谈谈Google Falcon的可靠传输论文并对比分析CIPU eRDMA
TL;DR
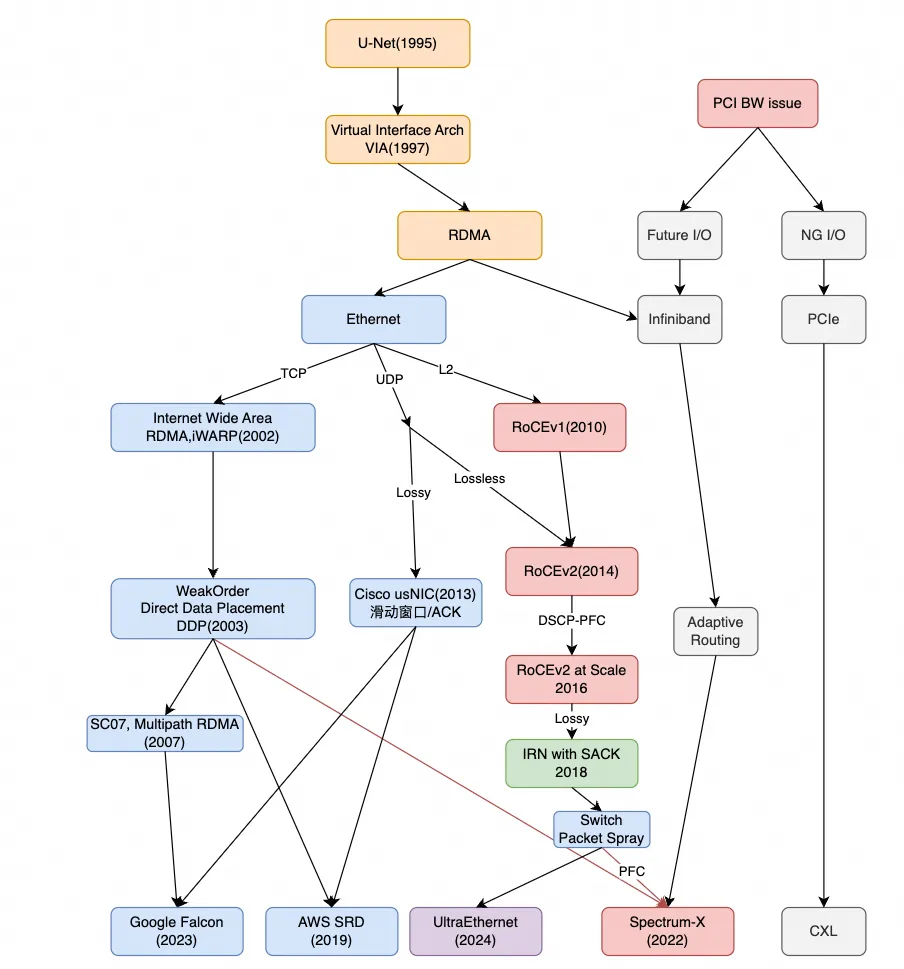
今年Sigcomm的会还没开, 但是所有论文就公开了. 抽空读一些记一些笔记吧. 今天要讲的这篇论文是Google 《Falcon: A Reliable, Low Latency Hardware Transport》[1]
对于Google Falcon是在2023年退出UEC后开源到OCP的. 其实里面也发生了很多故事:) 首先它是和Intel一起合作在Mt.Evans上开发的, Intel在2021年初就公布了Mt.Evans(IPU E2100), 规格为200Gbps, 但实际产品Launch的时间在2024年中, 基本上完美的错过了AI Infra这波建设. 中间发生了很多事情也间接的和Falcon有些关系, 后面会谈到.
相比于Google Falcon, CIPU eRDMA在200Gbps规格上2023年就完成了, 去年400Gbps的CIPU 2.0去年云栖大会发布后也上线了. 所以我一直说要自信一点, 中国人在一些局部的领域领先美国人是非常正常的一件事情. 别听NV说一些Marketing话术, 就觉得NV都是对的.例如Google Falcon其实也表示了根本不需要什么多轨道多平面标准的Jupiter组网即可解决问题.但是构建Lossy多路径并且IB RC verbs兼容的RDMA可靠传输是一个非常难的事情, 特别是在芯片PPA上兼顾更多的考虑, Google Falcon也有一些问题没做好, 我们后面会详细阐述.
另外, 我们是全球第一家在所有计算实例提供标准RDMA能力的云厂商, 并且从第8代通用计算实例开始就全地域全AZ部署, 如今eRDMA已经具有很大的部署规模, 而Google如今成为第二家. AWS SRD不算是因为它确实不兼容标准的RC Verbs.
0. Abstract
在论文的Abstract中, 首先肯定了RoCE的优势"high performance with minimal host CPU", Kernel bypass降低了CPU的负担, 但是"best suited to special-purpose deployments"表明了一个态度: RoCE 的高性能是建立在一个苛刻的假设之上的:网络是无损的(lossless).
在通用的以太网数据中心里,由于网络拥塞,丢包是常态.为了创造一个"无损"环境,RoCE 部署通常需要依赖PFC. 然而, PFC自身存在严重问题, 如队头阻塞(Head-of-Line Blocking)和死锁, 部署和调试非常复杂, 使其成为运维的噩梦.
因此,RoCE 往往被限制在专用的, 与通用网络隔离的后端网络(如存储网络,AI 训练集群网络)中.这句话为 Falcon 的出现设定了问题背景:如何打破 RoCE 的使用限制,使其走向通用?
然后作者阐述了一下Google Falcon, "We introduce Falcon, the first hardware transport that supports multiple Upper Layer Protocols (ULPs) and heterogeneous application workloads in general-purpose Ethernet datacenter environments (with losses and without special switch support)."
首先first hardware transport, 其实这件事情复杂度还挺高的, 也是间接的导致Mt.Evans从2021年宣布到2024年中才发布. 个人觉得一个完备的可靠传输层通过纯RTL硬件实现的复杂度很高, 并且一旦有bug修改起来也很难.
然后谈到了general-purpose Ethernet datacenter environments, 这一点和我们在23年初设计eRDMA多路径算法时的初衷是一样的, 从云的角度来看, 直接部署在任何标准的,大规模的以太网基础设施上,极大地降低了部署和运维成本,提升了通用性. 因此我们都是期望不依赖PFC, 不依赖任何交换机的特殊功能, 例如Adaptive Routing/Packet Spray, 甚至也不需要依赖INT这些Telemetry功能.
然后就是支持"multiple Upper Layer Protocols (ULPs) and heterogeneous application workloads", 实际上这也是云上IPU的一个需求, 希望使用一个统一的可靠传输协议来承接RDMA/存储/TCP加速(例如ENA-Express)以及其他各种workload.
然后作者列出了具体的几个技术支柱:
delay-based congestion control with multipath load balancing: Falcon主要就是依赖以前Timely, Swift这样的工作. 然后在这个基础上依赖于PLB这些算法扩展到多路径的场景. 其实我在2023年设计eRDMA多路径算法的时候, 也是同样的思路, 因为以前在思科的时候, 2011年就在做一些Delay based telemetry分析TCP传输质量的工作, 当时也有商用的产品AVC(Application Visibility Control), 其中Application Response Time (ART) metrics的工作原理和Swift是一致. 因此个人偏好上也喜欢用delay-based CC.a layered design with a simple request-response transaction interface : 实质上是把多种ULP和可靠传输解耦合. 把上层的RDMA/Nvme等语义映射到一个简单的Push/Pull模型. 避免了为每一个协议设计一套可靠传输的复杂性.hardware-based retransmissions and error-handling for scalability: Google的想法是传统的硬件传输协议在遇到丢包等异常时,往往需要固件甚至主机软件介入,导致性能急剧下降, 然后Falcon就把SACK等快速包恢复以及错误处理的逻辑直接在硬件中实现了, 保证数据路径的高效运行.a programmable engine for flexibility: 对于拥塞控制等算法策略可以通过引入的可编程引擎处理, 和前一点一起平衡了硬件性能和软件的灵活性.个人觉得通过硬件完全实现可靠传输协议这一点是不恰当的, 而且这也是很大程度上导致IPU E2100从21年发布到24年才GA的一个很重要的原因, 纯硬件做可靠传输复杂性太高.
1. Introduction
首先介绍了现代数据中心的工作负载对网络性能提出了极高的要求. 像高性能计算(HPC),横向扩展的 AI/ML,以及实时分析等应用,都需要高带宽和低延迟的传输.现代存储系统需要高读写操作速率,以充分利用高性能 SSD 设备的潜力.并且,网络协议栈必须在提供这种高性能的同时,消耗最少的主机CPU,以便 CPU 资源可以被应用程序使用.
然后硬件加速的传输协议,其传输数据路径在硬件中实现,能够满足这些严苛的要求,而这正是软件实现的传输协议所无法做到的.通过利用专用的硬件资源,这些传输协议可以同时提供高带宽和高操作速率,并在不产生显著 CPU 核心占用的情况下保持低延迟. 然后Google开篇对比了Falcon和他们软件实现的Pony Express的性能区别
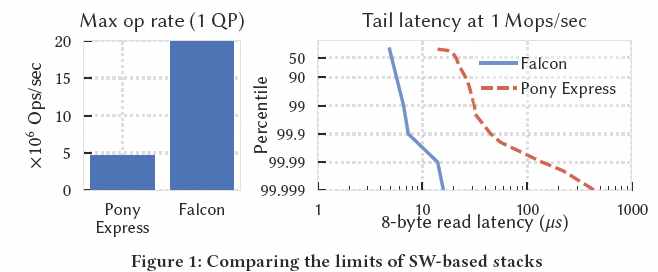 图片
图片
实质性的问题是在谈论RDMA这样的协议栈带来的Kernel bypass的收益. 此时作者给出了他们的目标:
开发一种传输协议,它既能结合硬件加速的性能,又具备软件传输协议的通用性,能够在多样的网络条件下支持异构的工作负载.我们设想的使用场景是,一个基于商用以太网的数据中心网络,连接着任意组合的计算服务器,存储和加速器, 并通过行业标准接口(如 IB Verbs 和 NVMe)支持混合工作负载.
这个目标是非常清晰的, 首先是在一个商用以太网的数据中心网络, 很简单的一个逻辑, 特别是对于云而言就是期望统一的非定制的一个网络把所有的算力和存储连接起来. 然后第二点很关键行业标准接口, 其实AWS SRD就是在这一点上犯了错(第二个犯错的是UEC). 对于一个云服务提供商, 特别是IaaS提供标准接口是非常重要的, 非标接口会对软件生态带来极大的麻烦. 所以CIPU eRDMA从第一天起就支持标准的IB RC Verbs, 保证客户在线下机房Mellanox上跑的好的应用不修改就能平滑迁移到云上.
那么直接把RoCE迁移上云确实不行的, 论文中讲了, RoCE 相比于通用数据中心用途, 更适合专用的场景.RoCE 源于 Infiniband 网络上的 RDMA, 它假设丢包不频繁.它通常与PFC一起使用,但 PFC 是一个部署上充满挑战的复杂功能. 在没有 PFC 的情况下,RoCE 通常部署在具有专用交换机(例如,Spectrum-X 自适应路由, 实际上还是开着PFC的), 这限制了它只能用于专用的后端网络. 而像 NVLink 和 ICI 这样的技术为 GPU 和 TPU 流量提供了专用的硬件传输, 但它们构成了难以扩展的"高性能孤岛",且不适用于通用工作负载.
实际上,在云的VPC环境中PFC是无法打开的, 另一方面云要求大量的业务自服务能力, 并不会针对客户的workload去做特殊的配置和调整, 更多的是提供一种通用的做法来适用通用工作负载.
此外, 在可靠性, 拥塞控制和多路径等方面的创新上, 硬件传输协议也落后于软件传输协议. 然后Google本身在软件上已经有成熟的Swift/RACK-TLP拥塞控制和丢包快速恢复, 以及PLB/PRR等多路径支持能力.
最后作者谈了一下主要贡献: 第一个在通用以太网数据中心环境中支持多种上层协议(ULP)和异构应用工作负载的硬件传输协议.Falcon 在完全由硬件实现的数据路径上,在多样的网络条件下(包括丢包,乱序和路径多样性)提供了卓越的性能.它不需要像 PFC 或自适应路由这样的专用交换机功能.并且,它在专用工作负载(如 ML 流量)和通用工作负载(如服务器 incast)上都表现出色.
其实首个算不上, 我们CIPU eRDMA都商用了好多年了, 并且在Falcon出来之前, 阿里云是唯一一个在全球全地域所有通用计算实例提供RDMA服务的云服务提供商.
主要的一些设计选择如下图所示:
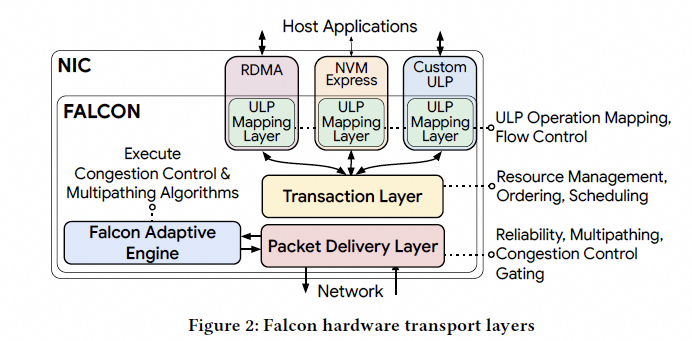 图片
图片
最后, 给出了一些Overview的性能对比: Falcon 为 RDMA 和 NVMe 应用提供了 120 Mops/sec 的峰值性能和接近最优的操作完成时间,即使在网络拥塞下也是如此.与 CX-7 RoCE 相比,在Lossy条件下,Falcon 的完成时间最多可降低 8 倍,有效吞吐量最多可提高 65%.
