Redis是如何高效管理有限内存的?
过期删除策略的深度剖析
Redis 可以对 key 设置过期时间的,为了防止过期的key长期占用内存,需要相应的过期删除策略将过期的key删除
基础操作
Redis设置过期时间setex key1 5 value1:创建记录的时候指定过期时间,设置key1在5秒后过期其实Redis这是一种基于创建时间来判定是否过期的机制,也即常规上说的TTL策略,当设定了过期时间之后不管有没有被使用都会到期被强制清理掉。但有很多场景下也会期望数据能够按照TTI(指定时间未使用再过期)的方式来过期清理,如用户鉴权场景:
假设用户登录系统后生成token并存储到Redis中,指定token有效期30分钟,那么如果用户一直在使用系统的时候突然时间到了然后退出要求重新登录,这个体验感就会很差。正确的预期应该是用户连续操作的时候就不要退出登录,只有连续30分钟没有操作的时候才过期处理。
略有遗憾的是,Redis并不支持按照TTI机制来做数据过期处理。但是作为补偿,Redis提供了一个重新设定某个key值过期时间的方法,可以通过expire方法来实现指定key的续期操作,以一种曲线救国的方式满足诉求。
实现缓存续期expire <key> <n>:设置 key 在 n 秒后过期,比如 expire key 100 表示设置 key 在 100 秒后过期;pexpire <key> <n>:设置 key 在 n 毫秒后过期,比如 pexpire key2 100000 表示设置 key2 在 100000 毫秒(100 秒)后过期。expireat <key> <n>:设置 key 在某个时间戳(精确到秒)之后过期,比如 expireat key3 1683187646 表示 key3 在时间戳 1683187646 后过期(精确到秒);pexpireat <key> <n>:设置 key 在某个时间戳(精确到毫秒)之后过期,比如 pexpireat key4 1683187660972 表示 key4 在时间戳 1683187660972 后过期(精确到毫秒)对于上面说的用户token续期的诉求,可以这样来操作:
用户首次登录成功后,会生成一个token令牌,然后将令牌与用户信息存储到redis中,设定30分钟有效期。 每次请求接口中携带token来鉴权,每次get请求的时候,就重新通过expire操作将token的过期时间重新设定为30分钟。 持续30分钟无请求后,此条token缓存信息过期失效。同样实现了TTI的效果。
ttl查看过期时间
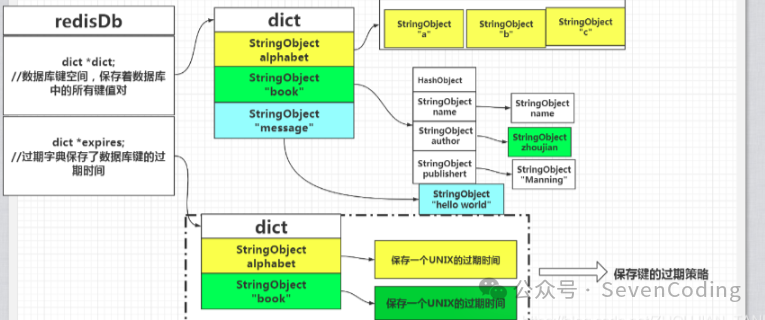
dict是hash表
*dict是键值对,指向的是数据库中保存的具体的key value对象,key是String类型,value是具体的数据类型*expires是过期字典,key与*dict中的key一致,value则是一个 long long 类型的整数,这个整数保存了 key 的过期时间;过期字典的数据结构如下图所示:
 图片
图片
简单地总结来说就是,设置了失效时间的key和具体的失效时间全部都维护在 expires 这个字典表中。未设置失效时间的key不会出现在expires字典表中。
所以当查询一个 key 时,Redis 首先检查该 key 是否存在于expires过期字典中:
如果不在,则正常读取键值;如果存在,则会获取该 key 的过期时间,然后与当前系统时间进行比对,如果比系统时间大,那就没有过期,否则判定该 key 已过期。过期删除策略
定时删除在设置key的过期时间的同时,为该key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除。
优点:保证内存被尽快释放,对内存友好
缺点:若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key,定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重。对CPU不友好
结论:此方法基本上没人用
惰性删除过期的key并不一定会马上删除,还会占用着内存。 当你真正查询这个key时,redis会检查一下,这个设置了过期时间的key是否过期了? 如果过期了就会删除,返回空。这就是惰性删除。
优点:删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,对 CPU友好
缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露。对内存不友好
定期删除每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键,至于要删除多少过期键,以及要检查多少个数据库,由算法决定
