Java 程序员的 Linux 性能调优宝典:三大经典场景深度剖析
本文整理了Linux系统性能问题排查的通用方法论和实践,将针对以下三个经典场景展开探讨:
I/O性能瓶颈CPU飙升偶发CPU飙升同时考虑到笔者文章的受众面大部分都是Java开发人员,所以复现问题故障的例子也都采用Java进行编码部署复现,对应的示例也都会在案例排查的最后展开说明。

一、应用程序延迟升高
第一个案例是用户反馈系统延迟升高,网卡打开缓慢。从开发者的角度一定要明白,所有表现为卡顿、延迟的原因很大概率是系统资源吃紧,只有在资源分配不足的情况下,才会导致程序运行阻塞,无法及时处理用户的请求。
关于服务器的阈值指标,按照业界通用的经验,对应CPU和内存的负载要求的合理上限为:
CPU使用率控制在75%左右内存使用率控制在80%以内虚拟内存尽可能保持在0%负载不超过CPU核心数的75%笔者一般会先通过top查看操作系统的CPU利用率,这里笔者因为是个人服务器原因则采用更强大、更直观的htop查看个人服务器的资源使用情况,对应的安装指令如下:
而本次htop输出的指标如下:
服务器为6核,对应的CPU使用率分别是3.9、0、0、2.7、0.7、1.4,按照业界的通用标准,当前服务器各核心CPU使用率较低,但需结合系统负载综合判断Mem代表了内存使用率,内存一般情况下是用于存储程序代码和数据,分为物理内存和虚拟内存,物理内存显示内存接近8G仅用了1G不到,使用率不到80%,说明资源冗余Swp显示交换空间即虚拟内存的使用情况,可以看到也仅仅用了32M,并没有大量的内存数据被置换到交换空间,结合第2点来看,内存资源充足Tasks显示进程数和线程数一共有35个进程,这35个进程对应100个线程处理,Kthr显示指标为0说明有0个内核线程,而Running为1说明有一个用户进程在运行而系统平均负载近1分钟为4.96,按照业界标准CPU核心数*0.75作为系统负载的运算阈值,如果超过这个值则说明系统处于高负载状态,很明显我们的6核服务器系统负载偏高了综合来看,服务器系统负载偏高但各CPU核心使用率较低,结合内存使用情况,问题可能出现在I/O资源等待上,此时我们就要从I/O资源角度进一步排查问题:

我们从I/O资源排查入手,通过vmstat 1执行每秒一次的监控指标输出,以笔者的服务器为例,可以看到如下几个指标:
r:按照文档解释为The number of runnable processes (running or waiting for run time)即正在运行或等待运行的进程数,如果大于CPU核心数则说明CPU处于过载状态,而当前服务器这个值为0,说明队列处理状态良好b::按照文档解释为The number of processes blocked waiting for I/O to complete即等待I/O完成的进程数,从参数b可以看出有大量进程等待I/O,说明当前服务器存在I/O瓶颈。swpd:the amount of swap memory used即交换空间也就是虚拟内存的使用,而当前服务器已被使用30468说明存在缓存置换,由此参数结合buff(缓存中尚未写入磁盘的内容)和cache(从磁盘加载出来的缓存数据)来看,当前内存资源持续升高,存在读写虚拟内存的情况,存在I/O性能瓶颈。从bo来看有大量任务进行每秒写块针对CPU一个板块输出的us(用户代码执行时间)、sy(内核执行时间)、id(空闲时间)、wa(等待I/O的时间),其中wa即等待I/O的时间持续处于一个高数值的状态,更进一步明确CPU在空转,等待I/O完成,而I/O资源处于吃紧的状态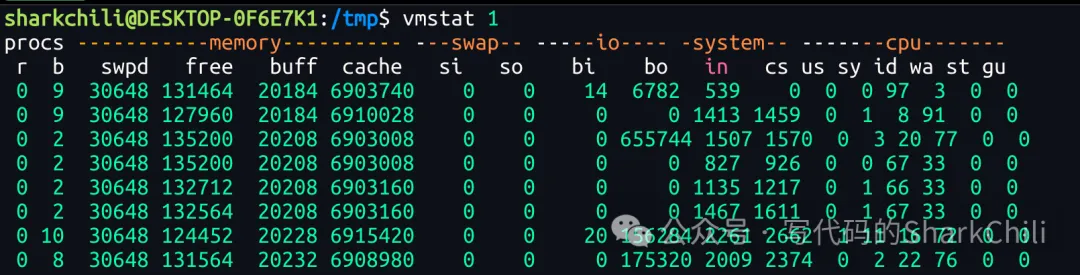
考虑为I/O资源瓶颈,我们优先从网络I/O角度排查问题,这里笔者采用nload进行网络资源诊断,如果没有下载的可以自行通过yum或者apt的方式自行下载,这里笔者也贴出ubuntu服务器的下载指令:
键入nload实时输出网络带宽的使用情况,可以看到:
输入流量(incoming)即下载流量,当前网速基本控制在1KB,仅在最大网速的20%左右,一般认为只有当前网速无限接近于最大网速才可认为带宽使用率接近饱和输出流量(outgoing)即上传流量,同理当前也仅仅使用8%,也未达到饱和的阈值所以I/O资源吃紧的问题原因并非网络I/O,我们需要进一步从服务器磁盘I/O角度进一步排查:

所以从这些指标来看,存在大量的线程在等待I/O资源的分配而进入阻塞,所以笔者基于iostat -x 1使每一秒都输出更详细的信息,可以看到sdd盘对应的磁盘忙碌百分比util基本跑满100%,已基本接近饱和,此时基本是确认有大量线程在进行I/O读写任务了,且查看I/O读写指标:
每秒读写的吞吐量w/s为175每秒写入wkB/s的172704KBSSD盘util即I/O资源利用率为100%,已经远超业界阈值60%,说明存在I/O性能瓶颈,需要补充说明的是当CPU100%时进程调度会因为操作系统优先级设置的原因并不会导致进程阻塞,但是I/O设备则不同,它不能区分优先级进行I/O中断响应,所以这个数值高的情况下就会使得大量I/O请求阻塞写请求的平均等待时间w_await为5151ms换算下来172704KB/175每秒写入的速率为987KB每秒,由此可确定因为磁盘性能读写性能瓶颈导致大量I/O读写任务阻塞,进而导致服务器卡顿,用户体验差:

所以,对于系统延迟严重的情况,整体排查思路为:
通过top指令查看CPU使用率,若正常进入步骤2基于vmstat查看内存使用率和I/O资源情况基于nload查看网络I/O使用情况基于iostat查看网络I/O和磁盘I/O情况最终确认问题本例子的最后笔者也给出本次故障问题的示例代码:
二、系统操作卡顿
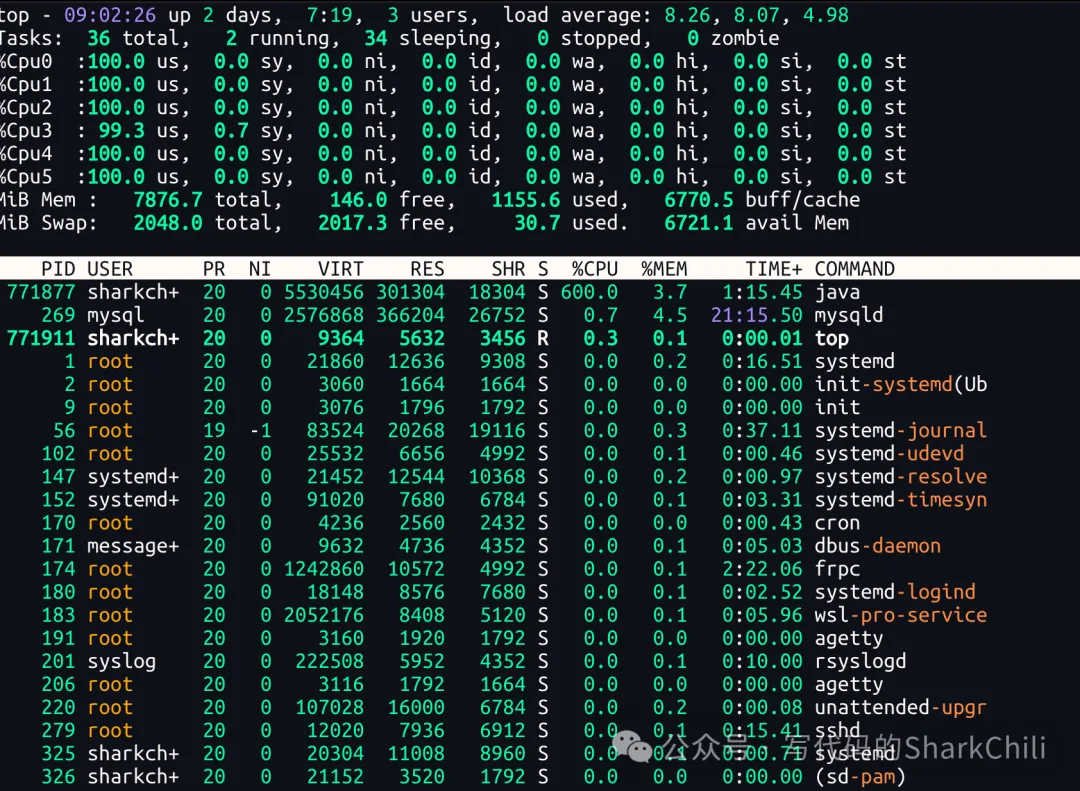
第二个例子也同样是用户反馈系统操作卡顿感严重,整体点击响应非常慢,我们还是考虑资源吃紧,优先使用top指令查看资源使用情况,从top指令来看:
输出us查看各个核心的CPU使用率跑满系统平均负载基本超过70%(6*0.7)已经超过4.2这就是经典的计算密集型任务跑满所有线程的经典例子:
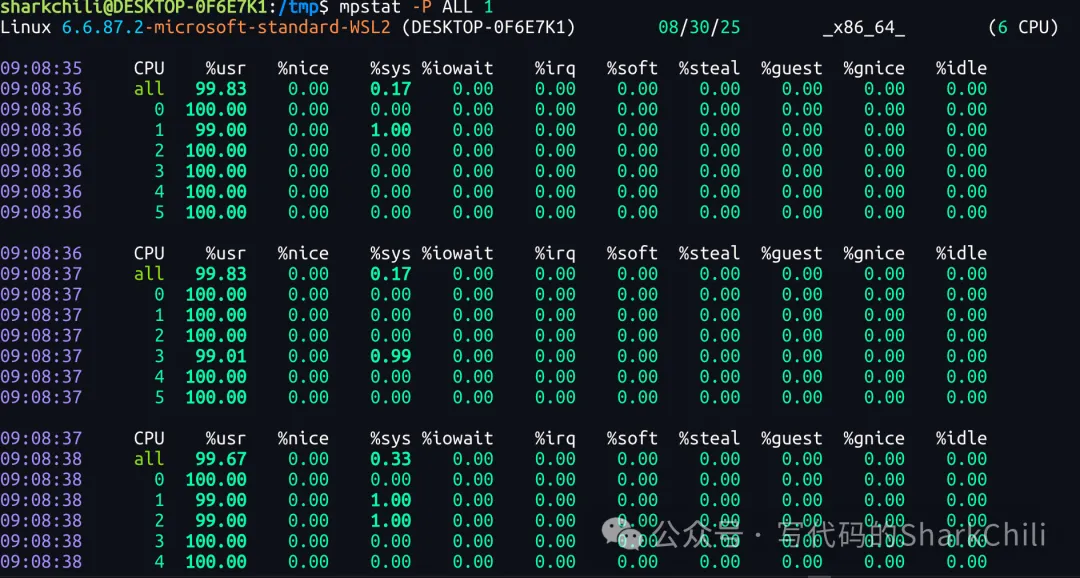
一般针对CPU跑满的问题,笔者一般会通过mpstat -P ALL 1查看CPU时间片是否分配均衡,是否出现偏斜导致CPU过热的情况,例如所有运算任务都往一个CPU核心上跑,经过笔者每秒1次的输出持续观察来看,整体资源吃紧,但并没有出现资源分配偏斜的情况,同时内存资源使用率也不高,也没有大量的iowait等待:
结合第一步top指令定位到的进程是Java进程,笔者索性通过Arthas直接定位故障代码,首先通过thread锁定问题线程,可以看到pool-前缀的线程基本都是跑满单个CPU,所以我们就可以通过thread id查看线程的栈帧:
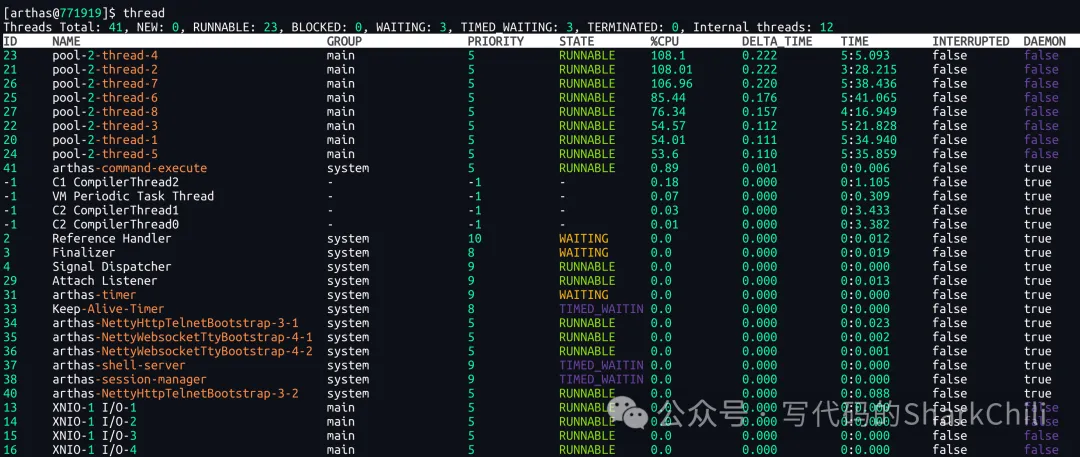
最终锁定到了这段代码段,即一个密集的循环运算的线程:

对应的笔者也贴出故障代码段示例,来总结一下系统使用卡顿的排查思路:
基本top查看用户态和内核态CPU使用率用户态使用率偏高,通过mpstat查看CPU使用是否偏斜,是否保证CPU亲和力如果CPU使用没有出现偏斜,则直接通过问题定位到Java进程,结合Arthas快速定位问题线程进行诊断三、持续的偶发性系统卡顿问题排查
此类问题比较棘手,系统偶发卡顿意味着是瞬时、频繁的资源吃紧,我们还是直接使用top指令无法明确立刻捕捉到进程,可能刚刚一看到飙升的进程就消失了。
同理使用mpstat、vmstat指令无法准确定位到超短期飙升问题的进程,而基于iostat也没有看到明显的I/O资源吃紧,所以我们可以采用perf指令解决问题,以笔者的Ubuntu服务器为例,对应的安装步骤:
在笔者完成安装并启动之后,系统抛出WARNING: perf not found for kernel xxxx的异常,对应的解决方案是要主动安装linux-tools-generic并定位到linux-tools目录下找到自己的generic版本完成符号链接,以笔者本次安装为例就是6.8.0-79:
完成上述安装之后,我们就可以通过将频率降低设置为99并将监控结果导出到tmp目录下的perf.data中:
可能很多读者好奇为什么需要将频率设置为99Hz,这样做的目的是为了避免与系统定时器中断频率(通常为100Hz)同步,从而避免锁步采样导致的偏差。
锁步采样是指采样频率与系统定时器中断频率相同或成倍数关系时,采样点会固定在相同的时间位置上,导致采样结果不能准确反映系统整体的性能状况。
使用99Hz这样的素数频率可以减少与系统周期性活动同步的概率,从而获得更全面、更准确的性能数据。
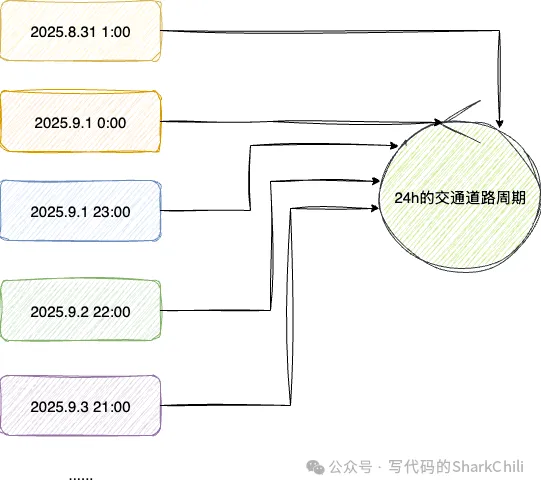
举个简单的例子,若我们试图确定道路是否出现拥堵,且通过24h一次的抽检查,那么当前样本就可能与交通保持一个平行的同步状态,例如:
交通车流情况在每天8点-12点拥堵,而我们的程序也是恰好在每天9点采集,那么它就会认为交通情况异常拥堵若每天14点进行一次采集那么就避开了交通阻塞的高峰期则会得到一个相反的、也是不正确的结论为了规避相同周期频率导致的lockstep即锁同步采样,我们可以适当降低频率避免与交通周期时间同步,保证一天的数据能够在一个周期内被完整地采集到,而本例最好的做法就是将定时间隔改为23h,这样一来每个23天的样本周期就会得到一天中所有时间的数据就能做到全面地了解到交通情况:
等待片刻后perf指令就会将结果输出到perf.data目录下:
此时,通过sudo perf report查看报告,可以看到一个pid为1115751的Java进程对应线程CPU使用率飙升到86,此时我们就可以基于这条信息到指定的进程上查看该线程是否存在密集的运算:

最后我们也给出本示例的问题代码:
四、小结
本文针对应用延迟、系统卡顿、偶发频繁卡顿三种常见的系统故障给出通用普适的排查思路,整体来说此类问题归根结底都是系统资源吃紧,需要找到饱和的资源结合代码推测根源并制定修复策略,以本文为例,通用的排查思路都为:
基于top查看CPU、内存、负载若CPU未饱和则通过vmstat查看I/O资源使用情况明确I/O瓶颈通过nload和iostat查询是网络I/O还是磁盘I/O若上述排查都无果,且CPU负载偶发飙高,可通过perf并调整频率监控系统定位系统中异常运行的资源结合上述推断结果查看是否是异常消耗,如果是则优化代码,反之结合情况增加硬件资源