2. 现有硬件传输协议的不足及业务需求
2.1 业务需求
这一章写的很好, 详细阐述了现有RoCE协议的不足以及为什么无法满足业务的需求. 这一部分是论文的方法论基础.作者没有直接开始介绍 Falcon 的设计,而是首先定义了 "一个好的数据中心硬件传输协议应该是什么样的" .这五个需求(R1-R5)构成了一个评估框架,既可以用来审视现有技术的不足,也可以用来指导 Falcon 的设计.
R1:可预测的性能 (Predictable Performance): 确保网络传输的完成时间接近最优, 强调的不是平均性能,而是可预测性和接近最优. 在大规模分布式系统中,长尾影响更加重要, 因此稳定且接近理论最优的性能比时快时慢的平均高性能更有价值.R2对多样化网络的适应性 (Adaptability to Diverse Networks):在各种网络部署中保持可预测的性能,包括那些存在超售(oversubscription),多租户(multi-tenancy)和异构拓扑(heterogeneous topologies)的网络.其实这一点非常重要, 超售代表了实际的网络需求大于供应, 必定会出现拥塞, 而多租户需要避免不同用户之间的流量干扰, 异构拓扑代表了网络结构的不规则特性. 一个好的协议必须能在这种"脏乱差"的环境中生存并表现良好,而不是只能在实验室的"无菌"环境中工作(说你呢Lossless). 所以其实工业界如今ScaleOut和FrontEnd两张网络分离的根本原因也在此.
R3压力下的鲁棒性 (Robustness under stress): : 在高带宽, 高Message OP/s的情况下, 又要应对大量的QPs, 同时要针对乱序/丢包/拥塞/网络抖动等多种极端场景下, 要保证性能. 这对协议本身的资源管理/错误处理/恢复能力的要求很高.R4兼容性: 支持 IB Verbs 和 NVMe 接口,而无需修改应用程序.保持与为这些接口优化的现有应用生态系统的兼容性至关重要.这是一个非常务实的需求.一个技术无论多先进,如果需要推倒重来,改变整个应用生态,其推广难度都将是巨大的.支持现有的 IB Verbs (RDMA 的标准 API) 和 NVMe 意味着可以无缝地迁移大量现有的 HPC, AI, 和存储应用,极大地降低了用户的采纳成本. AWS SRD就是一个反例, 因此我们在做eRDMA的时候, 第一点就是要保证IB RC Verbs兼容.
R5易于运维: 许在无需更换新硬件的情况下,修复性能问题和演进传输协议的组件. 硬件投资巨大,生命周期长.如果协议的任何一点小缺陷或优化都需要通过更换硬件来解决,那么成本将是无法接受的.这个需求直指硬件设计的最大痛点——僵化(inflexibility), 并为后文引入可编程引擎(FAE)埋下了伏"笔.但实际上, 完全硬件的SACK这些机制, 也带来了极大的复杂性, 本来IPU E2100在2021年就能发布的, 却因为硬件上的问题延误了3年到2024年才上线, 中间错过了大模型这一波基础建设高潮, 被迫只能提供一个800G的H100, 和使用GPUDirect-TCPX替代.
实际上这些业务需求,可以看看我一直在讲的, 和Google这几个需求是完全一致的. Google这一次在验证环节也强调Live Migration这些虚拟化相关的内容.
2.2 RoCEv2的缺陷
占主导地位的硬件传输协议 RoCE,在满足这些需求方面举步维艰.RoCE 支持 IB Verbs 接口(但不支持 NVMe,违反了 R4),但它在处理丢包和乱序数据包以实现高应用性能方面效率低下(违反了 R1-R3).从根本上说,RoCE 从 RDMA-over-Infiniband 的无损特性中继承了三个关键限制,这些限制使其无法很好地扩展到有损网络.
RoCE 不支持现代化的丢包恢复. RoCE 最初依赖 Go-Back-N 的丢包恢复, 即使只是单个数据包丢失. 虽然现在启用了选择性重传(Selective Repeat, SR), 但有很大限制. SR 仅支持 RDMA Write 和 Read Response, 而其他操作仍然受限于 Go-Back-N 恢复. SR 机制为每个乱序包发送一个NACK, 这可能导致恢复缓慢且不精确, 并产生高尾延迟. 而且在使用 SR 时, 丢包通常会导致乱序包交付, 这违反了 IB Verbs 的语义.在 RoCE 中添加像SACK这样最先进的丢包恢复机制, 同时又要满足 IB Verbs 的保序语义, 并非易事. RoCE NIC 缺乏像数据包缓冲区这样的资源. 为了维持顺序, RoCE 接收端在发生丢包后会丢弃所有乱序到达的数据包. 这限制了它向发送端精确指示丢失了哪些数据包的能力. 为了实现像 SACK 这样的精确丢包信令, RoCE NIC 将需要进行重大更改, 例如在接收端增加片上数据包缓冲区或修改保序语义. 因此, 在许多用例中, 仍然需要PFC来避免丢包.
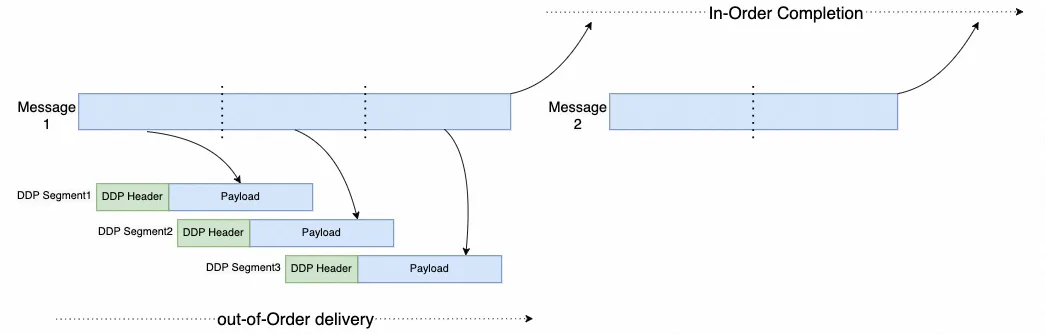
实质性的问题就是一个weakorder语义, 增加outstanding能够解决的, 也就是iWARP在20年前就支持Direct Data Placement. 在消息语义严格保序的基础上, 消息内允许outstanding乱序发送. 也就是out-of-order data delivery, in order message completion的原则.
RoCE 没有对多路径的协议级支持.当它与交换机上的自适应路由(Adaptive Routing)一起使用以利用所有网络路径时(这在 ML 后端网络中很常见), 这会引发并发症. 容忍多路径带来的自然乱序会对丢包恢复产生负面影响, 导致性能不佳, 因此通常使用 PFC 来避免丢包. 乱序的数据包也会被乱序交付, 这对于通用用途是有问题的, 因为它违反了 IB Verbs 的语义.多路径必然会导致乱序, 而传统Lossless的丢包检测机制和严格保序的语义自然在这种情况下产生了问题, 这也是Nvidia Spectrum-X解决方案要重新回到Lossless的根本原因.
RoCE 没有将拥塞控制与数据路径集成. 它的拥塞控制是作为一个附加组件实现的, 依赖于带外探测(out-of-band probes)来收集拥塞信号. 这种分离使其拥塞响应迟缓.从ZTR-CC开始, Nvidia就在尝试用带外信号来探测拥塞, 但是信号处理相对缓慢, 所以拥塞控制并不好. 然后近期的CX8通过PSA以及Spectrum-X的把Telemetry处理能力提高了1000x, 但事实上更频繁的带外周期行probe不光和数据路径分离, 还会很多的资源.
RoCE NIC 在固件中处理超时,错误和异常.这使其在压力下容易出现性能骤降, 无法满足 R3 的要求. 在第 6 章展示了RoCE 在丢包, 乱序和网络拥塞下的性能.这一大段是本章的核心,它使用前面定义的 R1-R5 框架, 对当前市场主导者 RoCE 进行了系统性的批判. 作者从 RoCE 的"基因缺陷"(源于无损 Infiniband)出发, 剖析了其三大根本性限制.
根本缺陷一: 落后的丢包恢复机制
Go-Back-N的效率就不用多说了, 对于丢包率的容忍情况可以通过下面这个公式计算出来
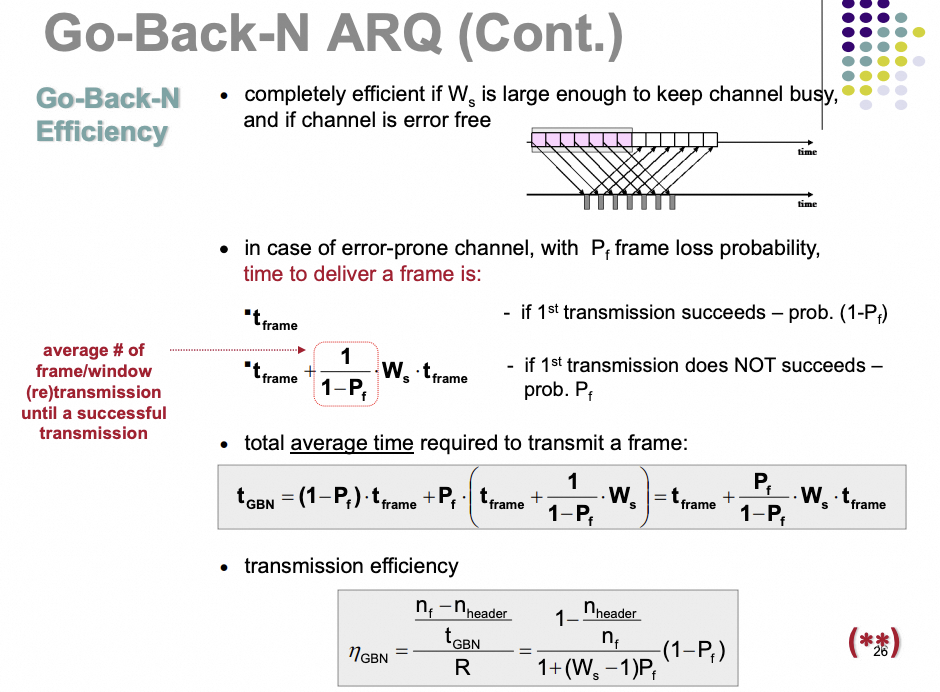 图片
图片
而对于Selective-Repeat, 虽然是对 GBN 的改进,但作者指出其限制重重:
非通用: 并非所有 RDMA 操作都支持,存在功能残缺.低效: 基于 NACK 的机制可能导致恢复缓慢.违反语义: 丢包后可能导致数据乱序交付给上层,这对于要求严格有序的 IB Verbs 是不可接受的.但是为什么不用SACK呢?
根本缺陷二: 协议层面不支持多路径.
多路径是提升网络利用率和鲁棒性的关键技术. 但 RoCE 协议本身并没有为多路径设计. 当与交换机的自适应路由等功能配合使用时, 不同路径的延迟差异会导致数据包到达顺序混乱. 乱序对 RoCE 是致命的. 如前所述, RoCE 的丢包恢复机制对乱序非常敏感, 很容易将乱序误判为丢包,从而触发不必要的重传,导致性能急剧下降.
为了解决这个问题,实际部署中往往只能再次求助于 PFC, 用 PFC 的暂停机制来掩盖路径延迟差异, 但这又回到了 PFC 自身的问题上. 这形成了一个恶性循环.
根本缺陷三: 拥塞控制与数据路径分离.
RoCE 的拥塞控制(如 DCQCN)更像是一个"外挂". 它需要通过发送专门的探测包来测量拥塞, 而不是像 TCP 或 Falcon 那样, 在每个数据包和 ACK 中都携带拥塞信号(in-band signaling). 带外探测(out-of-band) 的问题是响应迟缓. 当拥塞发生时, 它需要等待下一个探测周期才能感知到,这在瞬息万变的数据中心网络中可能已经太晚了. 而 Falcon 的带内(in-band) 方式可以做到逐包级别的快速响应.
其实这就是最关键的一点, 通过像Swfit那样直接带内的timestamp, 四个时间戳测量非常的容易, 纯硬件也可以做到非常高的性能.
3. 概述及设计原则
作者在第三章针对前一章的需求提出了一些设计原则:
需求R1-R2 确保系统能够有很好的端到端的应用性能. 需求R3-R5则是指导硬件如何实现高性能并与现有生态接口兼容.
