前言
在我们的日常开发中,经常会遇到分页查询接口的性能问题。
该接口访问前面几页很快,越往后翻页,接口返回速度越慢。
今天跟大家一起聊聊千万级大表如何高效的做分页查询,希望对你会有所帮助。
1.千万级大表分页为什么性能差?
核心痛点:当千万级别的订单大表需要查询limit 9999990,10时:
复制
SELECT * FROM orders
ORDER BY create_time DESC
LIMIT 9999990,10;1.2.3.
在分库分表环境下:
每个分片需扫描前9999990条归并节点需处理分片数 × 1000万数据内存溢出风险高达90%
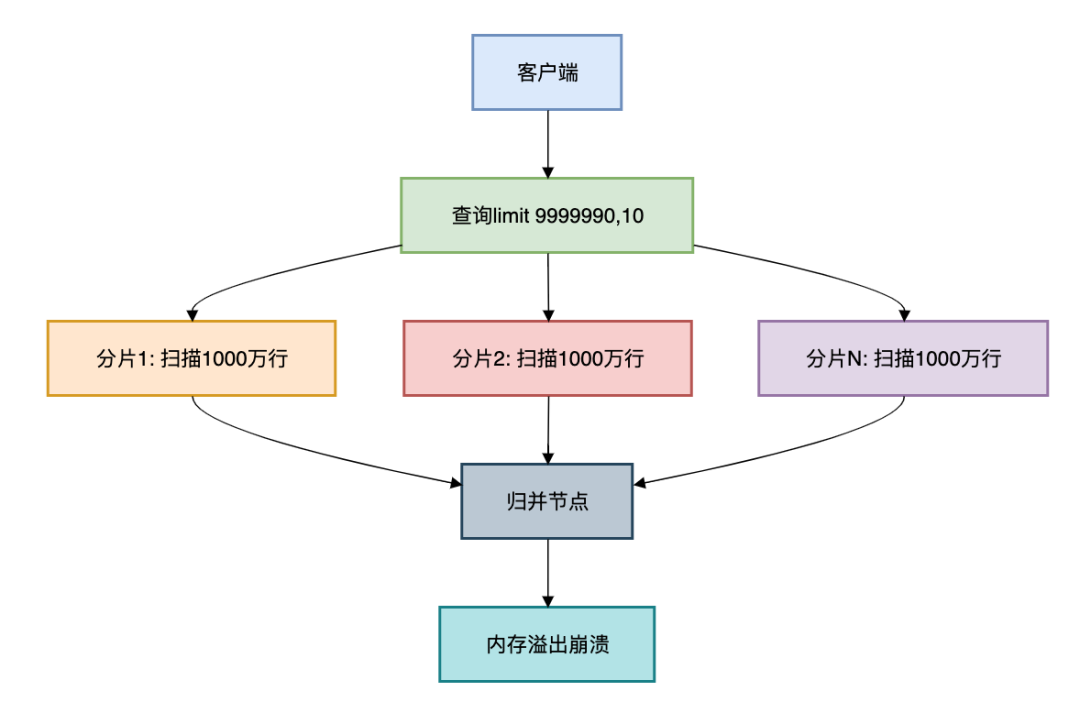
真实案例:某电商订单查询事故
在128分片的订单表上执行深度分页,实际扫描了128 × 1000万 = 12.8亿行数据,导致数据库集群OOM!
2.深分页的常见解决方案
方案1:游标分页(最优解)
原理:基于有序字段的连续分页
复制
public PageResult<Order> queryOrders(String lastCursor, int size) {
if (lastCursor == null) {
return orderDao.firstPage(size);
}
return orderDao.nextPage(lastCursor, size);
}1.2.3.4.5.6.
SQL优化:
复制
/* 首次查询 */
SELECT * FROM orders
ORDERBYidDESC
LIMIT10;
/* 后续查询 */
SELECT * FROM orders
WHEREid < ?lastId
ORDERBYidDESC
LIMIT10;1.2.3.4.5.6.7.8.9.10.