优点:通过限制删除操作执行的时长和频率,来减少删除操作对 CPU 的影响,同时也能删除一部分过期的数据减少了过期键对空间的无效占用。
缺点:
内存清理方面没有定时删除效果好,同时没有惰性删除使用的系统资源少。难以确定删除操作执行的时长和频率。如果执行的太频繁,定期删除策略变得和定时删除策略一样,对CPU不友好;如果执行的太少,那又和惰性删除一样了,过期 key 占用的内存不能及时得到释放Redis的过期删除策略
redis实际使用的过期键删除策略是定期删除策略和惰性删除策略:
定期删除策略:redis 会将每个设置了过期时间的 key 放入到一个独立的字典中,以后会定时遍历这个字典来删除到期的 key。惰性删除策略:只有当访问某个key时,才判断这个key是否已过期,如果已经过期,则从实例中删除定时删除是集中处理,惰性删除是零散处理。
定期删除策略Redis内部维护一个定时任务,默认每秒进行10次(也就是每隔100毫秒一次)过期扫描,过期扫描不会遍历过期字典中所有的 key,而是采用了一种简单的贪心策略。
从过期字典中随机取出20个key删除这 20 个 key 中已经过期的 key;如果这20个key中过期key的比例超过了25%,则重复步骤1为了保证过期扫描不会出现循环过度,导致线程卡死现象,算法还增加了扫描时间的上限,默认不会超过 25ms。
为什么key集中过期时,其它key的读写效率会降低?
Redis的定期删除策略是在Redis主线程中执行的,也就是说如果在执行定期删除的过程中,出现了需要大量删除过期key的情况,那么在业务访问时,必须等这个定期删除任务执行结束,才可以处理业务请求。此时就会出现,业务访问延时增大的问题,最大延迟为25毫秒。
为了尽量避免这个问题,在设置过期时间时,可以给过期时间设置一个随机范围,避免同一时刻过期。
惰性删除策略RDB:
生成rdb文件:生成时,程序会对key进行检查,过期key不放入rdb文件。载入rdb文件:载入时,如果以主服务器模式运行,程序会对文件中保存的key进行检查,未过期的key会被载入到数据库中,而过期key则会忽略;如果以从服务器模式运行,无论键过期与否,均会载入数据库中,过期key会通过与主服务器同步而删除。AOF:
当服务器以AOF持久化模式运行时,如果数据库中的某个key已经过期,但它还没有被惰性删除或者定期删除,那么AOF文件不会因为这个过期key而产生任何影响当过期key被惰性删除或者定期删除之后,程序会向AOF文件追加一条DEL命令,来显示的记录被该key已经发被删除在执行AOF重写的过程中,程序会对数据库中的key进行检查,已过期的key不会被保存到重写后的AOF文件中主从复制:当服务器运行在复制模式下时,从服务器的过期删除动作由主服务器控制:
主服务器在删除一个过期key后,会显式地向所有从服务器发送一个del命令,告知从服务器删除这个过期key;从服务器在执行客户端发送的读命令时,即使碰到过期key也不会将过期key删除,而是继续像处理未过期的key一样来处理过期key;从服务器只有在接到主服务器发来的del命令后,才会删除过期key。内存淘汰策略
过期删除策略,是删除已过期的 key,而当 Redis 的运行内存已经超过 Redis 设置的最大内存之后,则会使用内存淘汰策略删除符合条件的 key,以此来保障 Redis 高效的运行。这两个机制虽然都是做删除的操作,但是触发的条件和使用的策略都是不同的。
数据过期,是符合业务预期的一种数据删除机制,为记录设定过期时间,过期后从缓存中移除。数据淘汰,是一种“有损自保”的降级策略,是业务预期之外的一种数据删除手段。指的是所存储的数据没达到过期时间,但缓存空间满了,对于新的数据想要加入内存时,为了避免OOM而需要执行的一种应对策略。基础操作
设置 Redis 最大运行内存在配置文件redis.conf 中,可以通过参数 maxmemory <bytes> 来设定最大内存,当数据内存达到 maxmemory 时,便会触发redis的内存淘汰策略
不进行数据淘汰noeviction:不会淘汰任何数据。
当使用的内存空间超过 maxmemory 值时,也不会淘汰任何数据,但是再有写请求时,则返回OOM错误。
