容器与 Pod 有什么区别和联系?这篇文章解决你的困惑

刚开始接触 Kubernetes 时,你学到的第一件事就是每个 Pod 都有一个唯一的 IP 和主机名,并且在同一个 Pod 中,容器可以通过 localhost 相互通信。所以,显而易见,一个 Pod 就像一个微型的服务器。
但是,过段时间,你会发现 Pod 中的每个容器都有一个隔离的文件系统,并且从一个容器内部,你看不到在同一 Pod 的其他容器中运行的进程。好吧!也许 Pod 不是一个微型的服务器,而只是一组具有共享网络堆栈的容器。
但随后你会了解到,Pod 中的容器可以通过共享内存进行通信!所以,在容器之间,网络命名空间不是唯一可以共享的东西……
基于最后的发现,所以,我决定深入了解:
Pod 是如何在底层实现的 Pod 和 Container 之间的实际区别是什么 如何使用 Docker 创建 Pod在此过程中,我希望它能帮助我巩固我的 Linux、Docker 和 Kubernetes 技能。
1、探索 Container
OCI 运行时规范并不将容器实现仅限于 Linux 容器,即使用 namespace 和 cgroup 实现的容器。但是,除非另有明确说明,否则本文中的容器一词指的是这种相当传统的形式。
设置实验环境(playground)在了解构成容器的 namespace 和 cgroups 之前,让我们快速设置一个实验环境:
up
$ vagrant ssh1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.最后让我们启动一个容器:
首先我们来看一下,当容器启动后,哪些隔离原语(primitives)被创建了:
auxf
USER PID ... COMMAND
...
root 4707 /usr/bin/containerd-shim-runc-v2 -namespace moby -idcc9466b3e...
root 4727 \_ nginx: master process nginx -gdaemon off;
systemd+ 4781\_ nginx: worker process
systemd+ 4782\_ nginx: worker process
# Find the namespaces used by 4727 process.$ sudolsns
NS TYPE NPROCS PID USER COMMAND
...
4026532157 mnt 3 4727 root nginx: master process nginx -gdaemon off;
4026532158 uts 3 4727 root nginx: master process nginx -gdaemon off;
4026532159 ipc 3 4727 root nginx: master process nginx -gdaemon off;
4026532160 pid 3 4727 root nginx: master process nginx -gdaemon off;
4026532162 net 3 4727 root nginx: master process nginx -g daemon off;1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.我们可以看到用于隔离以上容器的命名空间是以下这些:
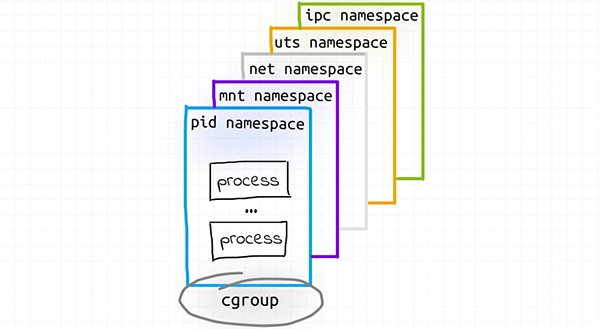
mnt(挂载):容器有一个隔离的挂载表。 uts(Unix 时间共享):容器拥有自己的 hostname 和 domain。 ipc(进程间通信):容器内的进程可以通过系统级 IPC 和同一容器内的其他进程进行通信。 pid(进程 ID):容器内的进程只能看到在同一容器内或拥有相同的 PID 命名空间的其他进程。 net(网络):容器拥有自己的网络堆栈。注意,用户(user)命名空间没有被使用,OCI 运行时规范提及了对用户命名空间的支持。不过,虽然 Docker 可以将此命名空间用于其容器,但由于固有的限制,它默认情况下没有使用。因此,容器中的 root 用户很可能是主机系统中的 root 用户。谨防!
另一个没有出现在这里的命名空间是 cgroup。我花了一段时间才理解 cgroup 命名空间与 cgroups 机制(mechanism)的不同。Cgroup 命名空间仅提供一个容器的 cgroup 层次结构的孤立视图。同样,Docker 也支持将容器放入私有 cgroup 命名空间,但默认情况下没有这么做。
探索容器的 cgroupsLinux 命名空间可以让容器中的进程认为自己是在一个专用的机器上运行。但是,看不到别的进程并不意味着不会受到其他进程的影响。一些耗资源的进程可能会意外的过多消耗宿主机上面共享的资源。
这时候就需要 cgroups 的帮助!