性能对比:
分页方式
100万页扫描行数
响应时间
传统limit
128亿行
>30s
游标分页
1280行
10ms
方案2:覆盖索引+延迟关联
适用场景:需要跳页的非连续查询
三步优化法:
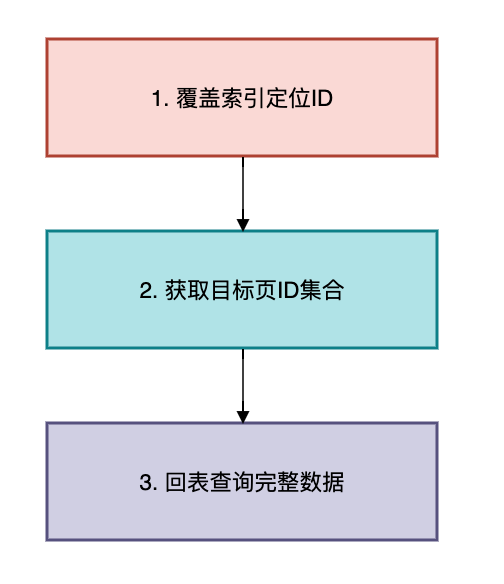
SQL实现:
复制
/* 传统写法(全表扫描) */
SELECT * FROM orders ORDERBY create_time DESCLIMIT9999990,10;
/* 优化写法 */
SELECT * FROM orders
WHEREidIN (
SELECTidFROM orders
ORDERBY create_time DESC
LIMIT9999990,10-- 仅扫描索引
);1.2.3.4.5.6.7.8.9.10.
执行计划对比:
类型
扫描行数
是否回表
是否文件排序
传统查询
1000万+
是
是
优化查询
10
是
否
方案3:全局二级索引
架构设计:

Java实现:
复制
public List<Order> queryByPage(int page, int size) {
// 1. 查询全局索引
PositionRange range = indexService.locate(page, size);
// 2. 分片并行查询
Map<ShardKey, Future<List<Order>>> futures = new HashMap<>();
for (Shard shard : shards) {
futures.put(shard.key, executor.submit(() ->
shard.query(range.startId, range.endId)
);
}
// 3. 结果归并
List<Order> result = new ArrayList<>();
for (Future<List<Order>> future : futures.values()) {
result.addAll(future.get());
}
return result;
}1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.
方案4:基因分片法
解决分页字段与分片键不一致问题:
复制
// 订单ID注入用户基因
long userId = 123456;
long orderId = (userId % 1024) << 54 | snowflake.nextId();1.2.3.
查询优化:
复制
SELECT * FROM orders
WHERE user_id = 123456
ORDER BY create_time DESC
LIMIT 9999990,10;1.2.3.4.
通过user_id路由到同一分片,避免跨分片查询
方案5:冷热分离 + ES同步
架构设计:
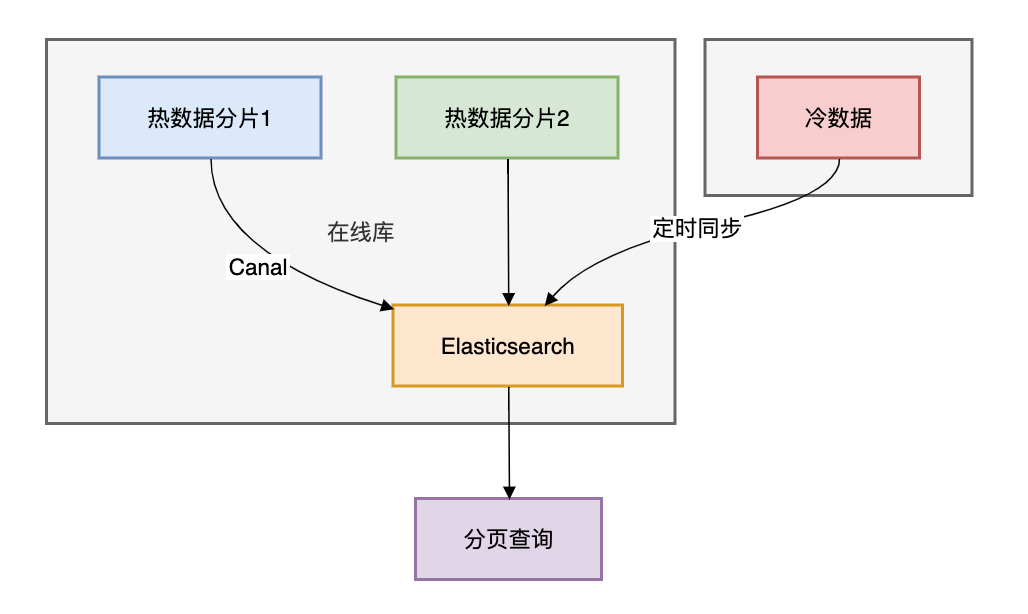
查询示例:
复制
SearchRequest request = new SearchRequest("orders_index");
request.source().sort(SortBuilders.fieldSort("create_time").order(SortOrder.DESC));
request.source().from(9999990).size(10);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);1.2.3.4.
ES分页原理:通过search_after实现深度分页"search_after": [lastOrderId, lastCreateTime]
方案6:业务折衷方案
1. 最大页数限制
复制
public PageResult query(int page, int size) {
if (page > MAX_PAGE) {
throw new BusinessException("最多查询前" + MAX_PAGE + "页");
}
// ...
}1.2.3.4.5.6.