3.1 Falcon Overview
Falcon 是一个面向连接的传输协议, 为各种上层协议(ULP)如 RDMA 和 NVMe 提供端到端的可靠传输, Falcon 由四个组件构成:
ULP 映射层: 将上层协议的操作(如 RDMA 读和写)翻译成 Falcon 连接, 并处理流控.事务层(TL): 为上层协议提供一个请求-响应接口,管理 NIC 上的资源, 进行调度和排序.包交付层(PDL): 执行基于延迟的拥塞控制(CC),通过时间轮(Timing Wheel)进行流量整形, 并使用 SACK 确保在多路径连接上的快速丢包恢复.可编程的 Falcon 自适应引擎(FAE): 与 PDL 协同工作, 以实现 CC 和多路径负载均衡. 这种可编程性使得在保持高速性能的同时, 能够在部署中进行适应性调整.加密 : Falcon还可以和PSP及IPSec这样的协议来对连接上传输的数据进行认证和加密.然后和原来软件的Pony Express进行了一些比较. 应用程序不直接与 Falcon 交互, 而是使用由 RDMA 和 NVMe 等 ULP 提供的标准 API. 这些 ULP 通过一个请求-响应的事务接口与 Falcon 通信, 并进行必要的适配, 以将其操作映射到 Falcon 事务上.然后Falcon的分层设计也继承和发展了Pony Express在软件领域被验证过的成功架构.
Falcon 的事务层和包交付层类似于 Pony Express 的Op层和Reliability层.但是不同是Pony Express 依赖 ULP 进行排序, 并在其Op层中进行分片; 而 Falcon 的事务层负责管理 ULP 操作的排序, 分片则由 ULP 自己处理.3.2 在多样化的网络中实现可预测的性能
文章阐述了一些其它工作并不能提供可预测的网络性能. 例如Homa/NDP/EQDS/pHost这样的reciever driven的方案假设了网络上不存在Oversubscription, 这通常是不成立的. 而且通常我们需要一个带收敛比的网络来降低成本. 而Packet-Spray 需要相对同构的网络架构做负载均衡, 在数据中心内基于CLOS拓扑的对称性是可行的, 但是有些时候需要跨越广域网时也会存在问题.
所以作者给出了第一个设计原则:
D1. 基于延迟的拥塞控制和多路径负载均衡: 这些思想来自于软件传输协议(Pony Express/TCP), 它们的设计和生产经验为 Falcon 提供了信息 .基于延迟的拥塞控制(Swift)利用硬件辅助的逐包往返时间(RTT)测量来调整传输速率. 多个硬件/软件时间戳将延迟分解到主机, NIC 和网络交换矩阵中, 这使得拥塞响应快速而精确. 基于延迟的 CC 还能缓解终端主机/NIC 内部的拥塞, 如 PCIe 和内存总线拥塞. 此外,通过时间轮(Carousel)进行的细粒度流量整形改善了租户间的公平性, 并在高度拥塞(当流的数量超过带宽延迟积时)下缩短了网络队列.
其实这也是我在设计eRDMA多路径拥塞控制算法时优先考虑的, 因为以前在思科(2012年)做Application Response Time Telemetry Metric这些工作时, 通过四个时间戳分段来了解拥塞状况已经是非常成熟的技术了, 在Swift出现时就对它利用这些延迟统计直接用作拥塞控制非常认同. 因此CIPU eRDMA多路径算法的基础也是借鉴了swift.
然后时Google的多路径负载均衡,在软件传输协议上, 每个连接使用了多个流(subflow), 每个流可以穿越不同的网络路径.每个流的速率根据路径拥塞动态调整,因此拥塞较少的路径会从连接中吸引更多流量.这种"实时(just-in-time)"调度,结合流重路由(Protective Load Balancing,PLB)将流量从拥塞路径移开,最小化了端到端延迟.单个流使用 Protective Reroute, PRR 来减轻网络中断的影响.当检测到中断时,它们会更改数据包上的 IPv6 流标签,使交换机选择不同的网络路径.
其实这一点上我在做eRDMA多路径拥塞控制算法时并没有这么做, 采用Falcon这样的做法对于网络拥塞抖动和失效等多种情况下的调整会非常麻烦. 拥塞时PLB和子路径的调整速率和链路故障时PRR切换, 会使得网络的收敛在毫秒级甚至秒级. 同时每个subflow的速率独立控制, 在超大规模组网时, 全局数万张网卡要收敛到一个均匀的状态, 可能耗费的时间更长, PLB实际的效果并没有那么好.
注: 这一点上是eRDMA做的比Google Falcon更好更简单的处理方式, 因为我们可以做到更大规模的subflow, 每个subflow是完全无状态的, 同时还能够满足微秒级的拥塞感知切换.
为了获得最佳的应用性能,丢包恢复需要在多路径负载均衡固有的包乱序情况下高效工作.Falcon 利用选择性确认(SACK)来高效地仅重传丢失的数据包. 并且进一步为 Falcon 的硬件适配了 RACK-TLP, 因为基于时间的区分丢包和乱序可以加速恢复, 尤其是在数据突发末尾发生丢包时.
同样在eRDMA多路径算法时, 也默认采用了SACK的方式, 其中一个很关键的问题是如何在接收窗口中区分乱序和丢包. 其实有一个非常简单的算法估计即可, 然后配合RACK进行快速恢复. 当然我们一开始没有在软件上实现TLP, 在测试过程中因为一条链路光纤有损的情况下触发了应用层NCCL的一个偶发性长尾, 最后加上TLP就好了.
3.3 硬件设计: 挑战和原则
构建像Falcon这样的硬件传输协议面临几个挑战.
必须同时为 HPC 和 AI/ML 应用提供高峰值性能,并在超大规模数据中心部署中提供可预测的持续性能.不仅是要在数据包完美有序到达的快速路径上, 还需要在产生产生乱序包,重传,超时和应用错误条件的网络条件下, 实现峰值操作速率/带宽和低延迟. 因为这些复杂情况在生产网络中非常常见.避免在O(100K)连接数下出现性能陡降的情况, 持续维持高性能也非常重要. 这些挑战需要仔细考虑片上空间,缓冲区,功耗等硬件限制,并涉及解决连接缓存未命中等瓶颈问题,以及在硬件中高效处理异常/错误. 硬件实现必须在 NIC 预先确定的资源内优化资源利用和性能.因此基于这些挑战, 作者列出了使 Falcon 高性能硬件实现成为可能的设计原则:
D2. 分层设计: 在 Falcon 和 ULP 之间做了清晰的职责划分,旨在减少 ULP 之间的功能重复. 这种方法通过将核心传输功能集中在 Falcon 内部,降低了 NIC 硬件的复杂性. Falcon 的事务层和包交付层之间的划分进一步细分了职责, 以便独立实现和演进.
D3. 支持多 ULP 的简单接口: Falcon 的多 ULP 支持是通过一个简单的事务接口实现的,其中每个事务由一个请求和相应的响应组成. 这与常见的 ULP 操作非常吻合. 这种设计便于添加新的 ULP, 包括那些具有自定义保序模式和错误通知要求的 ULP.
D4. 带有反压和错误处理的 NIC 硬件资源准入: 一个指导原则是消除由乱序网络包和错误条件引起的性能陡降. 为此, Falcon 利用专用的片上内存和基于硬件的重传机制, 支持 IB Verbs 的保序语义. Falcon 接收端使用其基于BDP大小的片上数据包缓冲区来吸收乱序包. 它向发送端指示丢失的包, 发送端则执行精确的重传, Falcon 能够为所有 IB Verbs 操作做到这一点而无需违反其语义. 逐连接的反压机制提供了连接间的隔离, 并保持了较低的 NIC 资源占用率. Falcon 通过在硬件中实现异常处理, 进一步避免了各种错误场景引起的性能抖降. 将 Falcon IP 集成到 NIC 中的成本很小: 在芯片尺寸方面占 5-6%, 在功耗方面占 3-4%.
其实Nvidia在CX7中虽然实现了AdaptiveRouting这样的功能, 但是其Out-of-Order delivery是无法支持SEND/RECV的. 这是RoCE协议的缺陷.
Falcon协议中定义了一个扩展的Offset Extended Transport Header(OETH)支持了Message Offset字段才行. 而eRDMA直接使用了iwarp中的direct-data-placement(DDP)的Message Offset字段. 下面这图是关键啊, 敲黑板!
另一方面文中所谈的芯片尺寸和功耗方面的占比实际上是偏低的, FAE的软件应该运行在了IPU E2100的ARM Core上, 而ARM这部分本来就非常占用Die面积, 一方面软件的开销没计算进来, buffer的开销还有本来diesize偏大功耗偏高的情况下这个占比数据是偏低的
D5. 硬件辅助的可编程引擎: 这是一个指导原则, 通过将算法与数据路径解耦, 来实现在软件中对拥塞控制和其他传输功能进行快速迭代. 为了避免硬件的复杂性和不灵活性, Falcon设计将传输功能的管理(实现为一个运行在通用 CPU 上的可编程引擎软件)与机制(在硬件路径中实现)分开.
软硬件接口和功能划分如下所示:
4. 详细设计
这一章详细介绍了Falcon的各个组件, 第一节介绍了PDL和FAE共同确保了可靠性. 第二节介绍了拥塞控制, 第三节介绍了多路径. 第四届介绍了事务层(TL)如何支持多种ULP, 第五节介绍了资源管理, 第六节介绍了连接隔离.
4.1 可靠性
Falcon确保了ULP Payload从发送到接收的端到端可靠性, 其主要目标是在不产生过多重传的情况下, 从丢包中快速恢复, 无论网络条件是乱序还是丢包.
与 Pony Express 类似,Falcon 的接收端使用bitmaps向发送端精确地传达已接收和丢失的数据包. 选择bitmap而不是 TCP 的可变长度选择性确认(SACK)块, 是为了便于硬件处理. 与 TCP 类似, Falcon 采用 RACK-TLP来区分丢包和乱序, 并从传输突发的末尾丢包中快速恢复.
其实对于Lossy的SACK通常一个极端的测试例是在5%随机丢包的场景下, 实际有效传输率(Goodput)能做到多高, Go-back-N即便是在1%的情况下就已经不可用了, 而SR也好不到哪儿去,大量的错误重传. 而Google Falcon和CIPU eRDMA均可以支持到接近90%的极限. 做到这个水平才能算把可靠性做过关了.
另一个是关于用TCP的Seq或者bitmap的方式来做SACK, 我觉得是架构师的偏好, 硬件实现的情况下, 通常会选择bitmap, 工业界做了很多年了并不稀奇. 但是当你需要兼顾长传路径, 特别是跨越地理上更长距离的长传, 链路上inflight的bytes会更多, 最终导致这个bitmap无法cover限制了最大窗口, 然后Google Falcon允许接收在bitmap-RX-Window之外的报文, 这样会带来一些复杂性,
发送端和接收端的PDL实现如下, 其实就是在谈SACK/RACK-TLP的实现.
接收端 (RX) : 接收端的 PDL 通过一个基于bitmap的接收窗口来跟踪数据包序列号(PSN). 这个bitmap在发出的 Falcon ACK 上会携带. 它帮助发送端识别丢失的数据包并触发重传. bitmap的大小在硬件实现的可行性和 ACK 开销之间取得了平衡; 128-bit的bitmap在Google用例中效果很好. 只要有足够的片上 NIC 资源, 接收端就会接受乱序数据包, 即使是那些在接收窗口之外的数据包.
发送端 (TX): 收到 ACK 后, 发送端采用RACK启发式算法来识别需要重传的数据包. 它分析 ACK 的时间戳和附带的 Rx bitmap,具体过程如下:
被标记为已收到的数据包直接忽略.在时间 之后传输的未确认数据包也会被忽略, 以确保 RACK 在经过足够的时间(约一个 RTT)之前不会触发重传.在之前发送的数据包, 如果其经过的时间超过了 rack_rto 时长, 就会被重传.这个启发式算法仅适用于 Rx bitmap范围内的数据包, 因为超出该范围的数据包的接收状态对发送端是未知的.
这个地方有点意思, 就像前面说的, 128bit RX-Window按照MTU8192计算也就1MB的窗口, 例如针对一个800Gbps 2ms的链路, inflight-window为也有200MB, 1MB的RX-Window要多次绕回, 感觉在这样的长传路径上, 128bit可能还是有点问题的...
因此在eRDMA中, 我们还是倾向于选择基于Seq的SACK方式来处理.
发送端TLP: 为了处理尾部丢失(tail losses), 发送端还使用TLP启发式算法. 在一段时间没有活动后(例如,由于尾部丢包或 ACK 丢失), 发送端会重传一个探测包, 包含序号最低的未确认PSN .这个探测会促使接收端生成一个 ACK. 收到这个 ACK 后, 发送端使用 RACK 启发式算法来触发必要的早期重传.
然后是FAE的功能: 它根据网络状况计算丢包恢复参数(例如, 重传和 TLP 的超时时间). 这使得 Falcon 能够根据各种网络场景调整恢复的激进程度.
对于软硬件协同上, 体现了"机制与策略分离"的思想:
硬件 (PDL): 负责执行 RACK-TLP 的机制, 比如时间戳比较, bitmap解析.软件 (FAE): 负责制定策略, 比如根据当前网络 RTT 和抖动情况, 动态计算出最优的 rack_rto 和 TLP 超时时间. 这使得丢包恢复的"灵敏度"可以自适应调整, 在网络稳定时减少误判, 在网络剧烈抖动时又能快速响应.RACK的机制其实很好的区分了乱序和丢包, 实际上是在发送窗口内, 区分了一段乱序容忍窗口和真实丢包窗口.
4.2 可编程拥塞控制
Falcon 通过在 PDL 和 FAE 之间划分职责来为每个连接实现拥塞控制.
