前言
大家好,我是田螺。
记得之前一位同事,分享他入职的故事。他说,刚来新公司,想查看一个表的索引,居然忘记命令啦~~ 其实一些常用的mysql命令,虽然网上也是很快能查到,但还是都记住比较好~ 这样会显得你基础很扎实!
本文总结了我日常工作,常用的mysql命令。小伙伴们收藏起来,慢慢看哈!
1. 连接mysql的命令
我们经常需要连接mysql数据库,用以下命令:
复制
mysql -u username -p -h host_name -P port_number1.
有些时候,我们要远程连接 MySQL,也是同样道理:
复制
mysql -u username -p -h remote_host_ip -P 33061.
remote_host_ip:远程 MySQL 服务器的 IP 地址。3306:MySQL 默认端口(如果是其他端口,修改为相应端口)。
2. 查看当前 MySQL 正在运行的所有线程及其状态
SHOW PROCESSLIST 命令返回一个包含当前活动的连接线程的列表,每个连接线程的状态、运行的查询等信息。它对于诊断性能问题、查看阻塞查询、监控数据库健康状态非常有用。

3. 查看系统变量
很多时候,我们需要查看mysql的一些变量。比如,你要查看是否开启了慢查询日志:
复制
show variables like slow_query_log;1.
而有些伙伴可能会这样查,加了个GLOBAL:
复制
show global variables like slow_query_log;1.
show variables like slow_query_log; 默认查询的是当前会话(连接)或实例的变量。show global variables 显式地查询的是 全局变量,即当前整个 MySQL 实例的配置。
其实除了慢查询日期是否开启,还有很多配置变量查询(大家如果要查其他变量,类似这样就好),如下:
复制
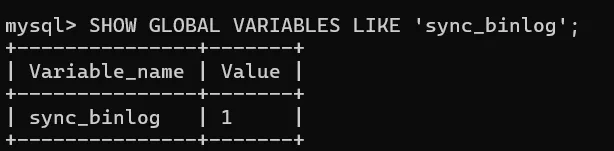
show global variables like sync_binlog;1.
 图片
图片
sync_binlog 的作用:用于设置 MySQL 在写入二进制日志时的同步策略。
如果设置为 1,表示 每次写操作后都强制将二进制日志刷写到磁盘,以确保数据持久性。如果设置为0,表示不强制每次写操作后刷新二进制日志,而是通过操作系统的缓存来控制。这种设置通常会带来更好的性能,但在崩溃恢复时可能会丢失一部分数据。
4.查看加锁信息
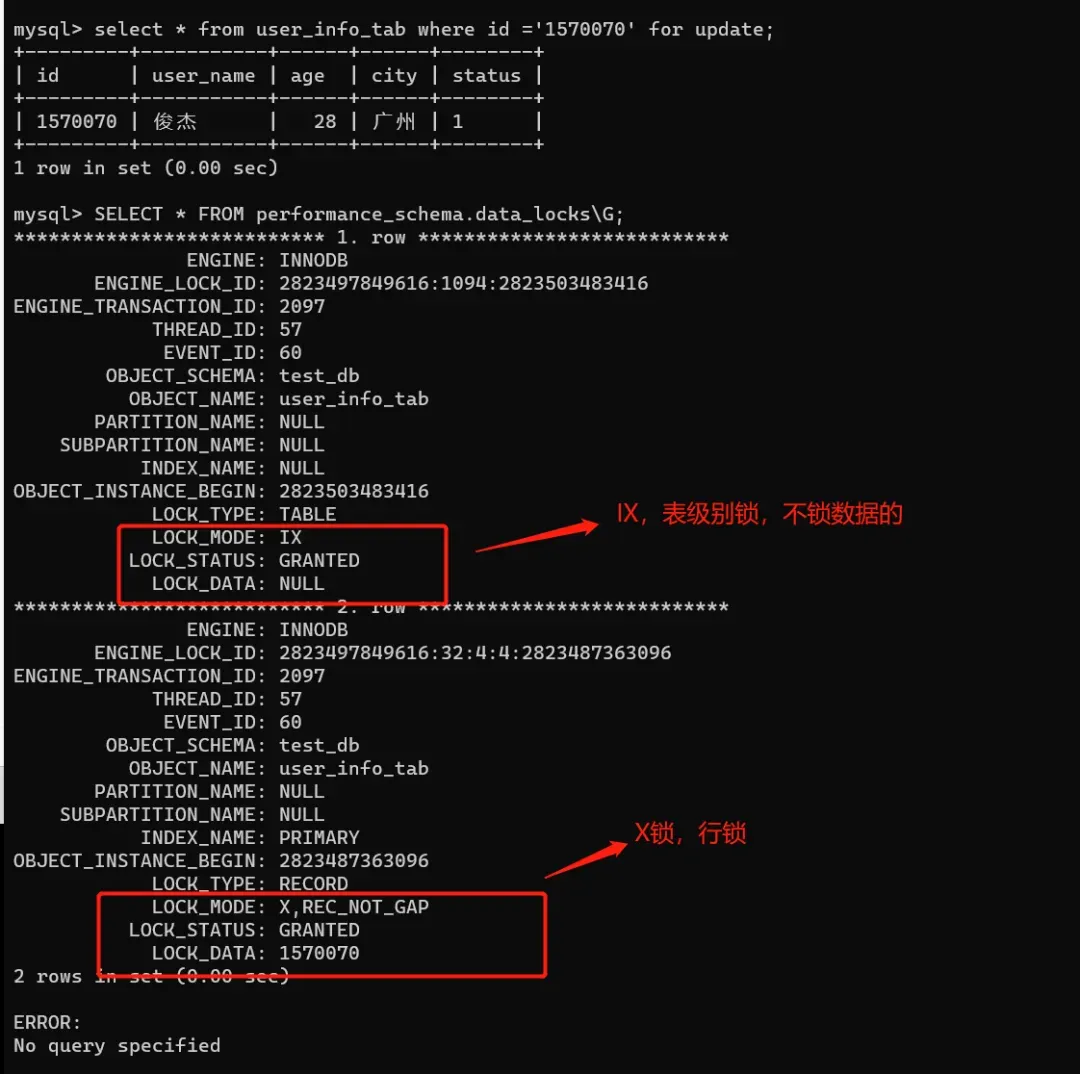
有些时候,我们看某个SQL加了什么锁,可以这样(MySQL 8.0+版本):
复制
SELECT * FROM performance_schema.data_locks\G;1.
它用于查询MySQL数据库中当前持有的和请求的数据锁信息。这些信息包括锁的类型、状态、持有者等
 图片
图片
5. 查看和设置隔离级别
有些时候,我们需要查看数据库的隔离级别、或者设置隔离级别。
复制
select @@tx_isolation; -- 查看当前会话的事务隔离级别
select @@global.tx_isolation; -- 查看全局的事务隔离级别1.2.
设置数据库隔离级别:
复制
set global TRANSACTION ISOLATION level read COMMITTED;1.
6. 操作索引(查看、新增、删除)
查看某个表的索引有多种方法。
最简单的就是直接:show index from table_name;
复制
mysql> show index from user_tab;
+----------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+--------------------------------------------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+----------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+--------------------------------------------------+---------+------------+