2. 跳页转搜索
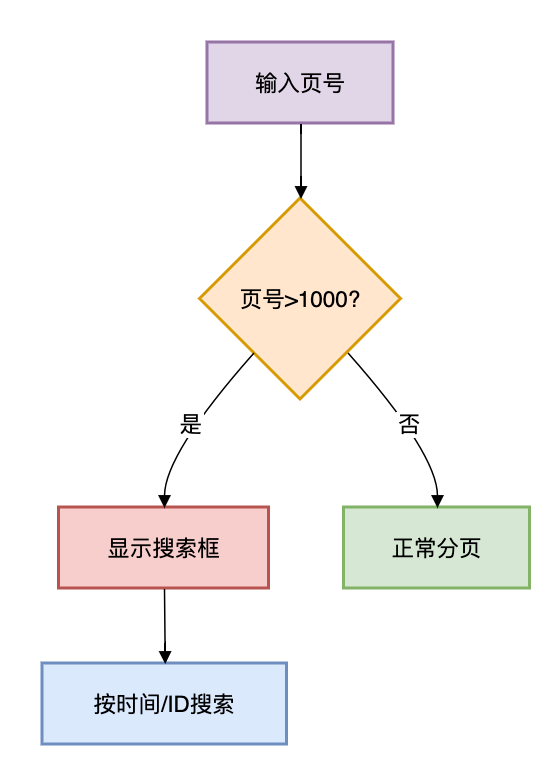
3.如何做性能优化?
3.1 索引设计黄金法则
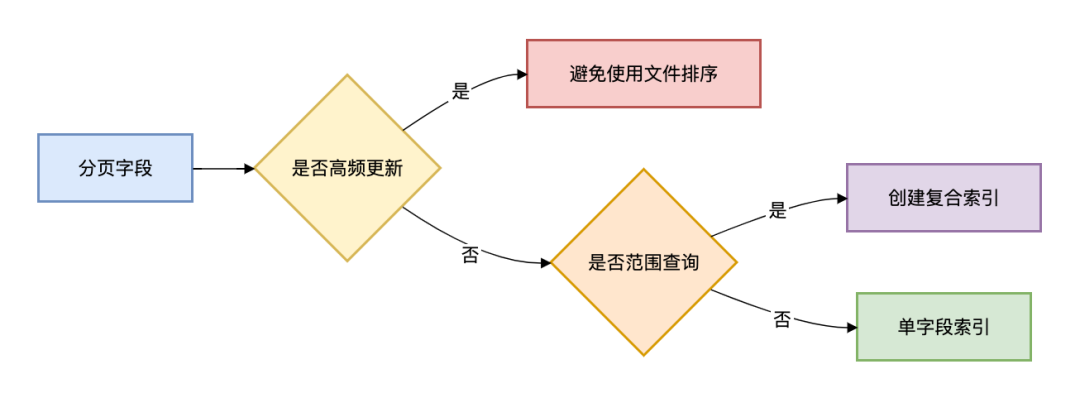
3.2 分页查询检查清单
复制
public void validateQuery(PageQuery query) {
if (query.getPage() > 1000 && !query.isAdmin()) {
throw new PermissionException("非管理员禁止深度分页");
}
if (query.getSize() > 100) {
query.setSize(100); // 强制限制每页数量
}
}1.2.3.4.5.6.7.8.9.
3.3 分页监控指标
指标
预警阈值
处理方案
单次扫描行数
>10万
检查是否走索引
分页响应时间
>500ms
优化SQL或增加缓存
归并节点内存使用率
>70%
扩容或调整分页策略
3.4 性能压测对比
方案
100万页耗时
CPU峰值
内存消耗
适用场景
原生limit
超时(>30s)
100%
OOM
禁止使用
游标分页
23ms
15%
50MB
连续分页
覆盖索引
210ms
45%
200MB
非连续跳页
二级索引归并
320ms
60%
300MB
分布式环境
ES搜索
120ms
30%
150MB
复杂查询
基因分片
85ms
25%
100MB
分库分表环境
测试环境:阿里云 PolarDB-X 32核128GB × 8节点
总结
单体阶段limit offset, size + 索引优化分库分表初期游标分页 + 最大页数限制百万级数据二级索引归并 + 异步构建千万级数据ES/Canal准实时搜索亿级高并发分布式游标服务 + 状态持久化
分页方案选型表:
场景
推荐方案
注意事项
用户连续浏览
游标分页
需有序字段
后台跳页查询
覆盖索引
索引维护成本
分库分表环境
基因分片
分片键设计
复杂条件搜索
ES同步
数据延迟问题
开放平台API
二级索引归并
索引存储空间
历史数据导出
分段扫描
避免事务超时
记住:没有完美的方案,只有最适合业务场景的权衡。
没有最好的方案,只有最适合场景的设计。