Linux I/O栈:如何精准定位性能瓶颈?
在Linux 系统的广袤世界里,I/O 性能犹如一座大厦的基石,支撑着整个系统的稳定运行和高效运作。从日常办公中的文件读写,到企业级应用里的数据存储与传输,I/O 操作无处不在。然而,当系统面临高并发的文件访问、大规模的数据传输或者复杂的存储架构时,I/O 栈的性能瓶颈就可能如潜伏的暗礁,随时让系统这艘巨轮触礁搁浅。
想象一下,在一个数据处理中心,大量的数据分析任务同时启动,每个任务都需要频繁地读取和写入海量的数据文件。此时,如果 I/O 栈无法高效地处理这些请求,就会导致任务执行缓慢,数据处理的时效性大打折扣,甚至可能引发整个系统的卡顿和崩溃。又比如在一个网络服务器集群中,众多用户同时访问服务器上的文件资源,I/O 性能的不足会使得用户体验急剧下降,访问延迟大幅增加,严重影响业务的正常开展。
这些因 I/O 性能瓶颈引发的问题,不仅在大型企业级场景中频繁出现,也在个人开发者的日常工作中时有发生。比如,在开发一个需要频繁读写本地文件的应用程序时,如果不能深入理解 Linux I/O 栈的工作原理,就很难发现和解决潜在的 I/O 性能问题,导致程序运行效率低下。因此,深入剖析 Linux I/O 栈,精准定位性能瓶颈,已经成为系统管理员、开发者和运维工程师们必须掌握的关键技能 。接下来,让我们一起揭开 Linux I/O 栈的神秘面纱,探寻性能瓶颈的定位之道。
Part1.Linux I/O 栈全景解析
1.1 I/O 栈架构总览
Linux I/O 栈宛如一座精心构筑的高楼大厦,自顶向下主要由文件系统层、通用块层和设备层这三个关键部分有序搭建而成。文件系统层作为与用户和应用程序交互的 “前沿阵地”,它以友好的姿态提供了诸如文件的创建、读取、写入和删除等一系列熟悉且便捷的操作接口,就像是大厦的大堂,直接面向用户,为用户提供各种服务入口 。通用块层则像是大厦的中层枢纽,它将来自上层的各种 I/O 请求进行整合与优化,精心规划这些请求的执行顺序,力求让整个 I/O 流程更加高效顺畅,如同大厦中层的调度中心,协调着各方资源。而设备层则如同大厦的根基,直接与物理存储设备紧密相连,切实执行 I/O 操作,是整个 I/O 栈的坚实基础,确保数据能够准确无误地在存储设备与内存之间传输 。
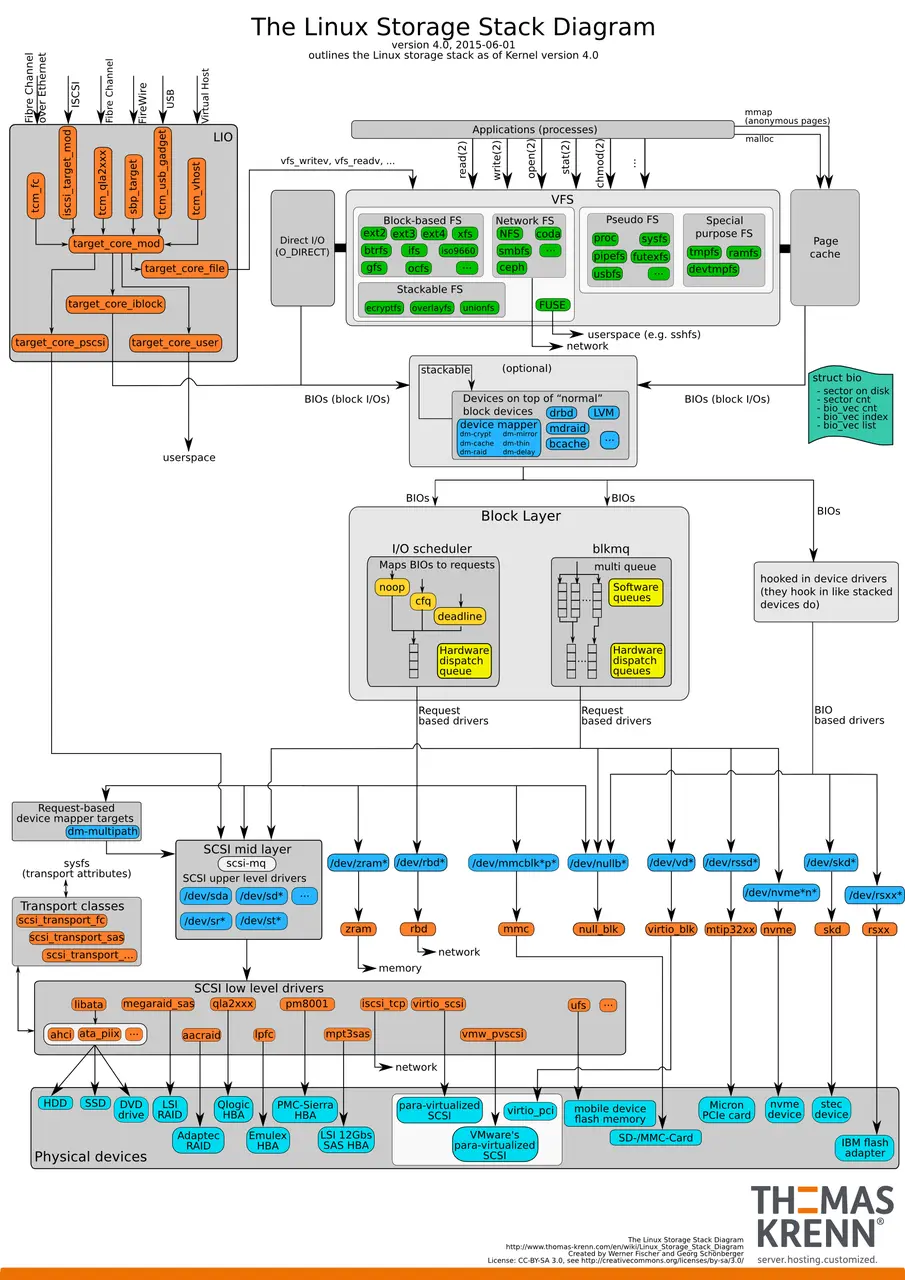 图片
图片
1.2文件系统层探秘
在文件系统层中,虚拟文件系统(VFS)无疑是最为闪耀的明星。它宛如一位神奇的翻译官,在各种形形色色的具体文件系统和上层应用程序之间搭建起了一座沟通的桥梁,提供了一套统一的标准接口。无论底层是古老经典的 ext4 文件系统,还是以高性能著称的 XFS 文件系统,又或是其他别具特色的文件系统,VFS 都能让它们在 Linux 系统中和谐共处,协同工作。就好比一个大型国际交流会议,VFS 就像是专业的同声传译,让来自不同国家、说着不同语言的参会者能够顺畅地交流合作。
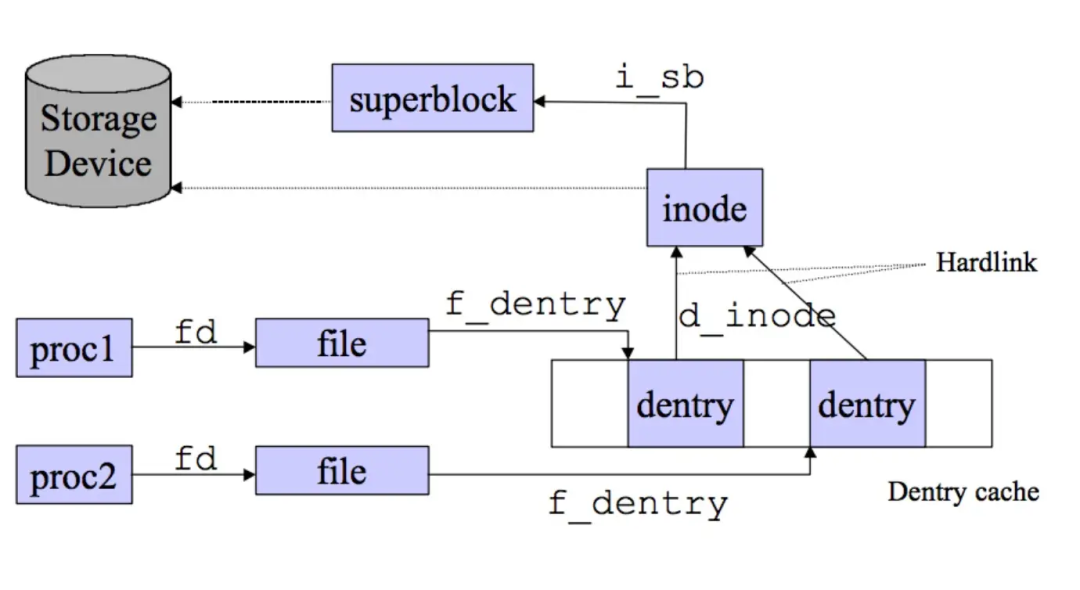 图片