FAE 实现 CC 算法, 根据 CC 信号计算拥塞窗口PDL 负责测量 CC 信号, 并通过连接调度器和时间轮来执行计算出的窗口.这种分工允许 CC 算法通过可编程的 FAE 进行演进, 而无需改变高效实现关键逐包操作的 PDL.
Falcon 的 CC 算法是 Swift的一个变体, 通过 fcwnd(网络拥塞窗口)和 ncwnd(NIC 拥塞窗口) 来处理网络拥塞和 NIC 拥塞, 有效窗口是两者的最小值.
处理网络拥塞 (Fabric Congestion) : 使用网络延迟作为拥塞信号. 为了精确估算网络延迟, Falcon 依赖于精确的硬件时间戳. t1 是数据包在物理线路上发送的时间, 并携带在包头中. t2是数据包到达远程 NIC 的时间. 远程 NIC 存储连接的最新t1和t2. t3是远程 NIC 发送 ACK 的时间, t4是 ACK 到达本地 NIC 的时间. ACK 头携带t3以及最新的t1 和t2值.
因此本地 PDL 可以按照如下方式计算, 且无需时钟同步.
处理接收端 NIC 拥塞 (Rx NIC Congestion): Falcon CC 明确地处理 NIC 内部流水线拥塞, 特别是 Rx 缓冲区, 它可能在两种情况下耗尽:
有序连接在经历丢包后会缓存乱序数据包, 这会在等待丢失包重传期间导致缓冲区堆积.接收端的主机侧瓶颈(PCIe, IOMMU 或内存)可能导致 NIC 的主机接口反压 ULP, ULP 进而反压 Falcon. 这导致缓冲区堆积, 直到从网络接收的数据包可以被转发给 ULP.Falcon 使用 NIC Rx 缓冲区占用率硬件计数器作为 NIC 拥塞信号. ACK 将此信号带回给发送端, 发送端用它来调整 ncwnd. 这可以防止因缺少 NIC Rx 资源而导致过多的数据包被丢弃.
Swift的设计确实是非常巧妙的, 在CIPU 1.0刚发布支持eRDMA时就采用了基于Swift RTT算法的CC, 同时需要注意的是fcwnd和ncwnd两个必不可少. 然后呢, CIPU在多路径的版本上做了一个更好玩的事情~
另外还有一个思考题: 为什么RoCE无法支持Window-Based拥塞控制? 主要有两点协议上的缺陷:
数据包和ack报文单独发送,数据包里面没有携带ack信息Read resp报文是用ack报文封装,实质是数据包,而read resp并没有对应的ack如果采用window based拥塞控制,需要ack来驱动,read场景就会导致read resp直接发不出去了,解法只能变成使用定时器加token,又变成rate based了.
4.3 多路径
多路径是 Falcon 的一个核心设计元素, 它通过允许单个连接使用多条路径来实现高单连接性能. 设计关键是以拥塞感知的方式使用这些路径: 偏向于拥塞较少的路径可以降低操作延迟并维持更高的吞吐量. Falcon 的目标是将每个数据包在通往目的地的最佳路径上传输. 这个目标需要两个决策: 为连接选择一组路径, 以及为每个数据包分配一条特定路径. 这两个决策都天然适合由 PDL 来做, 使其将多路径机制与上层隔离开来.
如图所示, Falcon 为每个连接维护一个带索引的流(flow)列表. 每个流被分配一个唯一的 IPv6 Flow Label, 并设置在流的出向数据包上. 这个Flow Label还包含流的索引, 以便于跟踪每个流的状态. 交换机在 ECMP/WCMP 4元组之外, 还会对流标签进行哈希, 因此每个流可以映射到一条可能不同的网络路径.
eRDMA采用了两种方式增加报文转发的信息熵, 一种方式是在VPC部署的时候, 直接利用VPC underlay的源UDP端口作为subflow的Label, 这样中间的交换机无需任何修改, 按照原有的ECMP工作即可. 另一种方式就是在Underlay部署时, 和Google相同的方式采用IPv6 Flow Label, 但此时交换机需要支持可定义的Hash计算能力.
尽管所有流共享连接的 PSN 空间, Falcon 会为每个独立的流跟踪拥塞状态并计算一个专用的 fcwnd. PDL 的工作是:
执行一个通过聚合各流 fcwnd 值计算出的连接级 fcwnd基于各流级的 fcwnd 值将数据包映射到流. 这个设计体现了一个经典的"精度-复杂度"权衡.通常多路径算法和拥塞控制存在两个极端调度的case:
PDL 可以简单地将数据包喷洒到各个流上, 不考虑每个流的拥塞, 这需要更简单的硬件.为每个流都使用独立的 PSN 空间并执行 fcwnd, 这会引入额外的硬件复杂性. 特别的来说这样的方式会导致网卡保存的信息, 在连接数为时内存开销是极大的, 转发效率也会出现断崖式下跌.作者发现, 通过结合连接级的 fcwnd 门控和流级的 fcwnd 调度来执行 CC, 提供了一个很好的平衡.
其实这样的实现是很复杂的, 因为每个subflow都要CC计算fcwnd, 当本来连接数到O(100K)级别时, 如果每个连接有多个subflow时(例如64个), 那么总共需要计算的CC-window数量超过6.4M, 计算复杂度非常高. 当subflow数量较少时, 单个subflow又很容易产生大象流, 例如一个800Gbps采用8个subflow, 并且每个subflow之间的窗口不平衡时, 单个subflow很有可能超过200Gbps, 实际上还是没有打散, 拥塞是降低窗口还是换路, PLB和CC并没有做到很好的协同, 收敛速度也会偏慢, 出现短暂的性能受损.
实际上这种Dynamic Weight Round-robin(DWRR)是设计多路径CC时很容易跳进去的一个坑, 特别是深受MPTCP影响的人.
现在通过追踪一个网络往返过程中的事件来详细描述这些机制:
拥塞控制: 当连接的拥塞窗口(ncwnd 和 fcwnd 的最小值)可用时, PDL 传输一个数据包. 准备好后, PDL 会选择具有最大空闲窗口的流, 该窗口定义为流的 fcwnd 与该流未确认数据包数量之差, 然后应用相应的 Flow Label. 数据包随后沿着其 Flow Label 指定的网络路径到达接收端. 接收端从 Flow Label 中提取流索引, 并更新每个流的拥塞元数据, 如时间戳. 它还实现逐流的 ACK 合并. 当为某个流生成 ACK 时, PDL 会用该流特定的拥塞元数据填充它. 收到 ACK 包后, PDL 使用 ACK 中携带的流索引来识别流. 然后它从 ACK 中提取每个流的拥塞元数据, 除了该流被确认的数据包数量. 这是因为单个 ACK 可能确认来自连接的多个流的 PSN. 为了精确计算每个流被确认的数据包数量, PDL 使用其内部状态, 该状态跟踪每个未确认数据包关联的流索引. PDL 将这些逐流的拥塞信号发送给 FAE.
FAE 的角色 :利用 PDL 提供的逐流拥塞信号, FAE 通过执行 CC 算法计算出流的新 fcwnd. 更新后的 fcwnd 被送回 PDL 以执行, 如前所述. 除了 CC, FAE 还实现 PLB 和 PRR 来根据路径状态决定每个流使用的 Flow Label. 为了便于这些计算, FAE 维护了每个流必要算法的状态.
可靠性: 单个连接内的数据包共享一个公共的 PSN 空间, 无论它们穿越哪个流. 这个设计选择的一个影响是, 跨流的数据包可能会以乱序的 PSN 到达. Falcon 的可靠性机制将乱序与丢包区分开来, 很好地处理了这些情况. ACK 中的 Rx bitmap允许跟踪跨流的已确认数据包. 此外, Falcon 为每个流实现 RACK-TLP, 以避免因乱序引起的伪重传.
总体来看, Falcon的优点是所有的subflow都共享连接的PSN空间, 降低了复杂性和硬件开销. 然后利用IPv6 FlowLabel配合交换机的一些配置就可以实现多路径, 对于交换没有任何额外的要求, 当然在Falcon的标准和一些文档中, 也提及了Falcon支持ECN或者CSIG的能力. 另一个优点是软硬件的协同设计上做的也不错. 最后也是最关键的SACK/RACK-TLP好评, Google在CC和FastRecovery这方面的工作是顶级的.
当然工程上的很多Trade-off也带来了一些缺点, 例如bitmap RX-Window可能针对跨越较长距离的数据中心间路径时, 窗口不够的问题, 特别是在扩展到800Gbps时. 然后subflow较多同时并发连接数在100K时, CC计算cwnd的代价也显著增加了. 同时swift算法和PLB/PRR并没有很好的协同设计.
而eRDMA采用的是一种更加节省网卡内存的做法, 做到了subflow无状态, 即便是在128K连接时仍然可以每个连接支持64个subflow. 然后拥塞控制和多路径负载均衡进行了协同设计, 可以在微秒级别进行快速收敛恢复.
4.4 支持多种ULP
Falcon 的事务层(TL)与多个上层协议(ULP)对接, 而这些 ULP 则向上层应用暴露定义良好的API(例如 RDMA 的 IB Verbs), 以及它如何提供灵活的排序和错误语义. 核心做法就是把ULP抽象成Falcon的事务. Falcon 通过一个定义明确的请求-响应事务(Request-Response Transaction)接口来支持多个 ULP. 每个 Push 或 Pull 事务都包含一个请求及其对应的响应. 在这两种事务中, 请求方 Falcon 向响应方 Falcon 发送一个请求包, 响应方则返回一个响应包. 关键区别在于数据流的方向:Push 用于请求方向响应方发送数据的操作(例如, 写操作). Pull 用于请求方从响应方接收数据的操作(例如, 读操作). 下表总结了 ULP 操作到 Push/Pull 事务的映射.
其实除此之外, 还有一些ULP的业务处理逻辑, 例如WRITE_with_Imm, 如何做到接受端的Fence等行为还是需要可编程的方式来处理.
设计事务接口需要解决两个问题:
接口是否应该对 ULP 执行的事务类型一无所知?接口的粒度是什么?事务类型感知 (Transaction Type Awareness): 与采用字节流模型的 TCP 不同, Falcon 接口能够感知事务类型, 以避免因有限的 NIC 资源而导致的死锁. 感知类型使得 TL 能够将来自 ULP 的请求和响应分配到独立的 PSN 空间, 以避免请求-响应死锁. 此外, 这也有助于性能——它使 Falcon 能够:
基于数据包类型精确地执行拥塞控制(因为 Pull 响应不受 ncwnd 约束, 因为请求方 Falcon 已经为要接收的响应预留了资源)通过将请求(或反向的响应)分配到合适的请求-响应调度器队列中, 来按序调度它们.MTU 粒度 (MTU Granularity): 对于 Falcon, 决定事务的长度不能超过一个 MTU(例如, 一个大的 READ 操作被分解为多个 MTU 大小的 Pull 事务). 这个选择简化了硬件, 因为每个请求都映射到单个响应. 同时, MTU 大小的事务使得对硬件资源的细粒度管理成为可能, 允许基于应用优先级进行仲裁.
灵活的排序语义 (Flexible Ordering Semantics): 每个 Falcon 连接可以被配置为有序(ordered)或无序(unordered). 有序模式反映了 IB Verbs 规范的排序要求, 即要求按序数据放置和按序完成. 此模式使传统的 RDMA 应用程序能够运行在 Falcon 之上. 无序模式, 顾名思义, 对应于乱序数据放置和乱序完成. 它迎合了那些发出独立操作的现代数据中心应用.
在需要时强制排序, TL 依赖于每个事务由一个唯一的请求序列号(Request Sequence Number, RSN)来标识, 并根据 RSN 对数据包进行排序. (注意: 仅靠 PSN 无法保证排序). 至关重要的是, 下一节将描述的片上 NIC 资源使得 Falcon 能够接受 OOO 包, 在等待更早的数据包时将它们缓冲起来, 然后按序交付给 ULP.
对于无序连接, TL 在数据包到达时就将其发送给 ULP. 此外, 弱有序语义(OOO 数据放置但按序完成), 即 iWARP 模型, 可以通过 ULP 在一个无序连接之上自己进行完成排序来实现. 下图将这些联系起来, 展示了一个 RDMA Write 操作在有序 Falcon 连接上的流程.
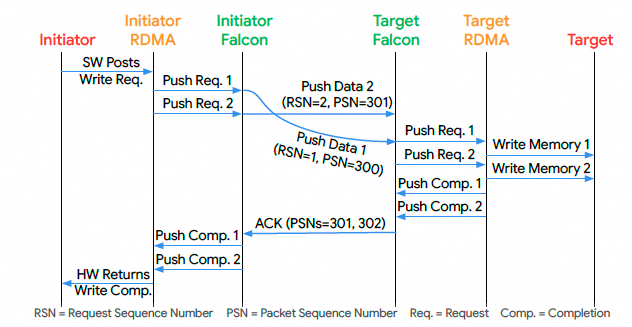 图片
图片
eRDMA支持Strict Order的方式, 也支持Weak Order的方式, 其实这是一种更好的选择, 针对传统的HPC应用, Strict Order保证了应用的兼容性, 而针对新的现代数据中心应用可以切换到Weak Order模式. 而且都是可以支持QP粒度的控制. 但是eRDMA的weak order做的更巧妙一些, 只需要占用很少的Re-Order-Buffer, 而并不需要缓冲Data.
