当访问无效内存时:Linux缺页中断的处理流程
在 Linux 系统中,程序运行时操作的 “内存地址” 并非都直接对应物理内存 —— 当代码试图访问未建立映射的 “无效内存”(比如越界访问数组、读写已释放的内存块)时,CPU 不会直接让程序崩溃,而是触发一种关键的内存管理机制:缺页中断。它就像系统的 “内存应急调节器”,一边拦截非法访问请求,一边衔接虚拟内存与物理内存的映射逻辑,是 Linux 保障内存安全、避免单个程序错误拖垮系统的核心环节。
那么,当 “无效内存访问” 发生时,缺页中断的处理流程会如何启动?首先 CPU 会暂停当前进程的执行,保存进程上下文(比如寄存器值、程序计数器),随后跳转到内核的缺页中断处理程序;接下来内核会先判断 “无效内存” 的本质 —— 是单纯的地址越界(完全非法的内存请求),还是虽未映射但属于进程合法地址空间的 “待加载页”?不同场景下,系统会给出截然不同的处理:是向进程发送SIGSEGV(段错误)信号终止程序,还是默默加载物理页、更新页表后让进程继续运行?这背后的逻辑,正是理解 Linux 内存保护与动态映射机制的关键。
一、缺页中断:虚拟内存管理的核心枢纽
1.1什么是缺页中断?
在 Linux 的内存管理体系中,缺页中断(Page Fault)是一个极其关键的概念。当进程访问的虚拟地址对应的物理页不在内存中时,CPU 就会触发一种硬件异常机制,这便是缺页中断 。简单来说,就好像你去图书馆找一本书,你知道这本书的编号(虚拟地址),但在书架(物理内存)上却找不到它,这时就触发了 “缺页” 情况,图书馆系统(操作系统)需要去仓库(磁盘)把这本书调出来放到书架上,这个过程就伴随着缺页中断的处理。
Linux 通过缺页中断实现了一种 “按需分页” 的策略,它不会在进程启动时就把所有可能用到的数据都加载到物理内存中,而是仅在需要时才将磁盘数据加载到物理内存 。这种策略大幅提升了内存的使用效率,让系统可以在有限的内存资源下运行更多的进程,就像一个聪明的图书管理员,不会一次性把所有书都摆在书架上,而是等读者需要时再去取,节省了书架空间(内存)。
缺页异常被触发通常有两种情况:
程序设计的不当导致访问了非法的地址;访问的地址是合法的,但是该地址还未分配物理页框。malloc()和mmap()等内存分配函数,在分配时只是建立了进程虚拟地址空间,并没有分配虚拟内存对应的物理内存。当进程访问这些没有建立映射关系的虚拟内存时,处理器自动触发一个缺页异常。
在请求分页系统中,可以通过查询页表中的状态位来确定所要访问的页面是否存在于内存中。每当所要访问的页面不在内存时,会产生一次缺页中断,此时操作系统会根据页表中的外存地址在外存中找到所缺的一页,将其调入内存。缺页本身是一种中断,与一般的中断一样,需要经过4个处理步骤:
保护CPU现场分析中断原因转入缺页中断处理程序进行处理恢复CPU现场,继续执行缺页中断的处理流程:
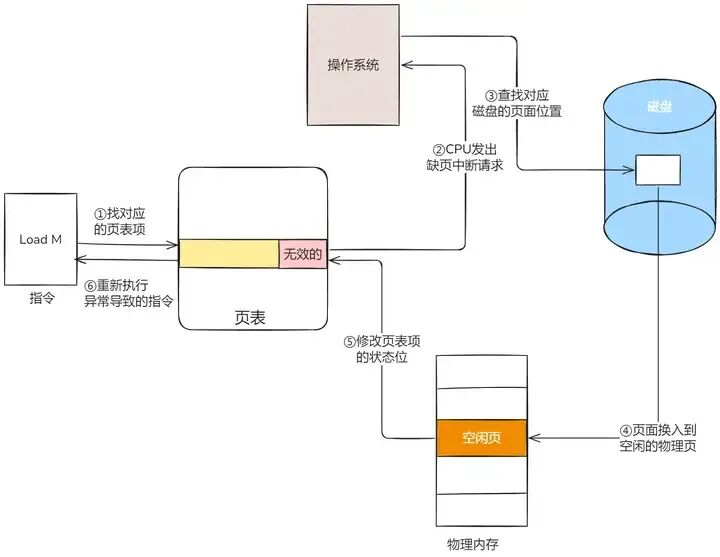 图片
图片
上面所说的过程,第 4 步是能在物理内存找到空闲页的情况,那如果找不到呢?