图片
以 ext4文件系统为例,它凭借出色的稳定性和广泛的兼容性,成为了众多Linux发行版的默认选择,在个人电脑和中小型服务器领域广泛应用,就像一位可靠的老伙计,一直默默坚守在岗位上。而 XFS 文件系统则凭借其对大文件的高效处理能力和卓越的性能表现,在大型数据中心和云环境中崭露头角,成为了处理海量数据的得力助手 。
file: 存放一个文件对象的信息。
dentry: 存放目录项和其下的文件链接信息。
inode: 索引节点对象,存在具体文件的一般信息,文件系统中的文件的唯一标识。
superblock: 超级块对象,记录该文件系统的整体信息。在文件系统安装时建立,在文件系统卸载时删除。
值得一提的是,页缓存机制在文件系统层中也扮演着至关重要的角色。它如同一个智能的 “数据仓库”,会将频繁访问的数据预先存储在内存中,当应用程序再次请求相同的数据时,就可以直接从这个 “仓库” 中快速获取,而无需再去缓慢的磁盘中读取,大大提高了数据的访问速度,就像在图书馆中,将热门书籍放在最容易拿到的位置,方便读者快速借阅。
1.3通用块层剖析
通用块层堪称 Linux I/O 栈中的 “优化大师”,它对 I/O 请求施展了一系列精妙的 “魔法”。其中,请求合并功能就像是一位高效的整理员,会将多个连续的 I/O 请求巧妙地合并成一个大请求,从而有效减少设备驱动程序处理请求的次数,提升处理效率。例如,当有多个小文件的写入请求连续到来时,通用块层会将这些请求整合为一个大的写入请求,一次性发送给设备层,避免了多次重复操作带来的开销。
I/O 调度功能则如同一位经验丰富的交通指挥员,它会根据不同的调度算法,对 I/O 请求进行合理排序和调度,确保 I/O 操作能够高效执行。常见的 I/O 调度算法中,CFQ(Completely Fair Queuing)算法秉持着公平的原则,为每个进程维护独立的 I/O 调度队列,均匀分配时间片,就像一位公正的裁判,平等对待每一个进程,让它们都能公平地获得 I/O 资源,非常适合运行大量进程的系统,如桌面环境和多媒体应用 。而 DeadLine 算法则更像是一位急性子的 “救火队员”,它为读写请求分别创建队列,并且会优先处理那些达到最终期限的请求,确保数据能够及时响应,有效提高了机械磁盘的吞吐量,特别适合 I/O 压力大的场景,比如数据库系统,在那里每一秒的响应都至关重要 。
1.4设备层
设备层是 Linux I/O 栈中与硬件直接对话的 “实干家”。存储设备作为设备层的核心成员,其种类繁多,不同的存储设备有着各自独特的特性,这些特性也对 I/O 性能产生着显著的影响 。
机械硬盘(HDD)就像是一位 “老工匠”,虽然工作起来稍显迟缓,但胜在存储容量大、成本相对较低。它由盘片和读写磁头组成,数据存储在盘片的环状磁道中。在进行读写操作时,需要移动读写磁头定位到数据所在的磁道,这就导致它的随机 I/O 性能较差,因为频繁移动磁头会耗费不少时间,但在连续 I/O 场景下,由于不需要频繁寻址,它的表现还算不错 。