进行数据淘汰volatile-lru:针对设置了过期时间的key,使用lru算法进行淘汰。allkeys-lru:针对所有key使用lru算法进行淘汰。volatile-lfu:针对设置了过期时间的key,使用lfu算法进行淘汰。allkeys-lfu:针对所有key使用lfu算法进行淘汰。volatile-random:针对设置了过期时间的key中使用随机淘汰的方式进行淘汰。allkeys-random:针对所有key使用随机淘汰机制进行淘汰。volatile-ttl:针对设置了过期时间的key,越早过期的越先被淘汰。Redis对随机淘汰和LRU策略进行的更精细化的实现,支持将淘汰目标范围细分为全部数据和设有过期时间的数据,这种策略相对更为合理一些。因为一般设置了过期时间的数据,本身就具备可删除性,将其直接淘汰对业务不会有逻辑上的影响;而没有设置过期时间的数据,通常是要求常驻内存的,往往是一些配置数据或者是一些需要当做白名单含义使用的数据(比如用户信息,如果用户信息不在缓存里,则说明用户不存在),这种如果强行将其删除,可能会造成业务层面的一些逻辑异常。
Redis的内存淘汰算法
操作系统本身有其内存淘汰算法,针对内存页面淘汰,详情请看 内存的页面置换算法[1]
LRU 算法LRU( Least Recently Used,最近最少使用)淘汰算法:是一种常用的页面置换算法,也就是说最久没有使用的缓存将会被淘汰。
传统的LRU 是基于链表结构实现的,链表中的元素按照操作顺序从前往后排列,最新操作的key会被移动到表头,当需要进行内存淘汰时,只需要删除链表尾部的元素即可,因为链表尾部的元素就代表最久未被使用的元素。
但是传统的LRU算法存在两个问题:
需要用链表管理所有的缓存数据,这会带来额外的空间开销;当有数据被访问时,需要在链表上把该数据移动到头端,如果有大量数据被访问,就会带来很多链表元素的移动操作,会很耗时,进而会降低 Redis 缓存性能。Redis 使用的是一种近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是给现有的数据结构添加一个额外的字段,用于记录此key的最后一次访问时间。Redis 内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 5 个值 (此值可配置) ,然后淘汰一个最少访问的key,之后把剩下的key暂存到一个池子中,继续随机取出一批key,并与之前池子中的key比较,再淘汰一个最少访问的key。以此循环,直到内存降到maxmemory之下。
在 LRU 算法中,Redis 对象头的 24 bits 的 lru 字段是用来记录 key 的访问时间戳,因此在 LRU 模式下,Redis可以根据对象头中的 lru 字段记录的值,来比较最后一次 key 的访问时间长,从而淘汰最久未被使用的 key。
但是 LRU 算法有一个问题,无法解决缓存污染问题,比如应用一次读取了大量的数据,而这些数据只会被读取这一次,那么这些数据会留存在 Redis 缓存中很长一段时间,造成缓存污染。Redis利用LFU解决这个问题
LFU 算法最不常用的算法是根据总访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
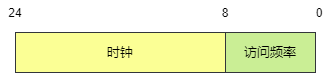
Redis 的 LFU 算法也是通过 robj 对象的 lru 字段来保存 Key 的访问频率的,LFU 算法把 lru 字段分为两部分,如下图:
 图片
图片
由于访问频率计数器只有8个位,所以取值范围为 0 ~ 255,如果每访问 Key 都增加 1,那么很快就用完,LFU 算法也就不起效果了。所以 Redis 使用了一种比较复杂的算法了计算访问频率,算法如下:
先按照上次访问距离当前的时长,来对 logc 进行衰减;然后,再按照一定概率增加 logc 的值具体为:
在每次 key 被访问时,会先对 访问频率 做一个衰减操作,衰减的值跟前后访问时间的差距有关系,如果上一次访问的时间与这一次访问的时间差距很大,那么衰减的值就越大,这样实现的 LFU 算法是根据访问频率来淘汰数据的,而不只是访问次数。访问频率需要考虑 key 的访问是多长时间段内发生的。key 的先前访问距离当前时间越长,那么这个 key 的访问频率相应地也就会降低,这样被淘汰的概率也会更大。对 访问频率 做完衰减操作后,就开始对 访问频率 进行增加操作,增加操作并不是单纯的 + 1,而是根据概率增加,如果 访问频率 越大的 key,它的 访问频率 就越难再增加。访问频率衰减算法:原理就是,Key 越久没被访问,衰减的程度就越大。
从 LFUDecrAndReturn 函数可知,lfu-decay-time 设置越大,衰减的力度就越小。如果 lfu-decay-time 设置为1,并且 Key 在 10 分钟内没被访问的话,按算法可知,访问频率计数器就会被衰减10。
访问频率增加算法:
[1] 内存的页面置换算法: https://www.seven97.top/cs-basics/operating-system/memorypagereplacementalgorithm.html