增强的错误通知 (Enhanced Error Notifications) : Falcon 支持现有的 ULP 错误处理语义, 包括接收端未就绪(Receiver Not Ready, RNR) 指示, 它允许目标 ULP 为一个事务指定重试时间. Falcon 对 ULP 透明地处理 RNR 重试. Falcon 还支持一种增强的细粒度错误通知, 出错完成并继续(Complete in Error and Continue, CIE). 它允许更优雅地处理像 RDMA 内存保护错误这样本不必是致命的错误. 目标 ULP 返回一个带错误码的 CIE 指示, Falcon 向发起方传输一个 CIE NACK, 从而以错误状态完成发起方的事务. 后续的事务可以继续成功完成.
这是一个非常实用的创新. 在传统 RDMA 中, 很多错误(如内存访问权限问题)会导致整个连接被终止, 影响巨大. CIE 允许"就事论事", 只让出错的那个操作失败, 而不影响连接上的其他操作. 这大大提高了大规模应用的稳定性和容错能力.
4.5 硬件资源管理 (Managing Hardware Resources)
Falcon 引入了片上 NIC 资源, 以原生支持 OOO 包到达, 并确保其所有 ULP 的可靠性. Falcon 使用两种硬件资源: 上下文(contexts) 和 缓冲区(buffers). 上下文存储固定大小的元数据(例如, 用于排序和可靠性的序列号, 持有的资源, 包头等). 缓冲区存储可变大小的元数据(例如, 散列表)和实际的数据包载荷.
这些资源是有限的, 其大小旨在满足给定一代 Falcon 的操作速率和带宽目标, 同时为 RTT 抖动或变化留出余量. TL 需要仔细管理 Falcon 资源, 以避免在请求-响应协议中可能发生的死锁. 下面是对协议转发至关重要的资源划分和预留-使用-释放生命周期.
资源划分 (Resource Carving): 在 Falcon 中, 资源根据三个直观的原则被划分为多个子池, 以避免死锁, 如下图所示:
TX和RX之间进行划分, 以便它们可以独立分配. 否则可能导致所有资源被出向包用完, 使得入向包无法被接受, 反之亦然.TX和RX资源进一步划分为Req和Resp, 以便它们两者可以独立的处理. 没有这种分离可能导致未完成的请求用尽所有资源, 从而阻止响应被发送, 反之亦然.Rx 请求资源池在一个资源占用阈值之上, 只允许队头(Head-of-Line, HoL) 请求进入. 对于有序连接, 当一个请求的 RSN 是上一个按序收到的请求 RSN+1 时, 它就是 HoL. 对于无序连接, 所有请求都被视为 HoL. 不接纳 HoL 请求可能导致所有资源被非 HoL 请求占据, 使得有序连接的协议无法推进.资源生命周期 (Resource Lifecycle): 每个事务在其生命周期内持有各种资源. 在从 ULP 收到请求时, 发起方 Falcon 不仅为该请求预留 Tx 资源, 还为相应的响应预留 Rx 资源(对于 Push 是完成信息; 对于 Pull 是 Pull 响应). 这种方法天然地消除了反向路径 incast 的形成, 因为发起方 Falcon 只有在能够接收相应响应时才会发出请求. 更重要的是, 这样做也确保了入向的 HoL 响应总是有预留好的资源, 从而确保了不会因 HoL 响应资源不可用而发生死锁. 在另一端, 目标方 Falcon 在请求(响应)从网络(ULP)到达时使用 Rx (Tx) 资源. 一旦接收到的数据包交付给 ULP, Rx 资源就被释放. 当传输的数据包对应的 ACK 被收到时, Tx 资源就被释放.
当 Falcon 耗尽资源来处理来自 ULP 的新事务时, 它会通过一个 Xon/Xoff 流控接口反压它们, 不让它们发送额外的事务. 当没有足够资源接受入向网络流量时, Falcon 会生成资源 NACK.
总体来看这些buffer资源的管理还是很经典的很有效的做法, 基本上很多网络处理器都有.
Tx vs Rx: 这是最基础的隔离. 防止"只发不收"或"只收不发"的死锁.Request vs Response: 这是第二层隔离. 防止请求耗尽所有资源, 导致响应无法发出(或接收), 而请求的完成又依赖于响应.HoL vs non-HoL: 专门针对有序连接设计的隔离.另外一个很好的设计是, 在 RDMA Read 或 NVMe Read 中, 多个客户端同时向一个服务器请求数据, 会导致大量响应数据同时涌向该服务器, 形成"响应 incast". Falcon 的机制天然地解决了这个问题:服务器只有在确认客户端有能力接收响应时, 才会发出请求, 从源头上控制了请求的发送速率, 避免了响应风暴.
然后保证无死锁: 这个机制从根本上保证了只要一个请求被发出, 其对应的响应就一定有资源可以接收. 这消除了因响应资源不足而引发的一大类死锁问题.
但是Google并没有谈到如何将它们配合QoS这些使用.
4.6 连接隔离 (Ensuring Isolation)
Falcon 提供了连接之间的隔离. 没有隔离, 一个进展缓慢的连接(因此持有资源更长时间)可能会剥夺其他连接的资源, 从而妨碍它们的性能. 隔离是在 Falcon 中而不是在 ULP 中实现的.
Falcon 对资源使用和连接进展有直接的可见性, 这两者都是确保隔离所必需的;如果不这样做, 将需要 ULP 对 Falcon 有更多的可见性, 并且不必要地在每个 ULP 中复制隔离逻辑.Falcon设计让 TL 能够在连接超过其资源使用阈值时, 通过一个逐连接的 Xon/Xoff 流控接口, 对 ULP 施加细粒度的反压. 这使得 Falcon 能够反压慢速连接, 阻止它们发送事务, 从而让其他连接能够继续取得进展. Falcon 动态地计算反压阈值, 并采用了类似于数据中心交换机缓冲区管理中常用的动态阈值(Dynamic Thresholds,DT) 算法. 与 DT 类似, Falcon 将连接的阈值计算为. 连接的 参数决定了它相对于其他连接的限制: 值越大意味着份额越大, 反之亦然.
FAE 的角色: 与 是静态的 DT 不同, FAE 动态地计算连接的 为 , 其中是一个拥塞感知的变量, 与 fcwnd 和 ncwnd 成正比, 但与网络延迟和缓冲区占用率成反比. 例如, 在网络(主机)拥塞的情况下, 如果 fcwnd (ncwnd) 很低和/或网络延迟(缓冲区占用率)很高, 这表明该连接进展缓慢, 需要较少的资源. Falcon 会相应地缩减 , 以降低该连接相对于无拥塞连接的反压阈值.
这一点Google Falcon设计的也挺不错的. 特别是如何在多租户环境中实现公平性和性能隔离, 防止"害群之马"影响整个系统. 问题的本质: 在共享资源的环境中, 一个行为异常或处于不良网络状况的"慢"连接, 会长时间占用 NIC 内部的缓冲区和上下文, 导致"快"连接无资源可用, 从而被拖慢. 这就是"队头阻塞"在连接层面的体现.
传统DT算法中的静态(决定连接份额的权重)通常是静态配置的. 这意味着无论连接快慢, 其资源份额比例是固定的. FAE将其变为动态, 因此阈值 不是固定的, 而是与当前空闲资源量 FreeResources 挂钩. 这意味着在资源充足时, 大家都可以多用一点;在资源紧张时, 大家的额度都会被收紧. 这是一种自适应的控制.
FAE 会持续监控每个连接的"健康状况"(通过 fcwnd, ncwnd, 延迟等指标). 对于一个"健康"的连接(高 fcwnd, 低延迟), FAE 会给它一个较大的 , 允许它使用更多资源, 尽情奔跑. 对于一个"生病"的连接(低 fcwnd, 高延迟), FAE 会主动调低其 . 这会降低它的资源阈值 , 导致它更容易被反压.
5. 构建一个可扩展的硬件传输协议
5.1 构建 Falcon 并将其集成到 NIC 中
这一章描述了实现 Falcon 传输协议的经验, 以及作者做出的一些值得注意的选择.
Google把 Falcon 构建成一个独立的硬件(HW)模块, 可以集成到供应商的基础 NIC (FNIC) 或基础设施处理器(IPU) 中. 当前已将 Falcon 模块集成到 Intel E2100 200Gbps IPU 中, 并已将 Falcon 模块扩展至 400Gbps 和 800Gbps 的速度. Falcon 作为一个 IP 模块与 NIC 的其余部分集成在同一个芯片上. 使用 ASIC 实现使得 Falcon 能够满足其峰值操作速率和低延迟的要求. 没有采用基于 FPGA 的实现等替代方案, 因为其TCO更高, 且在操作速率和低延迟方面的性能更差.
上图展示了 Falcon 硬件集成到一个通用 FNIC 中的情况, 它一侧与 ULP 对接, 另一侧与数据包处理模块对接. 在 NIC 中实现 Falcon 除了集成之外, 还需要额外的更改. ULP 内部需要进行更改, 以将其操作映射到 Falcon 事务上. 鉴于 Falcon 也依赖时间轮(Timing Wheel,TW)来可能地对数据包进行整形, 因此引入了一个独立的 TW 模块;或者它也可以在 Falcon 硬件内部实现. Falcon 还依赖于在靠近以太网端口的位置对数据包进行时间戳处理, 以实现精确的网络 RTT 测量. 通常, 这个时间戳功能是在内联加密模块中实现的(利用PSP或IP-SEC协议的IV字段). 下图展示了 Falcon 硬件的框图, 具有独立的发送和接收流水线以及共享的控制逻辑, 这是硬件传输协议实现的典型结构:
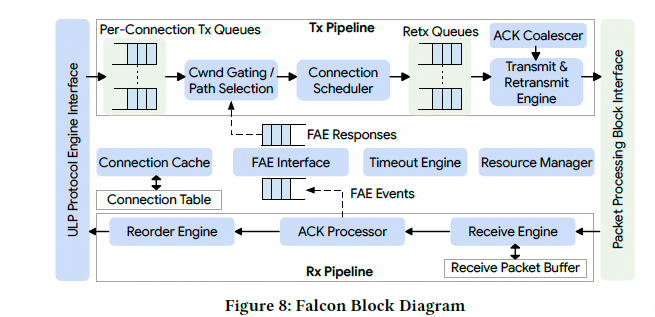 图片
图片
5.2 值得注意的实现选择
这一节重点介绍 Falcon 硬件实现中一些偏离传统经验的方法. 它的目标是确保该实现不易出现性能抖降, 以便能满足超大规模的数据中心应用, 这些应用通常涉及分布在 O(10K) 台机器上的 O(100K) 个通信进程; 这类应用的性能对通信的Tail-Latency非常敏感.
片上 NIC 资源 (On-NIC Resources): 传统上, 考虑到面积和功耗的影响, 人们会尽可能避免使用片上存储器. 然而, 对于 Falcon, 必须在接收路径上支持数据包缓冲, 以用于乱序处理, 这需要 量级的资源. 为了满足集群级别的要求, 对于 200Gbps IPU 和 50us RTT 的设置(典型的集群内 RTT), BDP 为 1.2MB. 对于 400Gbps 增长到 2.4MB, 800Gbps 增长到 4.8MB. 在当前的工艺技术(如台积电 N7, N5 或 N3)下, 数据包缓冲区需要 的芯片面积. 这小于 IPU SoC 芯片面积的1%, 使其在实现上是可行的. 至关重要的是, 为集群级设置确定数据包缓冲区的大小, 也同样能支持集群间和城域间的使用场景, 因为在这些场景下, 每个连接所需的典型带宽要低得多(至少 5-10 倍), 而RTT则相应地更高. 作者还举例说明了AI/ML中的集合通信场景, 随着通信以分层方式实现, 各网络层级的需求随之降低. 最后, 虽然 Falcon 协议有多种机制来确保片上资源不会成为性能瓶颈(例如, 当连接经历网络丢包或主机降速时), Falcon 硬件还允许数据包缓冲区从片上 SRAM 溢出到外部的片上DRAM. 这个选择使得在极端CornerCase情况下能够有较好的表现.
其实我一直对Falcon的bitmap RX-window实现还是有一点担忧的. 从网络上来看inter-cluster/inter-metro一定会有收敛比, 即便是在AI/ML场景中, 例如进行层次化的Reduce聚合后, 作为一个网卡可能还是要保证单卡能够在长传上跑满网卡的带宽. 而在这种设计上, 集合通信可能需要专门做一些reduce-scatter然后分散到多个Node(NIC)上向inter-metro的另一端发送. 当然集合通信算法设计一下可以规避单网卡长传打满的需求. 只是我觉得做网卡还是把这个case cover一下可能会好一点.
连接状态缓存 (Connection State Caching): 与其他面向连接的硬件传输协议一样, Falcon 采用连接缓存来将活动连接的状态保存在芯片上. 在超大规模下, 活动连接数远超缓存大小, 导致接近 100% 的缓存未命中率, 这可能导致吞吐量和延迟的急剧下降. 为了限制在这种情况下的性能抖降, Falcon从存储连接状态的内存系统中为缓存预留了足够的带宽. 此外, 还实现了一个更大的二级缓存(在 IPU 中的多个模块间共享), 以进一步改善未命中带宽和未命中延迟. 限制这种性能抖降的代价是额外的芯片面积和内存带宽, 但为了提供可预测的持续性能, 这种权衡是必要的.