固态硬盘(SSD)则像是一位身手敏捷的 “短跑健将”,凭借其由固态电子元器件组成的结构优势,无需磁头寻址,在连续 I/O 和随机 I/O 性能方面都大幅超越机械硬盘。不过,SSD 也有自己的小 “短板”,随机 I/O 会受到 “先擦除再写入” 的限制,并且在进行随机 I/O 操作时可能会触发垃圾回收机制,这在一定程度上会影响性能 。
设备驱动程序则像是存储设备与内核之间的 “翻译官”,它负责将内核的 I/O 请求准确无误地转换为设备能够理解的指令,同时将设备的状态和数据反馈给内核,确保双方能够顺畅沟通,协同完成 I/O 操作 。
Part2.I/O 性能指标与解读
2.1文件系统 I/O 指标
在评估文件系统 I/O 性能时,多个关键指标为我们提供了深入洞察其运行状况的视角。空间使用率直观地反映了文件系统已使用空间在总空间中所占的比例。当空间使用率逼近 100% 时,犹如一个被塞得满满当当的仓库,不仅会导致文件创建和写入操作的速度大幅减缓,还可能因缺乏足够的剩余空间而引发各类错误,严重影响系统的正常运行 。
索引节点使用情况则聚焦于文件系统中索引节点(inode)的使用比例。索引节点作为文件系统的关键数据结构,如同文件的 “身份证”,详细记录了文件的权限、所有者、大小和创建时间等重要元信息。当索引节点使用率过高时,就像图书馆的索引卡片几乎被全部占用,新文件的创建就会因无法获取空闲的索引节点而受阻 。
缓存命中率是衡量文件系统性能的另一关键指标,它展示了从缓存中成功获取数据的请求在总请求中所占的比例。较高的缓存命中率,意味着文件系统能够像一位经验丰富的图书管理员,快速地从缓存这个 “常用书架” 中找到用户所需的数据,从而大大减少了对低速磁盘的访问次数,显著提升了数据访问速度 。
IOPS(Input/Output Operations Per Second)即每秒输入输出操作次数,它衡量了文件系统在单位时间内能够处理的 I/O 请求数量。在诸如数据库这类对数据读写速度要求极高的应用场景中,高IOPS就如同高速公路上高效运行的收费站,能够快速处理大量的车辆(I/O 请求),确保数据的快速读写,对系统性能起着决定性的作用 。
响应时间是指从I/O请求发出到收到响应所经历的时间,它直接反映了文件系统对请求的处理效率。较短的响应时间,能让用户在操作文件时感受到流畅和高效,就像在网购时能够迅速加载商品页面,极大地提升了用户体验 。
吞吐量表示单位时间内成功传输的数据量,在进行大规模数据传输时,如数据备份和视频流处理,高吞吐量就像一条宽阔的高速公路,能够让大量的数据快速通过,保证了数据传输的高效性 。
2.2磁盘 I/O 关键指标
磁盘使用率揭示了磁盘忙于处理 I/O 请求的时间在总时间中所占的比例。当磁盘使用率长期居高不下,接近或超过 80% 时,就如同一位过度劳累的工人,可能会出现力不从心的情况,导致 I/O 性能急剧下降,成为系统性能的瓶颈 。