找不到空闲页的话,就说明此时内存已满了,这时候,就需要「页面置换算法」选择一个物理页,如果该物理页有被修改过(脏页),则把它换出到磁盘,然后把该被置换出去的页表项的状态改成「无效的」,最后把正在访问的页面装入到这个物理页中。
页表项通常有如下图的字段:
 图片
图片
所以,页面置换算法的功能是,当出现缺页异常,需调入新页面而内存已满时,选择被置换的物理页面,也就是说选择一个物理页面换出到磁盘,然后把需要访问的页面换入到物理页。
1.2核心价值:虚拟内存的 “按需供给”
在进程申请内存时,Linux 采用延迟分配策略。以 C 语言中的 malloc 函数为例,当我们调用 malloc 申请内存时,它并不会立即分配物理页,而是先为进程分配虚拟地址 。只有当进程首次访问这些虚拟地址时,才会真正触发物理页的分配,这就是所谓的 “惰性分配”。这种方式避免了内存的浪费,因为如果一个进程申请了内存但一直没有使用,那么就不会占用实际的物理内存资源,就好比你预订了一个房间(虚拟地址),但你没入住(未访问)之前,房间(物理内存)其实还可以被其他人使用。
Linux 利用写时复制(Copy - on - Write,COW)技术实现内存复用 。当多个进程共享同一块内存区域时,初始状态下它们共享相同的物理页,并且这些页被标记为只读。当其中一个进程试图对共享内存进行写操作时,系统才会为该进程分配一个新的物理页,并将原共享页的数据复制到新页中,然后该进程对新页进行写操作,而其他进程仍然共享原来的只读页。例如,在父子进程关系中,子进程通过 fork 创建时,它与父进程共享大部分内存,只有在某个进程需要修改共享内存时才会触发物理页的复制,这样大大节省了内存空间,多个进程就像合租室友,客厅(共享内存)大家先一起用,谁想改造客厅(写操作),就自己再单独弄一个类似的空间(新物理页)。
Swap 空间是虚拟内存的重要组成部分,它让系统能够突破物理内存的限制 。当物理内存不足时,系统会将一些不常用的物理页的数据保存到磁盘的 Swap 空间中,腾出物理内存给更需要的进程使用。当这些被换出的页再次被访问时,系统又会将它们从 Swap 空间读回物理内存。这就像是给内存增加了一个 “外挂”,让系统在逻辑上拥有比实际物理内存更大的内存空间,实现了 “虚拟内存大于物理内存” 的假象 ,就如同你有一个小衣柜(物理内存),但还有一个储物箱(Swap 空间),当衣柜放不下东西时,就把不常用的衣物放到储物箱里,需要时再取出来。
二、触发缺页中断的四大典型场景
2.1页面未加载:首次访问的 “惰性加载”
当进程首次访问一个刚刚分配但还未映射到物理页的虚拟地址时,就会触发这种类型的缺页中断 。例如,在 C 语言中使用 malloc 函数分配内存时,系统只是为进程在虚拟地址空间中划分了一块区域,并没有立刻分配物理页。直到进程首次对 malloc 返回的地址进行写入或读取操作时,才会触发缺页中断 。这就像是你租了一间毛坯房(虚拟地址),在你第一次想要在里面摆放家具(访问数据)时,才需要真正去装修布置(分配物理页)。
此时,内核会启动请求调页机制,它会在磁盘中找到对应的数据(如果是可执行文件的代码段或数据段,就从可执行文件中读取;如果是匿名映射的内存,可能是之前被换出到磁盘的页),将其加载到物理内存中,并建立虚拟地址到物理地址的映射关系 ,这样进程就可以继续访问该地址了。
请求调页是虚拟内存系统的核心特性,当进程首次访问未映射物理页的虚拟地址时触发。操作系统在进程创建或内存分配(如 malloc)时,仅分配虚拟地址空间,不立即分配物理内存。当程序实际访问该地址时,CPU 通过页表发现页表项的有效位为 0,触发缺页中断。内核响应后,分配物理页并建立虚拟地址到物理页的映射,实现 “按需加载”,显著提升内存使用效率。
案例实现:动态内存访问触发的首次缺页
以 C 语言程序为例,调用 malloc 分配 1MB 内存时,内核仅创建虚拟地址区间,未分配物理页。当程序首次写入该内存区域时触发缺页中断:
内核通过缺页中断处理函数(如 Linux 中的 do_page_fault)处理缺页,若判断为合法访问且页未存在(页表项有效位为 0),则调用 alloc_page 分配匿名页(无文件 backing)或 handle_mm_fault 处理文件映射页。以下为简化的内核处理逻辑伪代码:
通过请求调页,操作系统实现了高效的内存利用,只有在真正需要时才将数据加载到物理内存,减少了内存占用和初始化时间,提升了系统整体性能。
2.2页面被换出:内存紧张时的 “置换回归”