可以通过检查 cgroup 虚拟文件系统中的相应子树来查看给定进程的 cgroups 限制。Cgroupfs 通常被挂在 /sys/fs/cgroup 目录,并且进程特定相关的部分可以在 /proc//cgroup 中查看:
/cgroup
11:freezer:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
10:blkio:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
9:rdma:/
8:pids:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
7:devices:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
6:cpuset:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
5:cpu,cpuacct:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
4:memory:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
3:net_cls,net_prio:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
2:perf_event:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
1:name=systemd:/docker/cc9466b3eb67ca374c925794776aad2fd45a34343ab66097a44594b35183dba0
0::/system.slice/containerd.service1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.似乎 Docker 使用 /docker/模式。好吧,不管怎样
/memory.limit_in_bytes
536870912 # Yay! Its the 512MB we requested!# See the CPU limits.ls /sys/fs/cgroup/cpu/docker/${ID}1.2.3.4.5.6.有趣的是在不明确设置任何资源限制的情况下启动容器都会配置一个 cgroup。实际中我没有检查过,但我的猜测是默认情况下,CPU 和 RAM 消耗不受限制,Cgroups 可能用来限制从容器内部对某些设备的访问。
这是我在调查后脑海中呈现的容器:
2、探索 Pod
现在,让我们来看看 Kubernetes Pod。与容器一样,Pod 的实现可以在不同的 CRI 运行时(runtime)之间变化。例如,当 Kata 容器被用来作为一个支持的运行时类时,某些 Pod 可以就是真实的虚拟机了!并且正如预期的那样,基于 VM 的 Pod 与传统 Linux 容器实现的 Pod 在实现和功能方面会有所不同。
为了保持容器和 Pod 之间公平比较,我们会在使用 ContainerD/Runc 运行时的 Kubernetes 集群上进行探索。这也是 Docker 在底层运行容器的机制。
设置实验环境(playground)这次我们使用基于 VirtualBox driver 和 Containd 运行时的 minikube 来设置实验环境。要快速安装 minikube 和 kubectl,我们可以使用 Alex Ellis 编写的 arkade 工具:
kubectl minikube
$ minikube start --driver virtualbox --container-runtime containerd1.2.3.4.实验的 Pod,可以按照下面的方式设置:
实际的 Pod 检查应在 Kubernetes 集群节点上进行:
让我们看看那里 Pod 的进程:
auxf
USER PID ... COMMAND
...
root 4947 \_ containerd-shim -namespace k8s.io -workdir/mnt/sda1/var/lib/containerd/...
root 4966\_ /pause
root 4981 \_ containerd-shim -namespace k8s.io -workdir/mnt/sda1/var/lib/containerd/...
root 5001 \_ /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -kgevent
root 5016 \_ /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -kgevent
root 5018 \_ containerd-shim -namespace k8s.io -workdir/mnt/sda1/var/lib/containerd/...
100 5035 \_ /bin/sleep 3650d1.2.3.4.5.6.7.8.9.10.基于运行的时间,上述三个进程组很有可能是在 Pod 启动期间创建。这很有意思,因为在清单文件中,只有两个容器,httpbin 和 sleep。
可以使用名为 ctr 的 ContainerD 命令行来交叉检查上述的发现:
CONTAINER IMAGE RUNTIME
...
097d4fe8a7002 docker.io/curlimages/curl@sha256:1a220 io.containerd.runtime.v1.linux
...
dfb1cd29ab750 docker.io/kennethreitz/httpbin:latest io.containerd.runtime.v1.linux
...
f0e87a9330466 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux1.2.3.4.5.6.7.8.的确是三个容器被创建了。同时,使用另一个和 CRI 运行时监控的命令行 crictl 检测发现,仅仅只有两个容器:
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
097d4fe8a7002 bcb0c26a91c90 About an hour ago Running sidecar 0f0e87a9330466
dfb1cd29ab750 b138b9264903f About an hour ago Running app 0 f0e87a93304661.2.3.4.但是注意,上述的 POD ID 字段和 ctr 输出的 pause:3.1 容器 id 一致。好吧,看上去这个 Pod 是一个辅助容器。所以,它有什么用呢?