IOPS 对于磁盘 I/O 性能评估同样至关重要,它体现了磁盘在每秒内能够处理的 I/O 请求数量。在随机读写频繁的场景中,如小文件存储和 OLTP(Online Transaction Processing)数据库应用,磁盘需要频繁地在不同的存储位置进行读写操作,此时 IOPS 就如同短跑运动员的爆发力,是衡量磁盘性能的关键指标 。
吞吐量代表了磁盘在单位时间内传输的数据量,在顺序读写大量连续数据的场景下,如电视台的视频编辑和视频点播(VOD)系统,高吞吐量就像一条畅通无阻的高速数据通道,能够确保大量的连续数据快速传输,保障了业务的流畅运行 。
响应时间是从 I/O 请求发出到完成所耗费的时间,它综合反映了磁盘的处理能力和效率。低响应时间就像快递能够快速送达,让用户能够及时获取所需的数据,对于对数据响应及时性要求高的应用程序来说,是至关重要的性能指标 。
Part3.定位性能瓶颈的实用工具
3.1 iostat:磁盘 I/O 洞察利器
iostat 是 Linux 系统中一款强大的磁盘 I/O 性能分析工具,如同一位专业的医生,能精准地为磁盘 I/O “把脉问诊” 。在大多数 Linux 发行版中,它包含在 sysstat 包内,使用前需确保已安装。若未安装,在 Ubuntu/Debian 系统中,可通过命令 “sudo apt - get install sysstat” 安装;在 CentOS/RHEL 系统中,使用 “sudo yum install sysstat” 命令进行安装 。
安装完成后,运行 “iostat -x 1” 命令,其中 “-x” 选项用于显示扩展统计信息,“1” 表示每秒更新一次数据。命令执行后,会输出类似如下数据:
这些数据中,“rrqm/s” 表示每秒合并的读请求数量,“wrqm/s” 是每秒合并的写请求数量,它们体现了请求合并的情况,合并操作可减少磁盘寻道时间,提升 I/O 性能。“r/s” 和 “w/s” 分别代表每秒读取和写入的操作数,反映了磁盘的读写操作频率 。“await” 是每次请求的平均等待时间(单位:毫秒),“% util” 表示磁盘当前的使用率 。
通过观察这些指标,能深入了解磁盘 I/O 性能。例如,若 “tps”(每秒的 I/O 传输次数)持续很高,表明磁盘 I/O 操作频繁,可能处于高负载状态;“rkB/s” 和 “wkB/s” 分别是每秒从磁盘读取和写入的数据量,若它们接近磁盘的最大传输速率,可能意味着磁盘带宽已成为性能瓶颈 。
3.2 pidstat:进程 I/O 分析助手
pidstat专注于进程I/O性能分析,能帮助我们轻松找出高 I/O 占用的进程,如同在茫茫人海中精准定位目标人物 。使用时,运行 “pidstat -d 1” 命令,“-d” 选项用于显示块设备相关的I/O统计信息,“1” 表示每秒输出一次结果 。
命令执行后,输出结果类似如下:
从输出中可以清晰看到每个进程的 “kB_rd/s”(每秒读取的千字节数)和 “kB_wr/s”(每秒写入的千字节数)等信息 。如上述示例中,“mysqld” 进程每秒读取 1024KB 数据,写入 512KB 数据;“java” 进程每秒写入 2048KB 数据,无读取操作 。通过这些数据,能快速定位到如 “java” 这样高 I/O 写入的进程,进而针对性地进行优化 。