实际上这段就是在讲需要一个Memory-Rich架构的网卡, 而原有的Memory-Free架构的Connext-X系列QP数量多了以后性能下降的根因就在于此, 它们通常把这些缓存到主机内存中, 当Cache-Miss时, 需要通过PCIe去读取主机内存中的连接状态, 这样带来的延迟影响了整体的吞吐.
错误处理 (Error Handling): 硬件传输协议的设计通常选择在硬件中实现数据平面的快速路径, 而将异常路径和错误处理留给固件实现. 虽然这种方法简化了硬件设计, 但它可能导致性能抖降, 因为固件处理数据包可能会因数据包排序或数据依赖性要求而阻塞硬件快速路径. 在超大规模下, 错误和异常(由丢包, 乱序等触发)会定期发生, 并且常常是突发性的, 会使快速路径长时间停滞. 为了避免这种性能抖降, Falcon在硬件中实现了错误处理. 丢包恢复和错误处理是通过维护逐包上下文来实现的, 这些上下文存储了必要的元数据(如初始发送时间戳)和重试状态(如 RNR NACK). 重传超时是由高效的硬件线程处理的, 这些线程扫描每个连接的数据包上下文链表.
这一点来看, 有利有弊吧. 丢包乱序这些处理上, 纯硬件RTL实现使得整个项目做了非常辛苦, 从2021年Intel发布IPU到2024年才真正的商用落地, 也是一个代价.
5.3 实现和扩展FAE
在IPU的实现上, FAE运行在Intel IPU的ARM N2通用处理器核中, 每个核都有私有的 L1/L2 缓存和一个共享的 L3 缓存. FAE 通过共享内存队列, 使用定义明确的事件-响应格式与 PDL 通信. PDL 将相关信号打包在事件中, 传递给 FAE; FAE 计算各种传输参数, 并通过响应将其传回给 PDL.
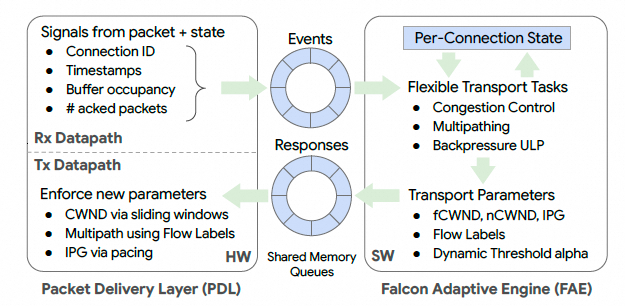 图片
图片
下表展示了 Falcon 如何通过划分机制(在硬件 PDL 中实现)和管理(在软件 FAE 中实现)来完成各种传输功能, 以及特定功能的接口信号.
功能特性
硬件 (PDL) 机制
接口信号
软件 (FAE) 任务
可靠性, 丢包恢复
ACK bitmap, RACK, TLP
时间戳, Rx 缓冲区占用水平
跳数, ECN, RTO, CSIG计算 RTO, RACK 超时, TLP 阈值
拥塞/流控制
滑动窗口, Pacing
计算 fcwnd, ncwnd, IPG, 目标延迟缩放因子
多路径,PLB, PRR
路径感知的流调度器
流标签 (Flow Labels)
流标签的(重新)分配和逐流的 CC 任务
资源隔离
动态阈值
资源占用率
基于动态因素计算 DT 的 alpha 值
纯 ACK 生成
报头中的 ACK Req bit
ACK 请求率
决定何时/如何设置 AR 位
除了确保 FAE 及时响应外, 优化其处理速率以使 FAE 使用最少的核也是至关重要的. 影响这一点的一个关键因素是 FAE 算法状态的管理方式. 在收到一个事件后, 访问每个连接的算法状态可能会导致缓存未命中(cache misses), 从而减慢 FAE. 当连接数增加, 导致累积状态超过缓存容量时, 就会发生缓存未命中.
为了避免状态缓存未命中的惩罚, 作者最初将 FAE 设计为无状态的(stateless), 将状态管理卸载给 PDL, 由 PDL 维护每个连接的算法状态, 并将其嵌入到 FAE 事件中. 这确保了状态与接口信号一起在事件中随时可用, 供 FAE 算法使用. 最后, FAE 在响应中将状态返回给 PDL.
然而, 无状态 FAE 受限于 PDL 能够管理的每个连接的算法状态量. 为了适应更多的用例, 转向了有状态的 FAE (stateful FAE), 其中 FAE 在软件中管理额外的状态, 这些状态在处理事件时被检索. 为了防止缓存未命中的开销, 在处理一个事件之前, FAE会查看事件队列的更深处, 并为即将到来的事件预取(prefetch)状态. 这种方法确保了后续的事件不会遭受状态检索的惩罚.
这是针对通用处理器软件优化的一种常见方式, 原来设计的方法是PDL硬件直接把Context送到ARM子系统, 确保Cache命中. 但是有很多业务场景Context过大, PDL处理负担也很重,特别是NOC上的压力, 因此采用了FAE去Prefetch的方式处理.
6. 评估
这一章评估了Falcon的可靠传输, 多路径, 网卡硬件性能以及对MPI/HPC和热迁移的影响. 使用一个由 32 台机器组成的测试平台,配备了 200 Gbps 的 Falcon NIC 和 400Gbps 的 NVIDIA CX-7 NIC (使用 RoCE; RTTCC作为 CC 算法). 在评估更高速 NIC 才有的功能如 RACK-TLP 和多路径时, 由于测试平台没有大规模的组网, 使用一个已经通过硬件仿真验证过的模拟器,以确保它能准确反映真实硬件的行为.模拟的拓扑是一个类似于Google Jupiter的三级网络.
实际上我认为多路径这一块的评估是有缺陷的, 例如在一个CLOS网络中模拟TOR/Leaf/Spine中断, 网卡-TOR之间链路闪断. 大面积网络故障例如一半的Leaf中断等异常情况下, 多路径和拥塞控制以及RACK-TLP这些是需要实际真机测试的. Astra-sim在我最开始做eRDMA多路径算法的时候也经常使用进行过仿真分析, 但讲真它和真实的环境还是有差距的.
6.1 Falcon协议的性能
这里是对比Falcon和RoCE都采用RDMA RC QP的性能.
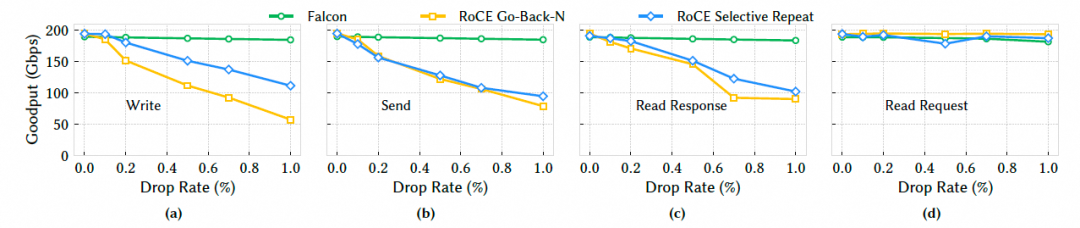
6.1.1 丢包恢复丢包影响采用两台机器点到点通信的方式, 在交换机上人为制造丢包或乱序,比较 Falcon 和 RoCE (GBN/SR/AR 模式) 的有效吞吐量 (goodput).测试采用单QP并都将网络速率设置成200Gbps, 采用8KB的RDMA消息进行测试.
 图片
图片
随着丢包率增加,Falcon 的吞吐量基本保持稳定在 200Gbps.而 RoCE 的三种模式吞吐量都急剧下降.即使是 RoCE 最好的 SR(选择性重传)模式,在 1% 丢包率下性能也比 Falcon 低 65%. 这有力地证明了 Falcon 基于 SACK/RACK-TLP 的丢包恢复机制远比 RoCE 的机制高效.RoCE 的 GBN 效率最低,而 SR 模式也存在限制(如并非所有操作都支持)和恢复慢的问题.Falcon 的机制能够精确地只重传丢失的包,并且快速恢复,因此对丢包不敏感.
CIPU eRDMA也做过类似的测试, 甚至在丢包率5%时, 还能够维持90%的Goodput
乱序影响及RACK-TLP的能力随着乱序率增加,Falcon 性能依然稳定.而 RoCE 的性能大幅下降,特别是 GBN 模式,几乎降为 0. 这是RACK设计较好带来的收益, Falcon 能够通过时间启发式算法准确区分"真丢包"和"网络乱序",从而避免了因乱序而触发的不必要重传.而 RoCE 将乱序误判为丢包,导致了大量的伪重传,严重影响性能.
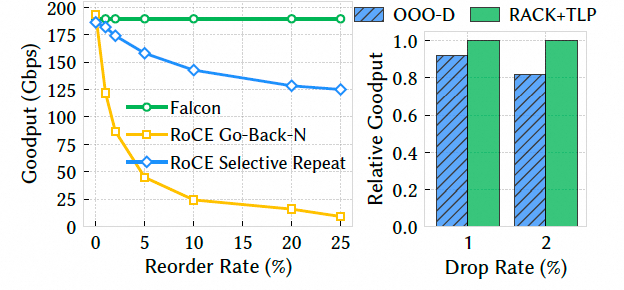 图片
图片
然后上面右图是另一个case, 对比 Falcon 最初的 OOO-D(基于乱序距离)算法,RACK-TLP 的吞吐量高出 7-18%. TLP在处理尾部丢包时优势巨大.OOO-D 在这种情况下只能等待 RTO,而 TLP 可以主动探测并快速恢复.这证明了采用 TCP 社区最先进的 RACK-TLP 算法是正确的选择.
CIPU eRDMA同样也测试过, 其实只要算法上区分好了乱序和丢包两个窗口, 不触发错误的快重传, 性能都能维持住. 第二个case挺好的, 我们起初在eRDMA上没有实现TLP, 也是在真实E2E测试中遇到一例光纤质量不稳定导致闪断的情况, 使得集合通信任务有长尾, 然后仔细排查后才加上TLP机制的.
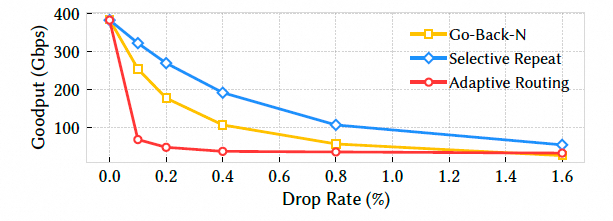
RoCE不同模式的对比增加了一个Adaptive Routing的测试, AR是最差的.
 图片
图片
实际上也说明了Nvidia为什么要在Spectrum-X解决方案中选择回Lossless网络了, 真的丢包的表现差的要死.所以我在这图一直吐槽, 怎么NV又回到了Lossless..
 图片
图片
总体来看, 这一节的测试写的挺好的, 基本上把RoCE在超大规模组网Lossless和半吊子的SR上的缺陷讲清楚了.
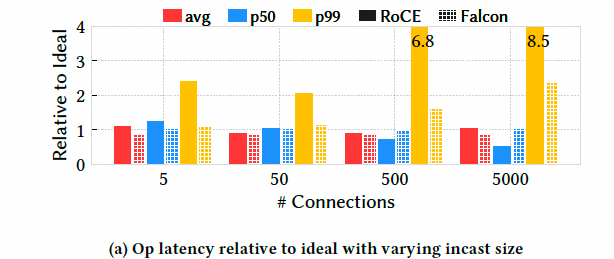
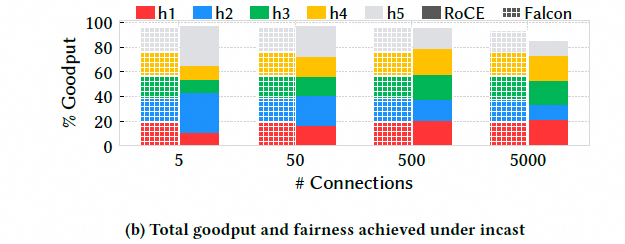
6.1.2 拥塞控制Fabric拥塞和Incast5 个客户端同时向 1 个服务器发送大量数据,模拟 Incast 场景. 在 5000:1 的 Incast 下,Falcon 的 p99 延迟仅为理想值的约 2 倍,而 RoCE 高达 8.5 倍.Falcon 的总吞吐量接近线速,而 RoCE 损失了 13%.这证明了 Falcon 基于延迟的拥塞控制(Swift)比 RoCE 的 RTTCC 更有效.Falcon 能够更早,更精确地感知到拥塞,并平滑地调整速率,避免了队列的过度积压和丢包,从而在高拥塞下保持了低延迟和高吞吐.