我还没有注意到在 OCI 运行时规范中有和 Pod 相对应的东西。因此,当我对 Kubernetes API 规范提供的信息不满意时,我通常直接进入 Kubernetes Container Runtime 接口(CRI)Protobuf 文件中查找相应的信息:
复制// kubelet expects any compatible container runtime
// to implement the following gRPC methods:
serviceRuntimeService {
...
rpc RunPodSandbox(RunPodSandboxRequest) returns (RunPodSandboxResponse) {}
rpc StopPodSandbox(StopPodSandboxRequest) returns (StopPodSandboxResponse) {}
rpc RemovePodSandbox(RemovePodSandboxRequest) returns (RemovePodSandboxResponse) {}
rpc PodSandboxStatus(PodSandboxStatusRequest) returns (PodSandboxStatusResponse) {}
rpc ListPodSandbox(ListPodSandboxRequest) returns (ListPodSandboxResponse) {}
rpc CreateContainer(CreateContainerRequest) returns (CreateContainerResponse) {}
rpc StartContainer(StartContainerRequest) returns (StartContainerResponse) {}
rpc StopContainer(StopContainerRequest) returns (StopContainerResponse) {}
rpc RemoveContainer(RemoveContainerRequest) returns (RemoveContainerResponse) {}
rpc ListContainers(ListContainersRequest) returns (ListContainersResponse) {}
rpc ContainerStatus(ContainerStatusRequest) returns (ContainerStatusResponse) {}
rpc UpdateContainerResources(UpdateContainerResourcesRequest) returns (UpdateContainerResourcesResponse) {}
rpc ReopenContainerLog(ReopenContainerLogRequest) returns (ReopenContainerLogResponse) {}
// ...
}
message CreateContainerRequest {
// ID of the PodSandbox inwhich the container should be created.
string pod_sandbox_id = 1;
// Config of the container.
ContainerConfig config = 2;
// Config of the PodSandbox. This is the same config that was passed
// to RunPodSandboxRequest to create the PodSandbox. It is passed again
// here just foreasy reference. The PodSandboxConfig is immutable and
// remains the same throughout the lifetime of the pod.
PodSandboxConfig sandbox_config = 3;
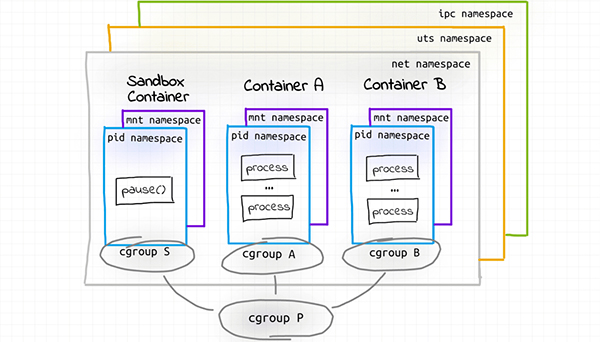
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.所以,Pod 实际上就是由沙盒以及在沙盒中运行的容器组成的。沙盒管理 Pod 中所有容器的常用资源,pause 容器会在 RunPodSandbox() 调用中被启动。简单的互联网搜索就发现了该容器仅仅是一个 idle 进程。
探索 Pod 的命名空间下面就是集群节点上的命名空间:
lsns
NS TYPE NPROCS PID USER COMMAND
4026532614 net 4 4966root /pause
4026532715 mnt 1 4966root /pause
4026532716 uts 4 4966root /pause
4026532717 ipc 4 4966root /pause
4026532718 pid 1 4966root /pause
4026532719 mnt 2 5001 root /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -kgevent
4026532720 pid 2 5001 root /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -kgevent
4026532721 mnt 1 5035 100/bin/sleep 3650d
4026532722 pid 1 5035 100 /bin/sleep 3650d1.2.3.4.5.6.7.8.9.10.11.前面第一部分很像 Docker 容器,pause 容器有五个命名空间:net、mnt、uts、ipc 以及 pid。但是很明显,httpbin 和 sleep 容器仅仅有两个命名空间:mnt 和 pid。这是怎么回事?
事实证明,lsns 不是检查进程名称空间的最佳工具。相反,要检查某个进程使用的命名空间,可以参考 /proc/${pid}/ns 位置:
/proc/5001/ns
...
lrwxrwxrwx 1 root root 0 Oct 24 14:05 ipc -> ipc:[4026532717]lrwxrwxrwx 1 root root 0 Oct 24 14:05 mnt -> mnt:[4026532719]lrwxrwxrwx 1 root root 0 Oct 24 14:05 net -> net:[4026532614]lrwxrwxrwx 1 root root 0 Oct 24 14:05 pid -> pid:[4026532720]lrwxrwxrwx 1 root root 0 Oct 24 14:05 uts -> uts:[4026532716]# sleep containersudo ls -l/proc/5035/ns
...
