时的销量(2020-07-23 09:00:00 到 2020-07-23 09:59:00 之间);然后,通用表表达式 hourly_rank 是基于 hourly_sales 计算的销量排名;rank() 函数是一个排名窗口函数,over 子句表示按照小时和产品进行分区,并且按照销量从到到低进行排序;join 用于关联产品的信息;最后,查询 hourly_rank 并返回了每个产品分类中排名前 3 的产品,用于前端页面显示。
由于产品分类下面还存在子类,例如“大家电”可以分为“空调”和“冰箱”,我们可以进一步按照子类计算销售排行榜:
复制
with hourly_sales(product_id, ymdh, quantity) as (
select product_id, date_format(sale_time, %Y%m%d%H), sum(quantity)
from sales
where sale_time between 2020-07-23 09:00:00 and 2020-07-23 09:59:00
group by product_id, date_format(sale_time, %Y%m%d%H)
),
hourly_rank as(
select product_category, product_subcategory, product_name, quantity,
rank() over (partition by ymdh, product_category, product_subcategory order by quantity desc) as rk
from hourly_sales s
join products p on (p.product_id = s.product_id)
)
select *
from hourly_rank
where rk <= 3
order by product_category, product_subcategory, rk;
product_category|product_subcategory|product_name |quantity|rk|
----------------|-------------------|----------------|--------|--|
大家电 |冰箱 |美的BCD-213TM(E)| 315| 1|
大家电 |冰箱 |康佳BCD-155C2GBU| 291| 2|
大家电 |冰箱 |海尔BCD-216STPT | 259| 3|
大家电 |空调 |海尔KFR-35GW | 293| 1|
大家电 |空调 |格力KFR-35GW | 279| 2|
大家电 |空调 |美的KFR-35GW | 277| 3|
手机通讯 |手机 |vivo Y70s | 298| 1|
手机通讯 |手机 |HUAWEI P40 | 273| 2|
手机通讯 |手机 |iPhone 11 | 261| 3|1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.
该查询只修改了 rank() 函数 over 子句中的 partition by 分区选项,增加了 product_subcategory 字段。
除了 RANK() 函数之外,ROW_NUMBER() 和 DENSE_RANK() 函数也可以用于实现排名分析;它们的区别在于对排名相同的数据处理不同:
数据
ROW_NUMBER()
RANK()
DENSE_RANK()
99
1
1
1
66
2
2
2
66
3
2
2
33
4
4
3
ROW_NUMBER() 返回的是不重复的编号;RANK() 对于相同的数据返回相同的排名,后续排名产生了跳跃;DENSE_RANK() 对于相同的数据返回相同的排名,后续排名没有跳跃。
按照产品分类的销量飙升榜
销量飙升榜是指按照过去一段时间内销量名次的增长率进行排名,返回增长率最大的产品。
亚马逊是按照过去 24 小时之内的增长率进行计算,我们按照过去 1 小时之内的增长率进行排名。也就是说,如果用户在 2020 年 7 月 23 日 10 点多查看排行榜,使用 9 点到 10 点的销量排名和 8 点到 9 点的销量排名计算增长率:
复制
with hourly_sales(product_id, ymdh, quantity) as (
select product_id, date_format(sale_time, %y%m%d%H), sum(quantity)
from sales
where sale_time between 2020-07-23 08:00:00 and 2020-07-23 09:59:00
group by product_id, date_format(sale_time, %y%m%d%H)
),
hourly_rank as(
select ymdh, product_category, product_subcategory, product_name,
rank() over (partition by ymdh, product_category order by quantity desc) as rk
from hourly_sales s
join products p on (p.product_id = s.product_id)
),
rank_gain as(
select product_category, product_subcategory, product_name,
rk, lag(rk, 1) over (partition by product_category, product_name order by ymdh) pre_rk,
100 * (ifnull(lag(rk, 1) over (partition by product_category, product_name order by ymdh), 99999999) - rk)
/rk as gain
from hourly_rank
),
top_gain as(
select *, rank() over (partition by product_category order by gain desc) gain_rk
from rank_gain
where pre_rk is not null
)
select product_category, product_subcategory, product_name, pre_rk, rk, concat(gain,%) gain, gain_rk
from top_gain
where gain_rk <= 3
order by product_category, product_subcategory, gain desc;
product_category|product_subcategory|product_name |pre_rk|rk|gain |gain_rk|
----------------|-------------------|---------------|------|--|---------|-------|
大家电 |冰箱 |美的BCD-213TM(E)| 9| 1|800.0000%| 1|
大家电 |空调 |海尔KFR-35GW | 6| 2|200.0000%| 2|
大家电 |空调 |美的KFR-35GW | 10| 5|100.0000%| 3|
手机通讯 |手机 |vivo Y70s | 4| 1|300.0000%| 1|
手机通讯 |手机 |小米10 | 5| 5|0.0000% | 2|
手机通讯 |手机 |OPPO Reno4 | 3| 4|-25.0000%| 3|1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.
对于“大家电”类产品,“美的BCD-213TM(E)”冰箱的销量排名从第 9 名提高到第 1 名,增长率为 800%,排在第一名。
该查询执行的过程如下:
首先,hourly_sales 是不同产品按照小时统计的销量,包含了 2020-07-23 08:00:00 到 2020-07-23 09:59:00 之间两个小时的销量;然后,hourly_rank 是基于 hourly_sales 计算的销量排名;rank() 函数是一个排名窗口函数,over 子句表示按照小时和产品进行分区,并且按照销量从到到低进行排序;join 用于关联产品的信息;接着,rank_gain 是基于 hourly_rank 计算的产品排名变化情况;lag(rk, 1) 函数返回的是同一产品前一行(对于 9 点到 10 点而言就是 8 点到 9 点)的销量排名,并且基于该排名计算增长率(100 * (pre_rk - rk)/ rk);然后,top_gain 是基于 rank_gain 计算的不同分类中的产品增长率排名;这里我们再次使用了 rank() 函数;最后,查询 top_gain 并返回了每个产品分类中增长率排名前 3 的产品,用于前端页面显示。
以上示例中的 LAG(rk, 1) 函数也可以替换为 LEAD(rk ,-1)。另外,FIRST_VALUE()、LAST_VALUE() 以及 NTH_VALUE() 函数的作用比较明确,本文没有进行演示。
总结
我们以电商平台的销售排行榜和销售飙升榜为案例,介绍了一些常用的 SQL 排名窗口函数和取值窗口函数的使用。包括聚合窗口函数在内的窗口函数为我们提供了强大的数据分析功能,值得我们每个人学习并熟练掌握。