当物理内存不足时,页面交换机制启动,这是操作系统维持系统运行的关键策略。在多进程环境下,众多进程对内存的需求总和往往超过物理内存的容量。此时,操作系统会将那些长时间未被访问的页面换出(Page-out)到磁盘的交换分区(Swap),释放对应的物理页框,以便为更急需内存的进程或数据提供空间。这些被换出的页面在磁盘上有专门的存储位置,通过页表与进程的虚拟地址空间保持关联。
当进程后续再次访问这些已被换出到磁盘的页面时,就会触发缺页中断。这是因为 CPU 在页表中查找对应的物理页框时,发现页面不在内存中(页表项的驻留位为 0)。内核接收到这个缺页中断后,会启动页面换入(Page-in)流程。它首先在磁盘的交换分区中找到对应的页面数据,然后分配一个空闲的物理页框,将磁盘上的页面数据读取到该页框中。之后,内核更新页表,将虚拟地址与新分配的物理页框建立映射关系,并将页表项的驻留位设置为 1,表示页面已在内存中。最后,进程恢复对该页面的访问,继续执行被中断的指令。
这种由于页面从磁盘交换分区换入内存而触发的缺页称为 “major fault”。与 “minor fault”(如请求调页、写时复制等不涉及磁盘 I/O 的缺页情况)相比,“major fault” 的开销明显更高。因为磁盘 I/O 操作的速度远远低于内存访问速度,一次磁盘 I/O 操作可能需要几毫秒甚至更长时间,而内存访问通常只需要几纳秒。频繁的 “major fault” 会导致系统性能大幅下降,因为大量的时间都消耗在等待磁盘数据传输上。因此,操作系统需要精心设计页面置换算法(如 LRU、Clock 等),尽量减少不必要的页面交换,提高内存使用效率和系统整体性能。
一旦触发这种缺页中断,内核会从 Swap 分区中找到对应的页面数据,将其读取回物理内存,然后更新页表,将虚拟地址重新映射到新恢复的物理页上 ,让进程能够继续访问这些数据,就好像你把冬天的衣服(不常用页面)放到了地下室(Swap 分区),当冬天再次来临(再次访问页面)时,就需要从地下室把衣服拿出来(从 Swap 读回内存)。
案例实现:主动触发页面换出与换入
在 Linux 系统中,我们可以通过echo 3 > /proc/sys/vm/drop_caches命令释放页缓存,结合stress工具模拟内存压力,主动触发页面交换。stress工具可以产生 CPU、内存、I/O 等各种系统压力,这里我们利用它的内存压力测试功能。假设系统内存有限,我们通过stress分配大量内存,使系统内存不足,从而迫使操作系统将部分页面换出到磁盘交换分区:
上述命令中,--vm 4表示启动 4 个内存分配进程,--vm-bytes 1G表示每个进程分配 1GB 内存,--vm-keep表示持续占用分配的内存。执行这些命令后,观察系统的内存使用情况(如通过top或free -h命令),可以看到内存逐渐被耗尽,交换分区开始被使用,页面被换出。
为了进一步验证页面换入,我们可以在页面被换出后,再次访问这些内存区域。例如,使用如下 Python 代码:
在这段代码中,首先创建一个 1GB 大小的文件,然后将其映射到内存中。当使用mm.read(1024)访问映射内存时,如果之前该部分页面已被换出,就会触发页面换入,从磁盘交换分区加载页面数据到内存。对于被换出到磁盘交换分区的页面,其页表项会存储该页面在交换分区中的地址信息。在内核中,通过检查页表项的驻留位(如PTE_PRESENT)来判断页面是否在内存中。当驻留位为 0 时,表明页面不在内存,可能在磁盘交换分区。
以 Linux 内核为例,缺页中断处理函数(如do_page_fault)在处理换入缺页时,会调用handle_mm_fault函数进一步处理。handle_mm_fault函数会根据页表项中的信息,判断该页面是否来自交换分区。如果是,它会调用swapin_readahead函数从交换分区读取页面数据。swapin_readahead函数负责与磁盘 I/O 子系统交互,将页面数据从磁盘读入内存缓冲区,然后分配物理页框,将缓冲区中的数据复制到物理页框中。
最后,更新页表项,将虚拟地址与新分配的物理页框建立映射,并设置页表项的驻留位和其他相关标志位,完成页面换入操作,使进程能够继续访问该页面。通过这一系列复杂而有序的内核处理流程,实现了内存与磁盘之间的数据高效交换,保障了系统在内存资源紧张情况下的正常运行 。
2.3写入保护冲突:写时复制的 “分家时刻”
写时复制(COW)是一种非常巧妙的内存优化技术,它常出现在多进程共享内存的场景中,比如在使用 fork 系统调用创建子进程时 。当父进程通过 fork 创建子进程后,子进程和父进程在初始阶段共享同一块物理内存页面,并且这些页面被标记为只读。这就好比两兄弟(父子进程)一开始住在同一间屋子里(共享物理页),并且规定大家都不能随意改造屋子(只读)。