3.3其他辅助工具
top 是一款实时监控系统整体资源使用情况的工具,就像一个全方位的监控器,能展示 CPU、内存、进程负载等信息 。在终端输入“top”命令,进入动态刷新的监控界面(默认 3 秒刷新一次) 。界面上半部分展示系统整体资源统计,包括 “load average”(系统 1/5/15 分钟的平均负载,数值≈CPU核心数时为饱和)、“% Cpu (s)”(其中 “us” 为用户进程占用CPU百分比,“sy” 为系统内核占用CPU百分比,“id” 为空闲CPU百分比,越高越好,“wa” 为 I/O 等待占用CPU百分比,高则可能存在磁盘瓶颈)以及内存 / 交换分区使用情况等 。下半部分是进程列表,默认按 CPU 使用率排序,通过关注 “% CPU”(进程占用 CPU 百分比)、“% MEM”(进程占用内存百分比)和 “S”(进程状态,“R” 为运行,“S” 为睡眠,“Z” 为僵尸进程)等指标,可快速发现占用大量资源的进程 。例如,若某个进程的 “% CPU” 占用率持续很高,可能是该进程存在性能问题,或者系统 CPU 资源不足;若有大量进程处于 “D”(不可中断睡眠)状态,可能表示系统存在 I/O 瓶颈,因为这些进程正在等待 I/O 操作完成 。
strace 用于跟踪系统调用,能详细展示进程执行的系统调用及其参数和返回值,如同为进程的系统调用操作拍摄 “特写镜头” 。运行 “strace -p [PID]” 命令(其中 “[PID]” 为要跟踪的进程 ID),可以查看指定进程的系统调用情况 。比如,当怀疑某个进程的 I/O 问题与系统调用相关时,使用 strace 跟踪该进程,通过分析输出结果,能了解进程在进行 I/O 操作时具体调用了哪些系统函数,以及这些调用的执行情况和返回值,从而找出潜在的问题,如系统调用错误、资源竞争等 。
lsof(List Open Files)用于查看系统中打开的文件信息,就像一本详细的文件打开目录,能显示打开文件的进程、文件类型、文件路径等 。运行 “lsof” 命令可查看系统中所有打开的文件;若要查看某个特定进程打开的文件,使用 “lsof -p [PID]” 命令 。在定位 I/O 瓶颈时,通过 lsof可以了解哪些文件被频繁访问,进而分析这些文件的访问模式和操作是否合理 。例如,若发现某个进程频繁打开和关闭大量小文件,可能会导致 I/O 性能下降,需要对该进程的文件操作进行优化 。
Part4.性能瓶颈定位实战
4.1案例背景与问题呈现
假设你负责维护一个基于 Linux 系统的 Web 服务器,该服务器承载着一个高流量的电商网站。最近,用户频繁反馈网站响应缓慢,页面加载时间过长,严重影响了用户购物体验和业务的正常开展。作为运维人员,你迅速对服务器进行排查,初步怀疑是 I/O 性能瓶颈导致了这一问题。
4.2排查步骤与分析思路