 图片
图片
 图片
图片
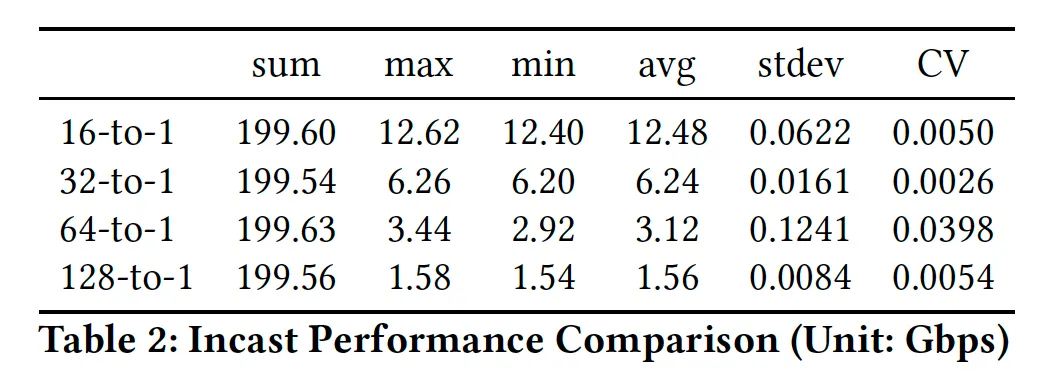
实我觉得这个测试规模还不够大, 作者不是有32台机器么, 直接32打1测测? 然后为什么不统计一下connection之间的变异系数呢? 给个eRDMA的测试结果给Falcon团队参考
 图片
图片
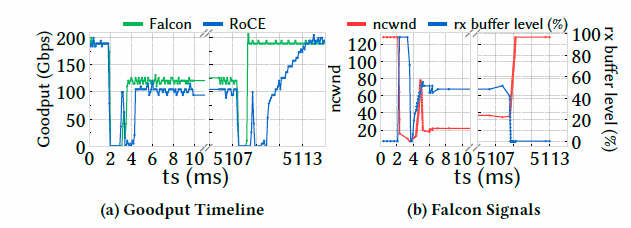
然后第二个实验人为降低接收端服务器的 PCIe 带宽,模拟主机侧瓶颈. 这是 Falcon ncwnd (NIC 拥塞窗口) 机制的展示测试.
当瓶颈出现时,Falcon 能在约 5 个 RTT 内迅速将速率收敛到瓶颈带宽,而 RoCE 需要两倍的时间.当瓶颈解除时,Falcon 也能迅速恢复,而 RoCE 需要 6 倍长的时间. Falcon 通过 ACK 将接收端 NIC 的缓冲区占用情况反馈给发送端,能够精确地感知到"非网络"因素导致的拥塞.这使得 Falcon 的拥塞控制更加全面,能够适应整个端到端的系统瓶颈.
 图片
图片
其实很多人学习Swift协议的时候, 只学会了那四个timer和窗口计算算法, 而忽视了文章附录中关于接收缓冲区深度信号的反馈. eRDMA早期的算法也是只有4个timer的拥塞窗口控制, 后来也是因为遇到了一个性能下降就加上了ncwnd的处理. 这是一个非常重要的细节, 具体什么场景就不多说了.
6.1.3 多路径这一章全部是仿真的, 仿真了24个host在一个Rack, 另外24个host在另一个rack. 然后单路径和多路径对比.
延迟和吞吐与单路径相比,Falcon 的多路径功能在高负载下可将延迟降低 180 倍,并能承受高达 90% 的网络负载(而单路径只能承受 60%).
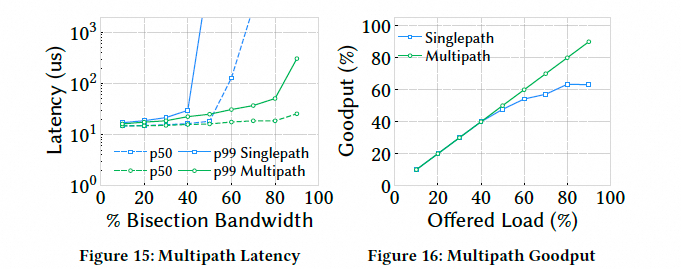 图片
图片
Falcon 的拥塞感知调度策略比简单的轮询(Round-Robin) 策略在高负载下延迟低 2-4 倍.
 图片
图片
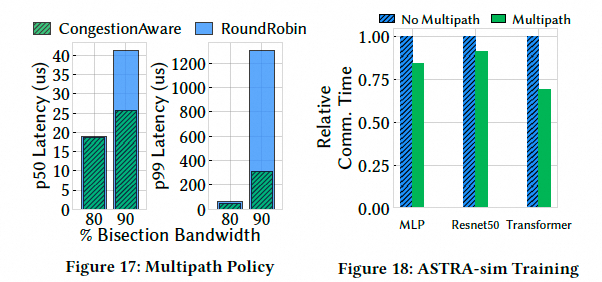
最后做了一个仿真训练对比, 在 ASTRA-sim 模拟中,多路径能将 ML 模型的通信时间减少高达 30%,整体训练时间提升 5%.
eRDMA在128卡GPU的环境中, 通过编排机器的Rank让每一个流量都穿越TOR形成ECMP Hash冲突, 真实的集合通信测试可以获得95%的Fabric利用.
其中BaseLine采用的是一个CUBIC算法, 然后采用RTT-CC, 最后叠加多路径的一个消融实验结果如下:
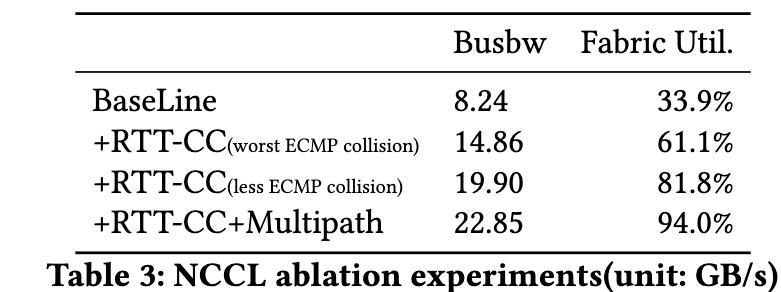 图片
图片
另一方面Google Falcon缺少的是两个集群同时进行集合通信的干扰对比测试, 以及alltoall这些DeepEP相关的测试(当然写论文的时候还没有DeepEP), 而我在2024年初就意识到了MoE在ScaleOut网络上的流量影响, 并在2023年设计CIPU多路径算法时就考虑到了
6.1.4 硬件性能不同消息size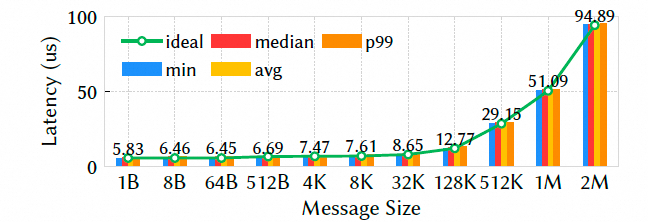 图片
图片
Falcon 的 p99 延迟和中位数延迟非常接近,与理想值仅差 1%.这表明 Falcon 的硬件流水线非常高效且稳定,没有明显的处理抖动,尾延迟控制得极好.
带宽可扩展性接近饱和带宽时,Falcon 的延迟比最先进的软件传输协议 Pony Express 低两个数量级. 然后测试了消息速率, 单 QP(队列对)可达 20Mops,仅用 12 个 QP 即可达到 120 Mops 的峰值速率.
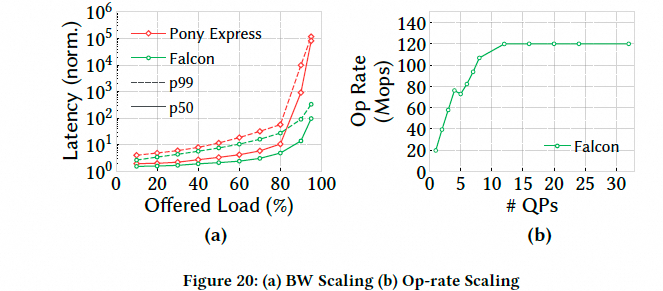 图片
图片
这里对比了和CX7在不同连接数下的延迟, 可以看到CX7在QP多了以后延迟陡增
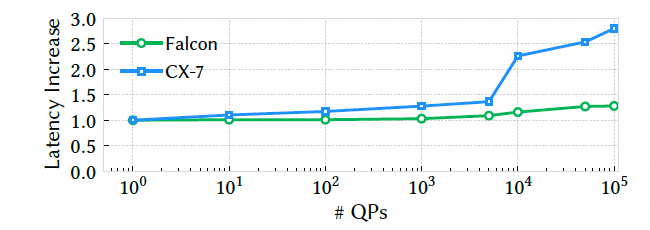 图片
图片
这是在回应前文中讲到的FAE是否做Prefetch的case, 带有prefetching功能的 FAE,即使在 1M 连接数下,也能保持 20 Mops 的稳定处理速率.即使 FAE 响应变慢(人为增加延迟),对整体性能影响也有限.对状态大小也不敏感.
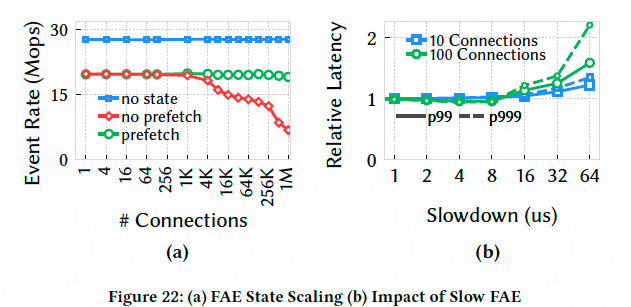 图片
图片
然后就是state size的影响
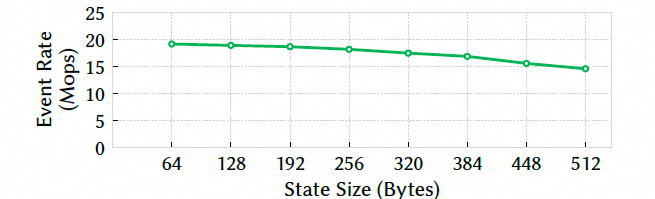 图片
图片
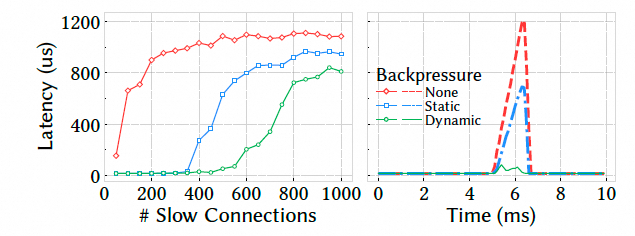
混合快速流和慢速流,观察慢速流对快速流的影响. 在没有隔离时,快流的延迟增加了 63 倍.使用 Falcon 的动态反压后,延迟增加被控制在 3 倍左右.
 图片
图片
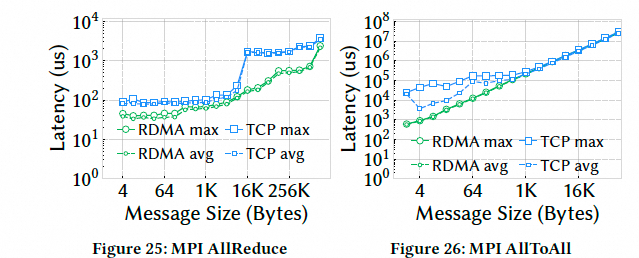
在 AllReduce 和 AllToAll 等典型的 HPC 集合操作中,RDMA-Falcon 比传统的 TCP 协议栈性能提升了 4.3 到 5.5 倍.直接展示了 Falcon 在 HPC 领域的巨大价值.
 图片
图片
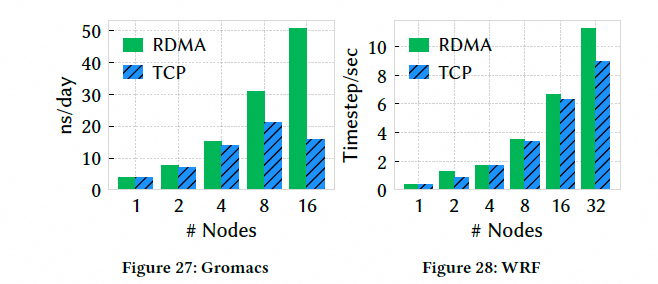
然后HPC场景选择用分子动力学模拟(GROMACS)和天气预报模型(WRF),Falcon 带来了 2.4 倍的性能提升和 32% 的模拟时间缩短.
 图片
图片
阿里云借助CIPU eRDMA早就商业化了云超算业务, 成本相对于线下专用RoCE网络机房下降xx%, 然后E2E性能和专用的RoCE网络只有3%的差距.Abaqus, LS-DYNA,Fluent这些应用相对于TCP有10%~80%的性能提升. 而Google基于Falcon的HPC业务才刚刚上线.
然后是做了一个近本地存储的Nvme-over-Falcon和本地磁盘对比, 使用 NVMe-over-Falcon 的网络存储,其性能(带宽和IOPS)可以达到本地 SSD 的 90% 以上..
 图片
图片
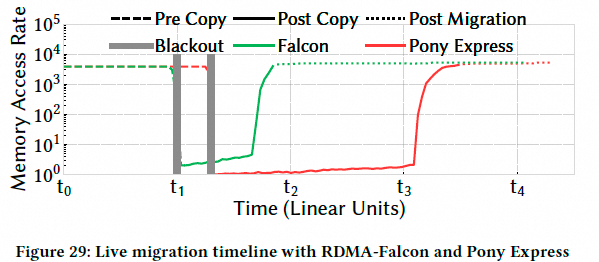
与软件方案 Pony Express 相比,Falcon 将迁移的关键阶段(post-copy)加速了 2.5 倍,vCPU 等待时间减少了 6 倍.