当其中一个进程(无论是父进程还是子进程)试图对共享的只读页面进行写入操作时,就会触发缺页中断 。这是因为此时的页面是只读的,写入操作违反了页面的访问权限。内核检测到这种写保护冲突后,会为发起写操作的进程分配一个新的物理页,并将原共享页的数据复制到新页中 。之后,该进程就可以在新的可写物理页上进行写入操作,而其他进程仍然共享原来的只读页,两兄弟就各自拥有了自己可以随意改造的屋子(独立可写副本),实现了内存资源的高效利用。
案例实现:fork 子进程后的写操作触发中断
以下是一个简单的 C 语言代码示例,展示了 fork 子进程后,子进程写入共享内存时如何触发写时复制缺页中断:
在这个示例中,父进程创建了共享内存并 fork 出子进程。子进程尝试写入共享内存时,会触发写时复制机制,因为共享内存页最初是只读共享的。这一过程中,内核会处理缺页中断,为子进程分配新的物理页并复制数据,确保写入操作的正确性和独立性。在内核层面,通过页表项的标志位来检测 COW 页。通常,页表项中有一个 “只读标志”(如 PTE_RDONLY)用于标记页面是否只读,以及一个专门的 “写时复制标志”(如 PTE_COW,在不同系统中可能有不同定义)用于标识该页是否为 COW 页。
当发生缺页中断时,内核的缺页处理程序(如 Linux 中的 do_page_fault 函数)会检查引发缺页的操作是否为写操作(通过检查 CPU 状态寄存器或错误码),以及对应的页表项是否设置了 COW 标志。如果满足这些条件,即判断为写时复制缺页:
上述代码展示了内核如何在缺页处理中识别 COW 页,并在写操作时进行页面复制和页表更新。通过这种机制,写时复制技术在保证内存高效利用的同时,确保了进程间内存访问的安全性和独立性 。
2.4非法访问:内存安全的 “守卫机制”
当进程访问了一个未分配的虚拟地址,比如程序中出现了野指针,指针指向了一个不确定的、未被分配给该进程的内存区域 ;或者进程试图越权访问受保护的内存区域,典型的例子就是用户态进程尝试访问内核空间的内存 ,这些情况都会触发缺页中断。这种缺页中断属于致命错误,内核通常会发送 SIGSEGV 信号给该进程,以终止它的运行,就像保安(内核)发现有人(进程)试图闯入禁区(非法内存区域),会立即将其赶走(终止进程)。这是操作系统保障内存安全的重要手段,防止一个进程的错误访问影响到整个系统的稳定性和安全性 ,确保每个进程都只能在自己被授权的内存空间内活动。
非法访问缺页中断是内存保护机制的关键防线,当进程试图访问未分配、越界或受保护的内存地址时触发。例如,使用空指针解引用(如int *p = NULL; *p = 10;)或访问内核空间的地址(用户态进程非法访问内核内存区域),都会引发此类中断。
CPU 在进行地址转换时,会检查页表项中的权限位,这些权限位包括读写权限标志(如 PTE_R 和 PTE_W,分别表示读和写权限)以及用户态 / 内核态标志(如 PTE_U,用于区分用户态和内核态访问权限)。如果当前进程的访问权限与页表项的权限位不匹配,比如用户态进程试图写入被标记为只读的页面(即页表项中 PTE_W 位为 0,但进程进行写操作),CPU 会触发缺页中断,并将控制权交给操作系统内核。
内核在接收到缺页中断后,会进一步判断中断原因是否为非法访问。如果确定是非法访问,内核通常会向引发异常的进程发送SIGSEGV信号(段错误信号)。这个信号会导致进程异常终止,防止其继续执行可能导致系统不稳定或安全漏洞的非法内存访问操作。在某些调试场景下,调试器可以捕获这个信号,允许开发者对异常程序进行调试分析,查找问题根源。
案例实现:空指针解引用引发段错误
下面的 C 语言代码展示了如何通过空指针解引用触发非法访问缺页中断:
在这段代码中,ptr被初始化为NULL,即空指针。当程序尝试通过*ptr = 10;解引用这个空指针时,CPU 会发现ptr指向的内存地址未被分配或不具备访问权限,从而触发缺页中断。由于这是明显的非法访问,内核会判定该行为违规,向进程发送SIGSEGV信号,导致程序崩溃并输出段错误信息。
在内核层面,主要通过检查错误码和地址范围来识别非法访问。以 x86 架构为例,缺页中断发生时,CPU 会将一个错误码压入栈中,这个错误码包含了丰富的信息。其中,第 0 位表示 “页不存在”(PF_PRESENT),第 1 位表示 “写操作”(PF_WRITE,1 表示写,0 表示读),第 2 位表示 “用户态访问”(PF_USER,1 表示用户态,0 表示内核态)。
内核通过检查这些位来初步判断访问类型。例如,如果错误码中 PF_PRESENT 位为 0,说明访问的页面不存在;如果 PF_WRITE 位为 1 且页面被标记为只读(即页表项中的写权限位为 0),则可能是写保护错误;如果 PF_USER 位为 1 且访问的地址属于内核空间,那么就是用户态进程非法访问内核区域。