| user_tab | 0 | PRIMARY | 1 | id | A | 4 | NULL | NULL | | BTREE | | | YES | NULL |
| user_tab | 0 | email | 1 | email | A | 4 | NULL | NULL | | BTREE | | | YES | NULL |
| user_tab | 0 | unique_username | 1 | username | A | 4 | NULL | NULL | | BTREE | | | YES | NULL |
| user_tab | 0 | idx_user_id | 1 | user_id | A | 4 | NULL | NULL | YES | BTREE | | user_id字段的唯一索引,确保user_id在整个表中唯一 | YES | NULL |
+----------+------------+-----------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+--------------------------------------------------+---------+------------+1.2.3.4.5.6.7.8.9.
也可以直接查看表结构,也可以看到索引:
复制
mysql> show create table user_tab;1.
 图片
图片
如果是新增索引:
复制
ALTER TABLE table_name
ADD INDEX index_name (column1, column2, ...);1.2.
删除索引:
复制
ALTER TABLE table_name DROP INDEX index_name;1.
7. 查看死锁日志
我在排查死锁日志的时候,经常用到
复制
show engine innodb status1.
这个mysql命令,用于显示 InnoDB 存储引擎的当前状态信息。
主要包括这些:
锁信息:包括当前持有的锁、等待的锁以及死锁的历史记录。事务信息:当前活跃的事务、事务的等待状态等。缓冲池信息:InnoDB 缓冲池的使用情况、脏页的数量、缓冲池中的读写操作等。日志信息:重做日志(redo log)和回滚日志(undo log)的状态。行操作统计:比如每秒插入、更新、删除的行数。
这是是我之前排查死锁问题,用show engine innodb status看到的日志:
 图片
图片
8. 查看有哪些数据库、哪些表
如果没有图形界面,我们查看数据库,需要这样的命令:
复制
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sakila |
| sys |
| test_db |
| test_db_00 |
| test_db_01 |
| world |
| xxl_job |
+--------------------+1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.
选择某个库,查看它的所有表:
复制
mysql> use test_db;
Database changed
mysql> show tables;
+------------------------+
| Tables_in_test_db |
+------------------------+
| user_info_tab |
| user_score |
| user_score_tab |
| user_tab |
| users |
+------------------------+1.2.3.4.5.6.7.8.9.10.11.12.
9. 查看未提交的事务
复制
SELECT * FROM information_schema.innodb_trx;1.