lrwxrwxrwx 1 100 101 0 Oct 24 14:05 ipc -> ipc:[4026532717]lrwxrwxrwx 1 100 101 0 Oct 24 14:05 mnt -> mnt:[4026532721]lrwxrwxrwx 1 100 101 0 Oct 24 14:05 net -> net:[4026532614]lrwxrwxrwx 1 100 101 0 Oct 24 14:05 pid -> pid:[4026532722]lrwxrwxrwx 1 100 101 0 Oct 24 14:05 uts -> uts:[4026532716]1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.虽然不太容易去注意到,但 httpbin 和 sleep 容器实际上重用了 pause 容器的 net、uts 和 ipc 命名空间!
我们可以用 crictl 交叉检测验证:
crictl inspect dfb1cd29ab750
{
...
"namespaces": [
{
"type": "pid"}
{
"type": "ipc",
"path": "/proc/4966/ns/ipc"},
{
"type": "uts",
"path": "/proc/4966/ns/uts"},
{
"type": "mount"},
{
"type": "network",
"path": "/proc/4966/ns/net"}
],
...
}
# Inspect sleep container.$ sudocrictl inspect 097d4fe8a7002
...1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.我认为上述发现完美的解释了同一个 Pod 中容器具有的能力:
能够互相通信 通过 localhost 和/或 使用 IPC(共享内存,消息队列等) 共享 domain 和 hostname然而,在看过所有这些命名空间如何在容器之间自由重用之后,我开始怀疑默认边界可以被打破。实际上,在对 Pod API 规范的更深入阅读后发现,将 shareProcessNamespace 标志设置为 true 时,Pod 的容器将拥有四个通用命名空间,而不是默认的三个。但是有一个更令人震惊的发现——hostIPC、hostNetwork 和 hostPID 标志可以使容器使用相应主机的命名空间。
有趣的是,CRI API 规范似乎更加灵活。至少在语法上,它允许将 net、pid 和 ipc 命名空间限定为 CONTAINER、POD 或 NODE。因此,可以构建一个 Pod 使其容器无法通过 localhost 相互通信 。
探索 Pod 的 cgroupsPod 的 cgroups 是什么样的?systemd-cgls 可以很好地可视化 cgroups 层次结构:
systemd-cgls
Control group /:
-.slice
├─kubepods
│ ├─burstable
│ │ ├─pod4a8d5c3e-3821-4727-9d20-965febbccfbb
│ │ │ ├─f0e87a93304666766ab139d52f10ff2b8d4a1e6060fc18f74f28e2cb000da8b2
│ │ │ │ └─4966 /pause
│ │ │ ├─dfb1cd29ab750064ae89613cb28963353c3360c2df913995af582aebcc4e85d8
│ │ │ │ ├─5001 /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -kgevent
│ │ │ │ └─5016 /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -kgevent
│ │ │ └─097d4fe8a7002d69d6c78899dcf6731d313ce8067ae3f736f252f387582e55ad
│ │ │ └─5035 /bin/sleep 3650d
...1.2.3.4.5.6.7.8.9.10.11.12.13.14.所以,Pod 本身有一个父节点(Node),每个容器也可以单独调整。这符合我的预期,因为在 Pod 清单中,可以为 Pod 中的每个容器单独设置资源限制。
此刻,我脑海中的 Pod 看起来是这样的:
3、利用 Docker 实现 Pod
如果 Pod 的底层实现是一组具有共同 cgroup 父级的半融合(emi-fused)容器,是否可以使用 Docker 生产类似 Pod 的构造?