此外,内核还会检查访问地址是否在进程的合法虚拟地址空间范围内。每个进程都有其独立的虚拟地址空间,由vm_area_struct结构体描述(在 Linux 内核中),内核通过查找这个结构体来确定地址是否合法。如果地址不在任何vm_area_struct描述的范围内,就判定为非法访问。通过上述机制,内核能够准确识别非法访问行为,及时采取措施保护系统安全,防止恶意程序或错误代码对内存的非法操作 。
三、从硬件到内核:缺页中断的完整处理流程
3.1硬件层:MMU 的异常捕获(以 ARMv7-A 为例)
在硬件层面,内存管理单元(MMU)扮演着至关重要的角色,它负责虚拟地址到物理地址的转换 。以 ARMv7-A 架构为例,当 CPU 执行内存访问指令时,MMU 会根据页表对虚拟地址进行解析 。
假设我们有一个用户程序试图写入 0x00008000 这个虚拟地址 。MMU 在解析页表时,如果发现对应的页表项中的 valid 位为 0,这就意味着该虚拟地址所对应的物理页当前不在内存中,即发生了地址转换失败 。此时,MMU 会向 CPU 报告一个数据中止异常(Data Abort) 。
一旦 CPU 接收到这个异常信号,它会迅速切换到中止模式,将当前指令地址保存到 LR_abt 寄存器中 ,这个寄存器就像是一个 “书签”,记录了异常发生时程序执行到的位置,方便后续恢复 。同时,CPU 会跳转至异常向量表中对应的入口,在 ARMv7-A 架构中,数据中止异常对应的向量表入口地址通常是 0xFFFF0010 。这一系列操作就像是在高速公路上开车,突然遇到前方道路施工(地址转换失败),车辆(CPU)不得不切换到应急车道(中止模式),并记录下当前的位置(保存指令地址),然后前往特定的处理点(异常向量表入口)寻求解决方案 。
3.2内核层:三级处理逻辑
当硬件层将异常信息传递给内核后,内核会按照一套严谨的三级处理逻辑来应对缺页中断 。
(1)合法性校验:内核首先会通过 DFAR(Data Fault Address Register)寄存器获取故障地址 ,这个寄存器就像是异常发生现场的 “定位器”,精准地指出问题出在哪里 。接着,内核会查询进程的虚拟内存区域(VMA),以此来判断该访问是否属于合法访问 。
非法访问:如果判断结果为非法访问,比如进程试图访问空指针,这就好比有人拿着一把错误的钥匙试图打开一扇门,内核会毫不留情地直接发送 SIGSEGV 信号给该进程 。这个信号就像是一声严厉的警告,告知进程它的行为是不被允许的,进程收到这个信号后通常会终止运行,以避免对系统造成进一步的破坏 。合法缺页:若访问是合法的缺页情况,内核会根据错误码(error code)来判断操作类型,是读操作还是写操作,以及是发生在用户态还是内核态 。这一步就像是医生在诊断病情时,不仅要确定病人是否生病,还要搞清楚病症的具体类型和严重程度,以便后续对症下药 。(2)页面加载策略:根据不同的操作类型,内核会采取不同的页面加载策略 。
读缺页:如果是读缺页情况,内核需要判断页面数据的来源 。若页面数据在磁盘上,比如是可执行文件的一部分,或者是之前被换出到 Swap 空间的页,内核会启动直接内存访问(DMA)机制,将数据从磁盘加载到物理内存中 ,这个过程就像是从仓库(磁盘)中搬运货物(数据)到货架(物理内存)上 。若页面是未分配的匿名页,内核会分配新的物理页,并将其清零,为后续存储数据做好准备 ,就像在货架上腾出一个全新的空位来放置新的货物 。写缺页:对于写缺页,情况会稍微复杂一些 。若页面是 COW 共享页,这就好比多个进程合租了一套房子(共享页),当其中一个进程想要对房子进行改造(写操作)时,内核会为该进程复制原页到新的物理页,并更新页表权限 ,这样每个进程就有了自己独立的可写空间,避免了相互干扰 。若为普通写操作,内核会检查页表的写权限,若权限不足,会分配可写的物理页,确保写操作能够顺利进行 ,就像确保租客有权利对自己的房间进行装修一样 。(3)页表更新与上下文恢复:当页面成功加载到物理内存后,内核会将物理页帧号(PFN)写入页表项,并设置 valid 位为 1 ,表示该页已经存在于内存中,可供进程访问 ,这就像是在图书馆的目录系统(页表)中更新书籍(页面)的位置信息 。同时,内核会恢复 CPU 的上下文,例如在 ARM 架构中,会将 SPSR_abt 寄存器的值恢复到 CPSR 寄存器中 ,这就像是将车辆从应急车道重新开回正常车道,让程序能够继续从异常发生的地方继续执行,仿佛什么都没有发生过一样 ,最后重新执行引发缺页的指令,完成整个缺页中断的处理流程 。