 图片
图片
VM热迁移其实对云上来说是一个非常刚需的业务, 我们也使用eRDMA在CIPU上做热迁移的工作. 同时GuestVM的eRDMA连接, 我们也可以做到热迁移, 这里Google并没有做相关的测试.
7. 相关工作
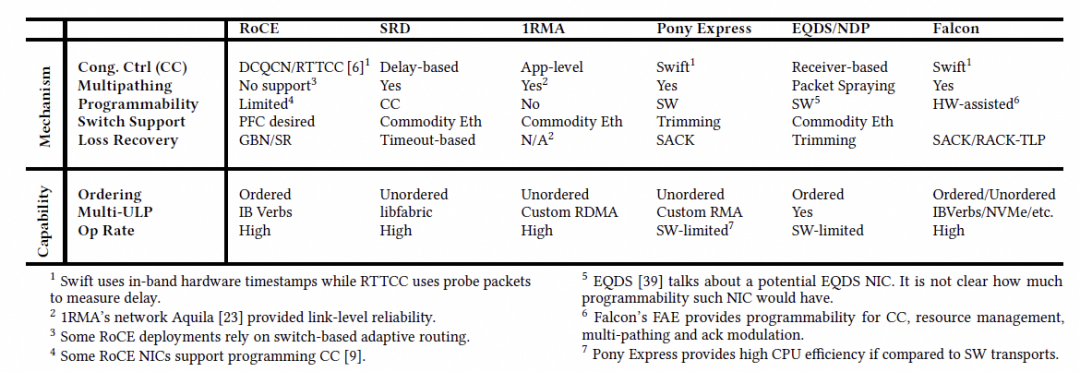
这一章也写的很好的, 原文有个表我补充一列eRDMA的.
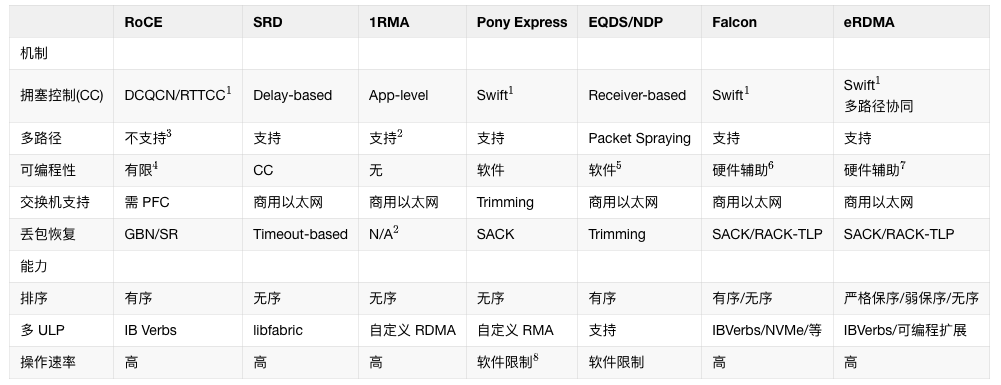 图片
图片
7.1 硬件传输协议
AWS SRD描述: SRD 是为多租户云环境设计的,为 HPC 提供 libfabric 接口,为 ML 提供 NCCL.它使用类似 BBR 的拥塞控制和多路径.与 Falcon 对比: SRD 将排序卸载给应用,而 Falcon 在提供多路径的同时,仍然保持了 IB Verbs 的严格有序语义.分析: 这是一个关键区别. SRD 更偏向于现代"无序"应用,而 Falcon 兼顾了传统有序应用和现代无序应用,适用范围更广.能够在使用多路径的同时保持有序,是 Falcon 一个重要的技术难点和亮点.CIPU eRDMA是全世界第一个基于VPC又支持多路径同时完全兼容IB RC Verbs的工业实现. 选择RC才是正路.
Tesla TTPoE描述: 特斯拉的 RDMA 硬件传输协议,使用片上 SRAM 提升性能.与 Falcon 对比: TTPoE 是为单租户,点对点传输模型设计的,不支持 IP 网络,没有拥塞控制和多路径.分析: TTPoE 是一个高度专用的协议,适用于像 Dojo 超算这种内部结构化网络.而 Falcon 的目标是大规模,多租户的通用 IP 数据中心网络,设计目标和复杂度完全不同.反正Dojo已经死了, 就不多说了. 其实TTPoE至少还是lossy可靠传输的吧, 人家的优点多写一笔不行么?
1RMAGoogle自己的工作, 就不多谈了
ZeroNIC描述: 一种协同设计的 NIC,结合了零拷贝的硬件数据路径和基于软件的控制路径.与 Falcon 对比: ZeroNIC 允许灵活实现不同的传输协议栈,但代价是可扩展性和性能相比 Falcon 更低.分析: ZeroNIC 更像一个通用的"可编程 NIC 框架",而 Falcon 是一个针对高性能传输协议深度优化和固化的产品.两者的定位不同,Falcon 在其目标领域性能更优.Ultra Ethernet Transport (UET)描述: UEC 联盟为 AI/ML 和 HPC 网络设计的传输协议. 与 Falcon 对比:与 Falcon 对比: UET 主要面向 AI/ML,而 Falcon 额外支持通用共享网络.API: UET 基于 libfabric,而 Falcon 兼容现有的 IB Verbs.可扩展性: UET 引入了"包交付上下文"这种按需的临时连接状态,而 Falcon 使用了更传统的连接缓存+DRAM的架构.负载均衡: UET 的包喷洒(packet spraying)仅限于无序流量,而 Falcon 的多路径可以支持有序流量.分析: 这是与 Falcon 最直接的竞争者.对比凸显了 Falcon 的几个优势:更强的兼容性(IB Verbs),更广的适用性(通用网络),更强大的功能(支持有序的多路径).说实话, 能够在多租户情况下, 支持多路径并且兼容IB RC Verbs是一件特别难的事情, CIPU eRDMA是工业界第一个做到的, 领先业界2年
7.2 丢包恢复
IRN and RoCE-SR描述: IRN 提出了为 RoCE 引入选择性确认,后来演变为 RoCE NIC 中的选择性重传(SR).与 Falcon 对比: 如第六章评估所示,SR 的性能远不及 Falcon.分析: 直接引用自己的实验结果来证明 Falcon 的优越性,非常有说服力.是男人就要硬刚Lossy, CIPU eRDMA做到了, Google Falcon也做到了.
SRNIC描述: 尝试通过只将频繁访问的状态卸载到 NIC,来缓解 SR 机制带来的连接可扩展性问题.分析: 这表明学术界和工业界都认识到了 RoCE 在可扩展性上的问题.SRNIC 是一种优化思路,而 Falcon 则是从更根本的架构层面(如高效的缓存设计)来解决这个问题.又来一个怼郭老师的, 说实话终局是Memory-Rich架构, 另外可以翻看一下SRNIC的论文, 对于RoCE的QP Conn Scale的测试值是偏低的.
7.3 负载均衡
ConWeave描述: 通过可编程的 ToR 交换机来掩盖乱序交付,从而为 RDMA 实现网络负载均衡.与 Falcon 对比: ConWeave 依赖可编程交换机,而 Falcon 无需特殊交换机支持.分析: 这再次凸显了 Falcon 的一个核心优势: 对网络基础设施要求低,部署更简单,成本更低.过去几年我一直在说, 不依赖任何交换机的高级特性, 不用任何特殊拓扑, 不要ECN, 不要PFC,不要INT/IFA, 不要PacketSpray, 不要多轨道, 不要多平面. 真的能做好RDMA
MP-RDMA描述: 为 RoCE 增加了多路径能力.与 Falcon 对比: MP-RDMA 仍然需要 PFC.分析: 这说明简单地给 RoCE "打补丁"无法解决根本问题.MP-RDMA 依然没有摆脱对无损网络的依赖.而 Falcon 是原生为有损网络的多路径设计的.7.4 可编程性
Tonic , HotCocoa描述:允许自定义 CC 算法的可编程框架.与 Falcon 对比: 它们无法支持 Falcon 的多路径 CC,因为 Falcon 的 CC 需要为单个连接维护多个拥塞窗口和路径选择原语.分析: 这说明 Falcon 的拥塞控制模型(特别是多路径部分)比这些通用框架考虑的场景更复杂,更先进.Falcon 的 FAE 是为这种复杂模型量身定制的.NanoTransport, nanoPU描述: 利用 P4 可编程架构和 FPGA/RISC-V 来降低延迟.与 Falcon 对比: P4 NIC 流水线在生产环境中的长期可行性尚未得到证实.分析: 这是一个非常务实的工程判断.P4 在学术研究中非常流行,但在大规模生产部署中仍面临挑战.Falcon 选择了更成熟的 ASIC + 通用 CPU 的架构,可靠性和性能更有保障.P4吐槽的非常好, 确实在工业界来看P4只适合处理一些简单的parser类的任务, 对于复杂状态是困难的. AMD Pensando在P4的基础上做了一些扩展, 有了PC有了通用寄存器, 似乎也是一条路,但是AMD网卡未来的演进还是有一些问题的. P4语言本身的表达能力并不是一个完备的实现,同时PPA的考虑来看, 实现P4的Match Unit功耗也是偏高的.
7.5 传输协议
Homa,NDP描述: 接收端驱动的调度协议.与 Falcon 对比: 它们需要全互联带宽的交换矩阵或依赖数据包修剪(trimming),这些假设在真实网络中难以满足.分析: 再次批判了学术界一些方案的理想化假设,反衬 Falcon 设计的现实性.EQDS:描述: 一种通用的数据报服务,设想了硬件 NIC 实现.与 Falcon 对比: 不支持标准的 IB Verbs.分析: 兼容性是 Falcon 的一个关键优势.AccelTCP, FlexTOE:描述: 高性能的 TCP 卸载引擎.分析: 这些是 TCP 领域的优化,而 Falcon 是一个全新的,面向 RDMA/NVMe 的传输协议,赛道不同.简单的把TCP offload到网卡上来也是错误的, Scaling是一个大问题, 并且也不支持标准的IB RC Verbs. 其实这里应该再加一个它们自己家的GPU-Direct-TCP-X
RoGUE:描述: 将 CC 卸载到 CPU 以便于升级.与 Falcon 对比: 在高拥塞事件率下可能产生沉重的开销.分析: 这就是 Falcon FAE 需要通过预取等技术来优化的原因.RoGUE 证明了简单的软硬件分离是不够的,还需要精心的性能优化.HPCC, PowerTCP, Bolt描述: 利用带内网络遥测(In-band Network Telemetry, INT)和先进的交换机功能来增强 CC.与 Falcon 对比: 它们依赖先进的交换机功能,限制了在传统网络中的应用.Falcon 无此依赖,但其可编程性也可能使其受益于这些功能.分析: 这再次强调了 Falcon 的普适性.它不依赖高级网络功能,但其 FAE 架构的灵活性使其具备了未来利用这些新技术的潜力.不依赖交换机高级功能, 不依赖交换机高级功能, 不依赖交换机高级功能, 简化运维. CIPU eRDMA和Google Falcon的观点是一致的.
8. 总结
这部分先看看作者是怎么说的:
Falcon 是硬件传输协议领域的一项重大进步: 它是一种融合的(converged) NIC, 能够在标准的, 存在丢包, 乱序和路径多样性的以太网数据中心网络上工作, 为专用和通用的横向扩展应用提供高性能, 高效率和高可扩展性. Falcon 与现有硬件传输协议的根本不同之处在于, 它能够在无需复杂的网络配置或专用交换机的情况下, 提供可预测的性能和 CPU 效率, 同时保持与现有应用接口的兼容性. 其分层架构, 硬件辅助的可编程引擎, 原生多路径支持, 以及基于硬件的重传和错误处理机制, 共同造就了其高性能. Falcon 的开发吸收了来自软件传输协议的生产经验, 随着数据中心网络在规模和复杂性上持续增长, Falcon 根植于适应性(adaptability)的设计, 使其成为一个有前景的, 能服务于现有和未来应用的传输协议.
渣B的锐评
总体来看Falcon是一个非常不错的实现方案, 软硬件协同做的非常好. 关键的是它实现了在维持RDMA IBRC Verbs语义的兼容性下, 支持了多路径的转发能力和Lossy组网的能力. 但是第一个真正商用的是CIPU eRDMA, 并且400Gbps的CIPU eRDMA网卡已经在去年云栖大会发布, 今年伴随着阿里云ECS第九代服务器商用了. 而Google Falcon的400Gbps版本刚在Hotchips上发布(基于Intel IPU E2200).并且我们和Google都强调了一点, 无需依赖特殊的交换机和特殊的拓扑即可实现.
另一方面, 我想说的是自信一点, 中国人在一些局部的领域领先美国人是非常正常的一件事情. 至少CIPU eRDMA在这个领域是做到了的, 作为400Gbps的DPU不光是在RDMA上,在存储等各个领域上都是领先Nvidia BF3的.
期待CIPU下一个版本, 还会给大家带来什么惊喜呢?
参考资料[1] Falcon: A Reliable, Low Latency Hardware Transport: https://dl.acm.org/doi/10.1145/3718958.3754353