①初步系统检查:首先,使用 top 命令对系统的整体资源使用情况进行实时监控。在终端输入 “top” 后,发现 CPU 的 iowait 指标(即 CPU 等待 I/O 操作完成的时间百分比)持续处于较高水平,达到了 40% 左右,而正常情况下该值应在 10% 以下 。同时,CPU 的其他使用率指标如 user(用户态进程占用 CPU 百分比)和 sys(内核态进程占用 CPU 百分比)相对稳定,没有出现异常升高的情况;内存使用率也在合理范围内,没有明显的内存不足迹象。这一发现让我们将怀疑的重点聚焦到了 I/O 方面,因为较高的 iowait 通常意味着系统存在 I/O 性能问题,导致 CPU 不得不花费大量时间等待 I/O 操作完成 。
②磁盘 I/O 评估:为了进一步确定是否是磁盘 I/O 导致的性能瓶颈,使用 iostat 命令对磁盘 I/O 进行详细分析。运行 “iostat -x 1”(每秒更新一次扩展统计信息)后,观察到磁盘的使用率(% util)长期保持在 85% 以上,接近满负荷状态 。同时,IOPS(r/s 和 w/s 之和)相对较低,远低于该磁盘的正常性能指标 。平均等待时间(await)也明显增加,达到了 50 毫秒以上,而正常情况下应在 10 毫秒以内 。这些数据清晰地表明,磁盘I/O存在严重的性能瓶颈,磁盘的高使用率和低 IOPS 导致了 I/O 请求的大量积压和等待,进而影响了整个系统的响应速度 。
③进程 I/O 排查:确定磁盘 I/O 存在问题后,需要找出是哪些进程在占用大量的 I/O 资源。通过 pidstat 命令来实现这一目标,运行 “pidstat -d 1”(每秒输出一次块设备相关的 I/O 统计信息) 。结果显示,一个名为 “php-fpm” 的进程的 I/O 读写量非常高,其每秒读取的数据量(kB_rd/s)达到了 5000KB 以上,每秒写入的数据量(kB_wr/s)也有 2000KB 左右,远远超过了其他进程 。这表明 “php-fpm” 进程很可能是导致磁盘 I/O 性能瓶颈的罪魁祸首,由于它频繁地进行大量的 I/O 操作,使得磁盘处于高负载状态,无法及时响应其他进程的 I/O 请求 。
④深入问题定位:为了深入了解 “php-fpm” 进程的 I/O 行为,结合 strace 和 lsof 命令进行进一步分析。首先,使用 strace 跟踪 “php-fpm” 进程的系统调用,运行 “strace -p [php-fpm 进程 ID]” 。从输出结果中发现,该进程频繁地进行文件读写操作,并且在一些系统调用上出现了较长的等待时间,如 “read” 和 “write” 系统调用的返回时间明显增加 。接着,使用 lsof 查看 “php-fpm” 进程打开的文件,运行 “lsof -p [php-fpm 进程 ID]” 。发现该进程正在频繁访问网站的日志文件和缓存文件,这些文件的读写操作非常频繁,而且由于文件的大小和访问模式不合理,导致了 I/O 效率低下 。综合分析 strace 和 lsof 的结果,最终确定问题的根源是 “php-fpm” 进程对日志文件和缓存文件的不合理读写操作,导致磁盘 I/O 负载过高,从而影响了整个 Web 服务器的性能 。