四、缺页中断分类:Minor vs Major 的性能分水岭
在 Linux 的内存管理中,缺页中断根据其处理过程和对系统性能的影响程度,可分为次缺页(Minor Fault)和主缺页(Major Fault) ,这两种类型就像是内存管理中的 “轻骑兵” 与 “重炮兵”,有着截然不同的特点和性能表现 。
4.1次缺页(Minor Fault):内存内的轻量操作
次缺页中断是一种相对 “温和” 的内存访问异常,它的显著特点是无需访问磁盘 。当进程访问的虚拟地址对应的物理页不在内存中,但系统可以在内存中直接分配一个新的物理页,或者通过写时复制(COW)机制从已有的共享页复制数据到新页 ,这种情况下就会触发次缺页中断 。例如,在进程首次访问匿名页时,由于该页尚未被分配物理内存,系统会直接在内存中为其分配一个新的物理页 ,就像你在图书馆的书架上发现一个空位(内存中的空闲物理页),可以直接把新书(匿名页数据)放上去;又比如在 COW 写操作中,当多个进程共享同一物理页,其中一个进程试图写入时,系统会从共享页复制数据到新页 ,这就好比几个租客原本共用一个房间(共享物理页),当其中一个租客想对房间进行改造(写操作)时,房东(系统)会给他分配一个新房间(新物理页)并复制原房间的布置(数据)。
次缺页中断的开销相对较小,通常只需要 1 - 10 微秒 。这主要是因为它的操作主要集中在内存内部,涉及的是 CPU 寄存器操作和页表更新 ,例如更新页表中的物理页帧号(PFN),以及可能的 CPU 缓存和转换后备缓冲器(TLB)的更新 。这些操作虽然需要消耗一定的 CPU 周期,但相比于磁盘 I/O 操作,其速度要快得多,就像是在电脑上复制文件,速度远远快于从外部硬盘读取文件。
在程序初始化阶段,大量的内存分配操作会导致次缺页中断频繁发生 。比如一个大型 C++ 程序在启动时,会为各种全局变量、堆内存分配空间 ,这些新分配的内存页首次被访问时就会触发次缺页中断 ,就像新开业的商场,在开业初期需要为各个店铺(内存分配)准备商品(数据),首次摆放商品时就会触发类似的 “缺页” 情况;在多线程编程中,当多个线程共享内存区域并进行写操作时,COW 机制会引发次缺页中断 ,例如多个线程共享一个数据结构,当其中一个线程尝试修改该数据结构时,就会触发次缺页中断来进行数据复制,保证每个线程有自己独立的可写副本 ,就像多个同事共同编辑一份文档(共享内存),当其中一个同事想要修改文档时,系统会为他生成一个独立的副本(新物理页)供其修改。
4.2主缺页(Major Fault):跨内存与磁盘的重量级交互
主缺页中断是一种 “重量级” 的内存访问异常,其核心特点是必须从磁盘加载数据 。当进程访问的页面数据当前不在内存中,且之前被换出到磁盘的 Swap 分区,或者是可执行文件的一部分在磁盘上尚未被加载到内存时 ,就会触发主缺页中断 。例如,当系统内存不足,将一些不常用的页面换出到 Swap 分区,后续进程再次访问这些页面时 ,系统就需要从 Swap 分区中将数据读取回内存,这就像你把冬天的衣服(不常用页面)放到了地下室(Swap 分区),当你再次需要穿这些衣服时,就必须从地下室把它们拿出来(从 Swap 读回内存);又比如程序在运行过程中需要访问一个尚未被加载到内存的动态链接库文件(存储在磁盘上),此时也会触发主缺页中断来从磁盘读取相关页面数据 ,就像你在玩游戏时,游戏需要加载一个新的地图文件(动态链接库),而这个文件在硬盘上,就需要从硬盘读取到内存中才能使用。
主缺页中断的开销要比次缺页中断大得多,大约在 1 - 10 毫秒 。这主要是因为它涉及到磁盘 I/O 操作,磁盘的读写速度远远低于内存 。在从磁盘读取数据的过程中,需要经过直接内存访问(DMA)传输,将数据从磁盘控制器传输到内存 ,并且还需要等待磁盘寻道、旋转等机械操作完成 ,这就好比从一个大型图书馆的仓库(磁盘)中找一本书,需要花费时间在仓库中查找(寻道)、搬运(DMA 传输),而不像在书架(内存)上找书那么快。
高频的主缺页中断会对系统性能产生严重的负面影响 。由于每次主缺页中断都伴随着磁盘 I/O 操作,这会导致 CPU 的内核态占用率飙升 ,因为内核需要花费大量时间来处理磁盘 I/O 请求、管理 DMA 传输以及更新页表 ,就像一个繁忙的交通枢纽,大量的车辆(I/O 请求)涌入,导致交通管制人员(CPU 内核)忙得不可开交;
同时,程序的响应延迟会加剧,因为进程需要等待磁盘数据加载完成才能继续执行 ,这对于那些对实时性要求较高的应用程序来说是致命的 ,比如在线游戏,玩家的操作响应可能会因为主缺页中断导致的延迟而变得迟钝,影响游戏体验;在内存不足的情况下,频繁的主缺页中断会引发 Swap 颠簸 ,即系统不断地将页面换出到磁盘又换入内存,使得系统性能急剧下降,整个系统就像陷入了一个恶性循环,越忙越乱,越乱越慢 。