最近我尝试做了一些类似的事情来让多个容器监听同一个套接字,我知道 Docker 可以通过 docker run —network container:语法来创建一个可以使用已存在的网络命名空间容器。但我也知道 OCI 运行时规范只定义了 create 和 start 命令。
因此,当你使用 docker exec在现有容器中执行命令时,实际上是在运行(即 create 然后 start)一个全新的容器,该容器恰好重用了目标容器的所有命名空间(证明 1[1] 和 2[2])。这让我非常有信心可以使用标准 Docker 命令生成 Pod。
我们可以使用仅仅安装了 Docker 的机器作为实验环境。但是这里我会使用一个额外的包来简化使用 cgroups:
首先,让我们配置一个父 cgroup 条目。为了简洁起见,我将仅使用 CPU 和内存控制器:
cpu,memory:/pod-foo
# Check if the corresponding folders were created:ls -l/sys/fs/cgroup/cpu/pod-foo/
ls -l /sys/fs/cgroup/memory/pod-foo/1.2.3.4.然后我们创建一个沙盒容器:
\
--namefoo_sandbox \
--cgroup-parent/pod-foo \
--ipc shareable\
alpine sleep infinity1.2.3.4.5.最后,让我们启动重用沙盒容器命名空间的实际容器:
\
--nameapp \
--cgroup-parent/pod-foo \
--networkcontainer:foo_sandbox \
--ipccontainer:foo_sandbox \
kennethreitz/httpbin
# sidecar (sleep)$ docker run -d --rm\
--namesidecar \
--cgroup-parent/pod-foo \
--networkcontainer:foo_sandbox \
--ipccontainer:foo_sandbox \
curlimages/curl sleep 365d1.2.3.4.5.6.7.8.9.10.11.12.13.14.你注意到我省略了哪个命名空间吗?没错,我不能在容器之间共享 uts 命名空间。似乎目前在 docker run 命令中没法实现。嗯,是有点遗憾。但是除开 uts 命名空间之外,它是成功的!
cgroups 看上去很像 Kubernetes 创建的:
systemd-cgls memory
Controller memory; Control group /:
├─pod-foo
│ ├─488d76cade5422b57ab59116f422d8483d435a8449ceda0c9a1888ea774acac7
│ │ ├─27865 /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -kgevent
│ │ └─27880 /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -kgevent
│ ├─9166a87f9a96a954b10ec012104366da9f1f6680387ef423ee197c61d37f39d7
│ │ └─27977 sleep365d
│ └─c7b0ec46b16b52c5e1c447b77d67d44d16d78f9a3f93eaeb3a86aa95e08e28b6
│ └─27743 sleep infinity1.2.3.4.5.6.7.8.9.10.全局命名空间列表看上去也很相似:
lsns
NS TYPE NPROCS PID USER COMMAND
...
4026532157 mnt 1 27743 root sleepinfinity
4026532158 uts 1 27743 root sleepinfinity
4026532159 ipc 4 27743 root sleepinfinity
4026532160 pid 1 27743 root sleepinfinity
4026532162 net 4 27743 root sleepinfinity
4026532218 mnt 2 27865 root /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -kgevent
4026532219 uts 2 27865 root /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -kgevent
4026532220 pid 2 27865 root /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -kgevent
4026532221 mnt 1 27977 _apt sleep365d
4026532222 uts 1 27977 _apt sleep365d
4026532223 pid 1 27977 _apt sleep 365d1.2.3.4.5.6.7.8.9.10.11.12.13.14.httpbin 和 sidecar 容器看上去共享了 ipc 和 net 命名空间:
/proc/27865/ns
lrwxrwxrwx 1 root root 0 Oct 28 07:56 ipc -> ipc:[4026532159]lrwxrwxrwx 1 root root 0 Oct 28 07:56 mnt -> mnt:[4026532218]lrwxrwxrwx 1 root root 0 Oct 28 07:56 net -> net:[4026532162]lrwxrwxrwx 1 root root 0 Oct 28 07:56 pid -> pid:[4026532220]lrwxrwxrwx 1 root root 0 Oct 28 07:56 uts -> uts:[4026532219]# sidecar container$ sudo ls -l/proc/27977/ns
lrwxrwxrwx 1 _apt systemd-journal 0 Oct 28 07:56 ipc -> ipc:[4026532159]lrwxrwxrwx 1 _apt systemd-journal 0 Oct 28 07:56 mnt -> mnt:[4026532221]lrwxrwxrwx 1 _apt systemd-journal 0 Oct 28 07:56 net -> net:[4026532162]lrwxrwxrwx 1 _apt systemd-journal 0 Oct 28 07:56 pid -> pid:[4026532223]lrwxrwxrwx 1 _apt systemd-journal 0 Oct 28 07:56 uts -> uts:[4026532222]1.2.3.4.5.6.7.8.9.10.11.12.13.14.4、总结
Container 和 Pod 是相似的。在底层,它们主要依赖 Linux 命名空间和 cgroup。但是,Pod 不仅仅是一组容器。Pod 是一个自给自足的高级构造。所有 Pod 的容器都运行在同一台机器(集群节点)上,它们的生命周期是同步的,并且通过削弱隔离性来简化容器间的通信。这使得 Pod 更接近于传统的 VM,带回了熟悉的部署模式,如 sidecar 或反向代理。