这条 SQL 语句用于查看当前 InnoDB 存储引擎中未提交的事务。information_schema.innodb_trx 表提供了关于当前活跃事务的信息,这对于诊断长时间运行的事务、死锁问题或了解事务的当前状态非常有用。
10.查看存储引擎支持情况
有些时候,我们要查看当前数据库服务器支持的存储引擎,可以用这两个命令:
复制
SHOW ENGINES; -- 会列出所有可用的存储引擎以及它们是否默认启用
SELECT * FROM information_schema.ENGINES; --information_schema 数据库包含了关于 MySQL 服务器实例的元数据。你可以查询 ENGINES 表来获取存储引擎的信息。1.2.
复制
mysql> SHOW ENGINES;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| ndbinfo | NO | MySQL Cluster system information storage engine | NULL | NULL | NULL |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| ndbcluster | NO | Clustered, fault-tolerant tables | NULL | NULL | NULL |+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.
11.查看数据库字符集与排序规则
查询当前数据库的字符集:
复制
SHOW VARIABLES LIKE character_set_database;1.
查询当前数据库的排序规则:
复制
SHOW VARIABLES LIKE collation_database;1.
还可以用这个:
复制
SELECT * FROM information_schema.schemata;1.
复制
mysql> SELECT * FROM information_schema.schemata;
+--------------+--------------------+----------------------------+------------------------+----------+--------------------+
| CATALOG_NAME | SCHEMA_NAME | DEFAULT_CHARACTER_SET_NAME | DEFAULT_COLLATION_NAME | SQL_PATH | DEFAULT_ENCRYPTION |
+--------------+--------------------+----------------------------+------------------------+----------+--------------------+
| def | mysql | utf8mb4 | utf8mb4_0900_ai_ci | NULL | NO |
| def | information_schema | utf8mb3 | utf8mb3_general_ci | NULL | NO |
| def | performance_schema | utf8mb4 | utf8mb4_0900_ai_ci | NULL | NO |
| def | sys | utf8mb4 | utf8mb4_0900_ai_ci | NULL | NO |
| def | sakila | utf8mb4 | utf8mb4_0900_ai_ci | NULL | NO |
| def | world | utf8mb4 | utf8mb4_0900_ai_ci | NULL | NO |
| def | test_db | utf8mb4 | utf8mb4_0900_ai_ci | NULL | NO |
| def | test_db_00 | utf8mb4 | utf8mb4_0900_ai_ci | NULL | NO |
| def | test_db_01 | utf8mb4 | utf8mb4_0900_ai_ci | NULL | NO |
| def | xxl_job | utf8mb4 | utf8mb4_unicode_ci | NULL | NO |
+--------------+--------------------+----------------------------+------------------------+----------+--------------------+1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.
12. SQL 导入导出
导出特定的表:
复制
mysqldump -u your_username -p your_database_name table1 table2 > export_file.sql1.
导出数据库结构而不包含数据:
复制
mysqldump -u your_username -p --no-data your_database_name > structure_only.sql1.
导入整个 SQL 文件:
复制
mysql -u your_username -p your_database_name < import_file.sql1.
13. 创建表、新增列、在某个字段后新增列
创建表的语句:
复制
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
email VARCHAR(100) NOT NULL
);1.2.3.4.5.
使用 ALTER TABLE 语句来向表中添加新的列:
复制
ALTER TABLE users ADD COLUMN age INT;1.
有些时候,我们想把新字段加在某个字段之后,从 MySQL 8.0.19 开始,可以直接使用 AFTER column_name 语法来指定列的位置。例如:
复制
ALTER TABLE users ADD COLUMN age INT AFTER email;1.
14. 存储过程,插入大量数据
有些时候,我们为了做测试,或者验证,需要往一个表插入很多数据,可以用存储过程~:
假设先有个用户表:
复制
CREATE TABLE user_tab (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL
);1.2.3.4.
接下来,创建一个存储过程来批量插入数据:
复制
DELIMITER //
CREATE PROCEDURE BatchInsertUsers(IN numUsers INT)
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= numUsers DO
INSERT INTO user_tab (username)
VALUES (CONCAT(user, i));
SET i = i + 1;
END WHILE;
END //
DELIMITER ;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.
调用这个存储过程并插入数据:
复制
CALL BatchInsertUsers(100);1.
15.创建视图
所谓视图,它为用户提供了一个虚拟的表结构,这个结构是基于SQL查询定义的。视图本身并不存储实际的数据,而是存储了一个查询语句,当用户查询视图时,数据库系统会执行这个查询语句,并返回结果集给用户,就好像用户正在查询一个实际的表一样。
假设我们的表,进行了分库分表,平时测试环境,如何查这些数据比较方便呢?
就是新建个视图,然后查这个视图就好啦~~
假设你有两个相同的表 user_table_1 和 user_table_2,它们分别存储在不同的分片中,且都有 id 和 username 字段。你可以创建一个视图来查询这两个表中的所有数据:
复制
CREATE VIEW all_users AS
SELECT id, username FROM user_table_1
UNION ALL
SELECT id, username FROM user_table_2;1.2.3.4.
有了视图,我们通过简单地查询 all_users 视图来获取所有相关数据啦~~