五、高频缺页中断的性能优化策略
5.1程序级优化:改善内存访问模式
在程序设计中,充分利用数据的局部性原理是减少缺页中断的有效手段。例如,在 C 语言中,数组的内存布局是连续的,当我们按顺序访问数组元素时,由于数据的空间局部性,大部分情况下数据会在同一个物理页中,从而减少跨页访问 。相比之下,链表的节点在内存中是分散存储的,每次访问下一个节点都可能导致一次新的页面访问,大大增加了缺页中断的概率 。所以,在可能的情况下,应优先选择数组来存储频繁访问的数据,就像把经常使用的工具放在一个固定的、容易拿到的地方,而不是分散在各个角落,这样可以显著减少缺页中断的发生,提高程序的执行效率 。
大页(Huge Pages)技术可以有效减少页表条目数量,提升转换后备缓冲器(TLB)的命中率 。在 Linux 中,我们可以通过 mlock () 系统调用锁定关键内存区域,确保这些区域使用大页内存 。例如,对于一个数据库应用程序,其数据缓存区是性能关键区域,我们可以使用 mlock () 将这部分内存锁定,使其使用大页 。同时,也可以通过修改内核参数,如在 /sys/kernel/mm/hugepages/ 目录下设置相关参数,来启用系统级的大页支持 ,为应用程序提供更大的页面尺寸,减少页表项的数量,让 TLB 能够缓存更多的地址映射,就像把书架上的小格子合并成大格子,能存放更多的书,提高了查找效率 。
野指针是程序中内存访问错误的常见来源,它可能导致非法内存访问,进而触发缺页中断 。地址 sanitizer(ASan)是一个强大的工具,它可以在程序运行时检测非法内存访问 。在编译程序时,我们可以通过添加编译选项,如在 GCC 中使用 -fsanitize=address 选项,启用 ASan 。这样,当程序中出现野指针访问时,ASan 会捕获到这些错误,并输出详细的错误信息,帮助我们定位和修复问题 ,就像给程序安装了一个 “安全卫士”,时刻监控内存访问,防止非法操作导致的缺页中断,保障程序的稳定性和安全性 。
5.2系统级调优:平衡内存与磁盘交互
Swappiness 是一个内核参数,它控制着系统将内存页换出到 Swap 分区的倾向,其默认值通常为 60 。当 Swappiness 值较高时,系统会更积极地将内存页换出到磁盘,以释放物理内存 。然而,在内存充足的情况下,这种主动换页可能是不必要的,会增加系统开销 。我们可以通过修改 /etc/sysctl.conf 文件,添加或修改 vm.swappiness = [想要的值] ,例如将其设置为 10,来降低系统使用 Swap 的倾向 ,减少不必要的磁盘 I/O 操作,让系统在内存充足时尽量使用物理内存,就像一个节俭的管家,不到万不得已不会动用储备物资(Swap 空间) 。修改完成后,执行 sysctl -p 命令使配置生效 。
对于一些对延迟非常敏感的应用程序,如数据库服务器、实时通信系统等,我们不希望它们的核心数据被换出到磁盘 。这时,可以使用 mlock () 系统调用将这些应用程序的关键内存区域锁定在物理内存中 。例如,在一个 C 语言编写的数据库应用中,我们可以在初始化阶段调用 mlock () 函数,将数据库的缓存区、索引区等关键内存区域锁定 ,确保这些区域的数据始终在内存中,避免因数据被换出而导致的主缺页中断,保证应用程序的高性能和稳定性 ,就像给重要文件加上了锁,防止被随意挪动 。
监控与诊断工具:
perf stat -e page-faults:这是一个强大的性能分析工具,通过 perf stat -e page-faults 命令,我们可以统计指定进程的缺页次数 。例如,要分析一个名为 myapp 的应用程序的缺页情况,只需执行 perf stat -e page-faults./myapp ,它会输出该进程在运行过程中的缺页中断次数,帮助我们了解该进程的内存访问模式,判断是否存在频繁的缺页问题 ,就像一个精准的计数器,记录下程序运行中缺页的次数 。vmstat -s:vmstat 命令用于监控系统的虚拟内存、进程、CPU 等活动情况 。使用 vmstat -s 可以查看系统级的 Major Fault 和 Minor Fault 总数 ,让我们对整个系统的缺页情况有一个宏观的了解 。它会输出一系列统计信息,包括内存使用情况、交换空间使用情况以及各种缺页中断的次数 ,就像一张系统状态的全景图,展示出系统在内存管理方面的整体状况 。dmesg | grep -i page:dmesg 命令用于显示内核环形缓冲区的消息 。通过执行 dmesg | grep -i page ,我们可以追踪内核中与缺页相关的日志信息 。这些日志包含了详细的缺页中断发生的时间、原因、涉及的进程等信息 ,帮助我们深入分析缺页问题的根源,就像一个侦探在现场寻找线索,通过这些日志信息来解开缺页中断背后的谜团 。5.3硬件级升级:突破性能瓶颈
最直接有效的方法之一就是增加物理内存 。当系统内存不足时,会频繁发生页面换入换出操作,导致大量的主缺页中断 。通过增加物理内存,可以扩大系统的内存容量,使更多的进程工作集能够常驻内存 ,减少对磁盘 Swap 空间的依赖,从而降低主缺页中断的发生频率 。例如,对于一个内存紧张的服务器,原本在运行多个应用程序时频繁出现性能问题,增加内存条后,内存充足,应用程序运行更加流畅,主缺页中断大幅减少,就像给一个小仓库扩充了空间,货物(数据)有了更多的存放地方,不用频繁地搬运(换页) 。
传统的机械硬盘由于其机械结构,读写速度相对较慢,在发生主缺页中断时,从机械硬盘读取数据的延迟会严重影响系统性能 。NVMe SSD 采用高速闪存技术和高性能接口,读写速度比机械硬盘快数倍甚至数十倍 。将系统的存储设备升级为 NVMe SSD,可以显著降低主缺页中断时的磁盘访问延迟 。当进程需要从磁盘加载页面数据时,NVMe SSD 能够快速响应,减少等待时间,提升系统整体性能 ,就像把一条崎岖的乡间小路(机械硬盘)升级为高速公路(NVMe SSD),车辆(数据传输)行驶更加快捷 。
透明大页(THP)是 Linux 内核的一项特性,它允许内核自动将连续的小页合并为大页 。启用 THP 后,进程在使用内存时可以获得更大的页面,从而减少页表项的数量,提高 TLB 命中率 。在大多数 Linux 系统中,可以通过修改 /sys/kernel/mm/transparent_hugepage/enabled 文件来启用或禁用 THP 。例如,将其设置为 always 表示始终启用 THP 。不过,需要注意的是,THP 在某些情况下可能会导致内存碎片化问题 ,因为大页的分配和回收相对不灵活,所以在启用 THP 时需要根据系统的实际情况进行评估和调整 ,就像使用大箱子装东西,虽然装的多,但可能不太容易灵活摆放,需要合理规划 。
六、实战案例:从 malloc 看缺页中断全流程
6.1场景复现:用户态程序触发缺页
让我们通过一个具体的 C 语言程序示例,来深入理解 malloc 函数背后隐藏的缺页中断机制。
在这个程序中,我们调用 malloc 函数申请了 1MB 的内存空间。当 malloc 函数返回时,它实际上只是为进程在虚拟地址空间中找到了一段空闲区域,假设这段虚拟地址范围是 0x100000 - 0x100FFF 。此时,内核仅仅是在进程的页表中,将这段虚拟地址对应的页表项标记为无效(invalid),这意味着虽然进程获得了虚拟地址,但对应的物理页还没有被分配 ,就像你预订了一个房间(虚拟地址),但房间还没有被实际装修布置好(未分配物理页)。
当程序执行到ptr[0] = 1;这一行时,进程首次对新分配的虚拟地址进行写入操作 。这时,内存管理单元(MMU)会按照虚拟地址去查询页表,当它发现对应页表项标记为 invalid 时,就如同发现了一个 “空房间”,MMU 会立即向 CPU 报告一个数据中止异常 ,以此来触发缺页中断 。
一旦触发缺页中断,内核便开始介入处理 。内核首先会检查该访问是否合法,在这个例子中,由于是通过合法的 malloc 函数分配的内存,所以访问是合法的 。接下来,内核会为该虚拟地址分配一个新的物理页,假设分配到的物理页帧号(PFN)是0x200。然后,内核会更新页表项,将虚拟地址0x100000 映射到物理页 0x200,并将页表项的权限设置为可写 ,这就像是给房间(虚拟地址)找到了实际的住所(物理页),并赋予了可以装修改造(写操作)的权限 。完成这些操作后,内核恢复程序的执行,ptr[0] = 1;这条指令得以顺利完成,进程继续运行 。
6.2内核日志分析
为了更直观地观察缺页中断的发生过程,我们可以借助内核日志。在 Linux 系统中,内核日志可以通过 dmesg 命令查看 。当上述程序运行并触发缺页中断时,我们在终端执行 dmesg | grep -i page 命令,可能会看到类似以下的日志信息:
从这些日志中,我们可以看到关键信息 。page allocation failure表明发生了页面分配操作,这是因为缺页中断导致内核需要为进程分配新的物理页 ;handle_pte_fault和handle_mm_fault等函数调用栈信息,展示了内核处理缺页中断的函数执行路径 ,就像一个详细的操作记录,告诉我们内核在处理缺页中断时都调用了哪些函数,以及这些函数是如何协同工作的,帮助我们深入了解缺页中断在内核中的处理流程 。